
DCPNet: A Densely Connected Pyramid Network for Monocular Depth Estimation


Abstract
:1. Introduction
- We proposed a novel pyramid network where the connections are much denser than traditional pyramid networks, which is effective for monocular depth estimation.
- To fuse features among different floors, we designed a dense connection module (DCM), which is simple and effective.
- We conducted various experiments on both outdoor and indoor datasets (i.e., the KITTI and the NYU Depth V2 datasets). The results demonstrate that the proposed network achieves the state-of-art results on the two datasets.
- Furthermore, we analyzed two configurations of the common upscale operation, which offers a new direction for us in devising a CNN model.
2. Related Work
2.1. Monocular Depth Estimation
2.2. Pyramid Netwoks
3. Method
3.1. Network Architecture
3.2. Dense Connection Module
3.3. Loss Function
| Algorithm 1. Computing depth with DCPNet |
Input: Backbone feature pyramid: Output: Depth map at input scale:
|
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
- Mean relative error (): ;
- Mean log10 error (): ;
- Squared relative error (): ;
- Root mean squared error (): ;
- Root mean squared log10 error (): ;
- Accuracy with threshold , i.e., the percantage (%) of subjecting to , here, .
4.3. Implementation Details
4.4. Results on the KITTI Dataset
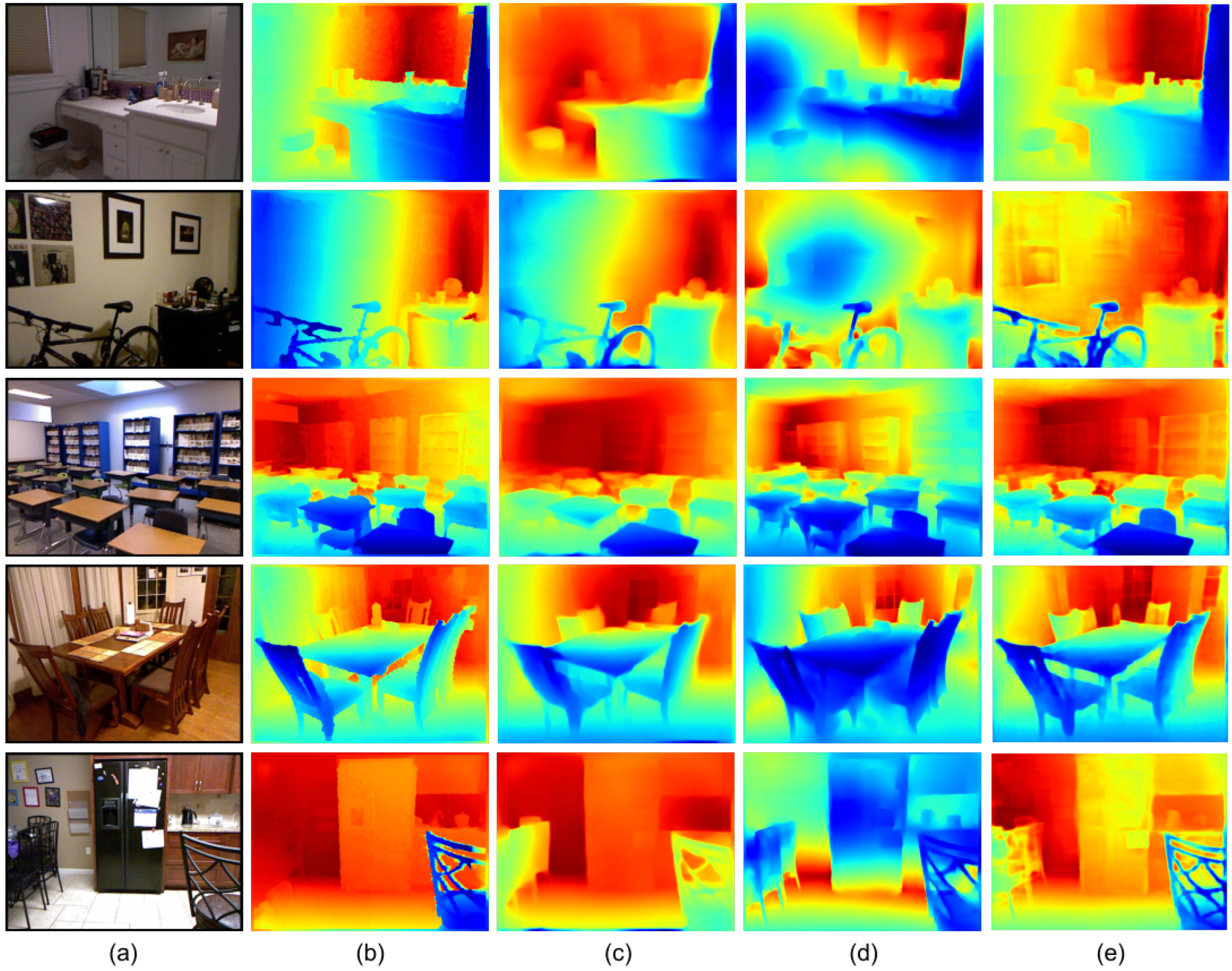
4.5. Results on the NYU Depth V2 Dataset
4.6. Ablation Study
4.6.1. Effect of Connection Density
4.6.2. Effect of Different Upscale Operations
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hoiem, D.; Efros, A.A.; Hebert, M. Geometric context from a single image. In Proceedings of the 10th IEEE International Conference on Computer Vision (ICCV 2005), Beijing, China, 17–20 October 2005; Volume 1, pp. 654–661. [Google Scholar]
- Cavoto, B.R.; Cook, R.G. The contribution of monocular depth cues to scene perception by pigeons. Psychol. Sci. 2006, 17, 628–634. [Google Scholar] [CrossRef]
- Saxena, A.; Sun, M.; Ng, A.Y. Make3d: Learning 3d scene structure from a single still image. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 824–840. [Google Scholar] [CrossRef] [Green Version]
- Delage, E.; Lee, H.; Ng, A.Y. A dynamic bayesian network model for autonomous 3d reconstruction from a single indoor image. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2006), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2418–2428. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 4th IEEE International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. Learning depth from single monocular images using deep convolutional neural fields. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2024–2039. [Google Scholar] [CrossRef] [Green Version]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. arXiv 2014, arXiv:1406.2283. [Google Scholar]
- Lee, J.H.; Kim, C.S. Multi-loss rebalancing algorithm for monocular depth estimation. In Proceedings of the 16th European Conference on Computer Vision (ECCV), Part XVII 16. Glasgow, UK, 23–28 August 2020; pp. 785–801. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- Huynh, L.; Nguyen-Ha, P.; Matas, J.; Rahtu, E.; Heikkilä, J. Guiding monocular depth estimation using depth-attention volume. In Proceedings of the 16th European Conference on Computer Vision (ECCV), Virtual Event, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 581–597. [Google Scholar]
- Chen, Y.; Zhao, H.; Hu, Z.; Peng, J. Attention-based context aggregation network for monocular depth estimation. Int. J. Mach. Learn. Cybern. 2021, 12, 1583–1596. [Google Scholar] [CrossRef]
- Ling, C.; Zhang, X.; Chen, H. Unsupervised Monocular Depth Estimation using Attention and Multi-Warp Reconstruction. IEEE Trans. Multimed. 2021. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Pan, X.; Gao, L.; Zhang, B.; Yang, F.; Liao, W. High-resolution aerial imagery semantic labeling with dense pyramid network. Sensors 2018, 18, 3774. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Chen, X.; Zha, Z.J. Structure-aware residual pyramid network for monocular depth estimation. arXiv 2019, arXiv:1907.06023. [Google Scholar]
- Miangoleh, S.M.H.; Dille, S.; Mai, L.; Paris, S.; Aksoy, Y. Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution Merging. In Proceedings of the CVRR, Virtual Event, 19–25 June 2021; pp. 9685–9694. [Google Scholar]
- Shi, C.; Chen, J.; Chen, J. Residual Feature Pyramid Architecture for Monocular Depth Estimation. In Cooperative Design, Visualization, and Engineering; Lecture Notes in Computer Science; Luo, Y., Ed.; Springer: Cham, Switzerland, 2019; Volume 11792, pp. 261–266. [Google Scholar] [CrossRef]
- Lee, J.H.; Han, M.K.; Ko, D.W.; Suh, I.H. From big to small: Multi-scale local planar guidance for monocular depth estimation. arXiv 2019, arXiv:1907.10326. [Google Scholar]
- Liu, J.; Zhang, X.; Li, Z.; Mao, T. Multi-Scale Residual Pyramid Attention Network for Monocular Depth Estimation. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 5137–5144. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the 12th European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 746–760. [Google Scholar]
- Criminisi, A.; Reid, I.; Zisserman, A. Single view metrology. IJCV 2000, 40, 123–148. [Google Scholar] [CrossRef]
- Xu, D.; Ricci, E.; Ouyang, W.; Wang, X.; Sebe, N. Multi-scale continuous crfs as sequential deep networks for monocular depth estimation. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5354–5362. [Google Scholar]
- Hao, Z.; Li, Y.; You, S.; Lu, F. Detail preserving depth estimation from a single image using attention guided networks. In Proceedings of the 6th International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 304–313. [Google Scholar]
- Ye, X.; Chen, S.; Xu, R. DPNet: Detail-preserving network for high quality monocular depth estimation. PR 2021, 109, 107578. [Google Scholar] [CrossRef]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- Godard, C.; Aodha, M.O.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Bristow, Seoul, Korea, 27 October–2 November 2019; pp. 3828–3838. [Google Scholar]
- Yang, D.; Zhong, X.; Gu, D.; Peng, X.; Hu, H. Unsupervised framework for depth estimation and camera motion prediction from video. Neurocomputing 2020, 385, 169–185. [Google Scholar] [CrossRef]
- Johnston, A.; Carneiro, G. Self-supervised monocular trained depth estimation using self-attention and discrete disparity volume. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 4756–4765. [Google Scholar]
- He, L.; Chen, C.; Zhang, T.; Zhu, H.; Wan, S. Wearable depth camera: Monocular depth estimation via sparse optimization under weak supervision. IEEE Access 2018, 6, 41337–41345. [Google Scholar] [CrossRef]
- Qi, X.; Liao, R.; Liu, Z.; Urtasun, R.; Jia, J. Geonet: Geometric neural network for joint depth and surface normal estimation. In Proceedings of the CVRR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 283–291. [Google Scholar]
- Yue, M.; Fu, G.; Wu, M.; Wang, H. Semi-Supervised Monocular Depth Estimation Based on Semantic Supervision. J. Intell. Robot. Syst. 2020, 100, 455–463. [Google Scholar] [CrossRef]
- Chang, J.R.; Chen, Y.S. Pyramid stereo matching network. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5410–5418. [Google Scholar]
- Bian, J.W.; Zhan, H.; Wang, N.; Li, Z.; Zhang, L.; Shen, C.; Cheng, M.; Reid, I. Unsupervised Scale-consistent Depth Learning from Video. Int. J. Comput. Vis. 2021, 129, 2548–2564. [Google Scholar] [CrossRef]
- Fang, Z.; Chen, X.; Chen, Y.; Gool, L.V. Towards good practice for CNN-based monocular depth estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass, CO, USA, 1–5 March 2020; pp. 1080–1089. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Jiao, J.; Cao, Y.; Song, Y.; Lau, R. Look deeper into depth: Monocular depth estimation with semantic booster and attention-driven loss. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 53–69. [Google Scholar]
- Ramamonjisoa, M.; Firman, M.; Watson, J.; Lepetit, V.; Turmukhambetov, D. Single Image Depth Prediction with Wavelet Decomposition. In Proceedings of the CVRR, Virtual Event, 19–25 June 2021; pp. 11089–11098. [Google Scholar]
- Yang, G.; Tang, H.; Ding, M.; Sebe, N.; Ricci, E. Transformer-Based Attention Networks for Continuous Pixel-Wise Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual Event, 11–17 October 2021. [Google Scholar]
- Kaushik, V.; Jindgar, K.; Lall, B. ADAADepth: Adapting Data Augmentation and Attention for Self-Supervised Monocular Depth Estimation. arXiv 2021, arXiv:2103.00853. [Google Scholar]
- Seferbekov, S.; Iglovikov, V.; Buslaev, A.; Shvets, A. Feature pyramid network for multi-class land segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 272–275. [Google Scholar]
- Chen, X.; Lou, X.; Bai, L.; Han, J. Residual pyramid learning for single-shot semantic segmentation. IEEE Trans. Intell. Transp. Syst. 2019, 21, 2990–3000. [Google Scholar] [CrossRef] [Green Version]
- Feng, S.; Zhao, H.; Shi, F.; Cheng, X.; Wang, M.; Ma, Y.; Xiang, D.; Zhu, W.; Chen, X. CPFNet: Context pyramid fusion network for medical image segmentation. IEEE Trans. Med. Imag. 2020, 39, 3008–3018. [Google Scholar] [CrossRef]
- Nie, D.; Xue, J.; Ren, X. Bidirectional Pyramid Networks for Semantic Segmentation. In Proceedings of the Asia Conference on Computer Vision (ACCV), Online Conference, 30 November–4 December 2020. [Google Scholar]
- Shamsolmoali, P.; Zareapoor, M.; Zhou, H.; Wang, R.; Yang, J. Road segmentation for remote sensing images using adversarial spatial pyramid networks. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4673–4688. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, X.; Dong, J.; Chen, C.; Lv, Q. GPNet: Gated pyramid network for semantic segmentation. Pattern Recognit. 2021, 115, 107940. [Google Scholar] [CrossRef]
- Xin, Y.; Wang, S.; Li, L.; Zhang, W.; Huang, Q. Reverse densely connected feature pyramid network for object detection. In Proceedings of the 14th Asian Conference on Computer Vision (ACCV), Perth, Australia, 2–6 December 2018; pp. 530–545. [Google Scholar]
- Wang, T.; Zhang, X.; Sun, J. Implicit feature pyramid network for object detection. arXiv 2020, arXiv:2012.13563. [Google Scholar]
- Ma, J.; Chen, B. Dual Refinement Feature Pyramid Networks for Object Detection. arXiv 2020, arXiv:2012.01733. [Google Scholar]
- Xing, H.; Wang, S.; Zheng, D.; Zhao, X. Dual attention based feature pyramid network. China Commun. 2020, 17, 242–252. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Xiong, B.; Kuang, G. Attention receptive pyramid network for ship detection in SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2738–2756. [Google Scholar] [CrossRef]
- Liang, T.; Wang, Y.; Zhao, Q.; Tang, Z.; Ling, H. MFPN: A novel mixture feature pyramid network of multiple architectures for object detection. arXiv 2019, arXiv:1912.09748. [Google Scholar]
- Xu, X.; Chen, Z.; Yin, F. Monocular Depth Estimation With Multi-Scale Feature Fusion. IEEE Signal Process. Lett. 2021, 28, 678–682. [Google Scholar] [CrossRef]
- Deng, Z.; Yu, H.; Long, Y. Fractal Pyramid Networks. arXiv 2021, arXiv:2106.14694. [Google Scholar]
- Kaushik, V.; Lall, B. Deep feature fusion for self-supervised monocular depth prediction. arXiv 2020, arXiv:2005.07922. [Google Scholar]
- Poggi, M.; Aleotti, F.; Tosi, F.; Mattoccia, S. Towards real-time unsupervised monocular depth estimation on cpu. In Proceedings of the 25th IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 5848–5854. [Google Scholar]
- Kim, S.W.; Kook, H.K.; Sun, J.Y.; Kang, M.C.; Ko, S.J. Parallel feature pyramid network for object detection. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 239–256. [Google Scholar]
- Liu, R.; Lehman, J.; Molino, P.; Such, F.P.; Frank, E.; Sergeev, A.; Yosinski, J. An intriguing failing of convolutional neural networks and the coordconv solution. arXiv 2018, arXiv:1807.03247. [Google Scholar]
- Hu, J.; Ozay, M.; Zhang, Y.; Okatani, T. Revisiting single image depth estimation: Toward higher resolution maps with accurate object boundaries. In Proceedings of the 19th IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1043–1051. [Google Scholar]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2002–2011. [Google Scholar]
- Yin, W.; Liu, Y.; Shen, C.; Yan, Y. Enforcing geometric constraints of virtual normal for depth prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 5683–5692. [Google Scholar]
- Alhashim, I.; Wonka, P. High quality monocular depth estimation via transfer learning. arXiv 2018, arXiv:1812.11941. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 8026–8037. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE-Computer-Society Conference on Computer Vision and Pattern Recognition Workshops, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Cheng, B.; Saggu, I.S.; Shah, R.; Bansal, G.; Bharadia, D. S3Net: Semantic-Aware Self-supervised Depth Estimation with Monocular Videos and Synthetic Data. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Virtual Event, 23–28 August 2020; pp. 52–69. [Google Scholar]
- Tiwari, L.; Ji, P.; Tran, Q.H.; Zhuang, B.; Anand, S.; Chandraker, M. Pseudo rgb-d for self-improving monocular slam and depth prediction. In In Proceedings of the 15th European Conference on Computer Vision (ECCV), Virtual Event, 23–28 August 2020; pp. 437–455. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Settings | KITTI | NYU Depth V2 |
|---|---|---|
| epochs | 50 | 50 |
| batch size | 8 | 8 |
| optimizer | AdamW | AdamW |
| optimizer | 1 × 10 | 1 × 10 |
| input height | 352 | 416 |
| input width | 704 | 544 |
| initial learning rate | 1 × 10 | 1 × 10 |
| initialization method | Xavier | Xavier |
| Method | ↓ | ↓ | ↓ | ↓ | ↑ | ↑ | ↑ |
|---|---|---|---|---|---|---|---|
| Eiegn et al. [7] | 0.190 | 1.515 | 7.156 | 0.270 | 0.692 | 0.899 | 0.967 |
| Liu et al. [6] | 0.217 | - | 7.046 | - | 0.656 | 0.881 | 0.958 |
| Alhashim et al. [67] | 0.093 | 0.589 | 4.170 | - | 0.886 | 0.965 | 0.986 |
| Fu et al. [65] | 0.072 | 0.307 | 2.727 | 0.120 | 0.932 | 0.984 | 0.994 |
| Yin et al. [66] | 0.072 | - | 3.258 | 0.117 | 0.938 | 0.990 | 0.998 |
| Lee et al. [20] | 0.059 | 0.245 | 2.756 | 0.096 | 0.956 | 0.993 | 0.998 |
| Godard et al. [30] | 0.106 | 0.806 | 4.530 | 0.193 | 0.876 | 0.958 | 0.980 |
| Yang et al. [44] | 0.064 | 0.252 | 2.755 | 0.098 | 0.956 | 0.994 | 0.999 |
| Liu et al. [21] | 0.111 | - | 3.514 | - | 0.878 | 0.977 | 0.994 |
| Ye et al. [28] | 0.112 | - | 4.978 | 0.210 | 0.842 | 0.947 | 0.973 |
| Ours—ResNet101 | 0.065 | 0.257 | 2.779 | 0.101 | 0.950 | 0.992 | 0.998 |
| Ours—ResNeXt101 | 0.061 | 0.238 | 2.699 | 0.096 | 0.957 | 0.993 | 0.998 |
| Ours—DenseNet161 | 0.063 | 0.248 | 2.762 | 0.098 | 0.955 | 0.993 | 0.999 |
| Method | ↓ | ↓ | ↓ | ↑ | ↑ | ↑ |
|---|---|---|---|---|---|---|
| Eiegn et al. [7] | 0.215 | - | 0.907 | 0.611 | 0.887 | 0.971 |
| Liu et al. [6] | 0.213 | 0.087 | 0.759 | 0.650 | 0.906 | 0.976 |
| Fu et al. [65] | 0.115 | 0.051 | 0.509 | 0.828 | 0.965 | 0.992 |
| Hu et al. [64] | 0.123 | 0.053 | 0.544 | 0.855 | 0.972 | 0.993 |
| Yin et al. [66] | 0.108 | 0.048 | 0.416 | 0.875 | 0.976 | 0.994 |
| Chen et al. [17] | 0.111 | 0.048 | 0.514 | 0.878 | 0.977 | 0.994 |
| Liu et al. [21] | 0.113 | 0.049 | 0.525 | 0.872 | 0.974 | 0.993 |
| Ye et al. [28] | - | 0.063 | 0.474 | 0.784 | 0.948 | 0.986 |
| Xu et al. [58] | 0.101 | 0.054 | 0.456 | 0.823 | 0.962 | 0.994 |
| Ours—ResNet101 | 0.126 | 0.054 | 0.433 | 0.846 | 0.974 | 0.995 |
| Ours—ResNeXt101 | 0.117 | 0.051 | 0.408 | 0.865 | 0.979 | 0.995 |
| Ours—DenseNet161 | 0.115 | 0.049 | 0.398 | 0.873 | 0.980 | 0.995 |
| Method | ↓ | ↓ | ↓ | ↓ | ↑ | ↑ | ↑ |
|---|---|---|---|---|---|---|---|
| Ours—DenseNet161 | 0.063 | 0.248 | 2.762 | 0.098 | 0.955 | 0.993 | 0.999 |
| Sparse | 0.061 | 0.250 | 2.821 | 0.098 | 0.954 | 0.992 | 0.998 |
| Sparser | 0.062 | 0.252 | 2.804 | 0.098 | 0.953 | 0.993 | 0.998 |
| Sparsest | 0.061 | 0.248 | 2.815 | 0.098 | 0.953 | 0.993 | 0.998 |
| Method | #Params | Time | ↓ | ↓ | ↓ | ↓ | ↑ | ↑ | ↑ |
|---|---|---|---|---|---|---|---|---|---|
| Ours—MobileNetV2 | 5.7M | 0.0270 | 0.071 | 0.295 | 2.978 | 0.109 | 0.940 | 0.991 | 0.998 |
| up_conv—MobileNetV2 | 5.7M | 0.0338 | 0.071 | 0.291 | 2.971 | 0.110 | 0.940 | 0.991 | 0.998 |
| Ours—ResNet34 | 30.8M | 0.0235 | 0.064 | 0.259 | 2.787 | 0.100 | 0.952 | 0.993 | 0.998 |
| up_conv—ResNet34 | 30.8M | 0.0387 | 0.064 | 0.259 | 2.856 | 0.101 | 0.951 | 0.993 | 0.998 |
| Ours—DenseNet161 | 63.9M | 0.0617 | 0.063 | 0.248 | 2.762 | 0.098 | 0.955 | 0.993 | 0.999 |
| up_conv—DenseNet161 | 63.9M | 0.1346 | 0.064 | 0.252 | 2.765 | 0.100 | 0.951 | 0.992 | 0.998 |
| Ours—ResNeXt50 | 155.2M | 0.0741 | 0.064 | 0.252 | 2.793 | 0.101 | 0.950 | 0.992 | 0.998 |
| up_conv—ResNeXt50 | 155.2M | 0.1370 | 0.066 | 0.262 | 2.768 | 0.102 | 0.948 | 0.992 | 0.998 |
| conv_up_BTS | 47.0M | 0.0482 | 0.065 | 0.253 | 2.820 | 0.100 | 0.952 | 0.993 | 0.999 |
| BTS [20] | 47.0M | 0.0481 | 0.060 | 0.249 | 2.798 | 0.096 | 0.956 | 0.993 | 0.998 |
| conv_up_TransDepth | 247.4M | 0.1703 | 0.065 | 0.258 | 2.738 | 0.098 | 0.953 | 0.993 | 0.999 |
| TransDepth [44] | 247.4M | 0.1705 | 0.064 | 0.252 | 2.755 | 0.098 | 0.956 | 0.994 | 0.999 |
| Method | ↓ | ↓ | ↓ | ↓ | ↑ | ↑ | ↑ |
|---|---|---|---|---|---|---|---|
| Ours—DenseNet161 | 0.063 | 0.248 | 2.762 | 0.098 | 0.955 | 0.993 | 0.999 |
| F#5—DenseNet161 | 0.062 | 0.253 | 2.793 | 0.098 | 0.954 | 0.992 | 0.998 |
| F#4—DenseNet161 | 0.061 | 0.248 | 2.789 | 0.097 | 0.955 | 0.993 | 0.998 |
| F#3—DenseNet161 | 0.063 | 0.251 | 2.765 | 0.099 | 0.953 | 0.993 | 0.998 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lai, Z.; Tian, R.; Wu, Z.; Ding, N.; Sun, L.; Wang, Y. DCPNet: A Densely Connected Pyramid Network for Monocular Depth Estimation. Sensors 2021, 21, 6780. https://doi.org/10.3390/s21206780
Lai Z, Tian R, Wu Z, Ding N, Sun L, Wang Y. DCPNet: A Densely Connected Pyramid Network for Monocular Depth Estimation. Sensors. 2021; 21(20):6780. https://doi.org/10.3390/s21206780
Chicago/Turabian StyleLai, Zhitong, Rui Tian, Zhiguo Wu, Nannan Ding, Linjian Sun, and Yanjie Wang. 2021. "DCPNet: A Densely Connected Pyramid Network for Monocular Depth Estimation" Sensors 21, no. 20: 6780. https://doi.org/10.3390/s21206780