
Accurate Pupil Center Detection in Off-the-Shelf Eye Tracking Systems Using Convolutional Neural Networks


Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
3.1. Datasets
3.1.1. PUPPIE
3.1.2. GI4E
3.1.3. I2Head
3.1.4. MPIIGaze Subset
3.1.5. U2Eyes
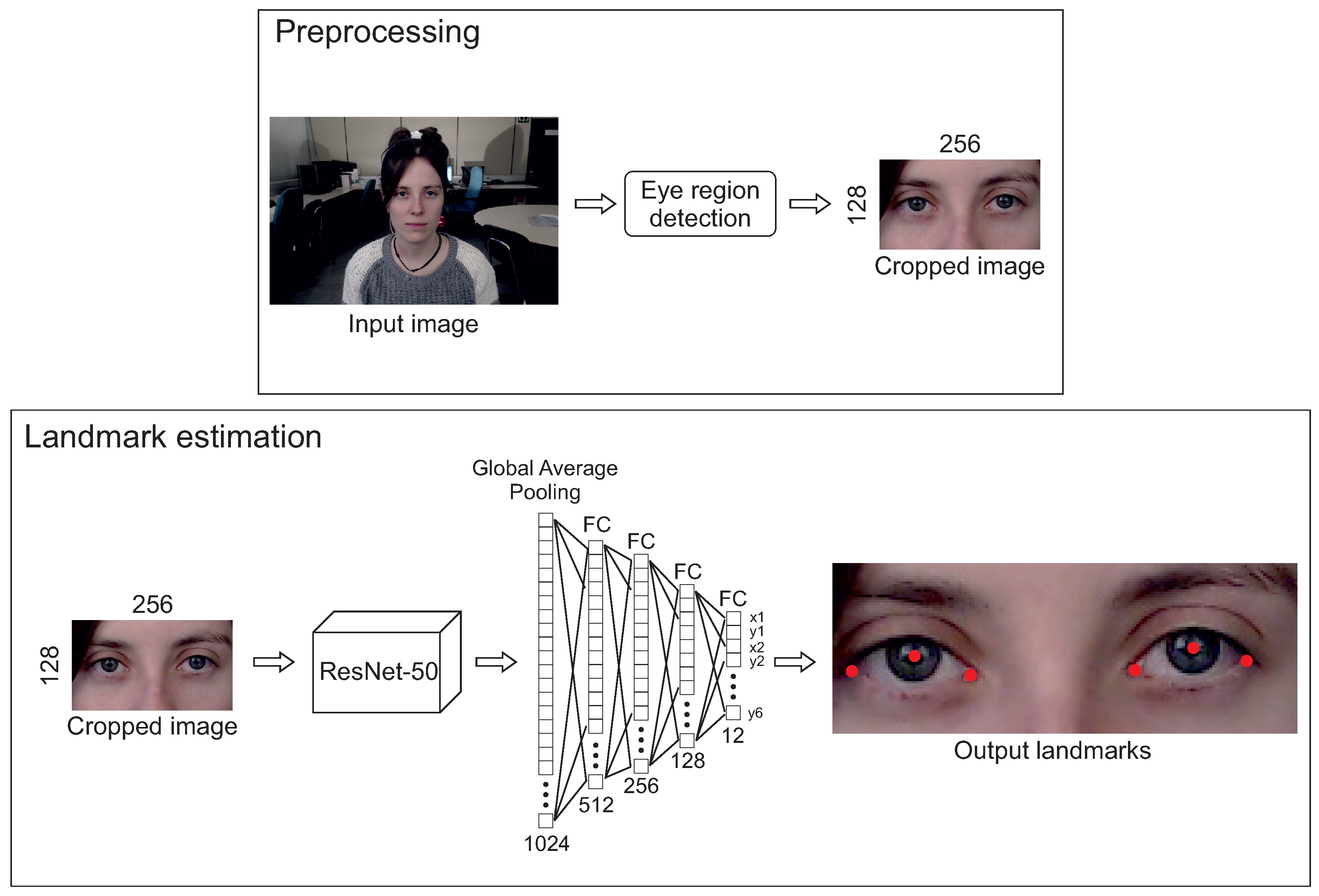
3.2. Preprocessing
3.3. Pupil Center Detection
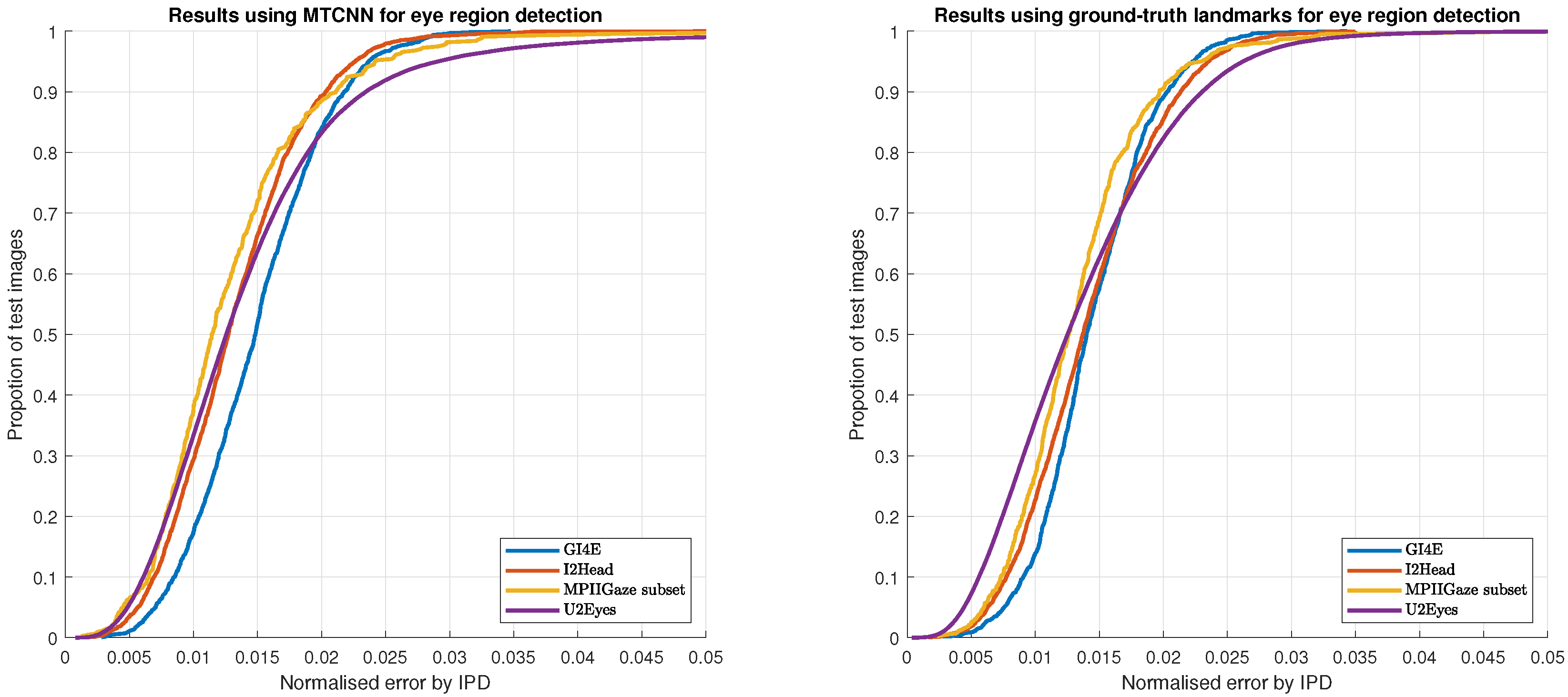
4. Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guestrin, E.D.; Eizenman, M. General theory of remote gaze estimation using the pupil center and corneal reflections. IEEE Trans. Biomed. Eng. 2006, 53, 1124–1133. [Google Scholar] [CrossRef] [PubMed]
- Sesma, L.; Villanueva, A.; Cabeza, R. Evaluation of pupil center-eye corner vector for gaze estimation using a web cam. In Proceedings of the Symposium on Eye Tracking Research and Applications, Santa Barbara, CA, USA, 28–30 March 2012; pp. 217–220. [Google Scholar]
- Bulling, A.; Gellersen, H. Toward mobile eye-based human-computer interaction. IEEE Pervasive Comput. 2010, 9, 8–12. [Google Scholar] [CrossRef]
- Lupu, R.G.; Bozomitu, R.G.; Păsărică, A.; Rotariu, C. Eye tracking user interface for Internet access used in assistive technology. In Proceedings of the 2017 E-Health and Bioengineering Conference (EHB), Sinaia, Romania, 22–24 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 659–662. [Google Scholar]
- Said, S.; AlKork, S.; Beyrouthy, T.; Hassan, M.; Abdellatif, O.; Abdraboo, M. Real time eye tracking and detection—A driving assistance system. Adv. Sci. Technol. Eng. Syst. J. 2018, 3, 446–454. [Google Scholar] [CrossRef] [Green Version]
- Rigas, I.; Komogortsev, O.; Shadmehr, R. Biometric recognition via eye movements: Saccadic vigor and acceleration cues. ACM Trans. Appl. Percept. (TAP) 2016, 13, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Rasch, C.; Louviere, J.J.; Teichert, T. Using facial EMG and eye tracking to study integral affect in discrete choice experiments. J. Choice Model. 2015, 14, 32–47. [Google Scholar] [CrossRef]
- Wedel, M.; Pieters, R.; van der Lans, R. Eye tracking methodology for research in consumer psychology. In Handbook of Research Methods in Consumer Psychology; Routledge: New York, NY, USA, 2019; pp. 276–292. [Google Scholar]
- Meißner, M.; Pfeiffer, J.; Pfeiffer, T.; Oppewal, H. Combining virtual reality and mobile eye tracking to provide a naturalistic experimental environment for shopper research. J. Bus. Res. 2019, 100, 445–458. [Google Scholar] [CrossRef]
- Duchowski, A.T. Eye Tracking Methodology: Theory and Practice; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Klaib, A.F.; Alsrehin, N.O.; Melhem, W.Y.; Bashtawi, H.O.; Magableh, A.A. Eye tracking algorithms, techniques, tools, and applications with an emphasis on machine learning and Internet of Things technologies. Expert Syst. Appl. 2021, 166, 114037. [Google Scholar] [CrossRef]
- Cognolato, M.; Atzori, M.; Müller, H. Head-mounted eye gaze tracking devices: An overview of modern devices and recent advances. J. Rehabil. Assist. Technol. Eng. 2018, 5, 2055668318773991. [Google Scholar] [CrossRef]
- Cerrolaza, J.J.; Villanueva, A.; Cabeza, R. Study of Polynomial Mapping Functions in Video-Oculography Eye Trackers. ACM Trans. Comput.-Hum. Interact. 2012, 19, 10:1–10:25. [Google Scholar] [CrossRef]
- Chaudhary, A.K.; Kothari, R.; Acharya, M.; Dangi, S.; Nair, N.; Bailey, R.; Kanan, C.; Diaz, G.; Pelz, J.B. RITnet: Real-time Semantic Segmentation of the Eye for Gaze Tracking. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3698–3702. [Google Scholar]
- Perry, J.; Fernandez, A. MinENet: A Dilated CNN for Semantic Segmentation of Eye Features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3671–3676. [Google Scholar]
- Yiu, Y.H.; Aboulatta, M.; Raiser, T.; Ophey, L.; Flanagin, V.L.; Zu Eulenburg, P.; Ahmadi, S.A. DeepVOG: Open-source pupil segmentation and gaze estimation in neuroscience using deep learning. J. Neurosci. Methods 2019, 324, 108307. [Google Scholar] [CrossRef] [PubMed]
- Fuhl, W.; Santini, T.; Kasneci, G.; Kasneci, E. PupilNet: Convolutional Neural Networks for Robust Pupil Detection. arXiv 2016, arXiv:1601.04902. [Google Scholar]
- Fuhl, W.; Santini, T.; Kasneci, G.; Rosenstiel, W.; Kasneci, E. Pupilnet v2.0: Convolutional neural networks for cpu based real time robust pupil detection. arXiv 2017, arXiv:1711.00112. [Google Scholar]
- Villanueva, A.; Cabeza, R. Models for gaze tracking systems. Eurasip J. Image Video Process. 2007, 2007, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Martinikorena, I.; Cabeza, R.; Villanueva, A.; Porta, S. Introducing I2Head database. In Proceedings of the 7th International Workshop on Pervasive Eye Tracking and Mobile Eye based Interaction, Warsaw, Poland, 14–17 June 2018. [Google Scholar]
- Choi, J.H.; Lee, K.I.; Kim, Y.C.; Song, B.C. Accurate eye pupil localization using heterogeneous CNN models. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2179–2183. [Google Scholar]
- Xia, Y.; Yu, H.; Wang, F.Y. Accurate and robust eye center localization via fully convolutional networks. IEEE/CAA J. Autom. Sin. 2019, 6, 1127–1138. [Google Scholar] [CrossRef]
- Lee, K.I.; Jeon, J.H.; Song, B.C. Deep Learning-Based Pupil Center Detection for Fast and Accurate Eye Tracking System. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 36–52. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Valenti, R.; Gevers, T. Accurate eye center location and tracking using isophote curvature. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–8. [Google Scholar]
- Zhang, W.; Smith, M.L.; Smith, L.N.; Farooq, A. Eye center localization and gaze gesture recognition for human–computer interaction. JOSA A 2016, 33, 314–325. [Google Scholar] [CrossRef]
- Timm, F.; Barth, E. Accurate eye centre localisation by means of gradients. Visapp 2011, 11, 125–130. [Google Scholar]
- Villanueva, A.; Ponz, V.; Sesma-Sanchez, L.; Ariz, M.; Porta, S.; Cabeza, R. Hybrid method based on topography for robust detection of iris center and eye corners. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2013, 9, 25:1–25:20. [Google Scholar] [CrossRef] [Green Version]
- Skodras, E.; Fakotakis, N. Precise localization of eye centers in low resolution color images. Image Vis. Comput. 2015, 36, 51–60. [Google Scholar] [CrossRef]
- George, A.; Routray, A. Fast and accurate algorithm for eye localisation for gaze tracking in low-resolution images. IET Comput. Vis. 2016, 10, 660–669. [Google Scholar] [CrossRef] [Green Version]
- Xiao, F.; Huang, K.; Qiu, Y.; Shen, H. Accurate iris center localization method using facial landmark, snakuscule, circle fitting and binary connected component. Multimed. Tools Appl. 2018, 77, 25333–25353. [Google Scholar] [CrossRef]
- Thevenaz, P.; Unser, M. Snakuscules. IEEE Trans. Image Process. 2008, 17, 585–593. [Google Scholar] [CrossRef] [Green Version]
- Xiong, X.; De la Torre, F. Supervised descent method for solving nonlinear least squares problems in computer vision. arXiv 2014, arXiv:1405.0601. [Google Scholar]
- Feng, Z.H.; Huber, P.; Kittler, J.; Christmas, W.; Wu, X.J. Random Cascaded-Regression Copse for robust facial landmark detection. Signal Process. Lett. IEEE 2015, 22, 76–80. [Google Scholar] [CrossRef] [Green Version]
- Larumbe, A.; Cabeza, R.; Villanueva, A. Supervised descent method (SDM) applied to accurate pupil detection in off-the-shelf eye tracking systems. In Proceedings of the 2018 ACM Symposium on Eye Tracking Research & Applications, Warsaw, Poland, 14–17 June 2018; pp. 1–8. [Google Scholar]
- Gou, C.; Wu, Y.; Wang, K.; Wang, F.Y.; Ji, Q. Learning-by-synthesis for accurate eye detection. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3362–3367. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Markuš, N.; Frljak, M.; Pandžić, I.S.; Ahlberg, J.; Forchheimer, R. Eye pupil localization with an ensemble of randomized trees. Pattern Recognit. 2014, 47, 578–587. [Google Scholar] [CrossRef] [Green Version]
- Kacete, A.; Royan, J.; Seguier, R.; Collobert, M.; Soladie, C. Real-time eye pupil localization using Hough regression forest. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–9 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–8. [Google Scholar]
- Levinshtein, A.; Phung, E.; Aarabi, P. Hybrid eye center localization using cascaded regression and hand-crafted model fitting. Image Vis. Comput. 2018, 71, 17–24. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Poulopoulos, N.; Psarakis, E.Z.; Kosmopoulos, D. PupilTAN: A Few-Shot Adversarial Pupil Localizer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3134–3142. [Google Scholar]
- Kitazumi, K.; Nakazawa, A. Robust Pupil Segmentation and Center Detection from Visible Light Images Using Convolutional Neural Network. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 862–868. [Google Scholar]
- King, D.E. Dlib-ml: A machine learning toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zdarsky, N.; Treue, S.; Esghaei, M. A Deep Learning-Based Approach to Video-Based Eye Tracking for Human Psychophysics. Front. Hum. Neurosci. 2021, 15. [Google Scholar] [CrossRef] [PubMed]
- Mathis, A.; Mamidanna, P.; Cury, K.M.; Abe, T.; Murthy, V.N.; Mathis, M.W.; Bethge, M. DeepLabCut: Markerless pose estimation of user-defined body parts with deep learning. Nat. Neurosci. 2018, 21, 1281–1289. [Google Scholar] [CrossRef]
- Insafutdinov, E.; Pishchulin, L.; Andres, B.; Andriluka, M.; Schiele, B. Deepercut: A deeper, stronger, and faster multi-person pose estimation model. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 34–50. [Google Scholar]
- Kim, S.; Jeong, M.; Ko, B.C. Energy Efficient Pupil Tracking Based on Rule Distillation of Cascade Regression Forest. Sensors 2020, 20, 5141. [Google Scholar] [CrossRef]
- Cai, H.; Liu, B.; Ju, Z.; Thill, S.; Belpaeme, T.; Vanderborght, B.; Liu, H. Accurate Eye Center Localization via Hierarchical Adaptive Convolution. In Proceedings of the 29th British Machine Vision Conference. British Machine Vision Association, Newcastle, UK, 3–6 September 2018; p. 284. [Google Scholar]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. Appearance-based gaze estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4511–4520. [Google Scholar]
- Porta, S.; Bossavit, B.; Cabeza, R.; Larumbe-Bergera, A.; Garde, G.; Villanueva, A. U2Eyes: A binocular dataset for eye tracking and gaze estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019; pp. 3660–3664. [Google Scholar]
- Gross, R.; Matthews, I.; Cohn, J.; Kanade, T.; Baker, S. Multi-pie. Image Vis. Comput. 2010, 28, 807–813. [Google Scholar] [CrossRef] [PubMed]
- Belhumeur, P.N.; Jacobs, D.W.; Kriegman, D.J.; Kumar, N. Localizing parts of faces using a consensus of exemplars. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2930–2940. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Ramanan, D. Face detection, pose estimation, and landmark localization in the wild. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; IEEE Computer Society: Washington, DC, USA, 2012. CVPR’12. pp. 2879–2886. [Google Scholar]
- Le, V.; Brandt, J.; Lin, Z.; Bourdev, L.; Huang, T. Interactive facial feature localization. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 679–692. [Google Scholar]
- Sagonas, C.; Antonakos, E.; Tzimiropoulos, G.; Zafeiriou, S.; Pantic, M. 300 faces in-the-wild challenge: Database and results. Image Vis. Comput. 2016, 47, 3–18. [Google Scholar] [CrossRef] [Green Version]
- Sagonas, C.; Tzimiropoulos, G.; Zafeiriou, S.; Pantic, M. A semi-automatic methodology for facial landmark annotation. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; IEEE Computer Society: Washington, DC, USA, 2013; pp. 896–903. [Google Scholar]
- Larumbe-Bergera, A.; Porta, S.; Cabeza, R.; Villanueva, A. SeTA: Semiautomatic Tool for Annotation of Eye Tracking Images. In Proceedings of the Symposium on Eye Tracking Research and Applications, Denver, CO, USA, 25–28 June 2019; pp. 45:1–45:5. [Google Scholar]
- Wood, E.; Baltrušaitis, T.; Morency, L.P.; Robinson, P.; Bulling, A. Learning an appearance-based gaze estimator from one million synthesised images. In Proceedings of the Ninth Biennial ACM Symposium on Eye Tracking Research & Applications, Charleston, SC, USA, 14–17 March 2016; pp. 131–138. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Jesorsky, O.; Kirchberg, K.J.; Frischholz, R.W. Robust face detection using the hausdorff distance. In International Conference on Audio-and Video-Based Biometric Person Authentication; Springer: Berlin/Heidelberg, Germany, 2001; pp. 90–95. [Google Scholar]
- Baek, S.J.; Choi, K.A.; Ma, C.; Kim, Y.H.; Ko, S.J. Eyeball model-based iris center localization for visible image-based eye-gaze tracking systems. IEEE Trans. Consum. Electron. 2013, 59, 415–421. [Google Scholar] [CrossRef]
- Gou, C.; Wu, Y.; Wang, K.; Wang, K.; Wang, F.Y.; Ji, Q. A joint cascaded framework for simultaneous eye detection and eye state estimation. Pattern Recognit. 2017, 67, 23–31. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | # of Total Images | # of Selected Images |
|---|---|---|
| PUPPIE | 4437 | 1791 |
| GI4E | 1236 | 1236 |
| I2Head | 2784 | 2784 |
| MPIIGaze | 10,848 | 585 |
| U2Eyes | 117,500 | 117,500 |
| Training Dataset | Testing Dataset | Results | ||
|---|---|---|---|---|
| PUPPIE | 1433 images | GI4E | 1236 images | Table 3 and Table 4 & Figure 5 |
| I2Head | 2784 images | Table 4 & Figure 5 | ||
| MPIIGaze | 585 images | Table 4 & Figure 5 | ||
| U2Eyes | 117,500 images | Table 4 & Figure 5 | ||
| Method | |||
|---|---|---|---|
| Timm11 [27] | 40.00 | 92.40 | 96.00 |
| Baek13 [69] | 59.00 | 79.50 | 88.00 |
| Villanueva13 [28] | 42.00 | 93.90 | 97.30 |
| Zhang16 [26] | - | 97.90 | 99.60 |
| George16 [30] | 72.00 | 89.28 | 92.30 |
| Gou16 [36] | 72.00 | 98.20 | 99.80 |
| Gou17 [70] | - | 94.20 | 99.10 |
| Levin18 [40] | 88.34 | 99.27 | 99.92 |
| Larumbe18 [35] | 87.67 | 99.14 | 99.99 |
| Cai18 [55] | 85.7 | 99.50 | - |
| Xiao18 [31] | 70.00 | 97.90 | 100 |
| Kitazumi18 [48] | 96.28 | 98.62 | 98.95 |
| Choi19 [21] | 90.40 | 99.60 | - |
| Xia19 [22] | 61.10 | 99.10 | 100 |
| Kim20 [54] | 79.50 | 99.30 | 99.90 |
| Lee20 [23] | 79.50 | 99.84 | 99.84 |
| Ours | 96.68 | 100 | 100 |
| Ours GT-CI | 98.46 | 100 | 100 |
| Database | ||||
|---|---|---|---|---|
| Ours | GI4E | 96.68 | 100 | 100 |
| I2Head | 97.92 | 99.96 | 100 | |
| MPIIGaze | 95.18 * | 99.54 * | 99.77 * | |
| U2Eyes | 91.92 * | 98.99 * | 99.80 * | |
| Ours GT-CI | GI4E | 98.46 | 100 | 100 |
| I2Head | 96.88 | 100 | 100 | |
| MPIIGaze | 97.09 | 99.83 | 100 | |
| U2Eyes | 93.44 | 99.93 | 100 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Larumbe-Bergera, A.; Garde, G.; Porta, S.; Cabeza, R.; Villanueva, A. Accurate Pupil Center Detection in Off-the-Shelf Eye Tracking Systems Using Convolutional Neural Networks. Sensors 2021, 21, 6847. https://doi.org/10.3390/s21206847
Larumbe-Bergera A, Garde G, Porta S, Cabeza R, Villanueva A. Accurate Pupil Center Detection in Off-the-Shelf Eye Tracking Systems Using Convolutional Neural Networks. Sensors. 2021; 21(20):6847. https://doi.org/10.3390/s21206847
Chicago/Turabian StyleLarumbe-Bergera, Andoni, Gonzalo Garde, Sonia Porta, Rafael Cabeza, and Arantxa Villanueva. 2021. "Accurate Pupil Center Detection in Off-the-Shelf Eye Tracking Systems Using Convolutional Neural Networks" Sensors 21, no. 20: 6847. https://doi.org/10.3390/s21206847
APA StyleLarumbe-Bergera, A., Garde, G., Porta, S., Cabeza, R., & Villanueva, A. (2021). Accurate Pupil Center Detection in Off-the-Shelf Eye Tracking Systems Using Convolutional Neural Networks. Sensors, 21(20), 6847. https://doi.org/10.3390/s21206847