
A CSI-Based Human Activity Recognition Using Deep Learning



Abstract
:1. Introduction
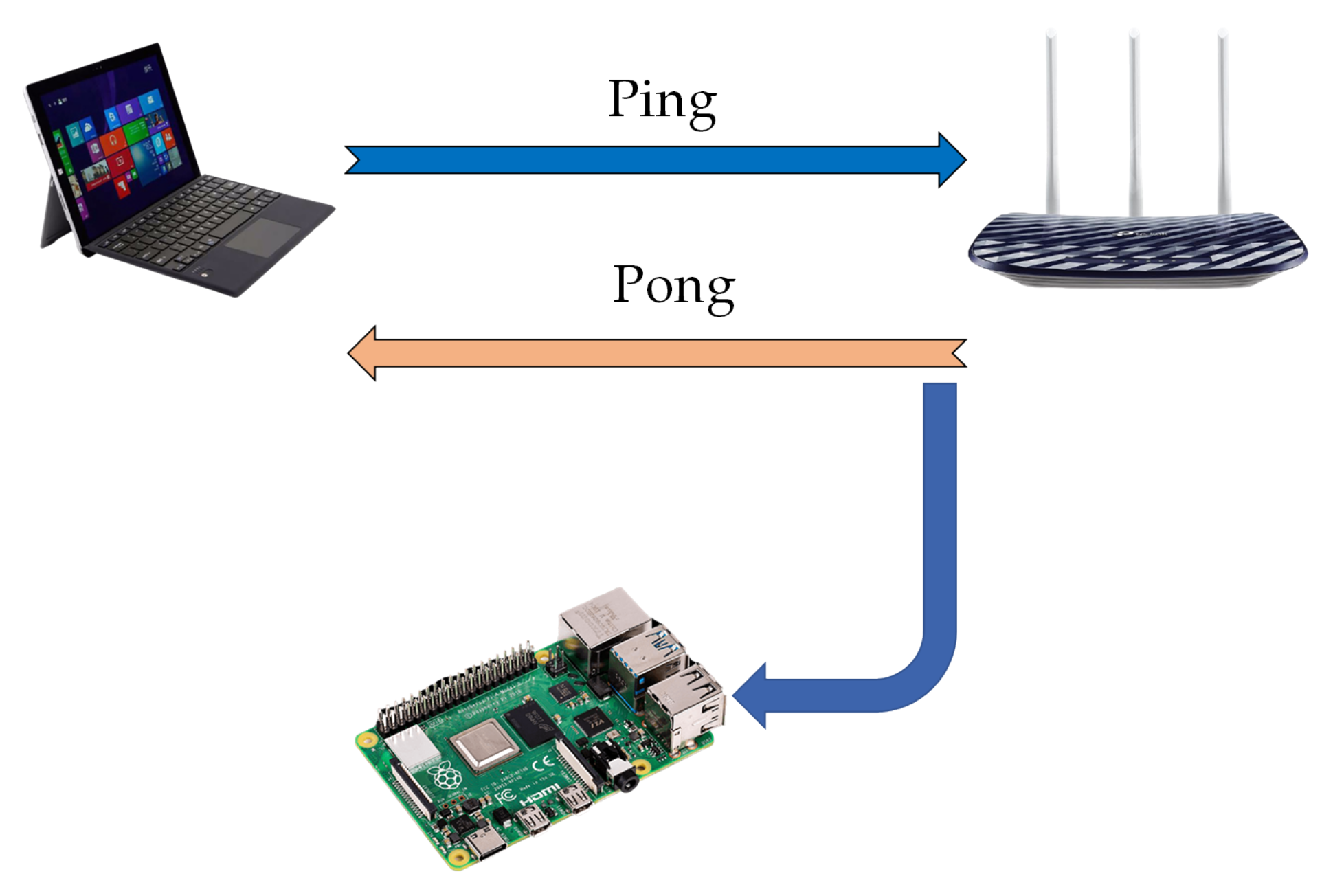
- We exploit Raspberry Pi for CSI data collection and offer a public CSI dataset for seven different activities including sit down, stand up, lie down, run, walk, fall and bend in an indoor environment using the Nexmon CSI tool [13]. Due to reflections induced by human activity, each subcarrier contains critical information that will increase HAR accuracy. The CSI matrices in our dataset are composed of 52 columns (available data subcarriers) and 600 up to 1100 rows depending on the period of each activity. The results demonstrate that this hardware is capable of providing tolerable data that is comparable to traditional technologies.
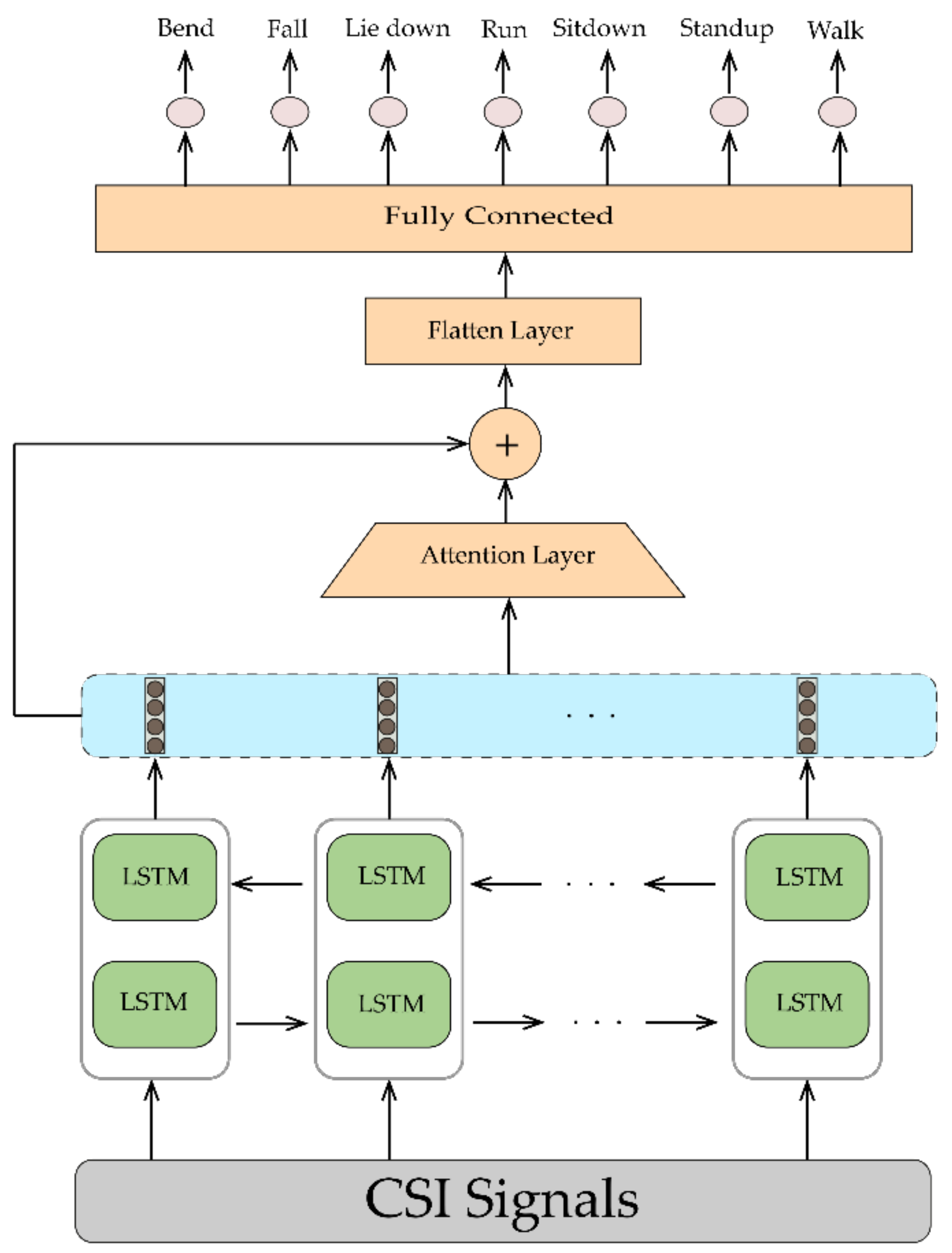
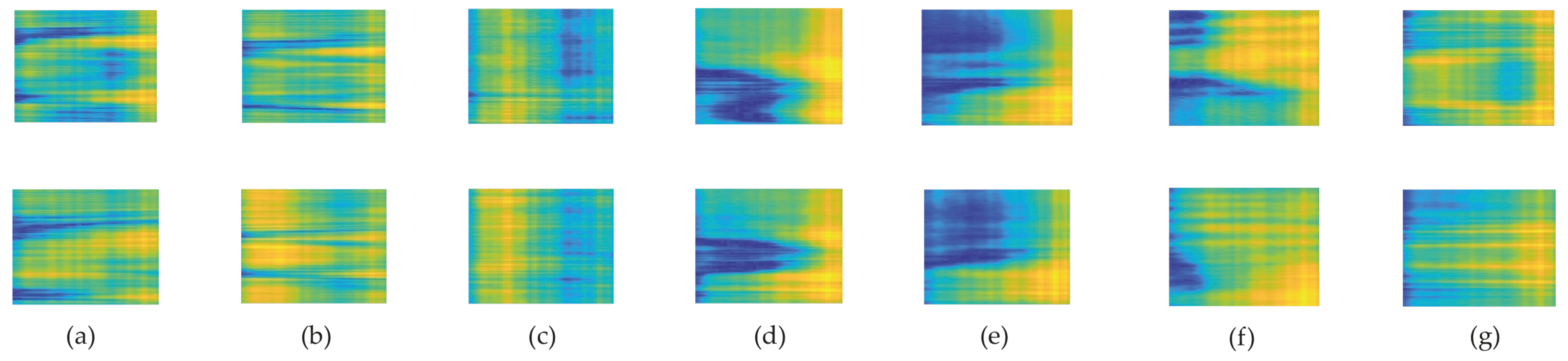
- We propose a new concept in improving the precision of HAR by converting CSI data into images using pseudocolor plots and feeding them into 2D-CNN. This method overcomes the mentioned limitations of LSTM and also the training time and computational complexity are less than those of other existing methods. We also exert a BLSTM network with an attention layer to address LSTM problems with future information. The results demonstrate that the conversion idea with 2D-CNN outperforms BLSTM in accuracy and consumed time.
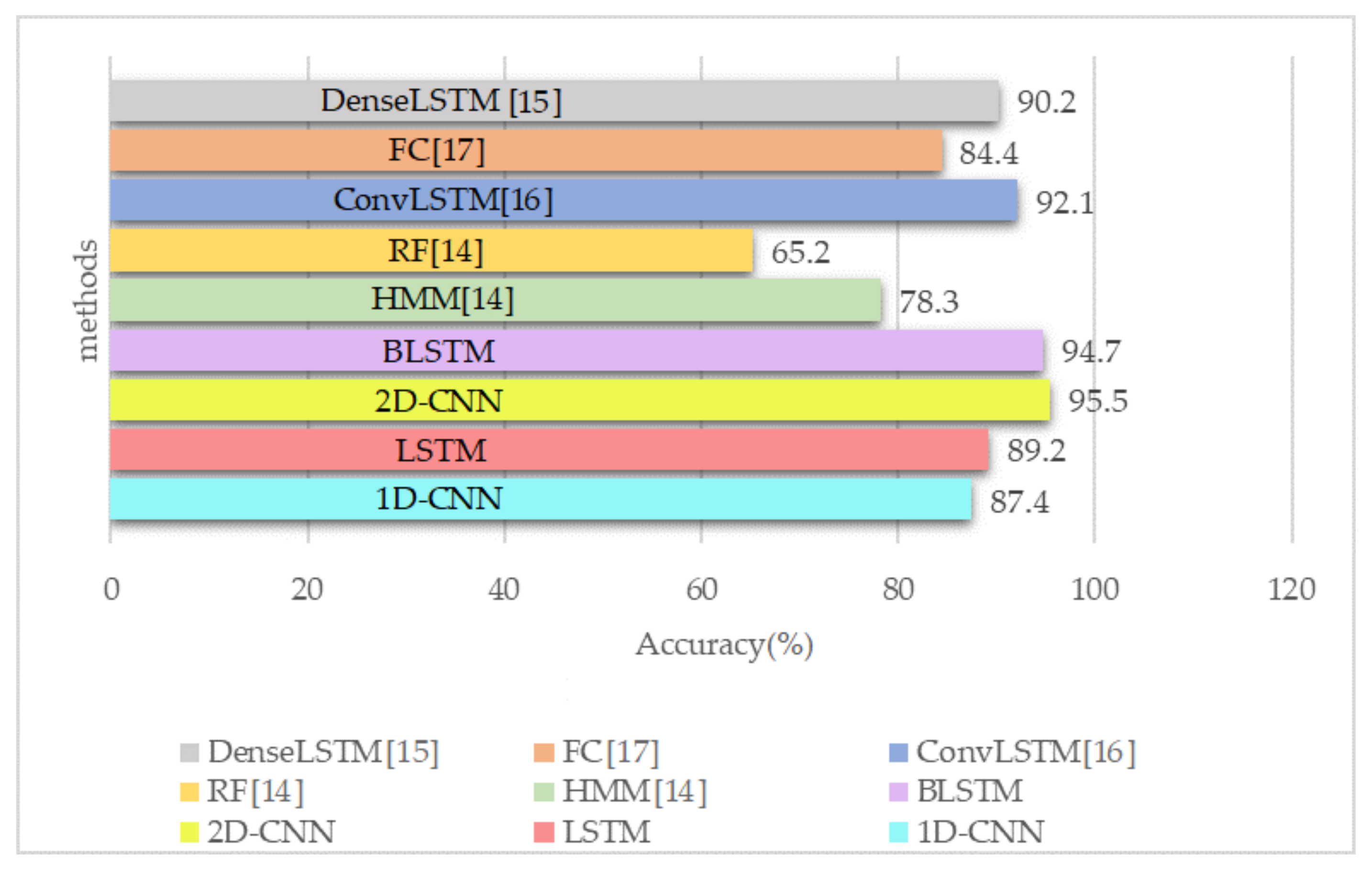
- We also perform a deep evaluation by implementing two other algorithms, including 1D-CNN and LSTM, and compare our results with four different models used for HAR, including Random Forest (RF) [14], Hidden Markov Model (HMM) [14], DenseLSTM [15], ConvLSTM [16] and Fully Connected (FC) network [17]. We analyze the performance of our dataset and proposed DL algorithms.
2. Related Works
3. System Model
3.1. Preliminary
3.2. Hardware and Firmware
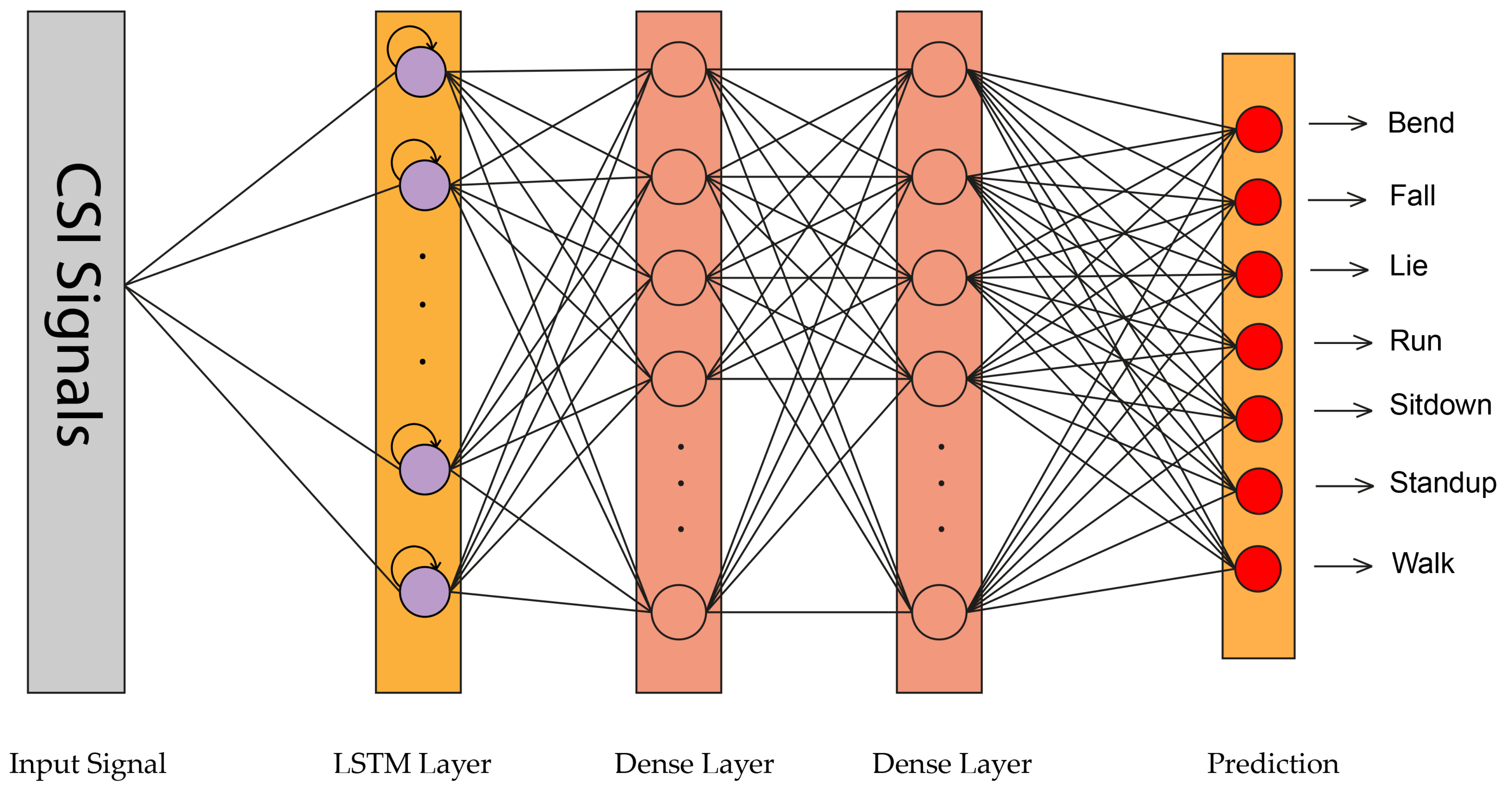
3.3. Neural Network
3.3.1. CNN
3.3.2. LSTM
3.4. Human Activity Recognition Datasets
4. Proposed Method
5. Evaluation
5.1. Measurement Setup
5.2. Simulations Results
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hassan, Q.F. Internet of Things A to Z: Technologies and Applications, 1st ed.; Wiley: Hoboken, NJ, USA, 2018; pp. 5–45. ISBN 978-1-119-45674-2. [Google Scholar]
- Dey, N.; Hassanien, A.E.; Bhatt, C.; Ashour, A.S.; Satapathy, S.C. Internet of Things and Big Data Analytics toward Next-Generation Intelligence, 1st ed.; Springer: New York, NY, USA, 2018; Volume 30, pp. 199–243. ISBN 978-3-319-86864-6. [Google Scholar]
- Perera, C.; Liu, C.H.; Jayawardena, S. The Emerging Internet of Things Marketplace from an Industrial Perspective: A Survey. IEEE Trans. Emerg. Top. Comput. 2015, 3, 585–598. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Feng, J.; Zhao, Y.; Zhang, X.; Zhang, S.; Han, J. Joint Activity Recognition and Indoor Localization with WiFi Fingerprints. IEEE Access 2019, 7, 80058–80068. [Google Scholar] [CrossRef]
- Vlachostergiou, A.; Stratogiannis, G.; Caridakis, G.; Siolas, G.; Mylonas, P. Smart Home Context Awareness Based on Smart and Innovative Cities; Association for Computing Machinery: New York, NY, USA, 2015; ISBN 9781450335805. [Google Scholar]
- Palipana, S.; Rojas, D.; Agrawal, P.; Pesch, D. FallDeFi: Ubiquitous Fall Detection using Commodity WiFi Devices. In Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, Singapore, 8–12 October 2018; Volume 1, pp. 1–25. [Google Scholar] [CrossRef]
- Moshiri, P.F.; Navidan, H.; Shahbazian, R.; Ghorashi, S.A.; Windridge, D. Using GAN to Enhance the Accuracy of Indoor Human Activity Recognition. In Proceedings of the 10th Conference on Information and Knowledge Technology, Tehran, Iran, 31 December 2019–2 January 2020. [Google Scholar]
- Ahad, M.A.R.; Ngo, T.T.; Antar, A.D.; Ahmed, M.; Hossain, T.; Muramatsu, D.; Makihara, Y.; Inoue, S.; Yagi, Y. Wearable Sensor-Based Gait Analysis for Age and Gender Estimation. Sensors 2020, 20, 2424. [Google Scholar] [CrossRef]
- Nabati, M.; Ghorashi, S.A.; Shahbazian, R. Joint Coordinate Optimization in Fingerprint-Based Indoor Positioning. IEEE Commun. Lett. 2021, 25, 1192–1195. [Google Scholar] [CrossRef]
- Zhang, W.; Zhou, S.; Yang, L.; Ou, L.; Xiao, Z. WiFiMap+: High-Level Indoor Semantic Inference with WiFi Human Activity and Environment. IEEE Trans. Veh. Technol. 2019, 68, 7890–7903. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, L.; Jiang, C.; Cao, Z.; Cui, W. WiFi CSI based passive Human Activity Recognition Using Attention Based BLSTM. IEEE Trans. Mob. Comput. 2019, 18, 2714–2724. [Google Scholar] [CrossRef]
- Elbayad, M.; Besacier, L.; Verbeek, J. Pervasive attention: 2d Convolutional Neural Networks for Sequence-to-Sequence Prediction. arXiv 2018, arXiv:1808.03867. [Google Scholar]
- Gringoli, F.; Schulz, M.; Link, J.; Hollick, M. Free Your CSI: A Channel State Information Extraction Platform For Modern Wi-Fi Chipsets. In Proceedings of the 13th International Workshop on Wireless Network Testbeds, Experimental Evaluation & Characterization, New York, NY, USA, 4 October 2019; pp. 21–28. [Google Scholar] [CrossRef]
- Yousefi, S.; Narui, H.; Dayal, S.; Ermon, S.; Valaee, S. A survey on behavior recognition using WiFi channel state information. IEEE Commun. Mag. 2017, 55, 98–104. [Google Scholar] [CrossRef]
- Zhang, J.; Fuxiang, W.; Wei, B.; Zhang, Q.; Huang, H.; Shah, S.W.; Cheng, J. Data Augmentation and Dense-LSTM for Human Activity Recognition Using WiFi Signal. IEEE Internet Things J. 2021, 8, 4628–4641. [Google Scholar] [CrossRef]
- Forbes, G.; Massie, S.; Craw, S. Wifi-based human activity recognition using Raspberry Pi. In Proceedings of the IEEE 32nd International Conference on Tools with Artificial Intelligence, Baltimore, MD, USA, 9–11 November 2020; pp. 722–730. [Google Scholar] [CrossRef]
- Zhou, N.; Sun, W.; Liang, M. Human Activity Recognition based on WiFi Signal Using Deep Neural Network. In Proceedings of the IEEE 8th International Conference on Smart City and Informatization, Guangzhou, China, 11 February 2020; pp. 26–30. [Google Scholar] [CrossRef]
- Mahjoub, A.B.; Atri, M. Human action recognition using RGB data. In Proceedings of the 11th International Design & Test Symposium, Hammamet, Tunisia, 18–20 December 2016. [Google Scholar] [CrossRef]
- Zhang, B.; Wang, L.; Wang, Z.; Qiao, Y.; Wang, H. Real-Time Action Recognition with Deeply Transferred Motion Vector CNNs. IEEE Trans. Image Process. 2018, 27, 2326–2339. [Google Scholar] [CrossRef]
- Agahian, S.; Farhood, N.; Cemal, K. Improving bag-of-poses with semi-temporal pose descriptors for skeleton-based action recognition. Vis. Comput. 2019, 35, 591–607. [Google Scholar] [CrossRef] [Green Version]
- Anitha, U.; Narmadha, R.; Sumanth, D.; Kumar, D. Robust Human Action Recognition System via Image Processing. Procedia Comput. Sci. 2020, 167, 870–877. [Google Scholar] [CrossRef]
- Tasnim, N.; Islam, M.K.; Baek, J.-H. Deep Learning Based Human Activity Recognition Using Spatio-Temporal Image Formation of Skeleton Joints. Appl. Sci. 2021, 11, 2675. [Google Scholar] [CrossRef]
- Rustam, F.; Reshi, A.A.; Ashraf, I.; Mehmood, A.; Ullah, S.; Khan, D.M.; Choi, G.S. Sensor-Based Human Activity Recognition Using Deep Stacked Multilayered Perceptron Model. IEEE Access 2020, 8, 218898–218910. [Google Scholar] [CrossRef]
- Du, Y.; Lim, Y.; Tan, Y. A Novel Human Activity Recognition and Prediction in Smart Home Based on Interaction. Sensors 2019, 19, 4474. [Google Scholar] [CrossRef] [Green Version]
- Nabati, M.; Navidan, H.; Shahbazian, R.; Ghorashi, S.A.; Windridge, D. Using Synthetic Data to Enhance the Accuracy of Fingerprint-Based Localization: A Deep Learning Approach. IEEE Sens. Lett. 2020, 4, 1–4. [Google Scholar] [CrossRef]
- Won, M.; Zhang, S.; Son, S.H. WiTraffic: Low-Cost and Non-Intrusive Traffic Monitoring System Using WiFi. In Proceedings of the 26th International Conference on Computer Communication and Networks, Vancouver, BC, Canada, 18 September 2017; pp. 1–9. [Google Scholar] [CrossRef]
- Tan, S.; Yang, J. WiFinger: Leveraging commodity WiFi for fine-grained finger gesture recognition. In Proceedings of the 17th ACM International Symposium on Mobile Ad Hoc Networking and Computing, New York, NY, USA, 5 July 2016; pp. 201–210. [Google Scholar] [CrossRef]
- Zhang, D.; Hu, Y.; Chen, Y.; Zeng, B. BreathTrack: Tracking indoor human breath status via commodity WiFi. IEEE Internet Things J. 2019, 6, 3899–3911. [Google Scholar] [CrossRef]
- Zeng, Y.; Pathak, P.H.; Xu, C.; Mohapatra, P. Your AP knows how you move: Fine-grained device motion recognition through WiFi. In Proceedings of the 1st ACM Workshop on Hot Topics in Wireless, New York, NY, USA, 11 September 2014; pp. 49–54. [Google Scholar] [CrossRef]
- Arshad, S.; Feng, C.; Liu, Y.; Hu, Y.; Yu, R.; Zhou, S.; Li, H. Wi-chase: A WiFi based human activity recognition system for sensorless environments. In Proceedings of the IEEE 18th International Symposium on A World of Wireless, Mobile and Multimedia Networks, Macau, China, 13 July 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Liu, X.; Cao, J.; Tang, S.; Wen, J. Wi-sleep: Contactless sleep monitoring via WiFi signals. IEEE Real-Time Syst. Symp. 2014, 346–355. [Google Scholar] [CrossRef]
- Halperin, D.; Hu, W.; Sheth, A.; Wetherall, D. Tool Release: Gathering 802.11n Traces with Channel State Information. ACM SIGCOMM Comput. Commun. Rev. 2011, 41, 53. [Google Scholar] [CrossRef]
- Xie, Y.; Li, Z.; Li, M. Precise Power Delay Profiling with Commodity WiFi. IEEE Trans. Mob. Comput. 2015, 18, 53–64. [Google Scholar] [CrossRef]
- Gast, M.S. 802.11ac: A Survival Guide; O’Reilly Media, Inc.: Sepastopol, CA, USA, 2013; pp. 11–20. ISBN 9781449343149. [Google Scholar]
- Li, Z.; Yang, W.; Peng, S.; Liu, F. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural. Netw. Learn. Syst. 2021, 1–21. [Google Scholar] [CrossRef]
- Peng, B.; Yao, K. Recurrent Neural Networks with External Memory for Language Understanding. arXiv 2015, arXiv:1506.00195. [Google Scholar]
- Wang, L.; Liu, R. Human Activity Recognition Based on Wearable Sensor Using Hierarchical Deep LSTM Networks. Circuits Syst. Signal Process. 2020, 39, 837–856. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Wu, Y. Mining action let ensemble for action recognition with depth cameras. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1290–1297. [Google Scholar]
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3D points. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition—Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 9–14. [Google Scholar]
- Yang, J.; Liu, Y.; Liu, Z.; Wu, Y.; Li, T.; Yang, Y. A Framework for Human Activity Recognition Based on WiFi CSI Signal Enhancement. Int. J. Antennas Propag. 2021, 2021, 6654752. [Google Scholar] [CrossRef]
- Ding, X.; Jiang, T.; Zhong, Y.; Wu, S.; Yang, J.; Xue, W. Improving WiFi-based Human Activity Recognition with Adaptive Initial State via One-shot Learning. In Proceedings of the IEEE Wireless Communications and Networking Conference, Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, W.; Liu, A.X.; Shahzad, M.; Ling, K.; Lu, S. Understanding and modeling of wifi signal based human activity recognition. In Proceedings of the 21st Annual International Conference on Mobile Computing and Networking, New York, NY, USA, 7 September 2015; pp. 65–76. [Google Scholar]
- Zhang, Y.; Wang, X.; Wang, Y.; Chen, H. Human Activity Recognition Across Scenes and Categories Based on CSI. IEEE Trans. Mob. Comput. 2020, 1. [Google Scholar] [CrossRef]
- Schulz, M.; Wegemer, D.; Hollick, M. Nexmon: The C-Based Firmware Patching Framework. 2017. Available online: https://nexmon.org (accessed on 27 October 2021).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PHY Standards | Subcarriers Range | Pilot Subcarriers | Total/Data Subcarriers |
|---|---|---|---|
| 802.11a/g | −26 to −1, +1 to +26 | −21, −7, +7, +21 | 52/48 |
| 802.11n 802.11ac 20 MHz | −28 to −1, +1 to +28 | −21, −7, +7, +21 | 56/52 |
| 802.11n 802.11ac 40 MHz | −58 to −2, +2 to +58 | −53, −25, −11, +11, +25, +53 | 114/108 |
| 802.11ac 80 MHz | −122 to −2, +2 to +122 | −103, −75, −39, −11, +11, +39, +75, +103 | 242/234 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fard Moshiri, P.; Shahbazian, R.; Nabati, M.; Ghorashi, S.A. A CSI-Based Human Activity Recognition Using Deep Learning. Sensors 2021, 21, 7225. https://doi.org/10.3390/s21217225
Fard Moshiri P, Shahbazian R, Nabati M, Ghorashi SA. A CSI-Based Human Activity Recognition Using Deep Learning. Sensors. 2021; 21(21):7225. https://doi.org/10.3390/s21217225
Chicago/Turabian StyleFard Moshiri, Parisa, Reza Shahbazian, Mohammad Nabati, and Seyed Ali Ghorashi. 2021. "A CSI-Based Human Activity Recognition Using Deep Learning" Sensors 21, no. 21: 7225. https://doi.org/10.3390/s21217225
APA StyleFard Moshiri, P., Shahbazian, R., Nabati, M., & Ghorashi, S. A. (2021). A CSI-Based Human Activity Recognition Using Deep Learning. Sensors, 21(21), 7225. https://doi.org/10.3390/s21217225