
Brain Strategy Algorithm for Multiple Object Tracking Based on Merging Semantic Attributes and Appearance Features



Abstract
:1. Introduction
- We introduced a new dataset, PGC (Pedestrians’ Gender and Clothes Attributes), including a total of 40,000 images with more than 190,000 annotations for four classes (trousers, shirts, men, and women). We intend to ensure that the datasets are available and accessible to the public so that other researchers can benefit from our dataset and continue from where we ended. The reasons behind introducing our dataset as a main contribution are explained in Section 3.
- After evaluating our dataset by comparing it with an open dataset with the same classes using the same detection model, the results show that our PGC dataset facilitates the learning of robust class detectors with much a better generalisation performance.
- We introduced and evaluated a novel MOT algorithm that mimics the human brain, addresses occlusion problems, and improves the state-of-the-art performance on standard benchmark datasets.
2. Related Work
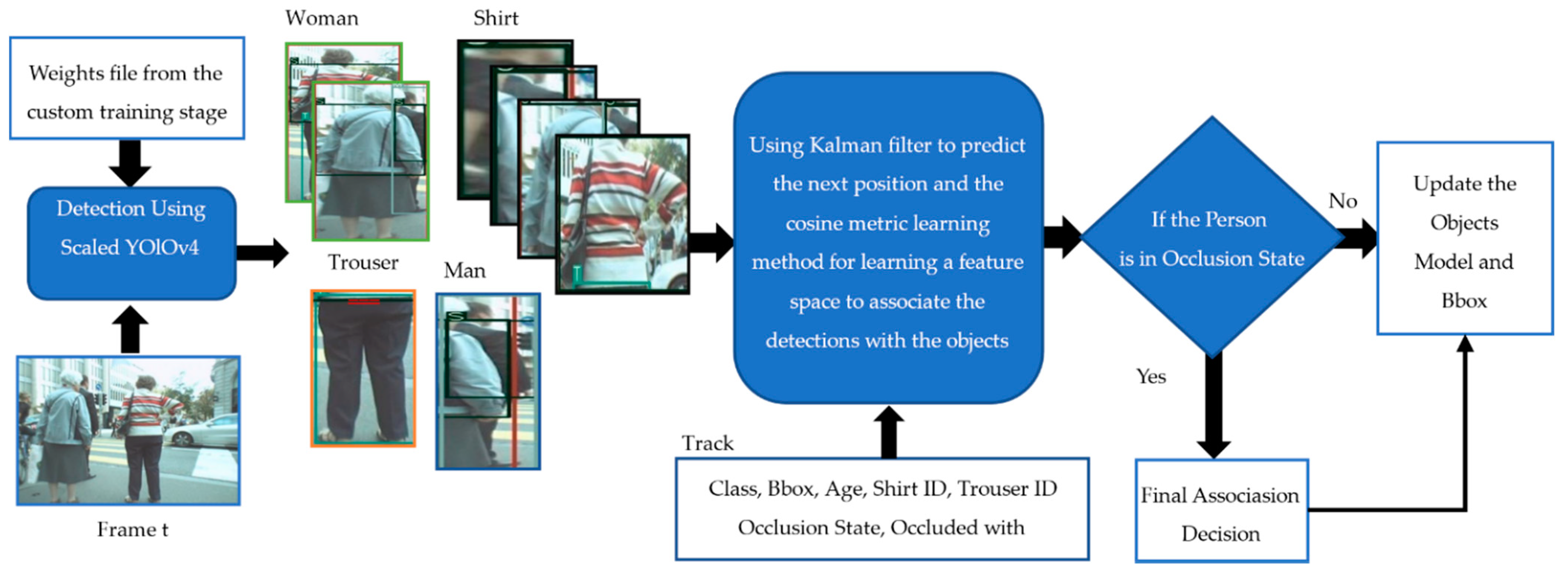
3. Proposed Algorithm
3.1. Detection
3.1.1. Classes
3.1.2. Dataset
3.1.3. Detection Model
3.2. First Association Stage
3.3. Final Association Stage
| Algorithm 1 Associated tracks and detection list |
| Input: List of associated tracks and detections |
| Output: Detecting occlusion state and save semantic attribute |
|
| Algorithm 2 Unassociated tracks list |
| Input: List of unassociated tracks |
| Output: Updated model |
|
| Algorithm 3 Unassociated detections list |
| Input: List of unassociated detections |
| Output: Retrieve the obj ID after appearing from occlusion |
|
4. Experiment Results
4.1. Performance Metrics
4.2. Detection Performance
4.2.1. Dataset
4.2.2. Detection Model
4.3. Tracking Performance
5. Limitations of the Study
6. What Went Wrong
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
- 1.
- Creating tight bounding boxes without taking any parts from the object.

- 2.
- Labelling all objects we could see in the image unless the appeared part was too small.

- 3.
- Label occluded (hidden partially behind another object), annotating the visible part only.

- 4.
- Be careful with the empty Bounding boxes that you may draw by mistake. Always count the annotated bounding boxes and make sure that there are no extra free boxes.

- 5.
- Shirt class includes any clothes on the upper body (blazer, short dress, T-shirt, blouse); trouser includes shorts too.

- 6.
- We added this rule later in the work: Make sure that no shirt or trouser includes any part from the person’s face as this will cause confusion to the model, and it will label any Bbox with a face as a shirt.

References
- Leonardelli, E.; Fait, E.; Fairhall, S.L. Temporal dynamics of access to amodal representations of category-level conceptual information. Sci. Rep. 2019, 9, 239. [Google Scholar] [CrossRef]
- Lyu, C.; Hu, S.; Wei, L.; Zhang, X.; Talhelm, T. Brain Activation of Identity Switching in Multiple Identity Tracking Task. PLoS ONE 2015, 10, e0145489. [Google Scholar] [CrossRef] [PubMed]
- Rupp, K.; Roos, M.; Milsap, G.; Caceres, C.; Ratto, C.; Chevillet, M.; Crone, N.E.; Wolmetz, M. Semantic attributes are encoded in human electrocorticographic signals during visual object recognition. NeuroImage 2017, 148, 318–329. [Google Scholar] [CrossRef]
- Ardila, A. People recognition: A historical/anthropological perspective. Behav. Neurol. 1993, 6, 99–105. [Google Scholar] [CrossRef] [Green Version]
- Hong, Z.; Chen, Z.; Wang, C.; Mei, X.; Prokhorov, D.; Tao, D. MUlti-Store Tracker (MUSTer): A cognitive psychology inspired approach to object tracking. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 749–758. [Google Scholar] [CrossRef]
- Song, Y.; Zhao, Y.; Yang, X.; Zhou, Y.; Wang, F.N.; Zhang, Z.S.; Guo, Z.K. Object detection and tracking algorithms using brain-inspired model and deep neural networks. J. Phys. Conf. Ser. 2020, 1507, 092066. [Google Scholar] [CrossRef]
- Zhang, S.; Lan, X.; Yao, H.; Zhou, H.; Tao, D.; Li, X. A Biologically Inspired Appearance Model for Robust Visual Tracking. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2357–2370. [Google Scholar] [CrossRef]
- Yoon, K.; Kim, D.Y.; Yoon, Y.-C.; Jeon, M. Data Association for Multi-Object Tracking via Deep Neural Networks. Sensors 2019, 19, 559. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Liu, Q.; Wu, Y.; Yang, M.-H. Robust Visual Tracking via Convolutional Networks without Training. IEEE Trans. Image Process. 2016, 25, 1779–1792. [Google Scholar] [CrossRef] [PubMed]
- Dequaire, J.; Ondrúška, P.; Rao, D.; Wang, D.; Posner, I. Deep tracking in the wild: End-to-end tracking using recurrent neural networks. Int. J. Robot. Res. 2017, 37, 492–512. [Google Scholar] [CrossRef]
- Kamkar, S.; Ghezloo, F.; Moghaddam, H.A.; Borji, A.; Lashgari, R. Multiple-target tracking in human and machine vision. PLoS Comput. Biol. 2020, 16, e1007698. [Google Scholar] [CrossRef] [Green Version]
- Atkinson, R.; Shiffrin, R. Human Memory: A Proposed System and its Control Processes. In Psychology of Learning and Motivation—Advances in Research and Theory 2; Academic Press: Cambridge, UK, 1968; Volume 2, pp. 89–195. [Google Scholar] [CrossRef]
- Gao, D.; Han, S.; Vasconcelos, N. Discriminant Saliency, the Detection of Suspicious Coincidences, and Applications to Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 989–1005. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Yang, H.; Liu, N.; Kim, M.; Zhang, W.; Yang, M.-H. Online Multi-Object Tracking with Dual Matching Attention Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 379–396. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Li, P.; Sun, C.; Wang, D.; Yang, G.; Lu, H. Multi attention module for visual tracking. Pattern Recognit. 2018, 87, 80–93. [Google Scholar] [CrossRef]
- Dwyer, B.; Nelson, J. Roboflow (Version 1.0). 2021. Available online: https://roboflow.com (accessed on 11 November 2021).
- Makovski, T.; Jiang, Y.V. The role of visual working memory in attentive tracking of unique objects. J. Exp. Psychol. Hum. Percept. Perform. 2009, 35, 1687–1697. [Google Scholar] [CrossRef] [Green Version]
- Qi, Y.; Wang, Y.; Xue, T. Brain Memory Inspired Template Updating Modeling for Robust Moving Object Tracking Using Particle Filter. In Proceedings of the International Conference on Brain Inspired Cognitive Systems, Shenyang, China, 11–14 July 2012; pp. 112–119. [Google Scholar] [CrossRef]
- Wang, Y.; Qi, Y.; Li, Y. Memory-Based Multiagent Coevolution Modeling for Robust Moving Object Tracking. Sci. World J. 2013, 2013, 793013. [Google Scholar] [CrossRef] [Green Version]
- Jiang, M.-X.; Deng, C.; Pan, Z.-G.; Wang, L.-F.; Sun, X. Multiobject Tracking in Videos Based on LSTM and Deep Reinforcement Learning. Complexity 2018, 2018, 4695890. [Google Scholar] [CrossRef]
- Kim, C.; Li, F.; Rehg, J.M. Multi-object Tracking with Neural Gating Using Bilinear LSTM. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 200–215. [Google Scholar] [CrossRef]
- Wang, D.; Fang, H.; Liu, Y.; Wu, S.; Xie, Y.; Song, H. Improved RT-MDNet for panoramic video target tracking. Harbin Gongye Daxue Xuebao J. Harbin Inst. Technol. 2020, 52, 152–160. [Google Scholar] [CrossRef]
- Grill-Spector, K.; Malach, R. The Human Visual Cortex. Annu. Rev. Neurosci. 2004, 27, 649–677. [Google Scholar] [CrossRef] [Green Version]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Iordanescu, L.; Grabowecky, M.; Suzuki, S. Demand-based dynamic distribution of attention and monitoring of velocities during multiple-object tracking. J. Vis. 2009, 9, 1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Welch, G.; Bishop, G. An Introduction to the Kalman Filter. Practice 2006, 7, 1–16. [Google Scholar]
- Haller, S.; Bao, J.; Chen, N.; He, J.C.; Lu, F. The effect of blur adaptation on accommodative response and pupil size during reading. J. Vis. 2010, 10, 1. [Google Scholar] [CrossRef]
- MOT Challenge. Available online: https://motchallenge.net/ (accessed on 16 May 2021).
- Van Koppen, P.J.; Lochun, S.K. Portraying perpetrators: The validity of offender descriptions by witnesses. Law Hum. Behav. 1997, 21, 661–685. [Google Scholar] [CrossRef]
- Sporer, S.L. An archival analysis of person descriptions. In Biennial Meeting of the American Psychology-Law Society; American Psychology-Law Society: San Diego, CA, USA, 1992. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar] [CrossRef] [Green Version]
- Deng, Y.; Luo, P.; Loy, C.C.; Tang, X. Pedestrian Attribute Recognition At Far Distance. In Proceedings of the 2014 ACM Conference on Multimedia. Association for Computing Machinery, Orlando, FL, USA, 3–7 November 2014; pp. 789–792. [Google Scholar] [CrossRef]
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A Survey on Bias and Fairness in Machine Learning. ACM Comput. Surv. 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Buolamwini, J. Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification. In Proceedings of the the 1st Conference on Fairness, Accountability and Transparency, New York, NY, USA, 23–24 February 2018. [Google Scholar]
- Klare, B.F.; Klein, B.; Taborsky, E.; Blanton, A.; Cheney, J.; Allen, K.; Grother, P.; Mah, A.; Burge, M.; Jain, A.K. Pushing the frontiers of unconstrained face detection and recognition: IARPA Janus Benchmark A. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1931–1939. [Google Scholar] [CrossRef]
- Forsyth, D. Object Detection with Discriminatively Trained Part-Based Models. Computer 2014, 47, 6–7. [Google Scholar] [CrossRef]
- Hosang, J.; Benenson, R.; Schiele, B. Learning Non-maximum Suppression. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6469–6477. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13024–13033. [Google Scholar] [CrossRef]
- Bae, S.-H.; Yoon, K.-J. Confidence-Based Data Association and Discriminative Deep Appearance Learning for Robust Online Multi-Object Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 595–610. [Google Scholar] [CrossRef]
- Mottaghi, R.; Chen, X.; Liu, X.; Cho, N.-G.; Lee, S.-W.; Fidler, S.; Urtasun, R.; Yuille, A. The Role of Context for Object Detection and Semantic Segmentation in the Wild. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; Institute of Electrical and Electronics Engineers (IEEE): Piscatway, NY, USA, 2014; pp. 891–898. [Google Scholar]
- Jefferies, E. The neural basis of semantic cognition: Converging evidence from neuropsychology, neuroimaging and TMS. Cortex 2013, 49, 611–625. [Google Scholar] [CrossRef]
- Gainotti, G. The organization and dissolution of semantic-conceptual knowledge: Is the ‘amodal hub’ the only plausible model? Brain Cogn. 2011, 75, 299–309. [Google Scholar] [CrossRef]
- Franconeri, S.; Jonathan, S.; Scimeca, J. Tracking Multiple Objects Is Limited Only by Object Spacing, Not by Speed, Time, or Capacity. Psychol. Sci. 2010, 21, 920–925. [Google Scholar] [CrossRef]
- Bernardin, K.; Stiefelhagen, R. Evaluating Multiple Object Tracking Performance: The CLEAR MOT Metrics. EURASIP J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef] [Green Version]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance Measures and a Data Set for Multi-target, Multi-camera Tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 17–35. [Google Scholar] [CrossRef] [Green Version]
- Benchmarking the Major Cloud Vision AutoML Tools. Available online: https://blog.roboflow.com/automl-vs-rekognition-vs-custom-vision/ (accessed on 3 April 2021).
- Open Images V6—Description. Available online: https://storage.googleapis.com/openimages/web/factsfigures.html (accessed on 14 May 2021).
- Dai, P.; Weng, R.; Choi, W.; Zhang, C.; He, Z.; Ding, W. Learning a Proposal Classifier for Multiple Object Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 2443–2452. [Google Scholar] [CrossRef]
- Braso, G.; Leal-Taixe, L. Learning a Neural Solver for Multiple Object Tracking. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 6246–6256. [Google Scholar] [CrossRef]
- Papakis, I.; Sarkar, A.; Karpatne, A. GCNNMatch: Graph Convolutional Neural Networks for Multi-Object Tracking via Sinkhorn Normalization. arXiv 2020, arXiv:2010.00067. [Google Scholar]
- Bergmann, P.; Meinhardt, T.; Leal-Taixe, L. Tracking Without Bells and Whistles. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef] [Green Version]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Brain Inspiration | Contributions | Advantages and Limitations |
|---|---|---|
| Visual attention | Gao et al. [13] | Most attention-based algorithms can handle variability in background and object appearance. However, this adaptation makes these algorithms suffer from occlusion. |
| Zhu et al. [14] | ||
| Chen et al. [15] | ||
| Visual memory | Qi et al. [18] | Memory-based algorithms can successfully handle occlusion and data association, but they need to formulate vital parameters to decide what to remember and what to forget. |
| Wang et al. [19] | ||
| Jiang et al. [20] | ||
| Kim et al. [21] | ||
| Wang et al. [22] |
| Eight Human Brain Strategies to Handle Object Tracking | How MSA-AF Simulated These Strategies | |
|---|---|---|
| 1 | Tracking in the human brain is a two-stage process; the first stage is for location processing, while the second stage is for identity processing [2]. | MSA-AF is a tracking-by-detection algorithm. The first stage is detection (location process), then association (identifying process). |
| 2 | Experimental results by [23] suggest that the human brain uses motion prediction to handle the tracking problem. | MSA-AF used Kalman to predict the next position of the object. |
| 3 | Neural representation is needed to achieve particular goals in scenes, e.g., recognition [1]. | MSA-AF used pre-trained CNN to compute the Bbox appearance descriptor in [24]. |
| 4 | Neural representations reflect stimulus attributes in low-level visual areas and perceptual outcomes in high-level visual areas [4]. | MSA-AF used semantic attributes (man, woman, shirt, trouser). |
| 5 | Experimental results by [17] conclude that the observer’s recovery from any errors during tracking was by storing surface properties in the visual working memory. | MSA-AF used the long-memory theory to save all information about each target and retrieve it when it is more needed, usually when the object is in an occlusion state. |
| 6 | The brain provides more attentional resources when objects are in a crowded scene, with a higher chance of being lost when target switching conditions happen [25]. | Using (4), MSA-AF can decide if any object is in an occlusion situation or not. If yes, MSA-AF gives more attention to this object by using semantic information. |
| 7 | The human brain uses optimised features to discriminate targets better and retrieve them faster and more efficiently [2]. | MSA-AF uses appearance information to discriminate the object. |
| 8 | When the possibility of confusing targets increases, it is suggested that human subjects benefit from rescue saccades (saccades toward targets that are in a critical situation) to avoid incorrect associations [26,27]. | Final association decision at MSA-AF, Section 3 imitates this concept. |
| Training Time | mAP 0.5 | mAP 0.5–0.95 | Precision | Recall | |
|---|---|---|---|---|---|
| Open Images Dataset V6 | 3 d 5 h 11 min | 0.4999 | 0.3983 | 0.2079 | 0.7867 |
| PGC Dataset (ours) | 3 d 1 h 27 min | 0.8924 | 0.6862 | 0.5487 | 0.9321 |
| MOT17 | ↑MOTA | ↑IDF1 | ↑MOTP | ↑MT | ↓ML | ↑Rcll | ↑Prcn | ↓FAF |
|---|---|---|---|---|---|---|---|---|
| LPC_MOT [51] | 59 | 66.8 | 78 | 29.9 | 33.9 | 63.3 | 93.9 | 1.3 |
| MPNTrack [52] | 58.8 | 61.7 | 78.6 | 28.8 | 33.5 | 62.1 | 95.3 | 1 |
| GNNMatch [53] | 57.3 | 56.3 | 78.6 | 24.4 | 33.4 | 60.1 | 96 | 0.8 |
| Tracktor++v2 [54] | 53.5 | 52.3 | 78 | 19.5 | 36.6 | 56 | 96.3 | 0.7 |
| SORT17 [55] | 43.1 | 39.8 | 77.8 | 12.5 | 42.3 | 49.0 | 90.7 | 1.6 |
| MSA-AF (Ours) | 44.4 | 37.1 | 80.1 | 13 | 30.25 | 50.6 | 89.55 | 0.7 |
| MOT20 | ↑MOTA | ↑IDF1 | ↑MOTP | ↑MT | ↓ML | ↑Rcll | ↑Prcn | ↓FAF |
|---|---|---|---|---|---|---|---|---|
| LPC_MOT [51] | 56.3 | 62.5 | 79.7 | 34.1 | 25.2 | 58.8 | 96.3 | 2.6 |
| MPNTrack [52] | 57.6 | 59.1 | 79 | 38.2 | 22.5 | 61.1 | 94.9 | 3.8 |
| GNNMatch [53] | 54.5 | 49 | 79.4 | 32.8 | 25.5 | 56.8 | 96.9 | 2.1 |
| Tracktor++v2 [54] | 52.6 | 52.7 | 79.9 | 29.4 | 26.7 | 54.3 | 97.6 | 1.5 |
| SORT17 [55] | 42.7 | 45.1 | 78.5 | 16.7 | 26.2 | 48.8 | 90.2 | 6.1 |
| MSA-AF (Ours) | 45.3 | 36.4 | 77.6 | 40 | 19 | 54.8 | 86.8 | 4.36 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Diab, M.S.; Elhosseini, M.A.; El-Sayed, M.S.; Ali, H.A. Brain Strategy Algorithm for Multiple Object Tracking Based on Merging Semantic Attributes and Appearance Features. Sensors 2021, 21, 7604. https://doi.org/10.3390/s21227604
Diab MS, Elhosseini MA, El-Sayed MS, Ali HA. Brain Strategy Algorithm for Multiple Object Tracking Based on Merging Semantic Attributes and Appearance Features. Sensors. 2021; 21(22):7604. https://doi.org/10.3390/s21227604
Chicago/Turabian StyleDiab, Mai S., Mostafa A. Elhosseini, Mohamed S. El-Sayed, and Hesham A. Ali. 2021. "Brain Strategy Algorithm for Multiple Object Tracking Based on Merging Semantic Attributes and Appearance Features" Sensors 21, no. 22: 7604. https://doi.org/10.3390/s21227604