Abstract
The incremental least-mean-square (ILMS) algorithm is a useful method to perform distributed adaptation and learning in Hamiltonian networks. To implement the ILMS algorithm, each node needs to receive the local estimate of the previous node on the cycle path to update its own local estimate. However, in some practical situations, perfect data exchange may not be possible among the nodes. In this paper, we develop a new version of ILMS algorithm, wherein in its adaptation step, only a random subset of the coordinates of update vector is available. We draw a comparison between the proposed coordinate-descent incremental LMS (CD-ILMS) algorithm and the ILMS algorithm in terms of convergence rate and computational complexity. Employing the energy conservation relation approach, we derive closed-form expressions to describe the learning curves in terms of excess mean-square-error (EMSE) and mean-square deviation (MSD). We show that, the CD-ILMS algorithm has the same steady-state error performance compared with the ILMS algorithm. However, the CD-ILMS algorithm has a faster convergence rate. Numerical examples are given to verify the efficiency of the CD-ILMS algorithm and the accuracy of theoretical analysis.
1. Introduction
Distributed processing over networks refers to the information extraction from streaming data collected at a group of spatially-dispersed and interconnected nodes. Distributed optimization problems of this kind appear in many applications, such as wireless sensor networks [1,2,3], multi-robot systems [4,5], smart grid programs [6,7,8,9], statistical learning over netwoks [10,11,12], and clustering [13,14]. Several classes of distributed optimization and estimation algorithms over multi-agent networks have been introduced in the literature. The consensus methods [15,16,17,18], incremental adaptive strategies [19,20,21,22,23,24], and diffusion networks [25,26,27,28,29] are among the most notable approaches.
In typical consensus strategies, each individual node collects noisy measurements over a period of time and performs a local processing task (e.g., calculates a local estimate). Then, the nodes collaborate through several iterations and share their information to achieve agreement. In the incremental strategies, a Hamilton cycle is established through the nodes where each node receives data from previous node on cycle path and sends the updated data to the next node. Such a mode of cooperation decreases the inter-node communication across the network and modifies the network independence. In diffusion strategies, information is spread through the network simultaneously and locally at all nodes and the task of distributed processing is performed. As in this mode of cooperation each node collaborates with its connected neighbors, the communication burden is higher than that of an incremental based strategy.
In this paper, we propose an incremental-based algorithm for solving the distributed estimation problem over a Hamilton network. One of the primary methods for solving this problem is the incremental least-mean-square (ILMS) algorithm reported in [19]. In this algorithm, the local calculated estimates are updated at each node by employing the LMS adaptation rule, without requiring any prior information about the data statistics. In order to implement the ILMS algorithm, it is assumed that at each time instant, the adaptation step has access to all entries of the approximate gradient vector—see expression (3) further ahead. In some practical situations (e.g., limited communication resources or missing data due to imperfect communication links) only a fraction of the approximate gradient vector is available for adaption. Thus, developing a new version of ILMS algorithm for networks with mentioned scenarios is of practical importance.
So far, different algorithms have been reported in the literature which solve the problem of distributed learning with partial information. In [30,31,32], a Bernoulli variable is used to model the step-size parameter, so that when the step-size is zero, not all entries of intermediate estimates are updated and the adaptation step is skipped for some. In [33,34,35,36,37,38], a different notion of partial diffusion of information is employed which relies on the exchange of a subset of entries of the weight estimate vectors themselves. In other words, it is assumed that each node shares only a fraction of its local information with its neighbors. Likewise, in [39], a situation is assumed in which some entries in the regression vector are missing at random due to incomplete information or censoring. In order to undo these changes, authors in [39] proposed an estimation scheme to estimate the underlying model parameters when the data are missing. Some other criteria have been proposed in the literature to motivate partial updating scheme. For instance, in [40], the periodic and sequential partial LMS updates are proposed, where the former scheme updates all filter coefficients every -th iteration, with , instead of every iteration. The later updates only a portion of coefficients, which are predetermined, at each iteration. In [41], the stochastic partial LMS algorithm is proposed that is a randomized version of sequential scheme where the coefficient subsets are selected in random instead of deterministic fashion. The works [42,43] utilize the concept of set-membership filtering to partially update the weight vector, where the updates occur only when the innovation obtained from the data exceeds a predetermined threshold. The works [12,44,45] employ Krylov subspace concept to partially update the weight vector that is based on dimensionality reduction policies. Some other techniques based on energy considerations limit the updates, e.g., [46]. In [47], a reduced complexity augmented complex least-mean-square algorithm is proposed by employing partial-update for improper complex signals. The algorithm involves selection of a fraction of coefficients at every iteration. In [48], the authors focus on diffusion learning mechanisms and study its mean-square error performance under a generalized coordinate-descent scheme where the adaptation step by each node involves only a random subset of the coordinate-descent gradient vector. None of the aforementioned works; however, rely on the adaptive incremental strategy. To address this issue, we combine two techniques (incremental mode of cooperation and coordinate-descent updates) to consolidate a new method, termed coordinate-descent ILMS (CD-ILMS), for distributed estimation problem.
The main contributions of this manuscript can be stated as follows:
- (a)
- A CD-ILMS algorithm is proposed to simulate the situation where some entries in approximate gradient vectors are missing or to control the computational burden of the update estimate purposely;
- 1.
- We examine the effect of random partial gradient information on the learning performance and convergence rate of ILMS algorithm for MSE cost function;
- 2.
- A theoretical analysis of the performance of CD-ILMS algorithm is concluded under some typical simplifying assumptions and approximations, typical in adaptive systems and tend to achieve a performance level that matches well with practice;
- 3.
- Stability conditions for CD-ILMS algorithm are derived both in mean and mean-square senses under certain statistical conditions. We find the necessary condition on step-size to guarantee the stability of CD-ILMS algorithms;
- 4.
- Employing the energy conservation paradigm, we derive closed-form expressions to describe the learning curves in terms of excess mean-square-error (EMSE) and mean-square-deviation (MSD);
- 5.
- We compare the CD-ILMS algorithm and regular full-update ILMS algorithm in terms of convergence rate and computational complexity. We find that although the CD-ILMS algorithm convergence to steady-state region takes longer, the overall computational complexity, i.e., savings in computation per iteration, does remain invariant.
The paper layout is organized as follows: In Section 2, we briefly explain the ILMS algorithm and formulate the CD-ILMS algorithm. In Section 3.1, we describe the system model and assumptions. The stability and performance analysis of CD-ILMS algorithm are analyzed both in mean and mean-square sense in Section 3.2 and Section 3.3, respectively. Section 3.4 and Section 3.5 investigate the transient and steady-state performance of CD-ILMS algorithm, respectively. In Section 4, we draw a comparison between ILMS and CD-ILMS algorithms on the basis of convergence rate and computational complexity. Performance evaluations are illustrated in Section 5. The paper is finally concluded in Section 6.
Notation: Throughout the paper, we adopt normal lowercase letters for scalars, bold lowercase letters for column vectors and bold uppercase letters for matrices, while denotes an identity matrix of appropriate size. Superscript denotes transposition for real-valued vectors and matrices. The symbol is the expectation operator, represents the trace of its matrix argument, vectorizes a matrix by stacking its columns on top of each other, and ⊗ is the standard Kronecker product.
2. Algorithm Description
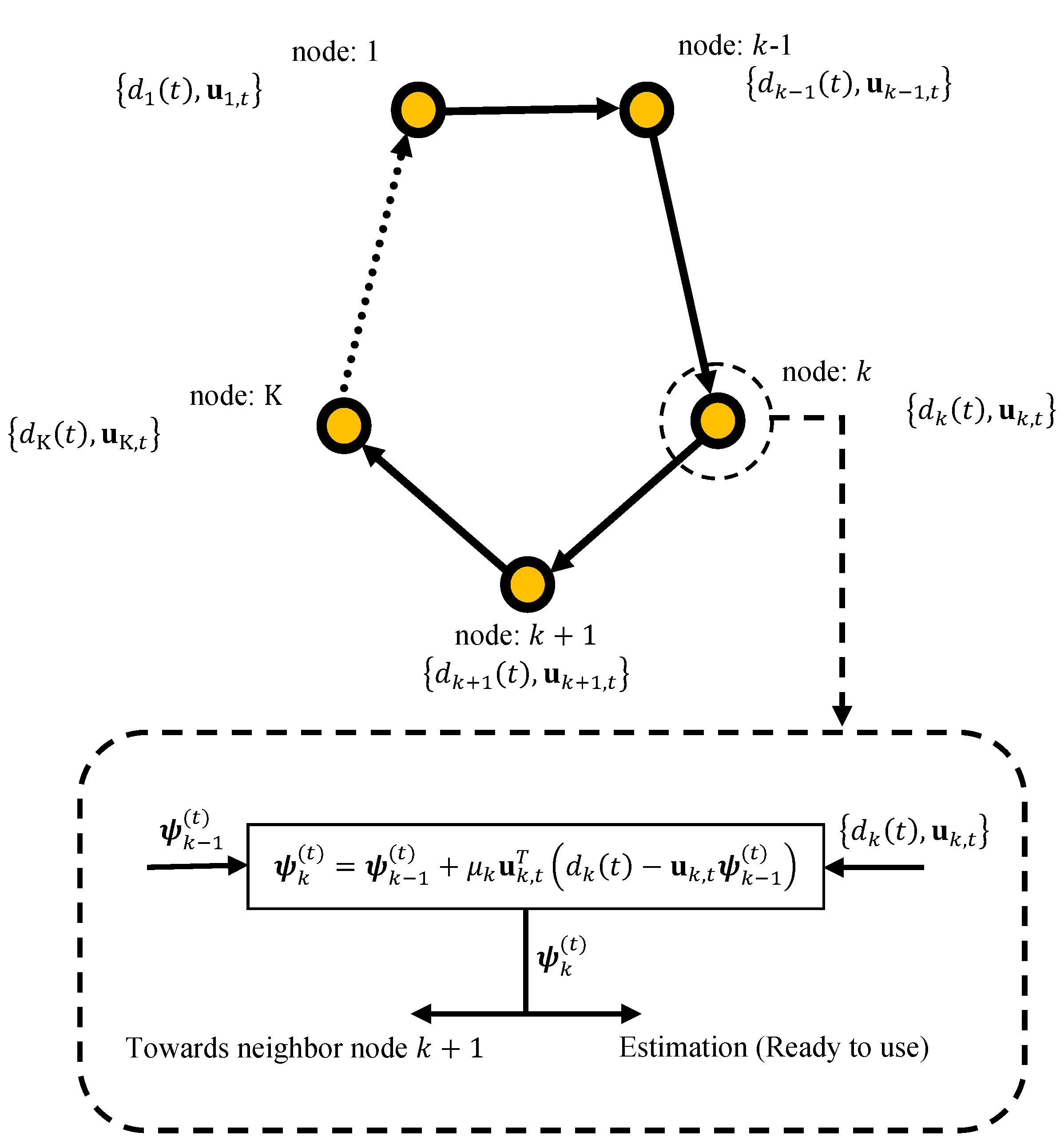
We consider a network with nodes with incremental cooperation topology, as shown in Figure 1. The network is used to estimate the parameter , that minimize the following aggregate global cost function:
where it is assumed that each individual cost function, is -strongly convex and its gradients satisfy the -Lipschitz condition [25]. These conditions are equivalent to requiring to be twice-differentiable and Hessian matrices of the individual costs, , to be bounded as follows
for some positive parameters , where . Some cases of interest, e.g., Log-Loss regression or MSE [25,26], automatically satisfy the condition in (2).
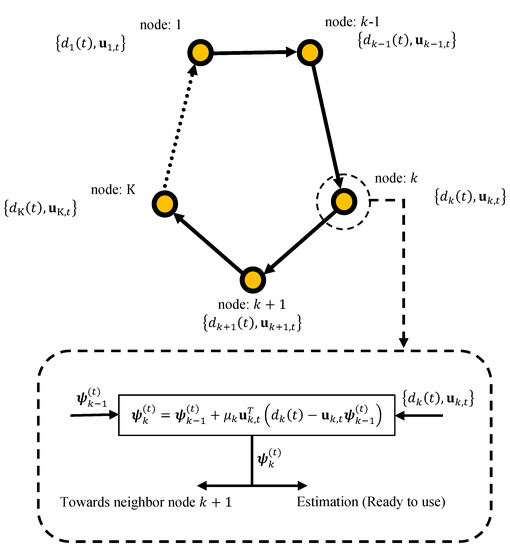
Figure 1.
Data processing in an incremental network.
2.1. Incremental Steepest-Descent Solution
By applying the steepest-descent method in conjunction with the incremental strategy to (1) gives the Incremental Steepest-Descent Solution as lists in Algorithm 1. Observe that in this implementation, each node k needs to receive the calculated estimate of at node (which is denoted by ). In (3), denotes a global estimation of at time instant t. Moreover, since the true gradient vectors, , are not available beforehand in many practical applications, they have been replaced by approximates, .
| Algorithm 1. Incremental Strategy [19]. |
| Initialization: start with initial condition. |
| for every time do |
| set |
| for nodes do |
| receive from node |
| end for |
| set |
| end for |
| End |
2.2. Coordinate-Descent Incremental Adaptation
Consider a case in which, due to some practical issues (e.g., missing data or limited computational and communication burden) only a subset of the approximate gradient vector can be updated as follows:
In order to handle such a situation, first a suitable model should be adopted. To this end, we follow a similar approach to [48] and define a diagonal random matrix of node k at iteration t as
where are some Bernoulli random variables, that the randomness in the update varies across space, k, and over time, t. We have or with the following probability
where means that l-th entry of is missing and l-th entry of in (3) is not updated. Multiplying the approximate gradient vector by , we replace by as
3. Performance Analysis
3.1. Data Model and Assumptions
Consider MSE networks where at each time instant t, each node k is assumed to observe a scalar measurement and a row regression vector . A linear regression model is used to describe the collected data at each individual node as follows:
where is the noise process. The individual cost function, , that is associated with each node k is the MSE (quadratic) cost
To proceed with analysis, we introduce some notation and assumptions. In our analysis, we assume that:
Assumption 1.
(i) For all nodes k, and , the measurement noises are all zero-mean, white, and independent from the input and desired signals, with variances ;
- 1.
- The regression data for all nodes k, and all observation times , are zero-mean, white overt time and space withwhere , and denotes the Kronecker delta, i.e., it is equal to one when and zero otherwise;
- 2.
- The step-sizes, , are small enough so as to ignore the quadratic term in .
Let the notation represent the available information about the random processes and at all agents for :
Assumption 2.
For all , the indicator variables and are assumed to be independent of each other. Moreover, the random variables and are independent of each other, for any iteration and for all nodes k.
Based on the adaptive implementation of incremental strategy [19], the adaptive distributed coordinate-descent incremental algorithm or distributed coordinate-descent incremental LMS (CD-ILMS) algorithm can be summarized in Algorithm 2. In this algorithm, each node updates the local estimate as
| Algorithm 2. Coordinate-Descent Incremental LMS (CD-ILMS) Strategy. |
| Initialization: start with initial condition. |
| for every time do |
| set the fictitious boundary condition at . |
| for nodes do |
| node k receives from its preceding neighbor |
| , |
| node k performs:
|
| end for |
| set |
| end for |
| End |
3.2. Mean Stability Analysis
Now, the mean behavior of the proposed algorithm is analyzed. More specifically, we seek conditions that for sufficiently large t and for all k, the proposed algorithm is asymptotically unbiased. To proceed, the following local error signals are defined:
Taking statistical expectations of both sides of (11) together with using the items on Assumption 1, we obtain
Through iterating recursion (12) over t and setting , we deduce that evolves according to
where . Clearly, the mean weight-error vector for the CD-ILMS depends on the spectral radius of . The following proposition summarizes the required mean stability condition for the proposed algorithm.
Proposition 1
(Mean Stability).Assume the data model (7) and Assumption 1 hold. Then, the CD-ILMS algorithm is asymptotically unbiased if, and only if, the step-size parameters satisfy the following condition:
where denotes the largest eigenvalue of its argument.
Proof.
The asymptotic unbiasedness of the CD-ILMS algorithm is guaranteed if, and only if, the matrix be stable, or equivalently, all its eigenvalues lie inside the unit disc, namely,
As the spectral radius of a matrix is always smaller than any induced norm of the same matrix [49] we have
where step is because every is a symmetric matrix. This means that its spectral radius agrees with its 2-induced norm, so that is justified. Accordingly, to guarantee the constraint (15) for all k, it is enough to have , which is equivalent to
Thus, the conclusion in (14) is verified. □
3.3. Mean-Square Performance
In this section, the mean-square performance of the error recursion (11) is examined. We start by equating the squared-weighted Euclidean norms of both sides of (11) and taking the expectations together with employing Assumption 1. After a straightforward calculation, we find the following weighted-variance relation:
for any arbitrary positive-definite weighting matrix . Due to the assumption on , the expectations of the cross-terms involving evaluate to zero. Note that items in Assumption 1 guarantee that is independent of and . Thus, the expectation can be rewritten as
By defining
and employing (20)–(22), we can modify (18) to
where and refer to the same quantities as and , respectively.
Taking the vectorization operator of both sides of (19), and using (21), (22), Assumptions 1 and 2, together with employing the relationship between the Kronecker product and the vectorization operator (For any matrices of compatible dimensions we have ) we find that the weighting vectors satisfy the following relation
where and given by
Note that the vectorization commutes through expectation. Considering Assumption 1, we can approximate as follows
To evaluate we employ a useful property from matrix algebra (which relates the vectorization operator matrix to trace operator (For real matrices , the trace of a product can be written as ) [50]) together with the fact that is symmetric and deterministic, to obtain
where
which, in the light of Assumptions 1 and 2, can be evaluated as
It follows by direct inspection that the entries of are given by
where
In the following proposition, we summarize the required conditions that guarantee the mean-square convergence for the DC-ILMS algorithm.
Proposition 2
Proof.
Let and be two arbitrary matrices of compatible dimensions. Then, any eigenvalue of is a product , where is an eigenvalue of and is an eigenvalue of [50]. Moreover, the sets of eigenvalues of and are equal. Accordingly, using the expression (26), we have that . It follows that is stable if, and only if, is stable. Therefore, that guarantee the mean stability, ensure mean-square stability as well. Thus, the result (14) follows. □
3.4. Learning Curves
In this section, the variance relation (31) is employed to obtain a recursive equation that explains the transient behavior of the CD-ILMS algorithm. Since the weighting matrices, , can be node-dependent, we can replace by , so that (31) can be rewritten in the following form
with . Observe that the expression (32) relates to (not ). To resolve this issue, the incremental topology along with the weighting matrices should be employed [19] as follows: first, by iterating (32) a set of coupled equalities are obtained
In order to explain the flow of energy through the agents it is required to make connection between the free parameters and . If we choose the weighting vector and combine (33) and (34) we get
Iterating in this manner, a recursive expression is obtained which relates to , namely
By choosing and substituting it in (36), gives the following expression that explains how MSD of node k evolves over time:
where , the product of matrices for each node, and are defined by
and
Therefore, the theoretical expression for MSD of node k is given by the compact form
where the vectors and are formulated by
Accordingly, the selection of leads to a an expression that explains how EMSE of node k evolves over time:
where the vectors and are given, respectively, by
3.5. Steady-State Behavior
The variance relation (32) can also be used to evaluate the steady-state performance of CD-ILMS algorithm. Let . At steady-state, i.e., when , the variance relation (32) can be written as
Iterating the Equation (42) for an incremental network topology and selecting appropriate weighting vectors for , we obtain an equality only involving , given by
Proper selection of the weighting vector in (44) gives the required mean-square values. Selecting the weighting vector as the solution of the linear equation or , the desired MSD and EMSE at node k can be obtained as follows:
The vector can be regarded as the effect of aggregating the transformed noise and the local data statistics from all the nodes in the incremental network topology and the matrix can be interpreted as the transition matrix for the weighting vector .
4. Further Insight into the Proposed CD-ILMS
In order to gain more insight into the performance of CD-ILMS algorithm, in this section we compare the convergence rate and computational complexity of CD-ILMS algorithm with the regular full-update ILMS algorithm [19].
4.1. Convergence Rate
To make the analysis more tractable, we consider the following assumption.
Assumption 3.
The missing probabilities , the covariance matrices , and the step-size are identical, i.e.,
It can be seen from (13) that the evolution of weight-error vector for both CD-ILMS and ILMS algorithms are controlled by the modes of the following matrices
where the subscript ‘coor’ and ‘full’ denote, respectively, the stochastic coordinate-descent and full-update incremental implementation. Thus, under Assumption 3, we have
From (51) and (52), we find that the modes of convergence are given by
where denotes the eigenvalues of . Letting and represent the largest number of time iterations that are required for the mean error vector, , to converge to zero. Then, it holds that
where in step we considered as .
Remark 2.
Expression (55) illustrates the increase in the convergence time in the CD-ILMS algorithm. Since the convergence time is longer, the CD-ILMS algorithm may need more quantities to be exchanged through the network compared to the ILMS algorithm.
4.2. Computational Complexity
We now provide a discussion on computational complexity of full-update ILMS and its coordinate-descent implementations. Let and represent the number of real additions and multiplications, respectively, that are required for every entry of the gradient vector. In CD-ILMS algorithm, every node requires real multiplication and real additions per iteration in adaptation step (10), while in the full implementation, every node requires multiplications and additions per iteration. Moreover, Let and denote the number of multiplications needed by the adaptation steps per iteration at each agent k in the CD-ILMS and full-update cases. Then,
If these algorithms require and iterations to attain their steady-state values, then the total number of real multiplications at node k, represented by and , are obtained by
so that employing (55) results in
Remark 3.
It is obvious that, and are essentially identical. This means that although the convergence of CD-ILMS algorithm to steady-state region takes longer, the overall computational complexity, i.e., savings in computation per iteration, does remain invariant. Generally speaking, in situations where the computational complexity per iteration require to be minimal, the coordinate-descent scheme is recommended. Moreover, the coordinate-descent scheme requires more iterations to achieve the same steady-state performance.
Remark 4
(Communication Costs).In coordinate-descent incremental and regular incremental schemes, each node k receives weight estimate, , from its predecessor node in the cycle. In this manner the overall number of communications needed at each node per iteration is . Moreover, the nodes also need to send their global estimate, , thus the communications requirement per iteration per node is .
5. Simulation Results
This section provides some computer simulations to evaluate the performance of CD-ILMS algorithm and verify the theoretical analysis. We assume a distributed network composed of agents with ring topology (see Figure 2). The vector is generated randomly with and step-sizes are . To obtain more accurate results, we conducted 100 independent simulations. Although the analysis depends on the independence assumptions, all simulations are accomplished by regressors with shift structure to deal with realistic scenarios. To this end, the regressors are generated by the following first-order auto-regressive model
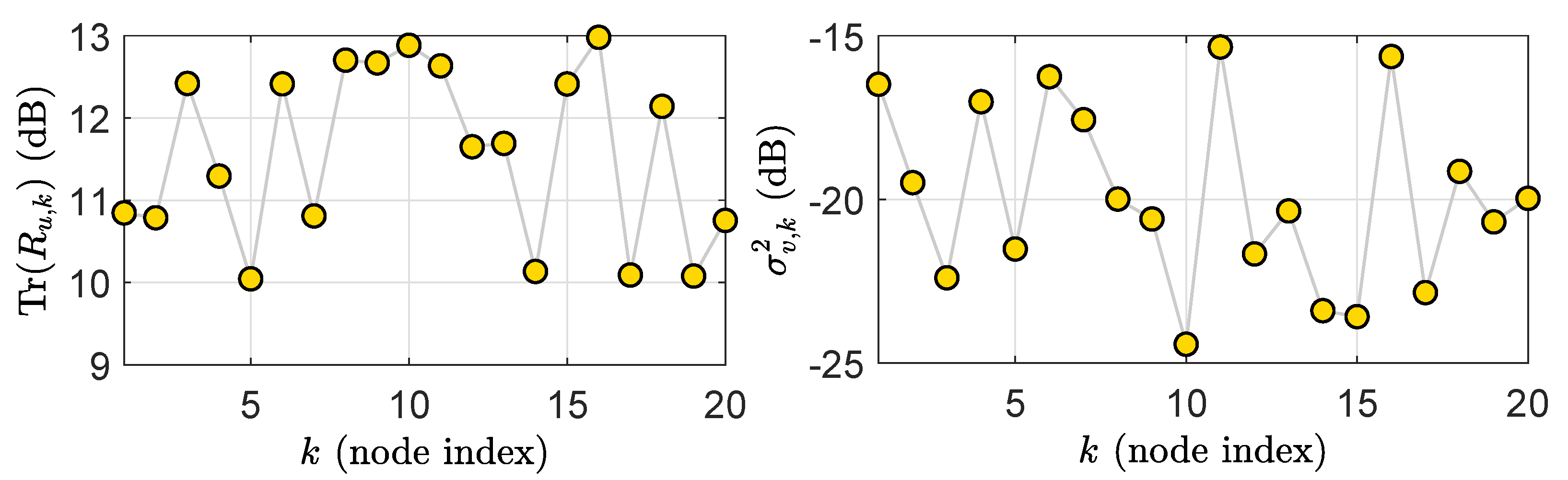
where the parameters and denotes a are zero-mean, unit-variance Gaussian sequences. For each node, the measurement noise is a zero mean white Gaussian sequence with . Figure 3 illustrates the network statistical settings.
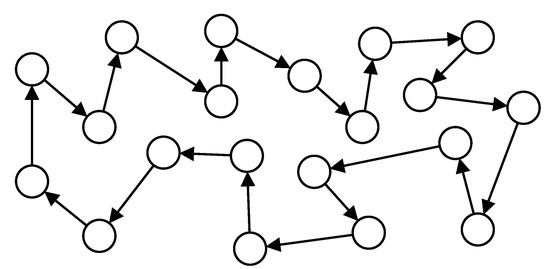
Figure 2.
Network topology consisting of agents with ring topology.
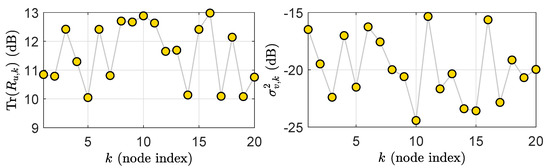
Figure 3.
The network statistical settings: regressor power profile (Left) and observation noise power profile (Right).
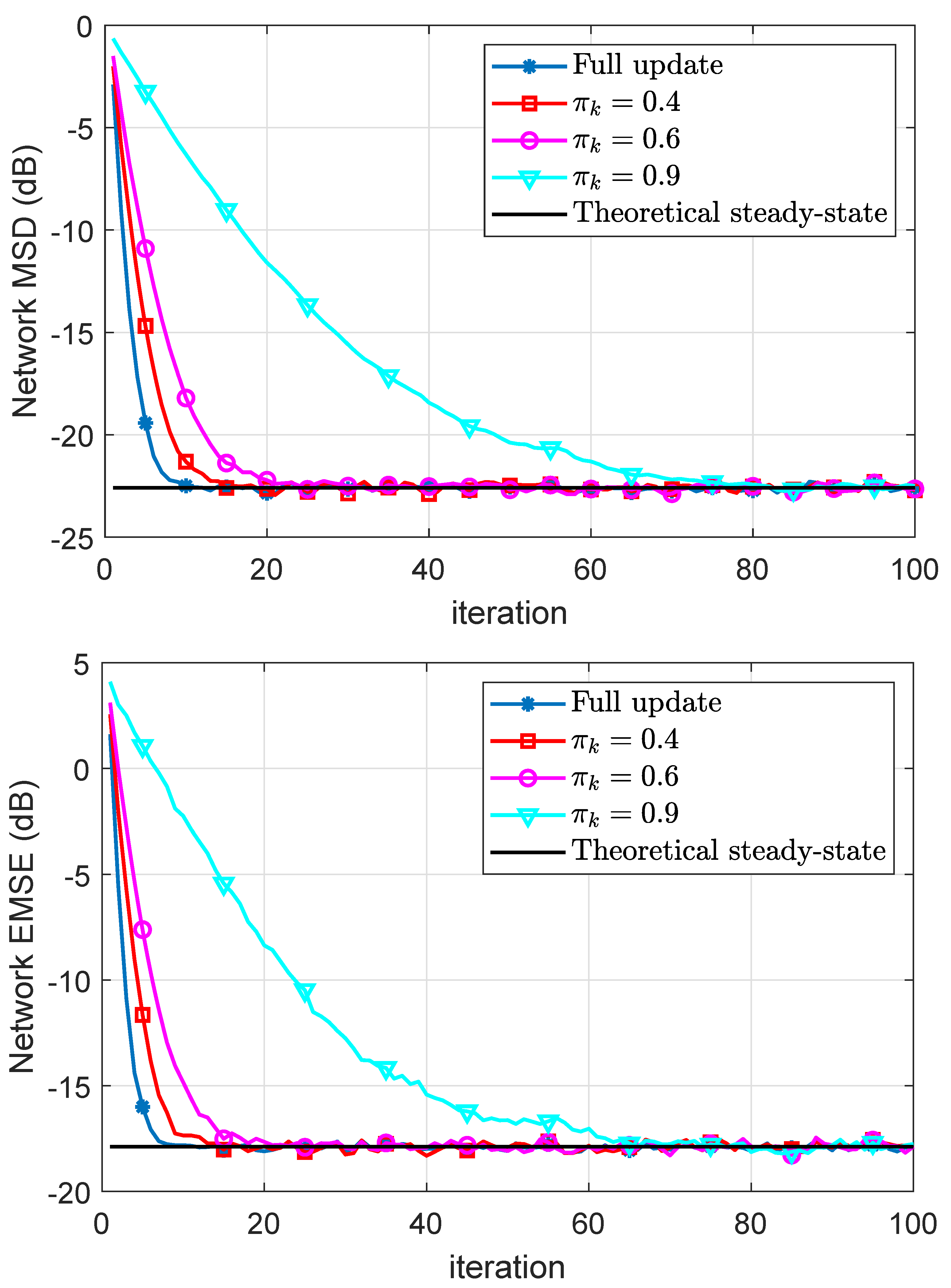
In Figure 4, we plot the experimental and theoretical MSD and EMSE learning curves using both full and partial updates for different values of . It can be observed that the CDILS algorithm has the same steady-state error performance compared with the ILMS algorithm. Moreover, as we expected, as the performance of the coordinate-descent approaches to that of the full-gradient incremental algorithm. Generally speaking, the speed of convergence reduces proportionally for coordinate-descent schemes as the missing probability is decreased.
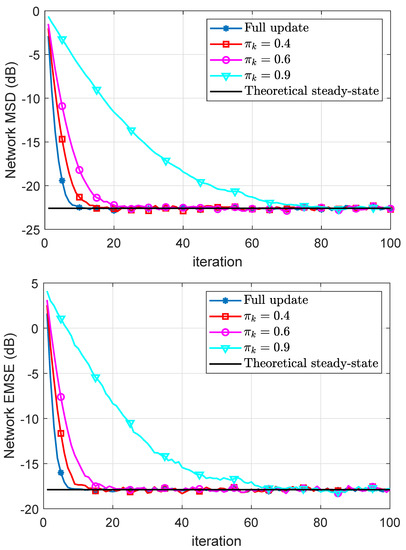
Figure 4.
Simulated network MSD and EMSE curves and their theoretical results.
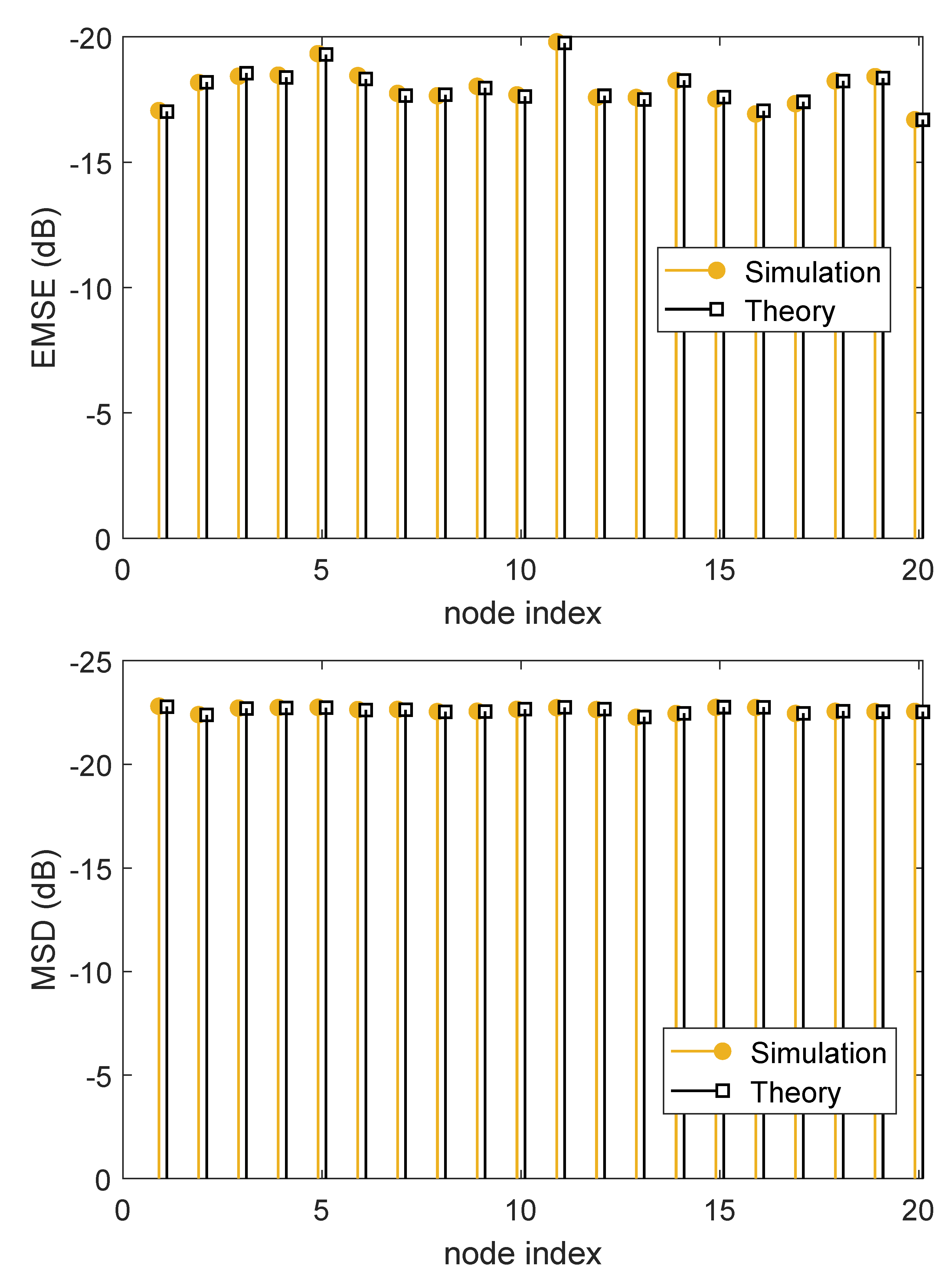
In Figure 5, we demonstrate the experimental and theoretical steady-state MSDs and EMSEs for . It can be seen that, the calculated steady-state MSD and EMSE values using the theoretical expressions in (47) and (48) have a good agreement between with those obtained by the simulation results.
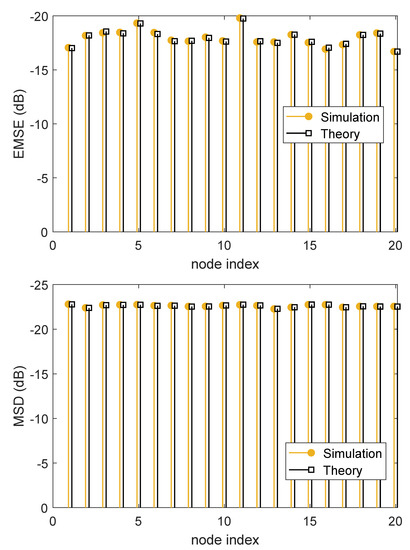
Figure 5.
Theoretical and experimental steady-state MSD and EMSE at each node.
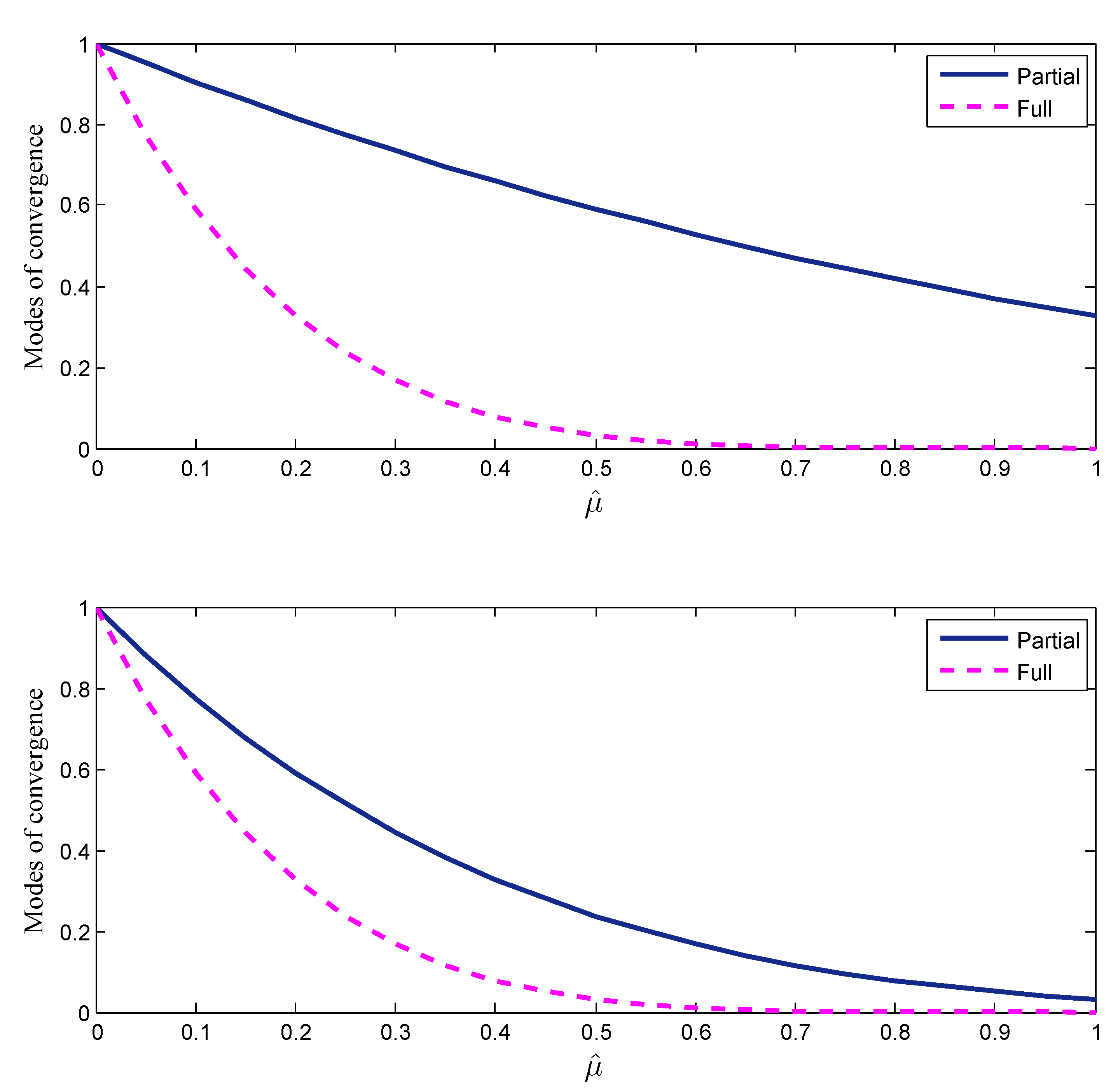
Figure 6 shows the modes of convergence for the case and , for , as a function of , both for ILMS and CD-ILMS algorithms. From Figure 6, it can be observed that, regardless of the values of step-size parameter, the full-update ILMS algorithm is always faster than the CD-ILMS algorithm.
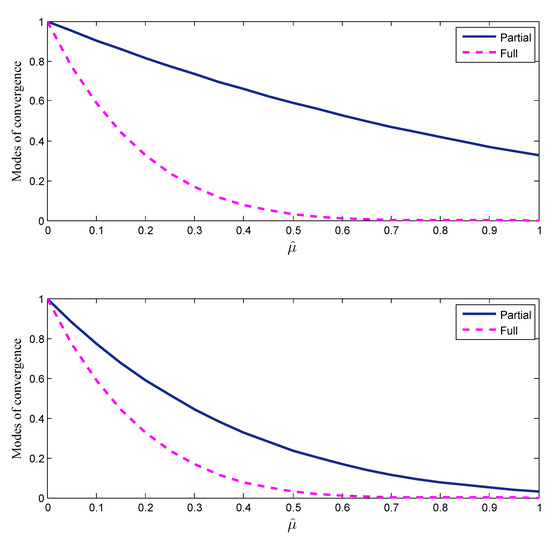
Figure 6.
Modes of mean-convergence, for ILMS and CD-ILMS algorithms using , (top) and (bottom).
6. Conclusions
In this paper, we have derived the CD-ILMS algorithm for adaptive estimation over incremental networks. Moreover, its detailed performance analysis based on the weighted energy-conservation approach under some assumptions and approximations has been discussed. More specifically, we have derived mean and mean-square stability conditions and theoretical expressions for steady-state and learning curves of MSD and EMSE. To gain further insight into the performance of CD-ILMS algorithm, its convergence and computational complexity have been compared with those of the full-update ILMS algorithm. It has been shown that the full-update ILMS algorithm and CD-ILMS algorithm provide the same steady-state performance, while full-update ILMS is always faster than the CD-ILMS algorithm. Finally, some numerical examples have been provided to support the theoretical derivations.
Author Contributions
Conceptualization, A.K., V.V. and A.R.; methodology, A.K., V.V. and A.R.; software, V.V. and A.R.; validation, A.K., V.V., A.R. and A.F.; investigation, A.K., V.V. and A.R.; resources, A.F. and K.T.T.K.; data curation, A.F. and K.T.T.K.; writing—original draft preparation, A.K., V.V. and A.R.; writing—review and editing, A.K., V.V., A.R., A.F. and K.T.T.K.; visualization, A.R.; supervision, S.S.; project administration, S.S.; All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Rossi, L.A.; Krishnamachari, B.; Kuo, C.C. Distributed parameter estimation for monitoring diffusion phenomena using physical models. In Proceedings of the 2004 First Annual IEEE Communications Society Conference on Sensor and Ad Hoc Communications and Networks, Santa Clara, CA, USA, 4–7 October 2004; pp. 460–469. [Google Scholar]
- Li, D.; Wong, K.D.; Hu, Y.H.; Sayeed, A.M. Detection, classification, and tracking of targets. IEEE Signal Process. Mag. 2002, 19, 17–29. [Google Scholar]
- Akyildiz, I.F.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. A survey on sensor networks. IEEE Commun. Mag. 2002, 40, 102–114. [Google Scholar]
- Ren, W.; Beard, R.W.; Atkins, E.M. Information consensus in multivehicle cooperative control. IEEE Control Syst. Mag. 2007, 27, 71–82. [Google Scholar]
- Zhou, K.; Roumeliotis, S.I. Multirobot active target tracking with combinations of relative observations. IEEE Trans. Robot. 2011, 27, 678–695. [Google Scholar]
- Amin, S.M.; Wollenberg, B.F. Toward a smart grid: Power delivery for the 21st century. IEEE Power Energy Mag. 2005, 3, 34–41. [Google Scholar]
- Ibars, C.; Navarro, M.; Giupponi, L. Distributed demand management in smart grid with a congestion game. In Proceedings of the 2010 First IEEE International Conference on Smart Grid Communications, Gaithersburg, MD, USA, 4–6 October 2010; pp. 495–500. [Google Scholar]
- Kim, H.; Kim, Y.J.; Yang, K.; Thottan, M. Cloud-based demand response for smart grid: Architecture and distributed algorithms. In Proceedings of the 2011 IEEE International Conference on Smart Grid Communications (SmartGridComm), Brussels, Belgium, 17–20 October 2011; pp. 398–403. [Google Scholar]
- Giannakis, G.B.; Kekatos, V.; Gatsis, N.; Kim, S.J.; Zhu, H.; Wollenberg, B.F. Monitoring and optimization for power grids: A signal processing perspective. IEEE Signal Process. Mag. 2013, 30, 107–128. [Google Scholar]
- Duchi, J.C.; Agarwal, A.; Wainwright, M.J. Dual averaging for distributed optimization: Convergence analysis and network scaling. IEEE Trans. Autom. Control 2011, 57, 592–606. [Google Scholar]
- Chen, J.; Towfic, Z.J.; Sayed, A.H. Dictionary learning over distributed models. IEEE Trans. Signal Process. 2014, 63, 1001–1016. [Google Scholar]
- Chouvardas, S.; Slavakis, K.; Kopsinis, Y.; Theodoridis, S. A sparsity promoting adaptive algorithm for distributed learning. IEEE Trans. Signal Process. 2012, 60, 5412–5425. [Google Scholar]
- Zhao, X.; Sayed, A.H. Distributed clustering and learning over networks. IEEE Trans. Signal Process. 2015, 63, 3285–3300. [Google Scholar]
- Chen, J.; Richard, C.; Sayed, A.H. Diffusion LMS over multitask networks. IEEE Trans. Signal Process. 2015, 63, 2733–2748. [Google Scholar]
- Kar, S.; Moura, J.M. Convergence rate analysis of distributed gossip (linear parameter) estimation: Fundamental limits and tradeoffs. IEEE J. Sel. Top. Signal Process. 2011, 5, 674–690. [Google Scholar]
- Barbarossa, S.; Scutari, G. Bio-inspired sensor network design. IEEE Signal Process. Mag. 2007, 24, 26–35. [Google Scholar]
- Khan, U.A.; Moura, J.M.F. Distributing the Kalman filter for large-scale systems. IEEE Trans. Signal Process. 2008, 56, 4919–4935. [Google Scholar]
- Schizas, I.D.; Mateos, G.; Giannakis, G.B. Distributed LMS for consensus-based in-network adaptive processing. IEEE Trans. Signal Process. 2009, 57, 2365–2382. [Google Scholar]
- Lopes, C.G.; Sayed, A.H. Incremental adaptive strategies over distributed networks. IEEE Trans. Signal Process. 2007, 55, 4064–4077. [Google Scholar]
- Rabbat, M.G.; Nowak, R.D. Quantized incremental algorithms for distributed optimization. IEEE J. Sel. Areas Commun. 2005, 23, 798–808. [Google Scholar]
- Li, L.; Chambers, J.A.; Lopes, C.G.; Sayed, A.H. Distributed estimation over an adaptive incremental network based on the affine projection algorithm. IEEE Trans. Signal Process. 2009, 58, 151–164. [Google Scholar]
- Cattivelli, F.S.; Sayed, A.H. Analysis of spatial and incremental LMS processing for distributed estimation. IEEE Trans. Signal Process. 2010, 59, 1465–1480. [Google Scholar]
- Khalili, A.; Tinati, M.A.; Rastegarnia, A. Steady-state analysis of incremental LMS adaptive networks with noisy links. IEEE Trans. Signal Process. 2011, 59, 2416–2421. [Google Scholar]
- Khalili, A.; Rastegarnia, A.; Sanei, S. Performance analysis of incremental LMS over flat fading channels. IEEE Trans. Control Netw. Syst. 2016, 4, 489–498. [Google Scholar]
- Sayed, A.H. Adaptive networks. Proc. IEEE 2014, 102, 460–497. [Google Scholar]
- Sayed, A.H. Adaptation, learning, and optimization over networks. Found. Trends Mach. Learn. 2014, 7, 311–801. [Google Scholar]
- Chen, J.; Sayed, A.H. Diffusion adaptation strategies for distributed optimization and learning over networks. IEEE Trans. Signal Process. 2012, 60, 4289–4305. [Google Scholar]
- Chen, J.; Sayed, A.H. On the learning behavior of adaptive networks—Part I: Transient analysis. IEEE Trans. Inf. Theory 2015, 61, 3487–3517. [Google Scholar]
- Chen, J.; Sayed, A.H. On the learning behavior of adaptive networks—Part II: Performance analysis. IEEE Trans. Inf. Theory 2015, 61, 3518–3548. [Google Scholar]
- Zhao, X.; Sayed, A.H. Asynchronous adaptation and learning over networks—Part I: Modeling and stability analysis. IEEE Trans. Signal Process. 2014, 63, 811–826. [Google Scholar]
- Zhao, X.; Sayed, A.H. Asynchronous adaptation and learning over networks—Part II: Performance analysis. IEEE Trans. Signal Process. 2014, 63, 827–842. [Google Scholar]
- Zhao, X.; Sayed, A.H. Asynchronous adaptation and learning over networks—Part III: Comparison analysis. IEEE Trans. Signal Process. 2014, 63, 843–858. [Google Scholar]
- Arablouei, R.; Dogancay, K.; Werner, S.; Huang, Y.F. Adaptive distributed estimation based on recursive least-squares and partial diffusion. IEEE Trans. Signal Process. 2014, 62, 3510–3522. [Google Scholar]
- Arablouei, R.; Werner, S.; Huang, Y.F.; Dogancay, K. Distributed least mean-square estimation with partial diffusion. IEEE Trans. Signal Process. 2014, 62, 472–484. [Google Scholar]
- Vahidpour, V.; Rastegarnia, A.; Khalili, A.; Bazzi, W.M.; Sanei, S. Analysis of partial diffusion LMS for adaptive estimation over networks with noisy links. IEEE Trans. Netw. Sci. Eng. 2018, 5, 101–112. [Google Scholar]
- Vahidpour, V.; Rastegarnia, A.; Khalili, A.; Sanei, S. Analysis of partial diffusion recursive least squares adaptation over noisy links. IET Signal Process. 2017, 11, 749–757. [Google Scholar]
- Vahidpour, V.; Rastegarnia, A.; Khalili, A.; Sanei, S. Partial Diffusion Kalman Filtering for Distributed State Estimation in Multiagent Networks. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3839–3846. [Google Scholar]
- Vahidpour, V.; Rastegarnia, A.; Latifi, M.; Khalili, A.; Sanei, S. Performance Analysis of Distributed Kalman Filtering with Partial Diffusion Over Noisy Network. IEEE Trans. Aerosp. Netw. Electron. Syst. 2019, 56, 1767–1782. [Google Scholar]
- Gholami, M.R.; Ström, E.G.; Sayed, A.H. Diffusion estimation over cooperative networks with missing data. In Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; pp. 411–414. [Google Scholar]
- Douglas, S.C. Adaptive filters employing partial updates. IEEE Trans. Circuits Syst. II Analog. Digit. Signal Process. 1997, 44, 209–216. [Google Scholar]
- Godavarti, M.; Hero, A.O. Partial update LMS algorithms. IEEE Trans. Signal Process. 2005, 53, 2382–2399. [Google Scholar]
- Werner, S.; Mohammed, M.; Huang, Y.F.; Koivunen, V. Decentralized set-membership adaptive estimation for clustered sensor networks. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 31 March–4 April 2008; pp. 3573–3576. [Google Scholar]
- Werner, S.; Huang, Y.F. Time-and coefficient-selective diffusion strategies for distributed parameter estimation. In Proceedings of the 2010 Conference Record of the Forty Fourth Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 7–10 November 2010; pp. 696–697. [Google Scholar]
- Chouvardas, S.; Slavakis, K.; Theodoridis, S. Trading off complexity with communication costs in distributed adaptive learning via Krylov subspaces for dimensionality reduction. IEEE J. Sel. Top. Signal Process. 2013, 7, 257–273. [Google Scholar]
- Theodoridis, S.; Slavakis, K.; Yamada, I. Adaptive learning in a world of projections. IEEE Signal Process. Mag. 2010, 28, 97–123. [Google Scholar]
- Gharehshiran, O.N.; Krishnamurthy, V.; Yin, G. Distributed energy-aware diffusion least mean squares: Game-theoretic learning. IEEE J. Sel. Top. Signal Process. 2013, 7, 821–836. [Google Scholar]
- Vahidpour, V.; Rastegarnia, A.; Khalili, A.; Bazzi, W.M.; Sanei, S. Variants of Partial Update Augmented CLMS Algorithm and Their Performance Analysis. arXiv 2019, arXiv:2001.08981. [Google Scholar]
- Wang, C.; Zhang, Y.; Ying, B.; Sayed, A.H. Coordinate-descent diffusion learning by networked agents. IEEE Trans. Signal Process. 2017, 66, 352–367. [Google Scholar]
- Horn, R.A.; Johnson, C.R. Matrix Analysis; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Abadir, K.M.; Magnus, J.R. Matrix Algebra; Cambridge University Press: Cambridge, UK, 2005; Volume 1. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).