1. Introduction
In the complicated and volatile ocean, underwater acoustic target recognition is considered as the most challenging task, and the objective conditions of the marine environment seriously interfere with the recognition accuracy, which mainly includes transmission attenuation, multi-path effects, and ocean environmental noise. Underwater signals contain various forms, such as ships, marine organisms, oceanic turbulence and internal waves, etc. The instruments detect very faint sound waves, and there are various target acoustic features in the collected signals that are quite similar to the auditory system of humans used to recognize different spectrogram characteristics. In external circumstances, objective factors dramatically affect the ability to audibly interpret the signals, and it is difficult to precisely classify acoustic signals even by well-trained people.
In underwater sound signal identification, one of the most valuable subject areas is ship-type recognition. Signal classification technologies based on ship features have been gaining significantly increased interest over the years, resulting in a demand for an increase in complexity and precision of the corresponding state-of-the-art algorithms. There are various factors that present a significant obstacle to underwater acoustic signal recognition. The vast majority of methods include two steps: characteristic extraction and a recognition algorithm. There are many types of extraction method, such as the short Fourier transform (STFT) [
1], low frequency analysis and recording (LOFAR) [
2], Mel-frequency cepstral coefficient (MFCC) [
3], and the detection of envelope modulation on noise (DEMON) [
4].
The extracted characteristic programs that reflect underwater acoustic signals can be improved to some extent, and the losses of raw data are unavoidable in the processing, which leads to high computational complexity. The classifier techniques need to correspond with signal characteristic dimensions and spectrum features, which create difficulties for the designed algorithm. The characteristic selecting modes more or less result in the missing details of the raw signal; this determines how effective underwater acoustic identification algorithms will be for particular sound data. The recognition classifiers span traditional machine learning [
5,
6,
7], the statistic approximation method [
8], and matched field [
9], which depend on critical prior knowledge and professional feature design, resulting in a dilemma in higher classification precision and greater operational efficiency.
Remarkable achievements have been obtained in the deep learning field, such as image vision, natural language processing, and voice identification [
10,
11,
12]. DLNs have a distinct advantage in the classification and identification tasks, which benefits from the multilayer network architecture’s ability to extract nonlinear features. Signal recognition algorithms based on DLN have made considerable progress. There are more and more deep learning methods used in underwater acoustic signal recognition. The deep neural network (DNN) uses modified time–frequency characteristics as input, which more clearly expresses the outstanding center feature of ship samples. There are impressive classification results in the ship signal dataset, and it is due to the fact that the identification anchors based on the objective function are gained in the space distance [
13]. The two dimensions of a convolutional neural network (CNN) excavates the ship signal characteristics in the spatial-temporal spectrum domain, which can weaken spectral fluctuation and prevent local minima [
14]. An end-to-end learning network, called the auditory perception inspired deep CNN (ADCNN), is an efficient network architecture in signal feature extraction, and the method transform signals from the temporal domain to the frequency domain. The deep representation of raw signal can be separated; this method achieves satisfactory performances in underwater acoustic target classification [
15]. The original signal data are input into the depthwise separable CNN (DSCNN) in the temporal domain. The desired identification effects suggest that the model inherits from the function of intra-class concentration, which isolates inter-class characteristics at the same time [
16]. The deep-belief network utilizes the pre-processing approach of standard Boltzmann machine, the hidden middle layer of the clustering method, and the training optimization of parameter updating [
17]. The underwater acoustic signal classifier adopts the convolutional recurrent neural network (CRNN), and the recurrent neural network (RNN), combined with a CNN, to acquire the different natures of sound characteristics, which further enhances the recognition effects by data augmentation [
18].
Currently, CNN and RNN are only employed with a direct hierarchical overlay or a simple combined connection between them, which has not been optimized in terms of the network structure design. The underwater acoustic signals are seriously affected by the harsh underwater environment; therefore, it is important to mitigate these factors in the deep network design. The contributions of this paper are as follows:
The hybrid routing network structure invests a simplistic format for the complex routing logic network. After several network units are overlaid structurally, the used network can generate multiple routing modes, which enhances the performance of extracted signal features.
The network unit is arranged by the different branches. When the main branch remains unchanged, the auxiliary branch adopts three optional orientations, and the classification ability of the used network is furthered by exchanging advanced signal features in different branches. It enriches the extraction categories of signal features.
The hybrid routing network was tested on real underwater ship signals. In the experiment, various multi-routing units were confirmed to illustrate the effectiveness of the used network, and there is also a comparative display of the different routing modes and the selection of auxiliary branches.
The remainder of this paper is organized as described below. The signal model is given in
Section 2 along with the basic network structure.
Section 3 explains the hybrid routing network structure form, and illustrates the multiple routing form and the optional auxiliary branches.
Section 4 introduces the ship signal dataset, and the classification performance of the hybrid routing network provides experimental verification. Finally,
Section 5 provides a summary of the paper.
3. Hybrid Routing Network Architecture
For gaining abundant classification features, the most general style of multi-route sparse network architecture is the intricate structure of the sparse fragmented network, which can extract the diversiform signal data; it is a valid model to improve the classification performance, whereas the sparse fragmented architecture has a poor adaptability to the signal dataset, especially in the various number of signals. Specifically, to benefit from the architecture, the new network is created, and named as the hybrid routing network—it further strengthens the ability to acquire the deep relating information of signals, and is a suitable method to handle the various input signal data.
The basic composition of the hybrid routing network is shown in
Figure 5. The hybrid routing network can achieve the effect of the sparse fragmented network to extract a variety of signal features, and it is dissimilar to the sparse fragmented network to reduce the training parallelism degree, such as ResNeXT [
23] and Nasnet automatically generated by AutoML [
24]. The sparse fragmented network tends to adopt the complex structure, where there are multifarious small convolutions and pooling operations in the layer structure, which leads to the complexity of the network structure, reduces the efficiency of the model, and slows down the training speed. The hybrid routing network can solve these problems by keeping the unchanged structure in the branches. In order to realize the capacity and efficiency of the ideal model, the key is how to maintain a large number of branches with the same width. In this manner, there are neither dense convolutions nor too many Add operations.
The input layer is fed by the original signal data. The gate recurrent unit (GRU), two-dimensional convolution (Conv_1), and MaxPooling pre-process the signal data. There are 512 cells in GRU, and the convolution kernels are
in other two pre-processing layers. The overall network structure is constructed by superimposing the multi-routing units (red solid wireframe). At the beginning of each unit, the network input is divided into different branches. The main branch
consists of seven basic layers, including group convolution (GConv) with the convolution kernel of
, three dropouts, ReLU activation function (ReLU), depthwise convolution (DepthConv_1) with the convolution kernel of
, two-dimensional convolution (Conv_2) with the convolution kernel of
. The three branches that can be selected on the auxiliary path correspond to
,
,
, respectively (red dotted wire frame). The auxiliary branch
consists of five basic layers, including DepthConv_2 that has the
convolution kernel, two dropouts, Conv_2, and ReLU. The auxiliary branch
includes the average pooling (AveragePooling), and the auxiliary branch
is a directly connecting link. The track restructure (TrackRestr) is the feature exchange operation between the different branches, and the concatenate layer (Concat) splices the extracting data from the different branches for continuing to learn in the next network unit. The structure is realized through the superposition of the multi-routing units. The corresponding formula is as follows:
where
j represents the superimposed units,
, and
J represents the maximum number of superimposed units.
represents the main branch,
represents a selection function to the auxiliary branch,
u represents the alternative mode of different auxiliary branches,
, and
U represents the total number of auxiliary branches. The
j layer can choose any optional auxiliary branch required from 1 to
U.
represents the final network structure.
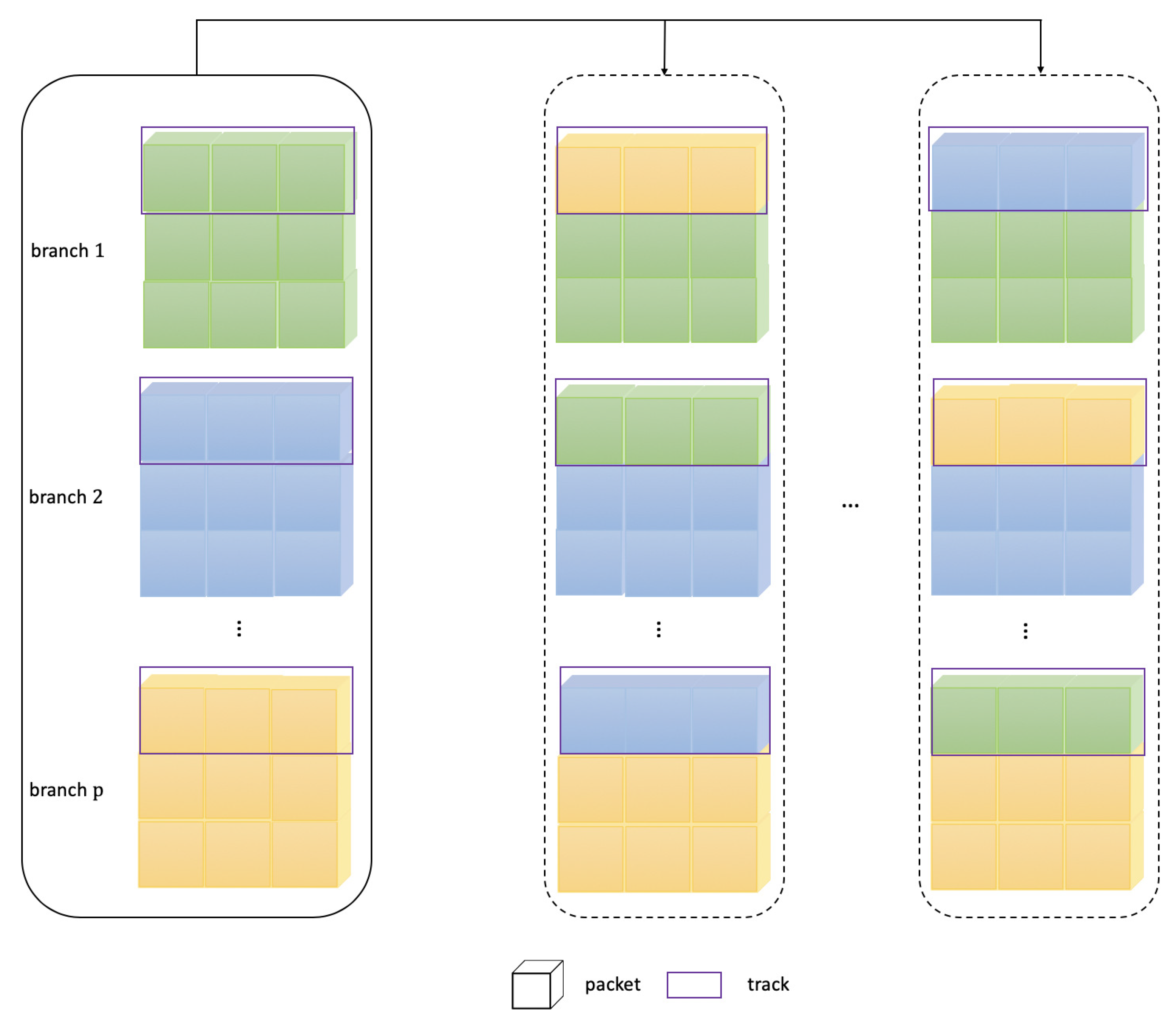
The different branches exchange the signal features are shown in
Figure 6. Branches (black solid wire frame) represent the multi-routing path from 1 to
pth. Packets are the signal features, and tracks (purple solid wire frame) are the selected range for the features exchange of each branch at a certain percentage. It is provided to the next unit for further learning by rotating and changing a certain proportion of features between different branches, which can avoid the limitations of different branches to pledge the rich signal features. The general convolution operates on all input feature maps, which is the full-track convolution. It is the track dense connection, which means that the convolution is performed on all tracks. In fact, the
convolution in ResNeXt basically takes up more than 90% of the multiply-add operations. Xception [
25], MobileNet [
26] also use a similar convolution; these algorithms also adopt DepthConv, which is actually a special convolution. Some packets make up a track, and each packet has only one feature map. The DepthConv amounts to adding a barrier to remove unnecessary data, thus reducing the computation amount. The disadvantages brought by the sparse fragmented network are solved by restructuring the convolution tracks, and it means that the hybrid routing network is a track sparse connection. When the GConv layer is stacked, the next problem is that the feature maps between different branches do not communicate, which is similar to dividing mutually irrelevant branches. The extracted features go their own way, and will reduce the feature extraction capability of the network.
The information contained different branches may be similar in the same packet. If there is no track exchange, the learned features will be very limited. If some tracks are exchanged after different branches, and the learned information can also be exchanged. Each packet has more information and more features can be extracted. To achieve the features of all other packets in each branch, the form is conducive to better results. For this reason, Xception and MobileNet are equipped with the serried
convolution, which ensures the information exchange between diverse packets of feature maps after the convolution operation, referred to as the restructuring conversion. The solution guarantees that the next convolution input comes from diverse packets so that the information can be transferred between diverse packets. Normally, the restructuring conversion is not random, but evenly disrupted, which is more beneficial for the sharing of the learned feature between the distinct manifestation of tracks; this only requires the simple dimension transformation and transposition to achieve an even restructure, which is simple and easy to operate. The two-dimensional feature matrix corresponding to each branch is
,
, ⋯,
, and the selected feature range percentage is
. The features involved in the exchange are
after the first network unit learns, the proportionally selected initial matrix is
the rotating and changing operation from 1 to
th is
to complete the exchanging operation, these features are connected into the feature sequence of the first multi-routing unit by Concat, which can be transmitted to the next multi-routing unit for further learning. When the above stage is completed, the global map pooling (GlobalMapPooling) is intended to reduce the feature map size to
, and finally the fully connected layer (Dense) outputs the ship type predictions.
4. Experiment
4.1. Training Setting and Ship Signal Dataset
The training setting of the used network is a batch size of 128; the optimizer selects the stochastic gradient descent (SGD) with momentum = 0.9, decay = , and learning rate = 0.05. To elevate the extension ability of the trained network, the early stopping technique uses a patience of 5.
In real shallow sea water, various forms of ships generate the signal dataset. Human disturbance and underwater environmental impacts are contained in the target signal dataset. The ship acoustic data are collected by an hydrophone, which was laid under water at 144 m. The approximate distances range from 50 m to 150 m, and the signal sampling frequency is 32 kHz. The classes of signal recordings are well annotated, which are conveniently applied to automatic identification algorithms. There are approximately 90 samples in each ship target signal type, which range from 9∼682 s in sample duration.
4.2. Classification Performance
Figure 7 shows the classification performance with different routing forms. There are the superposition of three units in the network structure.
represents the method of the auxiliary selection corresponding to the intermediate overlay units. Other forms of
have similar meanings, and
X is the different choice of
,
, or
.
is the percentage of the selected packet range as a track for the exchange between auxiliary branches. In the 12 different hybrid routing forms, 12 ship types can be effectively identified. When
is
, there are similar classification results in the different routing forms. With the increase in
, the classification ability differs from the the selection mode of auxiliary branches. The form of
increases by approximately
,
, and
compared to the three forms of
,
, and
at
, which has a distinct advantage over other routing forms. The presence of different routing forms turns out to be the sheep herd performance.
slightly improves
,
, and
than the other three routing forms of
,
, and
at
.
is better around
,
than compared to
,
, which performed better at
,
of the other three routing forms on average. When the sufficient exchange of the signal data are provided to the used network, more high dimensional signal features are extracted, which helps to identify ship types. The further addition of routing branches did not improve classification accuracy due to the fact that the hybrid routing network can more effectively extract the signal features by the full exchange of tracks, and the advantageous classification effect can be achieved under the
form; this explains the fact that the hybrid routing network is an efficient method for ship-type classification.
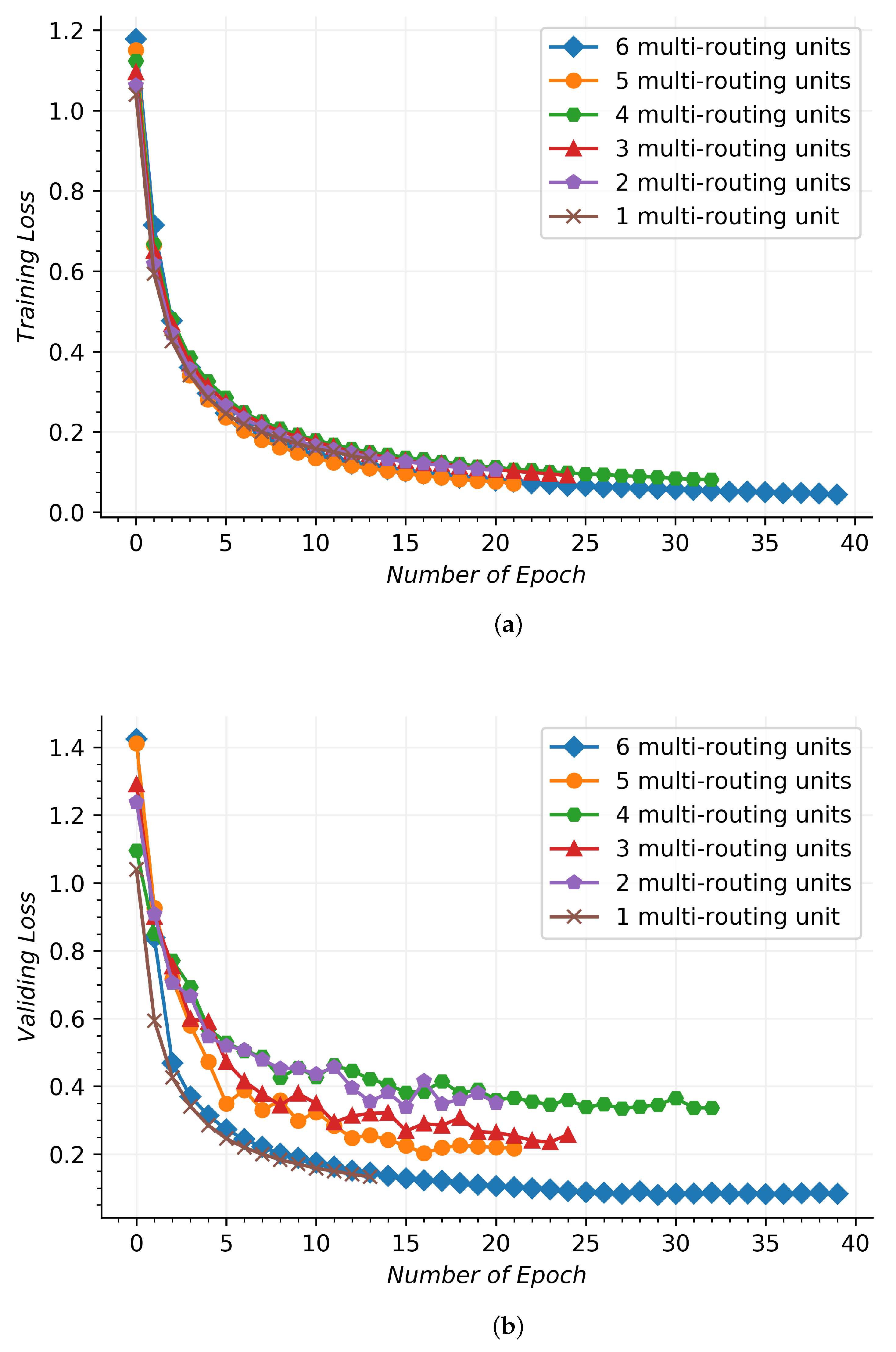
Figure 8 shows the convergence performance for the used network during the training and validating process, which involves different multi-routing units. In
Figure 8a, the training signal dataset send data across the used network to obtain the training losses by the categorical cross-entropy. In
Figure 8b, the validating signal dataset verify the trained network to obtain the validating losses, and the validating results are obtained by the same loss function, such as the training losses. In horizontal axis, the number of epoch is the learning number of the training process, which represents a whole training or validating dataset that moves through the network and returns once. At the beginning, the six kinds of the used network structures show a rapid convergence in the iterative procedure of the top five. When the multi-routing unit is six, the training loss obtains the best results, which has a longer epoch number. There is a similar convergence performance for the other five, which is higher than the multi-routing unit of six by an average of more than 0.004. As the multi-routing unit number increases, the epoch number displays a declining trend.
The validing loss of four multi-routing units is larger than that of two multi-routing units and three multi-routing units, and it is due to the fact that the validing dataset is under-fitted. Although the epochs of four multi-routing units are larger than the previously mentioned units, they cannot learn more hidden signal distinguishing features, resulting in larger validating losses. With the increase in multi-routing units, the ability to obtain signal hidden features is further improved, which can effectively reduce validing losses and achieve better classification results. Six multi-routing units and one multi-routing unit are partially coincident in the initial validing process. One multi-routing unit has a small number of layers, and it is impossible to obtain deeper signal classification information, which stops learning after 13 epoches. Six multi-routing units can dig out the deep distinguishing features of signals, and more epoches can effectively improve the classification effect. The training process with six multi-routing units and one multi-routing unit are partially coincident in the initial validating process. One multi-routing unit has a small number of layers, and it is impossible to obtain deeper signal classification information, which stops learning after 13 epochs. Six multi-routing units can dig out the deep distinguishing features of signals, and more epochs can effectively improve the classification effect, which shows that the used network can work effectively to learn the signal data features. The validating process is compared with the training process, and there is an approximate convergence tendency. The validating process is not the smooth course similar to the training process, and it is due to the fact that the probability distribution of the validating dataset is not entirely consistent with those of the training dataset, which can productively fulfill the validation of the trained network. In the validating process, the epoch number is also decreasing as the amount of multi-routing units increases, which is similar to the training process. It shows that the used network can effectively handle the ship acoustic signals by various multi-routing units.
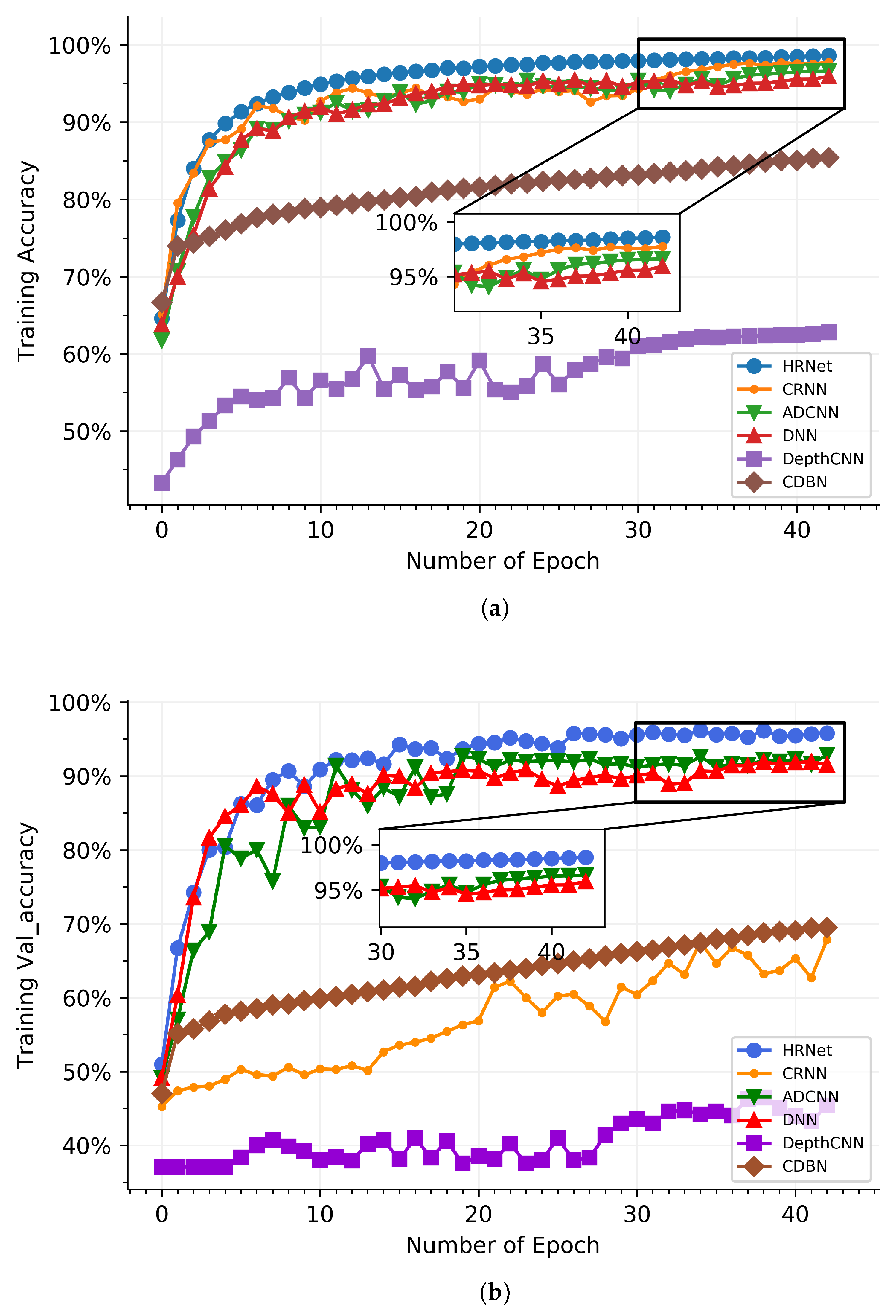
In
Figure 9, the used network is compared with DNN [
13], ADCNN [
15], DepthCNN [
16], CDBN [
17], and CRNN [
18]. HRNet is the hybrid routing network method. In
Figure 9a, HRNet has the better classification result than other networks in the epoch range of 0 and 6, and the recognition performance of CRNN is close to the used network, which significantly outperforms DepthCNN and CDBN. ADCNN and DNN have almost the same classification result when compared to HRNet, and the former are 4.96% than the latter. From the sixth epoch to the thirty-second epoch, the results generated by CRNN, ADCNN, and DNN share a great deal of similarity, which are 3.18% smaller than HRNet on average. At the scope from 33 to 43, HRNet is substantially higher than other networks in the classification rate, which is around 0.98%, 2.43%, and 3.17% than CRNN, ADCNN, and DNN on average, respectively. This shows that HRNet is structurally superior and obtained a more advanced classification of signals. In the validating accuracy process, there is an impressive melioration in the classification effect of all networks in
Figure 9b. The reason for vibration is that the training dataset is not completely corresponding to the validating dataset. HRNet shows impressive performance compared to the five other networks. ADCNN and DNN show an approximate tendency toward the classification effect; they are less effective than HRNet, which is 4.46% and 3.67% better than ADCNN and DNN, respectively—this is due to the fact that the hybrid routing network structure enriches the feature extraction of signals, which gain a better performance than CRNN, ADCNN, DNN, DepthCNN, and CDBN. In the classification of 11 ship types, HRNet recognizes more than 95% in
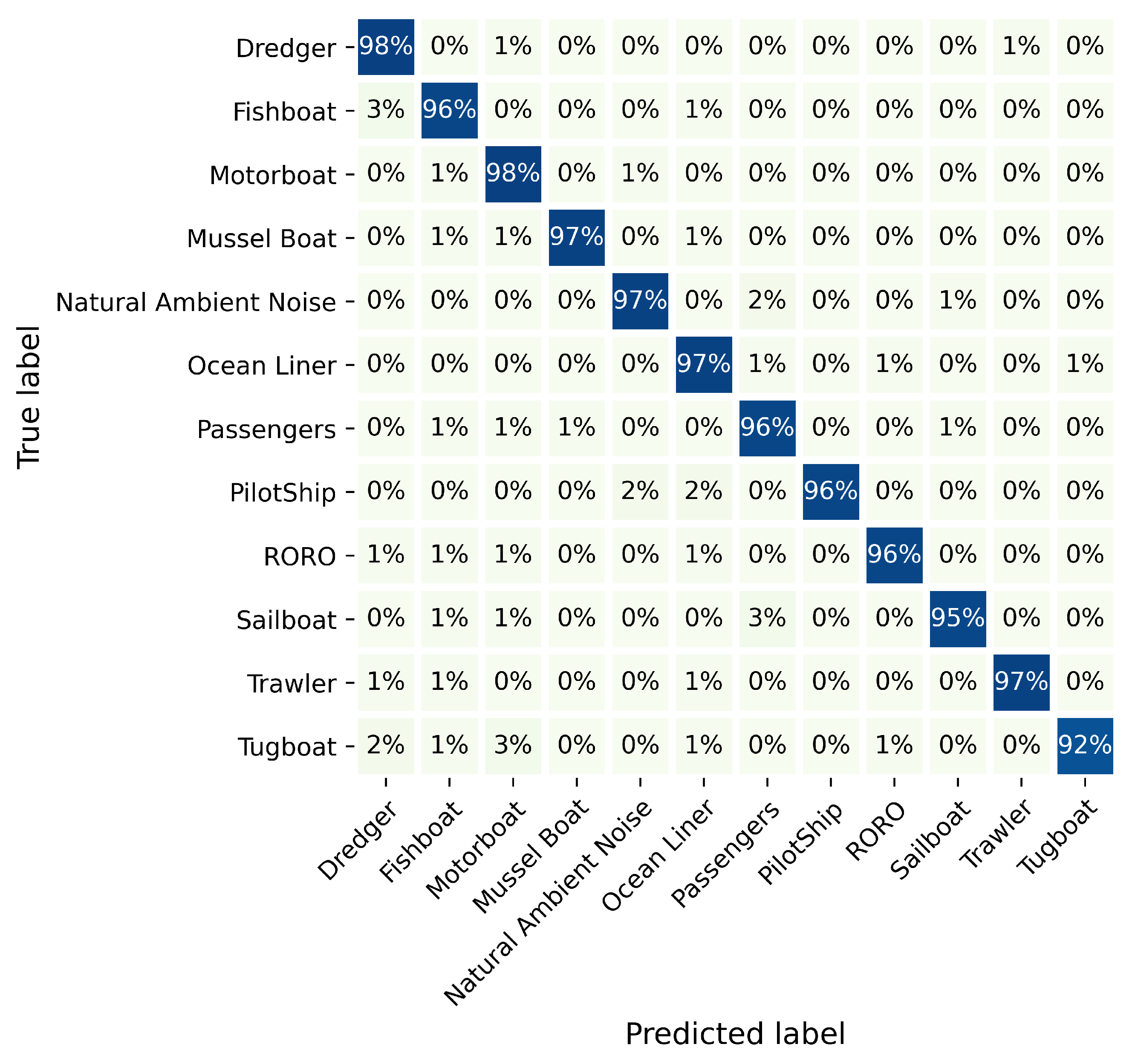
Figure 10, and the accuracy of the Tugboat can also achieve 92%, which proves the target recognition ability of HRNet.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









