1. Introduction
Global navigation satellite system (GNSS) is the most widely used navigation system. It uses satellites to broadcast positioning signals and provides positioning, navigation, and timing services for worldwide users. However, it also has some problems: (1) The signal landing power is about −130 dBm, which is easy to be interfered and spoofed. (2) The signal is easy to be blocked by obstacles, making it difficult to use in dense urban areas or indoor environments [
1]. In perspective of the above-mentioned problems of GNSS, an ever-increasing amount of researchers have begun to explore reliable positioning methods that do not rely on GNSS systems.
SOP navigation utilizes all potential wireless signals in the surroundings for positioning [
2]. SOP include various signals that are not specifically designed for navigation, such as digital audio broadcasting (DAB), digital video broadcasting (DVB), amplitude modulation radio (AM) and frequency modulation radio (FM), cellular signals, Bluetooth, ZigBee, Wi-Fi, and other wireless signals [
3]. These signals are widespread and usually used for communication rather than navigation. We can extract useful information from SOP such as signal strength, ranging and time information for navigation. Common types of SOP are demonstrated in
Table 1.
The process of SOP positioning can be roughly divided into signal perception, data preprocessing, information extraction, and positioning solution [
4]. Effectively identifying the SOP is the primary task of SOP navigation. It can be seen from the
Table 1 that there are many types of opportunistic signals, with different distribution frequency bands, bandwidths, and signal modulation methods, which brings difficulties to signal perception. The common signal perception methods include coherent detection, energy detection, cyclostationary feature detection, etc. [
5]. The schematic flow charts of three common detection methods as indicated in
Figure 1.
Matched filters are a common way for coherent detection. Its advantages are high recognition efficiency and high accuracy with a short detection time, so in a sense it might be said to be an optimal detector; the disadvantage is that the relatively high computational complexity and needs prior information about the SOP, such as modulation method, modulation order, pulse waveform, data packet format, etc. It also needs time, carrier, and even channel synchronization to enable correlation with the signal, which is complicated to implement for SOP system. For different types of signals, special receivers are required too.
Energy detection [
7,
8,
9]:
Most signals are broadcast with a fixed frequency. By detecting the energy of the specific frequency, we can judge whether the corresponding signal exists. This method is simple to implement, has strong adaptability, and does not require more prior signal information. To measure the energy of a signal at a certain frequency, the signal output by the band-pass filter with bandwidth W is squared and integrated over the observation time. Then the calculated energy value is compared with a threshold to determine the existence of signal. The energy detection algorithm has low complexity, but the threshold is easily affected by changes in noise power and becomes invalid. Meanwhile this algorithm is not suitable for direct sequence spread spectrum (DSSS) signal, frequency hopping signals, and co-band signals (e.g., Industrial Scientific Medical (ISM) band).
Cyclostationary feature detection [
10,
11]:
Communication signals usually include carrier frequencies, frequency hopping sequences, cyclic prefixes, etc., which make the signal statistical characteristics such as the mean value and correlation function periodic. However, noise does not have this characteristic, which can use to separate the noise from the target signal. This method has good detection performance even in the case of a low signal-to-noise ratio. The drawback of this method are higher complexity and longer detection time.
Over 1990s, Dr. Joseph Mitola proposed the concept of software radio [
12], which has a reconfigurable software and hardware architecture. The device’s communication frequency, transmission power, modulation method, coding system, etc. can be adjusted through software configuration, effectively improved the openness and flexibility of the communication system. With the development and maturity of software radio technology, software radio-based architecture is also used by more scholars in the field of SOP positioning [
13,
14,
15,
16,
17].
At present, the usual SOP positioning system architecture is shown in the
Figure 2. In order to complete signal perception and access, dedicated receivers need to equipped for each type of signal [
18,
19]. The equipped receiver will increase along with the types of signals, which leads to a series of problems: (1) since the lack of available signal information, all receivers need continue working to ensure the perception of all types signals, even if only no signal exist, which causes high power consumption, and hardware and energy resources waste; (2) different signals in the same frequency band (such as WiFi, ZigBee, Bluetooth, etc. in the ISM band) still need multiple devices to complete the signal perception, which does not make full utilization of hardware resources.
With this as the backdrop, this paper designs a new signal perception unit of the SOP positioning system to achieve efficient SOP perception. The relationship between the perception unit and the SOP positioning system is shown in
Figure 3. The task of SOP perception is completely performed by the perception unit. When the perception unit recognizes the existence of signal, it notifies the perception controller to flexibly configure the USRP equipment for target SOP and activity the corresponding receiver to start signal access. Otherwise, the receivers are in a standby state to decrease useless energy consumption. The flexibly configuration of USRP means each one can be used for all types of SOP, so we can develop a SOP positioning system with less USRP than fixed configuration system in
Figure 2. It improves the system integration and resource utilization efficiency. The remaining part is to completes signal capture, tracking and demodulation and produce pseudorange, carrier phase observables, time synchronization and signal strength, etc. The positioning engine calculates the positioning result according to the signal information obtained.
The advantages of the new SOP perception architecture are as follows: (1) it can monitor hundreds of MHz bandwidth at the same time, which is related to the bandwidth of the USRP device (in this article, B210 can monitor 50 M bandwidth). Combined with time-sharing frequency hopping technique, signal perception can be implemented in a wider frequency band, but it will reduce the real-time performance of perception; (2) it can identify multiple types of signals in the same frequency band at one time. A typical example of this situation is the ISM frequency band; (3) there is no need for multiple receivers, which can save hardware resources and reduce energy consumption. The new SOP perception architecture can be extended to other SOP and realize almost all frequency domain SOP perception.
In previous work [
20], we tried short-time Fourier transform (STFT) to convert signal samples into time-frequency images, speed up robust features (SURF) algorithm for feature extraction, K-means algorithm for clustering, and support vector machines (SVM) for signal classification. A simulation experiment was carried in the 2.4 GHz ISM frequency band, with Wi-Fi, Bluetooth and ZigBee as the target signals. The signal generation and perception were carried with Simulink and Matlab. The simulation experiment preliminarily verified the possibility of using time-frequency image for SOP perception. However, there are several problems in the previous work: (1) if there are multiple signals in the same time-frequency image, the result will be classified as the most likely one, and the SVM cannot identify all signal types; (2) the results are only verified by simulation, without considering the hardware implementation feasibility (which has not been actually tested).
In response to the above problems, this paper proposed an improved CNN feature extraction and classification method, built a prototype hardware system, and conducted actual experimental tests to verify the effectiveness of the designed perception architecture and algorithm. We still select Bluetooth, Wi-Fi, and ZigBee in the 2.4 GHz ISM frequency band to verify the perception ability. We also improved the time-frequency representation methods. The remaining chapters of this article are as follows:
Section 2 describes the model, including the target signal and the design of the signal perception unit.
Section 3 analyzes four signal time-frequency joint representation methods, and
Section 4 proposes a CNN-based SOP recognition method, this section also illustrate network design, negative learning-positive learning (PL-NL) combined training process and classification result.
Section 5 introduces the experimental system and experimental verification.
Section 6 summarizes the work of this paper, significance for SOP positioning system, points out the shortcomings and the direction of future work.
3. Time–Frequency Representation
Signal analysis can be carried out in the time or frequency domain by Fourier transform or inverse transform. However, the Fourier transform is a kind of overall transform, which is only suitable for stationary and deterministic signals, and cannot reflect the changes of signal frequency characteristics over time. To analyze the time-varying frequency information of a signal, time-frequency representation (TFR) is needed. TFR transforms the signal from single time/frequency domain into a time-frequency 2D feature image [
25], which reflects the time-frequency joint characteristics of the signal. A WiFi time-frequency image is shown in
Figure 10.
Since the non-parametric time-frequency analysis method does not require prior knowledge of the signal, the time and frequency resolution obtained does not depend on the specific signal, and is more suitable for the scenario of SOP perception. Commonly used non-parametric time-frequency analysis contains linear and nonlinear methods [
26,
27]. Typical linear analysis includes STFT, Continuous wavelet transform (CWT), etc., and typical nonlinear analysis includes Wigner-Ville distribution (WVD), Cohen Classes, etc.
3.1. Short-Time Fourier Transform
The basic idea of STFT is to use a window function for signal interception, and assume that the signal is stable within the window. Fourier transform is used to analyze the intercepted signal, and then move the window function along the signal time direction to obtain the time-frequency distribution relationship. The STFT of signal
x(
t) is expressed as:
where
x(
t) is the target signal and
g(
t) is the window function [
28].
In the process of STFT, the length of the window determines the time and frequency resolution of the time-frequency image. The longer the window length, the higher the frequency resolution after Fourier transform and the worse the time resolution. The length of the window needs to be adjusted according to the specific situation.
3.2. Continuous Wavelet Transform
The continuous wavelet transform of the signal
x(
t) is expressed as:
where
is the complex conjugate of
w,
w is the mother wavelet function that satisfies the admissible condition,
a is the expansion factor, and
b is the translation factor [
29]. The commonly used mother wavelet function is Morlet wavelet, and its expression is:
3.3. Wigner-Ville Distribution
The WVD is a basic non-linear analysis method, which was originally proposed by Wigner in quantum mechanics, and the Wigner-Ville distribution of signal
x(
t) is expressed as:
where
z(
t) is the analytical signal of
x(
t),
H[
x(
t)] represents the Hilbert transform of signal
x(
t), and
is the complex conjugate of
z [
30].
If
, then:
where
is the cross term of the Wigner-Ville nonlinear distribution:
3.4. Cohen Classes
The Cohen classes time-frequency analysis is a modification of the WVD, which can be expressed in a unified form:
In the formula, WVD is the Winger-Ville distribution, and
ϕ (
τ,
θ) is called the kernel function [
31].
Commonly used Cohen Classes distributions include pseudo-Wigner-Ville distribution (PWD), smoothed Wigner-Ville distribution (SWD), Born-Jordan distribution (BJD), Generalized rectangular distribution (GRD), Choi-Williams distribution (CWD), Zhao-Atlas-Marks distribution (ZAMD), etc.
3.5. Effect Analysis
We select a same segment of signal for experiment to compare the four time-frequency analysis methods, and the results are shown in the
Figure 11. The abscissa of image represents time, and the ordinate represents frequency. The lighter the color of the pixel, the higher the power. It can be seen that the time-frequency distribution of Cohen and WVD has obvious cross-term interference. Between STFT and CWT, the CWT’s signal energy more concentrated. Therefore, we select CWT for time-frequency representation in this article.
Through time-frequency joint representation, we have completed the transformation of signal information from time/frequency-domain to time-frequency joint characteristics, providing more usable information for signal perception. The next step is to send the obtained time-frequency image to the CNN for model training and signal perception.
4. CNN-Based Signal Classification Model
Machine learning is commonly used to instead artificial visual interpretation in image classification which can be roughly divided into: shallow learning and deep learning [
32]. Shallow learning includes: SVM, Boosting, Logistic Regression, etc. Deep learning includes: convolutional neural network (CNN), recurrent neural network (RNN), generative adversarial network (GAN), etc. A large number of experiments and practices have verified that the shallow learning performs poorly in processing high-dimensional data, but deep learning makes up for this shortcoming. By using multi-level non-linear processing units, it has advantages in extracting deep structural features, and is more suitable for tasks such as visual recognition [
33,
34], audio recognition [
35,
36], and natural language processing [
37,
38].
As a deep feedforward network, CNN’s core is to simulate the learning behavior of the human brain by constructing a neural network model, and optimize the parameters of the CNN model through training iterations [
39,
40]. The classic CNN models contains LeNet-5, AlexNet, ZF-Net, VGGNet, GoogLeNet, ResNet, and DenseNet.
AlexNet [
41] is a CNN framework proposed by Alex and Hinton when they participated in the 2012 ImageNet competition. They introduce the Relu activation function and Dropout to improve training speed and prevent overfitting. The advantages of AlexNet are simple calculation and fast convergence speed.
4.1. CNN Structure Design
The CNN consists of convolutional, pooling, and fully connected layers. The theoretical basis of the convolutional layer is the concept of receptive fields in biology, which can greatly reduce the parameters required for neural network training. Pooling, also known as down-sampling, is used to reduce the amount of data while retaining useful information. By superimposing the convolutional layer and the pooling layer, it forms one or more fully connected layers to achieve higher-order reasoning capabilities.
In this paper, a CNN model is designed based on the Alexnet architecture for signal classification and is streamlined to reduce the requirements for device performance. The network structure is in
Figure 12:
It contains four pairs of convolutional layers and pooling layers (C1-P1, C2-P2, C3-P3, and C4-P4), followed by two fully connected layers (FC1 and FC2) and an output layer (FC3). The main purpose of the convolutional layer is the feature abstraction and extraction, while the pooling layer is responsible for feature fusion and dimensionality reduction. The fully connected layer is responsible for logical inference, in which the first one is used to link the output of the convolutional layer, remove the spatial information (number of channels), and turn the three-dimensional matrix into vector. Each convolutional and fully connected layers’ output, except the last output layer, are connected to rectified linear unit (ReLU), which helps to alleviate the gradient disappearance or explosion, and speed up the training process.
After analysis, the color of the time-frequency image is of little significance to signal classification, meanwhile the more important things are signal pattern character and spatial distribution. Therefore, during preprocessing the time-frequency image obtained is directly transformed into a 224 × 224 grayscale image, so the input size of the network is 224 × 224 pixels. The convolution kernel size of the first convolution layer is 11 × 11 × 16, stride = 4 and padding = 2. The total parameters number of this layer is (11 × 11) × 16 = 1936, which represents the weight of the layer. The output size of each convolution kernel in the first layer is (224 − 11)/2 + 1 = 55, and the output size of the C1 is 55 × 55 × 16. The second layer is a pooling layer (P1), with a size of 3 × 3 and stride = 2. The output size of the kernel is (55 − 3/2 + 1) = 27, so the output size of this layer is 27 × 27 × 16. All parameters of the pooling layer are hyper-parameters and do not need to be learned. Similarly, we can calculate the size of each convolution and pooling layer. In the end there are 2 fully connected layers with 864 neurons in each layer, whose parameters are fully connected weight coefficients. We use the dropout layer after the fully connected layer to avoid overfitting.
Since the existence of signal is independent for each other, this is a multi-label classification problem. So, we replaced the original softmax with Sigmoid function in the last layer (FC3). The output probability of each signal is between [0, 1]. If the output is greater than the probability threshold (usually 0.5), we considered that corresponding signal exists.
4.2. Data Collection
Before the network training, a data set must be collected first for model training and training effect evaluation. This article uses hardware equipment to generate signals for testing and data acquisition. The equipment selection is as follows:
We select TP-Link mini wireless router node TL-WR802N as WiFi equipment, which main control chip is Qualcomm QCA9533. It follows IEEE802.11n standard, and runs in AP mode by default, transmission power <20 dbm. The photos of the TL-WR802N and the time-frequency image are in
Figure 13.
We select the E18-TBL-01 module produced by EBYTE as ZigBee equipment. The main control chip of the module is TI’s CC2530 chip, which integrates an enhanced 8051 CPU, follows the IEEE802.15.4 standard. Transmit power can set as 4.5/20/27 dBm. The module works in broadcast mode by default. The photos of the E18-TBL-01 and the time-frequency image are in
Figure 14.
The Bluetooth equipment uses Social Retail’s iBeacon node, and the main control chip is TI’s CC2541 Bluetooth chip. The iBeacon carries on BLE broadcasting whose frame period is 500 ms, and transmission power is 0 dBm. The photos of the Bluetooth iBeacon and the time-frequency image are in
Figure 15.
We choose a spacious environment for signal acquisition and to ensure that there was no interference signals. In order to monitor possible external interference sources at the test area (such as other Wi-Fi equipment), we used Rohde & Schwarz’s FSH8 spectrum analyzer which is shown in
Figure 16.
Figure 17 shows the spectrum analyzer detection result measured in two ways: (a) using the max hold mode to measure the maximum level within a period of time; and (b) using the clear/write mode, observe whether there is a jump on the 2.4 G spectrum. Perform interference detection before each experiment to check external interference, so as to avoid results bias.
If we acquire signal time-frequency images at the same time, the acquired image should only contain low-power noise signal and USRP device thermal noise which is shown in
Figure 18.
After confirming no external interference sources in the experimental environment, place the signal source equipment and turn on the signal acquisition system to collect time-frequency images under different signal combinations. The number of each type of node in the working state is variable, and should include all the signal combinations which is better in conformity with practical channel environment. Three types of signals can enumerate seven types of signal combination situations, as shown in
Figure 19. If the number of working signal source can change at the same time, the combination will be more complicated, so we do not list them one by one here.
We chose all situations in the
Figure 19 above as data set labels, and each label collected at least 200 pictures. In the actual acquisition process, images with weak signal characteristics or no signal at all will appear, and these poor-quality data need to be manually eliminated. Finally, we use 80% of the data set as the training set, 20% as the validation set, and collect other 20 images for each type of label as the test set.
Figure 20 shows a part of the data set.
4.3. Model Training
Sometimes the signal pattern in the time-frequency image is small and sparse, the features are not obvious. This often happens when the target signal has long broadcast cycle, weak power and small bandwidth (for example, Bluetooth). An example is shown in the
Figure 21, the white dot in the area enclosed by the yellow box in the figure are Bluetooth signal pattern.
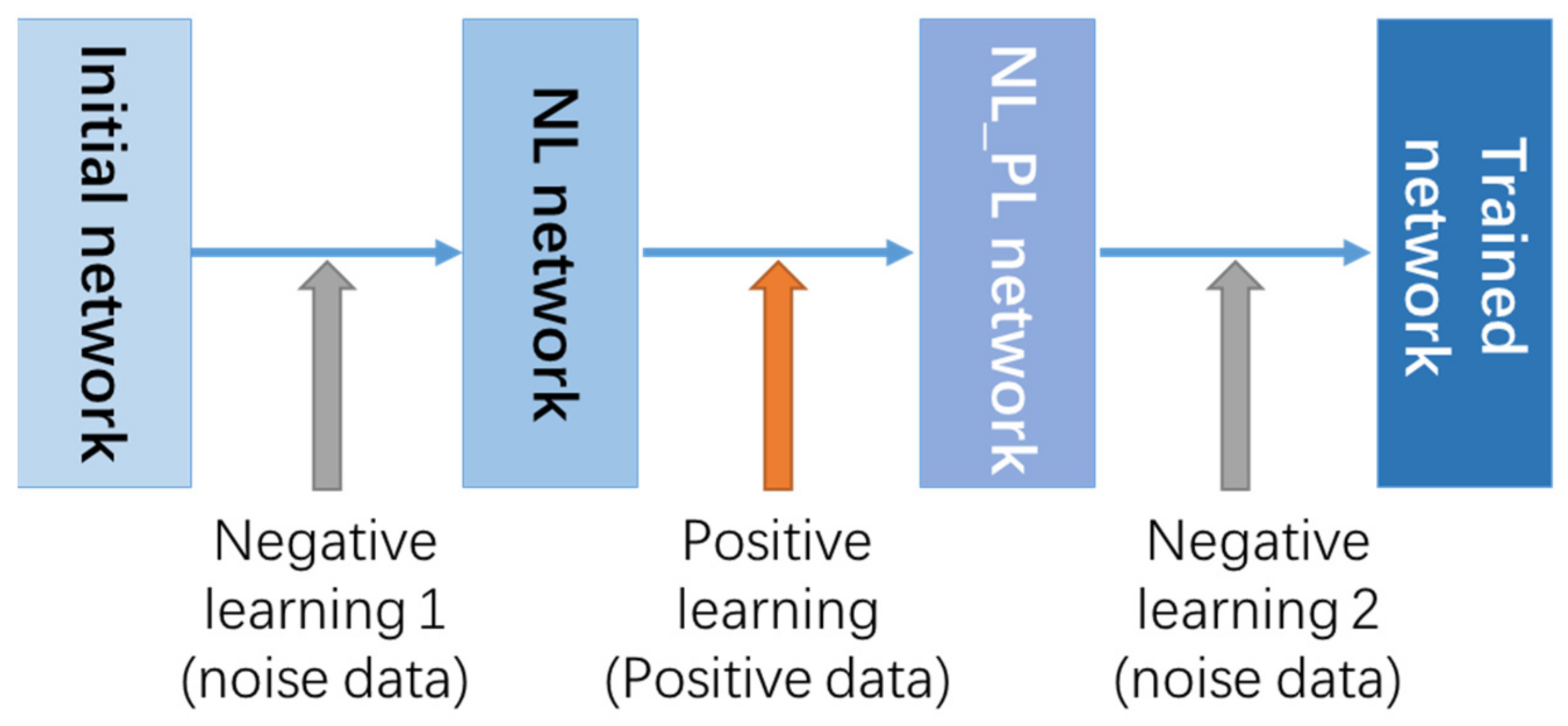
This will cause the model to learn the noise features incorrectly during the training process and cause over-fitting. So, we introduce a negative learning (NL) training method to prevent CNN from overfitting noisy data which is proved by Kim [
41]. NL method does not require any prior knowledge of noise data such as type and quantity. Different from the positive label data used in positive learning (PL) which contains the target feature information that the model focuses on, the negative label data can tell the model about the feature information of noise and interference information, which helps to distinguish the useless features. By combining PL and NL, we can improve accuracy while ensuring training speed. PL can quickly reduce the loss, but it is easy to overfit in the end. The obtained model after PL is then subjected to NL to correct the over-fitting of the noise and improve the recognition accuracy. This article uses a combination of two NL and one PL for training. The training process is shown in the
Figure 22.
In order to obtain the best classification performance, we need to adjust three hyperparameters which are the initial learning rate, the mini-batch size, and the training iterations number. We set different hyperparameter values for the three training processes, and conduct a series of training to try different parameter combinations. The final parameter values are shown in
Table 2.
4.4. Training Result
In a total of 55 iterations of training process, the loss function and training accuracy curve are shown in the
Figure 23. It can be seen that after the first 40 iterations of training, the loss function curve gradually decreased to a lower level. However, in the 41st training process, both the loss curve and the accuracy curve showed great changes which means the model has been overfitted. The second negative learning completed the correction of the over-fitting, and the loss function and accuracy curve returned to a normal level. The test results of the finally trained model on the test set are shown in the
Table 3.






































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}