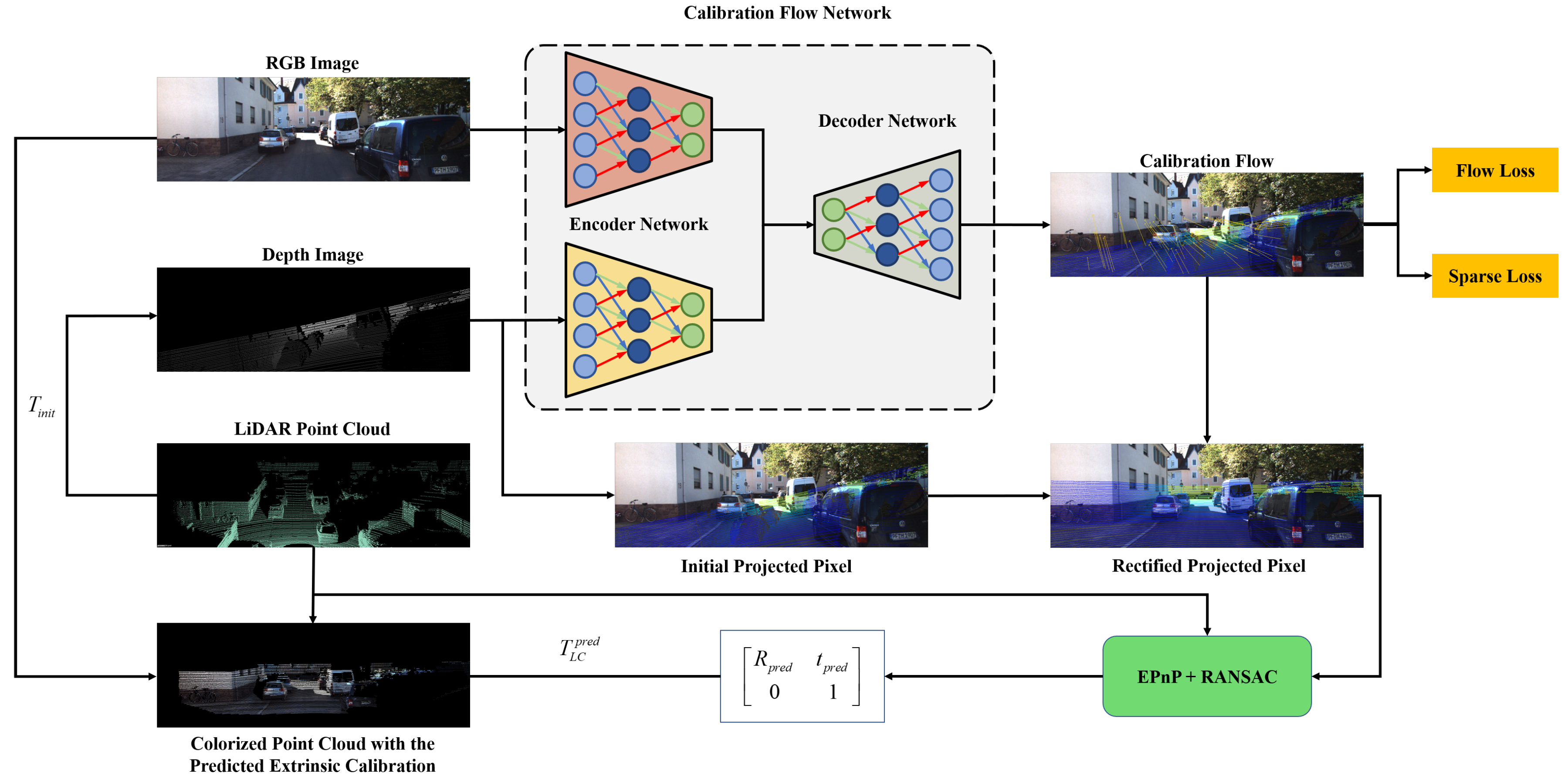
4.1. Dataset Preparation
We evaluated our approach on the KITTI benchmark datasets [
49], which include RGB images and Velodyne point cloud recordings collected from different scenes. The timestamps of the LiDAR and camera are synchronized, so the images and point clouds in each sequence are paired. We define the extrinsic parameters’ ground truth
between LiDAR and camera as the transformation matrix from the camera coordinate to the LiDAR coordinate. By adding a random variable
, we can obtain the initial calibration parameters
. The LiDAR point clouds are projected onto the image plane with
T and the camera intrinsic matrix
K to generate the mis-calibrated depth image
D. The network takes an RGB image
I and the corresponding depth image
D as input. The calibration flow ground truth can be obtained by Equation (
4).
We used the raw recordings from the KITTI dataset, specifically the left color image and Velodyne point clouds recordings. We used all drives (except 0005 and 0070 drive) in sequence
for training and validation. The initial calibration off-range
was
1.5 m,
. To compare our method with other learning-based (CNN-based) methods, we utilized the same four test datasets [
14] on the raw recordings of the KITTI dataset. Each test dataset was independent of the training dataset with the following test name configurations:
T1: 0028 drive in sequence, with initial off-range as 1.5 m, and 0.2 m, .
T2: 0005/0070 drive in sequence, with initial off-range as 0.2 m, .
T3: 0005/0070 drive in sequence, with initial off-range as 0.2 m, .
T4: 0027 drive in sequence, with initial off-range as 0.32 m, .
Due to the image dimensiosn in the KITTI benchmark dataset being different (ranging from to ), pre-processing was required to resize them to a consistent size. To fulfill the input size of the network, so that the input width and height were multiples of 32, we randomly cropped the original image to . We generated the sparse depth image by projecting the LiDAR point cloud onto the original image plane and then cropped the original RGB image and the sparse depth image simultaneously. Then the inputs of CFNet could be obtained without changing the camera data’s intrinsic parameters. Data augmentation was performed on the cropped input data. We added color augmentations with a 50 chance, where we performed random brightness, contrast, saturation, and hue shifts by sampling from uniform distributions in the ranges of for brightness, contrast, and saturation, for hue shifts.
KITTI360 datasets [
50] were utilized to test our proposed LiDAR-camera calibration algorithm CFNet as well. We fine-tuned the models trained on the raw KITTI recordings with 4000 frames from drive 0000 in
sequence of the KITTI360 datasets. Other sequences were selected as test datasets.
4.4. Results and Discussion
4.4.1. The Calibration Results with Random Initialization
The calibration results on the raw KITTI recordings are shown in
Table 3 and
Table 4. To compare the performance of CFNet with those of RegNet and CalibNet, we set two test datasets with different initial off-range as
1.5 m,
and
0.2 m,
according to the experimental settings of RegNet and CalibNet. Both of these two calibration methods adopt a similar iterative refinement algorithm to that described in
Section 3.4. As shown in
Table 3, CFNet achieved a mean translation error of 0.995 cm (X, Y, Z: 1.025, 0.919, 1.042 cm) and a mean angle error of
(roll, pitch, yaw:
,
,
) at initial off-range
1.5 m,
. It is obvious that CFNet is far superior to RegNet and CalibNet.
Figure 5 shows some examples of the CFNet predictions. It can be seen that the projected depth image generated by the predicted extrinsic calibration parameters is basically the same as the ground truth. The last row’s colorized point cloud also shows that the projected LiDAR point clouds align accurately with the RGB image. Our proposed CFNet can predict the LiDAR-camera extrinsic parameters accurately at different initial values and in different working scenes.
The comparison results from the test datasets T2, T3, and T4 shown in
Table 4 also illustrate the superiority of CFNet. Compared to the translation errors and the rotation errors utilized as the metrics in the above experiments,
error [
14] is a more direct evaluation metric. The initial off-range result of the test dataset T3 is smaller than that of the test dataset T2. The MSEE for
-RegNet and RGGNet are smaller for T3 than T2. Nevertheless, the MSEE are the same for CFNet using those two test datasets, proving that CFNet is more robust than
-RegNet and RGGNet with different off-range settings. For test dataset T4, the performance of
-RegNet degraded heavily, and RGGNet needed to re-train on an additional dataset by adding a small number of data from
sequence to achieve a good calibration result,
. CFNet did not need any additional training dataset and re-training process. The calibration results
demonstrate that CFNet generalizes well. Thus, CFNet outperforms most of the state-of-the-art learning-based calibration algorithms and even the motion-based calibration method. We can also see that compared to the motion-based algorithm [
39], our proposed method performs better, without the requirements of hand-crafted features or the extra IMU sensor.
4.4.2. Generalization Experiments
We also tested the performance of CFNet on the KITTI360 benchmark dataset. Due to the sensors’ parameters having changed, CFNet needed to be re-trained to fit the new sensor settings. We utilized 4000 frames from drive 0000 in the
sequence of the KITTI360 datasets to fine-tune the pre-trained models trained on the raw KITTI dataset. The evaluation results on the KITTI360 datasets are shown in
Table 5 and
Figure 6. Despite re-training on a tiny sub dataset with ten epochs, excellent results were obtained on the test sequences. Therefore, an excellent prediction model can be obtained with fast re-training when the sensor parameters change, such as the camera focal length and the LiDAR-camera extrinsic parameters. From
Table 5, it is easy to see that more training epochs will obtain better calibration results. However, the results obtained after training one epoch are also acceptable.
4.4.3. The Calibration Results in a Practical Application
In practical applications, the initial extrinsic parameters will not vary as widely as in the previous experiments. Thus, in this part, we validated the performance of the CFNet in practice. The initial extrinsic parameters of a well-designed sensor system are fixed values. The initial extrinsic parameters can be obtained by measurement or estimation. In this part, we took the assembly positions of each sensor in the sensor system as the initial values. The KITTI datasets and the KITTI360 datasets both provide these values, which can be used directly. In addition, estimating extrinsic parameters by a single frame will lead to outliers. Thus, we utilized multiple-image LiDAR sequences to predict extrinsic parameters of each frame. The median filtering algorithm was implemented for deleting the outliers, and the median value was regarded as the final extrinsic calibration estimation. By changing the length of sequences, we also tested the impacts of the length of sequence on estimating the extrinsic parameters and how to choose the appropriate length of sequences in practice. In the experiments, we randomly selected 20 sequences of fixed length from the test datasets, and took the assembly positions of sensors as the initial values for CFNet predicting extrinsic calibration parameters.
KITTI Odometry datasets. Each sequence in the KITTI Odometry datasets has different extrinsic calibration parameters. Therefore, we evaluated our CFNet on the KITTI Odometry datasest to test whether CFNet works with different extrinsic calibration parameters in various scenes. We selected sequences 00, 01, 08, 12, and 14 from the KITTI Odometry datasets as test data. Sequences 00 and 08 were collected in an urban area, so they include lots of buildings, pedestrians, and vehicles. Sequences 01 and 12 captured images of a highway with many vehicles moving at high speeds. For sequence 14, the data were collected in the city’s suburbs, thereby containing a large amount of vegetation and no buildings and vehicles.
The calibration results in
Table 6 illustrate that the CFNet can obtain accurate calibration results given initial parameters. The calibration errors for sequences 00 and 08 are a bit lower than those of the other three sequences. This is because most of the scenes in the training dataset belonged to the urban category, leading to a slight performance reduction in different scenes. By changing the length of sequences, we acquired a group of calibration results for analysis. In most cases, the mean translation error decreased when the length increased, and the mean rotation error had a small range of fluctuation. Although the sequence length influences the calibration results, the differences between different length settings are negligible. Therefore, a short sequence length, e.g., 10, is enough for a practical application.
Figure 7a shows visualized results from the predicted extrinsic calibration parameters in different scenes. Due to the initial values from assembly positions of sensors being close to the ground truth, the initial calibration error is small. However, CFNet still estimated the best extrinsic parameters and found correct correspondences between RGB pixels and LiDAR points. With the extrinsic calibration parameters estimated by the proposed CFNet, we constructed 3D colorized maps by fusing RGB images and exhibit them in
Figure 8a.
KITTI360 datasets. We also implement the proposed CFNet on KITTI360 datasets. All the sequences in the KITTI360 datasets have the same extrinsic calibration parameters. As shown in
Table 7, the deviation in the initial extrinsic parameters is large in the rotation part (
). Sequences 0002 and 0006 were captured in urban areas, so they include constructions, pedestrians, and vehicles. Sequence 0007, which only has high-speed moving vehicles and trees, was collected by a highway. It can be noticed that, after training a few epochs with new data, CFNet could accurately estimate extrinsic parameters for a new sensor system. Similarly to the KITTI odometry datasets, the deviations between different sequence lengths are tiny. In
Figure 7b, we exhibit some visualized examples of the calibration results predicted by CFNet. The 3D colorized fusion maps generated by predicted extrinsic calibration parameters from CFNet are shown in
Figure 8b.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}