
ARTFLOW: A Fast, Biologically Inspired Neural Network that Learns Optic Flow Templates for Self-Motion Estimation


Abstract
:1. Introduction
Learning Optic Flow Templates for Self-Motion Estimation
- Learned representations are stable and do not suffer from catastrophic forgetting.
- The learning process and predictions are explainable.
- Effective learning is possible with only a single pass through training samples (one-shot learning).
- Lifelong learning: the learning process need not occur in discrete training and prediction phases—learning may continue during operation.
2. Materials and Methods
2.1. Optic Flow Datasets
2.1.1. Dot-Defined Environments
2.1.2. Neighborhood and Warehouse Environments
2.2. Overview of ARTFLOW Neural Network
2.3. MT Preprocessing Layer
2.3.1. Optic Flow Integration
2.3.2. Net Input
2.3.3. Net Activation
2.4. Fuzzy ART Layer 1
2.5. Fuzzy ART Modules
2.5.1. Training
2.5.2. Prediction
2.6. Non-Input Fuzzy ART Layers (MSTd Layer)
2.7. Decoding Self-Motion Estimates
2.8. Training Protocol
2.9. Hierarchical Hebbian Network
2.10. Simulation Setup and Code Availability
3. Results
3.1. Learning Optic Flow Templates
3.2. Stability of Learning
3.3. Estimating Self-Motion from Optic Flow Templates
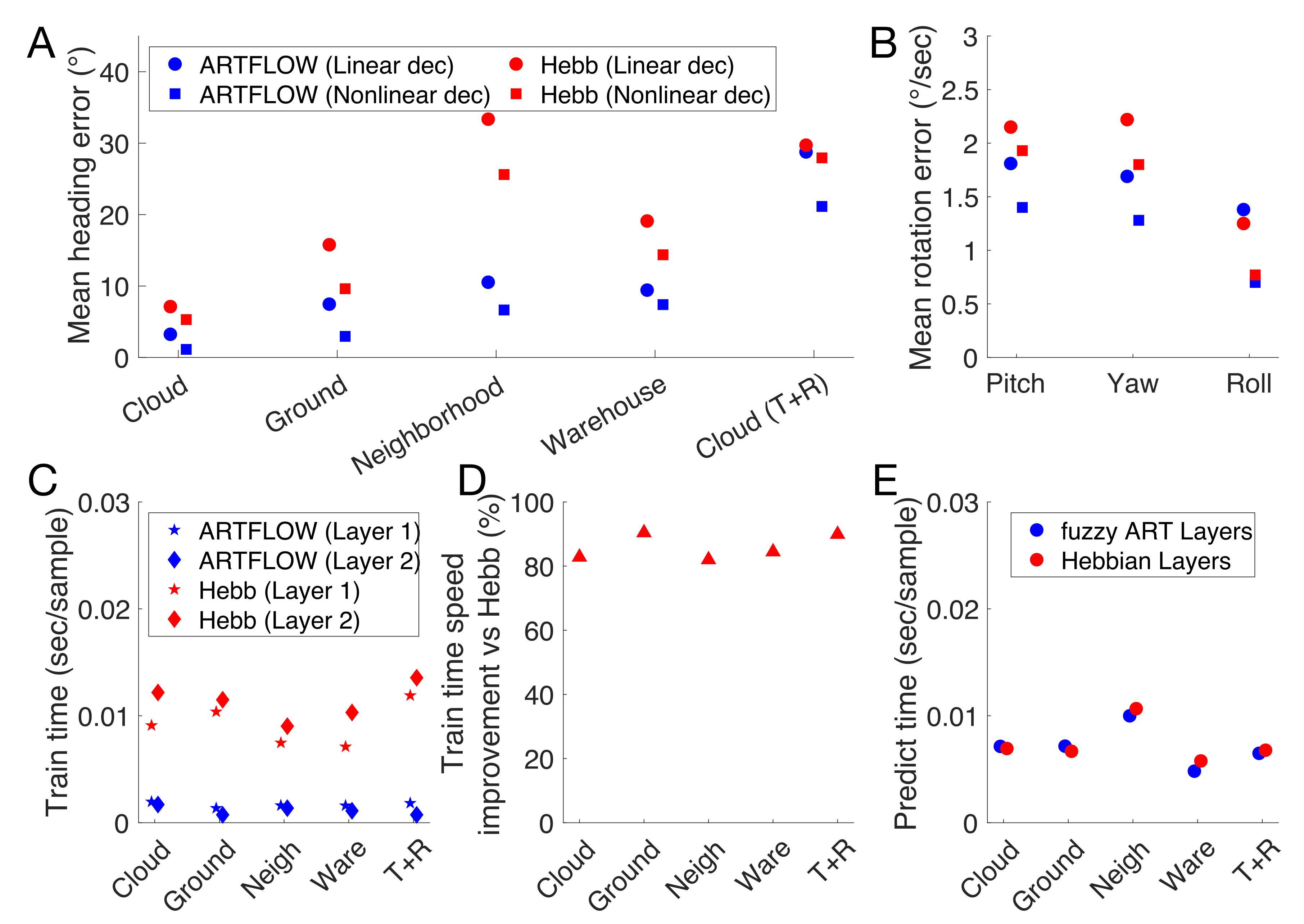
3.4. Runtime Comparison
3.5. Sensitivity Analysis to Vigilance
3.6. Generative Model of Optic Flow
4. Discussion
Comparison to Other Models
5. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| SD | standard deviation |
| T | translation |
| R | rotation |
| MSE | mean squared error |
| MAE | mean absolute error |
| MSTd | dorsal medial superior temporal area |
| MT | medial temporal area |
| PCA | principal component analysis |
| RF | receptive field |
Appendix A. Generative Model of Optic Flow
References
- Escobar-alvarez, H.; Johnson, N.; Hebble, T.; Klingebiel, K.; Quintero, S.; Regenstein, J.; Browning, N. R-ADVANCE: Rapid Adaptive Prediction for Vision-based Autonomous Navigation, Control, and Evasion. J. Field Robot. 2018, 35, 91–100. [Google Scholar] [CrossRef]
- Jean-Christophe, Z.; Antoine, B.; Dario, F. Optic Flow to Control Small UAVs. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS’2008), Nice, France, 22–26 September 2008. [Google Scholar]
- Van Breugel, F.; Morgansen, K.; Dickinson, M. Monocular distance estimation from optic flow during active landing maneuvers. Bioinspir. Biomim. 2014, 9, 025002. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Serres, J.; Ruffier, F. Optic flow-based collision-free strategies: From insects to robots. Arthropod. Struct. Dev. 2017, 46, 703–717. [Google Scholar] [CrossRef] [PubMed]
- Srinivasan, M. Honeybees as a model for the study of visually guided flight, navigation, and biologically inspired robotics. Physiol. Rev. 2011, 91, 413–460. [Google Scholar] [CrossRef]
- Srinivasan, M. Vision, perception, navigation and ‘cognition’ in honeybees and applications to aerial robotics. Biochem. Biophys. Res. Commun. 2020, 564, 4–17. [Google Scholar] [CrossRef] [PubMed]
- Warren, W.; Kay, B.; Zosh, W.; Duchon, A.; Sahuc, S. Optic flow is used to control human walking. Nat. Neurosci. 2001, 4, 213–216. [Google Scholar] [CrossRef]
- Chen, D.; Sheng, H.; Chen, Y.; Xue, D. Fractional-order variational optical flow model for motion estimation. Philos. Trans. R Soc. A Math. Phys. Eng. Sci. 2013, 371, 20120148. [Google Scholar] [CrossRef] [Green Version]
- Longuet-Higgins, H.; Prazdny, K. The interpretation of a moving retinal image. Proc. R Soc. Lond. B 1980, 208, 385–397. [Google Scholar]
- Gibson, J.J. The Perception of the Visual World; Houghton Mifflin: Boston, MA, USA, 1950. [Google Scholar]
- Perrone, J. Model for the computation of self-motion in biological systems. J. Opt. Soc. Am. A 1992, 9, 177–194. [Google Scholar] [CrossRef] [PubMed]
- Rieger, J.; Lawton, D. Processing differential image motion. J. Opt. Soc. Am. A 1985, 2, 354–360. [Google Scholar] [CrossRef] [PubMed]
- Royden, C. Mathematical analysis of motion-opponent mechanisms used in the determination of heading and depth. J. Opt. Soc. Am. A 1997, 14, 2128–2143. [Google Scholar] [CrossRef]
- Van Den Berg, A.; Beintema, J. Motion templates with eye velocity gain fields for transformation of retinal to head centric flow. Neuroreport 1997, 8, 835–840. [Google Scholar] [CrossRef]
- Perrone, J.; Krauzlis, R. Vector subtraction using visual and extraretinal motion signals: A new look at efference copy and corollary discharge theories. J. Vis. 2008, 8, 24. [Google Scholar] [CrossRef]
- Perrone, J. Visual-vestibular estimation of the body’s curvilinear motion through the world: A computational model. J. Vis. 2018, 18, 1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Elder, D.; Grossberg, S.; Mingolla, E. A neural model of visually guided steering, obstacle avoidance, and route selection. J. Exp. Psychol. Hum. Percept. Perform. 2009, 35, 1501. [Google Scholar] [CrossRef] [Green Version]
- Raudies, F.; Neumann, H. A review and evaluation of methods estimating ego-motion. Comput. Vis. Image Underst. 2012, 116, 606–633. [Google Scholar] [CrossRef]
- Royden, C. Computing heading in the presence of moving objects: A model that uses motion-opponent operators. Vis. Res. 2002, 42, 3043–3058. [Google Scholar] [CrossRef] [Green Version]
- Perrone, J. A neural-based code for computing image velocity from small sets of middle temporal (MT/V5) neuron inputs. J. Vis. 2012, 12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Warren, W.; Saunders, J. Perceiving heading in the presence of moving objects. Perception 1995, 24, 315–331. [Google Scholar] [CrossRef]
- Browning, N.; Grossberg, S.; Mingolla, E. Cortical dynamics of navigation and steering in natural scenes: Motion-based object segmentation, heading, and obstacle avoidance. Neural Netw. 2009, 22, 1383–1398. [Google Scholar] [CrossRef] [Green Version]
- Layton, O.; Mingolla, E.; Browning, N. A motion pooling model of visually guided navigation explains human behavior in the presence of independently moving objects. J. Vis. 2012, 12, 20. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Layton, O.; Fajen, B. Competitive dynamics in MSTd: A mechanism for robust heading perception based on optic flow. PLoS Comput. Biol. 2016, 12, e1004942. [Google Scholar] [CrossRef] [Green Version]
- Graziano, M.; Andersen, R.; Snowden, R. Tuning of MST neurons to spiral motions. J. Neurosci. 1994, 14, 54–67. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Duffy, C.; Wurtz, R. Response of monkey MST neurons to optic flow stimuli with shifted centers of motion. J. Neurosci. 1995, 15, 5192–5208. [Google Scholar] [CrossRef] [PubMed]
- Perrone, J.; Stone, L. A model of self-motion estimation within primate extrastriate visual cortex. Vis. Res. 1994, 34, 2917–2938. [Google Scholar] [CrossRef]
- Layton, O.; Niehorster, D. A model of how depth facilitates scene-relative object motion perception. PLoS Comput. Biol. 2019, 15, e1007397. [Google Scholar] [CrossRef] [PubMed]
- Layton, O.; Fajen, B. Computational Mechanisms for Perceptual Stability using Disparity and Motion Parallax. J. Neurosci. 2020, 40, 996–1014. [Google Scholar] [CrossRef]
- Steinmetz, S.T.; Layton, O.W.; Browning, N.A.; Powell, N.V.; Fajen, B.R. An Integrated Neural Model of Robust Self-Motion and Object Motion Perception in Visually Realistic Environments. J. Vis. 2019, 19, 294a. [Google Scholar]
- Brito Da Silva, L.; Elnabarawy, I.; Wunsch, D. A survey of adaptive resonance theory neural network models for engineering applications. Neural Netw. 2019, 120, 167–203. [Google Scholar] [CrossRef]
- Carpenter, G.; Grossberg, S.; Rosen, D. Fuzzy ART: Fast stable learning and categorization of analog patterns by an adaptive resonance system. Neural Netw. 1991, 4, 759–771. [Google Scholar] [CrossRef] [Green Version]
- Grossberg, S. A Path Toward Explainable AI and Autonomous Adaptive Intelligence: Deep Learning, Adaptive Resonance, and Models of Perception, Emotion, and Action. Front. Neurorobot. 2020, 14. [Google Scholar] [CrossRef]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. arXiv 2017, arXiv:1705.05065v2. [Google Scholar]
- Weinzaepfel, P.; Revaud, J.; Harchaoui, Z.; Schmid, C. DeepFlow: Large Displacement Optical Flow with Deep Matching. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 1385–1392. [Google Scholar]
- Deangelis, G.; Uka, T. Coding of horizontal disparity and velocity by MT neurons in the alert macaque. J. Neurophysiol. 2003, 89, 1094–1111. [Google Scholar] [CrossRef] [PubMed]
- Britten, K.; Van Wezel, R. Electrical microstimulation of cortical area MST biases heading perception in monkeys. Nat. Neurosci. 1998, 1, 59. [Google Scholar] [CrossRef] [PubMed]
- Beyeler, M.; Dutt, N.; Krichmar, J. 3D Visual Response Properties of MSTd Emerge from an Efficient, Sparse Population Code. J. Neurosci. 2016, 36, 8399–8415. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nover, H.; Anderson, C.; Deangelis, G. A logarithmic, scale-invariant representation of speed in macaque middle temporal area accounts for speed discrimination performance. J. Neurosci. 2005, 25, 10049–10060. [Google Scholar] [CrossRef]
- Brito Da Silva, L.; Elnabarawy, I.; Wunsch, D. Distributed dual vigilance fuzzy adaptive resonance theory learns online, retrieves arbitrarily-shaped clusters, and mitigates order dependence. Neural Netw. 2020, 121, 208–228. [Google Scholar] [CrossRef]
- Carpenter, G.; Gjaja, M. Fuzzy ART Choice Functions; Boston University, Center for Adaptive Systems and Department of Cognitive and Neural Systems: Boston, MA, USA, 1993; pp. 713–722. [Google Scholar]
- Carpenter, G.A. Default artmap. In Proceedings of the International Joint Conference on Neural Networks, Portland, OR, USA, 20–24 July 2003; pp. 1396–1401. [Google Scholar] [CrossRef]
- Sanger, T. Optimal unsupervised learning in a single-layer linear feedforward neural network. Neural Netw. 1989, 2, 459–473. [Google Scholar] [CrossRef]
- Warren, W.; Morris, M.; Kalish, M. Perception of translational heading from optical flow. J. Exp. Psychol. Hum. Percept. Perform. 1988, 14, 646. [Google Scholar] [CrossRef]
- Royden, C.; Crowell, J.; Banks, M. Estimating heading during eye movements. Vis. Res. 1994, 34, 3197–3214. [Google Scholar] [CrossRef]
- Zhao, B.; Huang, Y.; Wei, H.; Hu, X. Ego-Motion Estimation Using Recurrent Convolutional Neural Networks through Optical Flow Learning. Electronics 2021, 10, 222. [Google Scholar] [CrossRef]
- Zhu, Z.; Yuan, L.; Chaney, K.; Daniilidis, K. Unsupervised event-based learning of optical flow, depth, and egomotion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 989–997. [Google Scholar]
- Pandey, T.; Pena, D.; Byrne, J.; Moloney, D. Leveraging Deep Learning for Visual Odometry Using Optical Flow. Sensors 2021, 21, 1313. [Google Scholar] [CrossRef]
- Wang, R. A simple competitive account of some response properties of visual neurons in area MSTd. Neural Comput. 1995, 7, 290–306. [Google Scholar] [CrossRef] [PubMed]
- Wang, R. A network model for the optic flow computation of the MST neurons. Neural Netw. 1996, 9, 411–426. [Google Scholar] [CrossRef]
- Zhang, K.; Sereno, M.; Sereno, M. Emergence of position-independent detectors of sense of rotation and dilation with Hebbian learning: An analysis. Neural Comput. 1993, 5, 597–612. [Google Scholar] [CrossRef]
- Wunsch, D.; Caudell, T.; Capps, C.; Marks, R.; Falk, R. An optoelectronic implementation of the adaptive resonance neural network. IEEE Trans. Neural Netw. 1993, 4, 673–684. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, S.; Wunsch, D.C. A GPU based parallel hierarchical fuzzy ART clustering. In Proceedings of the 2011 International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011. [Google Scholar]
- Shigekazu, I.; Keiko, I.; Mitsuo, N. Hierarchical Cluster Analysis by arboART Neural Networks and Its Application to Kansei Evaluation Data Analysis. In Proceedings of the Korean Society for Emotion and Sensibility Conference; 2002. Available online: https://www.koreascience.or.kr/article/CFKO200211921583194.org (accessed on 1 October 2021).
- Bartfai, G. An ART-based modular architecture for learning hierarchical clusterings. Neurocomputing 1996, 13, 31–45. [Google Scholar] [CrossRef]
- Georgopoulos, A.; Schwartz, A.; Kettner, R. Neuronal population coding of movement direction. Science 1986, 233, 1416–1419. [Google Scholar] [CrossRef] [PubMed] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Video spatial resolution | 512 × 512 pixels |
| Translational speed | 3 m/s |
| Camera focal length | 1.74 cm |
| Field of view | 90 |
| Eye height | 1.61 m |
| Number of dots in scene | 2000 |
| Observer-relative depth range of dots | 1–50 m |
| Dataset | Description | Size (Num Videos) | Independent Variables |
|---|---|---|---|
| 3D dot cloud (T) | Translational self-motion through 3D dot cloud along random heading directions | Train: 500 Test: 250 | Heading azimuth and elevation: |
| Ground plane (T) | Translational self-motion over a ground plane with random heading directions | Train: 500 Test: 250 | Heading azimuth and elevation: |
| 3D dot cloud () | Self-motion through 3D dot cloud along random 2D heading directions with varying amounts of pitch, yaw, roll rotation | Train: 1000 Test: 500 | Heading azimuth and elevation: Rotation speed: s |
| Parameter | Layer Type | Description | Value |
|---|---|---|---|
| MT | Number of MT neurons | 5000 | |
| MT | RF radius | 15 pixels (2.5°) | |
| MT | Preferred direction of neuron | Uniform (0°, 360°) | |
| MT | Bandwidth of direction tuning | 3° | |
| MT | speed tuning bandwidth | ||
| MT | Non-negative offset parameter to prevent singularity in speed logarithm | Exp | |
| MT | Preferred speed of neuron | Uniform , Uniform , Uniform , Uniform , Uniform | |
| MT | Passive decay rate | 0.1 | |
| MT | Excitatory upper bound | 2.5 | |
| MT | Temporal integration time step | 0.1 frames (0.003 s) | |
| MT | Input value that yields 0.5 in sigmoid activation function | 0.007 (median empirical input) | |
| Fuzzy ART | Fuzzy ART module arrangement | Layer 1: 8 × 8, layer 2: 1 × 1 | |
| Fuzzy ART | Activation prior on existing representations | 0.01 | |
| Fuzzy ART | Vigilance | Layer 1: 0.65, layer 2: 0.85 | |
| Fuzzy ART | Learning rate | 1 (when committing new cell)0.1 (when updating weights) | |
| Fuzzy ART | Number of training epochs | Layer 1: 1, layer 2: 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Layton, O.W. ARTFLOW: A Fast, Biologically Inspired Neural Network that Learns Optic Flow Templates for Self-Motion Estimation. Sensors 2021, 21, 8217. https://doi.org/10.3390/s21248217
Layton OW. ARTFLOW: A Fast, Biologically Inspired Neural Network that Learns Optic Flow Templates for Self-Motion Estimation. Sensors. 2021; 21(24):8217. https://doi.org/10.3390/s21248217
Chicago/Turabian StyleLayton, Oliver W. 2021. "ARTFLOW: A Fast, Biologically Inspired Neural Network that Learns Optic Flow Templates for Self-Motion Estimation" Sensors 21, no. 24: 8217. https://doi.org/10.3390/s21248217