1. Introduction
Human Activity Recognition (HAR) deals with the recognition, interpretation, and assessment of human daily-life activities. Wearable sensors such as an accelerometer, gyroscope, depth sensors etc. can be attached on assorted body locations to record movement patterns and actions. In recent years, HAR research has attracted critical consideration on account of its boundless applications, such as in fashion [
1], surveillance systems [
2,
3], smart homes [
4] and healthcare [
5].
Several HAR systems have been designed to automate the aforementioned applications; however, assembling a completely automated HAR framework can be an extremely daunting undertaking since it requires a colossal pool of movement data and methodical classification algorithms. In addition, it is a troublesome undertaking in light of the fact that a solitary movement can be performed in more than one way [
6].
Human activities are generally categorized as basic activities, complex activities and the postural transitions between or within these activities. Postural transition is a finite movement between two activities, which varies between humans in terms of time and actions. Most of the works do not take into account the postural transitions because of their short duration. However, when performing multiple tasks in a short period of time, they play an important role in effectively identifying activities [
7].
Customary AI tools such as machine learning (M.L) algorithms have been utilized for classification and are capable of achieving satisfactory results. Activity recognition using standard M.L approaches such as K Nearest Neighborhood (KNN) [
8,
9,
10], Support Vector Machine (SVM) [
11,
12,
13,
14], Decision Tree (DT) [
15,
16], Random Forest (RF) [
17,
18] and Discrete Cosine Transform (DCT) [
19,
20,
21], etc., have been reported to produce good results under controlled environments [
22]. The accuracy of these models heavily depends on the process of feature selection/extraction.
A volume of research has been conducted on activity recognition based on features obtained from a variety of datasets collected using various sources such as accelerometers and gyroscopes. However, it is of great importance that a feature selection preprocess module is applied to select a subset that prunes away any noise and redundancy, which would otherwise only degrade the performance of the recognition system. This computation is also called dimensionality reduction; i.e., the selection of features that would complement each other. An assortment of feature selection strategies have been utilized to improve the performance of activity recognition systems, such as correlation-based [
23] and energy-based methods [
24], cluster analysis [
25], AdaBoost [
26], Relief-F [
27], Single Feature Classification (SFC), Sequential Forward Selection (SFS) [
28] and Sequential Floating Forward Search (SFFS) [
29]. The aim of feature selection methods is to drop features that carry the least information for discriminating an activity, consequently increasing efficiency without compromising robustness. For more on feature selection methods, readers are referred to a survey in [
30]. Mi Zhang and Alexander A.Sawchuk have proposed an SVM-based framework to analyze the effects of feature selection methods on the performance of activity recognition systems [
31]. This research has shown that the SFS method performs better than Relief-F and SFC methods. Essentially, this points to the fact that the most relevant features encode more information than the left out features, which considerably increases the performance of the activity recognition system.
Likewise, Ahmed et al. [
32] demonstrated a feature selection model based on a hybrid SFFS feature selection method that selects/extracts the best features in view of a set of specific rules. Moreover, sets of the best features are formed and contrasted with the next set of features. The final optimal features were input to a SVM classifier for activity classification. However, machine learning techniques to date have used shallow-structured learning architectures that only use one or two nonlinear layers of feature transformation. In addition, shallow architectures usually refer to statistical features such as the mean, frequency, variance, amplitude, etc., that could only be used for low-level activities such as running, walking and standing that are well-constrained activities and cannot model complex postural situations [
33]. Moreover, the lack of good quality data due to the costly process of labeling that requires human expertise/domain knowledge is also a bottleneck, as well as the manual selection of features, which is vulnerable to a margin of human error that would not generalize well to unseen data, because activity recognition tasks in real-life applications are much complicated and require close collaboration with the feature selection module [
34].
As the volume of datasets has increased to an unprecedented level, in recent years, deep learning (D.L) has accomplished noteworthy results in the space of HAR. One of the impactful aspects of deep learning is the automatic feature identification and classification with high accuracy, which consequently produced an effect in the space of HAR [
35]. A substantial amount of uni-model and hybrid approaches have been introduced to gain benefit from deep learning techniques, catering for the shortcomings of the machine learning domain and utilizing the multiple levels of features found in different levels of hierarchies. Deep learning models involve a hierarchy of layers to accommodate low and high-level features as well as linear and nonlinear feature transformations at these levels, which helps in learning and refining features. To this end, models such as Recurrent Neural Networks (RNN) [
36], Convolutional Neural Networks (CNN) [
37], Long Short-Term Memory (LSTM) [
38], etc., are used to overcome the impediments of traditional M.L algorithms that were dependent on manual features, in which the erroneous selection/classification of features could have undesirable impacts on the applications at hand. Therefore, deep learning networks have found a natural application in recognition tasks and have been popularly used for feature extraction in activity recognition research [
39]. One downside to the deep learning paradigm, especially using the hybrid architectures, is their increased cost of processing the available huge amount of datasets. However, it is worth the cost because a HAR system requires accurate classification results of the deep learning models.
In this context, this work proposes a hybrid deep-learning based approach where models are trained simultaneously, instead of in a pipelined setup, to recognize basic and transitional human activities. The novel aspects include the simultaneous implementation of multiple deep learning models to better distinguish the classification results and the inclusion of transitional activities to present a robust activity recognition approach.
The rest of this paper is structured as follows:
Section 2 provides the details about existing related works,
Section 3 presents the proposed approach,
Section 4 discusses the experimentation and results, and
Section 5 draws conclusions.
Supplementary Materials contains the repository link for the source code and datasets used in this approach.
3. Proposed Approach
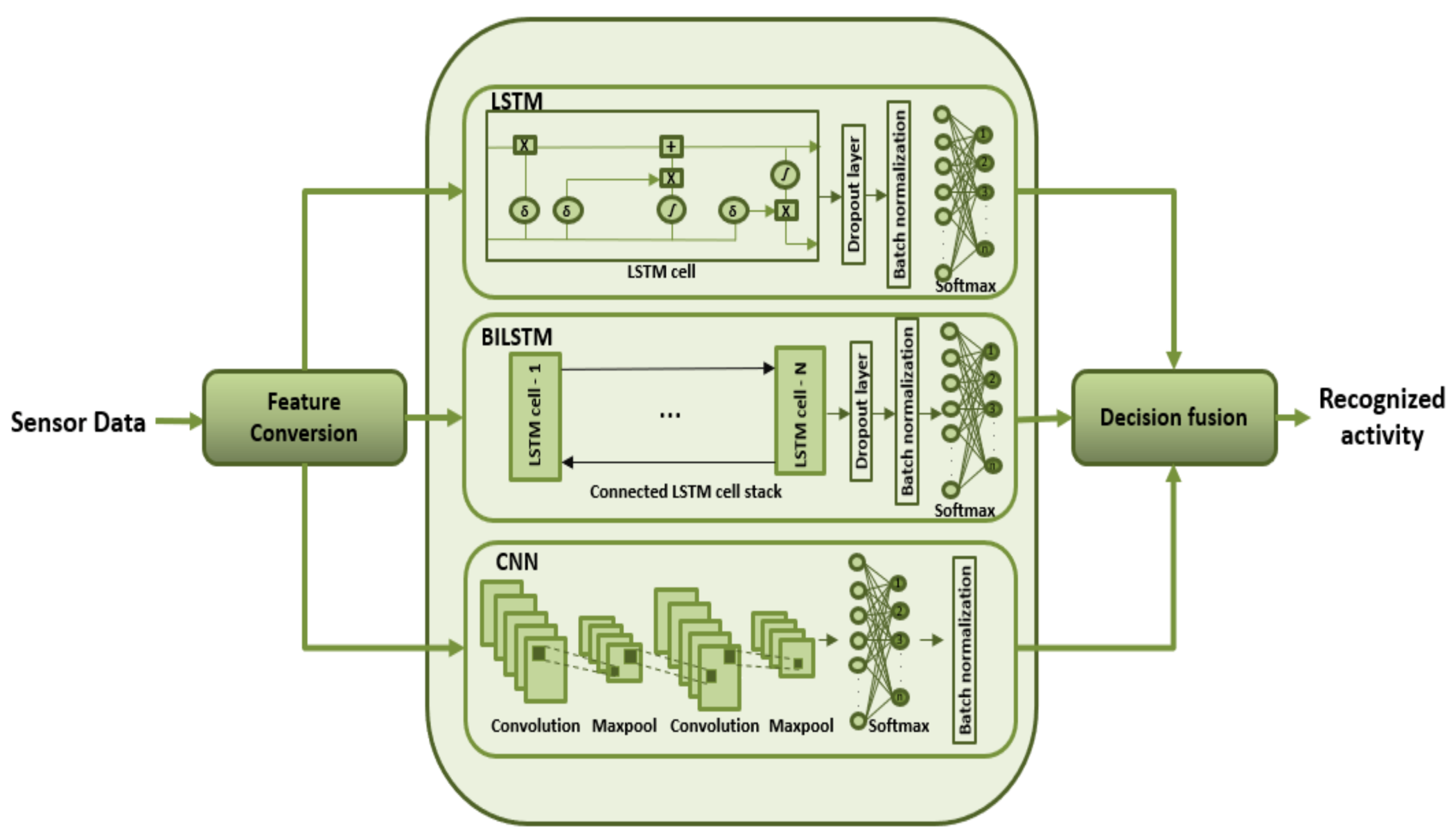
The architecture for the proposed approach consists of three deep learning (D.L) networks: LSTM, BiLSTM and CNN as depicted in
Figure 1. Three D.L. networks are utilized due to the imposition of the decision fusion module in the proposed approach. The proposed approach requires at least three D.L. networks to distinguish between the individual model results and implement decision fusion in an efficient manner. The raw sensor data are converted into a feature matrix and fed to these models separately. Batch normalization is employed in all three networks to normalize the output of each layer [
57]. After the classification results are retrieved from each model, a decision fusion module is initiated for the final classification. The subtleties of the proposed approach are given in the accompanying sections.
3.1. Long Short-Term Memory (LSTM)
The LSTM framework integrated in this approach is a standard unit contrived of an input gate, output gate, a forget gate and a memory cell. The LSTM unit is graphically shown in
Figure 2. The feature matrix is transformed into a 1D vector of
y elements and fed to the model for training, and the number of neurons are configured to be
. “Adam” is configured to be the adaptive optimizer as it performs best with sparse data. Moreover, the learning rate of
is adapted to achieve the best results while avoiding the loss of training input. A dropout rate of
is used to avoid over-fitting while maintaining the integrity of the input and output of neurons. Batch normalization is used after the fully connected layer to normalize the input of every layer in the model, and the Softmax layer classifies the results.
Table 2 shows all the hyper parameters in LSTM and their respective values for the two datasets involved.
represents the forget gate, which handles the amount of information to be kept and dropped. It is consumed by the
function, which scales the values between 0 and 1, thus dropping values <0.5.
represents the input gate that quantifies the importance of the next input (
) and updates the cell state. The new input (
) is standardized between −1 and 1 by the
function, and the output is point-wise multiplied by
.
represents the state of the cell at previous timestamps, which is updated after each time step. The information required to update the cell’s state is gathered at this point, and a bit-wise multiplication is carried out between the previous cell state (
) and the forget vector. This is followed by the bit-wise addition with the output of input gate, and the cell state is updated. Finally, the output gate (
) determines what the next hidden state should be. The hidden state encapsulates the information regarding previous inputs (
). The flow of information through the following gates is mathematically shown in Equation (
1).
where
W and
U represent the weights corresponding to their respective gates.
3.2. Bidirectional Long Short-Term Memory (BiLSTM)
The BiLSTM model utilized is based on dual recurrent (LSTM) layers, as shown in
Figure 3. The top-most layer is referred to as the embedding layer, which predicts the output for different time steps. The second layer is the forward LSTM (first recurrent) layer, which takes the input in the forward direction. The third layer is the backward LSTM (second recurrent) layer, which moves the input in the backwards direction. The first recurrent layer runs the input from the past to future, while the second recurrent layer runs the input from the future to past. The second recurrent layer is provided with the reverse sequence of the input that preserves the future information. This effectively increases the information required by the network for accurate predictions, thus improving the context available to the BiLSTM network. The additional training of data in BiLSTM model shows better results compared to those of LSTM. The BiLSTM hyper parameters were kept the same as those of the LSTM to avoid any inconsistencies in the network and to track the changes in performance on multiple datasets.
3.3. Convolutional Neural Networks (CNN)
In this research work, a 2D-CNN is designed which takes its input as a feature matrix
. The CNN is comprised of two stacked hidden layers, a fully connected layer, batch normalization layer and a softmax layer for classification, as shown in
Figure 4. Each hidden layer is a stack of “Convolution–ReLu–Maxpool” layers. The convolution layer outputs a feature map which is passed through the “Rectified Linear Unit (ReLu)” piece-wise linear function (
). The output of ReLu becomes the input to the pooling layer. Among various sorts of pooling techniques, max pooling chooses the greatest component from each block in the feature map. The pool size deals with the block to be covered and is kept as
. Padding is set to “SAME”, and the stride is set as
, such that the whole input block is covered by the filter.
The numbers of kernels in the two convolution layers are
and
, respectively. The kernel sizes are
and
, respectively. Zero padding is added to fill the edges of the input matrix, and a learning rate of
is adopted. The input to the convolution layer is of size
, where
h represents the height of the input,
w represents the width of the input, and
d refers to the dimension of the input. In this approach, the dimension of the input is 0 as we are dealing with sparse sensor data. The convolution layer applies a filter of size
, where
denotes the filter height and
represents the filter width. The convolution layer outputs a volume dimension or feature matrix (
) as shown in Equation (
2).
A batch normalization layer is utilized after the fully connected layer to normalize the data in all the previous layersm, and the output is sent to the softmax layer for classification. The mean and variance calculation in batch normalization is shown in Equations (
3) and (
4), where
x denotes the batch sample,
represents the batch mean, and
represents the mini batch variance.
Table 3 shows all the parameters involved in CNN and their respective values.
3.4. Model Implementation
An input is fed to each model separately, and activities are classified based on their respective labels. LSTM is utilized for its ability to achieve superior results in sequence to sequence classification. The LSTM encapsulates an input layer, hidden layers and a feed-forward output layer. The hidden layer confines memory cells and multiple gated units. The gated units are divided into input, output and forget gates. A feature vector is fed to the input gate which covers the update gate. The update gate is a combination and works on the same principals as the input and forget gate; thus, it decides which values to let through and which to drop. The tanh layer makes sure the values are scaled between −1 and 1. The forget gate sorts out how much information can be aggregated from the previous gate into the memory cell. The Sigmoid activation is used to scale the output from the gates between 0 and 1 to speed up the training and reduce the load on network. The results of the output gate are generated based on the cell’s state and flattened by the fully connected layer. All the parameters and inputs to layers are scaled and standardized by the batch normalization layer, and the final output is classified by softmax.
The feature vector is passed to a BiLSTM network. BiLSTM has same parameters and works on the same principles as an LSTM. The only point of difference is that in BiLSTM, the input is fed to the model twice for training: once from beginning to the end and once from end to the beginning. Therefore, by utilizing BiLSTM, we can preserve information at any time at a point in future and past, which generates a refined feature map. Furthermore, BiLSTM speeds up the training process, and this dual training of data better classifies the activities compared to LSTM. The final feature map is flattened and classified by softmax.
For the precise conversion of data into a matrix for CNN, zero padding is added to the input. Convolutions are performed on the matrix and weights are distributed among the filters. A bias is set to update the values of weights after a complete iteration. The output from the convolution layer is passed through the to convert all the negative values in the resulting feature matrix to zero.
The output of ReLu is input to the pooling layer to shrink the feature matrix and normalize the overall parameters in the hidden layer. Among several pooling techniques, maxpool is the most effective while dealing with sensor data and is thus utilized in our approach.
The feature map from the maxpool layer is input to the second hidden layer, and the whole process is repeated twice. The final feature matrix is flattened in the fully connected (FC) layer and forms a pre-classification sequence. After the FC layer, the batch normalization layer is used to normalize the output of all the layers in CNN. The softmax layer predicts polynomial probability distributions and generates categories based on these predictions.
Softmax is utilized in all models due to its ability to generate statistical probabilities alongside classes. These probabilities are exerted in the decision fusion module for final classification. After all three networks, the observations (instances) corresponding to each activity are input to the models, and each network returns the predicted classes along with the class probabilities. The predictions are then inter-compared and summed in a decision fusion module, and final classification results are generated.
3.5. Decision Fusion
The decision fusion module prioritizes the selection based on the class probabilities. Each returned class accommodates a probability value between 0 and 1 within all three networks. The resultant probabilities of each returned class from all networks are summed respectively, and the highest value-based class is designated to be the final recognized class such that.
Let
represent the probability of the first activity class in the
deep learning model; then, the probabilities of the recognized activities
in
networks can be defined as
, respectively, where
n represents the total number of deep learning networks in the model. Then, the sum of all the probabilities against each instance can be defined as (
5)
where
jM. The cumulative probability of the same resultant classes against each instance is calculated and compared with the cumulative probability of other resultant classes. For the function
, where
g is a subset of
j and contains the sum of same predicted classes from each model,
j represents the set of all generated probabilities from all networks.
k takes the maximum argument of all the values in
g and returns the classified activity, as shown in Equation (
6).
Finally, the class associated with the highest probability value
k will be returned as the recognized class. The algorithm for the decision fusion module is shown in Algorithm 1.
| Algorithm 1. Decision fusion. |
|










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}