1. Introduction
Nowadays, the growth of lightweight, robust, and effective encryption algorithms are required to provide network security for information technology applications. The developed encryption algorithms are essential for maximizing the throughput and data size of IoT, and it is used in mobile transmissions, video streaming, real-time communications, and so on [
1,
2,
3,
4,
5,
6]. The methods of encryption/decryption are classified into two types such as symmetric and asymmetric methods. In that, symmetric cryptography uses only one key for encryption and decryption, whereas asymmetric cryptography uses two distinct keys to accomplish the encryption and decryption [
7,
8,
9]. Symmetric cryptography is extensively used among all cryptographic methods due to its low energy necessities and simplicity. Hence, the symmetric block cipher, namely AES, was developed in 2001 by the National Institute of Standards and Technology (NIST); however, this AES is an alteration for the typical data encryption standard [
10,
11,
12,
13].
Some of block cipher algorithms used in the communication applications are Khudra [
14], KASUMI [
15], LRBC [
16], PRESENT [
17], SLIM [
18], HIGHT [
19], Simon [
20], KLEIN [
21], Midori [
22], and CLEFIA [
23]. However, the lightweight cipher affects the performance when the system has a huge number of devices during the communication [
24]. Additionally, the lightweight block ciphers offer only a lower level of security than the conventional algorithms [
25]. Authentication, confidentiality, and integrity are considered as the significant objectives of the cryptographic protocols. The AES is served as a significant cryptographic algorithm, whereas it satisfies the essential security goals of availability, confidentiality, and integrity during the communication on the insecure transmission medium [
26,
27]. Since the cryptographic process with an extreme computation complexity of ciphers avoids the key from the attempt of brute force [
28]. The AES is implemented in different hardware platforms such as graphics processing units, embedded processors, ASIC, and FPGA because of its extensive utilization [
29]. The configuration of hardware units using FPGA’s reconfigurable logic resources is used for achieving high pipelining and parallelism. The balancing over the pipeline is obtained by adding and relocating the registers. The usage of multiple ports in the memory units is used to increase the speed of the read/write operations [
30].
FPGA chips can operate simultaneously and it has a comparatively flexible architecture. Hence, the test cycles and design cost of the FPGA chips are lower [
31,
32,
33,
34]. Since two different LUT-based methods, namely substitution box (S-Box) and T-box, are used for an effective design of AES over the FPGA, LUT-based encryption and decryption are not only memory intensive but also asymmetric because of its transformation sequence and AES functions of encryption and decryption. Hence, the process of encryption and decryption are designed individually, and it occupies a significant amount of BRAM over the LUT-based AES [
35]. However, the clock speed, library, and throughout are difficult to achieve by AES design due to its complexity, its user scheduling process, and the dynamic nature of its design. Since the S-box of the AES’s sub-byte process consumes more power than the other modules of the circuit [
36]. The multiplicative inversion used in the sub-byte transformation requires higher resources and finite field arithmetic [
37].
Some of the conventional AES architectures are described as below:
Benhadjyoussef et al. [
38] presented the fault-resistant method for securing the AES against attacks. Parity checking was used to develop the error detection for the time redundancy of subbytes function and linear operations. Specifically, the error detection code depends on the cyclic redundancy check that was used to identify the parity of the Shift Rows, Mix Columns, and Add Round Key functions. On the other hand, faults were inserted in the SubBytes transformation to identify the temporal redundancy. However, the information redundancy method caused high overhead, which affects the system performance. Sheikhpour, Ko, and Mahani, [
39] developed the 32-bit AES encryption/decryption for IoT and resource-constrained applications. Here, the low-cost fault-resilient structure was developed for the data path. Subsequently, an on-the-fly key expansion unit was also designed for the key generation of encryption/decryption processes. Here, the area was minimized using resource-sharing among encryption and decryption operations. Sikka et al. [
40] presented the design of the AES for automotive applications. In this work, the 128-bit key of AES was designed using the High-Level Synthesis (HLS) tool. Specifically, HLS was based on the bit widths while designing the AES over the FPGA. However, the re-computation of the signal width increased the overall latency of the AES algorithm.
Zodpe and Sapkal [
41] presented the PN Sequence Generator (PNSG) for creating the S-box and initial keys for Encryption/Decryption. Here, the Linear Feedback Shift Register (LFSR) was used for designing the PNSG, whereas the LFSR was represented using the generator polynomial. The designed PNSG was used to offer different random number sequences by using the initial seed and feedback tap. The robustness of the AES cryptography was enhanced by using the feature of PNSG. However, the design of AES using non-pipelined stages required high hardware resources. Shahbazi and Ko [
42] presented the 128-bit of AES in counter mode for high traffic applications. Inner and outer pipelining methods were used to achieve high throughput, and an affine transformation (AT) method was designed to minimize the area. The developed affine transformation was the hybrid method of affine and inverse isomorphic transformation. In AES, the operations of Sub-Bytes and Shift Rows were swapped, and then Add Round Key was combined with the Shift Rows. Moreover, the Mix Column operation was divided into two distinct phases for achieving the latency. However, the accomplishment of mix column in one clock caused high latency. Madhavapandian and MaruthuPandi [
43] developed q 128-bit AES cryptographic method for securing the Transmission Control Protocol/Internet Protocol (TCP/IP). An effective mix column Boolean Expression (BE) using gate replacement and resource sharing structure was used to modify the mix column operation. Accordingly, the optimized architecture of AES was used to minimize power consumption. However, it was required that the time complexity be minimized because it increased the delay during the communication using TCP/IP protocol.
Arul et al. [
44] developed the Iterative Structure of the AES (ISAES) for lessening the hardware resources. The architecture of renovated S-box was used in the AES to minimize the area. Here, the usage of LUT in the composite field arithmetic was accomplished in the multiplication operation. Moreover, the Vedic multiplier was employed in the Mix Column transformation, which was used to decrease the hardware resources of AES. However, the operating frequency of the AES was less because of the high delay. Wegener et al. [
45] developed AES S-box by using the function of the Rotational Symmetry (RS). In this work, AES was designed by using the internal MUXes and slice registers, and this AES does not require any Block RAM (BRAM). The Boolean masking with a less amount of two shares over an AES’s decomposition was applied to generate the higher robustness against the attacks. Here, the masked AES design was used to optimize the LUT implementation. However, the replication of linear operators and their independent operation was increased the overall area of AES. Kumar [
46] developed the architecture of MPPRM for designing the AES’s SubBytes/InvSubBytes transformation. These transformations were utilized for designing the subpipelining architecture. The hardware resources such as AND and XOR gates were reduced using the MPPRM in SubBytes and InvSubBytes transformations. Here, a 128-bit key was generated by the key expansion structure, and this key was given to the subpipelined structure. Due to the utilization of the delay module in the output of AND gate, a high-speed encryption/decryption was achieved in AES. Here, the AES’s area was increased because of the recurrent key generation in the encryption process.
The problems of the conventional AES are stated as follows: The frequent computation of input, output, and intermediate signal width leads to an increase in the delay of the AES [
40]. The hardware resources also increased because of AES design using non-pipelined stages [
41]. Due to the high delay, the operating frequency is decreased in the AES architecture [
44]. The area of the overall AES is increased because of the replication of linear function and independent operation [
45]. Hence, the AES is developed with an effective FJMKE architecture to avoid the aforesaid issues. The FJMKE architecture is used to create the multiple subkeys simultaneously, which helps to decrease the delay in the AES. The generation of multiple subkeys using the FJMKE leads to reducing the combinational logics as it avoids frequent calculation subkeys.
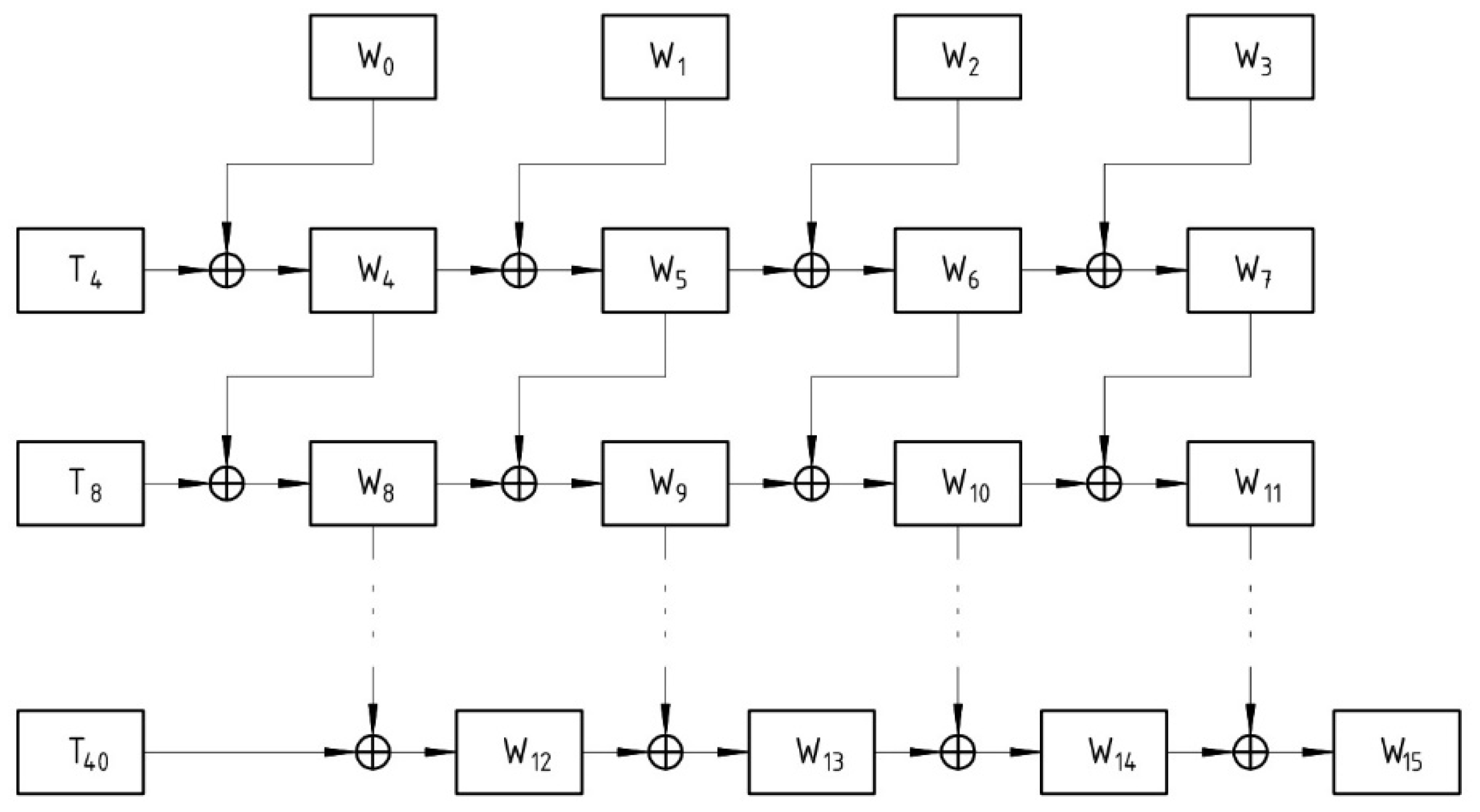
The conventional AES architecture generates the subkeys according to the previous step subkeys, whereas the proposed AES-FJMKE architecture generates the subkeys only based on the main key that helps to reduce the overall propagation delay.
The research contributions are as follows:
In this research, the FJMKE architecture is used to generate the subkeys in a parallel way, whereas the generation of the subkeys does not depend on the subkeys from the previous step this leads to minimize the propagation delay. This multiple subkey generation decreases the delay while encrypting the plain text.
The combinational logic of the overall AES is minimized by avoiding the frequent computation of secret keys using FJMKE architecture, which lessens AES’s resources.
There are six different FPGA devices, namely Virtex 4, Virtex 5, Virtex 6, Spartan 3, Spartan 6, and Kintex 7, that are used for analysing the AES-FJMKE architecture.
The organization of this research article is as follows.
Section 2 explains the typical AES architecture.
Section 3 describes the AES-FJMKE architecture in detail. The performance evaluation of the AES-FJMKE architecture is discussed in
Section 4. Further,
Section 5 discusses the research’s conclusion and future endeavours.



 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}