
Deep Auto-Encoder and Deep Forest-Assisted Failure Prognosis for Dynamic Predictive Maintenance Scheduling





Abstract
:1. Introduction
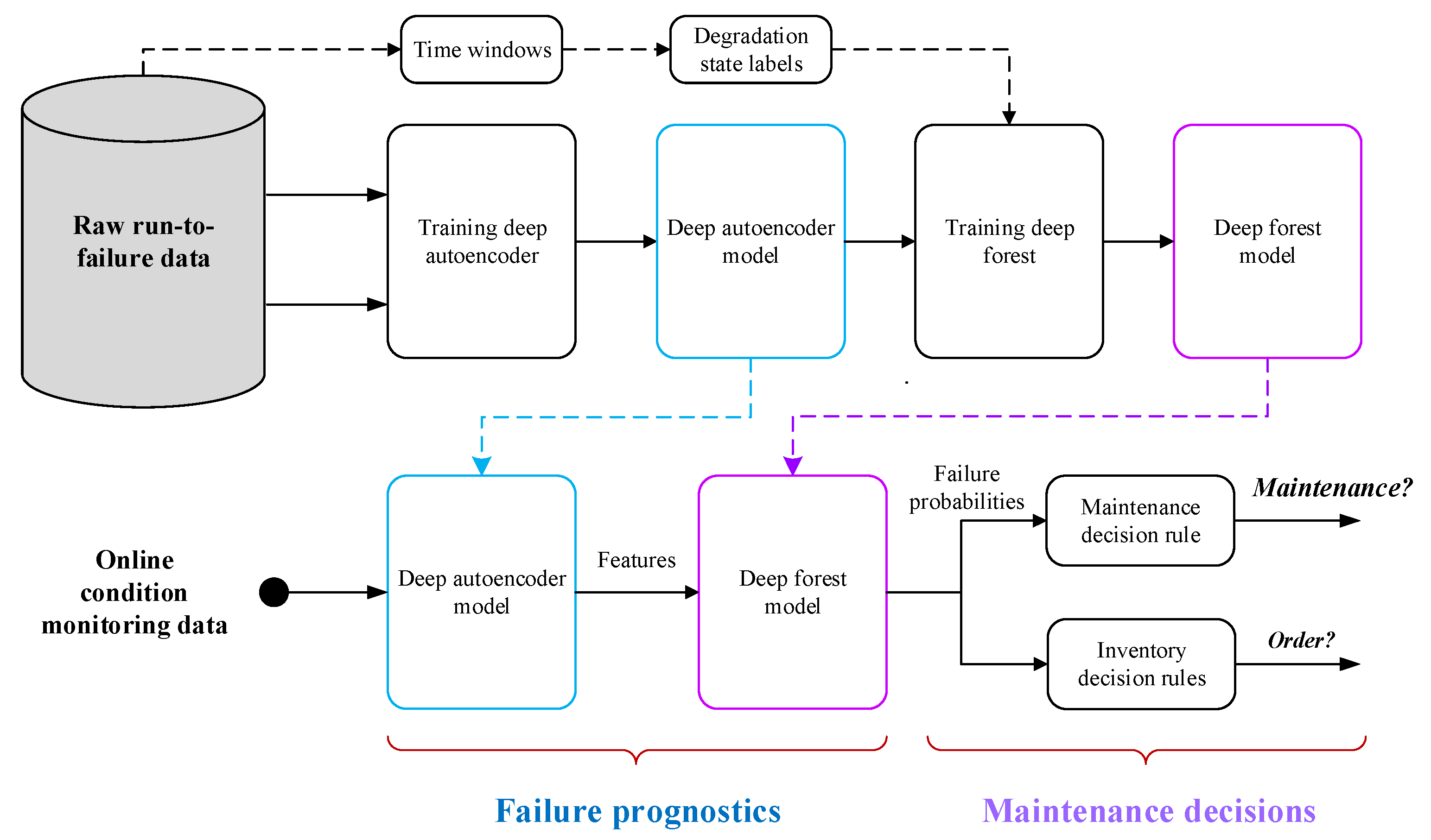
- A unified and powerful deep auto-encoder and deep forest integrated algorithm is proposed to handle the raw condition monitoring data. It can automatically extract the representative features reflecting system degradation and construct the mapping between the features and discrete degradation states for failure prognosis.
- Two decision rules are designed to deal with the DPMS. With the prognostic failure probabilities, the maintenance and inventory decisions can be made through quickly evaluating the costs of different decisions.
- With NASA’s open datasets of aircraft engines, the proposed DPMS method outperforms several state-of-the-art methods, which can benefit precise maintenance decisions and reduce maintenance costs.
2. Methodology
2.1. Key Idea
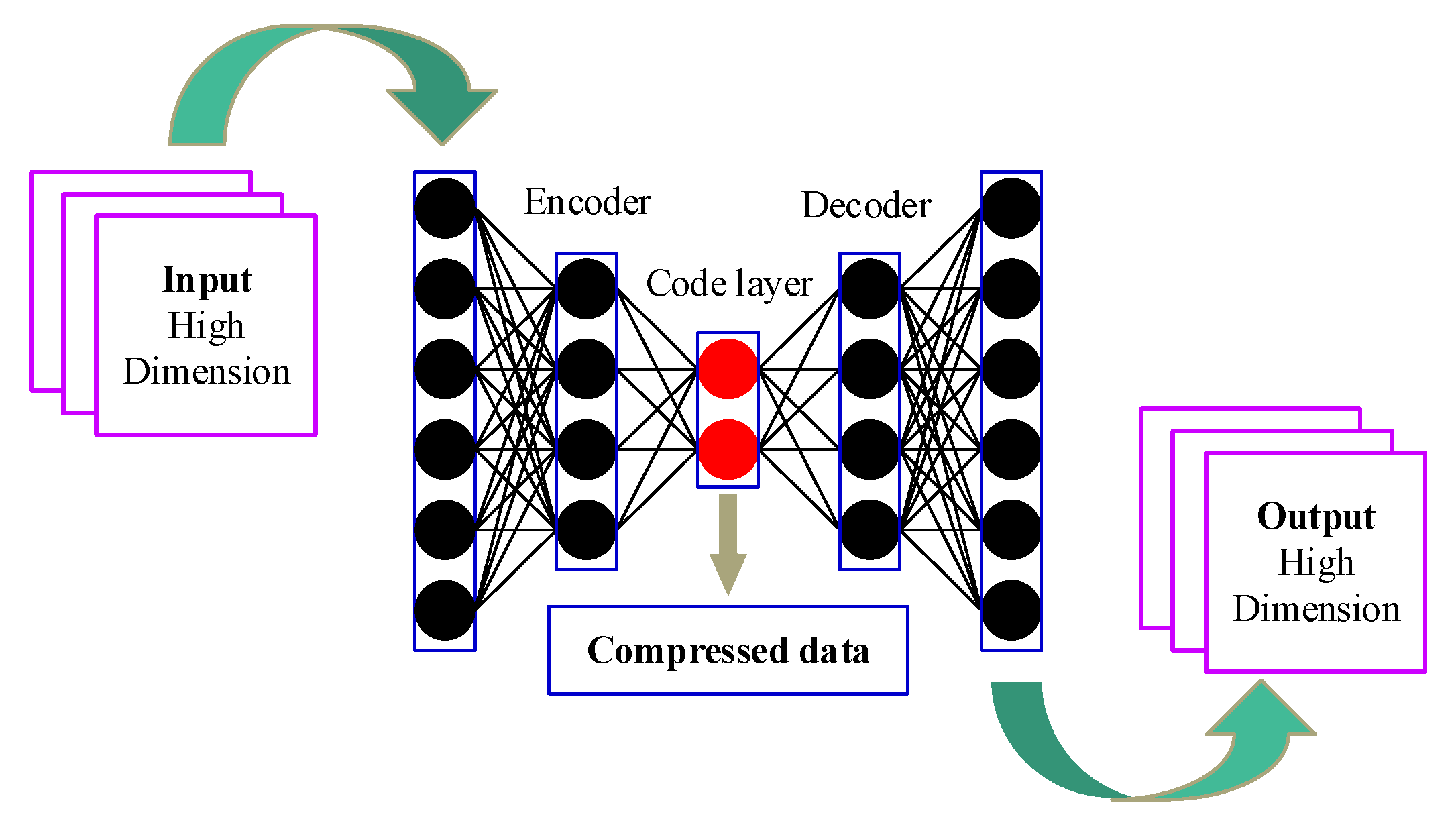
2.2. Degradation Feature Extraction Using a Deep Auto-Encoder
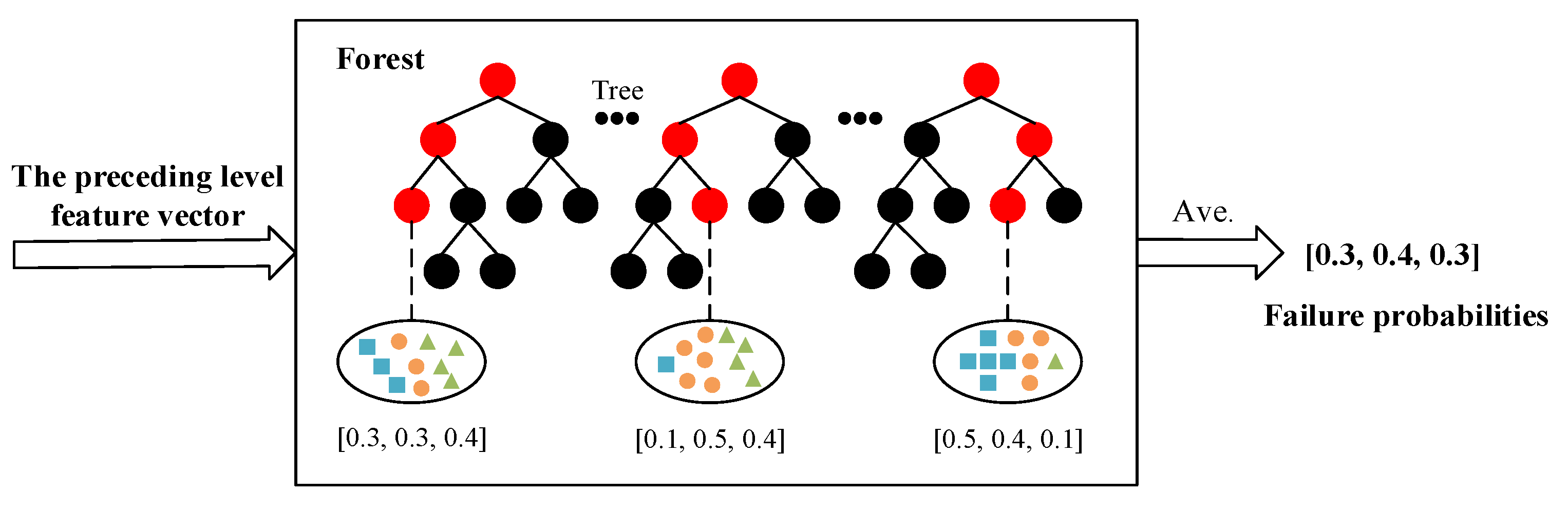
2.3. Failure Prognosis Using Deep Forest
2.4. Maintenance-Related Decision Rules Based on Prognostic Information
- Inventory decision: The inventory decision aims to determine whether to place a spare part order at the current inspection time (h-th inspection period for example). For an option to order the spare part, the cost is computed by
- Maintenance decision: The maintenance decision aims to determine whether to maintain the system at the current inspection time. For an option to maintain the system, the cost rate is computed by
2.5. Implementation Process of Predictive Maintenance
- Obtain the real-time condition monitoring data from multiple sensors installed in the system;
- Obtain the representative features that can reflect system degradation using the deep auto-encoder;
- Produce the failure probabilities in moving time horizons using deep forest;
- Compute the costs of different decisions, and schedule maintenance and inventory activities according to two decision cost-based rules.
3. Results
3.1. Description of the C-MAPSS Dataset
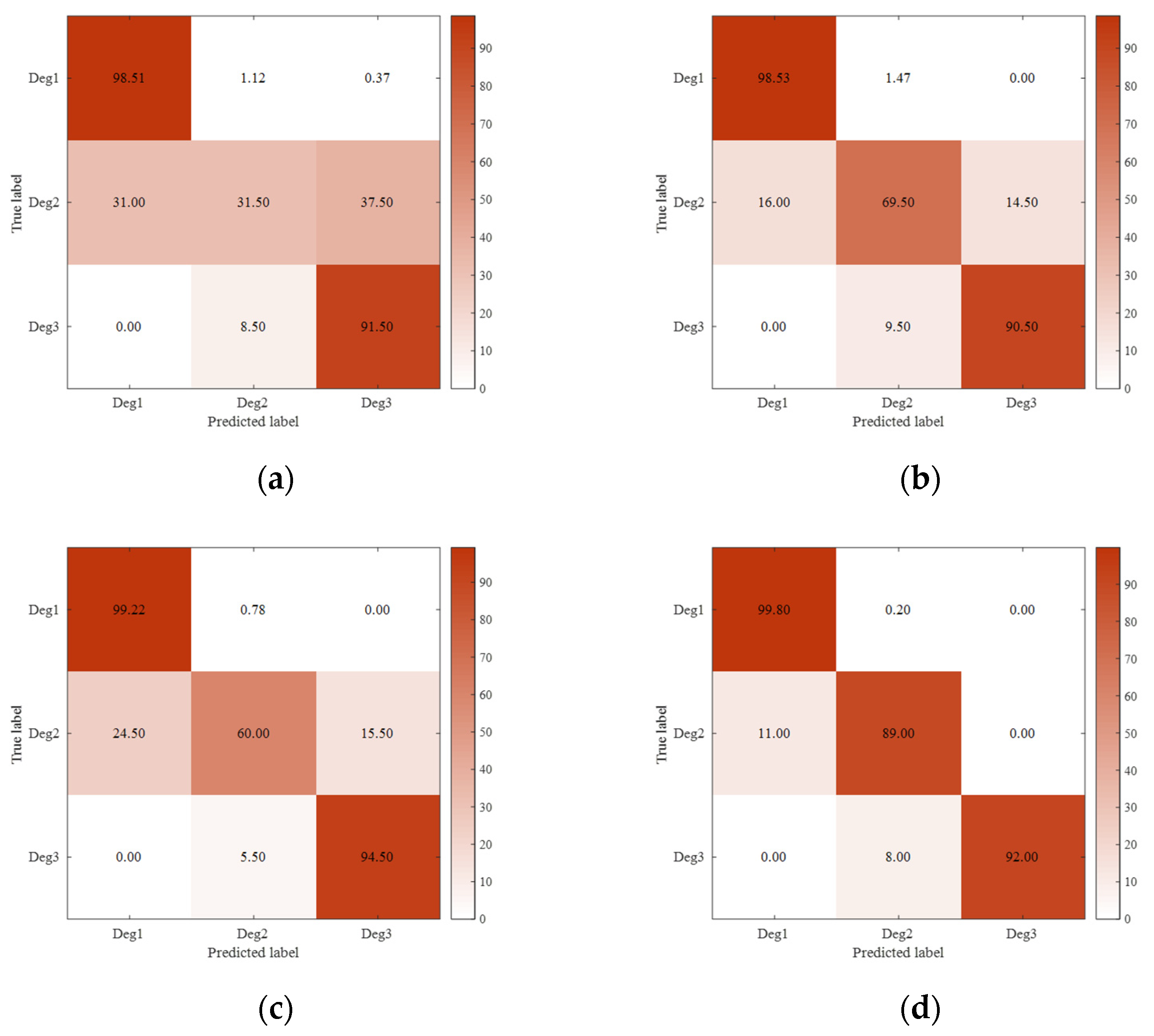
3.2. Accuracy of Failure Prognosis Model
3.3. Performance of the Dynamic Predictive Maintenance Strategy
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Olesen, J.F.; Shaker, H.R. Predictive Maintenance for Pump Systems and Thermal Power Plants: State-of-the-Art Review, Trends and Challenges. Sensors 2020, 20, 2425. [Google Scholar] [CrossRef] [PubMed]
- Yin, A.; Yan, Y.; Zhang, Z.; Li, C.; Sánchez, R.-V. Fault Diagnosis of Wind Turbine Gearbox Based on the Optimized LSTM Neural Network with Cosine Loss. Sensors 2020, 20, 2339. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, Y.; Lee, Y.S. A low-cost surge current detection sensor with predictive lifetime display function for maintenance of surge protective devices. Sensors 2020, 20, 2310. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, C.; Lu, N.; Jiang, B.; Xing, Y.; Zhu, Z.H. Prediction interval estimation of aero-engine remaining useful life based on bidirectional long short-term memory network. IEEE Trans. Instrum. Meas. 2021, 70, 3527213. [Google Scholar] [CrossRef]
- Chen, C.; Lu, N.; Jiang, B.; Wang, C. A Risk-Averse Remaining Useful Life Estimation for Predictive Maintenance. IEEE/CAA J. Autom. Sin. 2021, 8, 412–422. [Google Scholar] [CrossRef]
- Chen, C.; Lu, N.; Jiang, B.; Xing, Y. Condition-based maintenance optimization for continuously monitored degrading systems under imperfect maintenance actions. J. Syst. Eng. Electron. 2020, 31, 841–851. [Google Scholar]
- Chen, C.; Wang, C.; Lu, N.; Jiang, B.; Xing, Y. A data-driven predictive maintenance strategy based on accurate failure prognostics. Eksploat. I Niezawodn. 2021, 23, 387–394. [Google Scholar] [CrossRef]
- Hu, C.-H.; Pei, H.; Si, X.-S.; Du, D.-B.; Pang, Z.-N.; Wang, X. A Prognostic Model Based on DBN and Diffusion Process for Degrading Bearing. IEEE Trans. Ind. Electron. 2019, 67, 8767–8777. [Google Scholar] [CrossRef]
- Berri, P.C.; Vedova, M.D.D.; Mainini, L. Computational framework for real-time diagnostics and prognostics of aircraft actuation systems. Comput. Ind. 2021, 132, 103523. [Google Scholar] [CrossRef]
- Wang, C.; Lu, N.; Cheng, Y.; Jiang, B. A Data-Driven Aero-Engine Degradation Prognostic Strategy. IEEE Trans. Cybern. 2019, 51, 1531–1541. [Google Scholar] [CrossRef]
- Leukel, J.; González, J.; Riekert, M. Adoption of machine learning technology for failure prediction in industrial maintenance: A systematic review. J. Manuf. Syst. 2021, 61, 87–96. [Google Scholar] [CrossRef]
- Dalzochio, J.; Kunst, R.; Pignaton, E.; Binotto, A.; Sanyal, S.; Favilla, J.; Barbosa, J. Machine learning and reasoning for predictive maintenance in Industry 4.0: Current status and challenges. Comput. Ind. 2020, 123, 103298. [Google Scholar] [CrossRef]
- Dawood, T.; Elwakil, E.; Novoa, H.M.; Delgado, J.F.G. Pressure data-driven model for failure prediction of PVC pipelines. Eng. Fail. Anal. 2020, 116, 104769. [Google Scholar] [CrossRef]
- Zakikhani, K.; Nasiri, F.; Zayed, T. Availability-based reliability-centered maintenance planning for gas transmission pipelines. Int. J. Press. Vessel. Pip. 2020, 183, 104105. [Google Scholar] [CrossRef]
- Fernandes, S.; Antunes, M.; Santiago, A.R.; Barraca, J.P.; Gomes, D.; Aguiar, R.L. Forecasting Appliances Failures: A Machine-Learning Approach to Predictive Maintenance. Information 2020, 11, 208. [Google Scholar] [CrossRef] [Green Version]
- Rezamand, M.; Kordestani, M.; Carriveau, R.; Ting, D.S.-K.; Saif, M. An Integrated Feature-Based Failure Prognosis Method for Wind Turbine Bearings. IEEE/ASME Trans. Mechatron. 2020, 25, 1468–1478. [Google Scholar] [CrossRef]
- Su, Y.; Tao, F.; Jin, J.; Wang, T.; Wang, Q.; Wang, L. Failure Prognosis of Complex Equipment With Multistream Deep Recurrent Neural Network. J. Comput. Inf. Sci. Eng. 2020, 20, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Rahimi, A.; Kumar, K.D.; Alighanbari, H. Failure Prognosis for Satellite Reaction Wheels Using Kalman Filter and Particle Filter. J. Guid. Control. Dyn. 2020, 43, 585–588. [Google Scholar] [CrossRef]
- Kordestani, M.; Samadi, M.F.; Saif, M. A New Hybrid Fault Prognosis Method for MFS Systems Based on Distributed Neural Networks and Recursive Bayesian Algorithm. IEEE Syst. J. 2020, 14, 5407–5416. [Google Scholar] [CrossRef]
- Ruiz-Arenas, S.; Rusák, Z.; Mejía-Gutiérrez, R.; Horváth, I. Implementation of System Operation Modes for Health Management and Failure Prognosis in Cyber-Physical Systems. Sensors 2020, 20, 2429. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Zhu, Z.H.; Shi, J.; Lu, N.; Jiang, B. Dynamic Predictive Maintenance Scheduling Using Deep Learning Ensemble for System Health Prognostics. IEEE Sensors J. 2021, 21, 26878–26891. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Feng, J. Deep forest. Natl. Sci. Rev. 2019, 6, 74–86. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.T.; Ting, K.M.; Yu, Y.; Zhou, Z.H. Spectrum of Variable-Random Trees. J. Artif. Intell. Res. 2008, 32, 355–384. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, K.T.; Medjaher, K. A new dynamic predictive maintenance framework using deep learning for failure prognostics. Reliab. Eng. Syst. Saf. 2019, 188, 251–262. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, J. A Data-Driven Maintenance Framework Under Imperfect Inspections for Deteriorating Systems Using Multitask Learning-Based Status Prognostics. IEEE Access 2021, 9, 3616–3629. [Google Scholar] [CrossRef]
- Saxena, A.; Goebel, K. Turbofan Engine Degradation Simulation Data Set. 2008. Available online: https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/ (accessed on 20 July 2021).
- Zhou, Z.H.; Feng, J. gcForest v1.1.1. Available online: https://github.com/kingfengji/gcForest (accessed on 25 July 2021).
- Huang, C.-G.; Huang, H.-Z.; Li, Y.-F. A Bidirectional LSTM Prognostics Method under Multiple Operational Conditions. IEEE Trans. Ind. Electron. 2019, 66, 8792–8802. [Google Scholar] [CrossRef]
- Wang, C.; Zhu, Z.; Lu, N.; Cheng, Y.; Jiang, B. A data-driven degradation prognostic strategy for aero-engine under various operational conditions. Neurocomputing 2021, 462, 195–207. [Google Scholar] [CrossRef]
- Shi, Z.; Chehade, A. A dual-LSTM framework combining change point detection and remaining useful life prediction. Reliab. Eng. Syst. Saf. 2021, 205, 107257. [Google Scholar] [CrossRef]
- Ellefsen, A.L.; Bjørlykhaug, E.; Æsøy, V.; Ushakov, S.; Zhang, H. Remaining useful life predictions for turbofan engine degradation using semi-supervised deep architecture. Reliab. Eng. Syst. Saf. 2019, 183, 240–251. [Google Scholar] [CrossRef]
- Chui, K.T.; Gupta, B.B.; Vasant, P. A Genetic Algorithm Optimized RNN-LSTM Model for Remaining Useful Life Prediction of Turbofan Engine. Electronics 2021, 10, 285. [Google Scholar] [CrossRef]
- Saxena, A.; Goebel, K.; Simon, D.; Eklund, N. Damage Propagation Modeling for Aircraft Engine Run-to-Failure Simulation. In Proceedings of the 2008 International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008; pp. 1–9. [Google Scholar]
- Zhang, Y. Aeroengine Fault Prediction Based on Bidirectional LSTM Neural Network. In Proceedings of the 2020 International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Fuzhou, China, 12–14 June 2020; pp. 317–320. [Google Scholar]
- Liu, X.; Tian, Y.; Lei, X.; Liu, M.; Wen, X.; Huang, H.; Wang, H. Deep forest based intelligent fault diagnosis of hydraulic turbine. J. Mech. Sci. Technol. 2019, 33, 2049–2058. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Symbol | Description | Units |
|---|---|---|---|
| 1 | T2 | Total temperature at fan inlet | ºR |
| 2 | T24 | Total temperature at LPC outlet | ºR |
| 3 | T30 | Total temperature at HPC outlet | ºR |
| 4 | T50 | Total temperature at LPT outlet | ºR |
| 5 | P2 | Pressure at fan inlet | psia |
| 6 | P15 | Total pressure in bypass-duct | psia |
| 7 | P30 | Total pressure at HPC outlet | psia |
| 8 | Nf | Physical fan speed | rpm |
| 9 | Nc | Physical core speed | rpm |
| 10 | epr | Engine pressure ratio (P50/P2) | -- |
| 11 | Ps30 | Static pressure at HPC outlet | psia |
| 12 | phi | Ratio of fuel flow to Ps30 | pps/psi |
| 13 | NRf | Corrected fan speed | rpm |
| 14 | NRc | Corrected core speed | rpm |
| 15 | BPR | Bypass ratio | -- |
| 16 | farB | Burner fuel–air ratio | -- |
| 17 | htBleed | Bleed enthalpy | -- |
| 18 | Nf_dmd | Demanded fan speed | rpm |
| 19 | PCNfR_dmd | Demanded corrected fan speed | rpm |
| 20 | W31 | HPT coolant bleed | lbm/s |
| 21 | W32 | LPT coolant bleed | lbm/s |
| Operating Cycle | Sensor #1 (ºR) | Sensor #2 (ºR) | Sensor #3 (ºR) | Sensor #21 (lbm·s−1) | |
|---|---|---|---|---|---|
| 1 | 518.67 | 641.82 | 1589.70 | 23.42 | |
| 2 | 518.67 | 642.15 | 1591.82 | 23.42 | |
| 3 | 518.67 | 642.35 | 1587.99 | 23.34 | |
| 192 | 518.67 | 643.54 | 1601.41 | 22.96 |
| Feature Dimension | Prognostic Accuracy (%) |
|---|---|
| 4 | 97.23 |
| 8 | 97.73 |
| 12 | 98.13 |
| 16 | 97.55 |
| Running Cycle | Real RUL | Deg1 (%) | Deg2 (%) | Deg3 (%) | Order | Stock | Maintenance |
|---|---|---|---|---|---|---|---|
| 90 | 45 | 96.64 | 3.19 | 0.17 | 0 | 0 | 0 |
| 100 | 35 | 97.01 | 2.85 | 0.14 | 0 | 0 | 0 |
| 110 | 25 | 76.51 | 22.47 | 1.01 | 1 | 0 | 0 |
| 120 | 15 | 37.31 | 58.54 | 4.15 | 1 | 0 | 0 |
| 130 | 5 | 2.29 | 15.10 | 82.61 | 1 | 1 | 1 |
| 300 | 41 | 94.75 | 5.02 | 0.23 | 0 | 0 | 0 |
| 310 | 31 | 91.33 | 8.28 | 0.39 | 0 | 0 | 0 |
| 320 | 21 | 26.81 | 65.99 | 7.20 | 1 | 0 | 0 |
| 330 | 11 | 6.57 | 39.58 | 53.85 | 1 | 0 | 1 |
| 110 | 45 | 99.95 | 0.05 | 0.00 | 0 | 0 | 0 |
| 120 | 35 | 99.90 | 0.09 | 0.01 | 0 | 0 | 0 |
| 130 | 25 | 72.29 | 26.24 | 1.47 | 1 | 0 | 0 |
| 140 | 15 | 42.48 | 53.87 | 3.65 | 1 | 0 | 0 |
| 150 | 5 | 1.72 | 11.24 | 87.04 | 1 | 1 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, H.; Chen, C.; Lu, N.; Wang, C. Deep Auto-Encoder and Deep Forest-Assisted Failure Prognosis for Dynamic Predictive Maintenance Scheduling. Sensors 2021, 21, 8373. https://doi.org/10.3390/s21248373
Yu H, Chen C, Lu N, Wang C. Deep Auto-Encoder and Deep Forest-Assisted Failure Prognosis for Dynamic Predictive Maintenance Scheduling. Sensors. 2021; 21(24):8373. https://doi.org/10.3390/s21248373
Chicago/Turabian StyleYu, Hui, Chuang Chen, Ningyun Lu, and Cunsong Wang. 2021. "Deep Auto-Encoder and Deep Forest-Assisted Failure Prognosis for Dynamic Predictive Maintenance Scheduling" Sensors 21, no. 24: 8373. https://doi.org/10.3390/s21248373
APA StyleYu, H., Chen, C., Lu, N., & Wang, C. (2021). Deep Auto-Encoder and Deep Forest-Assisted Failure Prognosis for Dynamic Predictive Maintenance Scheduling. Sensors, 21(24), 8373. https://doi.org/10.3390/s21248373