
Metaknowledge Enhanced Open Domain Question Answering with Wiki Documents


Abstract
:1. Introduction
2. Related Work
2.1. Knowledge Base Question Answering (KBQA)
2.2. Graph Neural Networks for Graph Embedding
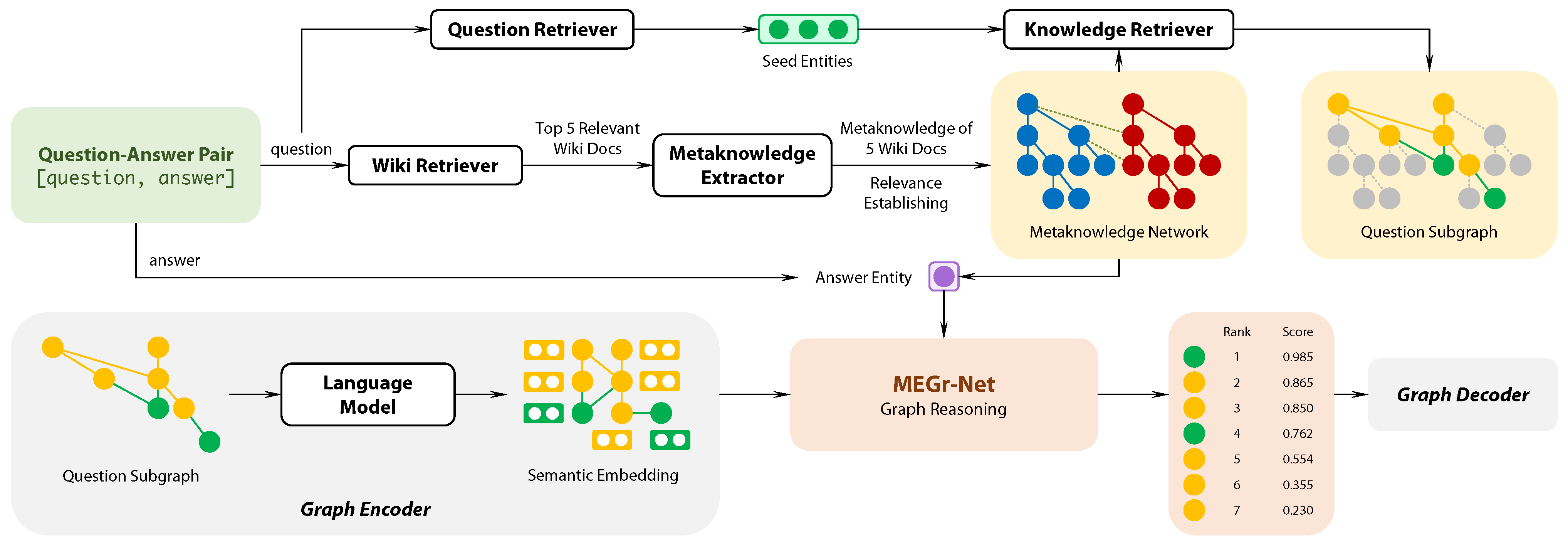
3. Approach
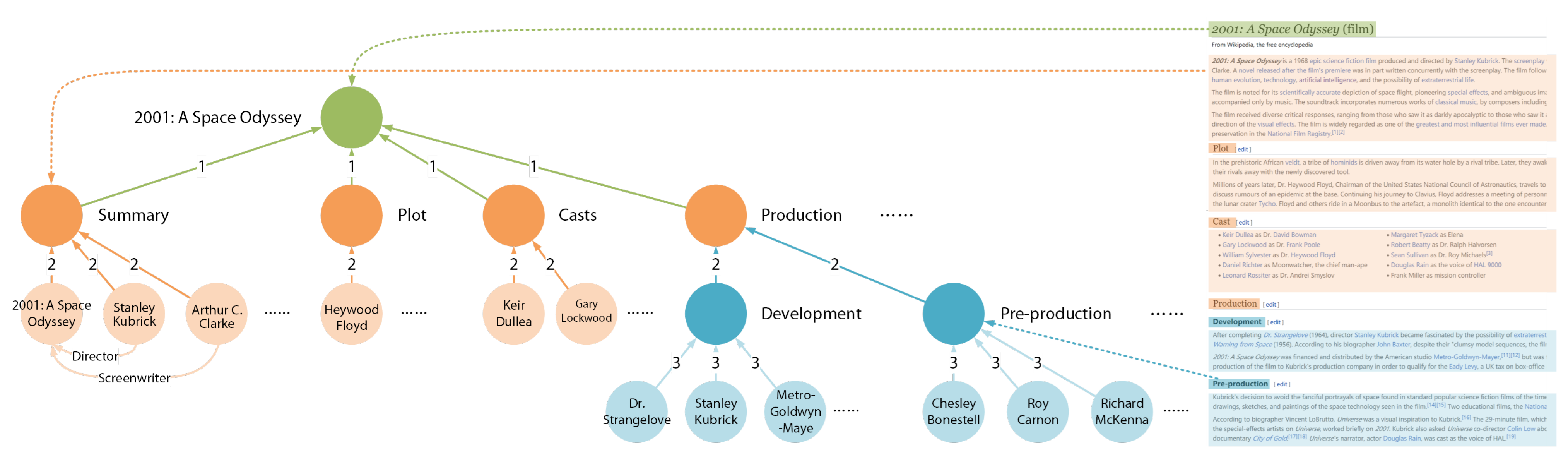
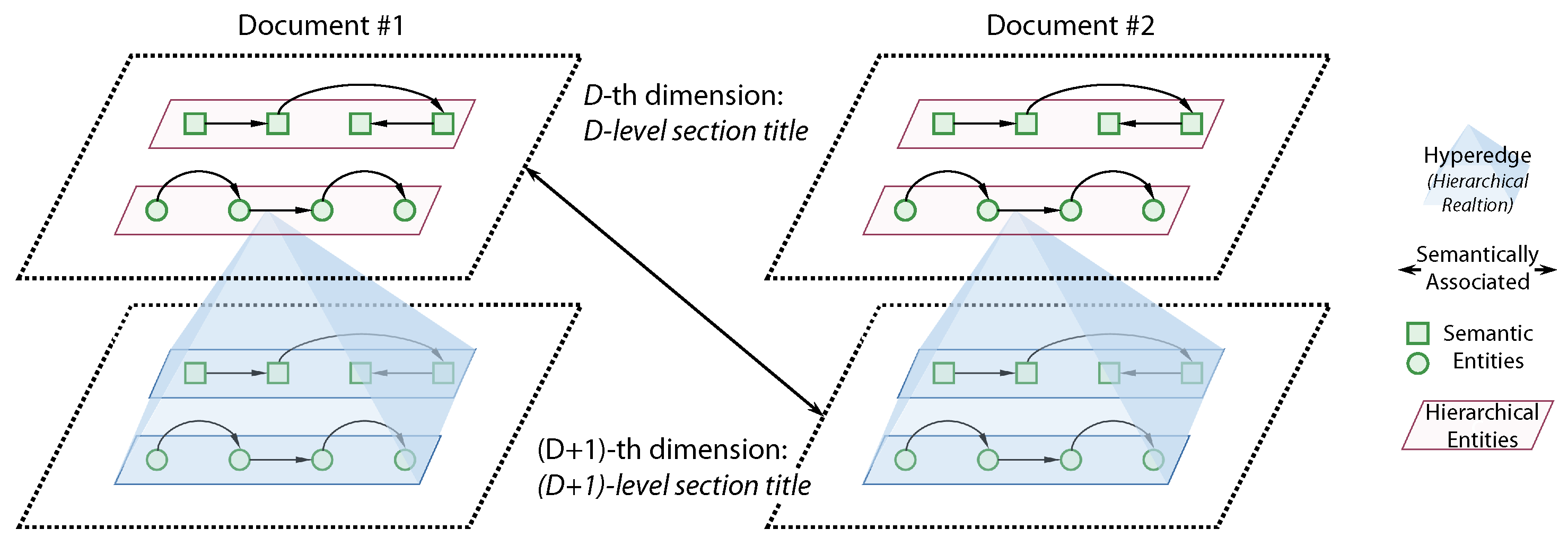
3.1. Generating Metaknowledge

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 |
3.2. Building Metaknowledge Network
3.3. Metaknowledge Encoding
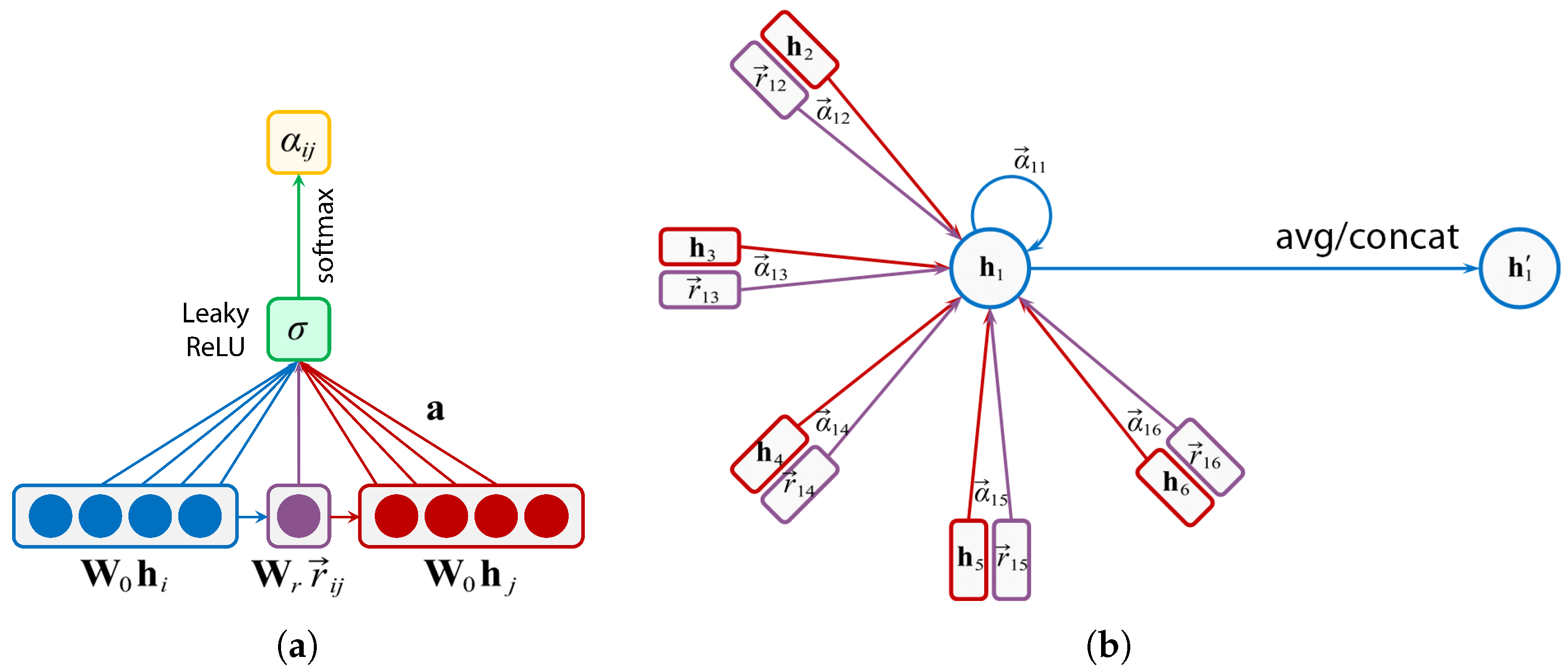
3.4. Graph Reasoning: MEGr-Net
4. Experiments
4.1. Datasets and Set-Ups
4.2. Experimental Control Groups
- Hierarchical metaknowledge and non-hierarchical triplet-based knowledge. This is the focus of this section, that is, what improvement hierarchical metaknowledge can make on open domain question answering compared with non-hierarchical triplet-based knowledge—in other words, whether metaknowledge and metaknowledge network have superiority in open domain QA tasks. As described in Section 3.1, considering the extraction quality of open domain entities and relationships by open source NLP models, this section uses the same data and extraction models to build a metaknowledge network (referred to as MK-Net in the experiment) and triplet knowledge base (referred to as Tri-KB) by the metaknowledge structure proposed in the beginning of Section 3 and the general triplet-based knowledge structure, respectively.
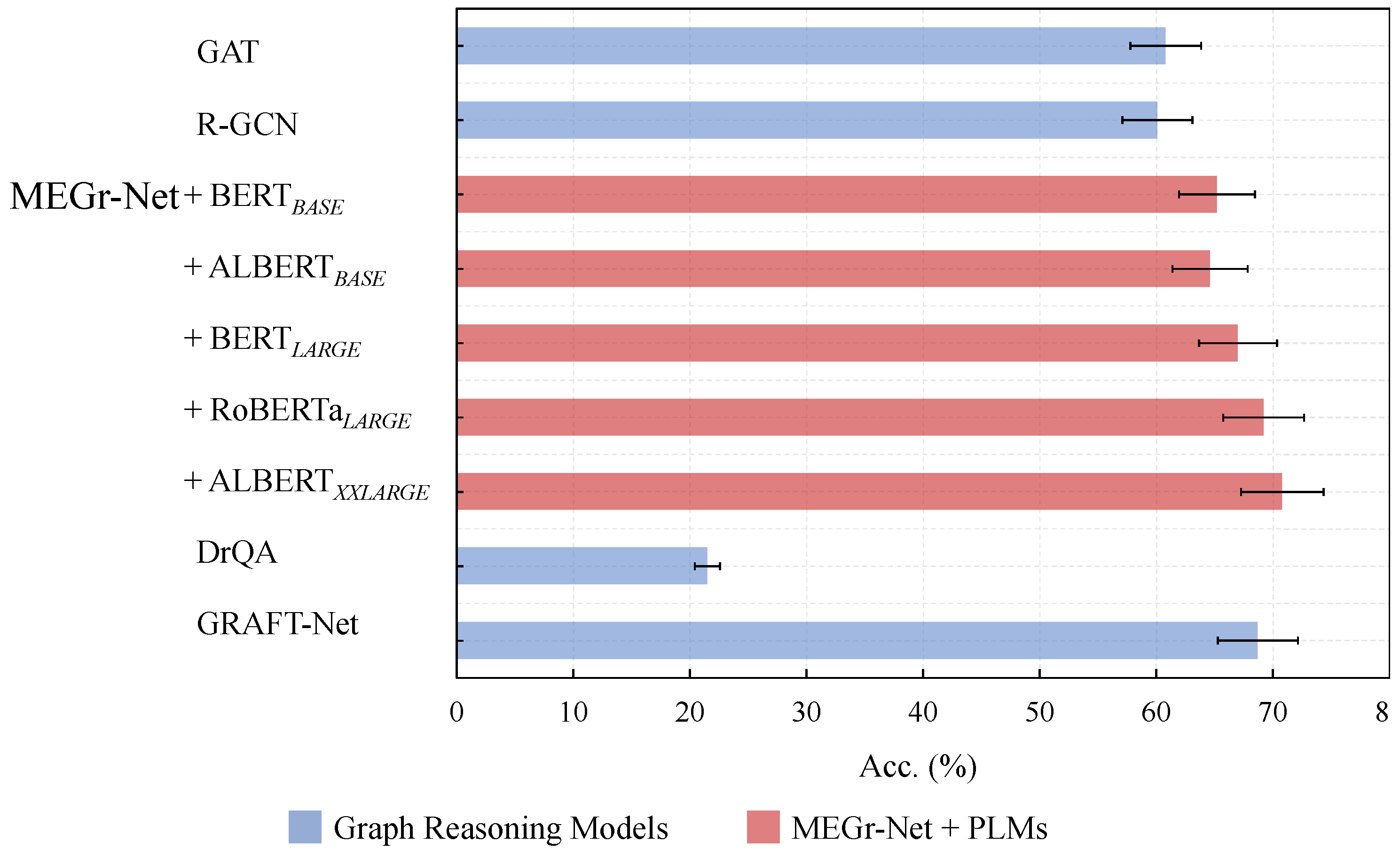
- Graph reasoning model. MEGr-Net, based on GAT, essentially achieves an improvement of graph data with complex relationships, like metaknowledge. Meanwhile, it partially adopts the relationship processing approach in R-GCN. Therefore, this section takes GAT and R-GCN as test baselines and compares them with MEGr-Net. To explain the impact of (meta)knowledge extraction quality on the results, this section introduces the results of DrQA [21] and GRAFT-Net [22] on the entire WebQuestionsSP as a reference.
- Pre-trained language models (PLMs). The input of MEGr-Net is the question subgraph encoded by GE4MK, and its semantic features mainly come from the text embedding vector encoded by the PLM in GE4MK. Therefore, different PLMs may exert different impact on the semantic feature richness of the problem subgraph. This section takes BERT as the baseline and RoBERTa [33] and ALBERT [36] as the control groups.
4.3. Results and Analysis
5. Discussion
5.1. Metaknowledge and Metaknowledge Network Modeling
5.2. MbQA and Graph Reasoning
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Appendix A. Experimental Environments of Hardware and Software
| Server #1: Providing BERT Embedding Service | ||
|---|---|---|
| Hard-ware Env. | CPU | 2 × Intel Xeon E5-2678 v3 (48) @ 3.300 GHz |
| RAM | 32 GB | |
| GPU | 4 × NVIDIA GV102 (11 GB VRAM) | |
| Software Env. | OS | Ubuntu 18.04.5 LTS |
| Python | Python 3.6.5: Anaconda | |
| PyTorch | 1.6.0 (for GPU) | |
| TensorFlow | 1.15.0 (for GPU) | |
| Server #2: Main Experimental Environment | ||
|---|---|---|
| Hard-ware Env. | CPU | 2 × Intel Xeon Silver 4210R (40) @ 3.200 GHz |
| RAM | 256 GB | |
| GPU | 4 × NVIDIA Tesla V100S (32 GB VRAM, using 1) | |
| Software Env. | OS | Ubuntu 20.04.2 LTS |
| Python | Python 3.7.7: Anaconda | |
| PyTorch | 1.9.0 (for GPU) | |
| TensorFlow | 1.15.0 (for GPU) | |
Appendix B. PLMs Used in This Work
- : https://huggingface.co/bert-base-uncased/tree/main (accessed on 9 December 2021).
- : https:///huggingface.co/bert-large-uncased/tree/main (accessed on 9 December 2021).
- : https://huggingface.co/roberta-large/tree/main (accessed on 9 December 2021).
- : https://huggingface.co/albert-base-v2/tree/main (accessed on 9 December 2021).
- : https://huggingface.co/albert-xxlarge-v2/tree/main (accessed on 9 December 2021).
References
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A nucleus for a web of open data. In Proceedings of the 6th International Semantic Web and 2nd Asian Semantic Web Conference, Busan, Korea, 11–15 November 2007; Volume 4825, pp. 722–735. [Google Scholar]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008; pp. 1247–1250. [Google Scholar]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Lan, Y.; He, G.; Jiang, J.; Jiang, J.; Zhao, W.X.; Wen, J.R. A Survey on Complex Knowledge Base Question Answering: Methods, Challenges and Solutions. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 21–26 August 2021; Volume 5, pp. 4483–4491. [Google Scholar]
- Zhang, N.; Jia, Q.; Deng, S.; Chen, X.; Ye, H.; Chen, H.; Tou, H.; Huang, G.; Wang, Z.; Hua, N.; et al. AliCG: Fine-grained and Evolvable Conceptual Graph Construction for Semantic Search at Alibaba. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 3895–3905. [Google Scholar]
- Li, Z.; Ding, X.; Liu, T. Constructing Narrative Event Evolutionary Graph for Script Event Prediction. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 4201–4207. [Google Scholar]
- Liu, S.K.; Xu, R.L.; Geng, B.Y.; Sun, Q.; Duan, L.; Liu, Y.M. Metaknowledge Extraction Based on Multi-Modal Documents. IEEE Access 2021, 9, 50050–50060. [Google Scholar] [CrossRef]
- Evans, J.A.; Foster, J.G. Metaknowledge. Science 2011, 331, 721–725. [Google Scholar] [CrossRef] [PubMed]
- Wu, P.; Zhang, X.; Feng, Z. A Survey of Question Answering over Knowledge Base. In Proceedings of the China Conference on Knowledge Graph and Semantic Computing, Hangzhou, China, 24–27 August 2019; pp. 86–97. [Google Scholar]
- Tunstall-Pedoe, W. True Knowledge: Open-Domain Question Answering Using Structured Knowledge and Inference. AI Mag. 2010, 31, 80–92. [Google Scholar] [CrossRef] [Green Version]
- Berant, J.; Chou, A.; Frostig, R.; Liang, P. Semantic Parsing on Freebase from Question-Answer Pairs. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1533–1544. [Google Scholar]
- Yih, S.W.; Chang, M.W.; He, X.; Gao, J. Semantic Parsing via Staged Query Graph Generation: Question Answering with Knowledge Base. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; Volume 1, pp. 1321–1331. [Google Scholar]
- Dong, L.; Lapata, M. Language to Logical Form with Neural Attention. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; Volume 1, pp. 33–43. [Google Scholar]
- Xu, K.; Wu, L.; Wang, Z.; Yu, M.; Chen, L.; Sheinin, V. Exploiting Rich Syntactic Information for Semantic Parsing with Graph-to-Sequence Model. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 Octobe–4 November 2018; pp. 918–924. [Google Scholar]
- Liang, C.; Berant, J.; Le, Q.V.; Forbus, K.D.; Lao, N. Neural Symbolic Machines: Learning Semantic Parsers on Freebase with Weak Supervision. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 23–33. [Google Scholar]
- Qiu, Y.; Zhang, K.; Wang, Y.; Jin, X.; Bai, L.; Guan, S.; Cheng, X. Hierarchical Query Graph Generation for Complex Question Answering over Knowledge Graph. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, 19–23 October 2020; pp. 1285–1294. [Google Scholar]
- Bordes, A.; Usunier, N.; Chopra, S.; Weston, J. Large-scale Simple Question Answering with Memory Networks. arXiv 2015, arXiv:1506.02075. [Google Scholar]
- Dong, L.; Wei, F.; Zhou, M.; Xu, K. Question Answering over Freebase with Multi-Column Convolutional Neural Networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; Volume 1, pp. 260–269. [Google Scholar]
- Jain, S. Question Answering over Knowledge Base using Factual Memory Networks. In Proceedings of the NAACL Student Research Workshop, San Diego, CA, USA, 12–17 June 2016; pp. 109–115. [Google Scholar]
- Chen, Z.Y.; Chang, C.H.; Chen, Y.P.; Nayak, J.; Ku, L.W. UHop: An Unrestricted-Hop Relation Extraction Framework for Knowledge-Based Question Answering. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 345–356. [Google Scholar]
- Chen, D.; Fisch, A.; Weston, J.; Bordes, A. Reading Wikipedia to Answer Open-Domain Questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 1870–1879. [Google Scholar]
- Sun, H.; Dhingra, B.; Zaheer, M.; Mazaitis, K.; Salakhutdinov, R.; Cohen, W.W. Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 Octobe–4 November 2018; pp. 4231–4242. [Google Scholar]
- Fang, Y.; Sun, S.; Gan, Z.; Pillai, R.; Wang, S.; Liu, J. Hierarchical Graph Network for Multi-hop Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual Event, 16–20 November 2020; pp. 8823–8838. [Google Scholar]
- Li, Q.; Tang, X.; Jian, Y. Adversarial Learning with Bidirectional Attention for Visual Question Answering. Sensors 2021, 21, 7164. [Google Scholar] [CrossRef] [PubMed]
- Guo, Z.; Han, D. Multi-Modal Explicit Sparse Attention Networks for Visual Question Answering. Sensors 2020, 20, 6758. [Google Scholar] [CrossRef] [PubMed]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Schlichtkrull, M.S.; Kipf, T.N.; Bloem, P.; van den Berg, R.; Titov, I.; Welling, M. Modeling Relational Data with Graph Convolutional Networks. Proceedings of the 15th International Conference on Extended Semantic Web Conference, ESWC 2018, 2018, pp. 593–607. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Qi, P.; Zhang, Y.; Zhang, Y.; Bolton, J.; Manning, C.D. Stanza: A Python Natural Language Processing Toolkit for Many Human Languages. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Online Conference, 5–10 July 2020; pp. 101–108. [Google Scholar]
- Han, X.; Gao, T.; Yao, Y.; Ye, D.; Liu, Z.; Sun, M. OpenNRE: An Open and Extensible Toolkit for Neural Relation Extraction. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP): System Demonstrations, Hong Kong, China, 3–7 November 2019; pp. 169–174. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K.N. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.G.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 5753–5763. [Google Scholar]
- Tau Yih, W.; Richardson, M.; Meek, C.; Chang, M.W.; Suh, J. The Value of Semantic Parse Labeling for Knowledge Base Question Answering. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin, Germany, 7–12 August 2016; Volume 2, pp. 201–206. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. In Proceedings of the ICLR 2020: Eighth International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Han, J.; Cheng, B.; Wang, X. Open Domain Question Answering based on Text Enhanced Knowledge Graph with Hyperedge Infusion. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16–20 November 2020; pp. 1475–1481. [Google Scholar]
- Ma, Y.; Ren, Z.; Jiang, Z.; Tang, J.; Yin, D. Multi-Dimensional Network Embedding with Hierarchical Structure. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Los Angeles, CA, USA, 5–9 February 2018; pp. 387–395. [Google Scholar]
- Yasunaga, M.; Ren, H.; Bosselut, A.; Liang, P.; Leskovec, J. QA-GNN: Reasoning with Language Models and Knowledge Graphs for Question Answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online Event, 6–11 June 2021; pp. 535–546. [Google Scholar]






| Entities | Relations | ||
|---|---|---|---|
| ENT_ID type content weight title up_id | Entity ID Entity Type Entity Textual Content Entity Weight Document Title Upper Hierarchical Entity ID | REL_ID type head_ID tail_ID weight | Relation ID Relation Type Head Entity ID Tail Entity ID Relation Weight |
| Parameters | Values |
|---|---|
| Epochs | 200 |
| Learning Rate | 5 |
| Attention Heads k | 8 |
| Dimension of Entity Features | 1000 |
| Dimension of Relation Features | 500 |
| Hidden Units | 1000 |
| (Meta) Knowledge Network | IH-Acc . |
|---|---|
| Tri-KB | 0.483 |
| MK-Net | 0.652 |
| Graph Reasoning Models | Acc. | |
|---|---|---|
| Baselines | GAT (MK-Net) | 0.608 (IH ) |
| R-GCN (MK-Net) | 0.601 (IH) | |
| MEGr-Net (MK-Net) | 0.652 (IH) | |
| DrQA (doc only) | 0.215 | |
| GRAFT-Net (KB+doc) | 0.687 | |
| MEGr-Net | PLMs | IH-Acc. |
|---|---|---|
| Baseline | +BERT | 0.652 |
| +ALBERT | 0.646 | |
| +BERT | 0.670 | |
| +RoBERTa | 0.692 | |
| +ALBERT | 0.708 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Xu, R.; Duan, L.; Li, M.; Liu, Y. Metaknowledge Enhanced Open Domain Question Answering with Wiki Documents. Sensors 2021, 21, 8439. https://doi.org/10.3390/s21248439
Liu S, Xu R, Duan L, Li M, Liu Y. Metaknowledge Enhanced Open Domain Question Answering with Wiki Documents. Sensors. 2021; 21(24):8439. https://doi.org/10.3390/s21248439
Chicago/Turabian StyleLiu, Shukan, Ruilin Xu, Li Duan, Mingjie Li, and Yiming Liu. 2021. "Metaknowledge Enhanced Open Domain Question Answering with Wiki Documents" Sensors 21, no. 24: 8439. https://doi.org/10.3390/s21248439