
Improved Action Recognition with Separable Spatio-Temporal Attention Using Alternative Skeletal and Video Pre-Processing



Abstract
:1. Introduction
2. Motivation
3. Alternative Skeletal and Video Pre-Processing
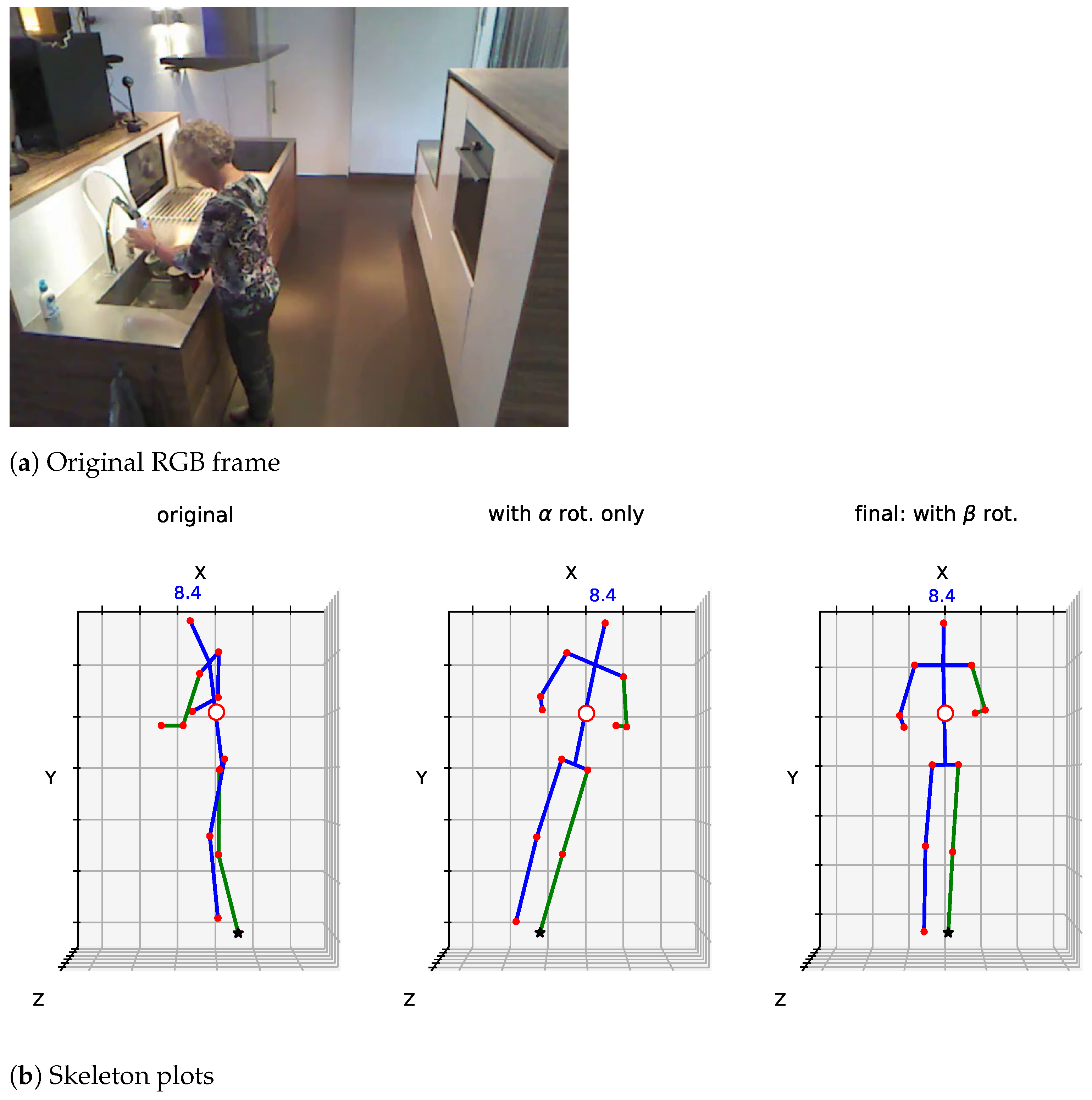
3.1. Skeletal Pre-Processing
3.2. Video Data Pre-Processing
3.3. Experimental Setup
4. Results and Discussion
4.1. Cross-Subject Evaluation
4.2. Cross-View
4.3. Comparison to Other Methods
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Organisation for Economic Co-operation and Development. Elderly Population (Data Trends). 2020. Available online: https://data.oecd.org/pop/elderly-population.htm (accessed on 1 February 2021).
- European Commission. The 2015 Ageing Report: Underlying Assumptions and Projection Methodologies. 2015. Available online: http://ec.europa.eu/economy_finance/publications/european_economy/2014/pdf/ee8_en.pdf (accessed on 1 February 2021).
- Colby, S.; Ortman, J. Projections of the Size and Composition of the US Population: 2014 to 2060. 2015. Available online: https://www.census.gov/content/dam/Census/library/publications/2015/demo/p25-1143.pdf (accessed on 1 February 2021).
- European Comission. Active Ageing: Special Eurobarometer 378. 2012. Available online: http://ec.europa.eu/public_opinion/archives/ebs/ebs_378_en.pdf (accessed on 1 February 2021).
- Calvaresi, D.; Cesarini, D.; Sernani, P.; Marinoni, M.; Dragoni, A.F.; Sturm, A. Exploring the ambient assisted living domain: A systematic review. J. Ambient. Intell. Humaniz. Comput. 2017, 8, 239–257. [Google Scholar] [CrossRef]
- Gorelick, L.; Blank, M.; Shechtman, E.; Irani, M.; Basri, R. Actions as Space-Time Shapes. Trans. Pattern Anal. Mach. Intell. 2007, 29, 2247–2253. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: A local SVM approach. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 26 August 2004; Volume 3, pp. 32–36. [Google Scholar]
- Firman, M. RGBD Datasets: Past, Present and Future. In Proceedings of the CVPR Workshop on Large Scale 3D Data: Acquisition, Modelling and Analysis, Las Vegas, NV, USA, 1 July 2016. [Google Scholar]
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3d points. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 9–14. [Google Scholar]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 29–30 September 2015; pp. 168–172. [Google Scholar]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Mining actionlet ensemble for action recognition with depth cameras. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1290–1297. [Google Scholar]
- Ni, B.; Wang, G.; Moulin, P. RGBD-HuDaAct: A Color-Depth Video Database for Human Daily Activity Recognition. In Proceedings of the IEEE Workshop on Consumer Depth Cameras for Computer Vision in Conjunction with ICCV, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Sung, J.; Ponce, C.; Selman, B.; Saxena, A. Unstructured human activity detection from rgbd images. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 842–849. [Google Scholar]
- Wang, J.; Nie, X.; Xia, Y.; Wu, Y.; Zhu, S.C. Cross-view action modeling, learning and recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2649–2656. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. NTU RGB+D 120: A Large-Scale Benchmark for 3D Human Activity Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Das, S.; Dai, R.; Koperski, M.; Minciullo, L.; Garattoni, L.; Bremond, F.; Francesca, G. Toyota Smarthome: Real-World Activities of Daily Living. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar] [CrossRef] [Green Version]
- Shotton, J.; Girshick, R.; Fitzgibbon, A.; Sharp, T.; Cook, M.; Finocchio, M.; Moore, R.; Kohli, P.; Criminisi, A.; Kipman, A.; et al. Efficient human pose estimation from single depth images. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2821–2840. [Google Scholar] [CrossRef] [PubMed]
- Güler, R.A.; Neverova, N.; Kokkinos, I. Densepose: Dense human pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7297–7306. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 1 February 2021).
- Rogez, G.; Weinzaepfel, P.; Schmid, C. LCR-Net++: Multi-person 2D and 3D Pose Detection in Natural Images. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1146–1161. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chaaraoui, A.A.; Padilla-López, J.R.; Climent-Pérez, P.; Flórez-Revuelta, F. Evolutionary joint selection to improve human action recognition with RGB-D devices. Expert Syst. Appl. 2014, 41, 786–794. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Das, S.; Koperski, M.; Bremond, F.; Francesca, G. Deep-temporal lstm for daily living action recognition. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Das, S. LSTM Action Recognition (Code). 2018. Available online: https://github.com/srijandas07/LSTM_action_recognition (accessed on 1 February 2021).
- Das, S. Inflated 3D Convolutional Network (Code). 2019. Available online: https://github.com/srijandas07/i3d (accessed on 1 February 2021).
- Das, S.; Chaudhary, A.; Bremond, F.; Thonnat, M. Where to focus on for human action recognition? In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 71–80. [Google Scholar]
- Mahasseni, B.; Todorovic, S. Regularizing long short term memory with 3D human-skeleton sequences for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3054–3062. [Google Scholar]
- Das, S.; Sharma, S.; Dai, R.; Bremond, F.; Thonnat, M. Vpn: Learning video-pose embedding for activities of daily living. In Proceedings of the European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2020; pp. 72–90. [Google Scholar]
- Ryoo, M.S.; Piergiovanni, A.; Kangaspunta, J.; Angelova, A. Assemblenet++: Assembling modality representations via attention connections. In Proceedings of the European Conference on Computer Vision; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 654–671. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12026–12035. [Google Scholar]
- Yang, D.; Dai, R.; Wang, Y.; Mallick, R.; Minciullo, L.; Francesca, G.; Bremond, F. Selective Spatio-Temporal Aggregation Based Pose Refinement System: Towards Understanding Human Activities in Real-World Videos. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, Waikoloa, HI, USA, 5–9 January 2021; pp. 2363–2372. [Google Scholar]
- Ryoo, M.S.; Piergiovanni, A.; Tan, M.; Angelova, A. AssembleNet: Searching for multi-stream neural connectivity in video architectures. arXiv 2019, arXiv:1905.13209. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2334–2343. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime multi-person 2D pose estimation using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 172–186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chaaraoui, A.A.; Climent-Pérez, P.; Flórez-Revuelta, F. An efficient approach for multi-view human action recognition based on bag-of-key-poses. In International Workshop on Human Behavior Understanding; Springer: Berlin/Heidelberg, Germany, 2012; pp. 29–40. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Variant | MPCA (in %) | Accuracy (%) |
|---|---|---|---|
| LSTM | Das et al. [17] | 42.5 [30] | — |
| Baseline | 53.4 | ||
| Rotation | 54.5 (59.0) * | ||
| Rot. + Ds | 36.7 | 54.1 | |
| I3D | Das et al. [17] | 53.4 | — |
| Baseline | 73.0 | ||
| Full crop | 63.4 | 74.3 | |
| Separable STA | Das et al. [17] | 54.2 | 75.3 |
| Baseline | 71.1 | ||
| Rot. + Ds | 74.0 | ||
| Rotation | 63.7 | 76.5 | |
| Both, jointly | 77.1 |
| Component | Variant | MPCA (in %) | Accuracy (%) |
|---|---|---|---|
| LSTM | Das et al. [17] | 17.2 [30] | — |
| Rotation | 30.1 | 46.3 | |
| I3D | Das et al. [17] | 45.1 | — |
| Baseline | 40.0 | 53.4 | |
| Full crop | 48.2 | 63.1 | |
| Separable STA | Das et al. [17] | 50.3 | 68.2 |
| Rotation | 40.9 | 53.0 | |
| Both, frozen | 50.3 | 65.7 | |
| Both, jointly | 53.6 | 65.6 |
| Method | CS | CV | CV |
|---|---|---|---|
| separable STA [17] | 54.2 | 35.2 | 50.3 |
| VPN [31] | 60.8 | 43.8 | 53.5 |
| AssembleNet++ [32] | 63.6 | — | — |
| 2s-AGCN [33,34] | 57.1 | 22.1 | 49.7 |
| 2s-AGCN+PRS [34] | 60.9 | 22.5 | 53.5 |
| 5C-AGCN+PRS [34] | 62.1 | 22.8 | 54.0 |
| VPN+PRS [34] | 65.2 | — | 54.1 |
| Proposed (best values) | 63.7 | — | 53.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Climent-Pérez, P.; Florez-Revuelta, F. Improved Action Recognition with Separable Spatio-Temporal Attention Using Alternative Skeletal and Video Pre-Processing. Sensors 2021, 21, 1005. https://doi.org/10.3390/s21031005
Climent-Pérez P, Florez-Revuelta F. Improved Action Recognition with Separable Spatio-Temporal Attention Using Alternative Skeletal and Video Pre-Processing. Sensors. 2021; 21(3):1005. https://doi.org/10.3390/s21031005
Chicago/Turabian StyleCliment-Pérez, Pau, and Francisco Florez-Revuelta. 2021. "Improved Action Recognition with Separable Spatio-Temporal Attention Using Alternative Skeletal and Video Pre-Processing" Sensors 21, no. 3: 1005. https://doi.org/10.3390/s21031005