
Multi-Scale Frequency Bands Ensemble Learning for EEG-Based Emotion Recognition




Abstract
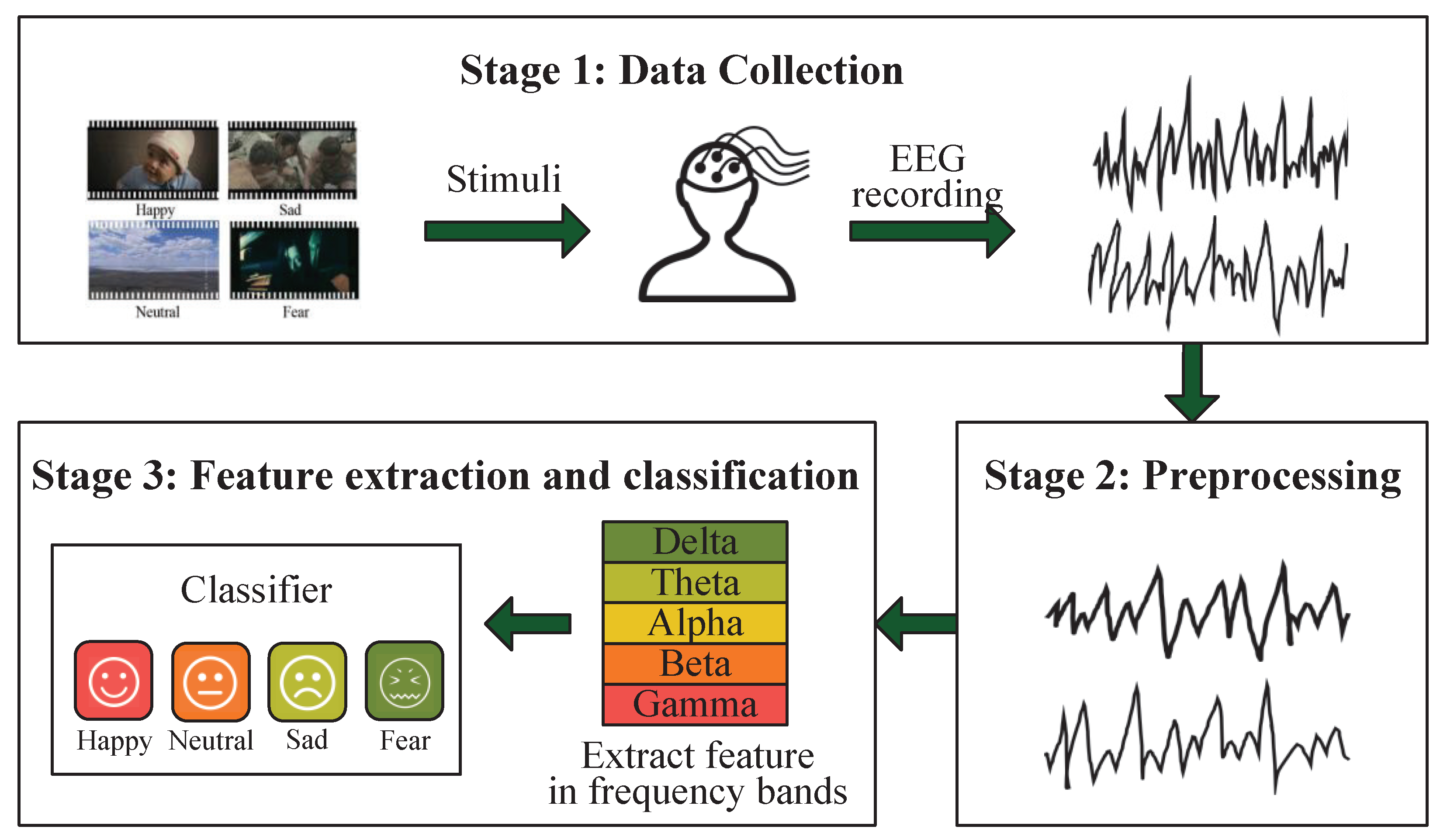
1. Introduction
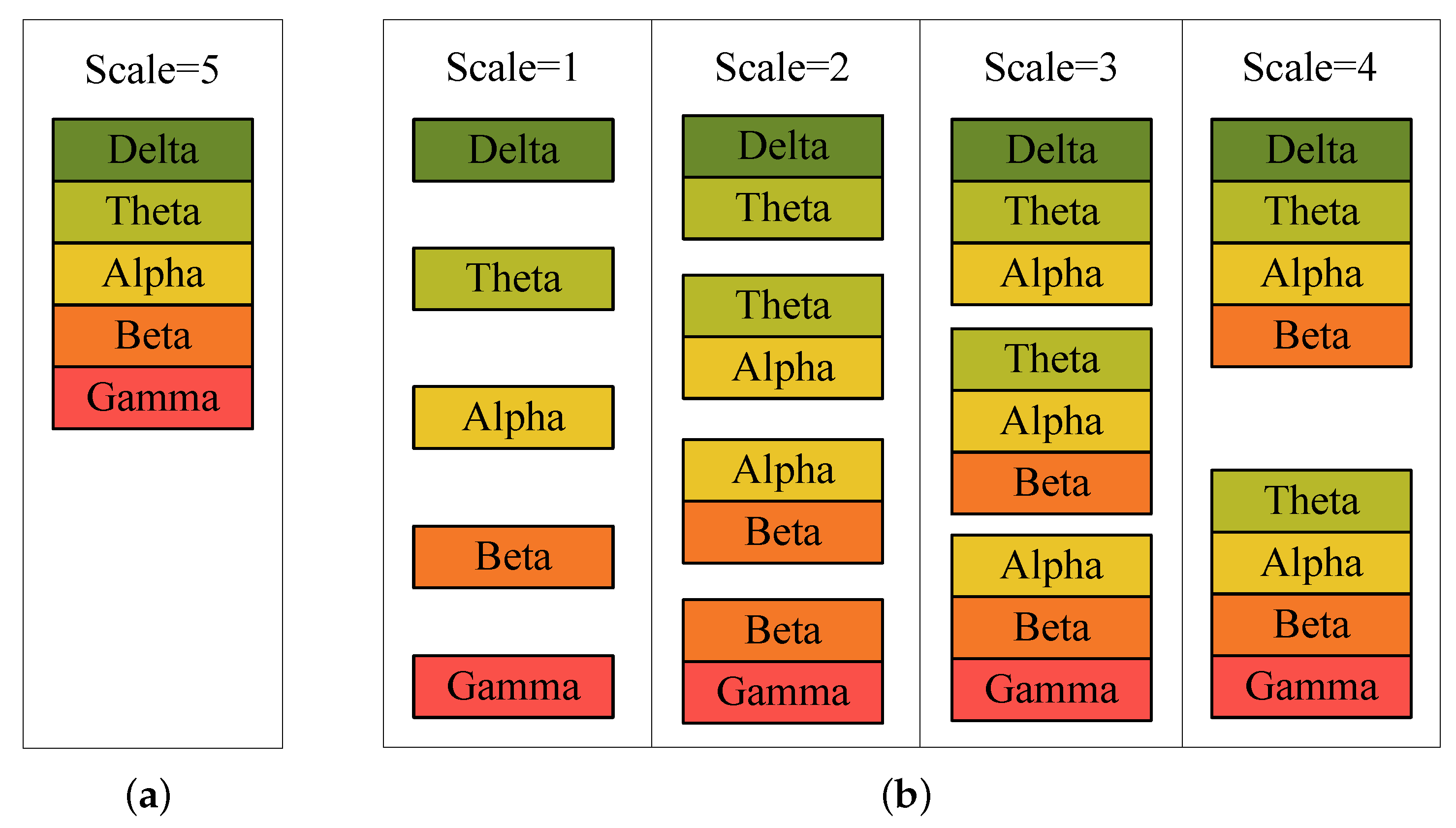
- We extended the way of combining different frequency bands into four local scales and one global scale, and then performed emotion recognition on every scale with a single-scale classifier.
- We proposed an effective adaptive weight learning method to ensemble multi-scale results, which can adaptively learn the respective weights of different scales according to the maximal margin criterion, whose objective can be formulated as a quadratic programming problem with the simplex constraint.
- We conducted extensive experiments on benchmark emotional EEG data sets, and the results demonstrated that the global scale that directly concatenating all frequency bands cannot always guarantee to obtain the best emotion recognition performance. Different scales provide complementary information to each other, and the proposed method can effectively combine these information to further improve the performance.
2. Method
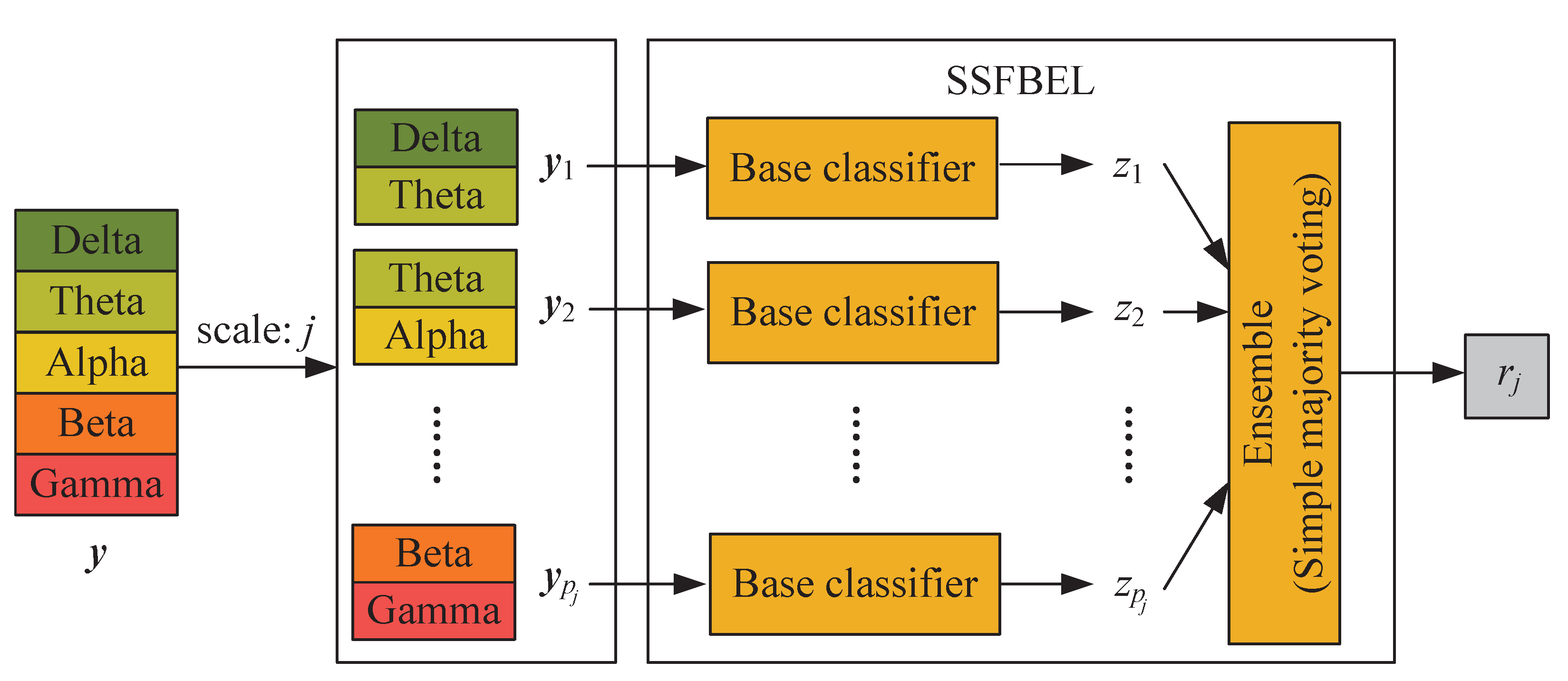
2.1. Single-Scale Frequency Band Ensemble Learning
- First, given an unlabeled DE feature-based sample , we divide it into a set of patches . Here d is the feature dimension of EEG samples. For example, if we use the DE-based EEG feature representation, d is equal to the product of the numbers of channels and frequency bands. Similarly, denotes the feature dimension of DE patches under scale j, that is, equals the product of the numbers of channels and frequency bands in a patch.
- Second, these patches are, respectively fed into base classifiers and then the corresponding predicted labels can be obtained.
- Finally, the predicted labels of all patches are combined by simple majority voting [28] to generate the final label for the sample under scale j.
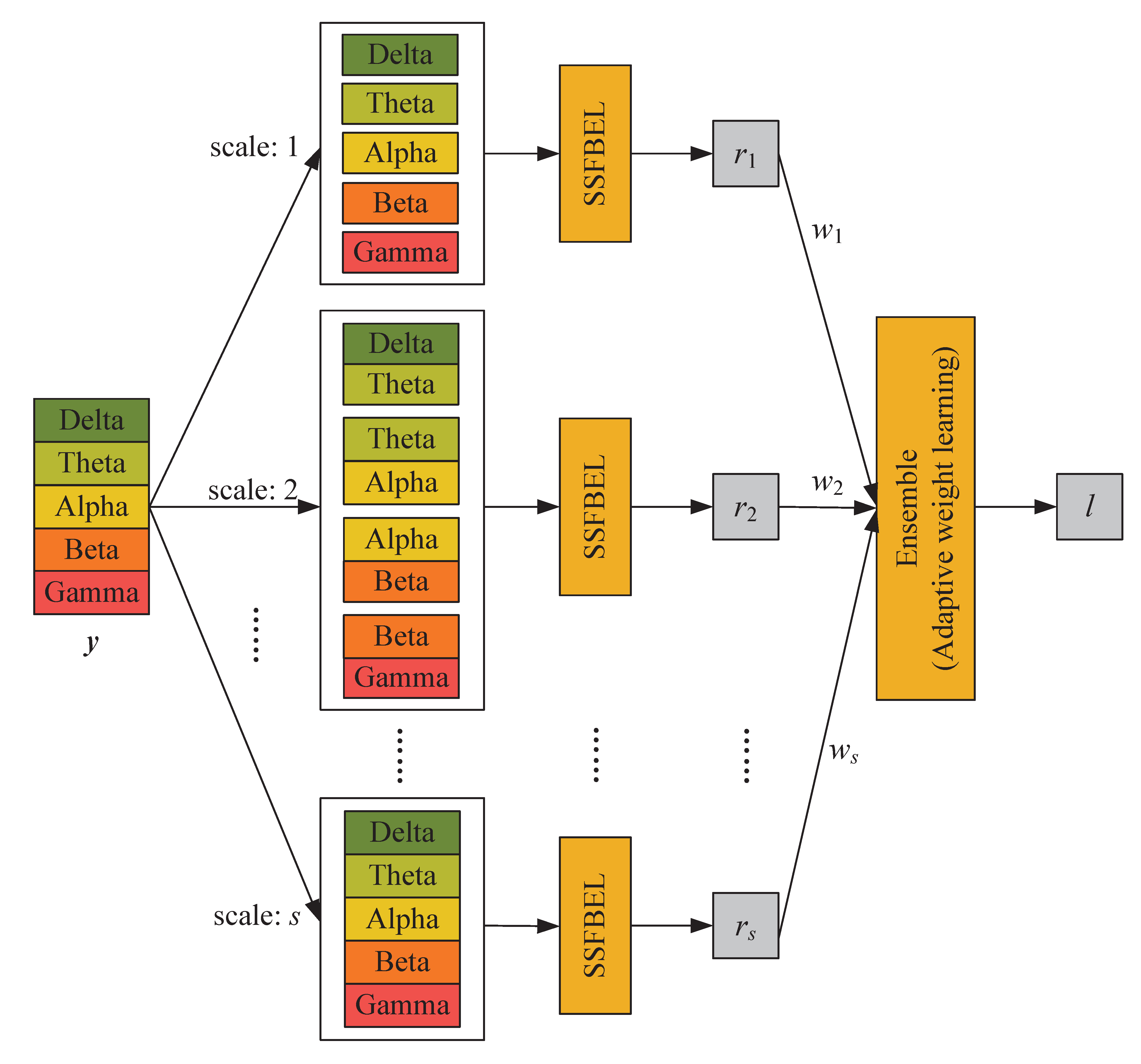
2.2. Adaptive Weight Learning
| Algorithm 1 The procedure for MSFBEL framework. |
| Input: Number of scales s, number of classes c, training data , training data label , a subset of training data , the labels of subset , testing data ; Output: The label of testing data: l. 1: for do 2: Compute the label of testing data under scale j via Algorithm 2; 3: end for 4: Compute decision matrix by Equation (4) with and ; 5: Compute and ; 6: Compute the adaptive weight via Algorithm 3; 7: Compute . |
3. Experiments and Results
| Algorithm 2 The procedure for SSFBEL framework. |
| Input:s, c, , , , where and ; Output: The label of testing data under scale j: . 1: Compute by Equation (2); 2: Compute by Equation (3); 3: Compute . |
| Algorithm 3 The algorithm to solve problem (11). |
| Input: and ; Output: The weight vector . 1: Initialize , , , and ; 2: while not converged do 3: Update by Equation (A1); 4: Update by solving problem (A3) via Algorithm 4; 5: Update ; 6: Update ; 7: end while |
| Algorithm 4 The algorithm to solve problem (A3). |
| Input:, , , and s; Output: The weight vector . 1: Compute ; 2: Compute ; 3: Use Newton’s method to obtain the root of Equation (A12); 4: The optimal solution , where . |
3.1. Data Set
3.1.1. SEED IV
3.1.2. DEAP
3.2. Experimental Settings
3.3. Experimental Results and Analysis
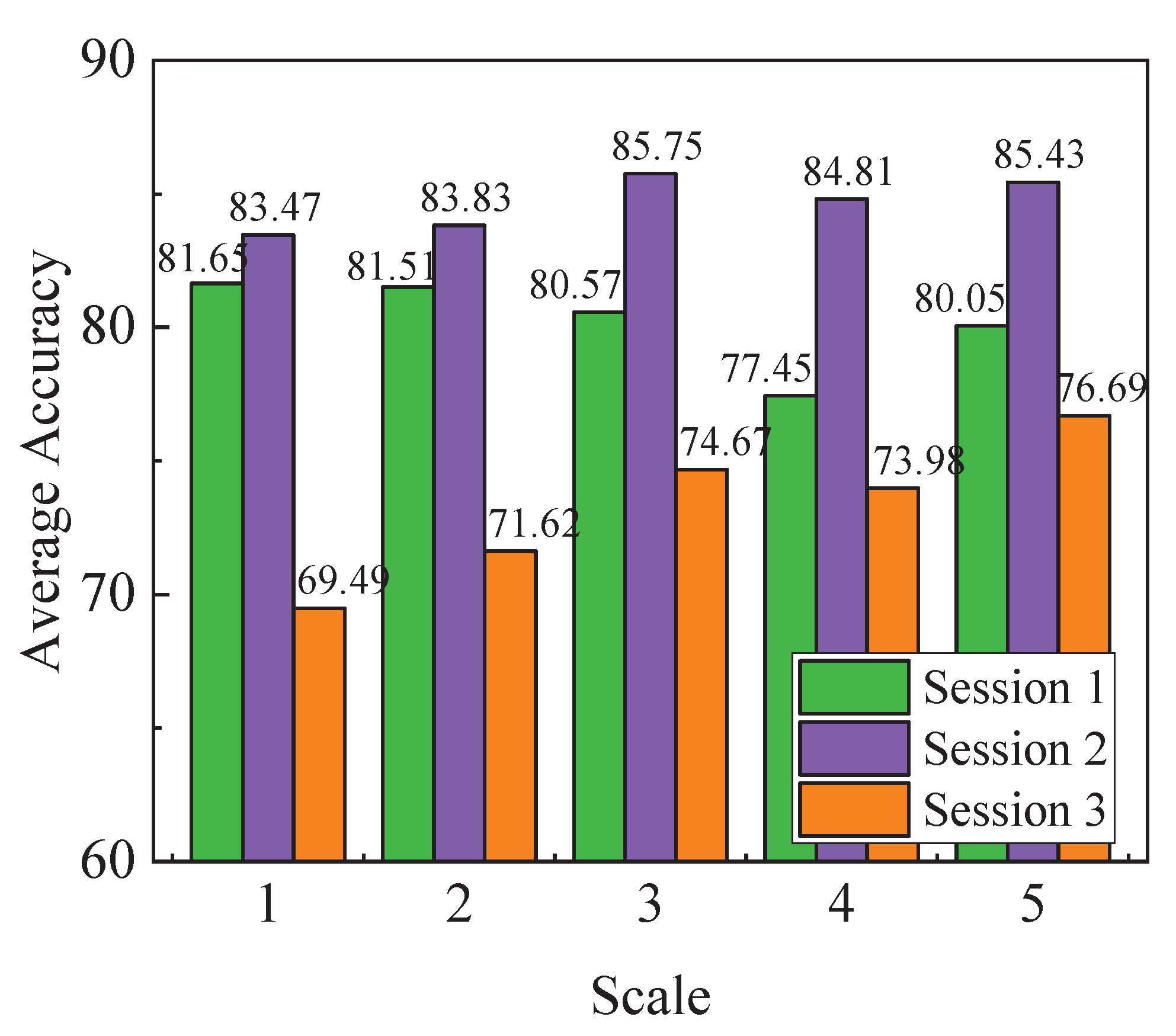
3.3.1. The Effect of Different Scales
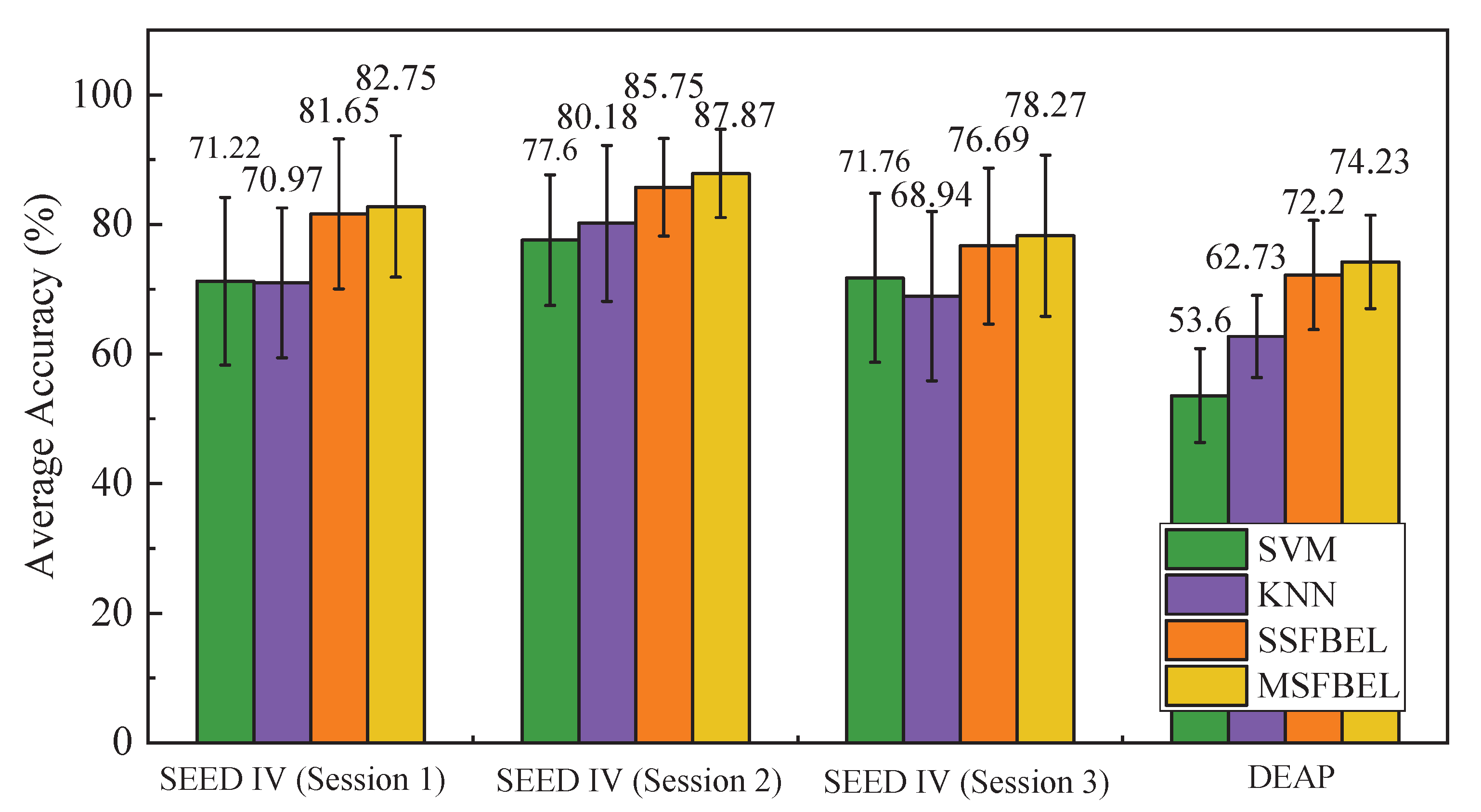
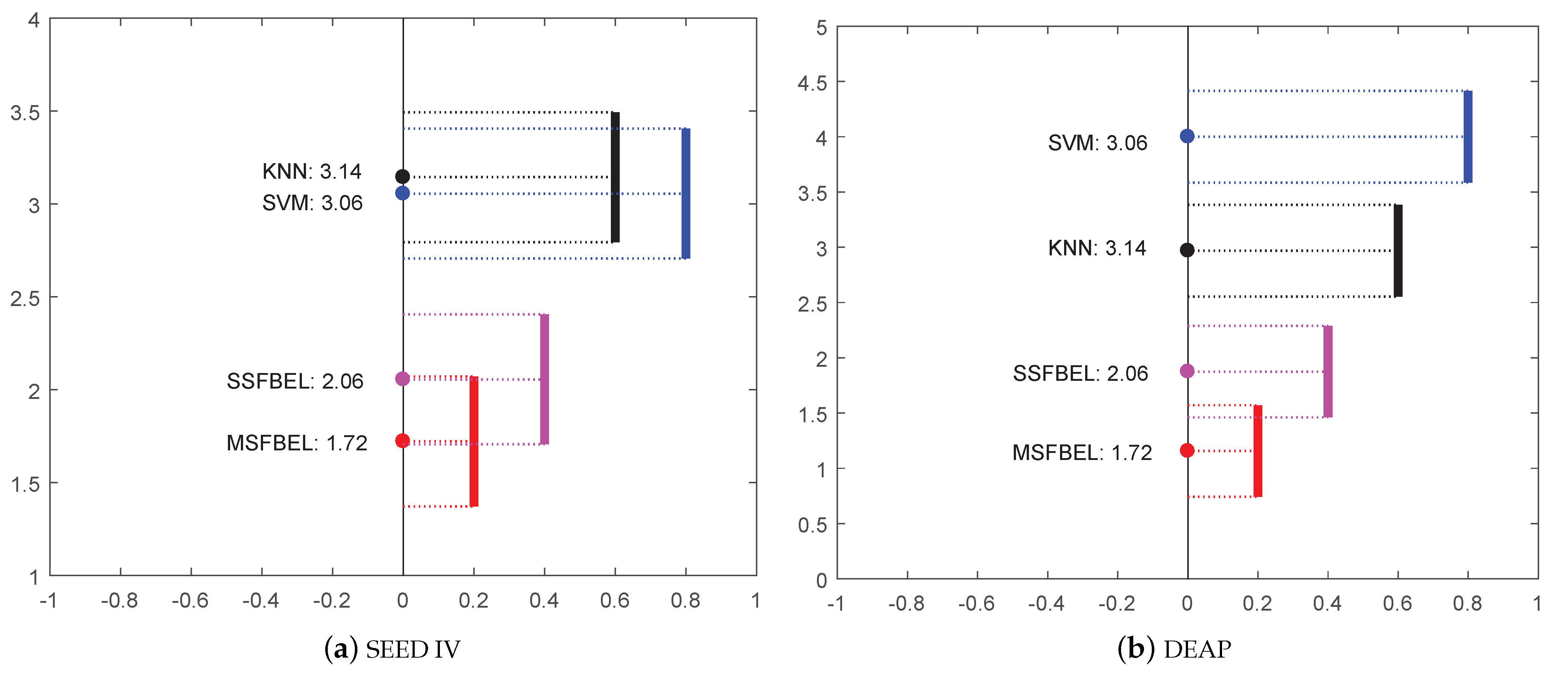
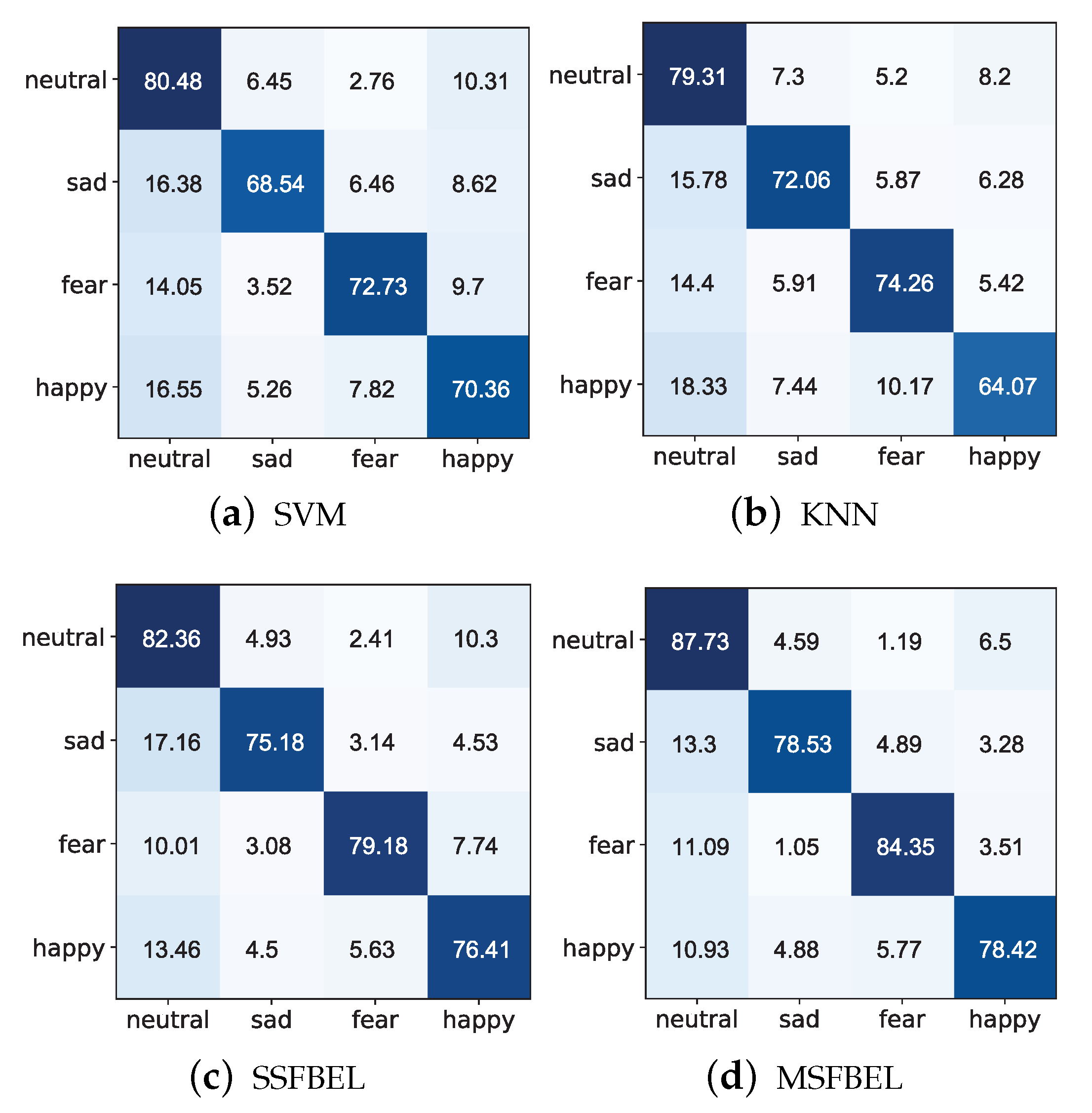
3.3.2. The Performance of MSFBEL
4. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Appendix A
References
- Cowie, R.; Douglas-Cowie, E.; Tsapatsoulis, N.; Votsis, G.; Kollias, S.; Fellenz, W.; Taylor, J.G. Emotion recognition in human-computer interaction. IEEE Signal Process. Mag. 2001, 18, 32–80. [Google Scholar] [CrossRef]
- Swangnetr, M.; Kaber, D.B. Emotional state classification in patient–robot interaction using wavelet analysis and statistics-based feature selection. IEEE Trans. Hum. Mach. Syst. 2012, 43, 63–75. [Google Scholar] [CrossRef]
- Qureshi, S.A.; Dias, G.; Hasanuzzaman, M.; Saha, S. Improving depression level estimation by concurrently learning emotion intensity. IEEE Comput. Intell. Mag. 2020, 15, 47–59. [Google Scholar] [CrossRef]
- Hu, B.; Rao, J.; Li, X.; Cao, T.; Li, J.; Majoe, D.; Gutknecht, J. Emotion regulating attentional control abnormalities in major depressive disorder: An event-related potential study. Sci. Rep. 2017, 7, 1–21. [Google Scholar] [CrossRef]
- Yang, D.; Alsadoon, A.; Prasad, P.C.; Singh, A.K.; Elchouemi, A. An emotion recognition model based on facial recognition in virtual learning environment. Procedia Comput. Sci. 2018, 125, 2–10. [Google Scholar] [CrossRef]
- Li, T.M.; Shen, W.X.; Chao, H.C.; Zeadally, S. Analysis of Students’ Learning Emotions Using EEG. In International Conference on Innovative Technologies and Learning; Springer: Cham, Switzerland, 2019; pp. 498–504. [Google Scholar]
- Zhang, J.; Zhao, S.; Yang, G.; Tang, J.; Zhang, T.; Peng, Y.; Kong, W. Emotional-state brain network analysis revealed by minimum spanning tree using EEG signals. In Proceedings of the 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Madrid, Spain, 3–6 December 2018; pp. 1045–1048. [Google Scholar]
- Peng, Y.; Li, Q.; Kong, W.; Qin, F.; Zhang, J.; Cichocki, A. A joint optimization framework to semi-supervised RVFL and ELM networks for efficient data classification. Appl. Soft Comput. 2020, 97, 106756. [Google Scholar] [CrossRef]
- Wu, S.; Xu, X.; Shu, L.; Hu, B. Estimation of valence of emotion using two frontal EEG channels. In Proceedings of the 2017 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Kansas City, MO, USA, 13–16 November 2017; pp. 1127–1130. [Google Scholar]
- Alarcao, S.M.; Fonseca, M.J. Emotions recognition using EEG signals: A survey. IEEE Trans. Affect. Comput. 2017, 10, 374–393. [Google Scholar] [CrossRef]
- Liu, Y.; Sourina, O. Real-time fractal-based valence level recognition from EEG. In Transactions on Computational Science XVIII; Springer: Berlin/Heidelberg, Germany, 2013; pp. 101–120. [Google Scholar]
- Hjorth, B. EEG analysis based on time domain properties. Electroencephalogr. Clin. Neurophysiol. 1970, 29, 306–310. [Google Scholar] [CrossRef]
- Petrantonakis, P.C.; Hadjileontiadis, L.J. Emotion recognition from EEG using higher order crossings. IEEE Trans. Inf. Technol. Biomed. 2009, 14, 186–197. [Google Scholar] [CrossRef]
- Shi, L.C.; Jiao, Y.Y.; Lu, B.L. Differential entropy feature for EEG-based vigilance estimation. In Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; pp. 6627–6630. [Google Scholar]
- Frantzidis, C.A.; Bratsas, C.; Papadelis, C.L.; Konstantinidis, E.; Pappas, C.; Bamidis, P.D. Toward emotion aware computing: An integrated approach using multichannel neurophysiological recordings and affective visual stimuli. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 589–597. [Google Scholar] [CrossRef]
- Lin, Y.P.; Wang, C.H.; Jung, T.P.; Wu, T.L.; Jeng, S.K.; Duann, J.R.; Chen, J.H. EEG-based emotion recognition in music listening. IEEE Trans. Biomed. Eng. 2010, 57, 1798–1806. [Google Scholar]
- Duan, R.N.; Zhu, J.Y.; Lu, B.L. Differential entropy feature for EEG-based emotion classification. In Proceedings of the 2013 6th International IEEE/EMBS Conference on Neural Engineering (NER), San Diego, CA, USA, 6–8 November 2013; pp. 81–84. [Google Scholar]
- Paszkiel, S. Using neural networks for classification of the changes in the EEG signal based on facial expressions. In Analysis and Classification of EEG Signals for Brain–Computer Interfaces; Springer: Cham, Switzerland, 2020; pp. 41–69. [Google Scholar]
- Chen, X.; Xu, L.; Cao, M.; Zhang, T.; Shang, Z.; Zhang, L. Design and Implementation of Human-Computer Interaction Systems Based on Transfer Support Vector Machine and EEG Signal for Depression Patients’ Emotion Recognition. J. Med. Imaging Health Inform. 2021, 11, 948–954. [Google Scholar] [CrossRef]
- Peng, Y.; Lu, B.L. Discriminative manifold extreme learning machine and applications to image and EEG signal classification. Neurocomputing 2016, 174, 265–277. [Google Scholar] [CrossRef]
- Li, J.; Zhang, Z.; He, H. Hierarchical convolutional neural networks for EEG-based emotion recognition. Cogn. Comput. 2018, 10, 368–380. [Google Scholar] [CrossRef]
- Zheng, W.L.; Lu, B.L. Investigating critical frequency bands and channels for EEG-based emotion recognition with deep neural networks. IEEE Trans. Auton. Ment. Dev. 2015, 7, 162–175. [Google Scholar] [CrossRef]
- Yang, Y.; Wu, Q.; Fu, Y.; Chen, X. Continuous convolutional neural network with 3d input for eeg-based emotion recognition. In International Conference on Neural Information Processing; Springer: Cham, Switzerland, 2018; pp. 433–443. [Google Scholar]
- Lin, D.; Tang, X. Recognize high resolution faces: From macrocosm to microcosm. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1355–1362. [Google Scholar]
- Krawczyk, B.; Minku, L.L.; Gama, J.; Stefanowski, J.; Woźniak, M. Ensemble learning for data stream analysis: A survey. Inf. Fusion 2017, 37, 132–156. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble methods in machine learning. In International Workshop on Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2000; pp. 1–15. [Google Scholar]
- Yang, P.; Hwa Yang, Y.; B Zhou, B.; Y Zomaya, A. A review of ensemble methods in bioinformatics. Curr. Bioinform. 2010, 5, 296–308. [Google Scholar] [CrossRef]
- Kumar, R.; Banerjee, A.; Vemuri, B.C. Volterrafaces: Discriminant analysis using volterra kernels. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 150–155. [Google Scholar]
- Zhang, L.; Yang, M.; Feng, X. Sparse representation or collaborative representation: Which helps face recognition? In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 471–478. [Google Scholar]
- Rosset, S.; Zhu, J.; Hastie, T. Boosting as a regularized path to a maximum margin classifier. J. Mach. Learn. Res. 2004, 5, 941–973. [Google Scholar]
- Shen, C.; Li, H. Boosting through optimization of margin distributions. IEEE Trans. Neural Netw. 2010, 21, 659–666. [Google Scholar] [CrossRef] [PubMed]
- Bonnans, J.F.; Gilbert, J.C.; Lemaréchal, C.; Sagastizábal, C.A. Numerical Optimization: Theoretical and Practical Aspects; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Nie, F.; Yang, S.; Zhang, R.; Li, X. A general framework for auto-weighted feature selection via global redundancy minimization. IEEE Trans. Image Process. 2018, 28, 2428–2438. [Google Scholar] [CrossRef] [PubMed]
- Zheng, W.L.; Liu, W.; Lu, Y.; Lu, B.L.; Cichocki, A. Emotionmeter: A multimodal framework for recognizing human emotions. IEEE Trans. Cybern. 2018, 49, 1110–1122. [Google Scholar] [CrossRef]
- Shi, L.C.; Lu, B.L. Off-line and on-line vigilance estimation based on linear dynamical system and manifold learning. In Proceedings of the 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology, Buenos Aires, Argentina, 31 August–4 September 2010; pp. 6587–6590. [Google Scholar]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. Deap: A database for emotion analysis; using physiological signals. IEEE Trans. Affect. Comput. 2011, 3, 18–31. [Google Scholar] [CrossRef]
- Yang, Y.; Wu, Q.; Qiu, M.; Wang, Y.; Chen, X. Emotion recognition from multi-channel EEG through parallel convolutional recurrent neural network. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- Li, J.; Qiu, S.; Shen, Y.Y.; Liu, C.L.; He, H. Multisource transfer learning for cross-subject EEG emotion recognition. IEEE Trans. Cybernet. 2019, 50, 3281–3293. [Google Scholar] [CrossRef] [PubMed]
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Kyrillidis, A.; Becker, S.; Cevher, V.; Koch, C. Sparse projections onto the simplex. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 235–243. [Google Scholar]
- Boyd, S.; Boyd, S.P.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Sherman, A.H. On Newton-iterative methods for the solution of systems of nonlinear equations. SIAM J. Numer. Anal. 1978, 15, 755–771. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject | Local Scale | Global Scale | |||
|---|---|---|---|---|---|
| Scale = 1 | Scale = 2 | Scale = 3 | Scale = 4 | Scale = 5 | |
| 1 | 84.85 | 73.43 | 80.19 | 76.69 | 83.68 |
| 2 | 96.04 | 100 | 100 | 90.68 | 100 |
| 3 | 82.75 | 72.26 | 81.82 | 67.60 | 82.05 |
| 4 | 100 | 92.07 | 89.74 | 89.74 | 89.74 |
| 5 | 68.30 | 73.66 | 69.00 | 75.29 | 79.72 |
| 6 | 65.73 | 79.25 | 78.55 | 72.73 | 66.67 |
| 7 | 97.20 | 96.04 | 69.93 | 76.92 | 79.72 |
| 8 | 65.03 | 79.49 | 83.22 | 70.63 | 77.86 |
| 9 | 93.47 | 93.47 | 93.47 | 93.47 | 93.47 |
| 10 | 83.45 | 74.13 | 63.64 | 65.27 | 66.20 |
| 11 | 80.19 | 69.00 | 81.82 | 75.29 | 76.46 |
| 12 | 79.95 | 77.62 | 77.62 | 74.13 | 73.66 |
| 13 | 66.67 | 75.76 | 80.65 | 76.92 | 76.69 |
| 14 | 72.49 | 84.15 | 77.39 | 70.86 | 70.86 |
| 15 | 88.58 | 82.28 | 81.59 | 85.55 | 83.92 |
| Average | 81.65 | 81.51 | 80.57 | 77.45 | 80.05 |
| Subject | Local Scale | Global Scale | |||
|---|---|---|---|---|---|
| Scale = 1 | Scale = 2 | Scale = 3 | Scale = 4 | Scale = 5 | |
| 1 | 64.06 | 67.97 | 76.28 | 72.13 | 76.28 |
| 2 | 97.56 | 91.69 | 97.56 | 96.33 | 88.51 |
| 3 | 91.20 | 85.82 | 88.75 | 91.20 | 91.20 |
| 4 | 82.89 | 88.75 | 84.11 | 88.75 | 88.75 |
| 5 | 80.93 | 82.40 | 88.51 | 88.51 | 88.51 |
| 6 | 88.75 | 92.18 | 94.13 | 85.09 | 89.49 |
| 7 | 97.31 | 97.56 | 92.91 | 97.56 | 97.56 |
| 8 | 71.15 | 78.24 | 87.04 | 78.24 | 80.93 |
| 9 | 88.75 | 75.79 | 73.11 | 73.35 | 73.11 |
| 10 | 88.75 | 94.13 | 92.91 | 94.13 | 94.13 |
| 11 | 69.68 | 82.64 | 80.68 | 78.00 | 80.68 |
| 12 | 77.26 | 79.95 | 85.57 | 71.39 | 79.95 |
| 13 | 78.97 | 73.11 | 72.37 | 79.22 | 75.79 |
| 14 | 74.82 | 73.11 | 80.68 | 86.55 | 82.40 |
| 15 | 100 | 94.13 | 91.69 | 91.69 | 94.13 |
| Average | 83.47 | 83.83 | 85.75 | 84.81 | 85.43 |
| Subject | Local Scale | Global Scale | |||
|---|---|---|---|---|---|
| Scale = 1 | Scale = 2 | Scale = 3 | Scale = 4 | Scale = 5 | |
| 1 | 60.32 | 78.82 | 80.16 | 80.43 | 69.97 |
| 2 | 89.01 | 89.01 | 89.01 | 89.01 | 89.01 |
| 3 | 56.57 | 60.59 | 61.13 | 56.57 | 78.55 |
| 4 | 89.01 | 80.16 | 89.01 | 91.96 | 89.01 |
| 5 | 64.34 | 72.12 | 72.12 | 85.79 | 72.12 |
| 6 | 70.24 | 80.97 | 88.47 | 89.01 | 89.01 |
| 7 | 89.01 | 94.91 | 84.45 | 70.24 | 84.99 |
| 8 | 63.00 | 71.58 | 78.55 | 75.87 | 86.33 |
| 9 | 54.96 | 62.73 | 62.73 | 62.73 | 66.49 |
| 10 | 64.61 | 64.61 | 69.17 | 64.61 | 74.80 |
| 11 | 67.29 | 56.57 | 61.13 | 61.13 | 61.13 |
| 12 | 54.96 | 49.06 | 49.06 | 53.62 | 53.62 |
| 13 | 61.13 | 64.34 | 61.13 | 61.13 | 61.13 |
| 14 | 79.36 | 70.24 | 95.44 | 89.01 | 95.44 |
| 15 | 78.55 | 78.55 | 78.55 | 78.55 | 78.82 |
| Average | 69.49 | 71.62 | 74.67 | 73.98 | 76.79 |
| Subject | Local Scale | Global Scale | ||
|---|---|---|---|---|
| Scale = 1 | Scale = 2 | Scale = 3 | Scale = 4 | |
| 1 | 60.21 | 77.92 | 80.42 | 86.88 |
| 2 | 41.04 | 50.42 | 51.67 | 57.92 |
| 3 | 53.13 | 60.63 | 62.50 | 73.75 |
| 4 | 55.42 | 60.21 | 67.29 | 63.54 |
| 5 | 48.54 | 58.33 | 58.54 | 68.33 |
| 6 | 58.54 | 67.50 | 72.71 | 77.71 |
| 7 | 45.63 | 60.00 | 60.83 | 71.88 |
| 8 | 45.63 | 65.63 | 63.54 | 75.00 |
| 9 | 47.92 | 60.83 | 63.75 | 67.08 |
| 10 | 65.42 | 78.04 | 72.92 | 75.92 |
| 11 | 42.92 | 56.88 | 58.33 | 64.38 |
| 12 | 51.25 | 64.79 | 62.71 | 64.21 |
| 13 | 73.13 | 74.17 | 80.17 | 77.58 |
| 14 | 55.00 | 63.96 | 76.04 | 72.50 |
| 15 | 71.04 | 79.79 | 80.42 | 84.58 |
| 16 | 67.08 | 82.29 | 88.75 | 87.71 |
| 17 | 48.33 | 65.63 | 66.67 | 77.08 |
| 18 | 49.58 | 69.58 | 70.63 | 81.67 |
| 19 | 47.92 | 57.08 | 57.50 | 64.17 |
| 20 | 58.33 | 69.79 | 73.54 | 77.50 |
| 21 | 48.54 | 60.21 | 61.25 | 67.71 |
| 22 | 42.71 | 54.04 | 50.21 | 51.75 |
| 23 | 64.38 | 78.75 | 83.75 | 87.29 |
| 24 | 54.17 | 59.79 | 63.54 | 61.67 |
| 25 | 58.96 | 66.67 | 68.75 | 70.83 |
| 26 | 51.88 | 64.79 | 66.25 | 70.21 |
| 27 | 62.50 | 63.54 | 64.17 | 67.50 |
| 28 | 49.79 | 73.33 | 72.92 | 80.21 |
| 29 | 47.29 | 62.29 | 64.17 | 72.71 |
| 30 | 44.17 | 62.50 | 64.38 | 72.50 |
| 31 | 46.67 | 62.92 | 66.88 | 73.75 |
| 32 | 49.38 | 56.67 | 68.54 | 65.00 |
| Average | 53.33 | 65.28 | 67.62 | 72.20 |
| Subject | Session 1 | Session 2 | Session 3 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SVM | KNN | SSFBEL | MSFBEL | SVM | KNN | SSFBEL | MSFBEL | SVM | KNN | SSFBEL | MSFBEL | |
| 1 | 73.43 | 65.97 | 84.85 | 80.19 | 76.28 | 75.06 | 76.28 | 76.28 | 63.27 | 57.91 | 69.97 | 80.16 |
| 2 | 86.01 | 100 | 96.04 | 100 | 97.56 | 94.62 | 97.56 | 97.56 | 81.77 | 70.24 | 89.01 | 89.01 |
| 3 | 75.99 | 75.76 | 82.75 | 73.66 | 75.06 | 81.91 | 88.75 | 91.20 | 56.57 | 49.06 | 78.55 | 78.55 |
| 4 | 83.22 | 79.25 | 100 | 100 | 71.15 | 84.11 | 84.11 | 88.75 | 94.91 | 89.01 | 89.01 | 91.42 |
| 5 | 52.68 | 59.21 | 68.30 | 75.29 | 82.64 | 77.26 | 88.51 | 85.57 | 78.02 | 76.14 | 72.12 | 75.87 |
| 6 | 59.44 | 54.55 | 65.73 | 66.67 | 64.55 | 80.44 | 94.13 | 93.40 | 69.71 | 89.01 | 89.01 | 89.01 |
| 7 | 52.45 | 71.33 | 97.20 | 97.20 | 91.69 | 97.56 | 92.91 | 99.27 | 85.25 | 80.16 | 84.99 | 94.91 |
| 8 | 77.16 | 77.16 | 65.03 | 79.49 | 66.99 | 88.02 | 87.04 | 87.04 | 89.54 | 81.23 | 86.33 | 86.33 |
| 9 | 83.22 | 87.41 | 93.47 | 100 | 73.11 | 67.24 | 73.11 | 74.82 | 62.73 | 62.73 | 66.49 | 66.49 |
| 10 | 45.22 | 58.28 | 83.45 | 73.66 | 85.33 | 91.20 | 92.91 | 91.69 | 68.36 | 75.07 | 74.80 | 64.88 |
| 11 | 70.16 | 72.49 | 80.19 | 79.72 | 80.93 | 66.99 | 80.68 | 80.68 | 61.13 | 49.06 | 61.13 | 67.29 |
| 12 | 75.76 | 71.33 | 79.95 | 77.62 | 57.21 | 61.37 | 85.57 | 83.86 | 49.06 | 59.52 | 53.62 | 54.96 |
| 13 | 83.68 | 60.14 | 66.67 | 77.62 | 78.48 | 62.59 | 72.37 | 87.29 | 61.13 | 61.13 | 61.13 | 61.13 |
| 14 | 64.34 | 66.90 | 72.49 | 72.49 | 77.75 | 74.33 | 80.68 | 86.55 | 86.60 | 54.96 | 95.44 | 95.44 |
| 15 | 85.55 | 64.80 | 88.58 | 87.65 | 85.33 | 100 | 91.69 | 94.13 | 68.36 | 78.82 | 78.82 | 78.55 |
| Average | 71.22 | 70.97 | 81.65 | 82.75 | 77.60 | 80.18 | 85.75 | 87.87 | 71.76 | 68.94 | 76.69 | 78.27 |
| Std | 12.94 | 11.58 | 11.57 | 10.92 | 10.07 | 12.05 | 7.52 | 6.83 | 13.03 | 13.08 | 12.02 | 12.45 |
| Subject | SVM | KNN | SSFBEL | MSFBEL | Subject | SVM | KNN | SSFBEL | MSFBEL |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 59.79 | 75.83 | 86.88 | 87.71 | 17 | 56.04 | 59.79 | 77.08 | 75.63 |
| 2 | 43.75 | 57.50 | 57.92 | 59.79 | 18 | 55.42 | 72.29 | 81.67 | 82.92 |
| 3 | 52.71 | 66.04 | 73.75 | 75.63 | 19 | 61.25 | 64.58 | 64.17 | 65.63 |
| 4 | 54.17 | 62.50 | 63.54 | 70.21 | 20 | 61.04 | 62.92 | 77.50 | 79.38 |
| 5 | 42.71 | 55.63 | 68.33 | 68.33 | 21 | 54.38 | 62.50 | 67.71 | 69.58 |
| 6 | 49.58 | 61.88 | 77.71 | 80.83 | 22 | 36.88 | 50.21 | 51.75 | 63.96 |
| 7 | 63.13 | 71.88 | 71.88 | 73.54 | 23 | 62.92 | 76.25 | 87.29 | 85.00 |
| 8 | 51.25 | 60.21 | 75.00 | 76.04 | 24 | 56.67 | 60.42 | 61.67 | 64.58 |
| 9 | 52.50 | 56.88 | 67.08 | 67.29 | 25 | 52.29 | 63.75 | 70.83 | 74.38 |
| 10 | 55.83 | 60.21 | 75.92 | 77.92 | 26 | 52.50 | 55.42 | 70.21 | 69.79 |
| 11 | 34.38 | 51.67 | 64.38 | 70.21 | 27 | 62.08 | 68.75 | 67.50 | 68.75 |
| 12 | 56.46 | 61.25 | 64.21 | 66.04 | 28 | 48.33 | 61.04 | 80.21 | 82.92 |
| 13 | 68.13 | 69.38 | 77.58 | 81.88 | 29 | 53.33 | 60.42 | 72.71 | 73.54 |
| 14 | 54.79 | 59.38 | 72.50 | 73.54 | 30 | 46.46 | 61.67 | 72.50 | 73.96 |
| 15 | 59.79 | 70.42 | 84.58 | 84.17 | 31 | 52.71 | 64.17 | 73.75 | 73.75 |
| 16 | 57.08 | 68.33 | 87.71 | 88.96 | 32 | 46.88 | 54.17 | 65.00 | 69.38 |
| Method | SVM | KNN | SSFBEL | MSFBEL | |||||
| Average | 53.60 | 62.73 | 72.20 | 74.23 | |||||
| Std | 7.32 | 6.34 | 8.42 | 7.23 | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, F.; Peng, Y.; Kong, W.; Dai, G. Multi-Scale Frequency Bands Ensemble Learning for EEG-Based Emotion Recognition. Sensors 2021, 21, 1262. https://doi.org/10.3390/s21041262
Shen F, Peng Y, Kong W, Dai G. Multi-Scale Frequency Bands Ensemble Learning for EEG-Based Emotion Recognition. Sensors. 2021; 21(4):1262. https://doi.org/10.3390/s21041262
Chicago/Turabian StyleShen, Fangyao, Yong Peng, Wanzeng Kong, and Guojun Dai. 2021. "Multi-Scale Frequency Bands Ensemble Learning for EEG-Based Emotion Recognition" Sensors 21, no. 4: 1262. https://doi.org/10.3390/s21041262
APA StyleShen, F., Peng, Y., Kong, W., & Dai, G. (2021). Multi-Scale Frequency Bands Ensemble Learning for EEG-Based Emotion Recognition. Sensors, 21(4), 1262. https://doi.org/10.3390/s21041262