
RobotP: A Benchmark Dataset for 6D Object Pose Estimation



Abstract
:1. Introduction
- A representative dataset providing high-quality RGB-D images, ground truth poses, object segmentation masks, 2D bounding boxes, and 3D models for different objects, which covers a wide range of pose estimation challenges.
- A novel pose refinement approach that uses a local-to-global optimization strategy to achieve the improved accuracy of each pose and global pose alignment.
- A novel depth generation algorithm producing high-quality depth images, which is able to accurately align the depth image to its corresponding color image and fill missing depth information.
- Careful merging of multi-modal sensor data for object reconstruction, followed by an algorithm to produce the segmentation mask and 2D bounding box for each object automatically.
- A training dataset is generated by a free-viewpoint image based rendering approach in a simulated environment. It provides a large amount of high-resolution and photo-realistic color-and-depth image pairs that have plausible physical locations, lighting conditions, and scales.
- The Shape Retrieval Challenge benchmark on 6D object pose estimation. The benchmark allows for evaluating and comparing pose estimation algorithms under the same standard. The evaluation results indicate that there is considerable room for improvement in 6D object pose estimation, particularly for objects that have dark colors or reflective characteristics, and knowledge that is learned from photo-realistic images can be successfully transferred to real-world data without domain constraints.
2. Related Work
3. The RobotP Dataset
3.1. Object Selection
- In order to cover as many aspects of pose estimation challenges as possible, the selected objects should be representative enough for the pose estimation problem. For example, objects with few textures are added to the dataset, as it is a challenge for pose estimation approaches to estimate 6D poses for texture-less objects is representative enough for the pose estimation problem.
- We aim to provide a 3D dataset allowing for easily carrying, shipping, and storing, which is helpful to carry out robotic manipulation experiments in the real world. Thus, the portability of the object is taken into consideration.
- To make the dataset easily reproducible, we choose the popular consumer products, which are low price and easy to buy as our target objects.
3.2. Collecting Scene Data
- The resolution of the captured image should be as high as possible. This is because, with high resolution images, we are able to obtain richer information about the captured object.
- The range of the 3D camera should be long enough, which allows for us to capture images with a variety of view positions; The frame rate of the 3D camera should be high, which is able to promise better tracking of capture processes.
- The 3D camera should be portable and low-cost, allowing large groups of inexperienced users to collect data.
3.3. Ground Truth Pose Estimation
3.4. Depth Generation
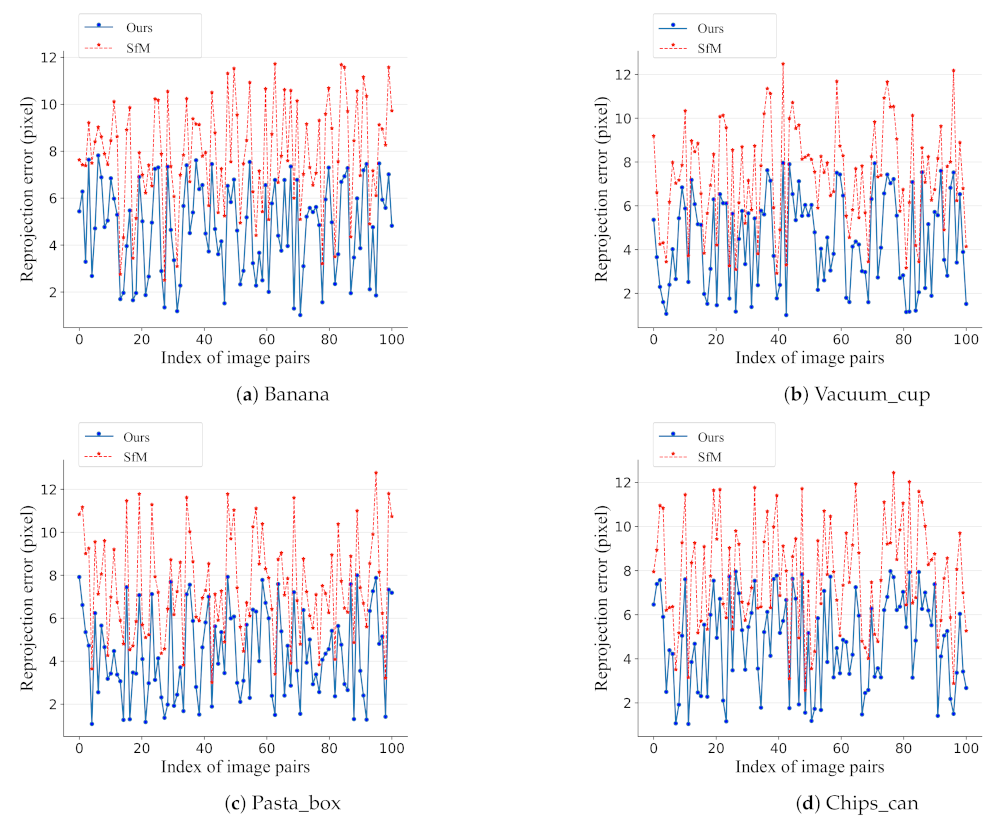
Depth and Color Image Alignment
| Algorithm 1 Overview of depth alignment procedure. |
| Input Captured depth image , estimated depth image ; |
| Output: aligned depth map for ; |
| 1: Run RANSAC to find the metric scaling factor. |
| 2: Extract patch in . |
| 3: Calculate scaled depth values and normals of . |
| 4: Initialize offset map O. |
| 5: Find a patch in based on O. |
| 6: for ∈ and ∈ do |
| 7: Calculate depth difference and normal angle between and . |
| 8: Run PatchMatch propagation to update offset map O. |
| 9: Mapping to based on O. |
3.4.2. Depth Fusion
3.5. 3D Modeling
- Quality. Each mask and its corresponding bounding box need to be tight. For example, the bounding box should be the minimum bounding box that fully encloses all visible parts of the object. In order to estimate the 6D object pose, the first step is to detect the target object. The quality of masks and bounding boxes influences the performance of object detection algorithms, which affects the accuracy of the estimated pose.
- Coverage. Each object instance needs to have a segmentation mask and a 2D bounding box that should only contain the object other than the background. For learning-based object detection and recognition approaches, they need to know exactly which part is the target object in a whole image.
- Cost. The designed algorithm should not only provide high-quality masks and 2D bounding boxes, but also have the minimum cost, as data annotation is a labor intensive and time-consuming process.
3.6. Photo-Realistic Rendering
3.7. Content
- 6D poses for each object.
- Color and depth images with the resolution of in PNG.
- Segmentation binary masks and 2D bounding boxes for the objects.
- 3D point clouds with RGB color and normals for the objects.
- Calibration information for each image.
4. Experimental Results
4.1. Evaluation of Dataset Generation Approaches
4.2. 6D Object Pose Estimation Challenge
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, C.; Xu, D.; Zhu, Y.; Martín-Martín, R.; Lu, C.; Fei-Fei, L.; Savarese, S. Densefusion: 6D object pose estimation by iterative dense fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 3343–3352. [Google Scholar]
- Chen, W.; Duan, J.; Basevi, H.; Chang, H.J.; Leonardis, A. Ponitposenet: Point pose network for robust 6D object pose estimation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 2824–2833. [Google Scholar]
- Tekin, B.; Sinha, S.N.; Fua, P. Real-time seamless single shot 6D object pose prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 292–301. [Google Scholar]
- Garcia-Garcia, A.; Martinez-Gonzalez, P.; Oprea, S.; Castro-Vargas, J.A.; Orts-Escolano, S.; Garcia-Rodriguez, J.; Jover-Alvarez, A. The robotrix: An extremely photorealistic and very-large-scale indoor dataset of sequences with robot trajectories and interactions. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 6790–6797. [Google Scholar]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. Epnp: An accurate O(n) solution to the pnp problem. Int. J. Comput. Vis. 2009, 81, 155. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Xu, C.; Xie, M. A robust O(n) solution to the perspective-n-point problem. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1444–1450. [Google Scholar] [CrossRef] [PubMed]
- Kehl, W.; Milletari, F.; Tombari, F.; Ilic, S.; Navab, N. Deep learning of local RGB-D patches for 3D object detection and 6D pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 205–220. [Google Scholar]
- Wang, H.; Sridhar, S.; Huang, J.; Valentin, J.; Song, S.; Guibas, L.J. Normalized object coordinate space for category-level 6D object pose and size estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 2642–2651. [Google Scholar]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. Posecnn: A convolutional neural network for 6D object pose estimation in cluttered scenes. arXiv 2017, arXiv:1711.00199. [Google Scholar]
- Qi, C.R.; Chen, X.; Litany, O.; Guibas, L.J. Imvotenet: Boosting 3D object detection in point clouds with image votes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4404–4413. [Google Scholar]
- Deng, X.; Xiang, Y.; Mousavian, A.; Eppner, C.; Bretl, T.; Fox, D. Self-supervised 6D object pose estimation for robot manipulation. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 31 May–31 August 2020; pp. 3665–3671. [Google Scholar]
- He, Y.; Sun, W.; Huang, H.; Liu, J.; Fan, H.; Sun, J. PVN3D: A deep point-wise 3D keypoints voting network for 6DoF pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11632–11641. [Google Scholar]
- Song, C.; Song, J.; Huang, Q. Hybridpose: 6D object pose estimation under hybrid representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 431–440. [Google Scholar]
- Hinterstoisser, S.; Holzer, S.; Cagniart, C.; Ilic, S.; Konolige, K.; Navab, N.; Lepetit, V. Multimodal templates for real-time detection of texture-less objects in heavily cluttered scenes. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 858–865. [Google Scholar]
- Drost, B.; Ulrich, M.; Bergmann, P.; Hartinger, P.; Steger, C. Introducing mvtec itodd-a dataset for 3D object recognition in industry. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2200–2208. [Google Scholar]
- Yang, J.; Ye, X.; Li, K.; Hou, C.; Wang, Y. Color-guided depth recovery from RGB-D data using an adaptive autoregressive model. IEEE Trans. Image Process. 2014, 23, 3443–3458. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.; Wang, L.; Yang, R.; Davis, J.E. Reliability fusion of time-of-flight depth and stereo geometry for high quality depth maps. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1400–1414. [Google Scholar] [PubMed] [Green Version]
- Schonberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. A large-scale hierarchical multi-view RGB-D object dataset. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1817–1824. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2097–2106. [Google Scholar]
- Tatsuma, A.; Koyanagi, H.; Aono, M. A large-scale shape benchmark for 3D object retrieval: Toyohashi shape benchmark. In Proceedings of the 2012 Asia Pacific Signal and Information Processing Association Annual Summit and Conference, Hollywood, CA, USA, 3–6 December 2012; pp. 1–10. [Google Scholar]
- SHREC2020—3D Shape Retrieval Challenge 2020. Available online: http://www.shrec.net/ (accessed on 13 June 2020).
- Kasper, A.; Xue, Z.; Dillmann, R. The KIT object models database: An object model database for object recognition, localization and manipulation in service robotics. Int. J. Robot. Res. 2012, 31, 927–934. [Google Scholar] [CrossRef]
- Brachmann, E.; Krull, A.; Michel, F.; Gumhold, S.; Shotton, J.; Rother, C. Learning 6D object pose estimation using 3D object coordinates. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 536–551. [Google Scholar]
- Tejani, A.; Tang, D.; Kouskouridas, R.; Kim, T.K. Latent-class hough forests for 3D object detection and pose estimation. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 462–477. [Google Scholar]
- Doumanoglou, A.; Kouskouridas, R.; Malassiotis, S.; Kim, T.K. Recovering 6D object pose and predicting next-best-view in the crowd. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3583–3592. [Google Scholar]
- Rennie, C.; Shome, R.; Bekris, K.E.; De Souza, A.F. A dataset for improved RGBD-based object detection and pose estimation for warehouse pick-and-place. IEEE Robot. Autom. Lett. 2016, 1, 1179–1185. [Google Scholar] [CrossRef] [Green Version]
- Eppner, C.; Höfer, S.; Jonschkowski, R.; Martín-Martín, R.; Sieverling, A.; Wall, V.; Brock, O. Lessons from the amazon picking challenge: Four aspects of building robotic systems. In Proceedings of the Robotics: Science and Systems, Ann Arbor, MI, USA, 18–22 June 2016. [Google Scholar]
- Hodan, T.; Haluza, P.; Obdržálek, Š.; Matas, J.; Lourakis, M.; Zabulis, X. T-LESS: An RGB-D dataset for 6D pose estimation of texture-less objects. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 880–888. [Google Scholar]
- Mahler, J.; Matl, M.; Liu, X.; Li, A.; Gealy, D.; Goldberg, K. Dex-Net 3. In 0: Computing robust vacuum suction grasp targets in point clouds using a new analytic model and deep learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1–8. [Google Scholar]
- Kaskman, R.; Zakharov, S.; Shugurov, I.; Ilic, S. Homebreweddb: RGB-D dataset for 6D pose estimation of 3D objects. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
- Zheng, J.; Li, J.; Li, Y.; Peng, L. A benchmark dataset and deep learning-based image reconstruction for electrical capacitance tomography. Sensors 2018, 18, 3701. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hodan, T.; Michel, F.; Brachmann, E.; Kehl, W.; GlentBuch, A.; Kraft, D.; Drost, B.; Vidal, J.; Ihrke, S.; Zabulis, X.; et al. Bop: Benchmark for 6D object pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 19–34. [Google Scholar]
- Giancola, S.; Valenti, M.; Sala, R. A Survey on 3D Cameras: Metrological Comparison of Time-of-Flight, Structured-Light and Active Stereoscopy Technologies; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Triggs, B.; McLauchlan, P.F.; Hartley, R.I.; Fitzgibbon, A.W. Bundle adjustment—A modern synthesis. In Proceedings of the International Workshop on Vision Algorithms, Corfu, Greece, 20–25 September 1999; pp. 298–372. [Google Scholar]
- Intel RealSense Depth Camera D415. Available online: https://www.intelrealsense.com/depth-camera-d415/ (accessed on 18 June 2020).
- Schönberger, J.L.; Zheng, E.; Pollefeys, M.; Frahm, J.M. Pixelwise View Selection for Unstructured Multi-View Stereo. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Rusu, R.B. Semantic 3D object maps for everyday manipulation in human living environments. KI-Künstliche Intell. 2010, 24, 345–348. [Google Scholar] [CrossRef] [Green Version]
- Barnes, C.; Shechtman, E.; Finkelstein, A.; Goldman, D.B. PatchMatch: A randomized correspondence algorithm for structural image editing. ACM Trans. Graph. 2009, 28, 24. [Google Scholar] [CrossRef]
- Rusu, R.B.; Cousins, S. 3D is here: Point Cloud Library (PCL). In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011. [Google Scholar]
- Yuan, H.; Veltkamp, R.C. PreSim: A 3D photo-realistic environment simulator for visual AI. 2020; unpublished. [Google Scholar]
- Zhou, T.; Tucker, R.; Flynn, J.; Fyffe, G.; Snavely, N. Stereo magnification: Learning view synthesis using multiplane images. arXiv 2018, arXiv:1805.09817. [Google Scholar] [CrossRef] [Green Version]
- Mildenhall, B.; Srinivasan, P.P.; Ortiz-Cayon, R.; Kalantari, N.K.; Ramamoorthi, R.; Ng, R.; Kar, A. Local light field fusion: Practical view synthesis with prescriptive sampling guidelines. ACM Trans. Graph. (TOG) 2019, 38, 1–14. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. NeRF: Representing scenes as neural radiance fields for view synthesis. arXiv 2020, arXiv:2003.08934. [Google Scholar]
- Yuan, H.; Veltkamp, R.C.; Albanis, G.; Zioulis, N.; Zarpalas, D.; Daras, P. SHREC 2020 Track: 6D Object Pose Estimation. In Eurographics Workshop on 3D Object Retrieval; Schreck, T., Theoharis, T., Pratikakis, I., Spagnuolo, M., Veltkamp, R.C., Eds.; The Eurographics Association: Norrköping, Sweden, 2020. [Google Scholar] [CrossRef]
- Niemeyer, M.; Mescheder, L.; Oechsle, M.; Geiger, A. Occupancy flow: 4d reconstruction by learning particle dynamics. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5379–5389. [Google Scholar]
- Mustafa, A.; Kim, H.; Guillemaut, J.Y.; Hilton, A. Temporally coherent 4d reconstruction of complex dynamic scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4660–4669. [Google Scholar]
- Doulamis, A.; Grammalidis, N.; Ioannides, M.; Potsiou, C.; Doulamis, N.D.; Stathopoulou, E.K.; Ioannidis, C.; Chrysouli, C.; Dimitropoulos, K. 5D modelling: An efficient approach for creating spatiotemporal predictive 3D maps of large-scale cultural resources. In Proceedings of the ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Taipei, Taiwan, 31 August–4 September 2015. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Year | 3D | Synthetic Data | Scenario | Novel | Available Data |
|---|---|---|---|---|---|---|
| Linemod [14] | 2012 | Yes | No | Household | Yes | RGB-D images, 3D models, object masks and bounding boxes |
| KIT [26] | 2012 | Yes | No | Household | No | 2D images and 3D models |
| Linemod-Occluded [27] | 2014 | Yes | No | Household | Yes | RGB-D images, 3D models, object masks and bounding boxes |
| IC-MI [28] | 2014 | Yes | No | Household | Yes | RGB images and 3D models |
| IC-BIN [29] | 2016 | Yes | No | Household | Yes | RGB-D images and 3D models |
| Rutgers APC [30] | 2016 | Yes | No | Household | Yes | RGB-D images and 3D models |
| T-LESS [32] | 2017 | Yes | No | Industry | No | RGB-D images and 3D models |
| ITODD [15] | 2017 | Yes | No | Industry | No | Gray images and 3D models |
| TYO-L [37] | 2018 | Yes | Yes | Household | No | RGB-D images, 3D models, and object masks |
| YCB-Video [9] | 2018 | Yes | Yes | Household | No | RGB-D images, 3D models, object masks and bounding boxes |
| HomebrewedDB [34] | 2019 | Yes | Yes | Household and Industry | No | RGB-D images and 3D models |
| RobotP (ours) | 2020 | Yes | Yes | Household | Yes | RGB-D images, 3D models, object masks and bounding boxes |
| Camera | Baseline | Depth FOV HD (Degree) | IR Projector FOV | Color Camera FOV | Z-Accuracy (or Absolute Error) | Module Dimensions (mm) |
|---|---|---|---|---|---|---|
| D415 | 55 mm | H: 65 ± 2/V: 40 ± 1/D: 72 ± 2 | H: 67/V: 41/D: 75 | H: 69 ± 1/V: 42 ± 1/D: 77 ± 1 | <2% | X = 83.7/Y = 10/ Z = 4.7 |
| SM [46] | LLFF [47] | NeRF [48] | Ours | |
|---|---|---|---|---|
| Dense | 20.11 | 22.93 | 33.25 | 30.17 |
| Sparse | 11.47 | 14.04 | 21.67 | 27.09 |
| Banana | Biscuit_Box | Chips_Can | Cookie_Box | Gingerbread_Box | Milk_Box | Pasta_Box | Vacuum_Cup | MEAN | |
|---|---|---|---|---|---|---|---|---|---|
| DenseFusion | 0.86 | 0.91 | 0.56 | 0.62 | 0.87 | 0.50 | 0.77 | 0.61 | 0.71 |
| ASS3D | 0.70 | 0.78 | 0.75 | 0.49 | 0.63 | 0.58 | 0.63 | 0.65 | 0.65 |
| GraphFusion | 0.83 | 0.93 | 0.69 | 0.61 | 0.90 | 0.66 | 0.84 | 0.63 | 0.76 |
| Banana | Biscuit_Box | Chips_Can | Cookie_Box | Gingerbread_Box | Milk_Box | Pasta_Box | Vacuum_Cup | MEAN | |
|---|---|---|---|---|---|---|---|---|---|
| DenseFusion | 0.86 | 0.95 | 0.94 | 0.74 | 0.94 | 0.81 | 0.91 | 0.90 | 0.88 |
| ASS3D | 0.75 | 0.88 | 0.85 | 0.66 | 0.86 | 0.62 | 0.72 | 0.75 | 0.76 |
| GraphFusion | 0.87 | 0.96 | 0.97 | 0.75 | 0.95 | 0.77 | 0.96 | 0.97 | 0.90 |
| Banana | Biscuit_Box | Chips_Can | Cookie_Box | Gingerbread_Box | Milk_Box | Pasta_Box | Vacuum_Cup | MEAN | |
|---|---|---|---|---|---|---|---|---|---|
| DenseFusion | 0.77 | 0.77 | 0.74 | 0.67 | 0.76 | 0.66 | 0.74 | 0.71 | 0.72 |
| ASS3D | 0.66 | 0.74 | 0.72 | 0.56 | 0.71 | 0.51 | 0.61 | 0.64 | 0.64 |
| GraphFusion | 0.75 | 0.79 | 0.76 | 0.66 | 0.78 | 0.67 | 0.77 | 0.74 | 0.74 |
| Real | Synthetic | |||||
|---|---|---|---|---|---|---|
| DenseFusin | ASS3D | GraphFusion | DenseFusin | ASS3D | GraphFusion | |
| banana | 0.85 | 0.70 | 0.84 | 0.86 | 0.70 | 0.82 |
| biscuit_box | 0.91 | 0.77 | 0.92 | 0.91 | 0.78 | 0.93 |
| chips_can | 0.55 | 0.75 | 0.69 | 0.57 | 0.74 | 0.69 |
| cookie_box | 0.61 | 0.48 | 0.60 | 0.63 | 0.49 | 0.61 |
| gingerbread_box | 0.88 | 0.63 | 0.91 | 0.87 | 0.63 | 0.90 |
| milk_box | 0.51 | 0.57 | 0.68 | 0.49 | 0.58 | 0.66 |
| pasta_box | 0.78 | 0.61 | 0.83 | 0.76 | 0.64 | 0.84 |
| vacuum_cup | 0.59 | 0.65 | 0.64 | 0.62 | 0.64 | 0.63 |
| Banana | Biscuit_Box | Chips_Can | Cookie_Box | Gingerbread_Box | Milk_Box | Pasta_Box | Vacuum_Cup | MEAN | |
|---|---|---|---|---|---|---|---|---|---|
| DenseFusion | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 |
| ASS3D | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 |
| GraphFusion | 0.04 | 0.04 | 0.04 | 0.04 | 0.04 | 0.04 | 0.04 | 0.04 | 0.04 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, H.; Hoogenkamp, T.; Veltkamp, R.C. RobotP: A Benchmark Dataset for 6D Object Pose Estimation. Sensors 2021, 21, 1299. https://doi.org/10.3390/s21041299
Yuan H, Hoogenkamp T, Veltkamp RC. RobotP: A Benchmark Dataset for 6D Object Pose Estimation. Sensors. 2021; 21(4):1299. https://doi.org/10.3390/s21041299
Chicago/Turabian StyleYuan, Honglin, Tim Hoogenkamp, and Remco C. Veltkamp. 2021. "RobotP: A Benchmark Dataset for 6D Object Pose Estimation" Sensors 21, no. 4: 1299. https://doi.org/10.3390/s21041299
APA StyleYuan, H., Hoogenkamp, T., & Veltkamp, R. C. (2021). RobotP: A Benchmark Dataset for 6D Object Pose Estimation. Sensors, 21(4), 1299. https://doi.org/10.3390/s21041299