Abstract
In this paper, we focus on the bandlimited graph signal sampling problem. To sample graph signals, we need to find small-sized subset of nodes with the minimal optimal reconstruction error. We formulate this problem as a subset selection problem, and propose an efficient Pareto Optimization for Graph Signal Sampling (POGSS) algorithm. Since the evaluation of the objective function is very time-consuming, a novel acceleration algorithm is proposed in this paper as well, which accelerates the evaluation of any solution. Theoretical analysis shows that POGSS finds the desired solution in quadratic time while guaranteeing nearly the best known approximation bound. Empirical studies on both Erdos-Renyi graphs and Gaussian graphs demonstrate that our method outperforms the state-of-the-art greedy algorithms.
1. Introduction
Graph Signal Processing (GSP) is a powerful tool for irregular data modeling and processing, and has attracted extensive attention from the signal processing [1,2], machine learning [3], and computer vision communities [4,5]. Traditional signal processing usually treat the data as a sequence of vectors, then analyze the features in the time domain or frequency domain, and try to extract information from the features. This implies that the data rely on an Euclidean space . However, in many real-world applications such as computer graphics [6] and machine learning [7], this assumption is not accurate enough. For example, the data captured by sensors in a sensor network are always interconnected to each other, and they may rely on a manifold embedded in an Euclidean space. Moreover, a RGB image lies within the pixel space , but the dimension of the natural image space is usually much lower. GSP brings the signal from the time (spatial) domain to the node domain, and allows us to use a similar tool in traditional signal processing, such as Fourier transform and wavelet analysis, to analyze the graph signals, and then extract the latent information. As an illustration, Figure 1 shows the graph signals supported on the Stanford bunny graph, the Swiss roll graph and the Minnesota road graph respectively.
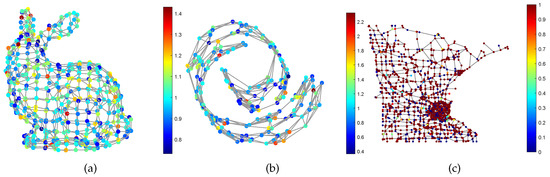
Figure 1.
Illustration of smooth graph signals. The signals are supported on (a) The stanford bunny graph; (b) The swiss roll graph; (c) The Minnesota road graph.
However, in some applications, the underlying graph is very large, which makes it very expensive to collect and process the data from all nodes. Graph signal sampling is a basic problem in GSP that aims to select a subset with the minimal reconstruction error from the graph node set. Hence, we just need to collect the signal from a small-sized sampling set, and the complete graph signal can be obtained via optimal graph signal reconstruction. Graph signal sampling has been widely used in many fields, e.g., sensor placement [8] and 3D point-cloud sampling [9]. Previous works [10,11] first considered the graph signal reconstruction problem, which aims to recover the whole graph signal from partial observations, then formulated the graph signal sampling problem as a subset of nodes with the minimal optimal reconstruction error. This sampling problem can be regarded as a subset selection problem, which plays a fundamental role in many fields, such as sparse reciprocal graphical model estimation [12] and sparse plus low rank graphical model estimation [13]. This problem is proved to be generally NP-hard [14], so we may not find a global optimal solution of this problem in polynomial time. A sub-optimal method is the greedy algorithm, which selects an element with the greatest improvement to the objective function at each iteration. The greedy algorithm is very simple, but also very effective. In [15], it is proved that the greedy algorithm achieves approximation ratio for normalized (that means ) monotonic weak submodular objective functions in general subset selection problems, where is the submodularity ratio of the objective function. For submodular objective functions we have , then the greedy algorithm guarantees performance, which is the best-so-far theoretical guarantee.
Recently, many Multi-Objective Evolutionary Algorithms (MOEAs) such as the Pareto Optimization for Subset Selection (POSS) algorithm have exhibited better performance than greedy algorithms do [16,17,18]. POSS treats the cardinality constraint as an additional objective function of the problem, then the original problem is transformed to a Bi-objective Optimization Problem (BOP). POSS adopts the evolutionary mutation operation to search for different Pareto optimal solutions of the BOP, and finally select a desired Pareto optimal solution.
Though POSS has been proved to be a powerful tool to solve the subset selection problem, it is infeasible to directly apply it to the graph signal sampling problem, since the evaluation of the optimal reconstruction error is very expensive. In this work, we propose the Pareto Optimization for Graph Signal Sampling (POGSS) based on POSS, and an acceleration algorithm is proposed. By introducing the supermodularity ratio of the objective function, we prove that this method theoretically achieves comparable performance as greedy algorithms do in polynomial time, and show that the supermodularity ratio is bounded as well. Our major contributions can be summarized as follows:
- Inspired by POSS, we formulate the graph signal sampling problem as a subset selection problem, and solve this problem by employing Pareto optimization, which has been proved to be superior to greedy methods.
- To accelerate the objective estimation procedure, we propose a novel acceleration algorithm based on matrix inversion lemma. Our acceleration algorithm is scalable since it can be used to accelerate the evaluation of solution, thus that can be directly applied to other evolutionary-based methods (e.g., POSS with recombination [17]).
- We provide comprehensive theoretical analyses of the proposed algorithm, including complexity analysis, Pareto optimality analysis and error bound analysis.
The remainder of this paper is organized as follows. We present the preliminaries and formulate the problem in Section 2.1. We give a brief introduction to the POSS method and introduce the Pareto optimization for graph signal sampling (POGSS) algorithm in Section 3. In Section 4, we provide comprehensive theoretical analyses of POGSS. The Numerical results and the conclusions are presented in Section 5 and Section 6, respectively.
2. Preliminaries
2.1. Notations
In this paper, we use the bold uppercase letters (e.g., ) to denote matrices and use bold lowercase letters (e.g., ) to denote vectors. -th entry of is denoted as or . denote the transpose, denote the inverse, denote the Moore-Penrose pseudo-inverse. denote the trace. denote the expectation. stands for a diagonal matrix with the diagonal entries given by a vector . Sets are denoted by calligraphic letters, e.g., (except the set of real number, which is denoted as ). denote the set of all integers from 1 to n, i.e., . denote the ceil operator, e.g., .
2.2. Graph Signal Processing
We consider a weighted, undirected graph , where is the set of nodes with , is the set of edges. Let be the adjacency matrix of , where is the weight of the edge between nodes i and j. The graph signal is a function that maps each node in to a real number, and can be written as a vector with its’ i-th entry denotes the signal value at nodes i.
Defined the unnormalized graph Laplacian matrix of as
where is a diagonal degree matrix with . Then we write the eigenvalue decomposition of the graph Laplacian matrix as
where is a diagonal matrix of graph frequencies, and is the matrix of graph Fourier bases. Then the graph Fourier transform of is defined as , and the inverse Fourier transform is given by . We say a graph signal is -bandlimited, if its’ graph Fourier coefficients indexed by are zero, i.e., . In [19], it was proved that if the sampling set size is not smaller than , then the -bandlimited graph signal can be perfectly recovered. However, in many applications we can only observe noise corrupted signals, we cannot find a perfect estimator under noise. Consequently, Bayesian estimation is adopted in the graph signal reconstruction problem.
2.3. Problem Formulation
Let be the original noise-free graph signal, and be the noise vector. In the graph signal reconstruction problem, only the noise corrupted samples in a sampling set are observable, thus we take the observation model as
where is the sampling matrix. We assume that is a zero-mean vector with covariance matrix , is -bandlimited and is a zero-mean vector with covariance matrix , hence the covariance matrix of is . Graph signal reconstruction is to approximately recover the original graph signal from partial noisy observation via a linear transform , i.e.,
The error covariance matrix with respect to is defined as
To find the optimal reconstruction matrix , one needs to minimize the scalar loss function for all . The derived optimal recover operator is [10]
and the correspongding error covariance matrix is given by
where , and the optimal mean squared error (MSE) is given by
The goal of graph signal sampling is to select a subset with at most k nodes, which minimizes the optimal reconstruction error , i.e., finding
Define , . By using the circular commutation property of trace, (6) is simplified to
3. Method
In this study, we propose to solve (7) by Pareto optimization. For representable convenience, we use the binary vector to represent the subset , the entry means that the node is included in and otherwise. We do not distinguish between the two notations. Please note that the original problem is a constrained problem with single objective function, we now reformulate this problem as an unconstrained BOP:
where
To compare two solutions, the Pareto dominance relationship and the Pareto optimality are defined as follows:
Definition 1
(Pareto dominance). Let and be two solutions, then
- (Weak dominance) weakly dominates (), if and only if and ;
- (Dominance) dominates (), if and only if and or .
Definition 2
(Pareto optimality). We say is a Pareto optimal solution with respect to , if there is no solution such that .
To summarize, a solution is said to weakly dominates if performs not worse than for all metrics, and for two solutions such that , we say dominates if there is at least one metric for which strictlly outperforms . is said to be a Pareto optimal solution with respect to if there is no solution in that dominates .
3.1. Pareto Optimization for Subset Selection (Poss)
POSS is an evolutionary algorithm for subset selection, and its overall procedure is shown in Algorithm 1. Denote as the set of all solutions, as the set of all solutions found so far. POSS maintains a set of all Pareto optimal solutions with respect to . At each step, POSS first randomly selects a solution from the set of Pareto optimal solutions , and then adopts the mutation operator to search for a potential Pareto optimal solution. If there is no solution that dominates the generated solution , then POSS includes the generated solution to , and remove the solutions which are weakly dominated by from ; Otherwise POSS discards the solution . Such update strategy in POSS guarantees that if is the Pareto optimal solution set at current iteration, then the updating operation does not change the optimality of . After T iterations, POSS outputs a solution with the minimal reconstructed error and a cardinality smaller than k, i.e., .
| Algorithm 1 POSS |
| Input: An universal set , , , . |
| Output: a subset with at most k nodes. |
| 1: , . |
| 2: for do |
| 3: Select from uniformly at random. |
| 4: Generate by bit-wise flipping with probability . |
| 5: if such that then |
| 6: . |
| 7: end if |
| 8: end for |
| 9: . |
3.2. Proposed Pareto Optimiazation for Graph Signal Sampling (Pogss)
However, due to the general complexity of the matrix inversion operation, the evaluation step of is very expensive in general, which means we cannot efficiently compare two solutions. Please note that at each iteration the new solution is generated from a solution evaluated before, we can accelerate the evaluation of the objective function by leveraging the information of the previous solution. More explicitly, by using the matrix inversion lemma [20] we deduced the following lemma:
Lemma 1.
Let , then for all , we have
Let be the elements to be included at the current iteration, denote the elements to be excluded, and denote the elements that will be retained. Instead of directly computing the , we propose to compute firstly, and then compute the desired . By using Lemma 1, we can easily compute by including the elements in to one by one, and then compute by excluding the elements in from separately. The full procedure of POGSS is described in Algorithm 2, and the solution flipping algorithm for acceleration is presented in Algorithm 3.
Denote as the number of bits that will be flipped at iteration t, then we have , which reveals the fact that we are expected to flip only 1 bit at each iteration. Please note that the evaluation of (9) and (10) can be done at a cost of , so the cost of evaluating the objective function in Algorithm 2 is expected to be , while the naive matrix inversion update requires a cost of . Therefore, this proposed procedure significantly accelerates the algorithm.
| Algorithm 2 POGSS |
| Input: , , integer , . |
| Output: a subset with at most k nodes. |
| 1: , , . |
| 2: for do |
| 3: Select from uniformly at random. |
| 4: Generate by bit-wise flipping with probability . |
| 5: |
| 6: if such that then |
| 7: . |
| 8: end if |
| 9: end for |
| 10: Output . |
| Algorithm 3 Solution Flipping |
| Input: . |
| Output: . |
| 1: Initialize , . |
| 2: Compute the difference set and . |
| 3: for do |
| 4: . |
| 5: Compute by using (9). |
| 6: end for |
| 7: for do |
| 8: . |
| 9: Compute by using (10). |
| 10: end for |
| 11: Output . |
4. Theoretical Analysis
In this section, we theoretically analyze the performance of POGSS, including the Pareto optimality of and the overall reconstruction error of POGSS.
We first show in Proposition 1 that the subset is the set of all Pareto optimal solutions with respect to .
Proposition 1
(Pareto optimality of ). At any iteration of the algorithm 2, let be the set of all solutions found so far, then
- for all , there is no such that ,
- for all , there is a solution such that .
We then analyze the performance of POGSS by introducing the supermodularity ratio. A set function is said to be a supermodular function, if holds for any and . For a general criterion f, Definition 3 defines how close it is to a supermodular function, i.e., the supermodularity ratio [21]. It is easy to prove that f is supermodular if and only if holds for any and k.
Definition 3
(Supermodularity ratio). Let f be a non-negative set function. The submodularity ratio of f with respect to a set and a parameter is
The most time-consuming operation in POGSS is the evaluation of the objective function after bit flipping. So here comes a question: how many bit flipping operations we need to obtain a desired solution? We provide an approximation upper bound of the optimal reconstruction MSE with bits flipped in Theorem 1. Please note that the greedy algorithm guarantees performance, where is the solution given by the greedy algorithm, POGSS achieves nearly the best known approximation guarantee as greedy algorithms do in quadratic time.
Theorem 1.
Define , let N be the total number of flipped bits, be the optimal value of (7). Then POGSS finds a solution such that
with
The proof of Theorem 1 relies on Lemma 2 and 3 stated bellow. The complete proof is similar to the proof of theorem 14.1 in [22], which is omitted due to the limited space.
Lemma 2.
For any ,
holds.
Lemma 3
([16]). , there exsits one nodes such that
Please note that the approximation upper bound in Theorem 1 involves , we show in Theorem 2 that is also bounded.
Proposition 2
(Lower bound for ). The supermodularity ratio satisfies
This conclusion is natural and obvious, since the equality holds when , and is also relatively loose. However, it is still meaningful because it is independent of the graph structure and the Signal-to-Noise Ratio (SNR), so it is tighter than the bound in [10] in high SNR scenarios.
5. Experiments
In this section, we conduct several experiments to evaluate the performance of POGSS. We first state the experimental settings, and then report the experimental results.
5.1. Experimental Settings
Two types of undirected graphs are adopted for evaluation:
- The Erdos-Renyi (ER) graph: For ER graphs, any two nodes are connected with probability p, i.e., , .
- The Gaussian graph: For Gaussian graphs, we uniformly sample n points in a unit square . The edges are first connected with weightsand we then set the weights which are smaller to some threshold to 0.
In our experiments, the number of nodes is set to 100 for all graphs, and we set for ER graphs, set for Gaussian graphs.
The graph signal is sampled from a Gaussian distribution:
where is the matrix of graph Fourier bases, is the covariance matrix of . In our experiments, is generated by , where is a random matrix with . The additive Gaussian noise is adopted in our experiments, and the noise power is set to .
We compare our methods with several algorithms, including the state-of-the-art greedy algorithm, the randomized greedy algorithm, and the convex relaxation algorithm. In all experiments, the number of iterations of POGSS is set to according to Theorem 1. The naive greedy graph siganl sampling algorithm [10] simply selects a node with the largest marginal gain at each iteartion. Assume subset of nodes obtained by the greedy algorithm at the current iteration is , then the node is included to . The randomized greedy algorithm [11] uses the similar strategy to the greedy algorithm, but accelerates the algorithm by selecting the best node from a random subset. More explicitly, it first samples a subset with size uniformly, where is a hyper-parameter, then includes the node to . Recall the original problem of graph signal sampling (7)
since the original problem is neither differentiable nor convex, we relax this problem to a convex optimization problem [23]
then let the largest k entries in to be included to the sampling set.
5.2. Experimental Results
We first evaluate the algorithms under the -bandlimited signal assumption. Under this assumption, the entries in indexed by are zero, thus can be perfectly represented by only graph Fourier bases. In the following experiments we set and use the first 40 graph Fourier bases to form .
We set the subset size k from 10 to 100 with stepsize 10, then independently run the simulation 10 times and report the average optimal reconstruction MSE of the obtained subset of each algorithm. Figure 2 and Figure 3 illustrate the results obtained on ER graphs and Gaussian graphs respectively. From Figure 2a and Figure 3a we observe that POGSS and greedy-based algorithms achieve near-optimal performance, the performance convex relaxation method is worse than other method, and POGSS outperforms others for any subset size. We note that when the subset size k is approaching the MSE decreases dramatically, and when (shown in the right-hand side of the vertical dotted line) all of the methods provide the solutions with very small reconstruction MSE. Figure 2b and Figure 3b plot the convergence curve of POGSS when . We can see that the MSE decreases very fast at first, and then becomes flat when . However, it keeps decreasing throughout the whole process. To be precise, POGSS reaches its’ final solution at the 2144-th iteration, while .
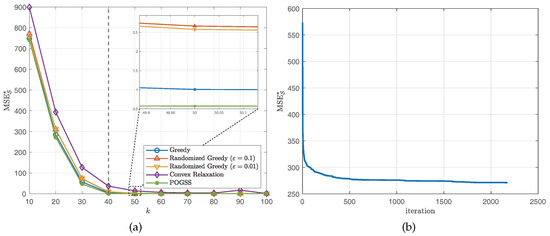
Figure 2.
Results for bandlimited graph signals obtained on ER graphs. (a) v.s. k. (b) Convergence curve when .
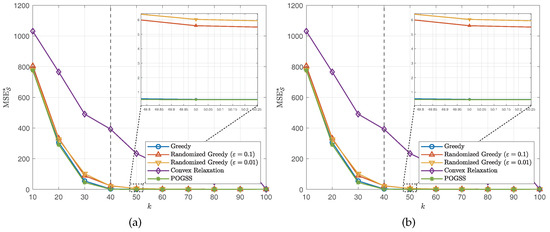
Figure 3.
Results for bandlimited graph signals obtained on Gaussian graphs. (a) v.s. k. (b) Convergence curve when .
We next evaluate the algorithms for non-bandlimited graph signals, i.e., . Similar to the bandlimited scenario, we set the subset size from 10 to 100 with step size 10 and present the average optimal reconstruction MSE of the obtained subset of each algorithm. Figure 4 and Figure 5 show the results obtained on ER graphs and Gaussian graphs respectively. From Figure 4a and Figure 5a we observe the similar results to the ones in Figure 2a and Figure 3a, where POGSS still achieves the best performance. It is worth noting that there is no “turning point” in Figure 4 and Figure 5, because the signals are non-bandlimited, and cannot be accurately reconstructed from partial observations.
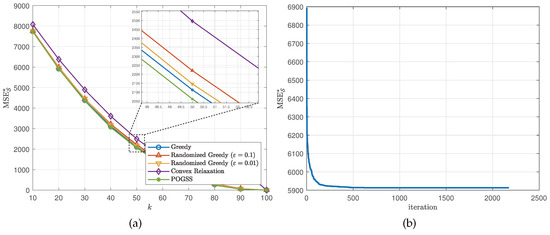
Figure 4.
Results for non-bandlimited graph signals obtained on ER graphs. (a) v.s. k. (b) Convergence curve when .
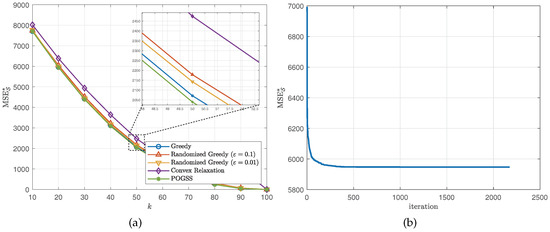
Figure 5.
Results for non-bandlimited graph signals obtained on Gaussian graphs. (a) v.s. k. (b) Convergence curve when .
In Figure 6 we compare the running time of different sampling set sizes. We observe that POGSS takes the most time to converge, which is as expected since Theorem 1 reveals that POGSS takse iterations to converge, while greedy algorithms require only k iterations to do that (the time consumption of each method to finish one iteration is almost the same). Although POGSS takes the most time to find a desired solution, it is still practicable for two reasons:
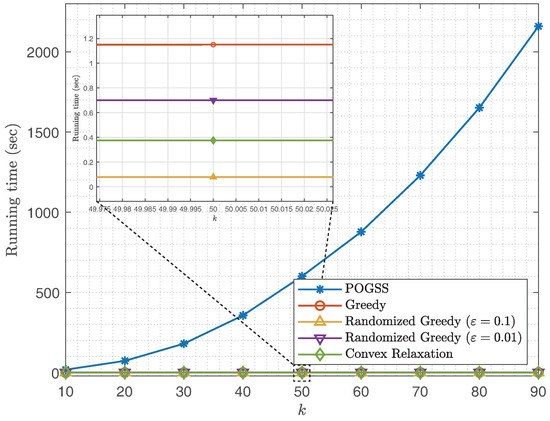
Figure 6.
Running time v.s. k for non-bandlimited graph signals obtained on ER graphs.
- if we fit the running time of POGSS with a quadratic function, then we have , thus POGSS only takes only when we add 10 nodes to the current sampling set, we think it is worthwhile to find a better solution with such a time consumption.
- In real world applications of graph signal sampling, e.g., [8], the sampling procedure is offline and the reconstruction procedure is online. We only need to sample the graph once then the entire graph signal can be always reconstructed with a small error, while the reconstruction time depends only on the size of the sampling set, rather than the sampling method.
We also provide a visual demonstration for our method. We use the stanford bunny data [6] to obtain the graph. The nodes are scanned from a 3D model, and the edges are obtained by connecting each node with its’ four nearest neighbors. The smooth graph signal is first sampled from a Gaussian distribution, and then filtered by a heat diffusion low-pass filter [24]. The resulting graph Fourier coefficients after filtering are
where t is the scaling parameter and is set to 10 in our experiment. As displayed in Figure 7a is the original smooth graph signal with Gaussian noise, the noise power is . There are nodes in the original graph, and we sample a subset with nodes by using POGSS to obtain Figure 7b, note that all of the edges are from the original graph. Figure 7c illustrates the optimally recovered graph signal by using (3), and the corresponding reconstruction error is .
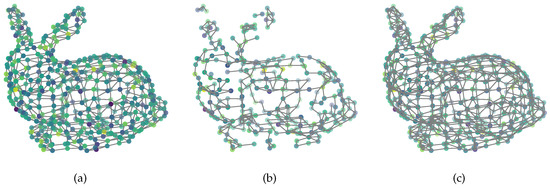
Figure 7.
(a) Original noisy signal; (b) sampled noisy signal; (c) reconstructed signal.
6. Conclusions
In this paper, we consider the graph signal sampling problem, which can be formulated as a subset selection problem. The evolutionary Pareto optimization for graph signal sampling (POGSS) is proposed for solving this problem. An efficient procedure is also proposed to accelerate the evaluation of the objective function. Theoretical analysis shows that POGSS, in polynomial time, achieves the best approximation upper bound of as the state-of-the-art greedy algorithm does, and an lower bound of is built as well. Simulation results demonstrate that POGSS outperforms the previous greedy algorithms.
Author Contributions
Conceptualization, D.L. and B.S.; methodology, D.L.; software, D.L.; validation, S.Z., F.Y. and J.Z.; formal analysis, D.L.; investigation, D.L.; resources, D.L.; writing—original draft preparation, D.L.; writing—review and editing, D.L. and S.Z.; visualization, D.L.; supervision, J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ortega, A.; Frossard, P.; Kovačević, J.; Moura, J.M.F.; Vandergheynst, P. Graph signal processing: Overview, challenges, and applications. Proc. IEEE 2018, 106, 808–828. [Google Scholar] [CrossRef]
- Huang, W.; Bolton, T.A.W.; Medaglia, J.D.; Bassett, D.S.; Ribeiro, A.; Van De Ville, D. A graph signal processing perspective on functional brain imaging. Proc. IEEE 2018, 106, 868–885. [Google Scholar] [CrossRef]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric deep learning: Going beyond Euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef]
- Sharma, V.K. Efficient image steganography using graph signal processing. IET Image Process. 2018, 12, 1065–1071. [Google Scholar] [CrossRef]
- Pang, J.; Cheung, G.; Hu, W.; Au, O.C. Redefining self-similarity in natural images for denoising using graph signal gradient. In Proceedings of the Signal and Information Processing Association Annual Summit and Conference (APSIPA), 2014 Asia-Pacific, Chiang Mai, Thailand, 9–12 December 2014; pp. 1–8. [Google Scholar] [CrossRef]
- Turk, G.; Levoy, M. Zippered polygon meshes from range images. In Proceedings of the 21st Annual Conference on Computer Graphics and Interactive Techniques, Orlando, FL, USA, 24–29 July 1994; Association for Computing Machinery: New York, NY, USA, 1994; pp. 311–318. [Google Scholar] [CrossRef]
- Lin, T.; Zha, H. Riemannian manifold learning. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 796–809. [Google Scholar]
- Sakiyama, A.; Tanaka, Y.; Tanaka, T.; Ortega, A. Efficient sensor position selection using graph signal sampling theory. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 6225–6229. [Google Scholar] [CrossRef]
- Chen, S.; Tian, D.; Feng, C.; Vetro, A.; Kovačević, J. Fast resampling of three-dimensional point clouds via graphs. IEEE Trans. Signal Process. 2018, 66, 666–681. [Google Scholar] [CrossRef]
- Chamon, L.F.O.; Ribeiro, A. Greedy sampling of graph signals. IEEE Trans. Signal Process. 2018, 66, 34–47. [Google Scholar] [CrossRef]
- Hashemi, A.; Shafipour, R.; Vikalo, H.; Mateos, G. Sampling and reconstruction of graph signals via weak submodularity and semidefinite relaxation. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4179–4183. [Google Scholar] [CrossRef]
- Alpago, D.; Zorzi, M.; Ferrante, A. Identification of sparse reciprocal graphical models. IEEE Control. Syst. Lett. 2018, 2, 659–664. [Google Scholar] [CrossRef]
- Ciccone, V.; Ferrante, A.; Zorzi, M. Robust identification of “Sparse Plus Low-rank” graphical models: An optimization approach. In Proceedings of the 2018 IEEE Conference on Decision and Control (CDC), Miami, FL, USA, 17–19 December 2018; pp. 2241–2246. [Google Scholar] [CrossRef]
- Natarajan, B.K. Sparse approximate solutions to linear systems. SIAM J. Comput. 1995, 24, 227–234. [Google Scholar] [CrossRef]
- Das, A.; Kempe, D. Submodular meets spectral: Greedy algorithms for subset selection, sparse approximation and dictionary selection. In Proceedings of the 2011 IEEE International Conference on Machine Learning (ICML), Washington, DC, USA, 28 June–2 July 2011. [Google Scholar]
- Qian, C.; Yu, Y.; Zhou, Z.H. Subset selection by Pareto Optimization. In Advances in Neural Information Processing Systems; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; MIT Press: Cambridge, MA, USA, 2015; Volume 28, pp. 1774–1782. [Google Scholar]
- Qian, C.; Bian, C.; Feng, C. Subset selection by Pareto Optimization with recombination. Proc. AAAI Conf. Artif. Intell. 2020, 34, 2408–2415. [Google Scholar] [CrossRef]
- Qian, C.; Shi, J.C.; Yu, Y.; Tang, K.; Zhou, Z.H. Subset selection under noise. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; MIT Press: Cambridge, MA, USA, 2017; Volume 30, pp. 3560–3570. [Google Scholar]
- Chen, S.; Varma, R.; Sandryhaila, A.; Kovačević, J. Discrete signal processing on graphs: Sampling theory. IEEE Trans. Signal Process. 2015, 63, 6510–6523. [Google Scholar] [CrossRef]
- Tylavsky, D.J.; Sohie, G.R.L. Generalization of the matrix inversion lemma. Proc. IEEE 1986, 74, 1050–1052. [Google Scholar] [CrossRef]
- Bogunovic, I.; Zhao, J.; Cevher, V. Robust maximization of non-submodular objectives. In Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, Lanzarote, Canary Islands, 9–11 April 2018; Storkey, A., Perez-Cruz, F., Eds.; PMLR: Brookline, MA, USA, 2018; Volume 84, pp. 890–899. [Google Scholar]
- Zhou, Z.H.; Yu, Y.; Qian, C. Evolutionary learning: Advances in Theories and Algorithms, 1st ed.; Springer: Singapore, 2019. [Google Scholar]
- Joshi, S.; Boyd, S. Sensor selection via Convex Optimization. IEEE Trans. Signal Process. 2009, 57, 451–462. [Google Scholar] [CrossRef]
- Zhang, F.; Hancock, E.R. Graph spectral image smoothing using the heat kernel. Pattern Recognit. 2008, 41, 3328–3342. [Google Scholar] [CrossRef]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).