
Sequential Sampling and Estimation of Approximately Bandlimited Graph Signals


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. System Model
2.1. Preliminaries
2.2. Signal Prior
2.3. Observation Model
2.4. Problem Formulation
3. Algorithm
3.1. Hyperparameter and Signal Estimation
| Algorithm 1 Hyperparameter and signal estimation by EM. |
3.2. Sample Selection
3.3. Sequential Sampling and Estimation
| Algorithm 2 Sequential sampling and estimation of approximately bandlimited graph signals. |
|
4. Asymptotic Analysis
5. Experiments
- RndEM: Select sampling nodes randomly and uniformly, and estimate hyperparameters and the signal using the proposed EM algorithm.
- OrcUS: Suppose that the hyperparameters are known in advance (the “oracle”). Select sampling nodes by US, and estimate the signal by MMSE/MAP.
- Anis2016: A heuristic sampling algorithm proposed in Anis et al. [7] to maximize the cut-off frequency such that the sampling set is a uniqueness set for the bandlimited subspace. The graph signal is recovered in the bandlimited subspace by least squares. The estimation order k of cut-off frequency is set to .
- Perraudin2018: A nonuniform random sampling method proposed in Perraudin et al. [21] with probability relevant to local uncertainty. Inpainting is done by minimizing total variation. The kernel in local uncertainty is where .
- Sakiyama2019: In this method by Sakiyama et al. [31], the graph signal is recovered by a linear combination of localization operators at the sampled nodes. The sampling set is designed such that the energy of operator at each node is large and meanwhile the overlapping areas are small. The kernel in localization operator is where . The Chebyshev polynomial approximation order is , and the signal recovery order is .
5.1. Simulations on Synthetic Data
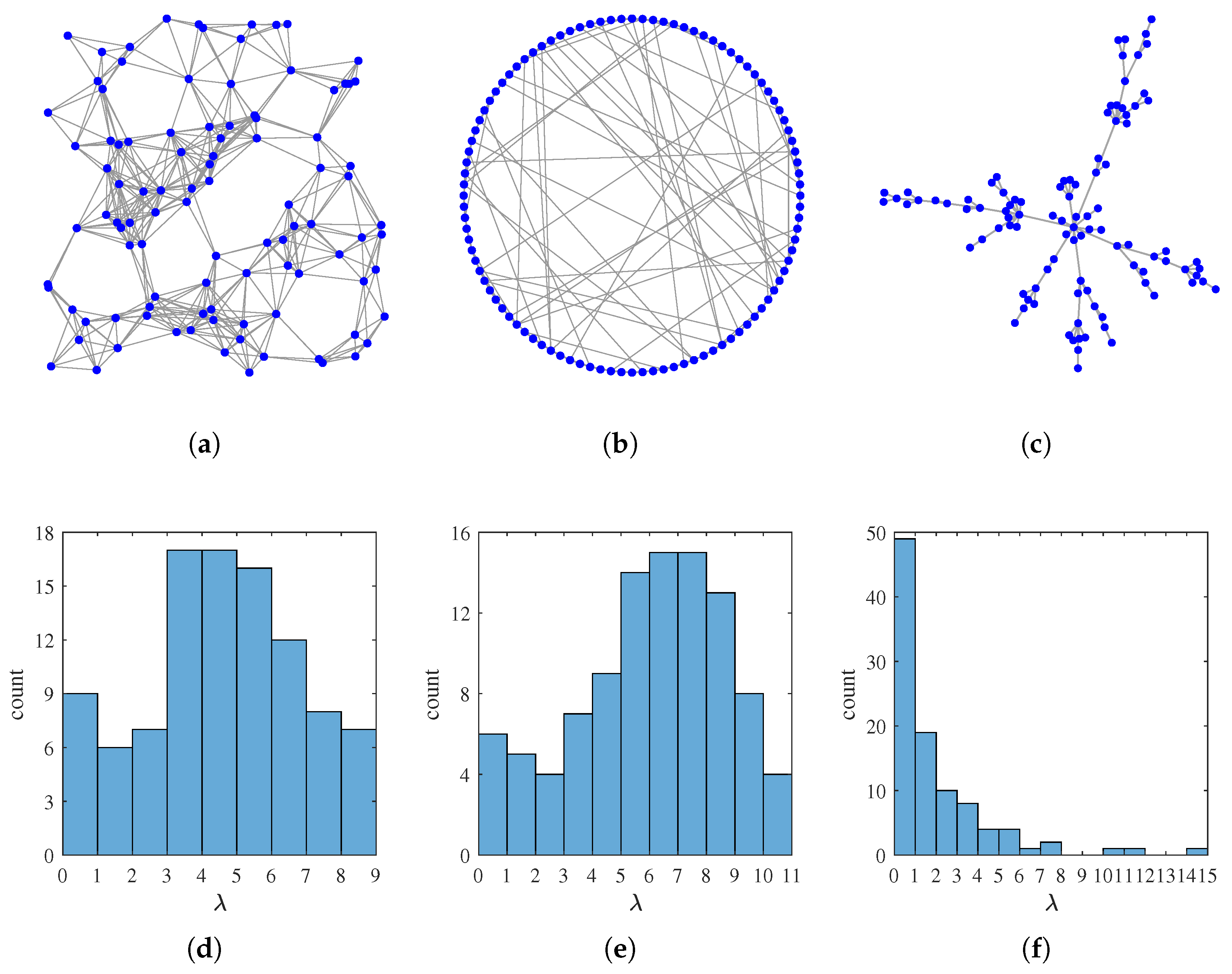
- : A random geometric graph with vertices randomly placed in a 1-by-1 square, and edge weights assigned via a thresholded Gaussian kernelwhere is the Euclid distance between vertex i and vertex j, and .
- : A small world graph with nodes, generated by the Watts–Strogatz model [32] with mean node degree 6 and rewiring probability .
5.2. A Real-World Example of Temperature Sensor Network
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Concavity of Objective Function in M Step
Appendix B. Search Method for Optimization Problem in M Step

Appendix C. Proof of Lemma 1
Appendix D. Proof of Theorem 2
References
- Shuman, D.I.; Narang, S.K.; Frossard, P.; Ortega, A.; Vandergheynst, P. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains. IEEE Signal Process. Mag. 2013, 30, 83–98. [Google Scholar] [CrossRef] [Green Version]
- Sandryhaila, A.; Moura, J.M.F. Discrete signal processing on graphs. IEEE Trans. Signal Process. 2013, 61, 1644–1656. [Google Scholar] [CrossRef] [Green Version]
- Shuman, D.I.; Vandergheynst, P.; Frossard, P. Chebyshev polynomial approximation for distributed signal processing. In Proceedings of the 2011 International Conference on Distributed Computing in Sensor Systems and Workshops (DCOSS), Barcelona, Spain, 27–29 June 2011. [Google Scholar]
- Shi, X.; Feng, H.; Zhai, M.; Yang, T.; Hu, B. Infinite impulse response graph filters in wireless sensor networks. IEEE Signal Process. Lett. 2015, 22, 1113–1117. [Google Scholar] [CrossRef]
- Loukas, A.; Simonetto, A.; Leus, G. Distributed autoregressive moving average graph filters. IEEE Signal Process. Lett. 2015, 22, 1931–1935. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Varma, R.; Sandryhaila, A.; Kovačević, J. Discrete signal processing on graphs: Sampling theory. IEEE Trans. Signal Process. 2015, 63, 6510–6523. [Google Scholar] [CrossRef] [Green Version]
- Anis, A.; Gadde, A.; Ortega, A. Efficient sampling set selection for bandlimited graph signals using graph spectral proxies. IEEE Trans. Signal Process. 2016, 64, 3775–3789. [Google Scholar] [CrossRef]
- Narang, S.K.; Gadde, A.; Ortega, A. Signal processing techniques for interpolation in graph structured data. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 5445–5449. [Google Scholar]
- Sakiyama, A.; Tanaka, Y.; Tanaka, T.; Ortega, A. Efficient sensor position selection using graph signal sampling theory. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 6225–6229. [Google Scholar]
- Jabłoński, I. Graph signal processing in applications to sensor networks, smart grids, and smart cities. IEEE Sens. J. 2017, 17, 7659–7666. [Google Scholar] [CrossRef]
- Huang, W.; Bolton, T.A.W.; Medaglia, J.D.; Bassett, D.S.; Ribeiro, A.; Ville, D.V.D. A graph signal processing perspective on functional brain imaging. Proc. IEEE 2018, 106, 868–885. [Google Scholar] [CrossRef]
- Cheung, G.; Magli, E.; Tanaka, Y.; Ng, M.K. Graph spectral image processing. Proc. IEEE 2018, 106, 907–930. [Google Scholar] [CrossRef] [Green Version]
- Dinesh, C.; Cheung, G.; Bajić, I.V. Point cloud denoising via feature graph Laplacian regularization. IEEE Trans. Image Process. 2020, 29, 4143–4158. [Google Scholar] [CrossRef] [PubMed]
- Gadde, A.; Anis, A.; Ortega, A. Active semi-supervised learning using sampling theory for graph signals. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 492–501. [Google Scholar]
- Anis, A.; El Gamal, A.; Avestimehr, A.S.; Ortega, A. A sampling theory perspective of graph-based semi-supervised learning. IEEE Trans. Inf. Theory 2019, 65, 2322–2342. [Google Scholar] [CrossRef] [Green Version]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the 5th International Conference on Learning Representations (ICLR), Palais des Congrès Neptune, Toulon, France, 24–26 April 2017. [Google Scholar]
- Chen, S.; Varma, R.; Singh, A.; Kovačević, J. Signal recovery on graphs: Fundamental limits of sampling strategies. IEEE Trans. Signal Inf. Process. Netw. 2016, 2, 539–554. [Google Scholar] [CrossRef] [Green Version]
- Puy, G.; Tremblay, N.; Gribonval, R.; Vandergheynst, P. Random sampling of bandlimited signals on graphs. Appl. Comput. Harmon. Anal. 2018, 44, 446–475. [Google Scholar] [CrossRef] [Green Version]
- Xie, X.; Feng, H.; Jia, J.; Hu, B. Design of sampling set for bandlimited graph signal estimation. In Proceedings of the 2017 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Montreal, QC, Canada, 14–16 November 2017; pp. 653–657. [Google Scholar]
- Lin, S.; Xie, X.; Feng, H.; Hu, B. Active sampling for approximately bandlimited graph signals. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 5441–5445. [Google Scholar]
- Perraudin, N.; Ricaud, B.; Shuman, D.I.; Vandergheynst, P. Global and local uncertainty principles for signals on graphs. APSIPA Trans. Signal Inf. Process. 2018, 7, e3. [Google Scholar] [CrossRef] [Green Version]
- Xie, X.; Yu, J.; Feng, H.; Hu, B. Bayesian design of sampling set for bandlimited graph signals. In Proceedings of the 2019 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Ottawa, ON, Canada, 11–14 November 2019. [Google Scholar]
- Gadde, A.; Ortega, A. A probabilistic interpretation of sampling theory of graph signals. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 3257–3261. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006; ISBN 9780387310732. [Google Scholar]
- Settles, B. Active Learning; Morgan & Claypool: San Rafael, CA, USA, 2012; ISBN 9781608457250. [Google Scholar]
- Bernardo, J.M.; Smith, A.F.M. Bayesian Theory; John Wiley & Sons: Hoboken, NJ, USA, 1994; ISBN 0471924164. [Google Scholar]
- Petrone, S.; Rousseau, J.; Scricciolo, C. Bayes and empirical Bayes: Do they merge? Biometrika 2014, 101, 285–302. [Google Scholar] [CrossRef] [Green Version]
- Pronzato, L. One-step ahead adaptive D-optimal design on a finite design space is asymptotically optimal. Metrika 2010, 71, 219–238. [Google Scholar] [CrossRef] [Green Version]
- Oppenheim, A.V.; Schafer, R.W. Discrete-Time Signal Processing, 3rd ed.; Prentice Hall: Englewood Cliffs, NJ, USA, 2009; ISBN 9780136024552. [Google Scholar]
- Kay, S.M. Fundamentals of Statistical Signal Processing, Volume I: Estimation Theory; Prentice Hall: Englewood Cliffs, NJ, USA, 1993; ISBN 9780133457117. [Google Scholar]
- Sakiyama, A.; Tanaka, Y.; Tanaka, T.; Ortega, A. Eigendecomposition-free sampling set selection for graph signals. IEEE Trans. Signal Process. 2019, 67, 2679–2692. [Google Scholar] [CrossRef] [Green Version]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Perraudin, N.; Paratte, J.; Shuman, D.; Martin, L.; Kalofolias, V.; Vandergheynst, P.; Hammond, D.K. GSPBOX: A toolbox for signal processing on graphs. arXiv 2016, arXiv:1408.5781v2 [cs.IT]. [Google Scholar]
- Integrated Surface Database (ISD) by National Climatic Data Center (NCDC) of the USA. Available online: https://www.ncdc.noaa.gov/isd (accessed on 11 December 2020).







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, S.; Xu, K.; Feng, H.; Hu, B. Sequential Sampling and Estimation of Approximately Bandlimited Graph Signals. Sensors 2021, 21, 1460. https://doi.org/10.3390/s21041460
Lin S, Xu K, Feng H, Hu B. Sequential Sampling and Estimation of Approximately Bandlimited Graph Signals. Sensors. 2021; 21(4):1460. https://doi.org/10.3390/s21041460
Chicago/Turabian StyleLin, Sijie, Ke Xu, Hui Feng, and Bo Hu. 2021. "Sequential Sampling and Estimation of Approximately Bandlimited Graph Signals" Sensors 21, no. 4: 1460. https://doi.org/10.3390/s21041460