
Siamese Networks-Based People Tracking Using Template Update for 360-Degree Videos Using EAC Format †

Abstract
:1. Introduction
1.1. Visual Tracking on 360-Degree Videos
1.2. Siamese Networks Based Visual Trackers
1.3. Template Update for Siamese Networks Based Visual Trackers
1.4. Motivation and Contributions of The Proposed Scheme
2. Overview of Projection Format Conversion and Fully-Convolutional Siamese Networks Based Tracker
2.1. Conversion from Equirectangular Projection (ERP) to Equi-Angular Cubemap (EAC)
2.2. Fully-Convolutional Siamese Networks Based Tracker
3. The Proposed Tracking Scheme for EAC Format of 360-Degree Videos
3.1. Face Stitching of EAC Format
3.2. Feature Extraction of Score Maps Using Machine Learning Based Dimensionality Reduction
3.3. The Proposed Machine Learning Based Timing Detector of Template Update
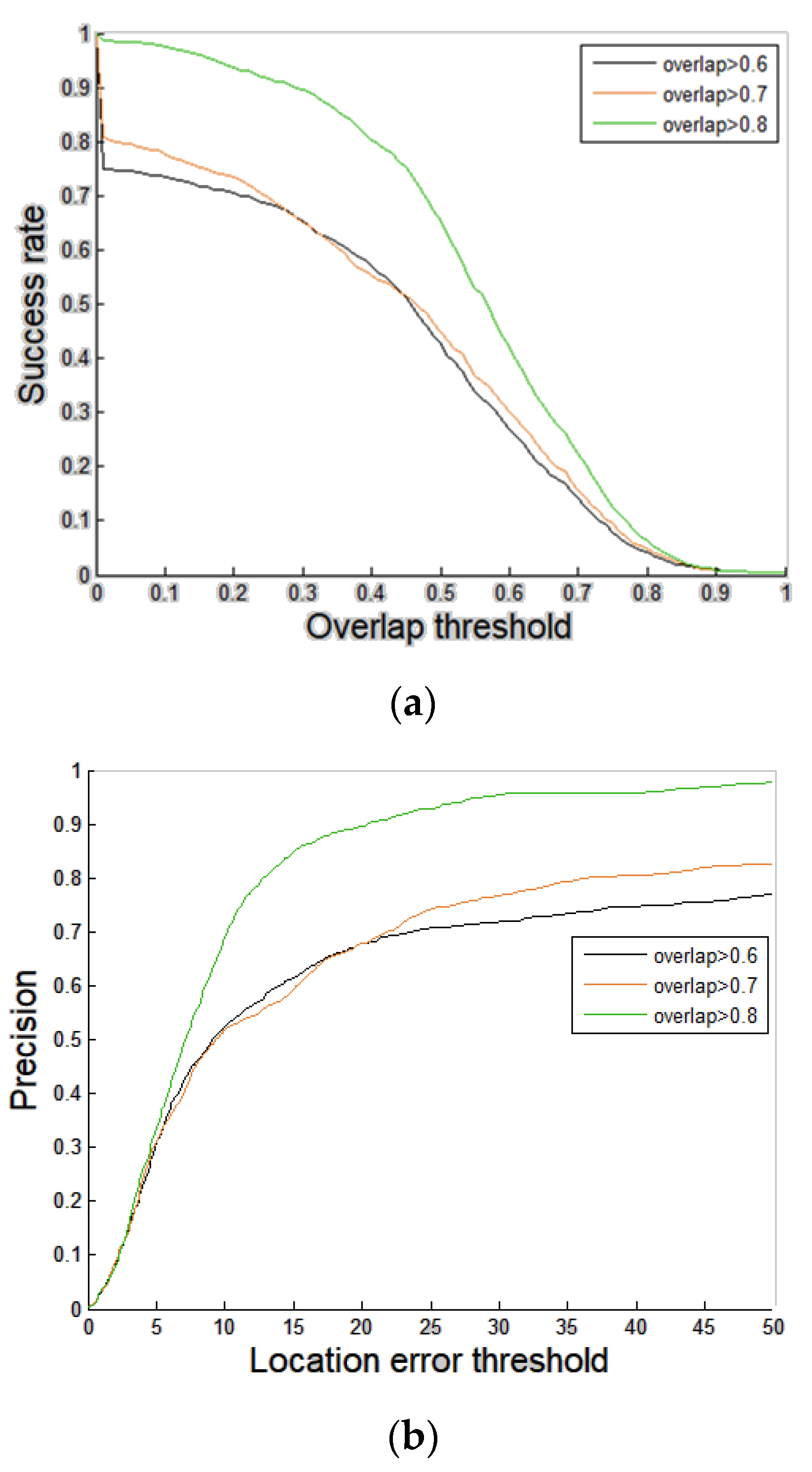
4. Experimental Results
4.1. Performance Analyses of Individual Components of the Proposed Scheme
4.2. Comparisons with State-of-the-Art People Trackers for 360-Degree EAC Format Videos
4.3. Comparisons with State-of-the-Art Score Map Based Timing Detector of Template Update
4.4. Validation of the Effectiveness of the Proposed Template Update Scheme for Siamese Networks Based Tracking on 360-Degree EAC Format Videos
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Azevedo, R.G.D.A.; Birkbeck, N.; De Simone, F.; Janatra, I.; Adsumilli, B.; Frossard, P. Visual Distortions in 360° Videos. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2524–2537. [Google Scholar] [CrossRef]
- Zhou, M. AHG8: A study on equi-angular cubemap projection (EAC). In Proceedings of the Joint Video Exploration Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11 7th Meeting: JVET-G0056, Torino, Italy, 13–21 July 2017. [Google Scholar]
- ISO/IEC JTC 1/SC29/WG11, “WG11 (MPEG) Press Release”. In Proceedings of the 131st WG 11 (MPEG) Meeting, online. 29 June–3 July 2020.
- Liu, K.-C.; Shen, Y.-T.; Chen, L.-G. Simple online and realtime tracking with spherical panoramic camera. In Proceedings of the IEEE International Conference on Consumer Electronics, Las Vegas, NV, USA, 12–15 January 2018; pp. 1–6. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Zhou, Z.; Niu, B.; Ke, C.; Wu, W. Static object tracking in road panoramic videos. In Proceedings of the IEEE International Symposium on Multimedia, Taichung, Taiwan, 13–15 December 2010; pp. 57–64. [Google Scholar]
- Available online: https://www.mettle.com/360vr-master-series-free-360-downloads-page (accessed on 1 June 2018).
- Mikolajczyk, K.; Schmid, C. A performance evaluation of local descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, N.; Yeung, D.Y. Learning a deep compact image representation for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 809–817. [Google Scholar]
- Bromley, J.; Guyon, I.; LeCun, Y.; Sackinger, E.; Shah, R. Signature verification using a Siamese time delay neural network. Int. J. Pattern Recog. 1993, 7, 669–688. [Google Scholar] [CrossRef] [Green Version]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 fps with deep regression networks. In Proceedings of the European Conference on Computer Vision, Amsterdan, The Netherlands, 11–14 October 2016; pp. 749–765. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.A. Fully-convolutional Siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision, Amsterdan, The Netherlands, 11–14 October 2016; pp. 850–865. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with Siamese region proposal network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese visual tracking with very deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4277–4286. [Google Scholar]
- Liang, Z.; Shen, J. Local semantic Siamese networks for fast tracking. IEEE Trans. Image Process. 2020, 20, 3351–3364. [Google Scholar] [CrossRef] [PubMed]
- He, A.; Luo, C.; Tian, X.; Zeng, W. A twofold Siamese network for real-time object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4834–4843. [Google Scholar]
- Han, Z.; Wang, P.; Ye, Q. Adaptive discriminative deep correlation filter for visual object tracking. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 155–166. [Google Scholar] [CrossRef]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H.S. End-to-end representation learning for correlation filter based tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5000–5008. [Google Scholar]
- Yang, T.; Chan, A.B. Learning dynamic memory networks for object tracking. arXiv 2018, arXiv:1803.07268. [Google Scholar]
- Xu, Z.; Luo, H.; Bin, H.; Chang, Z. Siamese tracking with adaptive template updating strategy. Appl. Sci. 2019, 9, 3725. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Liu, Y.; Huang, Z. Large margin object tracking with circulant feature maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 21–26. [Google Scholar]
- Wien, M.; Boyce, J.M.; Stockhammer, T.; Peng, W.-H. Standardization status of immersive video coding. IEEE J. Emerg. Sel. Topics Power Electron. 2019, 9, 5–17. [Google Scholar] [CrossRef]
- Tai, K.-C.; Tang, C.-W. Siamese networks based people tracking for 360-degree videos with equi-angular cubemap format. In Proceedings of the IEEE International Conference on Consumer Electronics-Taiwan, Taoyuan, Taiwan, 28–30 September 2020. [Google Scholar]
- Woods, R.; Czitrom, D.J.; Gonzales, R.C.; Armitage, S. Digital Image Processing, 3rd ed.; Prentice Hall: New Jersey, NJ, USA, 2008. [Google Scholar]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Fei-Fei Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.-H. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [Green Version]
- Fukunaga, K. Introduction to Statistical Pattern Recognition, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Shum sir, 360 VR, Shum sir Rebik’s Cube. 2017. Available online: https://www.youtube.com/watch?v=g5taEwId2wA (accessed on 19 August 2019).
- Duanmu, F.; Mao, Y.; Liu, S.; Srinivasan, S.; Wang, Y. A subjective study of viewer navigation behaviors when watching 360-degree videos on computers. In Proceedings of the IEEE International Conference on Multimedia Expo, San Diego, CA, USA, 23–27 July 2018; pp. 1–6. Available online: https://vision.poly.edu/index.html/index.php/HomePage/360-degreeVideoViewPrediction (accessed on 1 June 2019).
- Fodor, I.K. A Survey of Dimension Reduction Techniques, No. UCRL-ID-148494; Lawrence Livermore National Lab.: Livermore, CA, USA, 2020.
- Cooke, T.; Peake, M. The optimal classification using a linear discriminant for two point classes having known mean and covariance. J. Multivar. Anal. 2002, 82, 379–394. [Google Scholar] [CrossRef] [Green Version]
- Bilylee/SiamFC-TensorFlow. Available online: https://github.com/bilylee/SiamFC-TensorFlow (accessed on 27 March 2019).






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Examples | Template Update | Timing Detector of Template Update | Year | Remark | |
|---|---|---|---|---|---|
| Trackers for 360-Degree Videos | Liu et al. 2018 [4] | X | X | 2018 | 1. ERP format 2. DeepSort-based [5] |
| Zhou et al. [6] | X | X | 2010 | 1. CMP format 2. Mean Shift-Based | |
| The First Deep Learning-Based Tracker | DLT [9] | X | X | 2013 | Stacked autoencoder-based |
| Siamese Networks Based Trackers | GoTurn [11] | X | X | 2016 | Pioneer |
| SiamFC [12] | X | X | 2016 | Pioneer | |
| SiamRPN [13] | X | X | 2018 | Region proposal network | |
| SiamRPN++ [14] | X | X | 2019 | Effective sampling strategy | |
| SA-Siam [16] | X | X | 2018 | Semantic branch and similarity branch | |
| adaDCF [17] | X | X | 2020 | FDA discriminates between foreground and background | |
| CFNet [18] | Aggressive strategy | X | 2017 | Correlation filter-based template generation | |
| Yang et al. [19] | Aggressive strategy | X | 2018 | Attentional LSTM controls memory for template generation | |
| Xu et al. [20] | Non-aggressive strategy | Using highest score of a score map | 2019 | UAVs-Based Tracking | |
| Wang et al. [21] | Non-aggressive strategy | APCE of a score map | 2017 | ||
| Liang et al. [15] | Non-aggressive strategy | Update interval and APCE [21] | 2020 | ||
| Tai et al. [23] | Non-aggressive strategy | Statistics of score map | 2020 | EAC format |
| Overlap Ratio | Location Error (Units: Pixels) | |||||
|---|---|---|---|---|---|---|
| SiamFC | SiamFC + S | SiamFC + S + P (Proposed) | SiamFC | SiamFC + S | SiamFC + S + P (Proposed) | |
| Video#1 | 0.046 | 0.481 | 0.479 | 106.343 | 10.171 | 10.152 |
| Video#2 | 0.065 | 0.563 | 0.547 | 118.246 | 9958 | 9730 |
| Video#3 | 0.121 | 0.728 | 0.688 | 94.033 | 2270 | 2714 |
| Video#4 | 0.247 | 0.518 | 0.532 | 84.880 | 7507 | 6746 |
| Video#5 | 0.607 | 0.648 | 0.653 | 6276 | 5936 | 4956 |
| Video#6 | 0.303 | 0.363 | 0.366 | 25.024 | 11.341 | 10.763 |
| Video#7 | 0.100 | 0.236 | 0.593 | 316.711 | 90.486 | 9264 |
| Video#8 | 0.102 | 0.235 | 0.518 | 172.300 | 140.250 | 27.011 |
| Average | 0.199 | 0.491 | 0.547 | 115.477 | 34.740 | 10.167 |
| t = 2 | t = 120 | t = 200 | |
|---|---|---|---|
| SiamFC + S |  |  |  |
| SiamFC + S + P (Proposed Scheme) |  |  |  |
| Ground Truth | |||
|---|---|---|---|
| True | False | ||
| Prediction | Positive | 7 | 75 |
| Negative | 89 | 1421 | |
| t = 2 | t = 120 | t = 200 | |
|---|---|---|---|
| SiamFC + S |  |  |  |
| SiamFC + S+P (Proposed Scheme) |  |  |  |
| Overlap Ratio | Location Error (Units: Pixels) | |||
|---|---|---|---|---|
| SiamFC + S + H (Tai et al.) [23] | SiamFC + S + P (Proposed) | SiamFC + S + H (Tai et al.) [23] | SiamFC + S + P (Proposed) | |
| Video#1 | 0.481 | 0.479 | 10.160 | 10.152 |
| Video#2 | 0.405 | 0.547 | 13.267 | 9730 |
| Video#3 | 0.660 | 0.688 | 3718 | 2714 |
| Video#4 | 0.531 | 0.532 | 7702 | 6746 |
| Video#5 | 0.692 | 0.653 | 4043 | 4956 |
| Video#6 | 0.337 | 0.366 | 11.928 | 10.763 |
| Video#7 | 0.599 | 0.593 | 5758 | 9264 |
| Video#8 | 0.572 | 0.518 | 17.330 | 27.011 |
| Average | 0.534 | 0.547 | 9238 | 10.167 |
| t = 2 | t = 85 | t = 200 | |
|---|---|---|---|
| SiamFC + S+H (Tai et al.) [23] |  |  |  |
| SiamFC + S+P (Proposed Scheme) |  |  |  |
| Tracker | Videos #1–#6, #8 | Videos #7 |
|---|---|---|
| SiamFC [12] +S | 62.35 fps | 23.42 fps |
| Tai et al. [23] (SiamFC + S + H) | 60 fps | 20 fps |
| Proposed Tracker (SiamFC + S + P) | 52.9 fps | 11.2 fps |
| SiamFC [12] +S +Timing Detector of Template Update of LSSiam [15] | 55.95 fps | 10.53 fps |
| SA-Siam [16] +S | 50.16 fps | 11.7 fps |
| SA-Siam [16] +S + P | 46.04 fps | 9.78 fps |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tai, K.-C.; Tang, C.-W. Siamese Networks-Based People Tracking Using Template Update for 360-Degree Videos Using EAC Format. Sensors 2021, 21, 1682. https://doi.org/10.3390/s21051682
Tai K-C, Tang C-W. Siamese Networks-Based People Tracking Using Template Update for 360-Degree Videos Using EAC Format. Sensors. 2021; 21(5):1682. https://doi.org/10.3390/s21051682
Chicago/Turabian StyleTai, Kuan-Chen, and Chih-Wei Tang. 2021. "Siamese Networks-Based People Tracking Using Template Update for 360-Degree Videos Using EAC Format" Sensors 21, no. 5: 1682. https://doi.org/10.3390/s21051682
APA StyleTai, K.-C., & Tang, C.-W. (2021). Siamese Networks-Based People Tracking Using Template Update for 360-Degree Videos Using EAC Format. Sensors, 21(5), 1682. https://doi.org/10.3390/s21051682