
Weakly Supervised Reinforcement Learning for Autonomous Highway Driving via Virtual Safety Cages



Abstract
:1. Introduction
- We combine the safety cages with reinforcement learning by intervening on unsafe control actions, as well as providing an additional learning signal for the agent to enable safe and efficient exploration.
- We compare the effect of the safety cages during training for both models with optimised hyperparameters, as well as less optimised models which may require additional safety considerations.
- We test all trained agents without safety cages enabled, in both naturalistic and adversarial driving scenarios, showing that even if the safety cages are only used during training, the models exhibit safer driving behaviour.
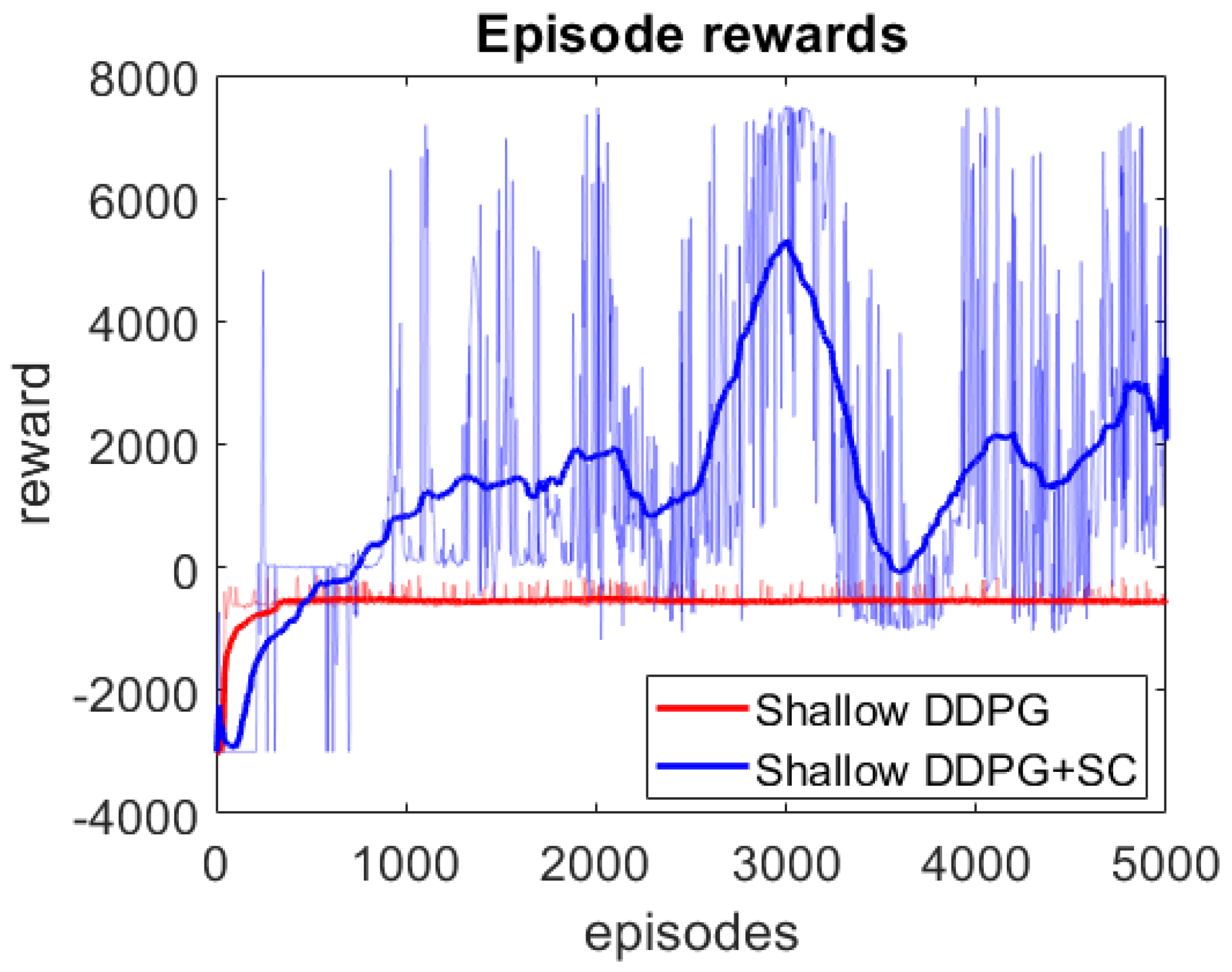
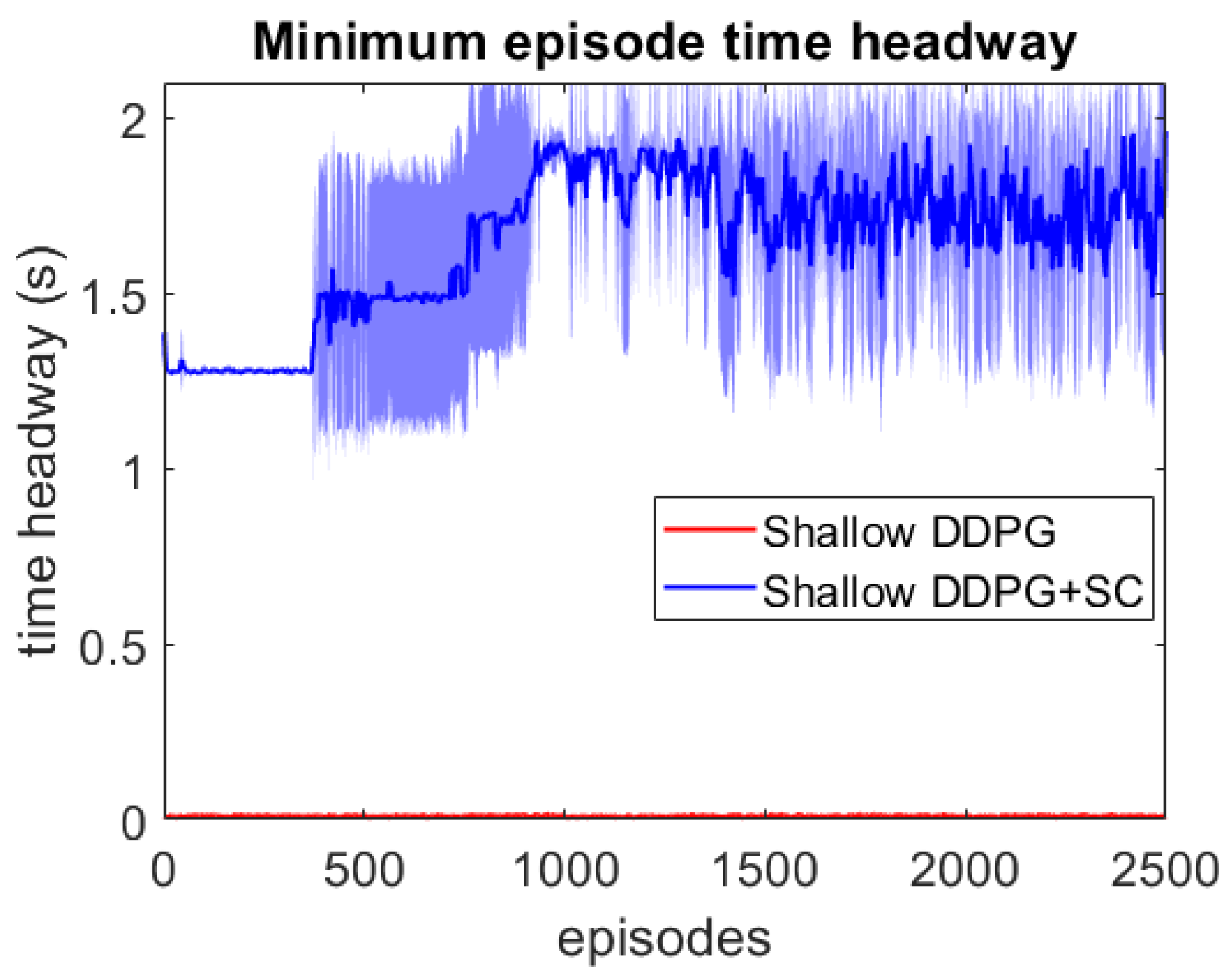
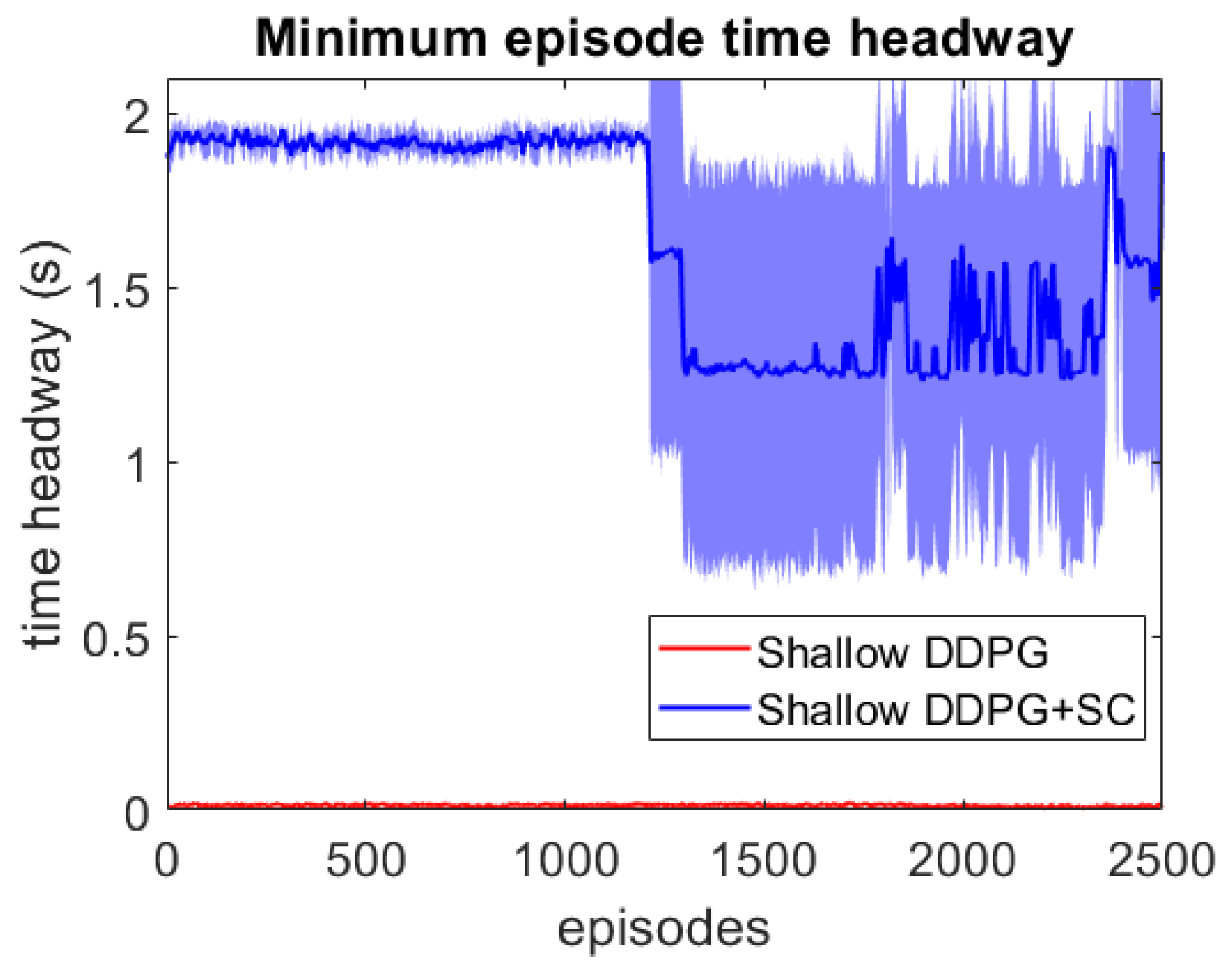
- We demonstrate that by using the weak supervision from the safety cages during training, the shallow model which otherwise could not learn to drive can be enabled to learn to drive without collisions.
2. Related Work
2.1. Autonomous Driving
2.2. Safety Cages
3. Materials and Methods
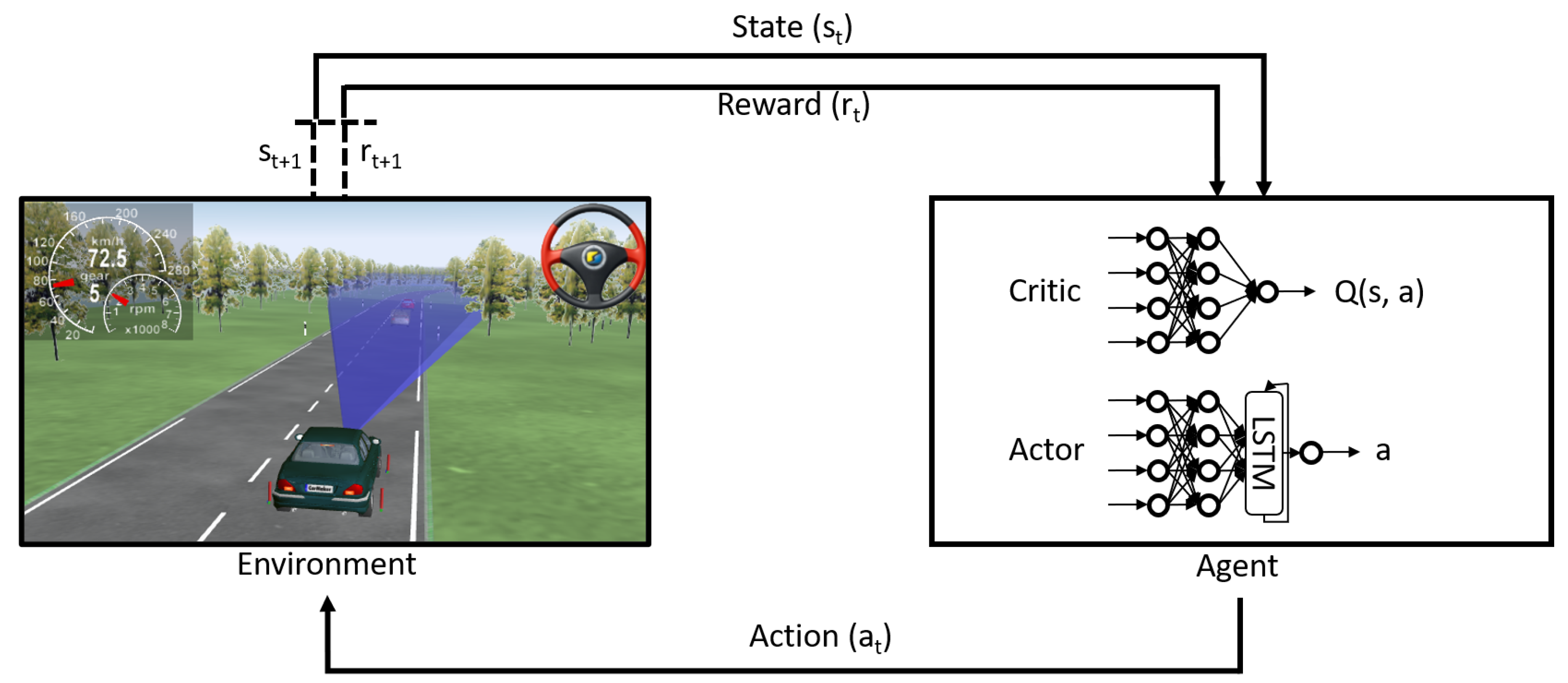
3.1. Reinforcement Learning
3.2. Deep Deterministic Policy Gradient
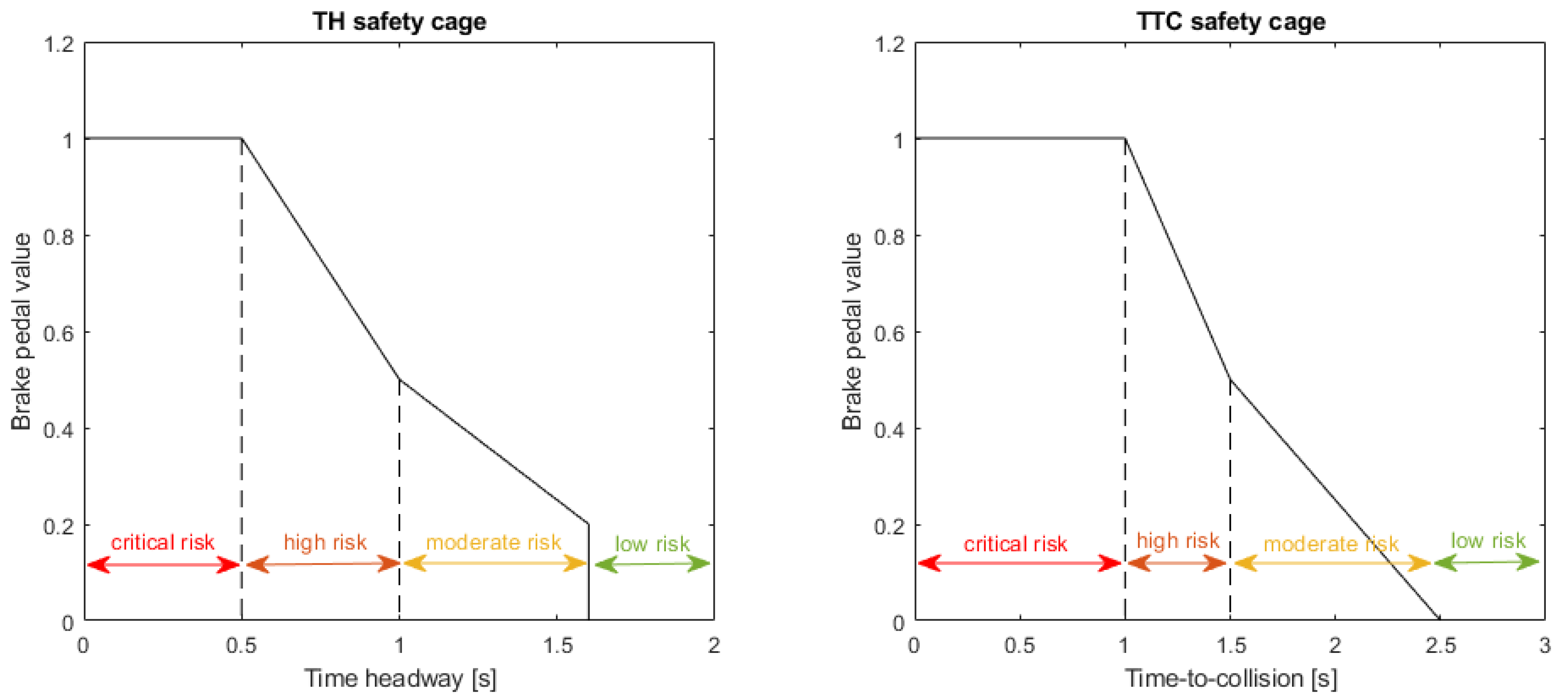
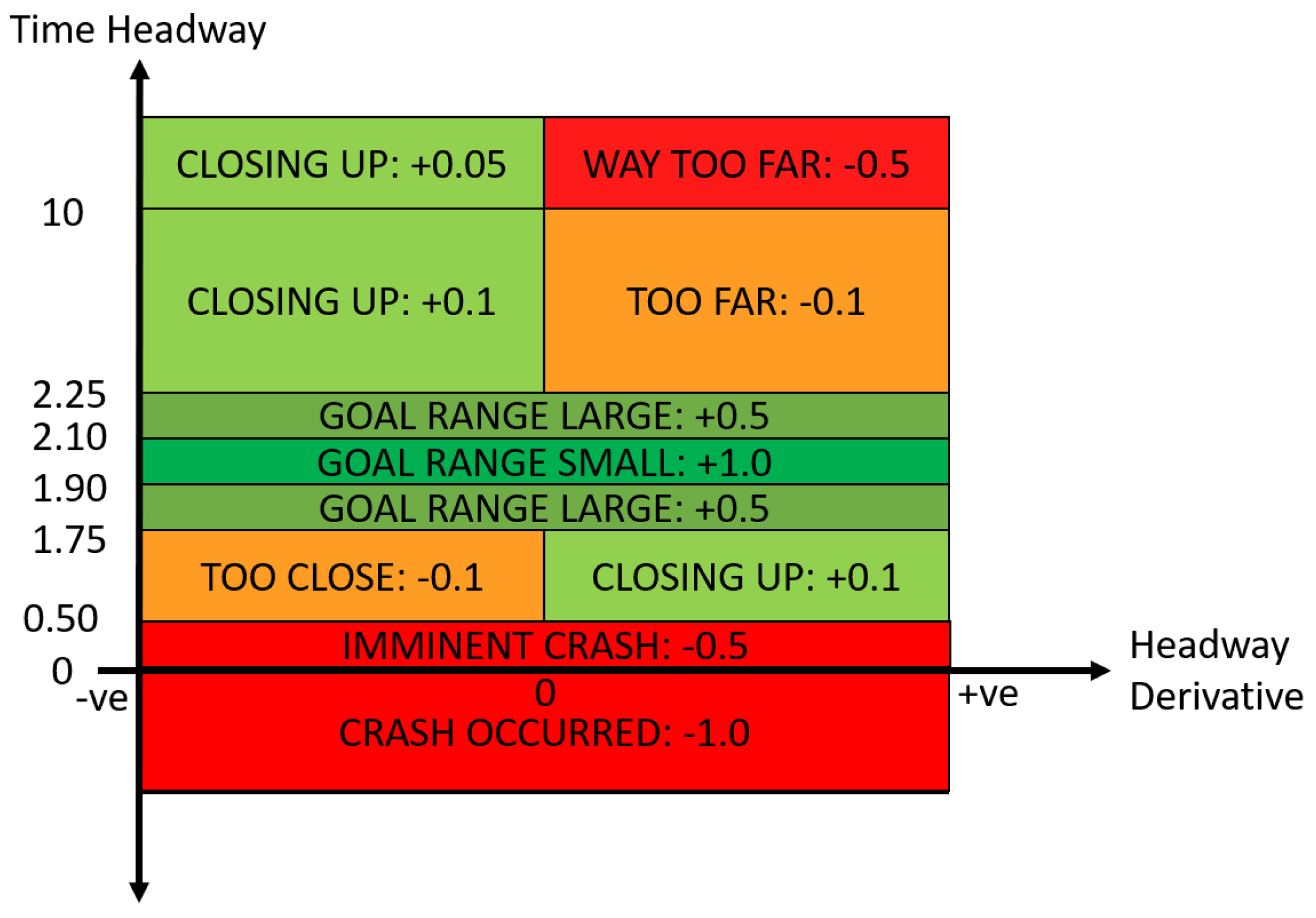
3.3. Safety Cages
3.4. Highway Vehicle Following Use-Case
3.5. Training
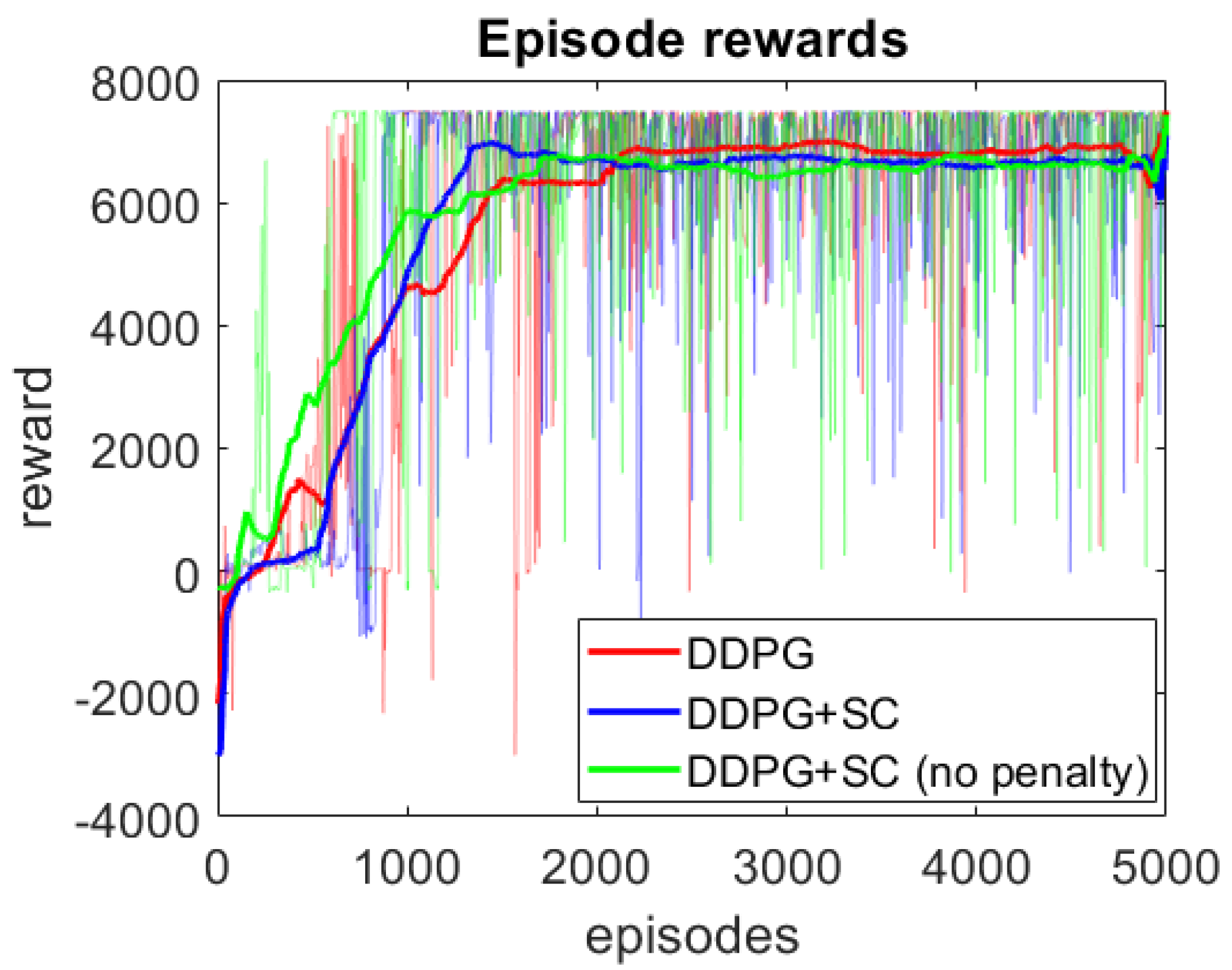
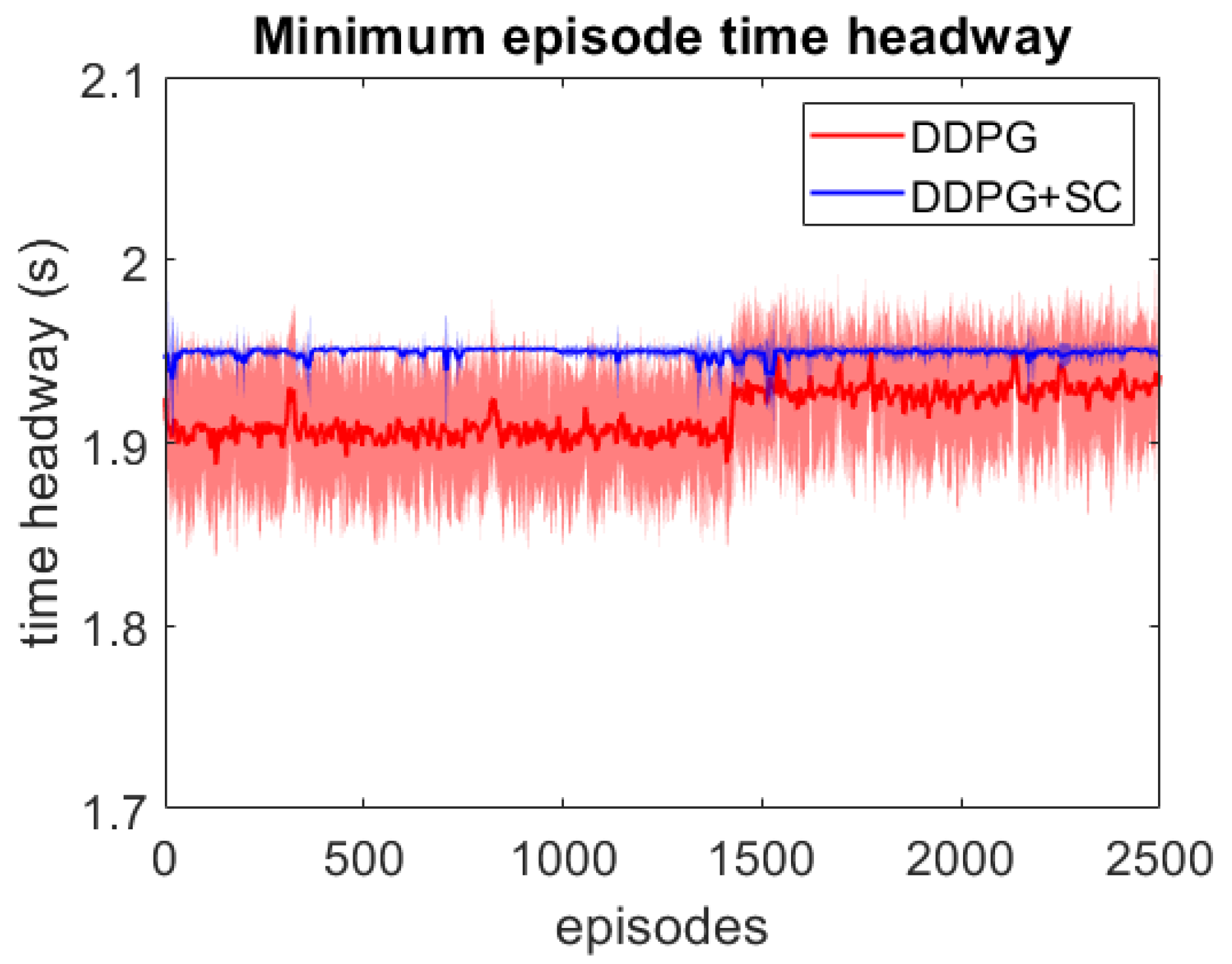
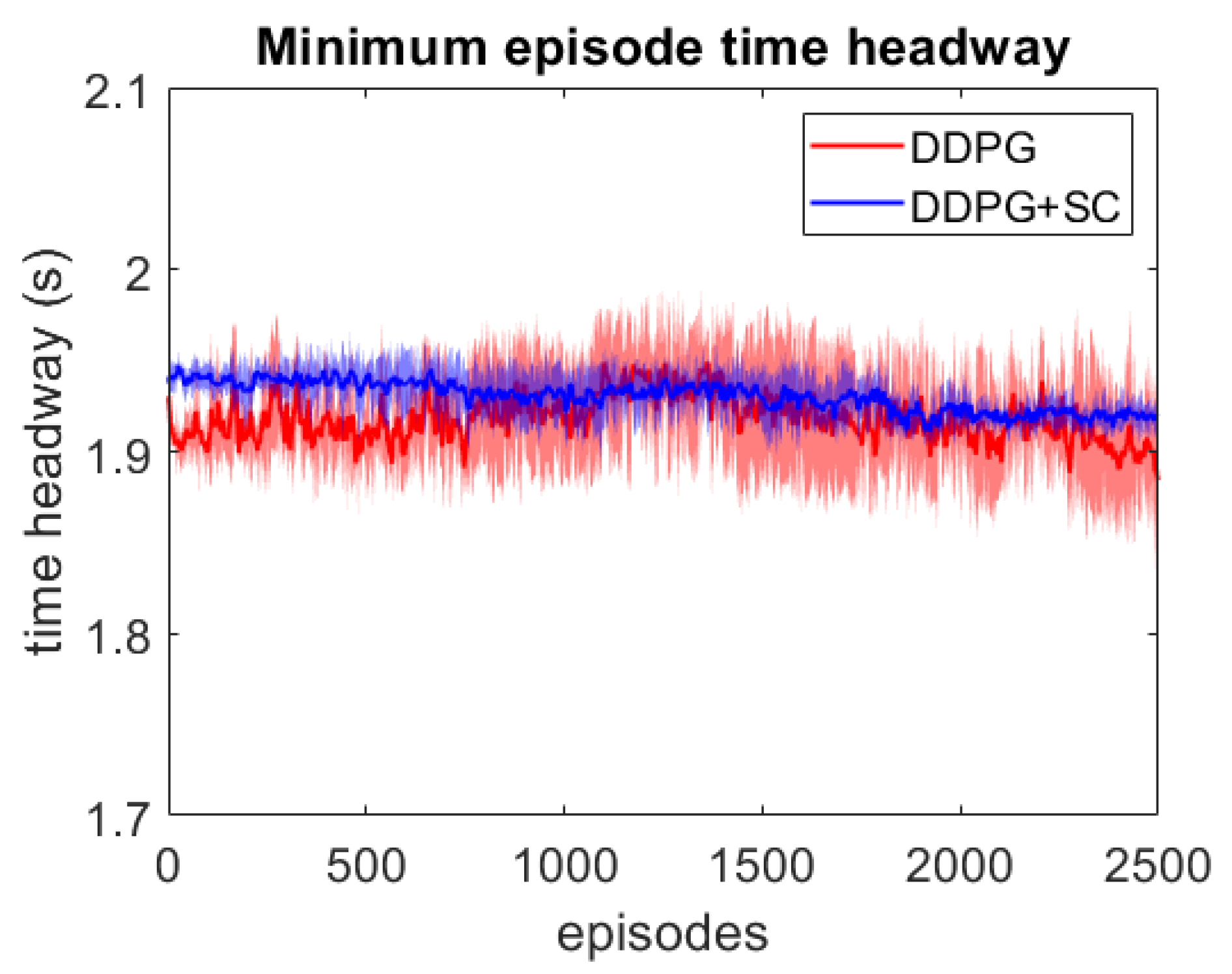
4. Results
4.1. Naturalistic Testing
4.2. Adversarial Testing
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Eskandarian, A.; Wu, C.; Sun, C. Research advances and challenges of autonomous and connected ground vehicles. IEEE Trans. Intell. Transp. Syst. 2019, 22, 683–711. [Google Scholar] [CrossRef]
- Montanaro, U.; Dixit, S.; Fallah, S.; Dianati, M.; Stevens, A.; Oxtoby, D.; Mouzakitis, A. Towards connected autonomous driving: Review of use-cases. Veh. Syst. Dyn. 2018, 57, 779–814. [Google Scholar] [CrossRef]
- Kuutti, S.; Fallah, S.; Bowden, R.; Barber, P. Deep Learning for Autonomous Vehicle Control: Algorithms, State-of-the-Art, and Future Prospects; Morgan & Claypool Publishers: San Rafael, CA, USA, 2019; pp. 1–80. [Google Scholar]
- Eskandarian, A. Handbook of Intelligent Vehicles; Springer: London, UK, 2012; Volume 2. [Google Scholar]
- Thrun, S. Toward robotic cars. Commun. ACM 2010, 53, 99–106. [Google Scholar] [CrossRef]
- Research on the Impacts of Connected and Autonomous Vehicles (CAVs) on Traffic Flow: Summary Report; Department for Transport: London, UK, 2017.
- Kuutti, S.; Bowden, R.; Jin, Y.; Barber, P.; Fallah, S. A survey of deep learning applications to autonomous vehicle control. IEEE Trans. Intell. Transp. Syst. 2020, 22, 712–733. [Google Scholar] [CrossRef]
- Borg, M.; Englund, C.; Wnuk, K.; Duran, B.; Levandowski, C.; Gao, S.; Tan, Y.; Kaijser, H.; Lönn, H.; Törnqvist, J. Safely entering the deep: A review of verification and validation for machine learning and a challenge elicitation in the automotive industry. arXiv 2018, arXiv:1812.05389. [Google Scholar] [CrossRef] [Green Version]
- Burton, S.; Gauerhof, L.; Heinzemann, C. Making the case for safety of machine learning in highly automated driving. International Conference on Computer Safety, Reliability, and Security; Springer: Cham, Switzerland, 2017; pp. 5–16. [Google Scholar]
- Varshney, K.R.; Alemzadeh, H. On the safety of machine learning: Cyber-physical systems, decision sciences, and data products. Big Data 2017, 5, 246–255. [Google Scholar] [CrossRef]
- Rajabli, N.; Flammini, F.; Nardone, R.; Vittorini, V. Software Verification and Validation of Safe Autonomous Cars: A Systematic Literature Review. IEEE Access 2021, 9, 4797–4819. [Google Scholar] [CrossRef]
- Kalra, N.; Paddock, S.M. Driving to safety: How many miles of driving would it take to demonstrate autonomous vehicle reliability? Transp. Res. Part Policy Pract. 2016, 94, 182–193. [Google Scholar] [CrossRef]
- Wachenfeld, W.; Winner, H. The new role of road testing for the safety validation of automated vehicles. In Automated Driving; Springer: Cham, Switzerland, 2017; pp. 419–435. [Google Scholar]
- Koopman, P.; Wagner, M. Challenges in autonomous vehicle testing and validation. SAE Int. J. Transp. Saf. 2016, 4, 15–24. [Google Scholar] [CrossRef] [Green Version]
- Xu, Z.; Tang, C.; Tomizuka, M. Zero-shot deep reinforcement learning driving policy transfer for autonomous vehicles based on robust control. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2865–2871. [Google Scholar]
- Wang, J.; Zhang, Q.; Zhao, D.; Chen, Y. Lane change decision-making through deep reinforcement learning with rule-based constraints. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–6. [Google Scholar]
- Arbabi, S.; Dixit, S.; Zheng, Z.; Oxtoby, D.; Mouzakitis, A.; Fallah, S. Lane-Change Initiation and Planning Approach for Highly Automated Driving on Freeways. arXiv 2020, arXiv:2007.14032. [Google Scholar]
- Heckemann, K.; Gesell, M.; Pfister, T.; Berns, K.; Schneider, K.; Trapp, M. Safe automotive software. International Conference on Knowledge-Based and Intelligent Information and Engineering Systems; Springer: Berlin/Heidelberg, Germany, 2011; pp. 167–176. [Google Scholar]
- Vom Dorff, S.; Böddeker, B.; Kneissl, M.; Fränzle, M. A fail-safe architecture for automated driving. In Proceedings of the 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020; pp. 828–833. [Google Scholar]
- Kuutti, S.; Bowden, R.; Joshi, H.; de Temple, R.; Fallah, S. End-to-end Reinforcement Learning for Autonomous Longitudinal Control Using Advantage Actor Critic with Temporal Context. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 2456–2462. [Google Scholar]
- Kuutti, S.; Bowden, R.; Joshi, H.; de Temple, R.; Fallah, S. Safe Deep Neural Network-driven Autonomous Vehicles Using Software Safety Cages. In Proceedings of the 2019 20th International Conference on Intelligent Data Engineering and Automated Learning (IDEAL), Manchester, UK, 14–16 November 2019; Springer: Cham, Switzerland, 2019; pp. 150–160. [Google Scholar]
- Pomerleau, D.A. Alvinn: An autonomous land vehicle in a neural network. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Denver, CO, USA, 27–30 November 1989; pp. 305–313. [Google Scholar]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to end learning for self-driving cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Zhang, J.; Cho, K. Query-efficient imitation learning for end-to-end autonomous driving. arXiv 2016, arXiv:1605.06450. [Google Scholar]
- Pan, Y.; Cheng, C.A.; Saigol, K.; Lee, K.; Yan, X.; Theodorou, E.; Boots, B. Agile autonomous driving using end-to-end deep imitation learning. arXiv 2018, arXiv:1709.07174. [Google Scholar]
- Ross, S.; Gordon, G.; Bagnell, D. A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the 2011 International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 627–635. [Google Scholar]
- Codevilla, F.; Müller, M.; López, A.; Koltun, V.; Dosovitskiy, A. End-to-end driving via conditional imitation learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 1–9. [Google Scholar]
- Bansal, M.; Krizhevsky, A.; Ogale, A. Chauffeurnet: Learning to drive by imitating the best and synthesizing the worst. arXiv 2018, arXiv:1812.03079. [Google Scholar]
- Wang, D.; Devin, C.; Cai, Q.Z.; Yu, F.; Darrell, T. Deep object centric policies for autonomous driving. arXiv 2018, arXiv:1811.05432. [Google Scholar]
- Hecker, S.; Dai, D.; Van Gool, L. End-to-end learning of driving models with surround-view cameras and route planners. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 435–453. [Google Scholar]
- Codevilla, F.; Santana, E.; López, A.M.; Gaidon, A. Exploring the limitations of behavior cloning for autonomous driving. In Proceedings of the 2019 IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9329–9338. [Google Scholar]
- Xu, H.; Gao, Y.; Yu, F.; Darrell, T. End-to-end learning of driving models from large-scale video datasets. In Proceedings of the 2017 IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2174–2182. [Google Scholar]
- Codevilla, F.; Lopez, A.M.; Koltun, V.; Dosovitskiy, A. On offline evaluation of vision-based driving models. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 236–251. [Google Scholar]
- Kuutti, S.; Fallah, S.; Bowden, R. Training adversarial agents to exploit weaknesses in deep control policies. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 108–114. [Google Scholar]
- De Haan, P.; Jayaraman, D.; Levine, S. Causal confusion in imitation learning. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019; pp. 11693–11704. [Google Scholar]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Sallab, A.A.A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. arXiv 2020, arXiv:2002.00444. [Google Scholar]
- Wu, J.; Wei, Z.; Li, W.; Wang, Y.; Li, Y.; Sauer, D. Battery thermal-and health-constrained energy management for hybrid electric bus based on soft actor-critic DRL algorithm. IEEE Trans. Ind. Informatics 2021, 17, 3751–3761. [Google Scholar] [CrossRef]
- Wu, J.; Wei, Z.; Liu, K.; Quan, Z.; Li, Y. Battery-involved Energy Management for Hybrid Electric Bus Based on Expert-assistance Deep Deterministic Policy Gradient Algorithm. IEEE Trans. Veh. Technol. 2020, 69, 12786–12796. [Google Scholar] [CrossRef]
- Puccetti, L.; Rathgeber, C.; Hohmann, S. Actor-Critic Reinforcement Learning for Linear Longitudinal Output Control of a Road Vehicle. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 2907–2913. [Google Scholar]
- Chae, H.; Kang, C.M.; Kim, B.; Kim, J.; Chung, C.C.; Choi, J.W. Autonomous braking system via deep reinforcement learning. In Proceedings of the 2017 IEEE Intelligent Transportation Systems Conference (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Zhao, D.; Xia, Z.; Zhang, Q. Model-Free Optimal Control Based Intelligent Cruise Control with Hardware-in-the-Loop Demonstration [Research Frontier]. IEEE Comput. Intell. Mag. 2017, 12, 56–69. [Google Scholar] [CrossRef]
- Li, G.; Görges, D. Ecological Adaptive Cruise Control for Vehicles With Step-Gear Transmission Based on Reinforcement Learning. IEEE Trans. Intell. Transp. Syst. 2019, 21, 4895–4905. [Google Scholar] [CrossRef]
- Huang, Z.; Xu, X.; He, H.; Tan, J.; Sun, Z. Parameterized batch reinforcement learning for longitudinal control of autonomous land vehicles. IEEE Trans. Syst. Man, Cybern. Syst. 2017, 49, 730–741. [Google Scholar] [CrossRef]
- Kurien, J.; Nayak, P.P.; Williams, B.C. Model Based Autonomy for Robust Mars Operations. In Proceedings of the 1st International Conference Mars Society, Boulder, CO, USA, 13–16 August 1998. [Google Scholar]
- Crestani, D.; Godary-Dejean, K.; Lapierre, L. Enhancing fault tolerance of autonomous mobile robots. Robot. Auton. Syst. 2015, 68, 140–155. [Google Scholar] [CrossRef] [Green Version]
- Haddadin, S.; Haddadin, S.; Khoury, A.; Rokahr, T.; Parusel, S.; Burgkart, R.; Bicchi, A.; Albu-Schäffer, A. On making robots understand safety: Embedding injury knowledge into control. Int. J. Robot. Res. 2012, 31, 1578–1602. [Google Scholar] [CrossRef]
- Kuffner, J.J., Jr.; Anderson-Sprecher, P.E. Virtual Safety Cages for Robotic Devices. US Patent 9,522,471, 21 January 2016. [Google Scholar]
- Polycarpou, M.; Zhang, X.; Xu, R.; Yang, Y.; Kwan, C. A neural network based approach to adaptive fault tolerant flight control. In Proceedings of the 2004 IEEE International Symposium on Intelligent Control, Taipei, Taiwan, 4 September 2004; pp. 61–66. [Google Scholar]
- Adler, R.; Feth, P.; Schneider, D. Safety engineering for autonomous vehicles. In Proceedings of the 2016 46th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshop (DSN-W), Toulouse, France, 28 June–1 July 2016; pp. 200–205. [Google Scholar]
- Jackson, D.; DeCastro, J.; Kong, S.; Koutentakis, D.; Ping, A.L.F.; Solar-Lezama, A.; Wang, M.; Zhang, X. Certified Control for Self-Driving Cars. In Proceedings of the DARS 2019: 4th Workshop On The Design And Analysis Of Robust Systems, New York, NY, USA, 13 July 2019. [Google Scholar]
- Pek, C.; Manzinger, S.; Koschi, M.; Althoff, M. Using online verification to prevent autonomous vehicles from causing accidents. Nat. Mach. Intell. 2020, 2, 518–528. [Google Scholar] [CrossRef]
- ISO 26262: Road Vehicles-Functional Safety; International Organization for Standardization: Geneva, Switzerland, 2011.
- Yurtsever, E.; Capito, L.; Redmill, K.; Ozguner, U. Integrating Deep Reinforcement Learning with Model-based Path Planners for Automated Driving. arXiv 2020, arXiv:2002.00434. [Google Scholar]
- Likmeta, A.; Metelli, A.M.; Tirinzoni, A.; Giol, R.; Restelli, M.; Romano, D. Combining reinforcement learning with rule-based controllers for transparent and general decision-making in autonomous driving. Robot. Auton. Syst. 2020, 131, 103568. [Google Scholar] [CrossRef]
- Baheri, A.; Nageshrao, S.; Tseng, H.E.; Kolmanovsky, I.; Girard, A.; Filev, D. Deep reinforcement learning with enhanced safety for autonomous highway driving. arXiv 2019, arXiv:1910.12905. [Google Scholar]
- Lee, L.; Eysenbach, B.; Salakhutdinov, R.; Finn, C. Weakly-Supervised Reinforcement Learning for Controllable Behavior. arXiv 2020, arXiv:2004.02860. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning; MIT Press: Cambridge, MA, USA, 1998; Volume 135. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic Policy Gradient Algorithms. In Proceedings of the Internation Conference on Machine Learning (ICML), Beijing, China, 21–26 June 2014. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Uhlenbeck, G.E.; Ornstein, L.S. On the theory of the Brownian motion. Phys. Rev. 1930, 36, 823. [Google Scholar] [CrossRef]
- Ha, D.; Schmidhuber, J. World models. arXiv 2018, arXiv:1803.10122. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Desjardins, C.; Chaib-Draa, B. Cooperative adaptive cruise control: A reinforcement learning approach. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1248–1260. [Google Scholar] [CrossRef]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the 2016 International Conference on Machine Learning (ICML), New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Corso, A.; Moss, R.J.; Koren, M.; Lee, R.; Kochenderfer, M.J. A Survey of Algorithms for Black-Box Safety Validation. arXiv 2020, arXiv:2005.02979. [Google Scholar]
- Riedmaier, S.; Ponn, T.; Ludwig, D.; Schick, B.; Diermeyer, F. Survey on Scenario-Based Safety Assessment of Automated Vehicles. IEEE Access 2020, 8, 87456–87477. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Mini-batch size | 64 |
| Hidden neurons in feedforward layers | 50 |
| LSTM units | 16 |
| Discount factor | 0.99 |
| Actor learning rate | 10−4 |
| Critic learning rate | 10−2 |
| Replay memory size | 106 |
| Mixing factor | 10−3 |
| Initial exploration noise scale | 1.0 |
| Max gradient norm for clipping | 0.5 |
| Exploration noise decay | 0.997 |
| Exploration mean | 0.0 |
| Exploration scale factor | 0.15 |
| Exploration variance | 0.2 |
| Parameter | IPG Driver | A2C [20] | DDPG | DDPG+SC | Shallow DDPG | Shallow DDPG+SC |
|---|---|---|---|---|---|---|
| min. xrel [m] | 10.737 | 7.780 | 15.252 | 13.403 | 0.000 | 5.840 |
| mean xrel [m] | 75.16 | 58.01 | 58.19 | 58.24 | 41.45 | 59.34 |
| max. vrel [m/s] | 13.90 | 7.89 | 10.74 | 9.33 | 13.43 | 6.97 |
| mean vrel [m/s] | 0.187 | 0.0289 | 0.0281 | 0.0271 | 4.59 | 0.0328 |
| min. TH [s] | 1.046 | 1.114 | 1.530 | 1.693 | 0.000 | 0.787 |
| mean TH [s] | 2.546 | 2.007 | 2.015 | 2.015 | 1.313 | 2.034 |
| collisions | 0 | 0 | 0 | 0 | 120 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuutti, S.; Bowden, R.; Fallah, S. Weakly Supervised Reinforcement Learning for Autonomous Highway Driving via Virtual Safety Cages. Sensors 2021, 21, 2032. https://doi.org/10.3390/s21062032
Kuutti S, Bowden R, Fallah S. Weakly Supervised Reinforcement Learning for Autonomous Highway Driving via Virtual Safety Cages. Sensors. 2021; 21(6):2032. https://doi.org/10.3390/s21062032
Chicago/Turabian StyleKuutti, Sampo, Richard Bowden, and Saber Fallah. 2021. "Weakly Supervised Reinforcement Learning for Autonomous Highway Driving via Virtual Safety Cages" Sensors 21, no. 6: 2032. https://doi.org/10.3390/s21062032
APA StyleKuutti, S., Bowden, R., & Fallah, S. (2021). Weakly Supervised Reinforcement Learning for Autonomous Highway Driving via Virtual Safety Cages. Sensors, 21(6), 2032. https://doi.org/10.3390/s21062032