
A Comparative Study on Supervised Machine Learning Algorithms for Copper Recovery Quality Prediction in a Leaching Process



Abstract
:1. Introduction
Advantages and Disadvantages of Data-Driven Approaches in Copper Mining
2. Related Works and Context
2.1. Traditional and Machine Learning Processes to Predict Copper Recovery by Leaching
2.2. Artificial Neural Network
2.3. Support Vector Machine
2.4. Random Forest
3. Materials and Methods
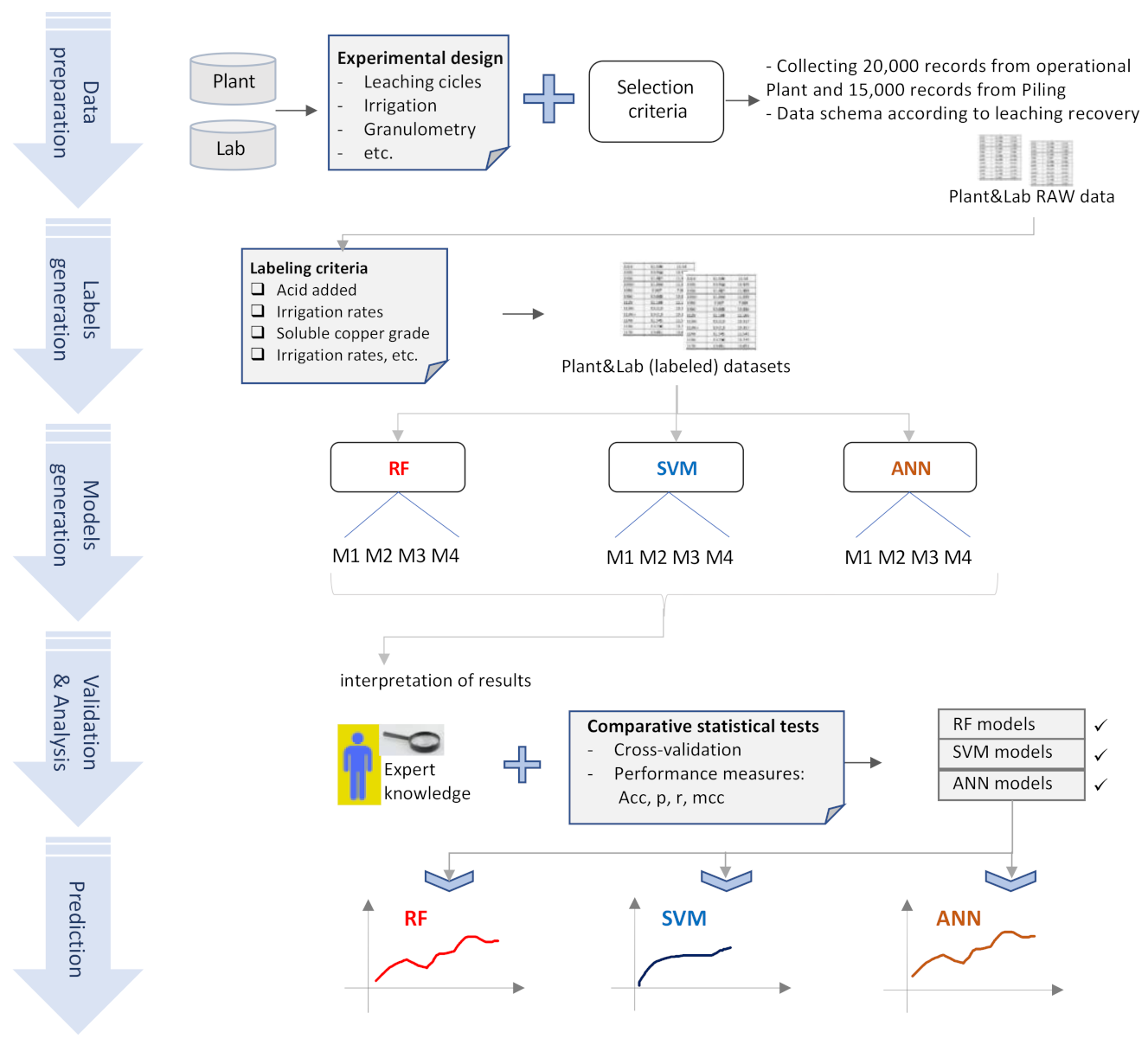
3.1. Data-Driving Techniques in the Copper Industry and the Methodology
- Data preparation. For this first step data from the copper heap (called plant) and data from the laboratory (called lab) were used, both data sets were acquired in accordance with an experimental design, described below. The datasets contain the features of both processes (the leaching process on the plant and the leaching process in the lab). In both cases, data were prepared according to the results of the predictive variable measurements on the heap and in the lab. In this stage, .csv archives were used with data collected at the plant and in the lab. The class “copper recovery”, and associated variables are detailed in Table 1.
- Labels generation. The second stage consisted in generating labels for the dependent variable Y (copper recovery—see Table 1) in both datasets, according to the threshold values of the other predictive variables. This process was aiming to prepare the entry data for the data mining algorithms. This resulted in datasets with labels for the dependent variable Y.
- Model generation. The third stage consists in training for developing predictive models, using some parts of the datasets for training and the remaining ones for validation; the details are given in Section 4.
- Validation and analysis of results. The fourth stage deals with the validation and interpretation of the results. In this stage, comparative statistical tests using classifier performance measures were utilized to determine the quality of the models developed. The models that resulted from these tasks were analyzed and interpretated, according to expert knowledge and experience in the field of copper mining exploitation by leaching.
- Prediction. Using the validated models, predictions of copper recovery by leaching were made, and these were compared using the techniques described in the previous step.
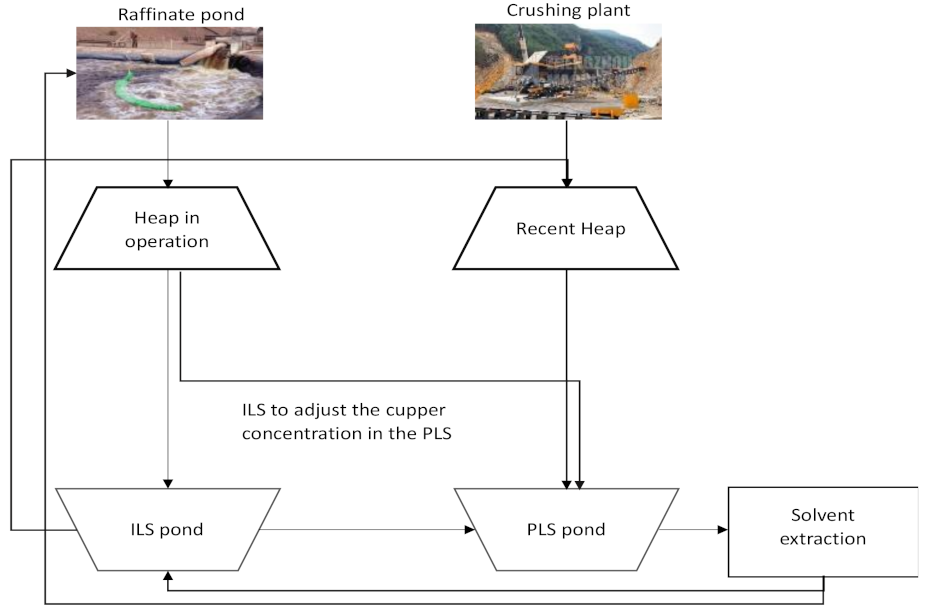
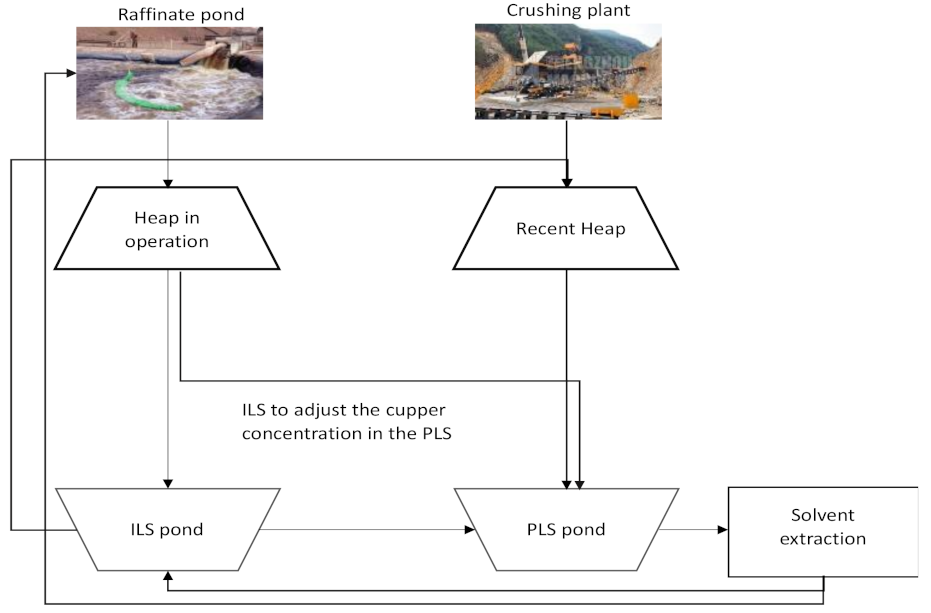
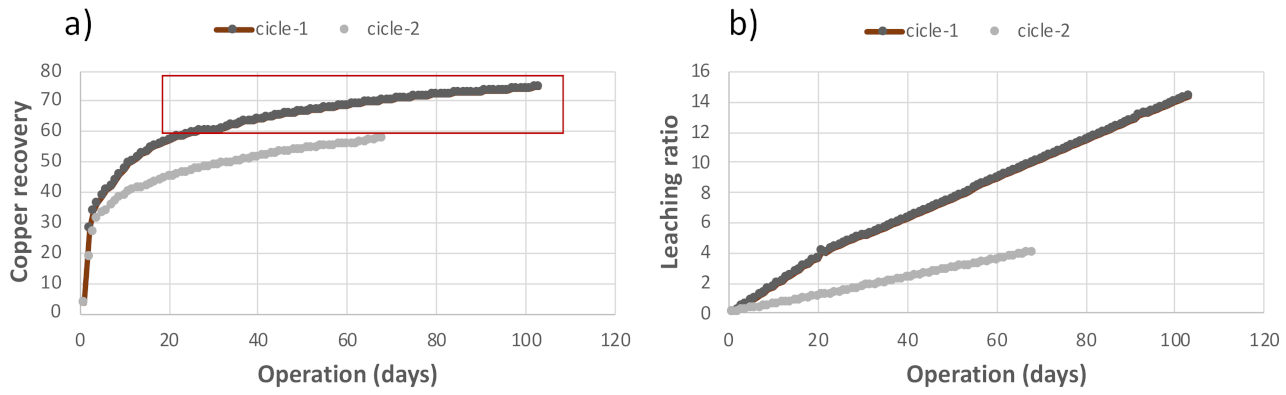
3.2. Data Preparation and Experimental Design
- Mono class granulometry (mm): ore particle size after the crushing process.
- Irrigation rates (Lhr/m2): amount of ILS solution added per m2 of the upper stockpile surface.
- Total acid added (g/L): concentration of acid added per liter of ILS.
- Stocked high (m): the height of the stockpile in operation.
- Total copper grade (%): the amount of copper in the ore to be leached.
- CO3 grade (%): the amount of carbonate in the mineral to be leached. This variable increases the acid consumption during the leaching process.
- Leaching ratio (m3/TMS): the amount of ILS added to the stockpile per amount of ore in the stockpile.
- Operation (days): the number of days during which the stockpile is in operation.
- Soluble copper grade stacked (%): in mineralogy, some ores can be leached, while others such as sulfates cannot. The amount of copper soluble in the ore is measured.
- Number of stockpiles: corresponding to the identification of the stockpile to be leached.
- Copper recovery (%): the copper recovered daily during the leaching process.
3.3. Validation Using Performance Measures
- 1.
- Accuracy (acc) corresponds to the ratio of correctly classified samples from all the samples in the dataset [38]. This indicator can be calculated with the confusion matrix data, according to Equation (5), assuming that the dataset is not empty.
- 2.
- Precision (p) is the proportion of true positives (a) among the elements predicted as positive. Conceptually, precision refers to the dispersion of the set of values obtained from the repeated measurements of a quantity. Specifically, a high precision value (p) implies a low dispersion in measurements. This indicator can be calculated according to Equation (6), assuming a + b ≠ 0.
- 3.
- Recall (r) is the proportion of true positives predicted among all elements classified as positive, that is, the fraction of relevant instances classified. Recall can be calculated according to Equation (7), assuming a + c ≠ 0.
- 4.
- Matthew’s correlation coefficient (mcc) is an indicator relating the predicted versus the real values, creating a balance between the classes, considering the instances correctly and incorrectly classified into classes quite different in size and with a significant number of observations [39]. The mcc value can be calculated according to Equation (8), assuming that the destination dividend (τ) is not zero.where
4. Results and Discussion
4.1. Results
4.2. Discussion
5. Conclusions
- Analyzing the system’s behavior with variables not currently measured in the field, such as stockpile permeability and mineralogy.
- Automatizing operational variables according to the predictive model to improve the planning of the leaching plant.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abedi, M.; Norouzi, G.H.; Bahroudi, A. Support vector machine for multi–classification of mineral prospectively areas. Comput. Geosci. 2012, 46, 272–283. [Google Scholar] [CrossRef]
- Abedi, M.; Torabi, S.A.; Norouzi, G.H.; Hamzeh, M.; Elyasi, G.R. PROMETHEE II: A knowledge–driven method for copper exploration. Comput. Geosci. 2012, 46, 255–263. [Google Scholar] [CrossRef]
- Flores, V.; Keith, B.; Leiva, C. Using Artificial Intelligence Techniques to Improve the Prediction of Copper Recovery by Leaching. J. Sens. 2020, 2020, 2454875. [Google Scholar] [CrossRef] [Green Version]
- Sun, T.; Chen, F.; Zhong, I.; Liu, W.; Wang, Y. GIS–based mineral prospectively mapping using machine learning methods: A case study from Tongling ore district, eastern China. Ore Geol. Rev. 2019, 109, 26–49. [Google Scholar] [CrossRef]
- Peters, T. Data–Driven Science and Engineering: Machine Learning, Dynamical Systems, and Control; Cambridge University Press: Cambridge, UK, 2019. [Google Scholar]
- Barga, R.; Fontama, V.; Tok, W.H. Predictive Analytics with Microsoft Azure Machine Learning; Apress: Berkeley, CA, USA, 2015; pp. 221–241. [Google Scholar]
- Milivojevic, M.; Stopic, S.; Friedrich, B.; Drndarevic, D. Computer modeling of high–pressure leaching process of nickel laterite by design of experiments and neural networks. Int. J. Miner. Metall. Mater. 2012, 19, 584–594. [Google Scholar] [CrossRef]
- Çığşar, B.; Ünal, D. Comparison of data mining classification algorithms determining the default risk. Sci. Program. 2019. [Google Scholar] [CrossRef] [Green Version]
- Flores, V.; Correa, M. Performance of Predicting Surface Quality Model Using Softcomputing, a Comparative Study of Results. Proceeding of the International Work–Conference on the Interplay Between Natural and Artificial Computation, Almería, Spain, 3–7 June 2017; pp. 233–242. [Google Scholar]
- Leiva, C.; Flores, V.; Salgado, F.; Poblete, D.; Acuña, A. Applying Softcomputing for copper recovery in leaching process. Sci. Program. 2017. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Song, X.; Yang, X.; Wu, Q. Support–Vector–Regression Machine Technology for Total Organic Carbon Content Prediction from Wireline Logs in Organic Shale: A Comparative Study. J. Nat. Gas Sci. Eng. 2015, 26, 792–802. [Google Scholar] [CrossRef]
- Saljoughi, B.S.; Hezarkhani, A. A comparative analysis of artificial neural network (ANN), wavelet neural network (WNN), and support vector machine (SVM) data–driven models to mineral potential mapping for copper mineralization in the Shahr-e-Babak region, Kerman, Iran. Appl. Geomat. 2018, 10, 229–256. [Google Scholar] [CrossRef]
- Piccarozzi, M.; Aquilani, B.; Gatti, C. Industry 4.0 in management studies: A systematic literature review. Sustainability 2018, 10, 3821. [Google Scholar] [CrossRef] [Green Version]
- Song, Y.; Yang, K.; Chen, J.; Wang, K.; Sant, G.; Bauchy, M. Machine Learning Enables Rapid Screening of Reactive Fly Ashes Based on Their Network Topology. ACS Sustain. Chem. Eng. 2021. [Google Scholar] [CrossRef]
- Hu, J.; Kim, C.; Halasz, P.; Kim, J.F.; Kim, J.; Szekely, G. Artificial intelligence for performance prediction of organic solvent nanofiltration membranes. J. Membr. Sci. 2021, 619, 118513. [Google Scholar] [CrossRef]
- Deng, T.; Xu, C.; Jobe, D.; Xu, R. Comparative Study of Three Supervised Machine–Learning Algorithms for Classifying Carbonate Vuggy Facies in the Kansas Arbuckle Formation. Petrophysics 2019, 60, 838–853. [Google Scholar]
- Sadeghi, F.; Monjezi, M.; Armaghani, D. Evaluation and optimization of prediction of toe that arises from mine blasting operation using various soft computing techniques. Nat. Resour. Res. 2020, 29, 887–903. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy logic, Neural Networks and soft computing. Commun. Acm 1984, 37, 77–84. [Google Scholar] [CrossRef]
- Grove, W.M.; Meehl, P.E. Comparative efficiency of informal (subjective, impressionistic) and formal (mechanical, algorithmic) prediction procedures: The clinical–statistical controversy. Psychol. Public Policy Law 1996, 2, 293. [Google Scholar] [CrossRef]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian Optimization of Machine Learning Algorithms. Adv. Neural Inf. Process. Syst. 2012, 25, 2951–2959. [Google Scholar]
- Welgama, P.; Mills, R.G.; Aboura, K.; Struthers, A.; Tucker, D. Evaluation of Options to Improve Copper Production. In Proceedings of the 6th International Conference on Manufacturing Engineering, Melbourne, Australia, 29 November–1 December 1995; pp. 219–223. [Google Scholar]
- Aboura, K. A Statistical Model for Shutdowns due to Air Quality Control for a Copper Production Decision Support System. Organizacija 2015, 48, 198–202. [Google Scholar] [CrossRef] [Green Version]
- Mahmoud, A.; Elkatatny, S.; Mahmoud, M.; Abouelresh, M.; Ali, A. Determination of the Total Organic Carbon (TOC) Based on Conventional Well Logs Using Artificial Neural Network. Int. J. Coal Geol. 2017, 179, 72–80. [Google Scholar] [CrossRef]
- Xu, C.; Misra, S.; Srinivasan, P.; Ma, S. When Petrophysics Meets Big Data: What Can Machine Do? In Proceedings of the SPE Middle East Oil and Gas Show and Conference, Manama, Bahrain, 18–21 March 2019. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.; Li, S. ADASYN: Adaptive Synthetic Sampling Approach for Imbalanced Learning. Proceeding of the IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Koul, N. Learning Predictive Models from Massive, Semantically Disparate Data. Ph.D. Thesis, Iowa State University, Ames, IA, USA, 2011. [Google Scholar]
- Hopfield, J.J. Artificial Neural Networks. In IEEE Circuits and Devices Magazine; IEEE: Pasadena, CA, USA, 1988; Volume 4. [Google Scholar]
- Saneifar, M.; Aranibar, A.; Heidari, Z. Rock Classification in the Haynesville Shale Based on Petrophysical and Elastic Properties Estimated from Well Logs. Interpretation 2015, 3, 65–75. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifer Neural Networks. In Proceedings of the Fourteenth International Conference On Artificial Intelligence and Statistics, Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Trevor, H.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2003. [Google Scholar]
- Breiman, I. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Lior, R. Data mining with decision trees: Theory and applications. World Sci. 2014, 81, 11–50. [Google Scholar]
- Ho, T.K. Random decision forests. Proceeding of the 3rd International Conference on Document Analysis and Recognition, Sydney, Australia, 14–15 August 1995; pp. 278–282. [Google Scholar]
- Barandiaran, I. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Hofmann, H.; Klinkenberg, R. RapidMiner: Data Mining Use Cases and Business Analytics Applications; CRC Pres Teylor & Francys Group: Boca Raton, FL, USA, 2013. [Google Scholar]
- Chow, C.K.; Liu, C. Approximating discrete probability distributions with dependence trees. IEEE Trans. Inf. Theory 1968, 14, 462–467. [Google Scholar] [CrossRef] [Green Version]
- Arlot, S.; Celisse, A. A Survey of Cross–Validation Procedures for Model Selection. Stat. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- Hardian, R.; Liang, Z.; Zhang, X.; Szekely, G. Artificial intelligence: The silver bullet for sustainable materials development. Green Chem. 2020, 22, 7521–7528. [Google Scholar] [CrossRef]
- Bisgin, H.; Bera, T.; Ding, H.; Semey, H.G.; Wu, L.; Liu, L.; Tong, W. Comparing SVM and ANN based machine learning methods for species identification of food contaminating beetles. Sci. Rep. 2018, 8, 1–12. [Google Scholar] [CrossRef]
- Yan, B.; Xu, D.; Chen, T.; Wang, M. Leachability characteristic of heavy metals and associated health risk study in typical copper mining–impacted sediments. Chemosphere 2020, 239, 124773. [Google Scholar] [CrossRef]
- Hu, G.; Mao, Z.; He, D.; Yang, F. Hybrid modeling for the prediction of leaching rate in leaching process based on negative correlation learning bagging ensemble algorithm. Comput. Chem. Eng. 2011, 35, 2611–2617. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Var | Description | Low | Normal | High |
|---|---|---|---|---|
| X1 | mono class granulometry (mm) | [11.5,12) | [12,13) | [13,15) |
| X2 | irrigation rates (Lhr/m2) | [6,8) | [8,11) | [11,14) |
| X3 | total acid added (g/L) | [0.5,20) | [2050) | [50,75) |
| X4 | stocked high (m) | [1,3) | [3,4) | [4,5) |
| X5 | total copper grade (%) | [0.4,0.7) | [0.7,1.2) | [1.2,2.1) |
| X6 | CO3 grade (%) | [0.5,4) | [4,6) | [6,10) |
| X7 | leaching ratio (m3/TMS) | [0.012,5) | [5,10) | [10,15) |
| X8 | operation (days) | [1,50) | [50,100) | [100,168] |
| X9 | soluble copper grade stacked (%) | [55,65) | [65,80) | [80,98] |
| X10 | Number of stockpiles | - | - | - |
| Y | Copper recovery (%) | [10,65) | [65,80) | (80,98] |
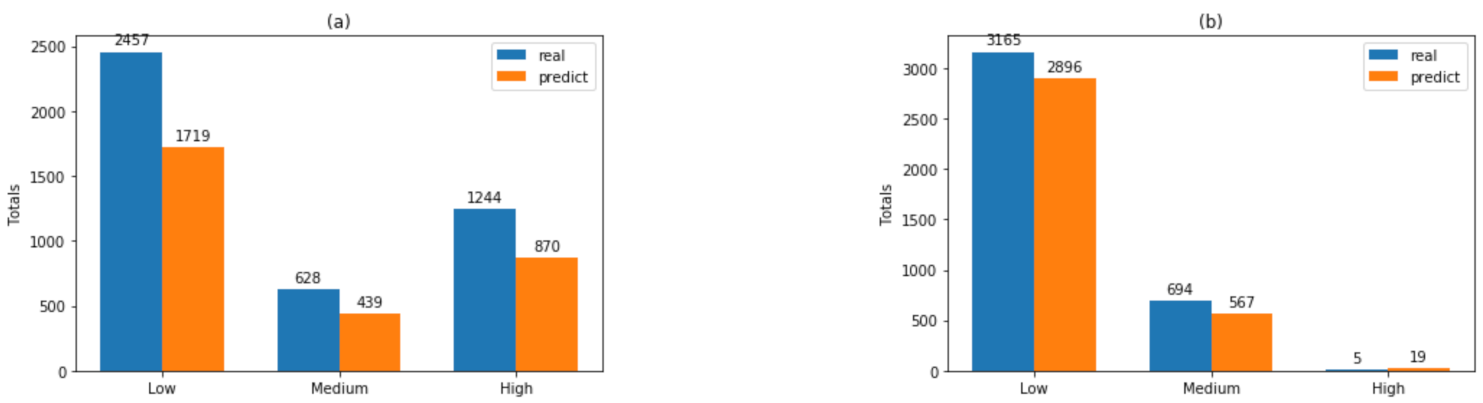
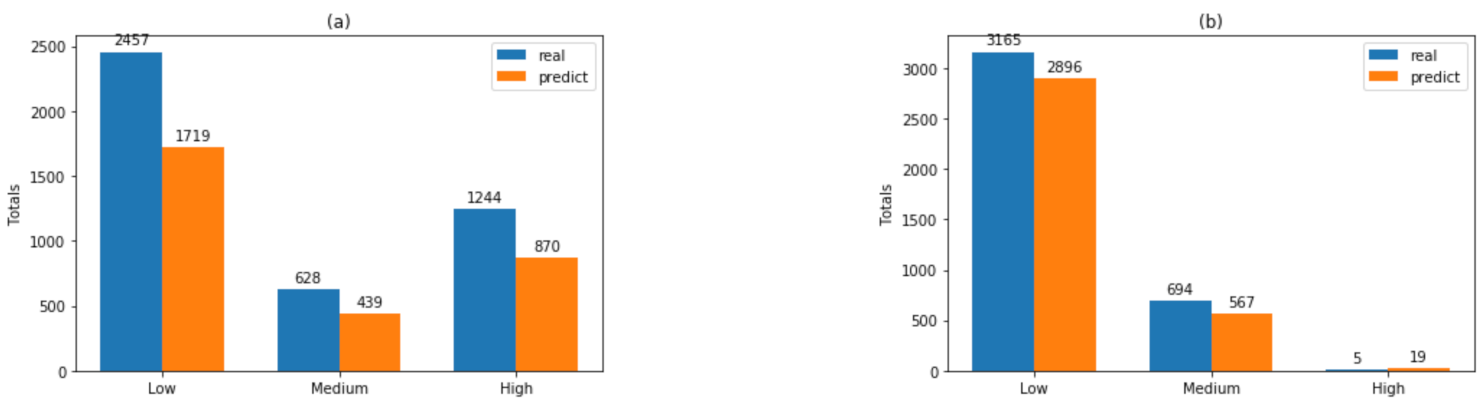
| Dataset A1 Accuracy: 99.97% ± 0.09% | Dataset A2 Accuracy: 99.94% ± 0.12% | |||||||
|---|---|---|---|---|---|---|---|---|
| true low | true medium | true high | class precision | True low | true medium | true high | class precision | |
| pred. low | 1719 | 0 | 0 | 100.00% | 2896 | 0 | 0 | 100.00% |
| pred. medium | 1 | 439 | 0 | 99.82% | 0 | 567 | 0 | 100.00% |
| pred. high | 0 | 1 | 870 | 95.00% | 0 | 1 | 19 | 99.43% |
| class recall | 99.97% | 99.82% | 100.00% | 100.00% | 99.73% | 100.00% | ||
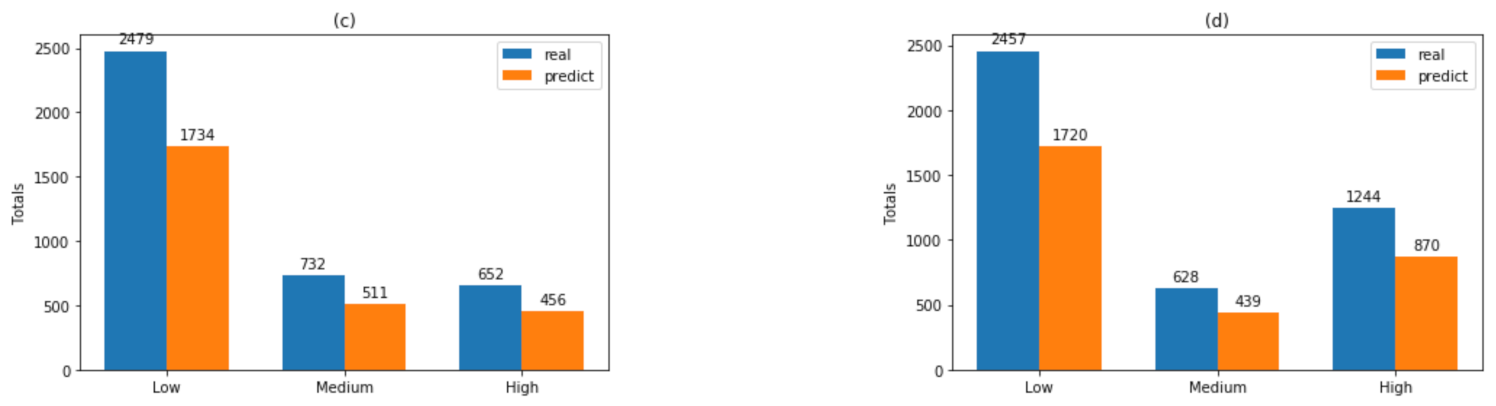
| Dataset B1 Accuracy: 99.93% ± 0.16% | Dataset B2 Accuracy: 99.93% ± 0.14% | |||||||
|---|---|---|---|---|---|---|---|---|
| true low | true medium | true high | class precision | true low | true medium | true high | class precision | |
| pred. low | 1734 | 1 | 0 | 99.94% | 1720 | 0 | 0 | 100.00% |
| pred. medium | 1 | 511 | 0 | 99.80% | 0 | 439 | 1 | 99.77% |
| pred. high | 0 | 0 | 456 | 100.00% | 0 | 1 | 870 | 99.89% |
| class recall | 99.94% | 99.80% | 100.00% | 100.00% | 99.77% | 99.89% | ||
| Dataset | Class Precision | acc | p | r | mcc | |
|---|---|---|---|---|---|---|
| RF | A1 | 99.700 | 0.9491 | 99.7558 | 1.0000 | 0.0563 |
| A2 | 100.000 | 0.9945 | 99.4548 | 1.0000 | 0.0529 | |
| B1 | 100.000 | 0.8214 | 83.1261 | 1.0000 | 0.0026 | |
| B2 | 99.850 | 0.9993 | 71.3012 | 1.0000 | 0.0016 | |
| SVM | A1 | 98.635 | 0.9491 | 99.7558 | 0.9955 | 0.0571 |
| A2 | 98.717 | 0.9945 | 99.4548 | 0.9878 | 0.0537 | |
| B1 | 98.607 | 0.8314 | 83.1361 | 0.9877 | 0.0025 | |
| B2 | 99.381 | 0.9993 | 71.3712 | 0.9878 | 0.0015 | |
| ANN | A1 | 99.381 | 0.9491 | 99.8350 | 1.0000 | 0.0042 |
| A2 | 99.921 | 0.9946 | 99.6177 | 0.9984 | 0.0437 | |
| B1 | 99.381 | 0.8312 | 83.5156 | 0.9954 | 0.0018 | |
| B2 | 99.381 | 0.9958 | 71.4451 | 0.9981 | 0.0011 |
| Dataset A1 | Dataset A2 | |||||
|---|---|---|---|---|---|---|
| true low | true high | class precision | true low | true high | class precision | |
| pred. low | 3265 | 0 | 100.00% | 3466 | 0 | 100.00% |
| pred. high | 1 | 275 | 99.43% | 0 | 1023 | 100.00% |
| class recall | 99.97% | 100.00% | 100.00% | 100.00% | ||
| Dataset B1 | Dataset B2 | |||||
| true low | true high | class precision | true low | true high | class precision | |
| pred. low | 2248 | 0 | 100.00% | 2159 | 1 | 99.95% |
| pred. high | 0 | 456 | 100.00% | 1 | 869 | 99.89% |
| class recall | 100.00% | 100.00% | 99.95% | 99.89% | ||
| Dataset A1 | Dataset A2 | |||||
|---|---|---|---|---|---|---|
| true low | true high | class precision | true low | true high | class precision | |
| pred. low | 3660 | 26 | 99.45% | 3074 | 50 | 98.40% |
| pred. high | 5 | 224 | 97.82% | 12 | 894 | 99.00% |
| class recall | 99.89% | 90.60% | 99.61% | 95.98% | ||
| Dataset B1 | Dataset B2 | |||||
| true low | true high | class precision | true low | true high | class precision | |
| pred. low | 3203 | 48 | 98.52% | 2074 | 50 | 98.40% |
| pred. high | 8 | 604 | 98.69% | 12 | 894 | 99.00% |
| class recall | 99.75% | 92.64% | 99.61% | 95.98% | ||
| Dataset A1 | Dataset A2 | |||||
| true low | true high | class precision | true low | true high | class precision | |
| pred. low | 3662 | 2 | 99.96% | 4951 | 2 | 99.84% |
| pred. high | 3 | 248 | 98.80% | 0 | 1092 | 100.00% |
| class recall | 99.94% | 99.20% | 100% | 98.42% | ||
| Dataset B1 | Dataset B2 | |||||
| true low | true high | class precision | true low | true high | class precision | |
| pred. low | 3207 | 19 | 99.41% | 2771 | 9 | 99.61% |
| pred. high | 4 | 633 | 99.37% | 16 | 1231 | 99.51% |
| class recall | 99.88% | 97.09% | 99.81% | 99.03% | ||
| A1 | A2 | B1 | B2 | A1 | A2 | B1 | B2 | PCC | |
|---|---|---|---|---|---|---|---|---|---|
| ‘low’ | ‘high’ | ||||||||
| RF | 88.92 | 95.79 | 70.01 | 69.96 | 62.50 | 98.18 | 69.94 | 69.91 | 78.15 |
| SVM | 99.67 | 93.01 | 92.64 | 99.61 | 80.00 | 88.20 | 92.64 | 95.98 | 93.61 |
| ANN | 99.73 | 98.37 | 97.09 | 89.79 | 88.57 | 99.09 | 97.09 | 99.03 | 96.44 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Flores, V.; Leiva, C. A Comparative Study on Supervised Machine Learning Algorithms for Copper Recovery Quality Prediction in a Leaching Process. Sensors 2021, 21, 2119. https://doi.org/10.3390/s21062119
Flores V, Leiva C. A Comparative Study on Supervised Machine Learning Algorithms for Copper Recovery Quality Prediction in a Leaching Process. Sensors. 2021; 21(6):2119. https://doi.org/10.3390/s21062119
Chicago/Turabian StyleFlores, Victor, and Claudio Leiva. 2021. "A Comparative Study on Supervised Machine Learning Algorithms for Copper Recovery Quality Prediction in a Leaching Process" Sensors 21, no. 6: 2119. https://doi.org/10.3390/s21062119
APA StyleFlores, V., & Leiva, C. (2021). A Comparative Study on Supervised Machine Learning Algorithms for Copper Recovery Quality Prediction in a Leaching Process. Sensors, 21(6), 2119. https://doi.org/10.3390/s21062119