1. Introduction
Obesity constitutes a major public health concern globally, generating considerable direct and indirect costs, and affecting over one-third of the world’s population [
1]. Obesity is recognized as a complex, multifactorial disease, determined by a combination of factors and impacting both physical and psychological health [
2]. However, existing research generally treats this condition mainly as a result of both behavioral factors, namely, an excessive caloric intake relative to metabolic energy expenditure [
3], and genetic influences, such as single gene mutations [
4]. The role of other relevant determinants, including psychological ones, tends therefore to be neglected although these variables clearly also contribute to weight gain and weight-related pathologies. Nevertheless, particularly in the field of psychology, researchers have emphasized a mutual association between overweight, obesity and high levels of negative affectivity, operationalized mainly as depression. For example, adults diagnosed with obesity report higher depression and anxiety levels compared to normally weighted individuals [
5,
6], and negative affects emerged as important factors for the maintenance of eating pathology [
7]. At the same time, the literature shows inconsistencies with regards to strength and causal direction of such associations [
8].
These mixed results might be related to several factors, including specific methodological issues, viz., the variables being measured, assessment tools, and strategies to data management. In fact, the tendency to employ a limited conceptualization of obesity, together with the general application of conventional regression analyses (e.g., linear and logistic regressions) to test empirical assumptions, reinforce existing difficulties in predicting and treating obesity. The use of regressions have certainly helped to identify risk factors of medical outcomes, however, in the case of a multidimensional, lifestyle condition such as obesity, these methods have made less progress [
9].
One of the main approaches that may help to reduce these research-flaws and to improve scientific knowledge is the use of artificial intelligence (AI). In health-related disciplines, there is currently an increasing interest in the use of AI, particularly when the primary task is identifying clinically useful patterns in high-dimensional data sets. For example, several studies employed AI to classify a number of medical parameters that could efficiently predict obesity and body mass index (BMI; weight in kilograms divided by the square of the height in meters) [
10], while a recent systematic review showed the application of machine learning (ML) algorithms for childhood obesity care [
11].
Detection and diagnosis of diseases by the use of AI, in particular ML, is indeed an ongoing and prominent topic in scientific papers [
12]. The interest in its potentiality has increased, even if the possible unintended consequences that may result from its application in clinical practice are clear, and include an overreliance on the capabilities of automation, thus reducing the skills of physician, as well as relying more on the data than on the clinical context [
11]. Several medical investigations employed ML approaches to develop advanced remote healthcare systems to monitor long-term patients with BMI-related chronic illnesses [
13,
14,
15,
16]. Specifically, while a number of these studies attempted to predict BMI by voice signals [
15], face images [
16,
17], or face points extracted with a Kinect [
18], other studies focused on blood and biochemical indexes [
19,
20,
21]. However, to our knowledge there are currently no studies analyzing the relationship between psychological functioning and BMI values through ML techniques.
Here, we aim to address this gap by further exploring the relationship between affect-related psychological variables and BMI through ML algorithms. Specifically, we applied ML to infer predictive features related to psychological functioning over BMI using data from a study [
22] that demonstrated, employing correlational analysis, that depression levels may be useful in order to discriminate among BMI levels (normal weight, overweight, and all obesity classes). The main contributions of this work are twofold. Firstly, this study attempts to reproduce the results obtained on the relationship between affect-related psychological variables and BMI [
22] by using ML techniques. Computational reproducibility is the ability to repeat an analysis of a given data set and obtain sufficiently similar results [
23,
24]. Not only is reproducibility critical for ML research [
25], but it also constitutes a necessary requirement for science in general, given the constantly increasing need to subject study findings to more intensive scrutiny [
26]. Secondly, this study aims to test whether psychological variables can be used as predictors to forecast unobserved BMI values [
27]. The main objective of this study is therefore to identify risk and/or protective factors, conceptualized as negative and positive affectivity respectively, for overweight and obesity. Depending on the evidence for causality, these factors can be useful for screening patients who are at risk in a broader population as well as for the development of therapeutic interventions.
2. Materials and Methods
This section details the research questions at the base of this study, illustrates the dataset and the machine learning algorithms used, and then describes the employed approach together with the evaluation metrics adopted.
2.1. Research Questions
As anticipated in the Introduction section, the purpose of this study is to deepen the relationship between risk and protective factors, in the form of negative and positive affectivity for overweight and obese people through the use of Machine learning algorithms. In particular, the research questions that drove our study are the following ones:
- (1)
Is it possible to predict the BMI value (or the BMI class) using psychological variables?
- (2)
Which psychological variables, the positive or the negative ones, allow to better predict the BMI?
- (3)
Among them, which one has more influence on the prediction capability?
To answer these research questions, we followed the steps outlined below. Firstly, we used all the psychological variables as input to predict the BMI. Secondly, we considered separately the positive and the negative ones. This had let us to understand which ones allow to better predict the BMI. Finally, we evaluated those ones that work better following a leave-one-out approach to understand if one of them is more related than other ones to the BMI.
2.2. Dataset Description
The dataset used is composed of psychological variables exhibited by adults seeking treatment for their obesity, and by the control group. A detailed description of both participants and data collection procedure for this study is available in a recently published article [
22]. The dataset comprised a set of both positive and negative psychological variables relative to 320 subjects. Positive variables were those psychological factors that may play a protective role against obesity and include trait emotional intelligence (trait EI) measured with the Trait Emotional Intelligence Questionnaire–Short Form [
27]; cognitive reappraisal as emotion regulation strategy measured with the Emotion Regulation Questionnaire [
28]; and happiness, measured with the Oxford Happiness Inventory [
29]. Negative variables were instead potential risk-factors for the development and maintenance of obesity, and included: expressive suppression as emotion regulation strategy, binge eating, assessed with the Binge Eating Scale [
30], depression, assessed with the Beck Depression Inventory [
31], trait and state anxiety, assessed with the State Trait Anxiety Inventory-Y [
32]. Each of these questionnaires used to measure a certain psychological variable returns an integer value. Hence, for each subject, there are seven different values representing the psychological state of the subject. In addition to these ones, there are the BMI obtained for each participant and BMI categories computed according to the BMI ranges given by the World Health Organization [
33]. The subjects were organized into three groups: normal weight, overweight, and obese adults (see
Table 1).
2.3. Machine Learning Algorithms
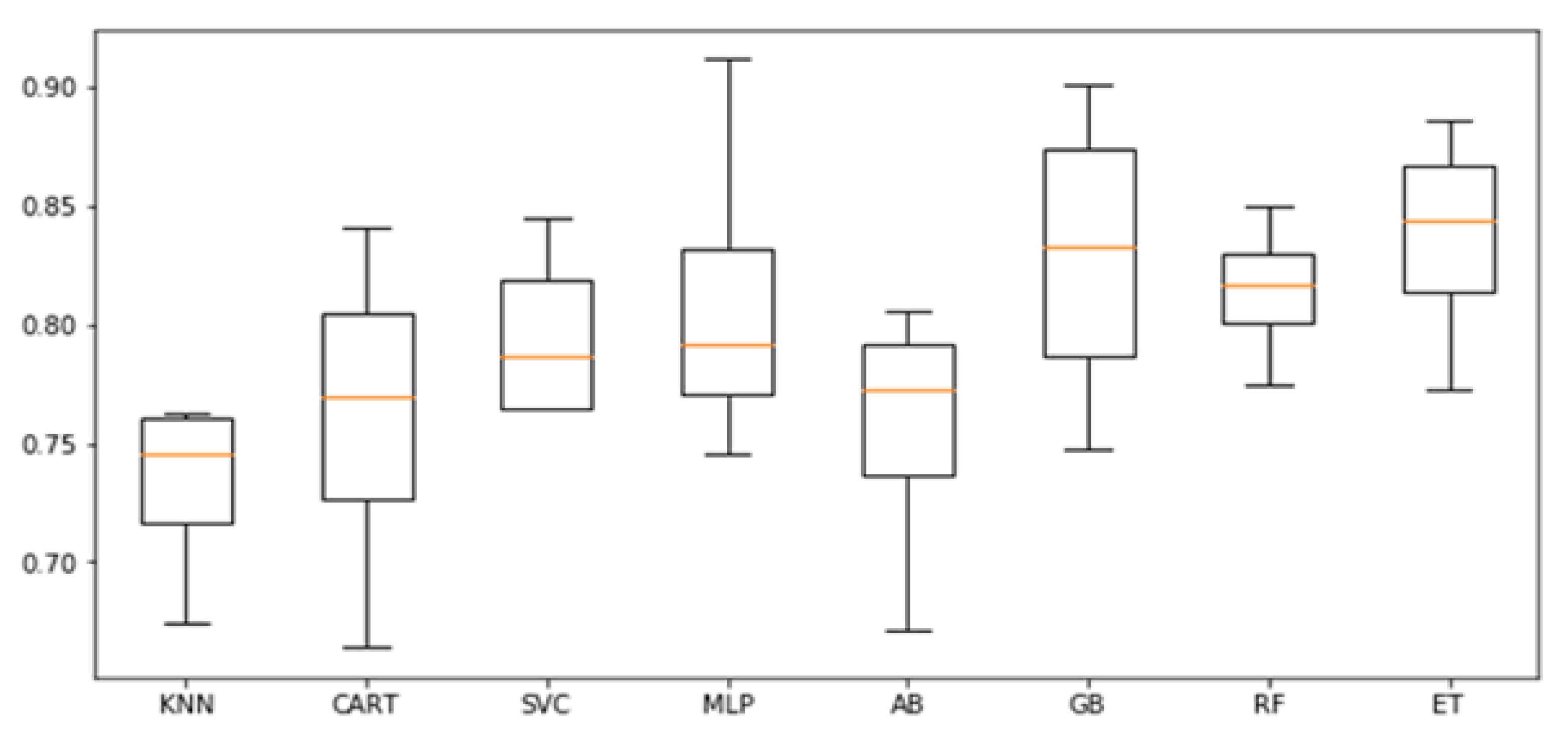
BMI was considered as both a continuous and a categorical variable. We took advantage of several algorithms, with the aim of understanding which ones work best in this specific context. In particular, we evaluated: K-nearest neighbor (KNN) [
34], classification and regression tree (CART) [
35], support vector machine (SVM) [
36], multi-layer perceptron (MLP) [
37], Ada boosting with decision tree (AB) [
38], gradient boosting (GB) [
39], random forest (RF) [
40], and extra tree (ET) [
41].
All algorithms were used for both the classification and the regression problem. For the regression analysis, we employed Lasso [
42] and Elastic Net Regression [
43] as additional algorithms.
We employed the Scikit-learn machine learning library in all our experiments. For all the algorithms, we used the default parameters with the only exception of the random state one, that we provided when possible to ensure reproducibility of results.
2.4. Approach and Evaluation Criteria
First of all, the dataset has been preprocessed to deal with missing values. Since the subjects with missing values not only had one but had many (five to seven psychological variables were missing out of a total of seven), we decided to simply remove those subjects from the dataset. In this way, the number of subjects in the dataset has gone from 320 to 221. Moreover, the dataset was divided in two different parts, one for the training phase, composed of the 80% of subjects (i.e., 176), and the other one for the testing phase, composed of the remaining 20% of subjects (i.e., 45). Then, for each one of the three steps described in
Section 2.1, in the training phase, we employed the stratified k-fold cross validation, a technique used to reduce the bias deriving from random sampling [
44]. We chose to use the number of folds equal to four, considering that the size of the dataset does not allow the use of the typical ten-fold cross validation. In fact, by dividing the training set into 10 folds, at each iteration, the overweight class in validation would only count 2 elements. Instead, using 4 folds, at each iteration, the overweight class in validation counts 5 elements, number which is also consistent with the size of the class in the test set. Before each training phase, the data were scaled, subtracting the average value and dividing by the standard deviation.
With regard to the classification,
Table 1 shows that the dataset suffers the problem of imbalance among the three classes. In fact, the subjects of the class Obesity are more than five times the ones of the class Overweight. This imbalance could lead to predictions that are more accurate on the majority class than on a minority class, resulting in a bias in favour of the majority class. To deal with this problem, we took advantage of a resampling technique with the aim of over-sampling the minority classes. In particular, we employed the synthetic minority over-sampling technique (SMOTE) [
45]. This technique exploits K-nearest neighbour in the feature space to generate synthetic examples of the minority class. In this way, during training, the number of examples for each class will be always the same.
A final consideration is due to the evaluation metrics. To assess the performance of classifiers, we employed a global metric, namely the F1-score, that is the harmonic average of the precision and recall together with two class-specific metrics, the sensitivity and specificity to measure the ability of the classifiers to predict true positives and true negatives. The prediction accuracy of our regressors has been evaluated with two different measures: mean absolute error (MAE) and Pearson correlation coefficient (PCC). The MAE measures the prediction error (i.e., the average deviation between the real BMI values and the predicted ones). The PCC quantifies the degree of the linear association between real and predicted BMI values. The reason to couple MAE and PCC is that when the values are all distributed near the average, a naive regressor that predicts always the mean value, achieve good performance. In such case, the PCC will instead be low, allowing to highlight, and consequently to avoid, such a problem.
4. Discussion
The current study aimed at exploring whether BMI values can be predicted from psychological parameters by using ML techniques. ML techniques represent a powerful set of algorithms that can derive useful knowledge for the medical field in general and for obesity more specifically, as they can help us to improve our understanding of such pathology and our capacity to predict it with greater precision [
46]. Risk prediction of adverse health conditions and events is a primary goal of much health research, and this study had the objective to provide evidence about the role of psychological factors as either risk (negative affectivity) or protective (positive affectivity) determinants of BMI levels through non-conventional statistical techniques.
Several ML algorithms were used to test theoretical models about the relationship between psychological variables and BMI. First of all, we can highlight how regardless of how the BMI is conceptualized (i.e., as a continuous value or as a categorical variable), the results are the same, without particular differences. For this reason, in the presentation of the answers to the research questions, we will not differentiate between the two types of problems. From the results presented in
Section 3.1, it is clear that the answer to the first research question is affirmative. In fact, using affect-related variables it is possible to predict the BMI with a good level of accuracy. To answer the second research question, instead, we have used as input positive and negative affect-related variables separately. The results reported in
Section 3.2 showed that BMI can be better predicted by the set of negative affect-related variables, such as depression, anxiety, and emotion suppression, whereas variables with more positive contents, such as happiness and emotion regulation, did not seem to play a predictive role over BMI. Hence, in the third step of our experiments, we considered only negative affect-related variables, leaving out one variable in turn to respond to the last research question. Among the psychological variables that we considered, depression seemed to have the strongest predictive power. In fact, the results presented in
Section 3.3 it is clear how the removal of depression generally leads to a significant lowering of the predictive capabilities of the machine learning algorithms, which does not happen for the other variables. Such a finding reinforces already published results that have highlighted the role of depression [
22]. These results add to the literature on ML and obesity by focusing on relevant psychological parameters for the prediction of BMI, and suggest that affective variables, particularly depression, should be considered in preventive and treatment care of BMI-related problems, especially in the case of elevated BMI and obesity.
To our knowledge, no prior investigation has used ML techniques to test for the predictive effects of emotional and affective variables over BMI values. In fact, already published studies where ML was employed took into account physiological parameters such as voice signals [
15] and face images [
16,
17]. However, further research should combine these findings by taking into account both medical and psychological parameters simultaneously. This would help to verify and compare the predictive role of these variables.
We must address the limitations of the current study. Firstly, it did not employ newly collected data, thus making our inferences limited. However, it allowed us to have a basis for comparison and to test for the reproducibility of previous findings [
23,
24,
25,
26]. Secondly, this study suffers from a number of methodological flaws, such as cross-sectional study design and a prevalence of self-evaluation (with the exclusion of BMI values which were directly assessed by the medical staff), as already discussed in [
22]. Those issues should be solved in future studies. Thirdly, from a technical perspective, the main limitation of this work is surely the restricted number of subjects. Increasing the size of the dataset, possibly in a balanced way, would help to strengthen the obtained results. Moreover, it would also allow the use of more powerful, yet data-hungry, algorithms, such as deep neural networks. Lastly, aside from BMI, the present study took into account psychological and demographic variables only. However, given the multifactorial nature of weight-related disorders, future studies need to include relevant medical and ‘lifestyle’ variables which may contribute to the explanation of present results (e.g., actual calories intake, weekly exercise, social support).
In conclusion, despite these limitations, present findings provide statistically strong information regarding the possibility to predict BMI values by means of a set of psychological variables with negative contents. Particularly, this is one of the first studies investigating the predictive role of psychological factors over a condition such as obesity, through ML algorithms [
47]. These data highlight the importance of considering the affective component of individual’s experience for a better and more complete understanding of weight-related disorders, as it can inform psychological interventions and treatment approaches, as well as improve preventive and therapeutic strategies. Yet, the use of ML has several advantages, as it outperforms traditional statistics, can be used to compare the impact of more variables on the prediction of the chosen outcome, and can handle any kind of variable. However, in order to improve the strength of these findings, future research aimed at overcoming present study limitations is required.


 ,
, 




{kind=link}