
Accelerating On-Device Learning with Layer-Wise Processor Selection Method on Unified Memory


Abstract
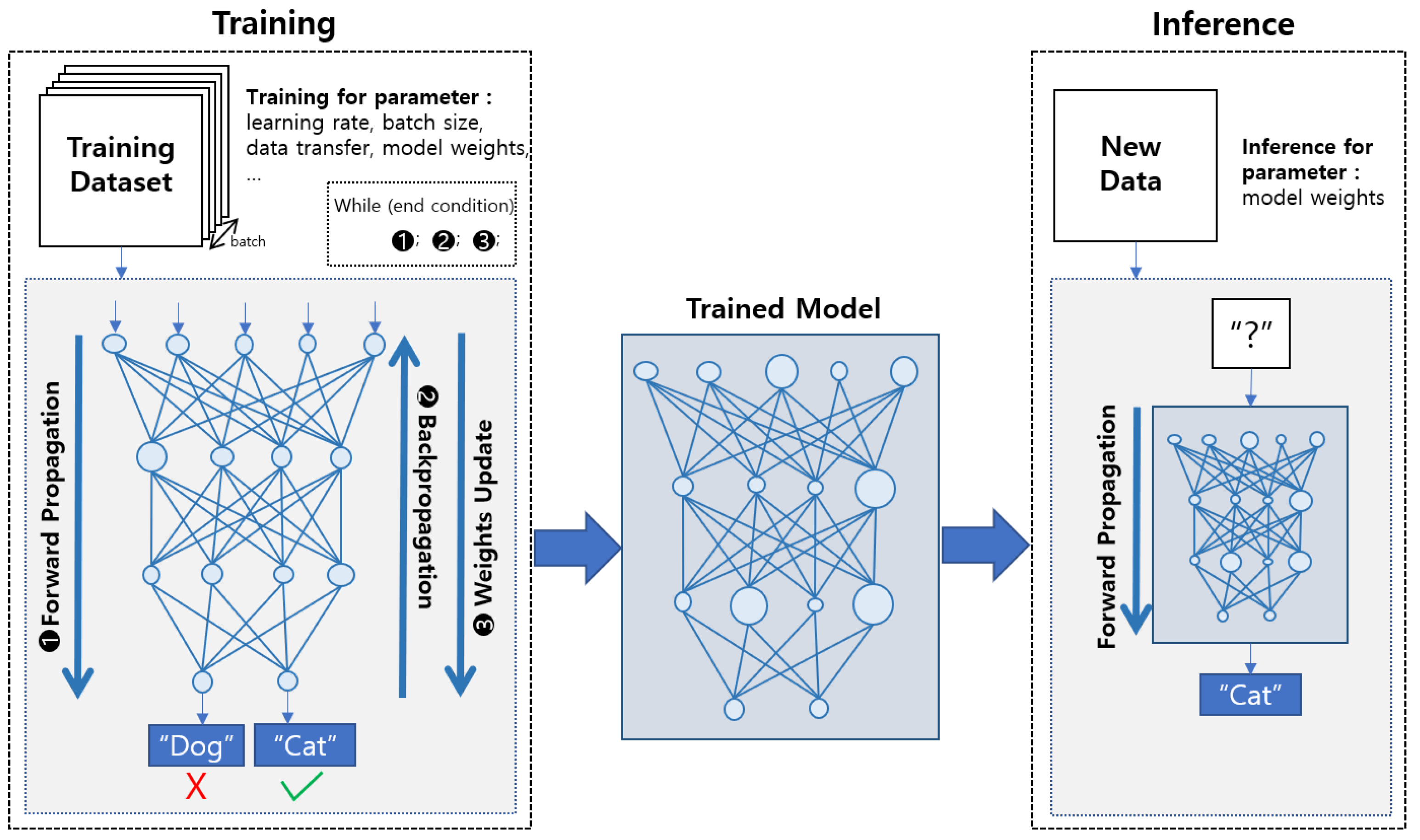
1. Introduction
- We propose the layer-wise PSM on unified memory to effectively utilize memory and resources. Compared to existing methods for inference, the proposed method is made more suitable for deep learning training by considering its cyclic process;
- We explore the usability by applying on-device learning to the ASC field. The performance of on-device learning can be varied by various factors such as batch size and average power consumption. Through experiments using various batch sizes to measure the average power consumption, we confirm that device heterogeneity, which is a challenging issue of ASC, is alleviated by performing on-device learning using the proposed method.
2. Related Work
2.1. Accelerating Inference/Training of Neural Network on Mobile Devices
2.2. Hardware for Accelerating Neural Network
2.3. Acoustic Scene Classification (ASC)
3. Proposed Method
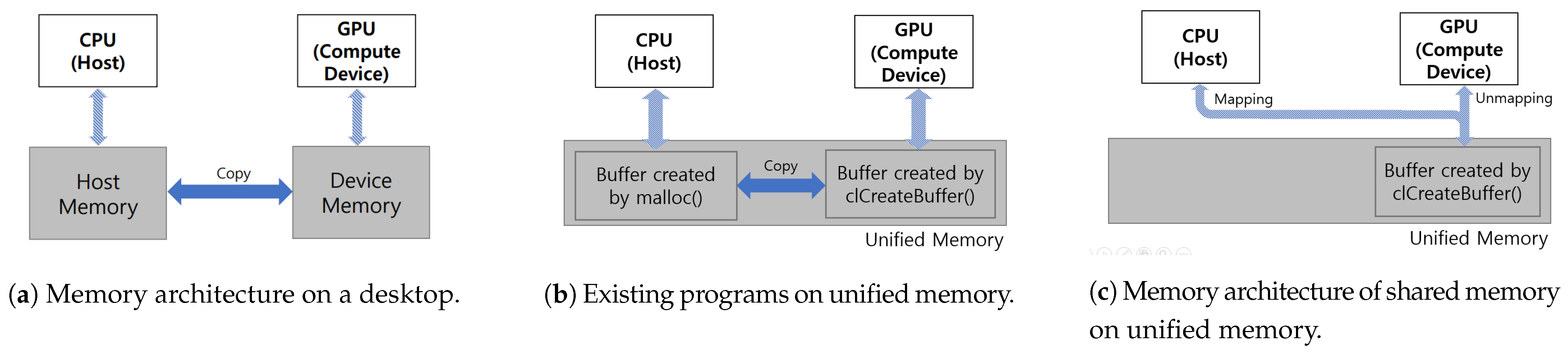
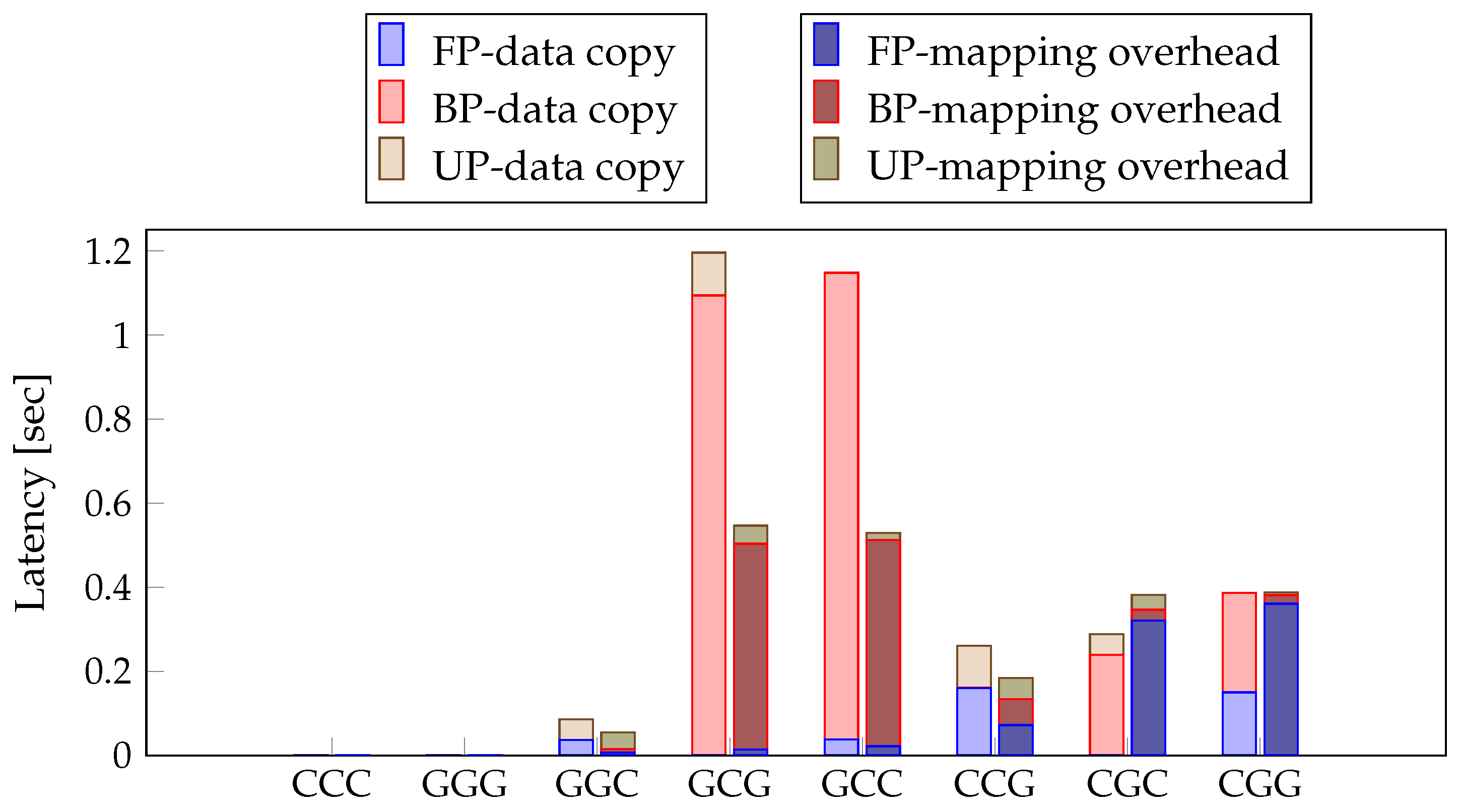
3.1. Data Transfer on Unified Memory
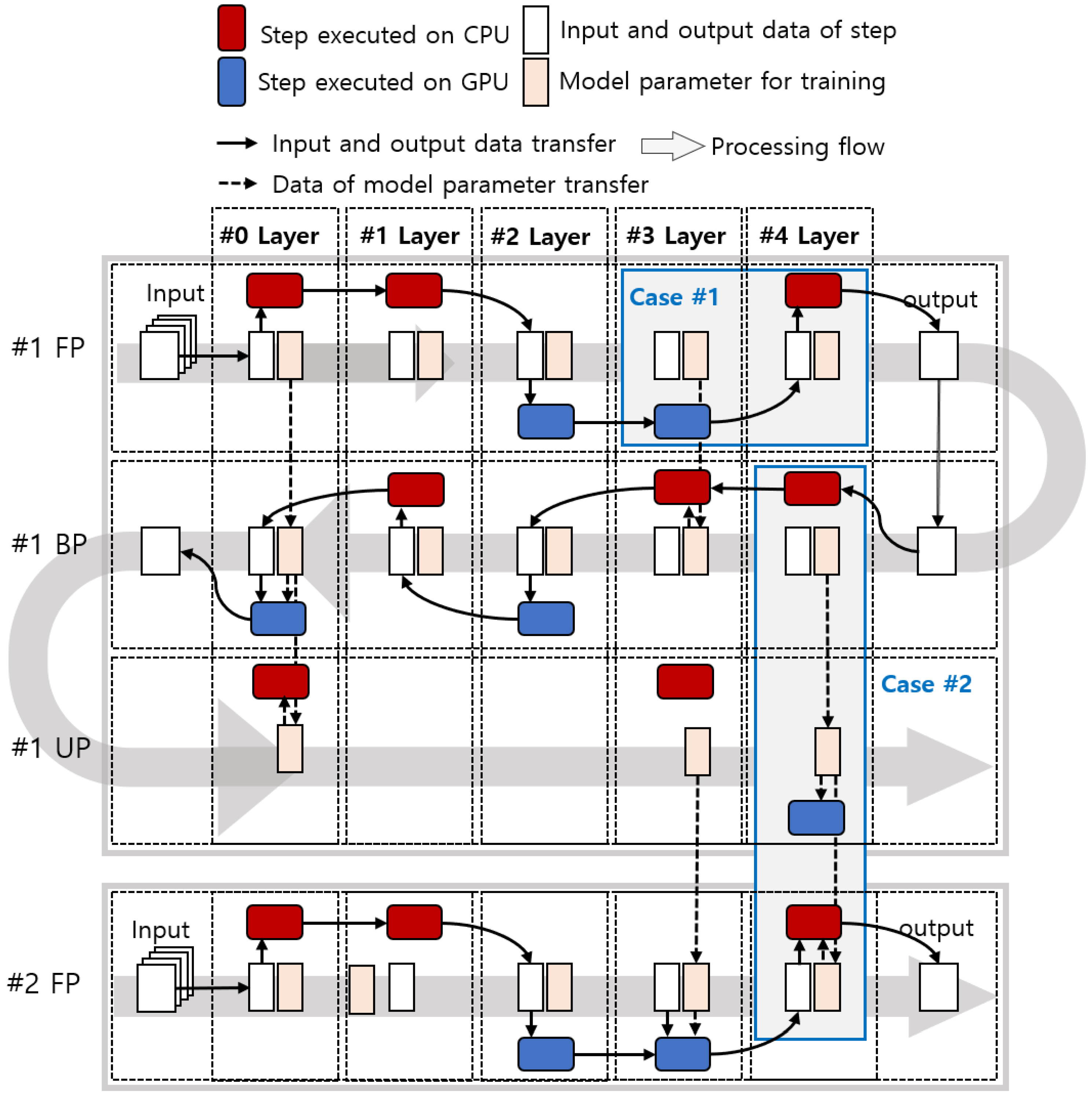
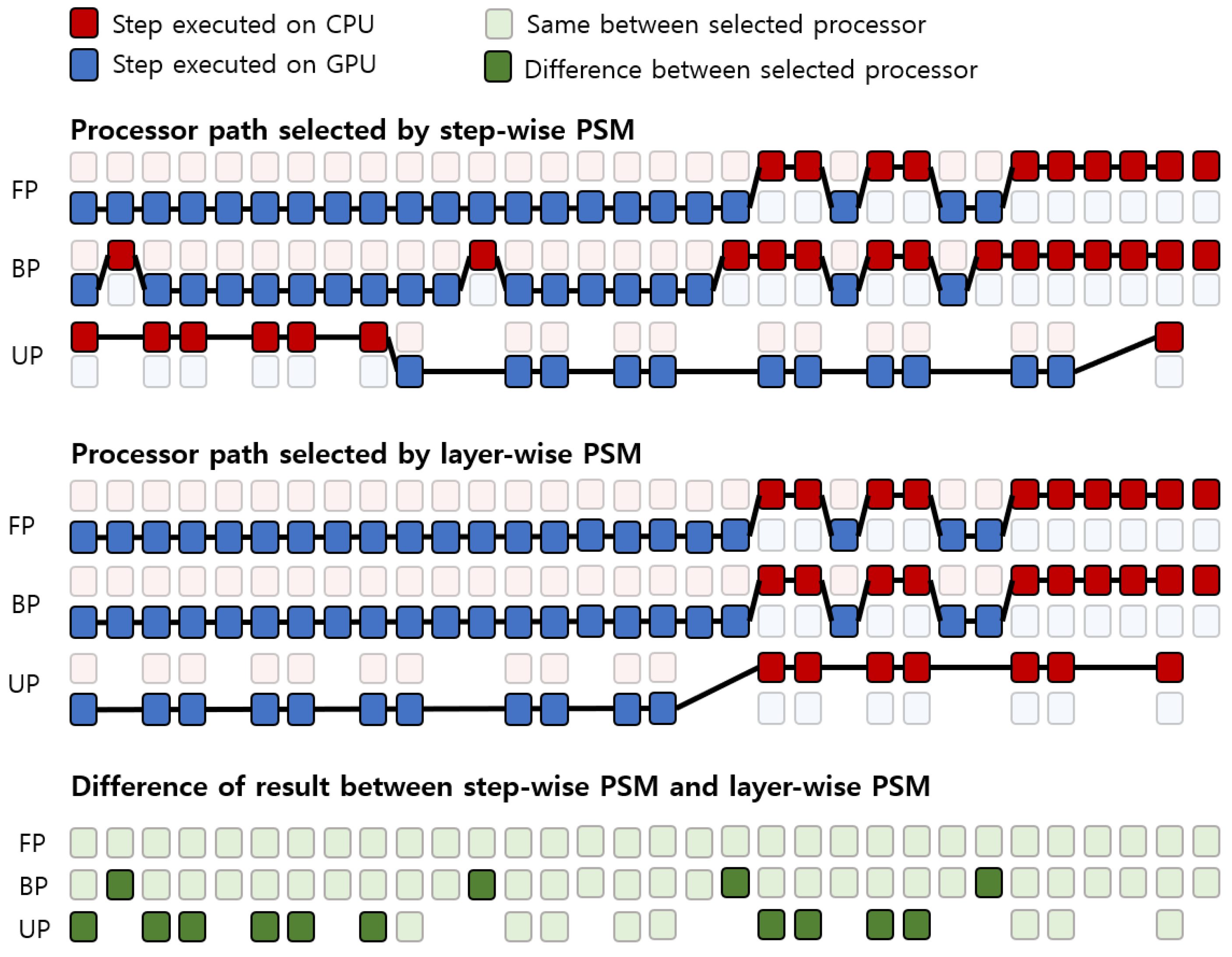
3.2. Layer-Wise Processor Selection Method (PSM)
| Algorithm 1 Layer-wise PSM |
|
4. Experiments
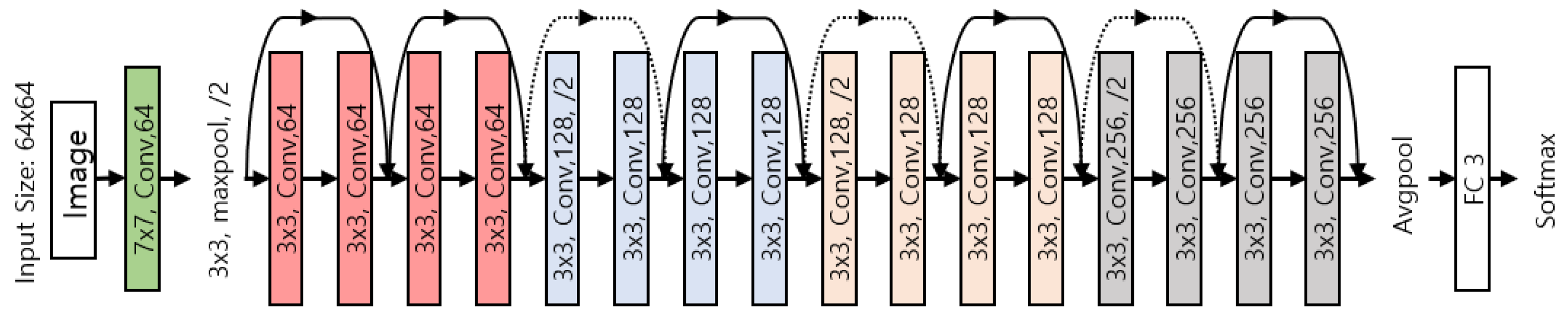
4.1. Experimental Setup
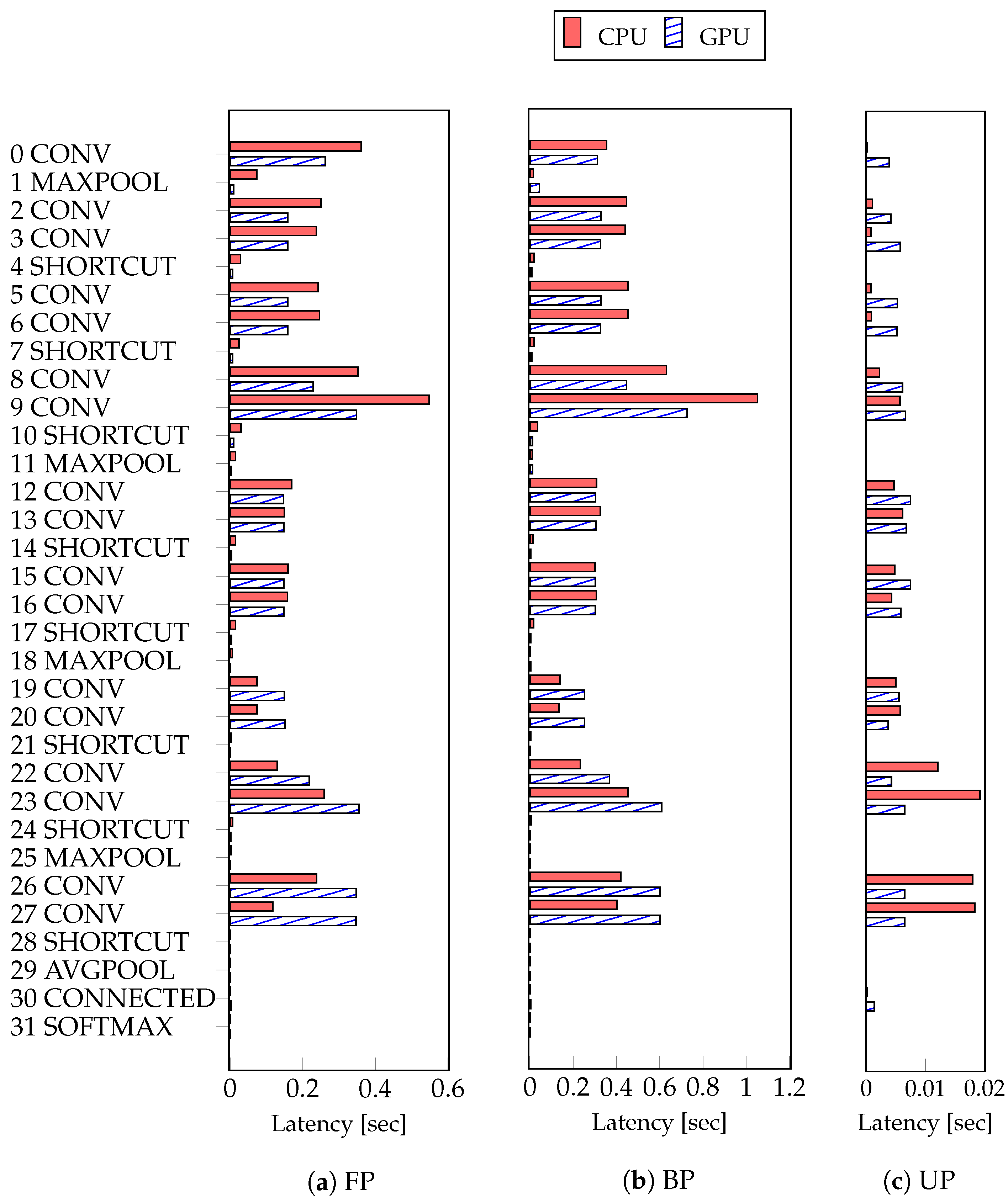
4.2. Experiments of Device Heterogeneity in ASC
4.3. Experiments of Proposed Method
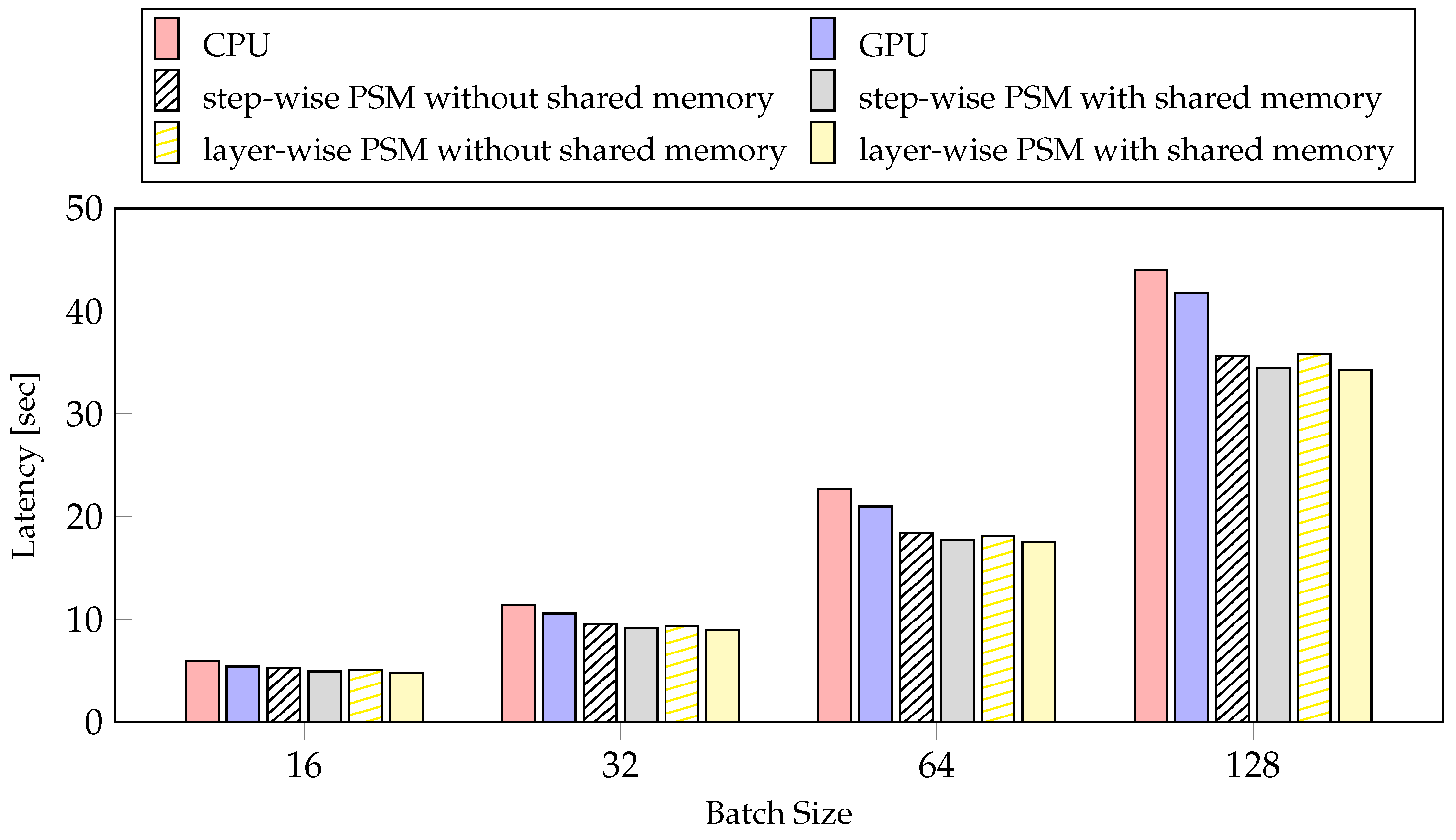
4.4. Evalution Experiments
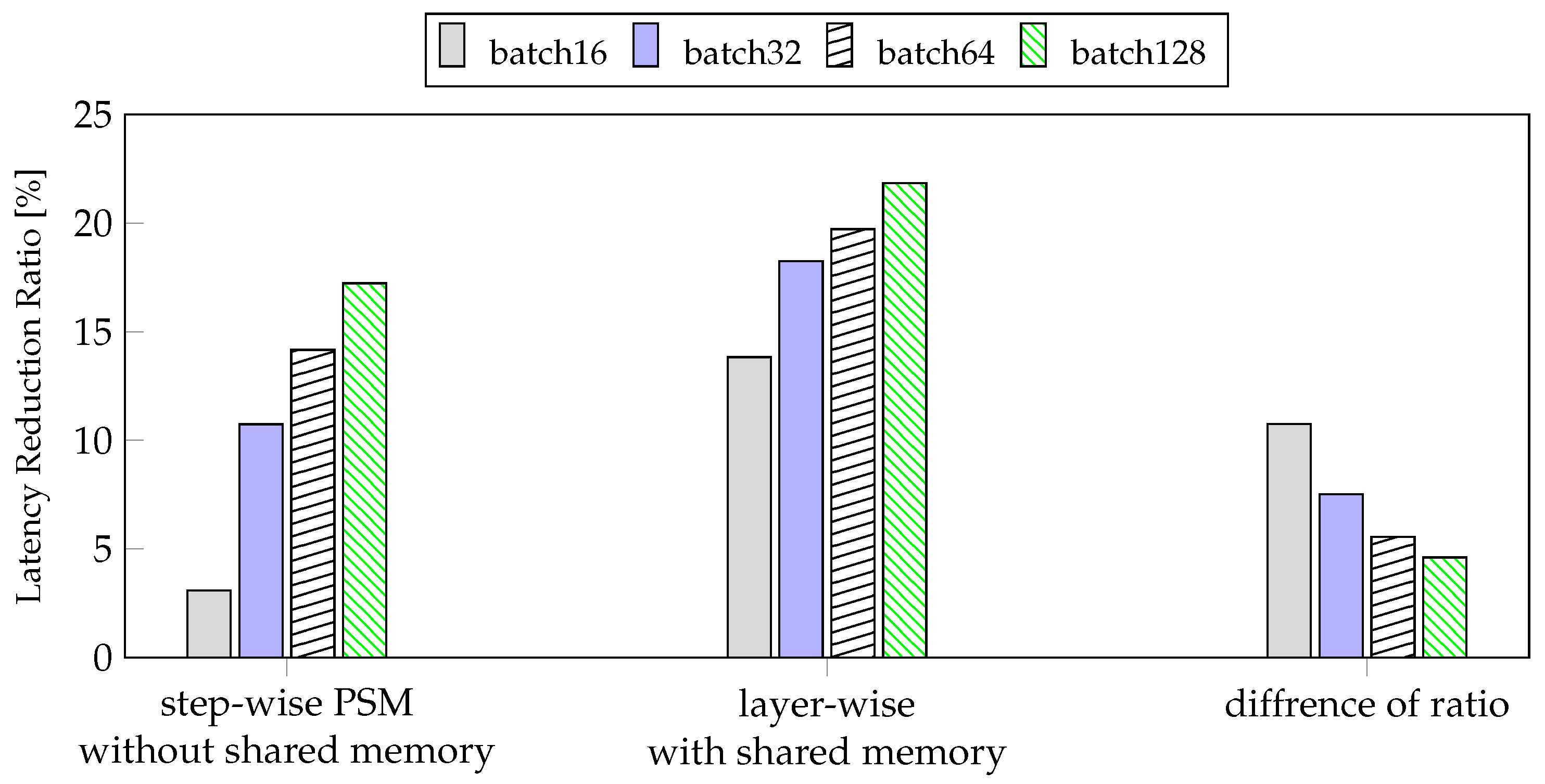
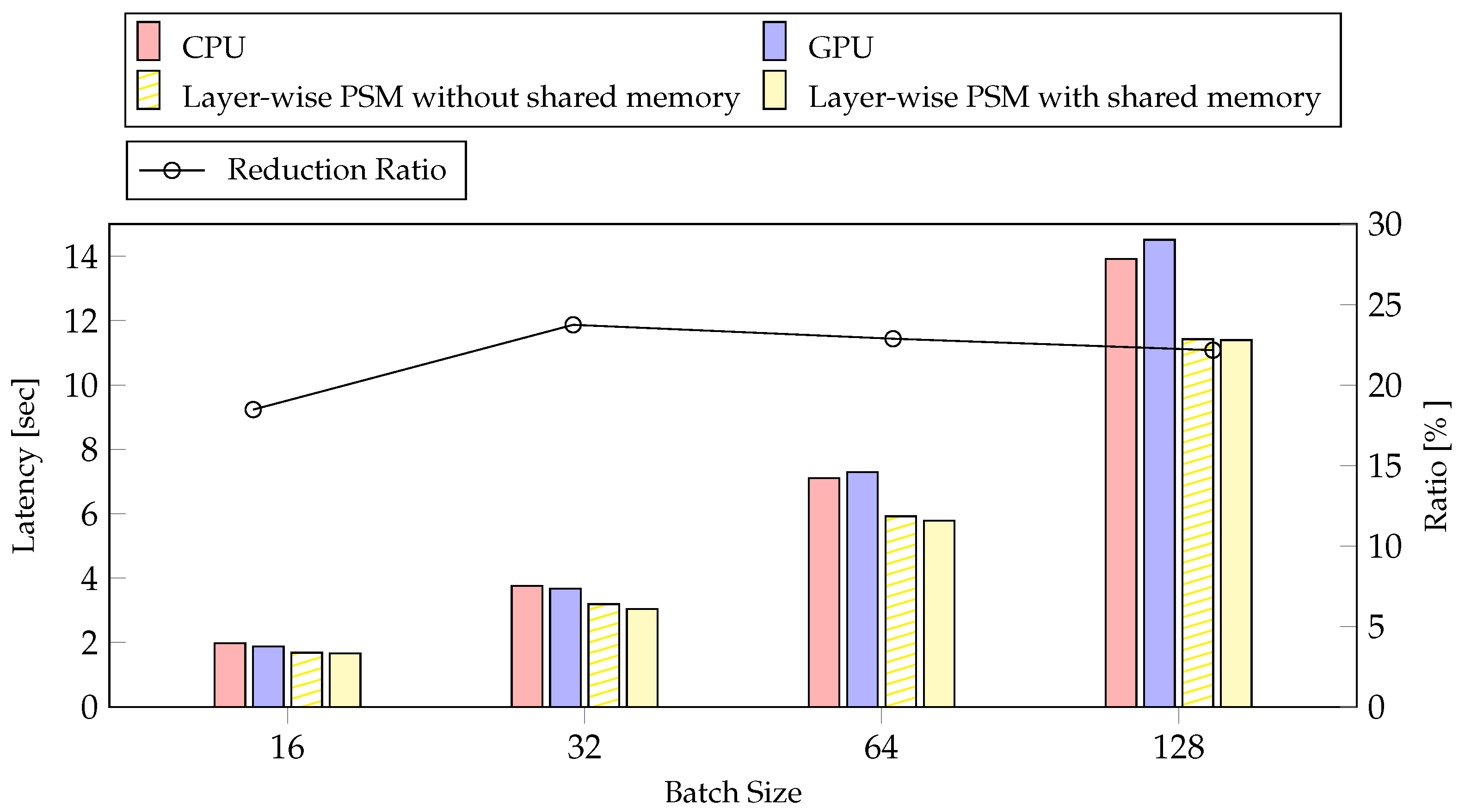
4.4.1. Batch Size
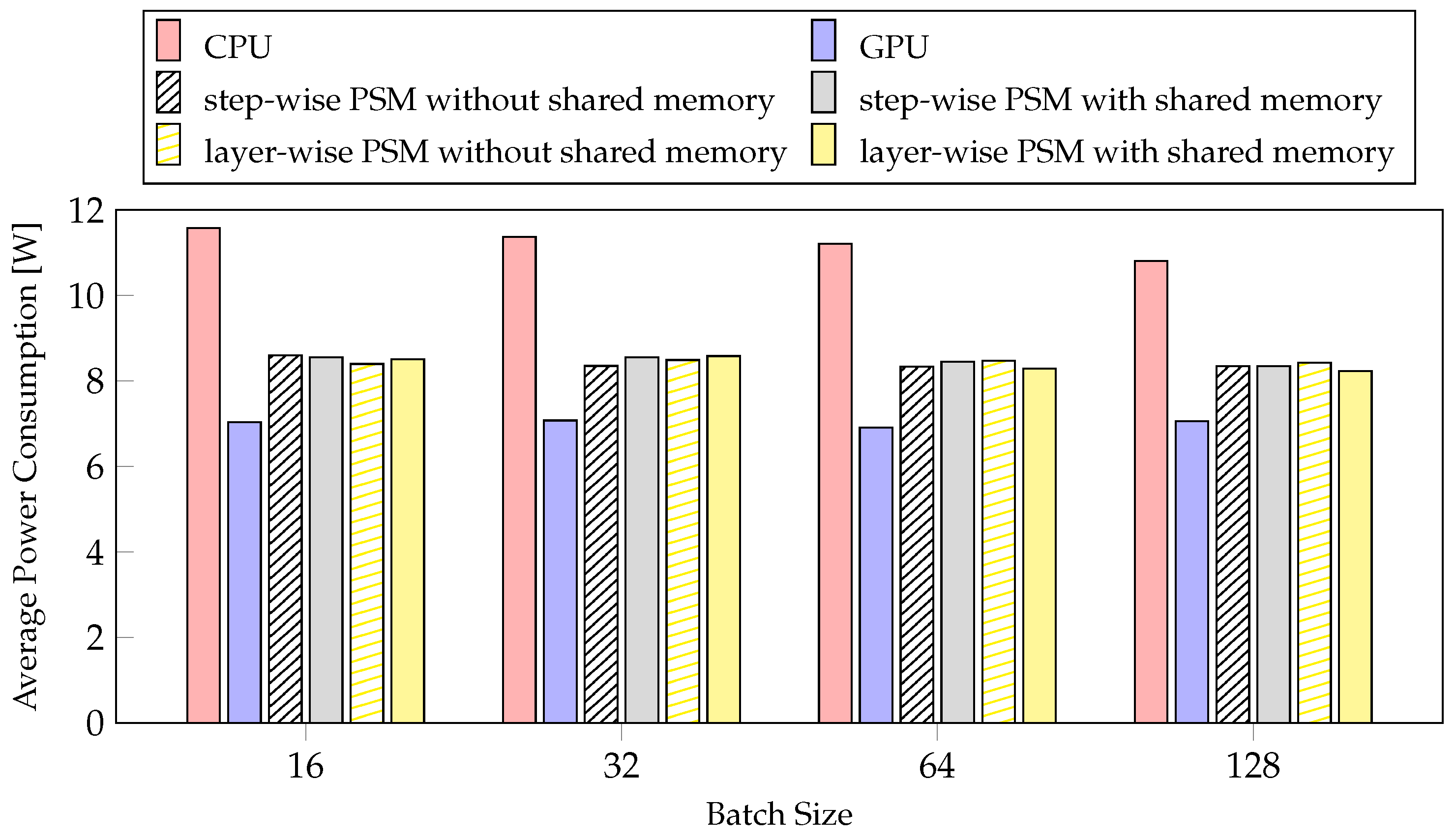
4.4.2. Average Power Consumption
4.4.3. Deep Learning Inference
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-Datacenter Performance Analysis of a Tensor Processing Unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture, ISCA ’17, Toronto, ON, Canada, 24–28 June 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 1–12. [Google Scholar] [CrossRef]
- Buetti-Dinh, A.; Galli, V.; Bellenberg, S.; Ilie, O.; Herold, M.; Christel, S.; Boretska, M.; Pivkin, I.V.; Wilmes, P.; Sand, W.; et al. Deep neural networks outperform human expert’s capacity in characterizing bioleaching bacterial biofilm composition. Biotechnol. Rep. 2019, 22, e00321. [Google Scholar] [CrossRef] [PubMed]
- Mesaros, A.; Heittola, T.; Virtanen, T. Assessment of human and machine performance in acoustic scene classification: DCASE 2016 case study. In Proceedings of the 2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 15–18 October 2017; pp. 319–323. [Google Scholar] [CrossRef]
- Kim, K.; Jeong, I.; Cho, J. Design and Implementation of a Video/Voice Process System for Recognizing Vehicle Parts Based on Artificial Intelligence. Sensors 2020, 20, 7339. [Google Scholar] [CrossRef] [PubMed]
- Noh, K.J.; Jeong, C.Y.; Lim, J.; Chung, S.; Kim, G.; Lim, J.M.; Jeong, H. Multi-Path and Group-Loss-Based Network for Speech Emotion Recognition in Multi-Domain Datasets. Sensors 2021, 21, 1579. [Google Scholar] [CrossRef]
- Jeong, C.; Yang, H.S.; Moon, K. A novel approach for detecting the horizon using a convolutional neural network and multi-scale edge detection. Multidimens. Syst. Signal Process. 2019, 30, 1187–1204. [Google Scholar] [CrossRef]
- Chen, Y.; Zheng, B.; Zhang, Z.; Wang, Q.; Shen, C.; Zhang, Q. Deep Learning on Mobile and Embedded Devices: State-of-the-art, Challenges, and Future Directions. ACM Comput. Surv. (CSUR) 2020, 53, 1–37. [Google Scholar] [CrossRef]
- Ota, K.; Dao, M.S.; Mezaris, V.; Natale, F.G.B.D. Deep Learning for Mobile Multimedia: A Survey. ACM Trans. Multimed. Comput. Commun. Appl. 2017, 13. [Google Scholar] [CrossRef]
- Wang, J.; Cao, B.; Yu, P.; Sun, L.; Bao, W.; Zhu, X. Deep Learning towards Mobile Applications. In Proceedings of the 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS), Vienna, Austria, 2–5 July 2018; pp. 1385–1393. [Google Scholar] [CrossRef]
- Zhang, C.; Patras, P.; Haddadi, H. Deep Learning in Mobile and Wireless Networking: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 2224–2287. [Google Scholar] [CrossRef]
- Jeong, C.Y.; Kim, M. An Energy-Efficient Method for Human Activity Recognition with Segment-Level Change Detection and Deep Learning. Sensors 2019, 19, 3688. [Google Scholar] [CrossRef]
- Changmin, K.; Soonshin, S.; Ji-Hwan, K. Multi-Channel Feature Using Inter-Class and Inter-Device Standard Deviations for Acoustic Scene Classification; Technical Report, DCASE 2020; IEEE Signal Processing Society: New York, NY, USA, 2020. [Google Scholar]
- Fanioudakis, E.; Vafeiadis, A. Investigating Temporal and Spectral Sequences Combining GRU-Rnns for Acoustic Scene Classification; Technical Report, DCASE 2020; IEEE Signal Processing Society: New York, NY, USA, 2020. [Google Scholar]
- Hu, H.; Yang, C.H.H.; Xia, X.; Bai, X.; Tang, X.; Wang, Y.; Niu, S.; Chai, L.; Li, J.; Zhu, H.; et al. Device-Robust Acoustic Scene Classification Based on Two-Stage Categorization and Data Augmentation; Technical Report, DCASE 2020; IEEE Signal Processing Society: New York, NY, USA, 2020. [Google Scholar]
- Wang, P.; Cheng, Z.; Xu, X. Acoustic Scene Classification with Device Mismatch Using Data Augmentation by Spectrum Correction; Technical Report, DCASE 2020; IEEE Signal Processing Society: New York, NY, USA, 2020. [Google Scholar]
- Xu, G.; Li, H.; Ren, H.; Yang, K.; Deng, R.H. Data Security Issues in Deep Learning: Attacks, Countermeasures, and Opportunities. IEEE Commun. Mag. 2019, 57, 116–122. [Google Scholar] [CrossRef]
- Kholod, I.; Yanaki, E.; Fomichev, D.; Shalugin, E.; Novikova, E.; Filippov, E.; Nordlund, M. Open-Source Federated Learning Frameworks for IoT: A Comparative Review and Analysis. Sensors 2021, 21, 167. [Google Scholar] [CrossRef]
- Motamedi, M.; Fong, D.; Ghiasi, S. Cappuccino: Efficient CNN Inference Software Synthesis for Mobile System-on-Chips. IEEE Embed. Syst. Lett. 2019, 11, 9–12. [Google Scholar] [CrossRef]
- Latifi Oskouei, S.S.; Golestani, H.; Hashemi, M.; Ghiasi, S. CNNdroid: GPU-Accelerated Execution of Trained Deep Convolutional Neural Networks on Android. In Proceedings of the 24th ACM International Conference on Multimedia, MM ’16, Amsterdam, The Netherlands, 15–19 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1201–1205. [Google Scholar] [CrossRef]
- Nguyen Huynh, L.; Lee, Y.; Balan, R. DeepMon: Mobile GPU-based Deep Learning Framework for Continuous Vision Applications. In Proceedings of the 15th Annual International Conference on Mobile Systems, Applications, and Services, Niagara Falls, NY, USA, 19–23 June 2017; pp. 82–95. [Google Scholar] [CrossRef]
- Lane, N.D.; Bhattacharya, S.; Georgiev, P.; Forlivesi, C.; Jiao, L.; Qendro, L.; Kawsar, F. DeepX: A Software Accelerator for Low-Power Deep Learning Inference on Mobile Devices. In Proceedings of the 2016 15th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), Vienna, Austria, 11–14 April 2016; pp. 1–12. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, J.; Chae, D.; Kim, D.; Kim, J. μlayer: Low Latency On-Device Inference Using Cooperative Single-Layer Acceleration and Processor-Friendly Quantization. In Proceedings of the Fourteenth EuroSys Conference 2019, EuroSys ’19, Dresden, Germany, 25–28 March 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Valery, O.; Liu, P.; Wu, J.J. A collaborative CPU-GPU approach for deep learning on mobile devices. Concurr. Comput. Pract. Exp. 2019, 31, e5225. [Google Scholar] [CrossRef]
- Ha, D. Improving Speed of Deep learning Assigning Tasks from Processing Units on Embedded Device. Master’s Thesis, Chungnam National University, Daejeon, Korea, 2020. [Google Scholar]
- Han, M.; Hyun, J.; Park, S.; Park, J.; Baek, W. MOSAIC: Heterogeneity-, Communication-, and Constraint-Aware Model Slicing and Execution for Accurate and Efficient Inference. In Proceedings of the 2019 28th International Conference on Parallel Architectures and Compilation Techniques (PACT), Seattle, WA, USA, 23–26 September 2019; pp. 165–177. [Google Scholar] [CrossRef]
- Lane, N.D.; Georgiev, P.; Qendro, L. DeepEar: Robust Smartphone Audio Sensing in Unconstrained Acoustic Environments Using Deep Learning. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, UbiComp ’15, Umeda, Osaka, Japan, 7–11 September 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 283–294. [Google Scholar] [CrossRef]
- Valery, O.; Liu, P.; Wu, J. CPU/GPU Collaboration Techniques for Transfer Learning on Mobile Devices. In Proceedings of the 2017 IEEE 23rd International Conference on Parallel and Distributed Systems (ICPADS), Shenzhen, China, 15–17 December 2017; pp. 477–484. [Google Scholar] [CrossRef]
- Capra, M.; Bussolino, B.; Marchisio, A.; Shafique, M.; Masera, G.; Martina, M. An Updated Survey of Efficient Hardware Architectures for Accelerating Deep Convolutional Neural Networks. Future Internet 2020, 12, 113. [Google Scholar] [CrossRef]
- Wang, T.; Wang, C.; Zhou, X.; Chen, H. An Overview of FPGA Based Deep Learning Accelerators: Challenges and Opportunities. In Proceedings of the 2019 IEEE 21st International Conference on High Performance Computing and Communications; IEEE 17th International Conference on Smart City; IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Zhangjiajie, China, 10–12 August 2019; pp. 1674–1681. [Google Scholar] [CrossRef]
- Kim, H.; Lyuh, C.G.; Kwon, Y. Automated optimization for memory-efficient high-performance deep neural network accelerators. ETRI J. 2020, 42, 505–517. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, T.; Xu, Z.; Sun, N.; Temam, O. DianNao Family: Energy-Efficient Hardware Accelerators for Machine Learning. Commun. ACM 2016, 59, 105–112. [Google Scholar] [CrossRef]
- Sophiya, E.; Jothilakshmi, S. Deep Learning Based Audio Scene Classification. In Proceedings of the International Conference on Computational Intelligence, Cyber Security, and Computational Models, Coimbatore, India, 14–16 December 2017; pp. 98–109._9. [Google Scholar] [CrossRef]
- Piczak, K.J. Environmental sound classification with convolutional neural networks. In Proceedings of the 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Abeßer, J. A Review of Deep Learning Based Methods for Acoustic Scene Classification. Appl. Sci. 2020, 10, 2020. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Suh, S.; Park, S.; Jeong, Y.; Lee, T. Designing Acoustic Scene Classification Models with CNN Variants; Technical Report, DCASE 2020; IEEE Signal Processing Society: New York, NY, USA, 2020. [Google Scholar]
- Koutini, K.; Eghbal-zadeh, H.; Widmer, G.; Kepler, J. CP-JKU Submissions to DCASE’19: Acoustic Scene Classification and Audio Tagging with REceptive-Field-Regularized CNNs. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop (DCASE2019), New York, NY, USA, 25–26 October 2019; pp. 25–26. [Google Scholar]
- McDonnell, M.D.; Gao, W. Acoustic Scene Classification Using Deep Residual Networks with Late Fusion of Separated High and Low Frequency Paths. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual Conference, 4–8 May 2020; pp. 141–145. [Google Scholar] [CrossRef]
- Liu, M.; Wang, W.; Li, Y. The System for Acoustic Scene Classification Using Resnet; Technical Report, DCASE 2019; IEEE Signal Processing Society: New York, NY, USA, 2019. [Google Scholar]
- ODROID XU4. Available online: https://www.hardkernel.com/ (accessed on 2 February 2021).
- Exynos 5422. Available online: https://www.samsung.com/semiconductor/minisite/exynos/products/mobileprocessor/exynos-5-octa-5422/ (accessed on 2 February 2021).
- High Voltage Power Monitor. Available online: https://www.msoon.com/high-voltage-power-monitor (accessed on 2 February 2021).
- Sowa, P.; Izydorczyk, J. Darknet on OpenCL: A Multi-Platform Tool for Object Detection and Classification. 2020. preprints202007.0506.v1. Available online: https://www.preprints.org/manuscript/202007.0506/v1 (accessed on 2 February 2021).
- Darknet: Open Source Neural Networks in C. Available online: https://pjreddie.com/darknet/ (accessed on 2 February 2021).
- NVIDIA; Vingelmann, P.; Fitzek, F.H. CUDA, Release: 10.2.89. 2020. Available online: https://developer.nvidia.com/cuda-toolkit. (accessed on 2 February 2021).
- Stone, J.E.; Gohara, D.; Shi, G. OpenCL: A Parallel Programming Standard for Heterogeneous Computing Systems. Comput. Sci. Eng. 2010, 12, 66–73. [Google Scholar] [CrossRef] [PubMed]
- Xian-yi, Z.; Qian, W.; Yun-quan, Z. Openblas: A High Performance Blas Library on Loongson 3a cpu. 2011. Available online: https://www.openblas.net/ (accessed on 2 February 2021).
- Nugteren, C. CLBlast: A Tuned OpenCL BLAS Library. In Proceedings of the International Workshop on OpenCL, Association for Computing Machinery, IWOCL ’18, Oxford, UK, 14–16 May 2018. [Google Scholar] [CrossRef]
- Mesaros, A.; Heittola, T.; Virtanen, T. A multi-device dataset for urban acoustic scene classification. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2018 Workshop (DCASE2018), Surrey, UK, 19–20 November 2018; pp. 9–13. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Kandel, I.; Castelli, M. The effect of batch size on the generalizability of the convolutional neural networks on a histopathology dataset. ICT Express 2020, 6, 312–315. [Google Scholar] [CrossRef]
- Pramanik, P.K.D.; Sinhababu, N.; Mukherjee, B.; Padmanaban, S.; Maity, A.; Upadhyaya, B.K.; Holm-Nielsen, J.B.; Choudhury, P. Power Consumption Analysis, Measurement, Management, and Issues: A State-of-the-Art Review of Smartphone Battery and Energy Usage. IEEE Access 2019, 7, 182113–182172. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
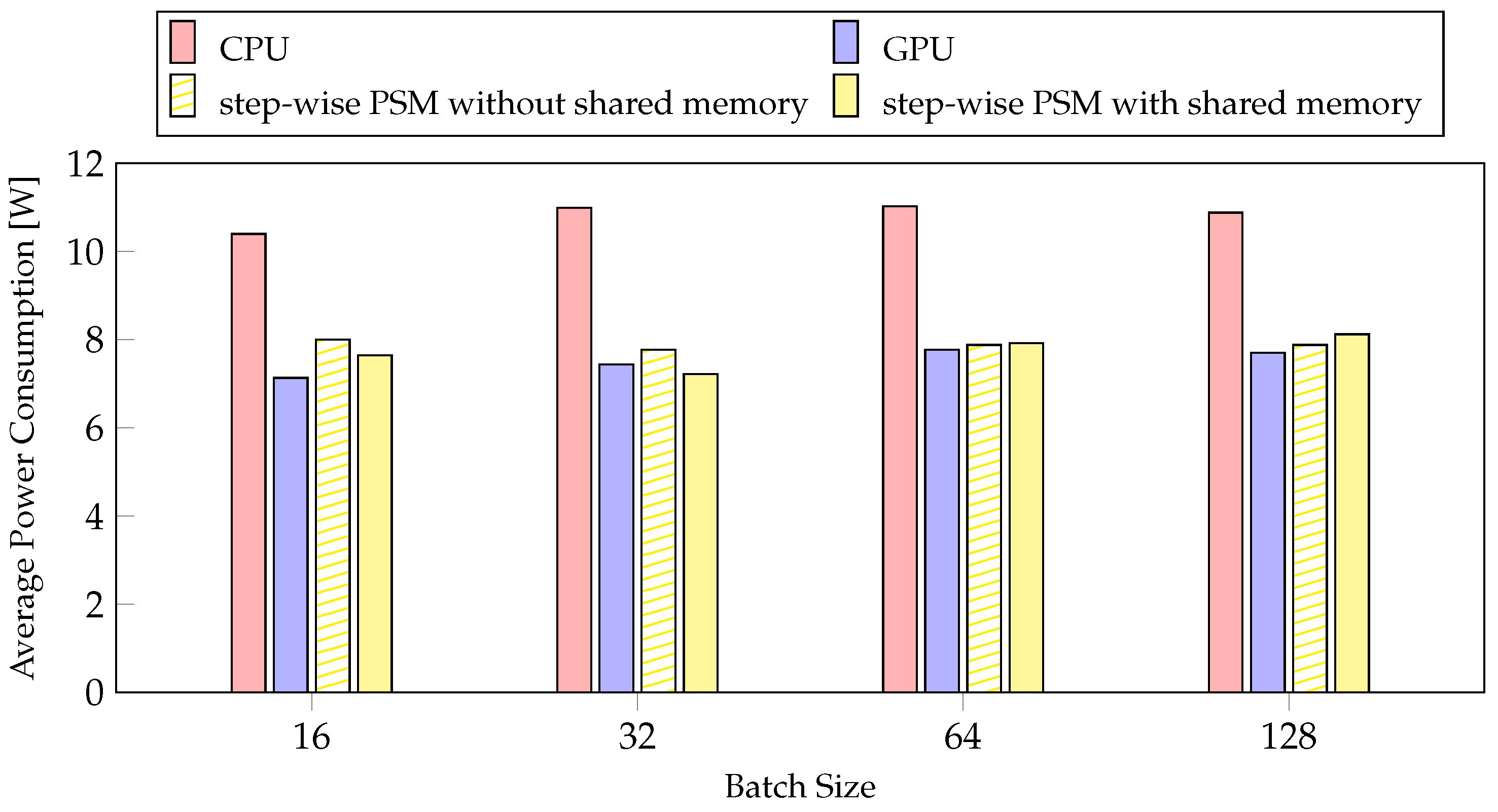{kind=link}
| Latency [s] | Reduction Ratio [%] | |
|---|---|---|
| CPU | 11.43 | - |
| GPU | 10.57 | 8.14 |
| Step-wise PSM without shared memory | 9.55 | 19.68 |
| Step-wise PSM with shared memory | 9.25 | 23.57 |
| Layer-wise PSM without shared memory | 9.31 | 22.78 |
| Layer-wise PSM with shared memory | 8.94 | 27.80 |
| Latency Reduction Ratio [%] | Average Power Consumption Reduction Ratio [%] | |||
|---|---|---|---|---|
| Inference | Training | Inference | Training | |
| Batch 16 | 18.47 | 24.23 | 36.06 | 37.83 |
| Batch 32 | 23.74 | 27.80 | 36.98 | 33.89 |
| Batch 64 | 22.88 | 28.22 | 37.01 | 34.32 |
| Batch 128 | 22.17 | 28.40 | 35.66 | 35.33 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ha, D.; Kim, M.; Moon, K.; Jeong, C.Y. Accelerating On-Device Learning with Layer-Wise Processor Selection Method on Unified Memory. Sensors 2021, 21, 2364. https://doi.org/10.3390/s21072364
Ha D, Kim M, Moon K, Jeong CY. Accelerating On-Device Learning with Layer-Wise Processor Selection Method on Unified Memory. Sensors. 2021; 21(7):2364. https://doi.org/10.3390/s21072364
Chicago/Turabian StyleHa, Donghee, Mooseop Kim, KyeongDeok Moon, and Chi Yoon Jeong. 2021. "Accelerating On-Device Learning with Layer-Wise Processor Selection Method on Unified Memory" Sensors 21, no. 7: 2364. https://doi.org/10.3390/s21072364
APA StyleHa, D., Kim, M., Moon, K., & Jeong, C. Y. (2021). Accelerating On-Device Learning with Layer-Wise Processor Selection Method on Unified Memory. Sensors, 21(7), 2364. https://doi.org/10.3390/s21072364