
Visibility Restoration: A Systematic Review and Meta-Analysis


Abstract
:1. Introduction
- Researchers who require a systematically organized body of knowledge on relevant studies.
- Practitioners who are interested in general knowledge on existing methods and techniques.
- Laypeople who need a readable and understandable review of relevant research.
2. Preliminaries
2.1. PRISMA
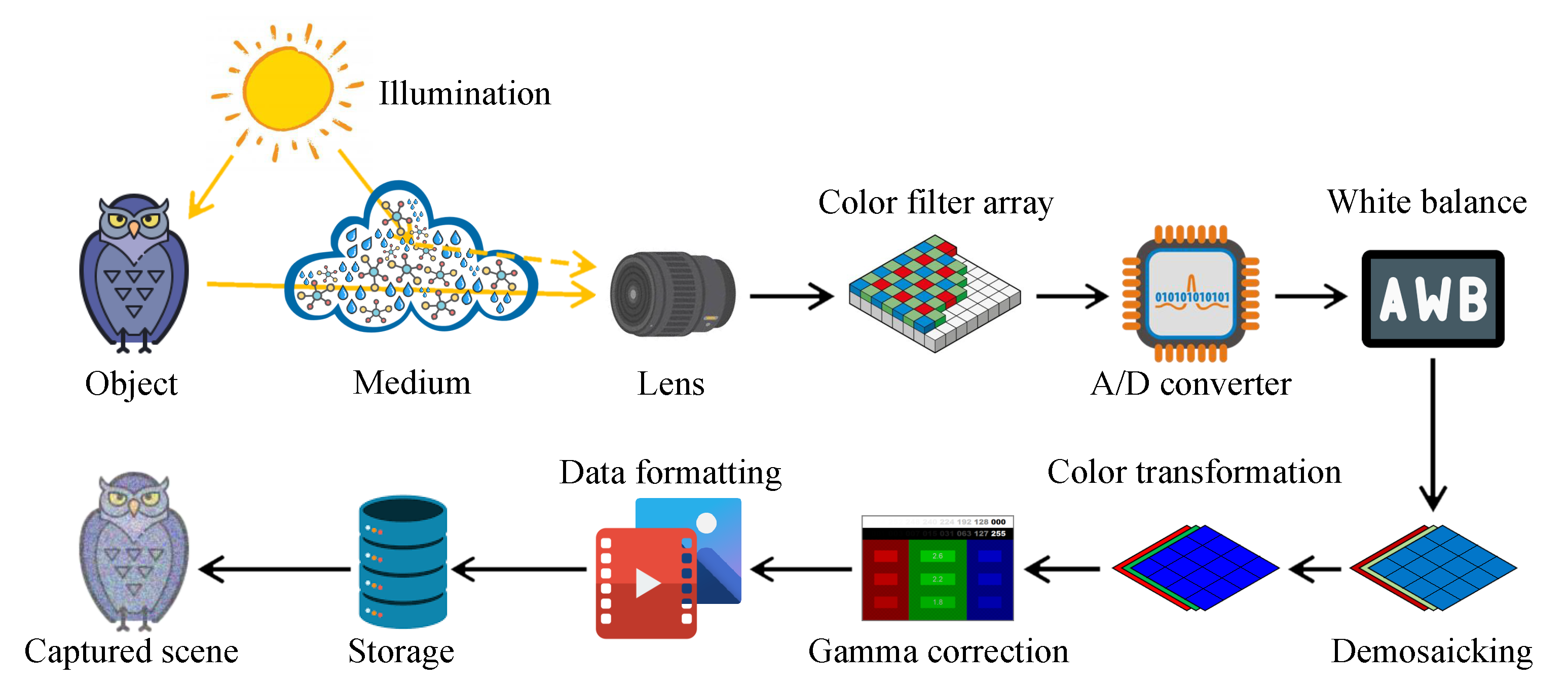
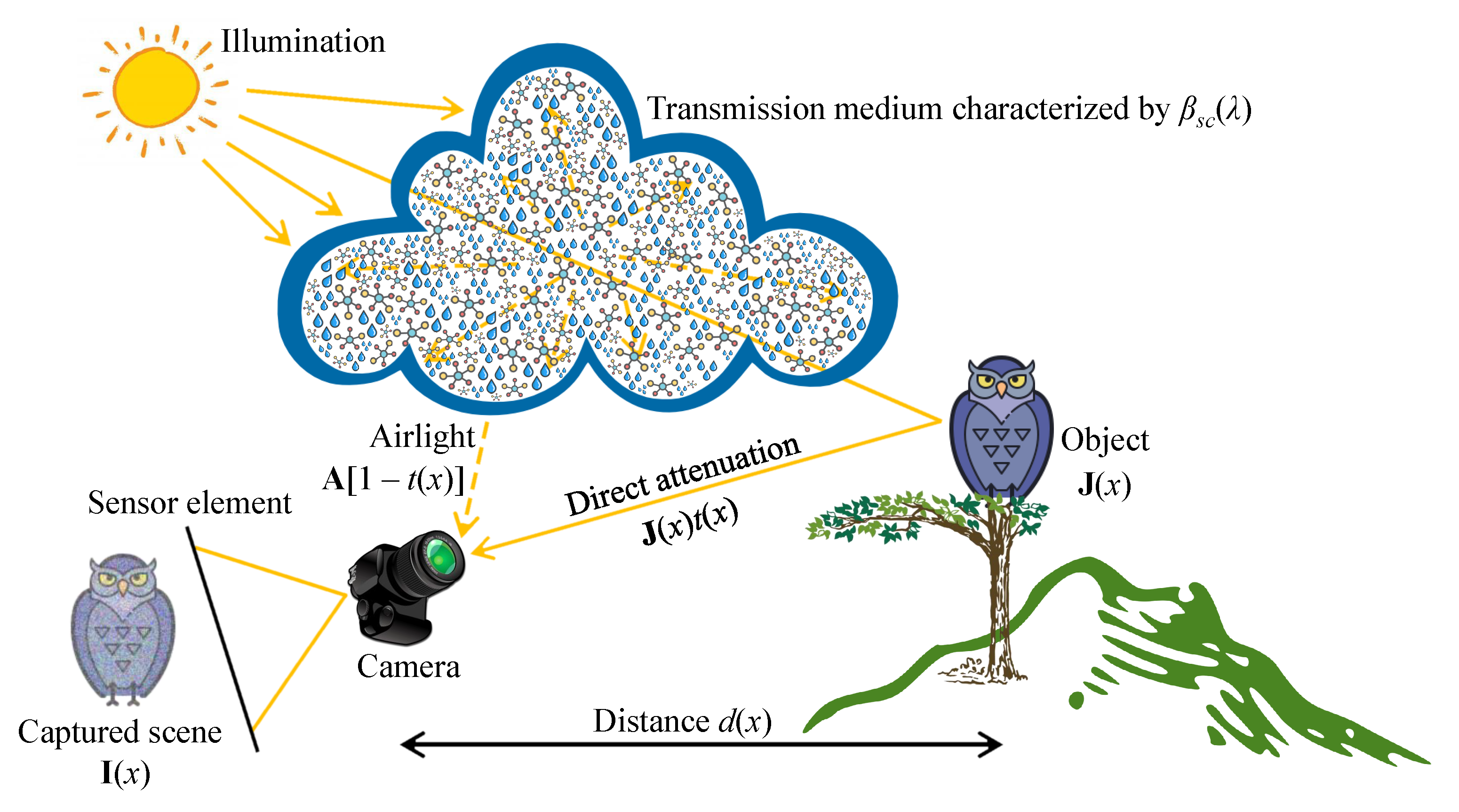
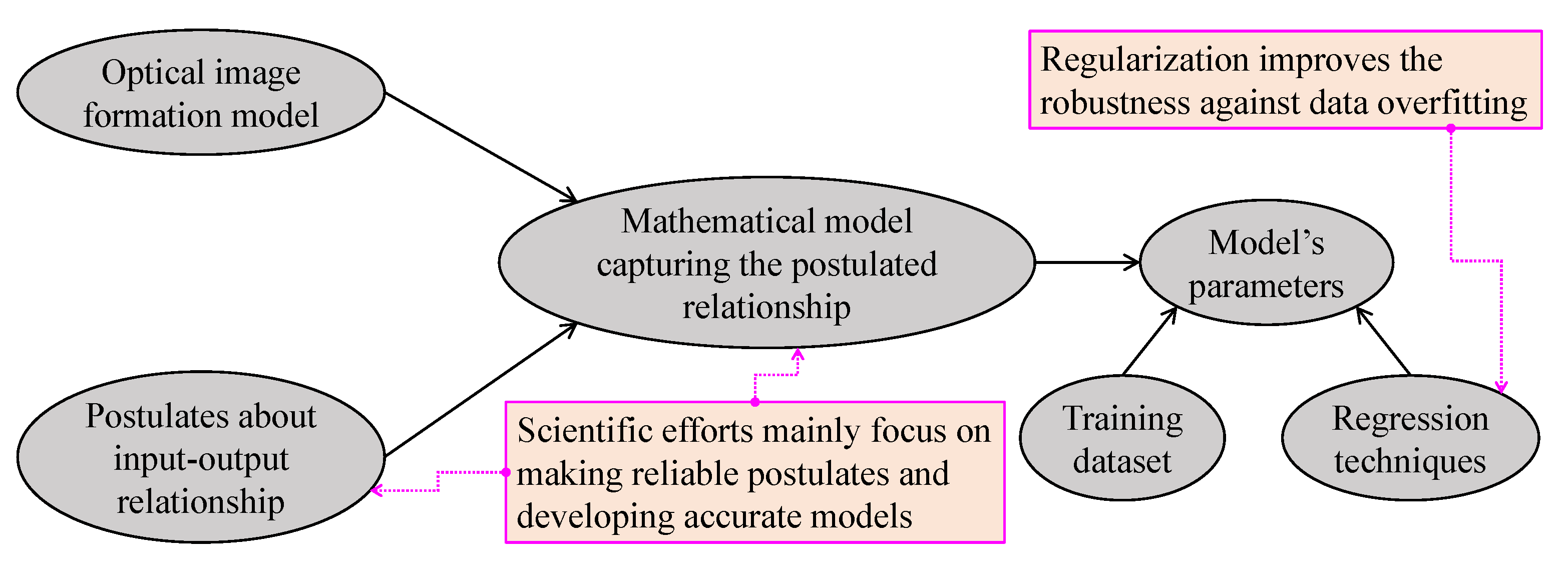
2.2. Optical Image Formation
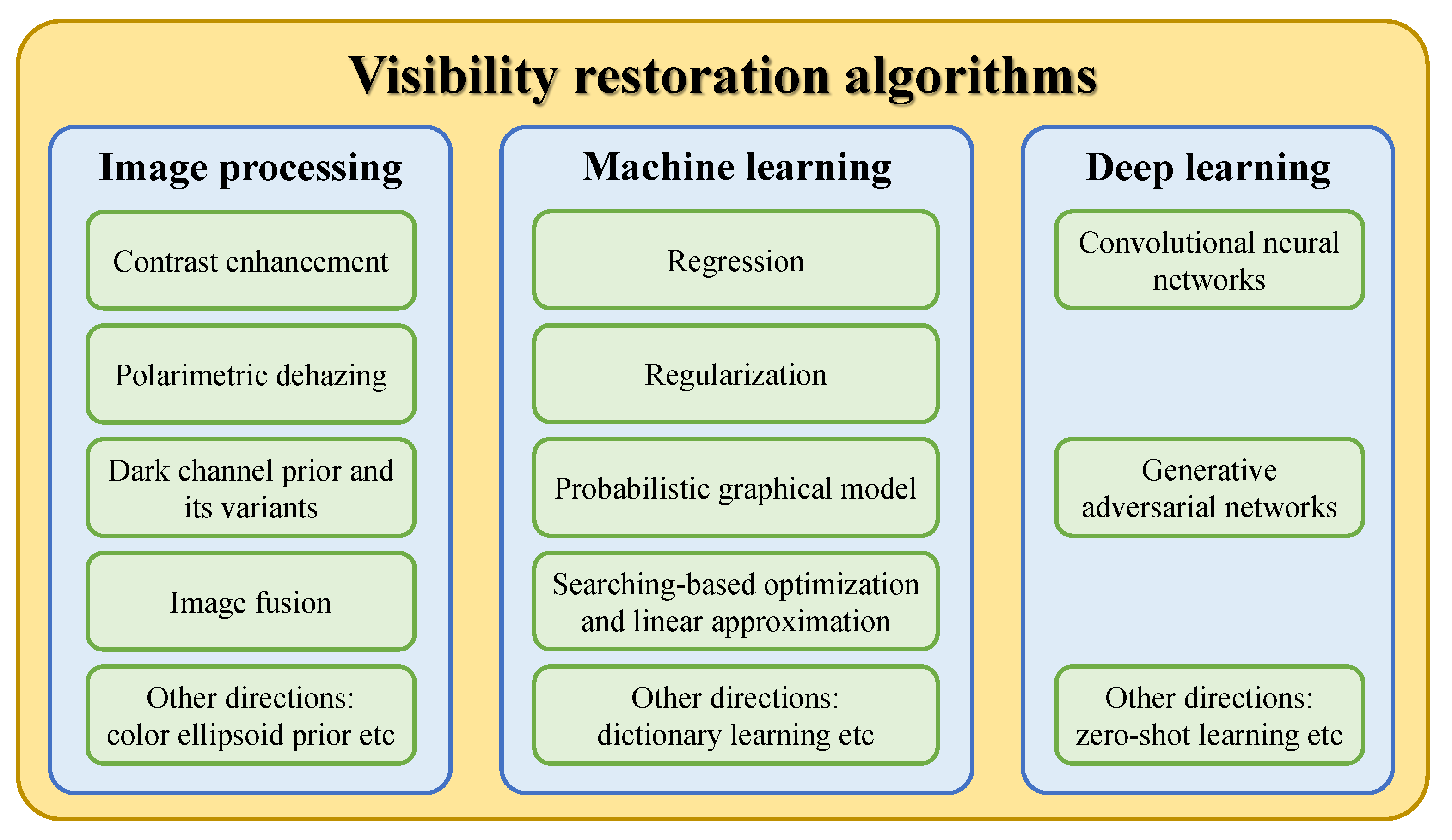
2.3. General Classification
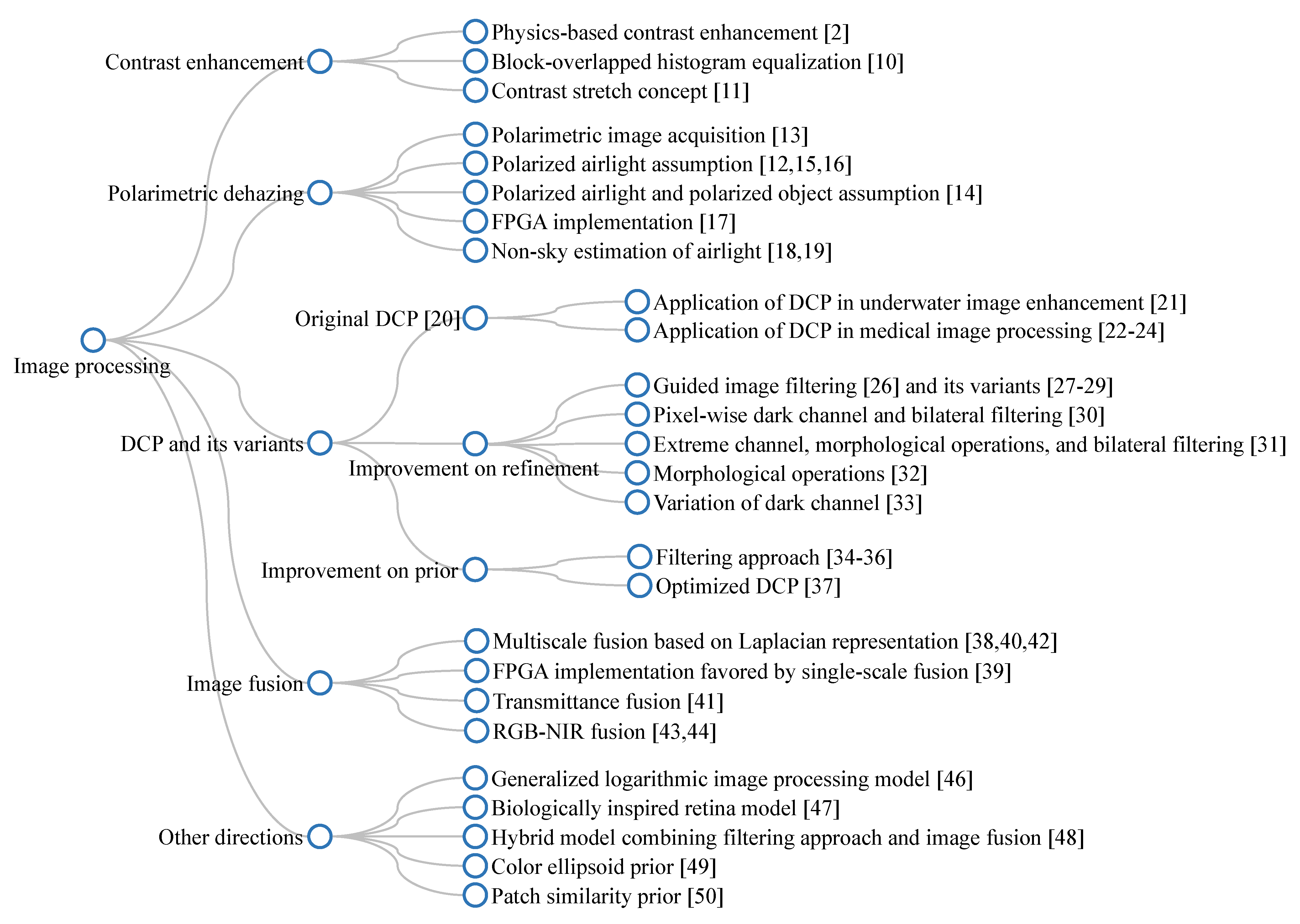
2.3.1. Image Processing
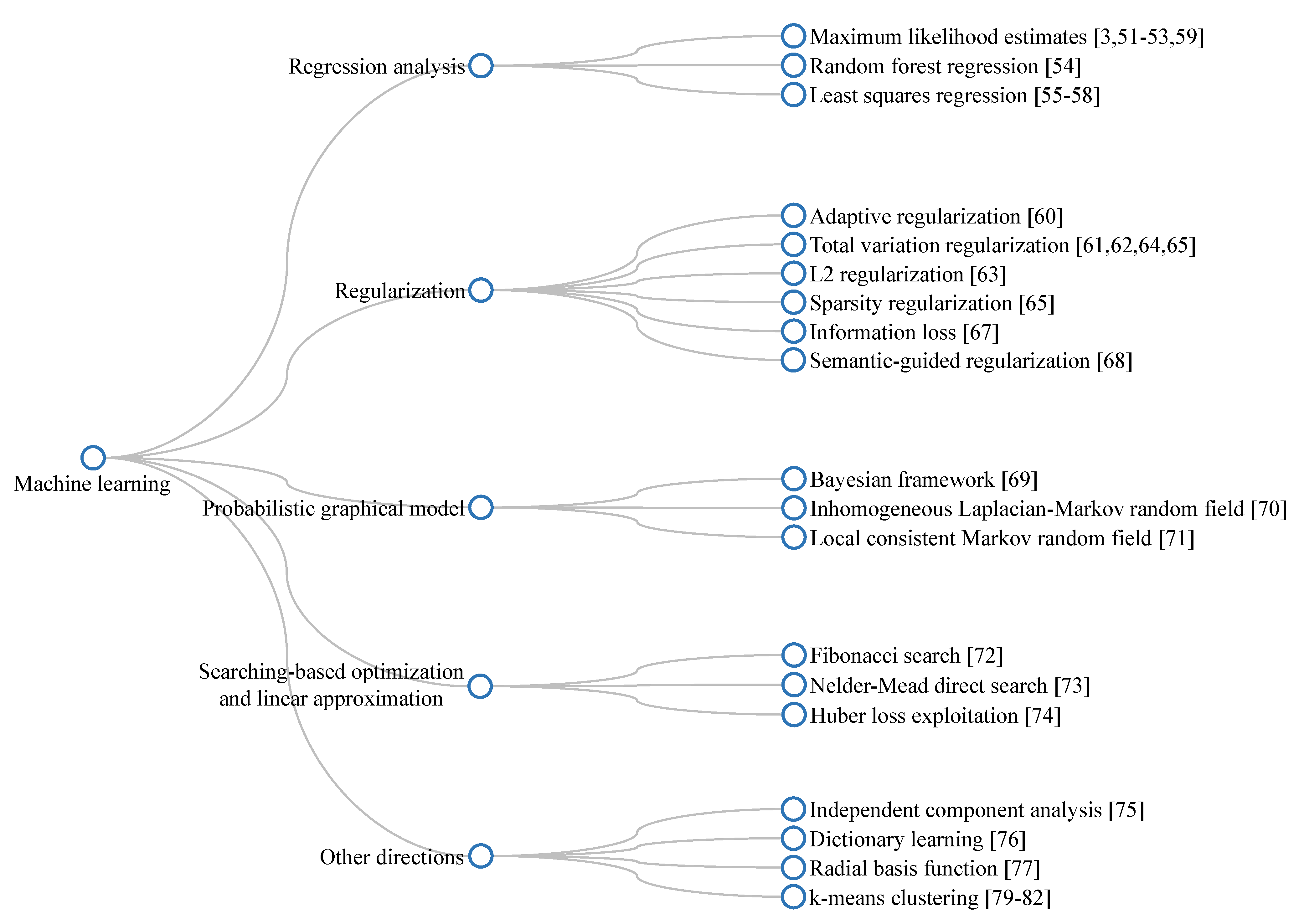
2.3.2. Machine Learning
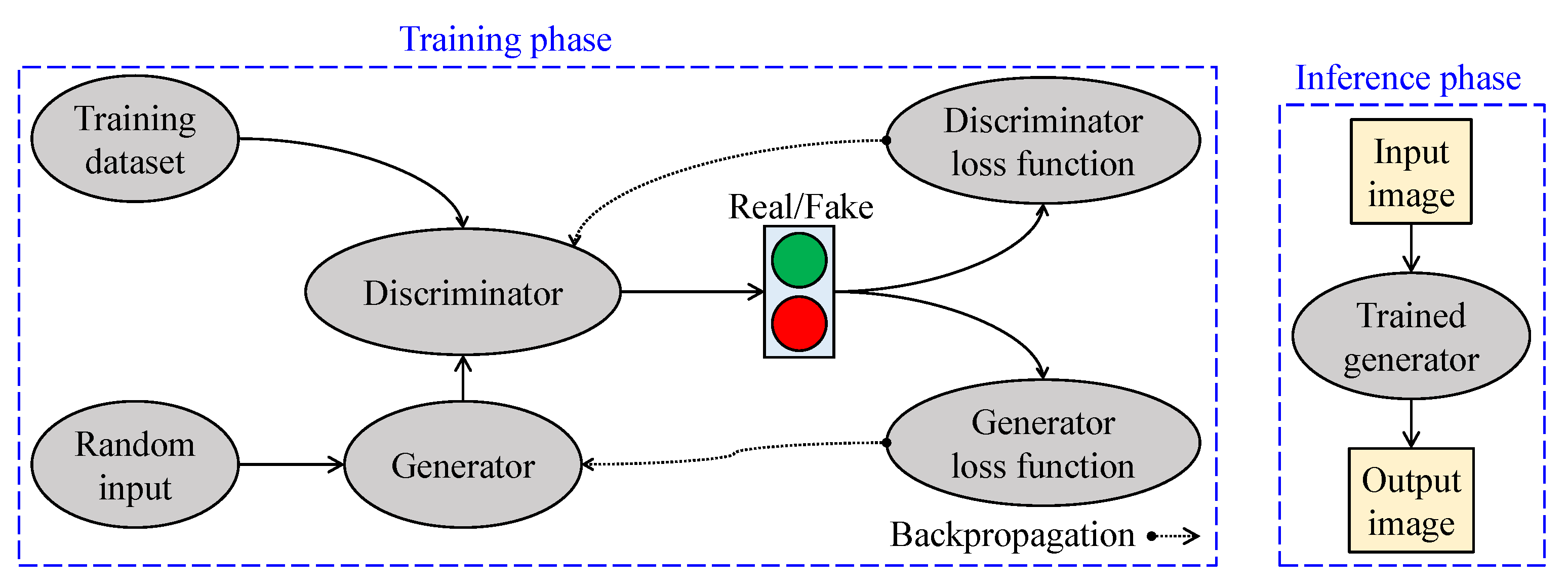
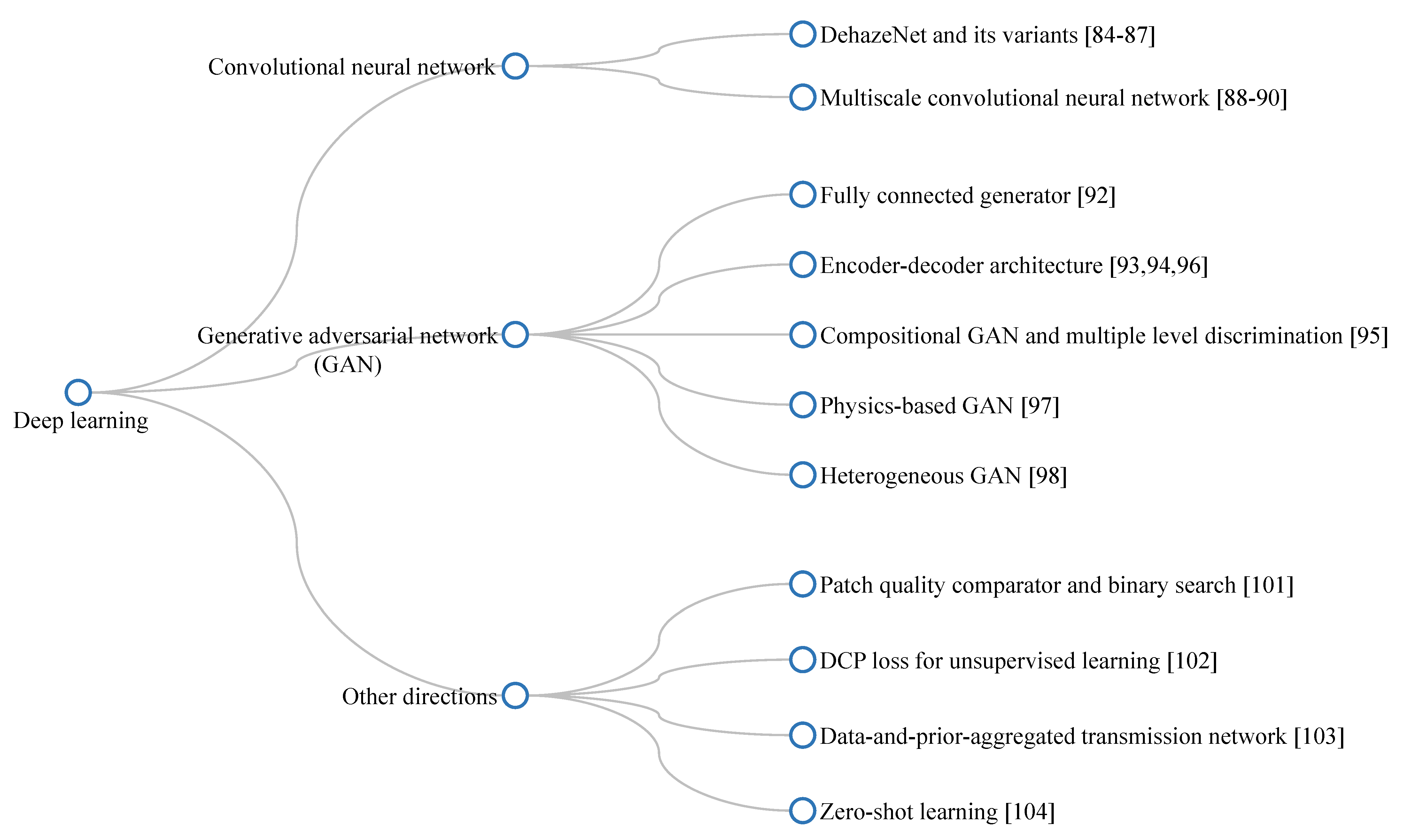
2.3.3. Deep Learning
3. Current Difficulties
3.1. Real-Time Processing
3.2. Training Dataset
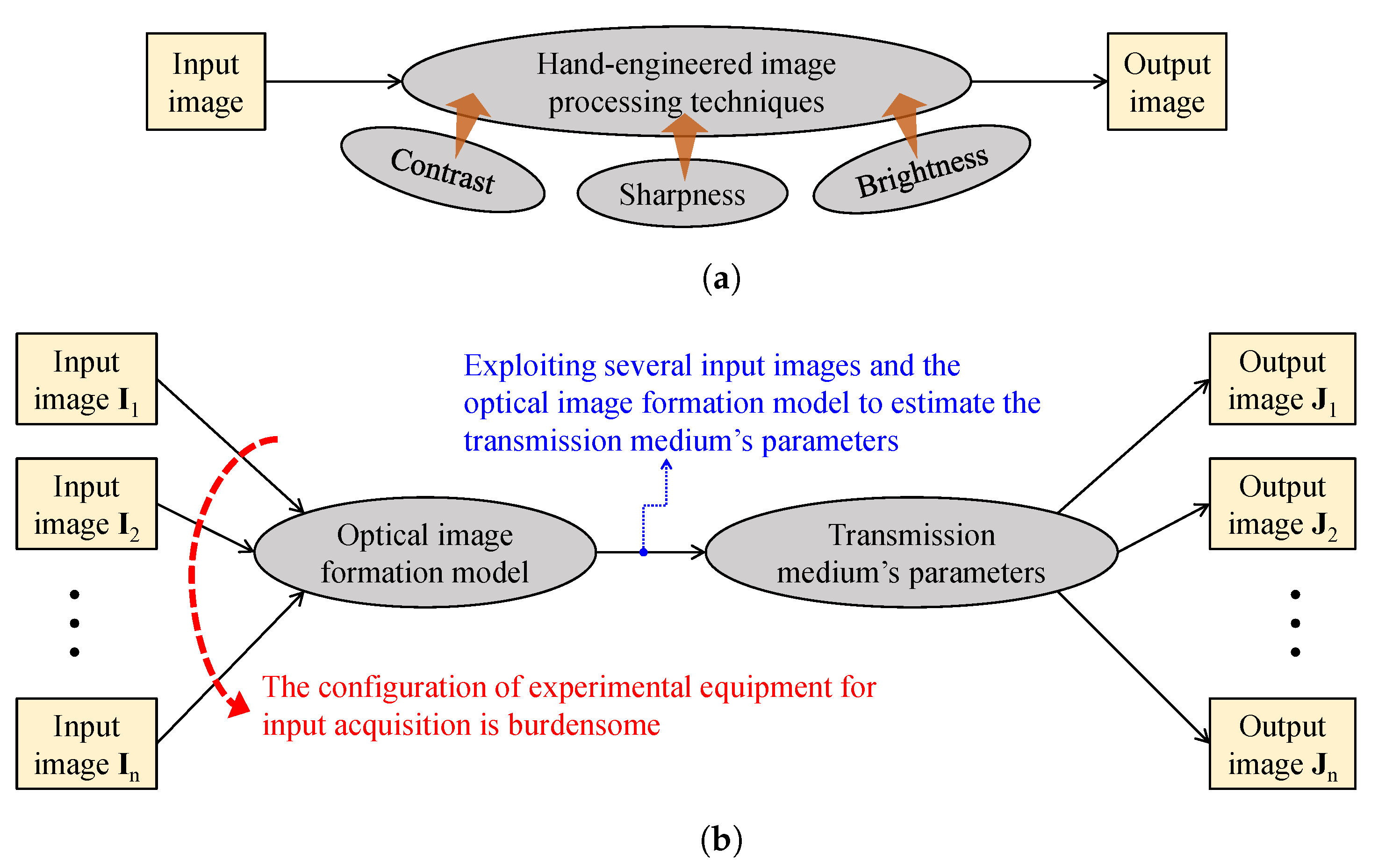
3.3. Image Formation Model
4. Proposed Dehazing Framework
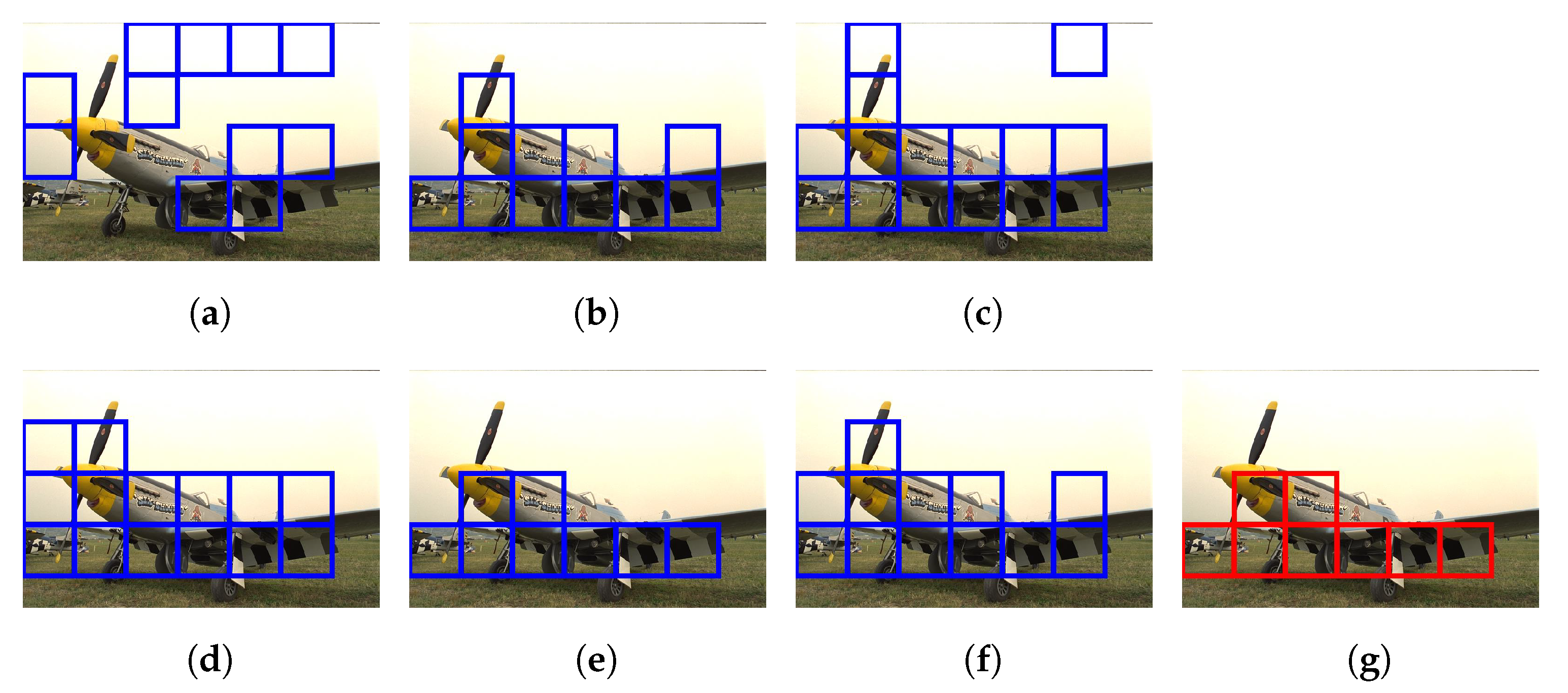
4.1. Data Cleaning Based on Haze-Relevant Features
4.2. Scene Depth Estimation
| Algorithm 1 Mini-batch gradient ascent. |
1: Initialization , , and are initialized with random values drawn from 2: while do 3: 4: while do 5: if then 6: 7: 8: 9: check for termination 10: else 11: 12: 13: 14: check for termination 15: end if 16: 17: end while 18: 19: end while |
4.3. Atmospheric Light Estimation
4.4. Evaluation with State-of-the-Art Methods
4.4.1. Employed Datasets
4.4.2. Qualitative Evaluation
4.4.3. Quantitative Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| PRISMA | Preferred Reporting Items for Systematic Reviews and Meta-Analyses |
| A/D | Analog-to-Digital |
| RGB | Red-Green-Blue |
| FPGA | Field-Programmable Gate Array |
| DCP | Dark Channel Prior |
| GIF | Guided Image Filter |
| WGIF | Weighted Guided Image Filter |
| G-GIF | Globally Guided Image Filter |
| NIR | Near-Infrared |
| HDR | High Dynamic Range |
| GLIP | Generalized Logarithmic Image Processing |
| CEP | Color Ellipsoid Prior |
| MLE | Maximum Likelihood Estimates |
| IQA | Image Quality Assessment |
| TV | Total Variation |
| MRF | Markov Random Field |
| CNN | Convolutional Neural Network |
| MSE | Mean Squared Error |
| GAN | Generative Adversarial Network |
| fps | Frames Per Second |
| CycleGAN | Cycle Consistent Generative Adversarial Network |
| cGAN | Conditional Generative Adversarial Network |
| DPATN | Data-and-Prior-Aggregated Transmission Network |
| ATR | Adaptive Tone Remapping |
References
- Parulski, K.; Spaulding, K. Color image processing for digital cameras. In Digital Color Imaging Handbook; Sharma, G., Ed.; CRC Press: Boca Raton, FL, USA, 2003; Chapter 12; pp. 734–739. [Google Scholar]
- Oakley, J.P.; Satherley, B.L. Improving image quality in poor visibility conditions using a physical model for contrast degradation. IEEE Trans. Image Process. 1998, 7, 167–179. [Google Scholar] [CrossRef]
- Tan, K.K.; Oakley, J.P. Physics-based approach to color image enhancement in poor visibility conditions. J. Opt. Soc. Am. A Opt. Image Sci. Vis. 2001, 18, 2460–2467. [Google Scholar] [CrossRef]
- Liu, Z.; He, Y.; Wang, C.; Song, R. Analysis of the Influence of Foggy Weather Environment on the Detection Effect of Machine Vision Obstacles. Sensors 2020, 20, 349. [Google Scholar] [CrossRef] [Green Version]
- Pei, Y.; Huang, Y.; Zou, Q.; Zhang, X.; Wang, S. Effects of Image Degradation and Degradation Removal to CNN-based Image Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking Single Image Dehazing and Beyond. IEEE Trans. Image Process. 2019, 28, 492–505. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, W.; Yuan, Y.; Ren, W.; Liu, J.; Scheirer, W.J.; Wang, Z.; Zhang, T.; Zhong, Q.; Xie, D.; Pu, S.; et al. Advancing Image Understanding in Poor Visibility Environments: A Collective Benchmark Study. IEEE Trans. Image Process. 2020, 29, 5737–5752. [Google Scholar] [CrossRef] [PubMed]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; Group, T.P. Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. PLoS Med. 2009, 6, e1000097. [Google Scholar] [CrossRef] [Green Version]
- Byron, C.W.; Kevin, S.; Carla, E.B.; Joseph, L.; Thomas, A.T. Deploying an interactive machine learning system in an evidence-based practice center: Abstrackr. In Proceedings of the 2nd ACM SIGHIT International Health Informatics Symposium (IHI), Miami, FL, USA, 28–30 January 2012; pp. 819–824. [Google Scholar] [CrossRef]
- Grossberg, M.D.; Nayar, S.K. What is the space of camera response functions? In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; p. II–602. [Google Scholar] [CrossRef] [Green Version]
- Kim, T.K.; Paik, J.K.; Kang, B.S. Contrast enhancement system using spatially adaptive histogram equalization with temporal filtering. IEEE Trans. Consum. Electron. 1998, 44, 82–87. [Google Scholar] [CrossRef]
- Kim, S.E.; Park, T.H.; Eom, I.K. Fast Single Image Dehazing Using Saturation Based Transmission Map Estimation. IEEE Trans. Image Process. 2020, 29, 1985–1998. [Google Scholar] [CrossRef]
- Schechner, Y.Y.; Narasimhan, S.G.; Nayar, S.K. Polarization-based vision through haze. Appl. Opt. 2003, 42, 511–525. [Google Scholar] [CrossRef] [PubMed]
- Fade, J.; Panigrahi, S.; Carré, A.; Frein, L.; Hamel, C.; Bretenaker, F.; Ramachandran, H.; Alouini, M. Long-range polarimetric imaging through fog. Appl. Opt. 2014, 53, 3854–3865. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fang, S.; Xia, X.; Xing, H.; Chen, C. Image dehazing using polarization effects of objects and airlight. Opt. Express 2014, 22, 19523–19537. [Google Scholar] [CrossRef] [PubMed]
- Liang, J.; Ren, L.; Ju, H.; Zhang, W.; Qu, E. Polarimetric dehazing method for dense haze removal based on distribution analysis of angle of polarization. Opt. Express 2015, 23, 26146–26157. [Google Scholar] [CrossRef]
- Liu, F.; Cao, L.; Shao, X.; Han, P.; Bin, X. Polarimetric dehazing utilizing spatial frequency segregation of images. Appl. Opt. 2015, 54, 8116–8122. [Google Scholar] [CrossRef]
- Zhang, W.; Liang, J.; Ren, L.; Ju, H.; Qu, E.; Bai, Z.; Tang, Y.; Wu, Z. Real-time image haze removal using an aperture-division polarimetric camera. Appl. Opt. 2017, 56, 942–947. [Google Scholar] [CrossRef]
- Qu, Y.; Zou, Z. Non-sky polarization-based dehazing algorithm for non-specular objects using polarization difference and global scene feature. Opt. Express 2017, 25, 25004–25022. [Google Scholar] [CrossRef]
- Liang, J.; Ju, H.; Ren, L.; Yang, L.; Liang, R. Generalized Polarimetric Dehazing Method Based on Low-Pass Filtering in Frequency Domain. Sensors 2020, 20, 1729. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar] [CrossRef]
- Chiang, J.Y.; Chen, Y.C. Underwater image enhancement by wavelength compensation and dehazing. IEEE Trans. Image Process. 2012, 21, 1756–1769. [Google Scholar] [CrossRef]
- Gu, L.; Liu, P.; Jiang, C.; Luo, M.; Xu, Q. Virtual digital defogging technology improves laparoscopic imaging quality. Surg. Innov. 2015, 22, 171–176. [Google Scholar] [CrossRef]
- Wang, Q.; Zhu, Y.; Li, H. Imaging model for the scintillator and its application to digital radiography image enhancement. Opt. Express 2015, 23, 33753–33776. [Google Scholar] [CrossRef]
- Ruiz-Fernández, D.; Galiana-Merino, J.J.; de Ramón-Fernández, A.; Vives-Boix, V.; Enríquez-Buendía, P. A DCP-based Method for Improving Laparoscopic Images. J. Med. Syst. 2020, 44, 78. [Google Scholar] [CrossRef]
- Levin, A.; Lischinski, D.; Weiss, Y. A Closed-Form Solution to Natural Image Matting. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 228–242. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1397–1409. [Google Scholar] [CrossRef]
- Li, Z.; Zheng, J.; Zhu, Z.; Yao, W.; Wu, S. Weighted guided image filtering. IEEE Trans. Image Process. 2015, 24, 120–129. [Google Scholar] [CrossRef]
- Li, Z.; Zheng, J. Single Image De-Hazing Using Globally Guided Image Filtering. IEEE Trans. Image Process. 2018, 27, 442–450. [Google Scholar] [CrossRef]
- Sun, Z.; Han, B.; Li, J.; Zhang, J.; Gao, X. Weighted Guided Image Filtering with Steering Kernel. IEEE Trans. Image Process. 2020, 29, 500–508. [Google Scholar] [CrossRef] [PubMed]
- Yeh, C.H.; Kang, L.W.; Lee, M.S.; Lin, C.Y. Haze effect removal from image via haze density estimation in optical model. Opt. Express 2013, 21, 27127–27141. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.; Wang, H.; Sun, C.; Guo, B.; Jia, W.; Sun, M. Fast single image haze removal via local atmospheric light veil estimation. Comput. Electr. Eng. 2015, 46, 371–383. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Salazar-Colores, S.; Cabal-Yepez, E.; Ramos-Arreguin, J.M.; Botella, G.; Ledesma-Carrillo, L.M.; Ledesma, S. A Fast Image Dehazing Algorithm Using Morphological Reconstruction. IEEE Trans. Image Process. 2019, 28, 2357–2366. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Zheng, J. Edge-Preserving Decomposition-Based Single Image Haze Removal. IEEE Trans. Image Process. 2015, 24, 5432–5441. [Google Scholar] [CrossRef] [PubMed]
- Tarel, J.; Hautière, N. Fast visibility restoration from a single color or gray level image. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2201–2208. [Google Scholar] [CrossRef]
- Kim, G.J.; Lee, S.; Kang, B. Single Image Haze Removal Using Hazy Particle Maps. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2018, 101, 1999–2002. [Google Scholar] [CrossRef]
- Gibson, K.B.; Vo, D.T.; Nguyen, T.Q. An investigation of dehazing effects on image and video coding. IEEE Trans. Image Process. 2012, 21, 662–673. [Google Scholar] [CrossRef] [PubMed]
- Amer, K.O.; Elbouz, M.; Alfalou, A.; Brosseau, C.; Hajjami, J. Enhancing underwater optical imaging by using a low-pass polarization filter. Opt. Express 2019, 27, 621–643. [Google Scholar] [CrossRef] [PubMed]
- Ancuti, C.O.; Ancuti, C. Single image dehazing by multi-scale fusion. IEEE Trans. Image Process. 2013, 22, 3271–3282. [Google Scholar] [CrossRef]
- Ngo, D.; Lee, S.; Nguyen, Q.H.; Ngo, T.M.; Lee, G.D.; Kang, B. Single Image Haze Removal from Image Enhancement Perspective for Real-Time Vision-Based Systems. Sensors 2020, 20, 5170. [Google Scholar] [CrossRef]
- Choi, L.K.; You, J.; Bovik, A.C. Referenceless Prediction of Perceptual Fog Density and Perceptual Image Defogging. IEEE Trans. Image Process. 2015, 24, 3888–3901. [Google Scholar] [CrossRef]
- Guo, J.M.; Syue, J.Y.; Radzicki, V.R.; Lee, H. An Efficient Fusion-Based Defogging. IEEE Trans. Image Process. 2017, 26, 4217–4228. [Google Scholar] [CrossRef]
- Ancuti, C.; Ancuti, C.O.; De Vleeschouwer, C.; Bovik, A.C. Day and Night-Time Dehazing by Local Airlight Estimation. IEEE Trans. Image Process. 2020, 29, 6264–6275. [Google Scholar] [CrossRef]
- Liang, J.; Zhang, W.; Ren, L.; Ju, H.; Qu, E. Polarimetric dehazing method for visibility improvement based on visible and infrared image fusion. Appl. Opt. 2016, 55, 8221–8226. [Google Scholar] [CrossRef]
- Zhou, Z.; Dong, M.; Xie, X.; Gao, Z. Fusion of infrared and visible images for night-vision context enhancement. Appl. Opt. 2016, 55, 6480–6490. [Google Scholar] [CrossRef] [PubMed]
- Jee, S.; Kang, M.G. Sensitivity Improvement of Extremely Low Light Scenes with RGB-NIR Multispectral Filter Array Sensor. Sensors 2019, 19, 1256. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deng, G. A generalized logarithmic image processing model based on the gigavision sensor model. IEEE Trans. Image Process. 2012, 21, 1406–1414. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.S.; Gao, S.B.; Li, C.Y.; Li, Y.J. A Retina Inspired Model for Enhancing Visibility of Hazy Images. Front. Comput. Neurosci. 2015, 9, 151. [Google Scholar] [CrossRef] [PubMed]
- Luo, X.; McLeod, A.J.; Pautler, S.E.; Schlachta, C.M.; Peters, T.M. Vision-Based Surgical Field Defogging. IEEE Trans. Med. Imaging 2017, 36, 2021–2030. [Google Scholar] [CrossRef]
- Bui, T.M.; Kim, W. Single Image Dehazing Using Color Ellipsoid Prior. IEEE Trans. Image Process. 2018, 27, 999–1009. [Google Scholar] [CrossRef] [PubMed]
- Mandal, S.; Rajagopalan, A.N. Local Proximity for Enhanced Visibility in Haze. IEEE Trans. Image Process. 2020, 29, 2478–2491. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Q.; Mai, J.; Shao, L. A Fast Single Image Haze Removal Algorithm Using Color Attenuation Prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [CrossRef] [Green Version]
- Ngo, D.; Lee, G.D.; Kang, B. Improved Color Attenuation Prior for Single-Image Haze Removal. Appl. Sci. 2019, 9, 4011. [Google Scholar] [CrossRef] [Green Version]
- Ngo, D.; Lee, S.; Lee, G.D.; Kang, B. Single-Image Visibility Restoration: A Machine Learning Approach and Its 4K-Capable Hardware Accelerator. Sensors 2020, 20, 5795. [Google Scholar] [CrossRef]
- Tang, K.; Yang, J.; Wang, J. Investigating Haze-Relevant Features in a Learning Framework for Image Dehazing. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2995–3002. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Sun, C.; Zhao, Y.; Yang, L. Fog Density Estimation and Image Defogging Based on Surrogate Modeling for Optical Depth. IEEE Trans. Image Process. 2017, 26, 3397–3409. [Google Scholar] [CrossRef]
- Lee, Y.; Hirakawa, K.; Nguyen, T.Q. Joint Defogging and Demosaicking. IEEE Trans. Image Process. 2017, 26, 3051–3063. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gu, K.; Tao, D.; Qiao, J.F.; Lin, W. Learning a No-Reference Quality Assessment Model of Enhanced Images With Big Data. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 1301–1313. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peng, Y.T.; Cao, K.; Cosman, P.C. Generalization of the Dark Channel Prior for Single Image Restoration. IEEE Trans. Image Process. 2018, 27, 2856–2868. [Google Scholar] [CrossRef] [PubMed]
- Raikwar, S.C.; Tapaswi, S. Lower bound on Transmission using Non-Linear Bounding Function in Single Image Dehazing. IEEE Trans. Image Process. 2020. [Google Scholar] [CrossRef]
- Schechner, Y.Y.; Averbuch, Y. Regularized image recovery in scattering media. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1655–1660. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, C.Y.; Guo, J.C.; Cong, R.M.; Pang, Y.W.; Wang, B. Underwater Image Enhancement by Dehazing With Minimum Information Loss and Histogram Distribution Prior. IEEE Trans. Image Process. 2016, 25, 5664–5677. [Google Scholar] [CrossRef]
- Kim, H.; Park, J.; Park, H.; Paik, J. Iterative Refinement of Transmission Map for Stereo Image Defogging Using a Dual Camera Sensor. Sensors 2017, 17, 2861. [Google Scholar] [CrossRef] [Green Version]
- Son, C.H.; Zhang, X.P. Near-Infrared Coloring via a Contrast-Preserving Mapping Model. IEEE Trans. Image Process. 2017, 26, 5381–5394. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Liu, J.; Yang, W.; Sun, X.; Guo, Z. Structure-Revealing Low-Light Image Enhancement Via Robust Retinex Model. IEEE Trans. Image Process. 2018, 27, 2828–2841. [Google Scholar] [CrossRef]
- Liu, Q.; Gao, X.; He, L.; Lu, W. Single Image Dehazing With Depth-aware Non-local Total Variation Regularization. IEEE Trans. Image Process. 2018, 27, 5178–5191. [Google Scholar] [CrossRef] [PubMed]
- Pan, J.; Sun, D.; Pfister, H.; Yang, M.H. Deblurring Images via Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2315–2328. [Google Scholar] [CrossRef]
- Dong, T.; Zhao, G.; Wu, J.; Ye, Y.; Shen, Y. Efficient Traffic Video Dehazing Using Adaptive Dark Channel Prior and Spatial-Temporal Correlations. Sensors 2019, 19, 1593. [Google Scholar] [CrossRef] [Green Version]
- Wu, Q.; Zhang, J.; Ren, W.; Zuo, W.; Cao, X. Accurate Transmission Estimation for Removing Haze and Noise from a Single Image. IEEE Trans. Image Process. 2020, 29, 2583–2597. [Google Scholar] [CrossRef] [PubMed]
- Nan, D.; Bi, D.Y.; Liu, C.; Ma, S.P.; He, L.Y. A Bayesian framework for single image dehazing considering noise. Sci. World J. 2014, 2014, 651986. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.K.; Fan, C.T. Single image defogging by multiscale depth fusion. IEEE Trans. Image Process. 2014, 23, 4826–4837. [Google Scholar] [CrossRef]
- Qu, C.; Bi, D.Y.; Sui, P.; Chao, A.N.; Wang, Y.F. Robust Dehaze Algorithm for Degraded Image of CMOS Image Sensors. Sensors 2017, 17, 2175. [Google Scholar] [CrossRef] [Green Version]
- Ju, M.; Ding, C.; Guo, Y.J.; Zhang, D. IDGCP: Image Dehazing Based on Gamma Correction Prior. IEEE Trans. Image Process. 2020, 29, 3104–3118. [Google Scholar] [CrossRef]
- Ngo, D.; Lee, S.; Kang, B. Robust Single-Image Haze Removal Using Optimal Transmission Map and Adaptive Atmospheric Light. Remote Sens. 2020, 12, 2233. [Google Scholar] [CrossRef]
- Wang, W.; Li, Z.; Wu, S.; Zeng, L. Hazy Image Decolorization with Color Contrast Restoration. IEEE Trans. Image Process. 2020, 29, 1776–1787. [Google Scholar] [CrossRef]
- Namer, E.; Shwartz, S.; Schechner, Y.Y. Skyless polarimetric calibration and visibility enhancement. Opt. Express 2009, 17, 472–493. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, L.; Zhao, J.; Zheng, N.; Bi, D. Haze Removal Using the Difference- Structure-Preservation Prior. IEEE Trans. Image Process. 2017, 26, 1063–1075. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.H.; Huang, S.C.; Li, C.Y.; Kuo, S.Y. Haze Removal Using Radial Basis Function Networks for Visibility Restoration Applications. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3828–3838. [Google Scholar] [CrossRef] [PubMed]
- Yuan, F.; Huang, H. Image Haze Removal via Reference Retrieval and Scene Prior. IEEE Trans. Image Process. 2018, 27, 4395–4409. [Google Scholar] [CrossRef]
- Berman, D.; Treibitz, T.; Avidan, S. Single Image Dehazing Using Haze-Lines. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 720–734. [Google Scholar] [CrossRef] [PubMed]
- Berman, D.; Levy, D.; Avidan, S.; Treibitz, T. Underwater Single Image Color Restoration Using Haze-Lines and a New Quantitative Dataset. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [Green Version]
- Hu, H.M.; Guo, Q.; Zheng, J.; Wang, H.; Li, B. Single Image Defogging Based on Illumination Decomposition for Visual Maritime Surveillance. IEEE Trans. Image Process. 2019, 28, 2882–2897. [Google Scholar] [CrossRef]
- Afridi, I.U.; Bashir, T.; Khattak, H.A.; Khan, T.M.; Imran, M. Degraded image enhancement by image dehazing and Directional Filter Banks using Depth Image based Rendering for future free-view 3D-TV. PLoS ONE 2019, 14, e0217246. [Google Scholar] [CrossRef] [Green Version]
- Matsugu, M.; Mori, K.; Mitari, Y.; Kaneda, Y. Subject independent facial expression recognition with robust face detection using a convolutional neural network. Neural Netw. 2003, 16, 555–559. [Google Scholar] [CrossRef]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. DehazeNet: An End-to-End System for Single Image Haze Removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [Green Version]
- Wang, A.; Wang, W.; Liu, J.; Gu, N. AIPNet: Image-to-Image Single Image Dehazing with Atmospheric Illumination Prior. IEEE Trans. Image Process. 2019, 28, 381–393. [Google Scholar] [CrossRef]
- Dudhane, A.; Murala, S. RYF-Net: Deep Fusion Network for Single Image Haze Removal. IEEE Trans. Image Process. 2020, 29, 628–640. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.C.; Le, T.H.; Jaw, D.W. DSNet: Joint Semantic Learning for Object Detection in Inclement Weather Conditions. IEEE Trans. Pattern Ana.l Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.H. Single Image Dehazing via Multi-scale Convolutional Neural Networks. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 154–169. [Google Scholar] [CrossRef]
- Ren, W.; Pan, J.; Zhang, H.; Cao, X.; Yang, M.H. Single Image Dehazing via Multi-scale Convolutional Neural Networks with Holistic Edges. Int. J. Comput. Vis. 2020, 128, 240–259. [Google Scholar] [CrossRef]
- Yeh, C.H.; Huang, C.H.; Kang, L.W. Multi-Scale Deep Residual Learning-Based Single Image Haze Removal via Image Decomposition. IEEE Trans. Image Process. 2020, 29, 3153–3167. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 2, pp. 2672–2680. [Google Scholar]
- Liu, K.; He, L.; Ma, S.; Gao, S.; Bi, D. A Sensor Image Dehazing Algorithm Based on Feature Learning. Sensors 2018, 18, 2606. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ren, W.; Zhang, J.; Xu, X.; Ma, L.; Cao, X.; Meng, G.; Liu, W. Deep Video Dehazing with Semantic Segmentation. IEEE Trans. Image Process. 2019, 28, 1895–1908. [Google Scholar] [CrossRef]
- Li, L.; Dong, Y.; Ren, W.; Pan, J.; Gao, C.; Sang, N.; Yang, M.H. Semi-Supervised Image Dehazing. IEEE Trans. Image Process. 2020, 29, 2766–2779. [Google Scholar] [CrossRef]
- Zhu, H.; Cheng, Y.; Peng, X.; Zhou, J.T.; Kang, Z.; Lu, S.; Fang, Z.; Li, L.; Lim, J.H. Single-Image Dehazing via Compositional Adversarial Network. IEEE Trans. Cybern. 2019. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Pan, J.; He, M.; Li, Z.; Tang, J. Task-Oriented Network for Image Dehazing. IEEE Trans. Image Process. 2020, 29, 6523–6534. [Google Scholar] [CrossRef] [PubMed]
- Pan, J.; Dong, J.; Liu, Y.; Zhang, J.; Ren, J.; Tang, J.; Tai, Y.W.; Yang, M.H. Physics-Based Generative Adversarial Models for Image Restoration and Beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [Green Version]
- Park, J.; Han, D.K.; Ko, H. Fusion of Heterogeneous Adversarial Networks for Single Image Dehazing. IEEE Trans. Image Process. 2020, 29, 4721–4732. [Google Scholar] [CrossRef]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef] [Green Version]
- Sohn, K.; Yan, X.; Lee, H. Learning structured output representation using deep conditional generative models. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 2, pp. 3483–3491. [Google Scholar]
- Santra, S.; Mondal, R.; Chanda, B. Learning a Patch Quality Comparator for Single Image Dehazing. IEEE Trans. Image Process. 2018, 27, 4598–4607. [Google Scholar] [CrossRef]
- Golts, A.; Freedman, D.; Elad, M. Unsupervised Single Image Dehazing Using Dark Channel Prior Loss. IEEE Trans. Image Process. 2019, 29, 2692–2701. [Google Scholar] [CrossRef] [Green Version]
- Liu, R.; Fan, X.; Hou, M.; Jiang, Z.; Luo, Z.; Zhang, L. Learning Aggregated Transmission Propagation Networks for Haze Removal and Beyond. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2973–2986. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, B.; Gou, Y.; Liu, J.Z.; Zhu, H.; Zhou, J.T.; Peng, X. Zero-Shot Image Dehazing. IEEE Trans. Image Process. 2020, 29, 8457–8466. [Google Scholar] [CrossRef] [PubMed]
- Shiau, Y.; Yang, H.; Chen, P.; Chuang, Y. Hardware Implementation of a Fast and Efficient Haze Removal Method. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 1369–1374. [Google Scholar] [CrossRef]
- Zhang, B.; Zhao, J. Hardware Implementation for Real-Time Haze Removal. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2017, 25, 1188–1192. [Google Scholar] [CrossRef]
- Ngo, D.; Lee, G.D.; Kang, B. A 4K-Capable FPGA Implementation of Single Image Haze Removal Using Hazy Particle Maps. Appl. Sci. 2019, 9, 3443. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks. IEEE J. Solid-State Circuits 2017, 52, 127–138. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Yang, T.; Emer, J.; Sze, V. Eyeriss v2: A Flexible Accelerator for Emerging Deep Neural Networks on Mobile Devices. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 292–308. [Google Scholar] [CrossRef] [Green Version]
- Venieris, S.I.; Bouganis, C. fpgaConvNet: Mapping Regular and Irregular Convolutional Neural Networks on FPGAs. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 326–342. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, C.; Sun, G.; Fang, Z.; Zhou, P.; Pan, P.; Cong, J. Caffeine: Toward Uniformed Representation and Acceleration for Deep Convolutional Neural Networks. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2019, 38, 2072–2085. [Google Scholar] [CrossRef]
- Ghaffari, A.; Savaria, Y. CNN2Gate: An Implementation of Convolutional Neural Networks Inference on FPGAs with Automated Design Space Exploration. Electronics 2020, 9, 2200. [Google Scholar] [CrossRef]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In European Conference on Computer Vision, Proceedings of the 2012 European Conference on Computer Vision ECCV, Florence, Italy, 7–13 October 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; pp. 746–760. [Google Scholar] [CrossRef]
- Ancuti, C.O.; Ancuti, C.; Timofte, R.; Vleeschouwer, C.D. O-HAZE: A Dehazing Benchmark with Real Hazy and Haze-Free Outdoor Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 867–8678. [Google Scholar] [CrossRef] [Green Version]
- Ancuti, C.; Ancuti, C.O.; Timofte, R.; Vleeschouwer, C.D. I-HAZE: A dehazing benchmark with real hazy and haze-free indoor images. In Advanced Concepts for Intelligent Vision Systems; Blanc-Talon, J., Helbert, D., Philips, W., Popescu, D., Scheunders, P., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 620–631. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; Sbert, M.; Timofte, R. Dense-Haze: A Benchmark for Image Dehazing with Dense-Haze and Haze-Free Images. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1014–1018. [Google Scholar] [CrossRef] [Green Version]
- Ignatov, A.; Kobyshev, N.; Timofte, R.; Vanhoey, K.; Gool, L.V. WESPE: Weakly Supervised Photo Enhancer for Digital Cameras. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 804–80409. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Shao, Y.; Li, L.; Ren, W.; Gao, C.; Sang, N. Domain Adaptation for Image Dehazing. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2805–2814. [Google Scholar] [CrossRef]
- Park, D.; Park, H.; Han, D.K.; Ko, H. Single image dehazing with image entropy and information fidelity. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4037–4041. [Google Scholar] [CrossRef]
- Cho, H.; Kim, G.J.; Jang, K.; Lee, S.; Kang, B. Color Image Enhancement Based on Adaptive Nonlinear Curves of Luminance Features. J. Semicond. Technol. Sci. 2015, 15, 60–67. [Google Scholar] [CrossRef]
- Tarel, J.; Hautiere, N.; Caraffa, L.; Cord, A.; Halmaoui, H.; Gruyer, D. Vision Enhancement in Homogeneous and Heterogeneous Fog. IEEE Intell. Transp. Syst. Mag. 2012, 4, 6–20. [Google Scholar] [CrossRef] [Green Version]
- Ancuti, C.; Ancuti, C.O.; Vleeschouwer, C.D. D-HAZY: A dataset to evaluate quantitatively dehazing algorithms. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 2226–2230. [Google Scholar] [CrossRef]
- Ma, K.; Liu, W.; Wang, Z. Perceptual evaluation of single image dehazing algorithms. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3600–3604. [Google Scholar] [CrossRef]
- Hautiere, N.; Tarel, J.P.; Aubert, D.; Dumont, E. Blind contrast enhancement assessment by gradient ratioing at visible edges. Image Anal. Stereol. 2008, 27, 87–95. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A Feature Similarity Index for Image Quality Assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [Green Version]
- Yeganeh, H.; Wang, Z. Objective Quality Assessment of Tone-Mapped Images. IEEE Trans. Image Process. 2013, 22, 657–667. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Typical Techniques | Pros and Cons |
|---|---|---|
| Image processing | Histogram equalization | Pros: Simplicity and fast processing speed |
| Cons: Noise amplification | ||
| Polarimetric dehazing | Pros: High restoration quality | |
| Cons: Complex configuration of experimental equipment | ||
| Dark channel prior | Pros: High restoration quality and efficacy | |
| Cons: Failures in sky regions | ||
| Image fusion | Pros: Circumvention of challenging estimation process, efficacy, and fast processing speed | |
| Cons: Tradeoff between restoration quality and hardware friendliness | ||
| Color ellipsoid prior | Pros: High restoration quality and robustness to noise | |
| Cons: Probable artifacts in dense-haze regions | ||
| Patch similarity | Pros: High restoration quality and versatility | |
| Cons: Probable ringing artifacts | ||
| Machine learning | Regression | Pros: Simplicity and efficacy |
| Cons: Data overfitting and poor performance in dense-haze regions | ||
| Regularization | Pros: Robustness to overfitting and high restoration quality | |
| Cons: Prolonged processing time and probable color distortion | ||
| Probabilistic graphical model | Pros: Facilitation of the analysis of complex data distributions | |
| Cons: High algorithmic complexity and probable color distortion | ||
| Searching-based optimization | Pros: High restoration quality | |
| Cons: Prolonged processing time | ||
| Radial basis function | Pros: High restoration quality | |
| Cons: Prolonged processing time | ||
| Non-local haze-line prior | Pros: High restoration quality | |
| Cons: Tradeoff between restoration quality and processing time | ||
| Deep learning | Convolutional neural network | Pros: Spatial invariance and high restoration quality |
| Cons: Poor performance in heterogeneous lighting conditions and probable domain-shift problem | ||
| Generative adversarial network | Pros: High restoration quality | |
| Cons: Unstable training phase and probable domain-shift problem | ||
| Zero-shot learning | Pros: High restoration quality and elimination of training phase | |
| Cons: Prolonged inference time |
| Category | Method | Image Size | ||||
|---|---|---|---|---|---|---|
| 640 × 480 | 800 × 600 | 1024 × 768 | 1920 × 1080 | 4096 × 2160 | ||
| Image processing | Kim et al. [36] | 0.16 | 0.29 | 0.43 | 1.01 | 4.81 |
| Bui and Kim [50] | 0.32 | 0.52 | 0.86 | 2.37 | 10.06 | |
| Machine learning | Zhu et al. [52] | 0.22 | 0.34 | 0.55 | 1.51 | 6.39 |
| Ngo et al. [54] | 0.18 | 0.34 | 0.49 | 1.13 | 5.77 | |
| Deep learning | Cai et al. [85] | 1.53 | 2.39 | 3.88 | 10.68 | 47.35 |
| Ren et al. [89] | 0.54 | 0.88 | 1.53 | 3.43 | 17.90 | |
| Dataset | Authors | Description | Available at |
|---|---|---|---|
| NYUDepth v2 | Silbermanet al. [114] | Indoor images and corresponding scene depths captured by Kinect camera | https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html (accessed on 19 January 2021) |
| O-HAZE | Ancutiet al. [115] | Pairs of outdoor real hazy and haze-free images | https://data.vision.ee.ethz.ch/cvl/ntire18//o-haze/ (accessed on 21 January 2021) |
| I-HAZE | Ancutiet al. [116] | Pairs of indoor real hazy and haze-free images | https://data.vision.ee.ethz.ch/cvl/ntire18//i-haze/ (accessed on 21 January 2021) |
| Dense-Haze | Ancutiet al. [117] | Pairs of both outdoor and indoor real hazy and haze-free images | https://data.vision.ee.ethz.ch/cvl/ntire19//dense-haze/ (accessed on 21 January 2021) |
| Type | Dataset | Hazy Images (#) | Haze-Free Images (#) | Ground Truth |
|---|---|---|---|---|
| Synthetic | FRIDA2 | 264 | 66 | Yes |
| D-HAZY | 1472 | 1472 | Yes | |
| Real | IVC | 25 | NA | No |
| O-HAZE | 45 | 45 | Yes | |
| I-HAZE | 30 | 30 | Yes |
| Method | Metric | Haze Type | ||||
|---|---|---|---|---|---|---|
| Type 1 | Type 2 | Type 3 | Type 4 | Overall Average | ||
| Tarel and Hautiere [35] | TMQI | 0.7259 | 0.7310 | 0.7312 | 0.7373 | 0.7314 |
| FSIMc | 0.7833 | 0.7725 | 0.7567 | 0.8104 | 0.7807 | |
| He et al. [21] | TMQI | 0.7639 | 0.6894 | 0.6849 | 0.7781 | 0.7291 |
| FSIMc | 0.8168 | 0.7251 | 0.7222 | 0.8343 | 0.7746 | |
| Kim et al. [36] | TMQI | 0.7320 | 0.7037 | 0.7015 | 0.7343 | 0.7179 |
| FSIMc | 0.8048 | 0.7805 | 0.7751 | 0.8134 | 0.7935 | |
| Bui and Kim [50] | TMQI | 0.7973 | 0.6956 | 0.6785 | 0.8163 | 0.7469 |
| FSIMc | 0.8106 | 0.7057 | 0.6955 | 0.8427 | 0.7636 | |
| Zhu et al. [52] | TMQI | 0.7533 | 0.7254 | 0.7080 | 0.7674 | 0.7385 |
| FSIMc | 0.7947 | 0.7845 | 0.7764 | 0.8117 | 0.7918 | |
| Ngo et al. [74] | TMQI | 0.7005 | 0.6976 | 0.6867 | 0.7135 | 0.6996 |
| FSIMc | 0.7950 | 0.8014 | 0.7931 | 0.8078 | 0.7993 | |
| Cai et al. [85] | TMQI | 0.7398 | 0.7307 | 0.7119 | 0.7592 | 0.7354 |
| FSIMc | 0.7987 | 0.7886 | 0.7778 | 0.8199 | 0.7963 | |
| Ren et al. [89] | TMQI | 0.7165 | 0.7275 | 0.7094 | 0.7393 | 0.7232 |
| FSIMc | 0.8044 | 0.7922 | 0.7831 | 0.8239 | 0.8009 | |
| Proposed framework | TMQI | 0.7027 | 0.6917 | 0.6797 | 0.6707 | 0.6862 |
| FSIMc | 0.8013 | 0.7852 | 0.7890 | 0.7771 | 0.7882 | |
| Dataset | IVC | D-HAZY | O-HAZE | I-HAZE | ||||
|---|---|---|---|---|---|---|---|---|
| Metric | TMQI | FSIMc | TMQI | FSIMc | TMQI | FSIMc | ||
| Method | ||||||||
| Tarel and Hautiere [35] | 1.30 | 2.15 | 0.8000 | 0.8703 | 0.8416 | 0.7733 | 0.7740 | 0.8055 |
| He et al. [21] | 0.39 | 1.57 | 0.8631 | 0.9002 | 0.8403 | 0.8423 | 0.7319 | 0.8208 |
| Kim et al. [36] | 1.27 | 2.07 | 0.8702 | 0.8590 | 0.6502 | 0.6869 | 0.7026 | 0.7879 |
| Bui and Kim [50] | 1.80 | 2.37 | 0.8799 | 0.8554 | 0.7655 | 0.7576 | 0.7116 | 0.7737 |
| Zhu et al. [52] | 0.78 | 1.17 | 0.8206 | 0.8880 | 0.8118 | 0.7738 | 0.7512 | 0.8252 |
| Ngo et al. [74] | 0.53 | 1.29 | 0.7683 | 0.8676 | 0.8616 | 0.8244 | 0.7756 | 0.8522 |
| Cai et al. [85] | 0.63 | 1.28 | 0.7932 | 0.8870 | 0.8413 | 0.7865 | 0.7601 | 0.8482 |
| Ren et al. [89] | 0.65 | 1.47 | 0.8021 | 0.8821 | 0.8645 | 0.8402 | 0.7719 | 0.8521 |
| Proposed framework | 0.62 | 1.55 | 0.7668 | 0.8565 | 0.8938 | 0.8277 | 0.8006 | 0.8618 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ngo, D.; Lee, S.; Ngo, T.M.; Lee, G.-D.; Kang, B. Visibility Restoration: A Systematic Review and Meta-Analysis. Sensors 2021, 21, 2625. https://doi.org/10.3390/s21082625
Ngo D, Lee S, Ngo TM, Lee G-D, Kang B. Visibility Restoration: A Systematic Review and Meta-Analysis. Sensors. 2021; 21(8):2625. https://doi.org/10.3390/s21082625
Chicago/Turabian StyleNgo, Dat, Seungmin Lee, Tri Minh Ngo, Gi-Dong Lee, and Bongsoon Kang. 2021. "Visibility Restoration: A Systematic Review and Meta-Analysis" Sensors 21, no. 8: 2625. https://doi.org/10.3390/s21082625