
Korean Grammatical Error Correction Based on Transformer with Copying Mechanisms and Grammatical Noise Implantation Methods

Abstract
:1. Introduction
- We introduce a novel approach to create Korean GEC datasets by implanting various realistic grammatical errors appearing in Korean texts into original correct sentences and thus capable of creating Korean parallel corpora for GEC in an effective manner.
- We implemented a Transformer-based Korean GEC engine equipped with the Copying Mechanism and a realistic grammatical error detection and correction rule set for many errors that cannot be handled by the main model.
- We showed that the proposed system drastically outperforms two commercial GEC engines in various aspects.
- We analyze the results by comparing the performance with other NMT-based models.
2. Related Work
3. Methods
3.1. Grammatical Noise Implantation for Korean Language
3.1.1. Grapheme to Phoneme Noising Rules
3.1.2. Heuristic-Based Noising Rules
3.1.3. Word Spacing Noising Rules
3.1.4. Heterograph Nosing Rules
3.2. Transformer
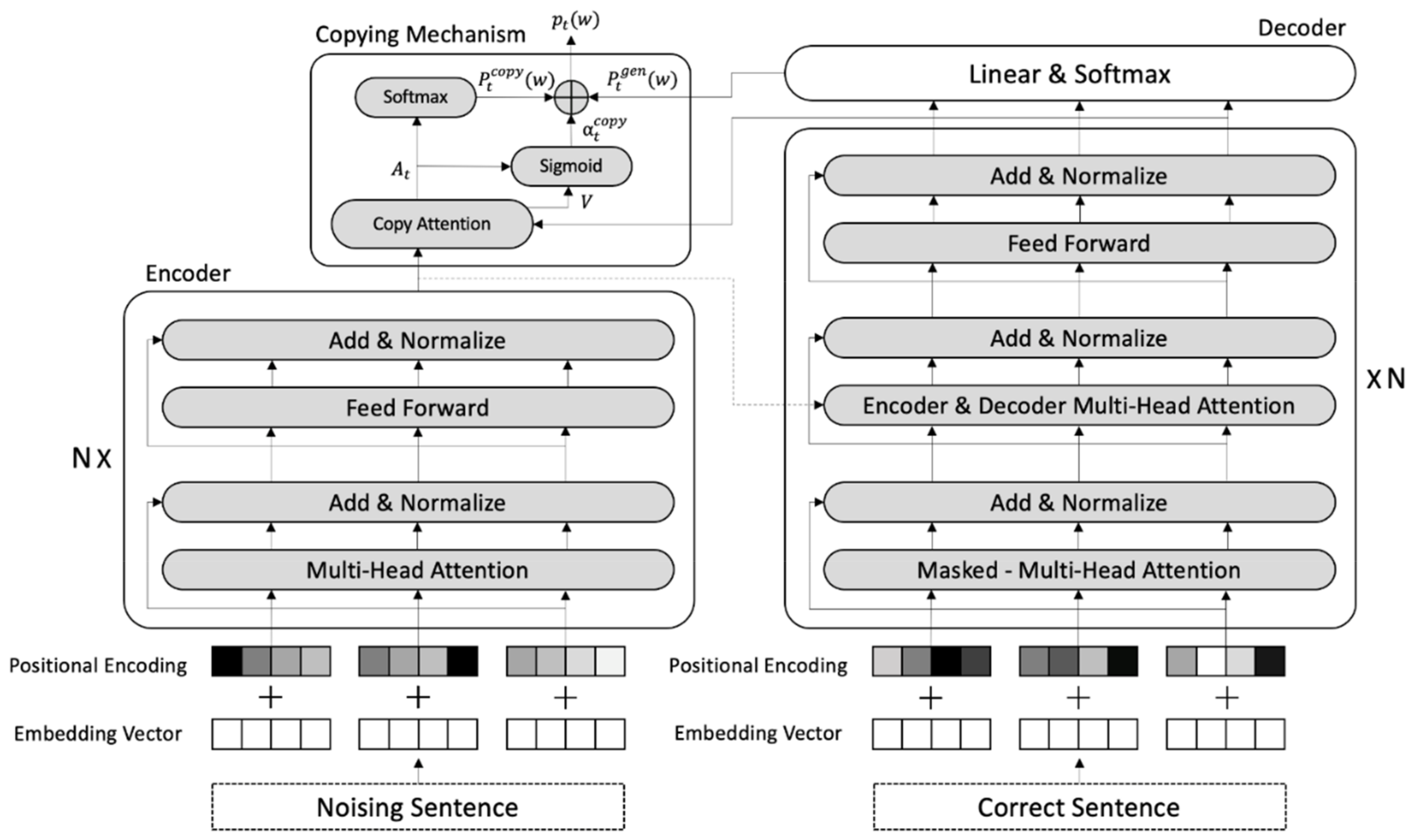
3.3. Copying Mechanism
4. Experiments and Discussion
4.1. Data
4.2. Model and Parameters
4.3. Evaluation Metrics
4.4. Result and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Y.; Wang, Y.; Liu, J.; Liu, Z.A. Comprehensive Survey of Grammar Error Correction. arXiv 2020, arXiv:2005.06600. [Google Scholar]
- Bak, S.H.; Lee, E.J.; Kim, P.K. A Method for Spelling Error Correction in Korean Using a Hangul Edit Distance Algorithm. Smart Media J. 2017, 6, 16–21. [Google Scholar]
- Cho, S.W.; Kwon, H.S.; Jung, H.Y.; Lee, J.H. Adoptaion of a Neural Language Model in an Encoder for Ecoder-Decoder based Korean Grammatical Error Correction. Kiise Trans. Comput. Pract. 2018, 24, 301–306. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Zhao, W.; Wang, L.; Shen, K.; Jia, R.; Liu, J. Improving grammatical error correction via pre-training a copy-augmented architecture with unlabeled data. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MI, USA, 2–7 June 2019; pp. 156–165. [Google Scholar]
- Bryant, C.; Felice, M.; Andersen, Ø.E.; Briscoe, T. The BEA-2019 shared task on grammatical error correction. In Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications, Florence, Italy, 2 August 2019; pp. 52–75. [Google Scholar]
- Yuan, Z.; Briscoe, T. Grammatical error correction using neural machine translation. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–15 June 2016; pp. 380–386. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Xie, Z.; Avati, A.; Arivazhagan, N.; Jurafsky, D.; Ng, A.Y. Neural language correction with character-based attention. arXiv 2016, arXiv:1603.09727. [Google Scholar]
- Lichtarge, J.; Alberti, C.; Kumar, S.; Shazeer, N.; Parmar, N. Weakly supervised grammatical error correction using iterative decoding. arXiv 2018, arXiv:1811.01710. [Google Scholar]
- Chollampatt, S.; Ng, H.T. A multilayer convolutional encoder-decoder neural network for grammatical error correction. In Proceedings of the Thirty-Second AAAI Conference of Artifical Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 5755–5762. [Google Scholar]
- Choe, Y.J.; Ham, J.; Park, K.; Yoon, Y. A neural grammatical error correction system built on better pre-training and sequential transfer learning. In Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications, Florence, Italy, 2 August 2019; pp. 213–227. [Google Scholar]
- Park, C.J.; Jeong, S.; Yang, K.; Lee, S.; Joe, J.; Lim, H. Korean Spell Correction based on Denoising Transformer. In Proceedings of the 31st Annual Conference on Human & Cognitive Language Technology, Daejeon, Korea, 11–12 October 2021; pp. 368–374. [Google Scholar]
- Zhao, Z.; Wang, H. MaskGEC: Improving Neural Grammatical Error Correction via Dynamic Masking. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 1226–1233. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the 27th Interna-tional Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Kim, S.K.; Kime, T.Y.; Kang, R.W.; Kim, J. Characteristics of Korean Liaison Rule in the Reading and Writing of Children of Korean-Vietnamese Multicultural Families and the Correlation with Mothers’ Korean Abilities. Korean Speech-Lang. Hear. Assoc. 2020, 29, 57–71. [Google Scholar]
- Park, K.B. G2pk. Available online: https://github.com/Kyubyong/g2pK (accessed on 15 February 2021).
- Lee, K. Patterns of Word Spacing Errors in University Students’ Writing. J. Res. Soc. Lang. Lit. 2018, 97, 289–318. [Google Scholar]
- Seo, S.I. ChatSpace: Space Correcting Model for Improving Tokenization of Korean Conversational Text. Master’s Thesis, Yonsei University, Seoul, Korea, 2020. [Google Scholar]
- Py-Hanspell. Available online: https://github.com/ssut/py-hanspell (accessed on 15 February 2021).
- Hanspell. Available online: https://github.com/9beach/hanspell (accessed on 15 February 2021).
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Mutton, A.; Dras, M.; Wan, S.; Dale, R. GLEU: Automatic evaluation of sentence-level fluency. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, 20–23 June 2007; pp. 344–351. [Google Scholar]
- AI-Hub Korean-English Parallel Corpus. Available online: https://www.aihub.or.kr/aidata/87 (accessed on 23 March 2021).
- Kudo, T.; Richardson, J. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Brussels, Belgium, 2–4 November 2018; pp. 66–71. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Type | Word & Means | |
|---|---|---|
| Original Sentence | Korean | 오랜만에 |
| Pronunciation | olaenman-e | |
| Meaning | After a long time | |
| Noised Sentence | Korean | 오랜마네 |
| Pronunciation | olaen-mane | |
| Meaning | - | |
| Type | Sentence and Meaning | |
|---|---|---|
| Original Sentence | Korean | 나는 어제 밥을 먹었다. |
| Pronunciation | naneun eoje bab-eul meog-eottda. | |
| Meaning | I ate meal yesterday. | |
| Noised Sentence | Korean | 나는 어제 바블 먹었다. |
| Pronunciation | naneun eoje babeul meog-eottda. | |
| Meaning | I ate babeul yesterday. | |
| Type | Sentence and Meaning | |
|---|---|---|
| Original Sentence | Koreans | 나는 집을 깨끗이 청소했다. |
| Pronunciation | naneun jib-eul kkaekkeus-i cheongsohaessda. | |
| Meaning | I cleaned my house cleanly. | |
| Noised Sentence | Koreans | 나는 집을 깨끗히 청소했다. |
| Pronunciation | naneun jib-eul kkaekkeushi cheongsohaessda. | |
| Meaning | I cleaned my house kkaekkeushi. | |
| Original Sentence | Koreans | 나는 오랜만에 친구를 만났다. |
| Pronunciation | naneun olaenman-e chinguleul mannattda. | |
| Meaning | I met a friend after a long time. | |
| Noised Sentence | Koreans | 나는 오랫만에 친구를 만났다. |
| Pronunciation | naneun olaesman-e chinguleul mannattda. | |
| Meaning | I met a friend for a long time. | |
| Type | Sentence and Meaning | |
|---|---|---|
| Input Sentence | Korean | 나는 그럴 수 없지. |
| Pronunciation | naneun geuleol su eobsji. | |
| Meaning | I cannot do that. | |
| Output Sentence | Korean | 나는 그럴수 없지. |
| Pronunciation | Naneun geuleolsu eobsji. | |
| Meaning | I cannot dothat. | |
| Syllable Position | Similar Syllables Group |
|---|---|
| Neutral | ㅔ[e], ㅐ[ae] |
| ㅖ[ye], ㅒ[yae] | |
| ㅚ[we], ㅞ[we], ㅙ[wae] | |
| Final | ㅂ[p], ㅍ[p] |
| ㅅ[t], ㅆ[tt], ㄷ[t], ㅌ[t], ㅈ[t], ㅊ[t], ㅎ[t] | |
| ㄱ[k], ㄲ[kk], ㅋ[k] |
| Type | Sentence and Meaning | |
|---|---|---|
| Original Sentence | Korean | 나는 간장에 밥을 비벼 먹었다. |
| Pronunciation | naneun ganjang-e bab-eul bibyeo meok-eottda. | |
| Meaning | I ate rice on soy sauce. | |
| Noised Sentence | Korean | 나는 간장에 밥을 비벼 먺엇다. |
| Pronunciation | naneun ganjang-e bab-eul bibyeo meokk-eotda. | |
| Meaning | I meokkeot rice on soy sauce. | |
| Domain | Explanation | Size |
|---|---|---|
| News | News text | 800 K |
| Government | Government and Local Government Websites, Publications | 100 K |
| Law | Administrative rules, autonomous laws | 100 K |
| Korean Culture | Korean history and culture contents | 100 K |
| Colloquial | Natural colloquial sentences | 400 K |
| Dialogue | Context/scenario-based conversation set | 100 K |
| Parameters | Size |
|---|---|
| Position-wise Feed forward layer | 4096 |
| Encoder/Decoder Layer size | 8 |
| Embedding Size | 512 |
| Attention-Head | 8 |
| Dropout ratio | 0.1 |
| Smoothing value | 0.1 |
| Vocabulary size | 30,000 |
| Model | GLEU | BLEU1 | BLEU2 | BLEU3 | BLEU4 |
|---|---|---|---|---|---|
| Py-Hanspell | 46.55 | 63.27 | 48.63 | 38.18 | 30.39 |
| Hanspell | 48.28 | 63.95 | 50.23 | 40.19 | 32.36 |
| Seq2Seq | 72.18 | 83.38 | 74.57 | 66.82 | 59.89 |
| Seq2Seq with Attention | 77.02 | 86.34 | 79.09 | 72.65 | 66.72 |
| Transformer | 76.09 | 86.10 | 77.63 | 70.47 | 63.67 |
| Transformer with Copying Mechanism | 79.37 | 88.00 | 80.78 | 74.67 | 68.58 |
| Model | Precision | Recall | F0.5 |
|---|---|---|---|
| Py-Hanspell | 28.73 | 28.03 | 27.81 |
| Hanspell | 30.85 | 29.82 | 29.80 |
| Seq2Seq | 65.88 | 65.56 | 65.61 |
| Seq2Seq with Attention | 70.94 | 70.46 | 70.76 |
| Transformer | 73.83 | 72.46 | 73.24 |
| Transformer with Copying Mechanism | 75.30 | 74.13 | 74.86 |
| Type | Sentence and Meaning | |
|---|---|---|
| Input Sentence with Grammatical Errors | Korean | 수업시가네 선생님이수학을 가리켰다. |
| Pronounciation | sueobsigane seonsaengnim-isuhak-eul galikyeossda. | |
| Meaning | sueobsigane, my teachermathpointed to. | |
| Py-Hanspell | Korean | 수업 시 가네 선생님이 수학을 가리켰다. |
| Pronounciation | sueob si gane seonsaengnim-i suhak-eul galikyeossda. | |
| Meaning | sueob si gane, my teacher pointed to math. | |
| Hanspell | Korean | 수업시가 네 선생님 이수학을 가리켰다. |
| Pronounciation | sueobsiga ne seonsaengnim isuhak-eul galikyeossda. | |
| Meaning | sueobsiga, your teacher pointed toisuhak. | |
| NMT-based models | Korean | 수업 시간에 선생님이 수학을 가르쳤다. |
| Pronounciation | sueob sigan-e seonsaengnim-i suhak-eul galeuchyeossda. | |
| Meaning | In class, my teacher taught math. | |
| Noise | Sentence and Meaning | ||
|---|---|---|---|
| G2PK | Input | Korean | 그러면 중국사람 드리투표를 해줘야 하는데 다소 어렵다. |
| Pronunciation | geuleomyeon jung-gugsalam deulitupyoleul haejwoya haneunde daso eolyeobda. | ||
| Meaning | Then, the Chinese have to deulitupy, which is a bit difficult. | ||
| Predict | Korean | 그러면 중국 사람들이 투표를 해줘야 하는데 다소 어렵다. | |
| Pronunciation | geuleomyeon jung-gug salamdeul-i tupyoleul haejwoya haneunde daso eolyeobda. | ||
| Meaning | Then, the Chinese people have to vote, which is a bit difficult. | ||
| Correct | Korean | 그러면 중국 사람들이 투표를 해줘야 하는데 다소 어렵다. | |
| Pronunciation | geuleomyeon jung-gug salamdeul-i tupyoleul haejwoya haneunde daso eolyeobda. | ||
| Meaning | Then, the Chinese people have to vote, which is a bit difficult. | ||
| Heuristic | Input | Korean | 항상 요리하기 전에 찬물로퀴 노아를 깨끗히 씻고 완전이 말려라. |
| Pronunciation | hangsang yolihagi jeon-e chanmullokwi noaleul kkaekkeushi ssisgo wanjeon-i mallyeola. | ||
| Meaning | Always wash Noah thoroughly with chanmullokwi and dry thoroughly before cooking. | ||
| Predict | Korean | 항상 요리하기 전에 찬 물로 퀴노아를 깨끗이 씻고 완전히 말려라. | |
| Pronunciation | hangsang yolihagi jeon-e chan mullo kwinoaleul kkaekkeus-i ssisgo wanjeonhi mallyeola. | ||
| Meaning | Always wash quinoa thoroughly with cold water and dry thoroughly before cooking. | ||
| Correct | Korean | 항상 요리하기 전에 찬 물로 퀴노아를 깨끗이 씻고 완전히 말려라. | |
| Pronunciation | hangsang yolihagi jeon-e chan mullo kwinoaleul kkaekkeus-i ssisgo wanjeonhi mallyeola. | ||
| Meaning | Always wash quinoa thoroughly with cold water and dry thoroughly before cooking. | ||
| Heterograph | Input | Korean | 저는 이런 일이 일어나리라고 얘상하지 뫃햏거든요. |
| Pronunciation | jeoneun ileon il-i il-eonalilago yae sanghaji mothaetgeodeun-yo. | ||
| Meaning | I mothaet yae sang this to happen. | ||
| Predict | Korean | 저는 이런 일이 일어나리라고 예상하지 못했거든요. | |
| Pronunciation | jeoneun ileon il-i il-eonalilago yesanghaji mothaetgeodeun-yo. | ||
| Meaning | I didn’t expect this to happen. | ||
| Correct | Korean | 저는 이런 일이 일어나리라고 예상하지 못했거든요. | |
| Pronunciation | jeoneun ileon il-i il-eonalilago yesanghaji mothaetgeodeun-yo. | ||
| Meaning | I didn’t expect this to happen. | ||
| Type | Sentence and Meaning | |
|---|---|---|
| Correct Sentence | Korean | 경기도를 나무와 숲으로 둘러싸인 녹색도시로 만들기 위한 특별한 신용카드가 출시된다. |
| Pronunciation | gyeonggi-doleul namuwa sup-eulo dulleossain nogsaegdosilo mandeulgi wihan teugbyeolhan sin-yongkadeuga chulsidoenda. | |
| Meaning | A special credit card is released to make Gyeonggido a green city surrounded by trees and forests. | |
| Transformer | Korean | 나무와 숲으로 둘러싸인 녹색도시로 만들기 위한 특별한 신용카드가 출시된다. |
| Pronunciation | namuwa sup-eulo dulleossain nogsaegdosilo mandeulgi wihan teugbyeolhan sin-yongkadeuga chulsidoenda. | |
| Meaning | A special credit card is released to make a green city surrounded by trees and forests. | |
| Transformer with Copying Mechanism | Korean | 경기도를 나무와 숲으로 둘러싸인 녹색도시로 만들기 위한 특별한 신용카드가 출시된다. |
| Pronunciation | gyeonggi-doleul namuwa sup-eulo dulleossain nogsaegdosilo mandeulgi wihan teugbyeolhan sin-yongkadeuga chulsidoenda. | |
| Meaning | A special credit card is released to make Gyeonggido a green city surrounded by trees and forests. | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, M.; Shin, H.; Lee, D.; Choi, S.-P. Korean Grammatical Error Correction Based on Transformer with Copying Mechanisms and Grammatical Noise Implantation Methods. Sensors 2021, 21, 2658. https://doi.org/10.3390/s21082658
Lee M, Shin H, Lee D, Choi S-P. Korean Grammatical Error Correction Based on Transformer with Copying Mechanisms and Grammatical Noise Implantation Methods. Sensors. 2021; 21(8):2658. https://doi.org/10.3390/s21082658
Chicago/Turabian StyleLee, Myunghoon, Hyeonho Shin, Dabin Lee, and Sung-Pil Choi. 2021. "Korean Grammatical Error Correction Based on Transformer with Copying Mechanisms and Grammatical Noise Implantation Methods" Sensors 21, no. 8: 2658. https://doi.org/10.3390/s21082658
APA StyleLee, M., Shin, H., Lee, D., & Choi, S.-P. (2021). Korean Grammatical Error Correction Based on Transformer with Copying Mechanisms and Grammatical Noise Implantation Methods. Sensors, 21(8), 2658. https://doi.org/10.3390/s21082658