Unsupervised Monocular Depth Estimation for Colonoscope System Using Feedback Network

Abstract
:1. Introduction
2. Related Works
2.1. Colonoscpy Depth Estimation
2.2. Unsupervised Monocular Depth and Pose Estimation
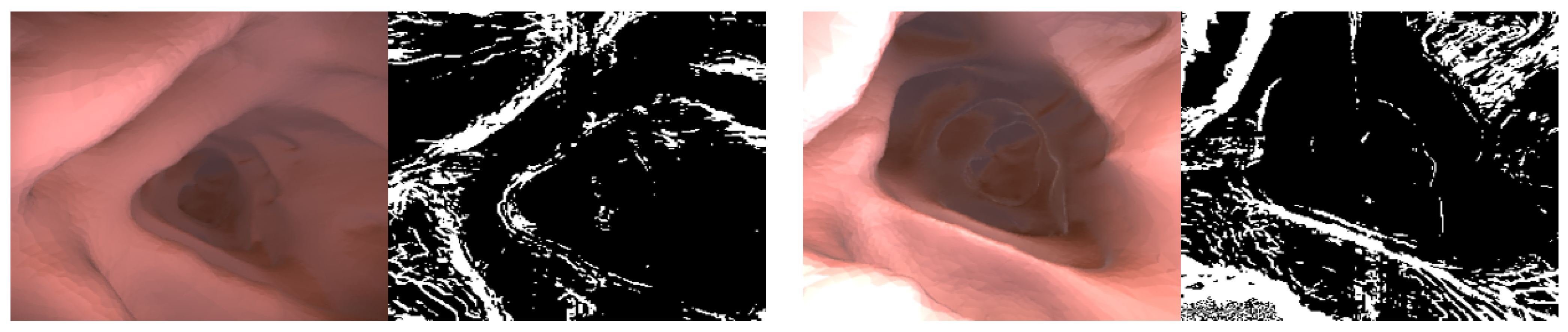
3. Methods
3.1. Self-Supervised Training
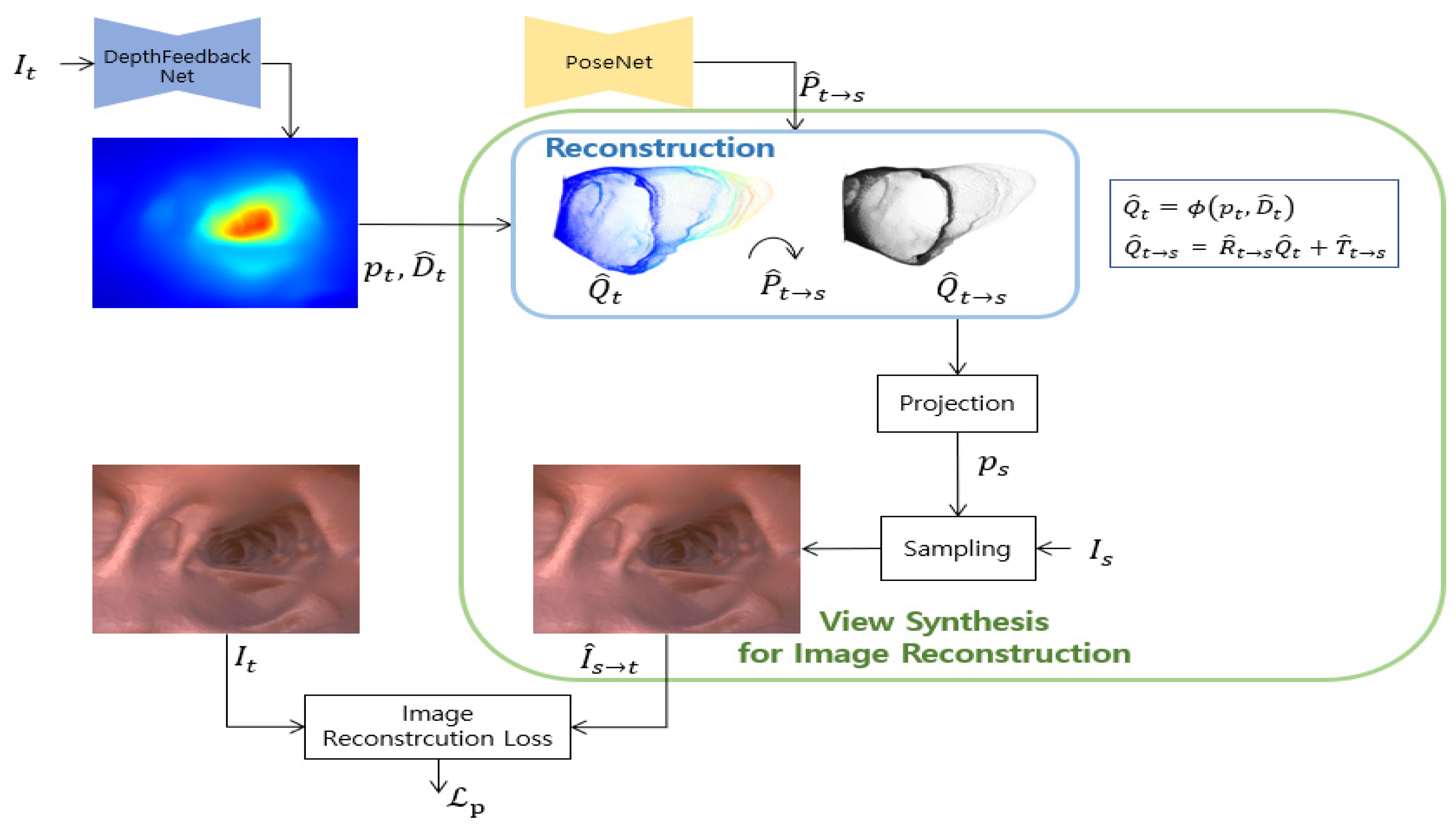
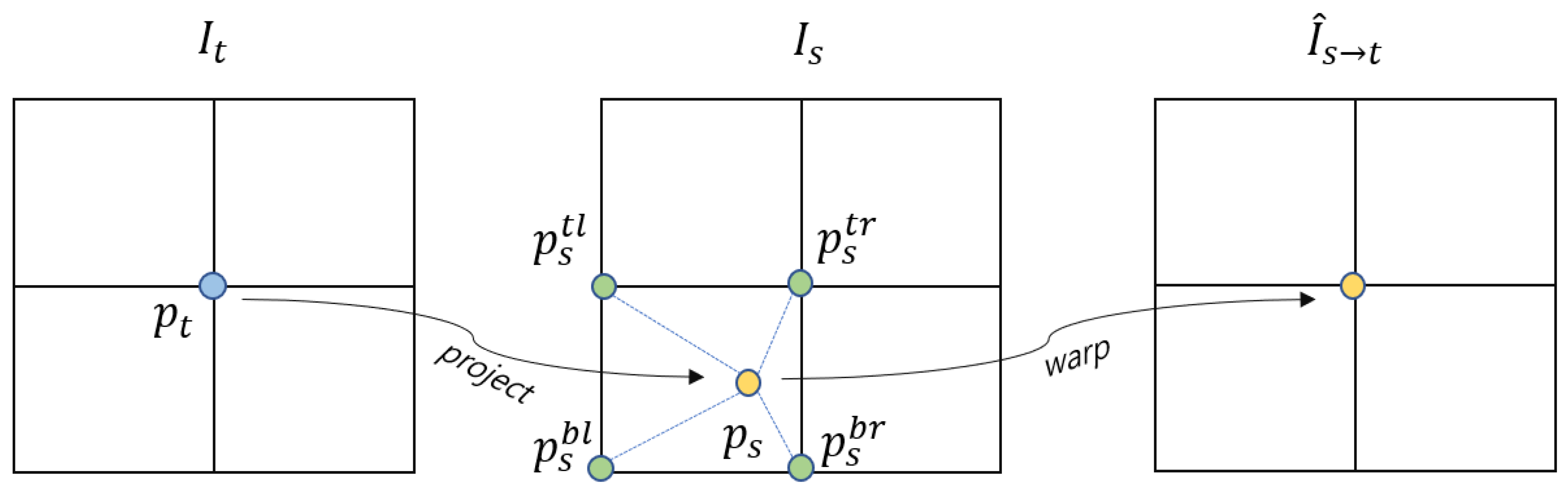
3.1.1. Image Reconstruction Loss
3.1.2. Depth Smoothness Loss
3.1.3. Multi-Scale Estimation
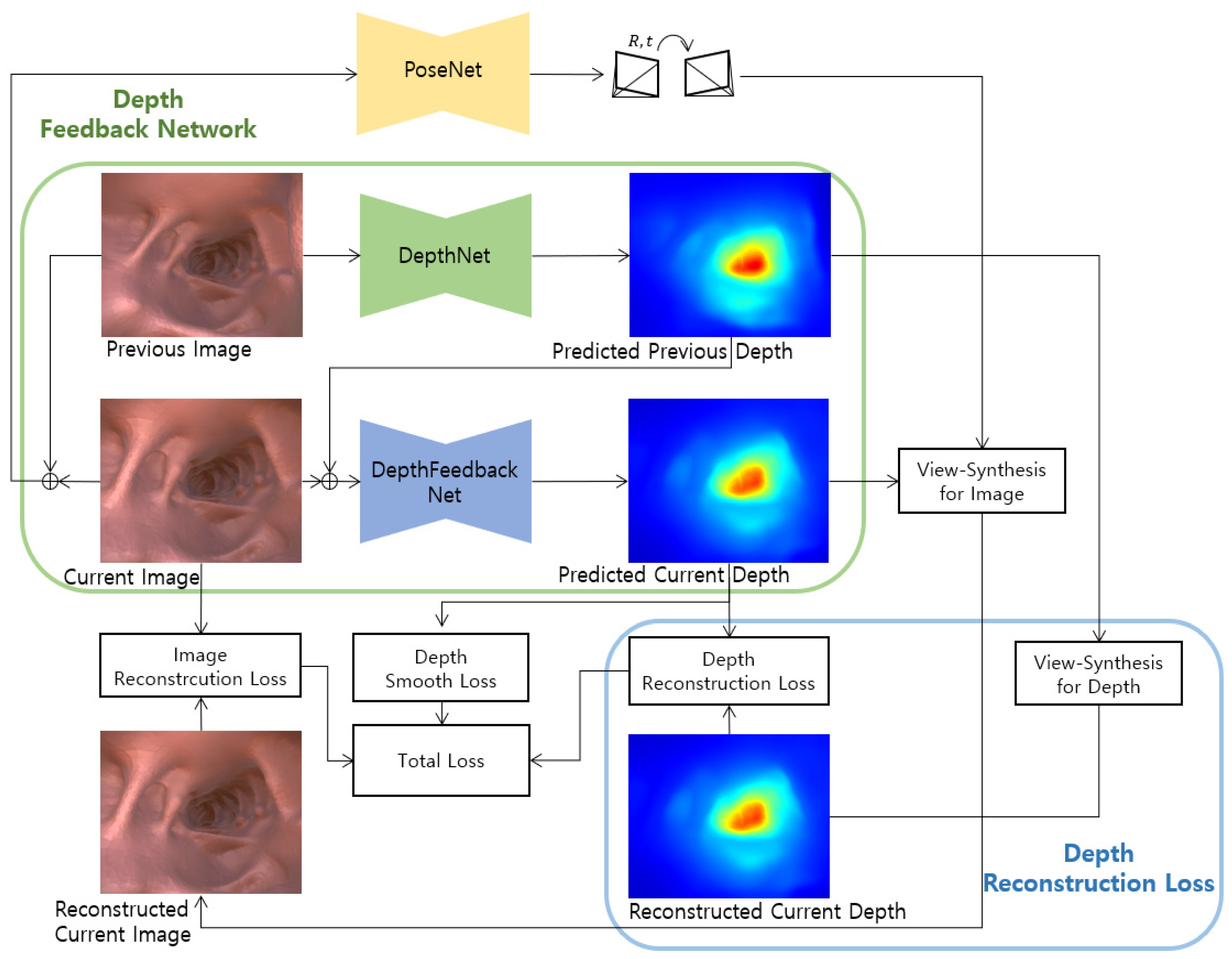
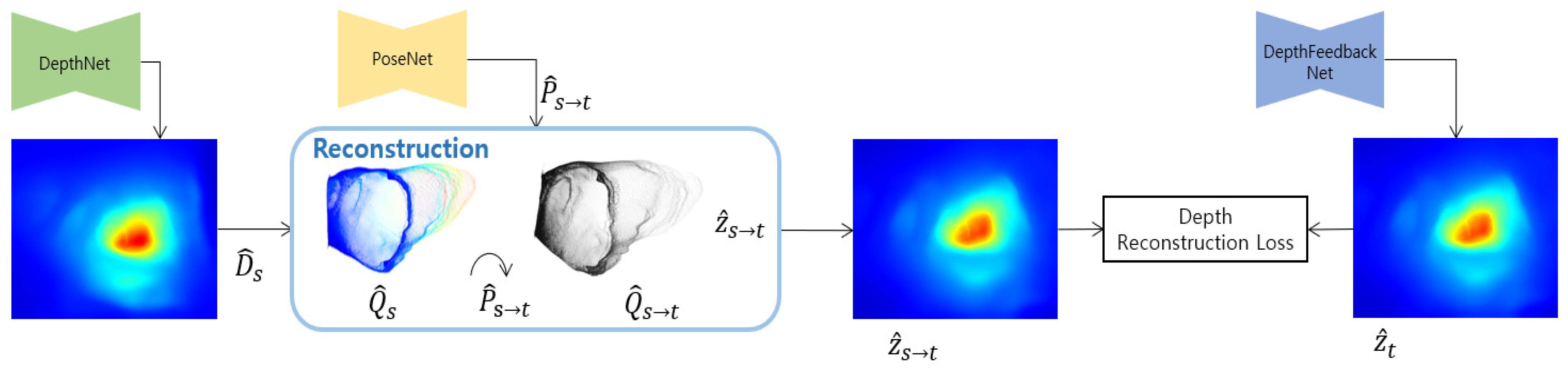
3.2. Improved Self-Supervised Training
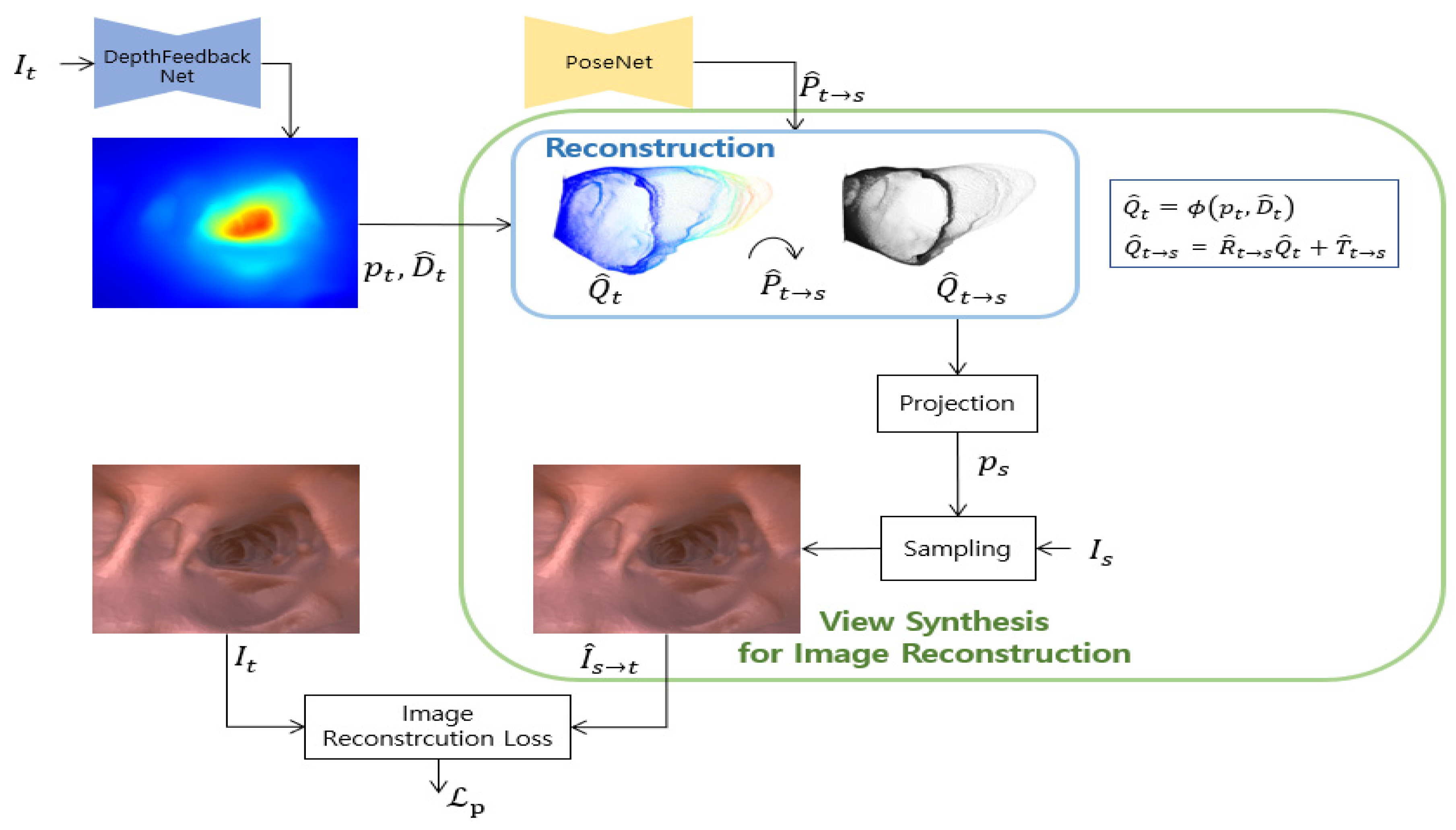
3.2.1. Depth Reconstruction Loss
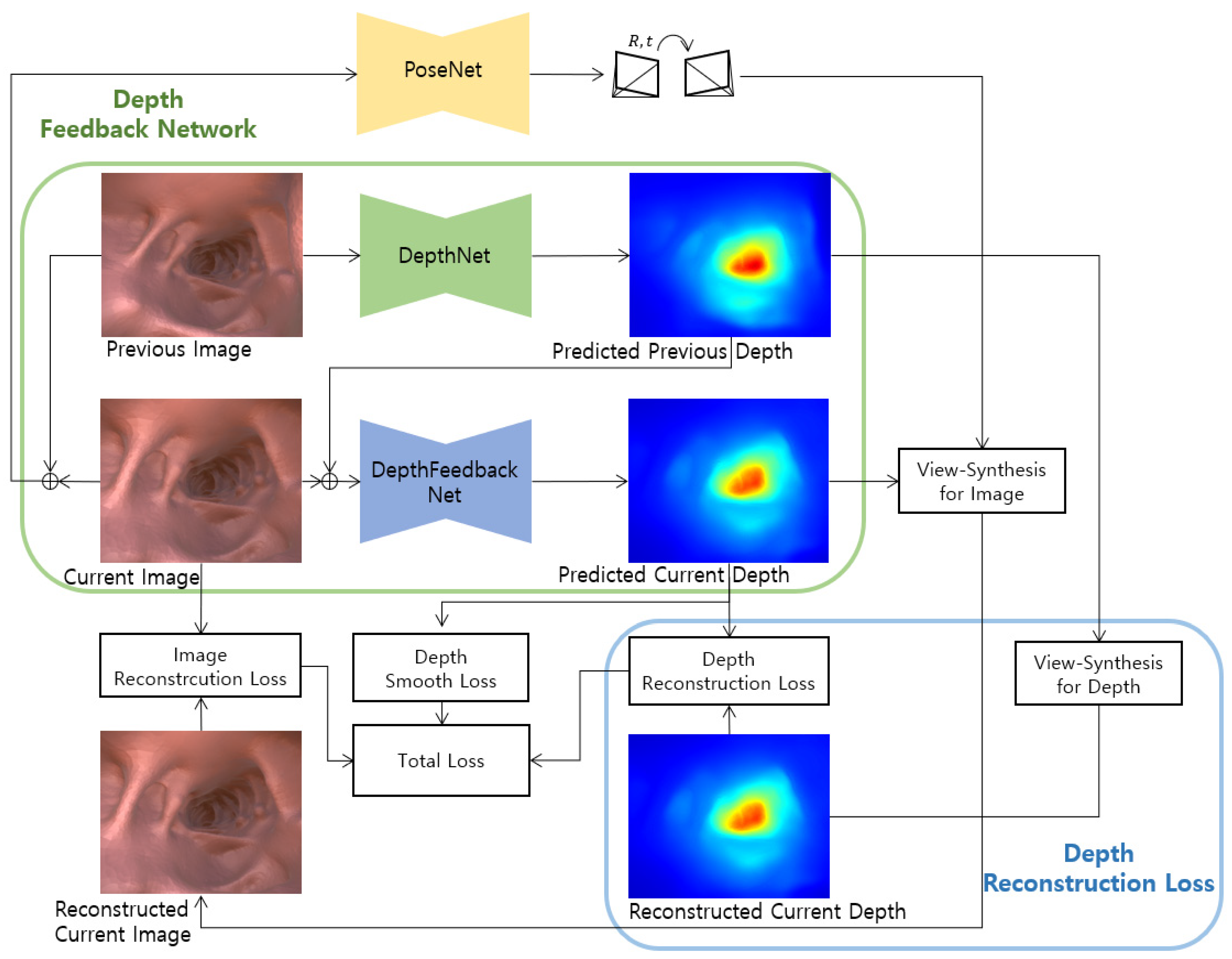
3.2.2. Depth Feedback Network
3.2.3. Final Loss
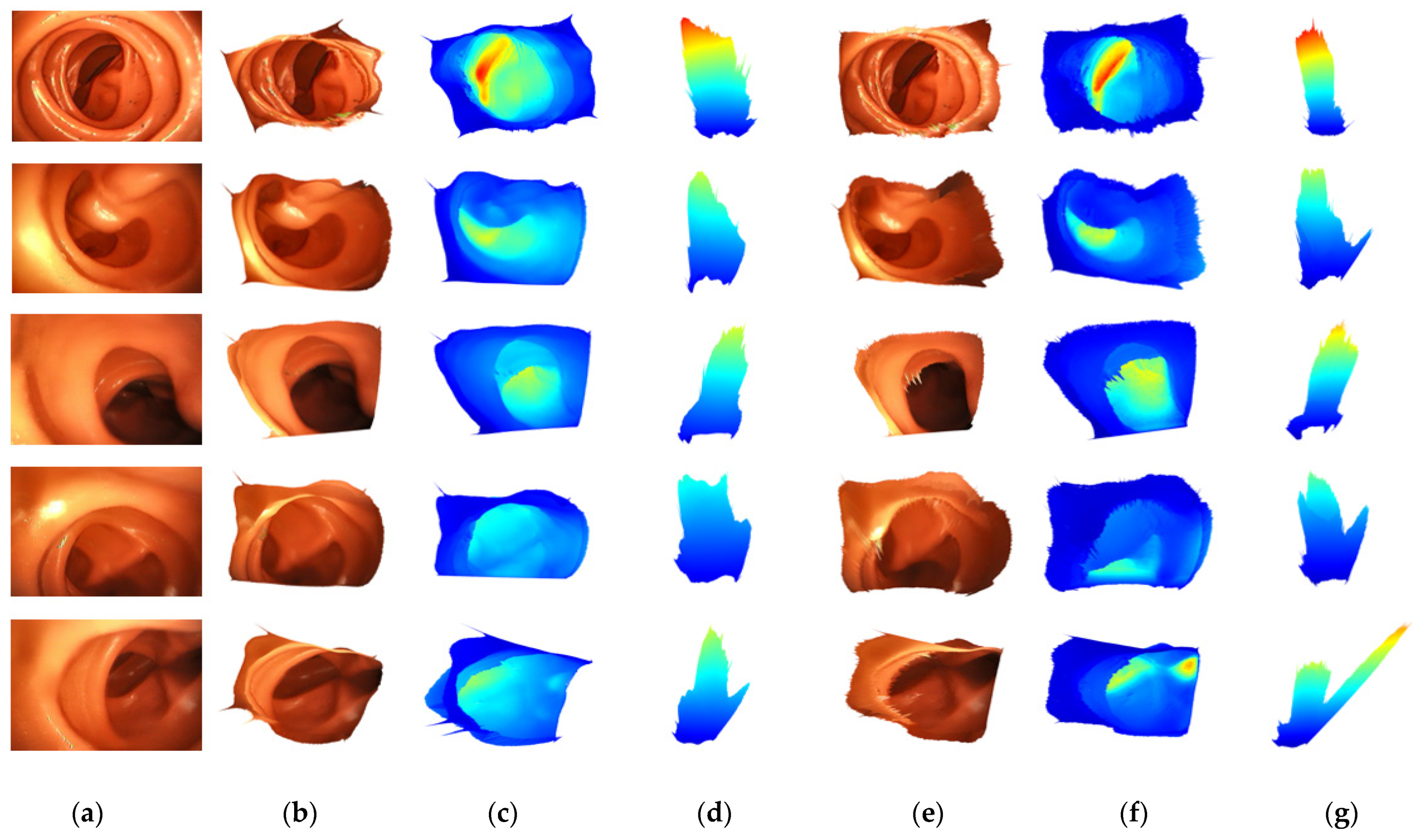
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Evaluation Metrics
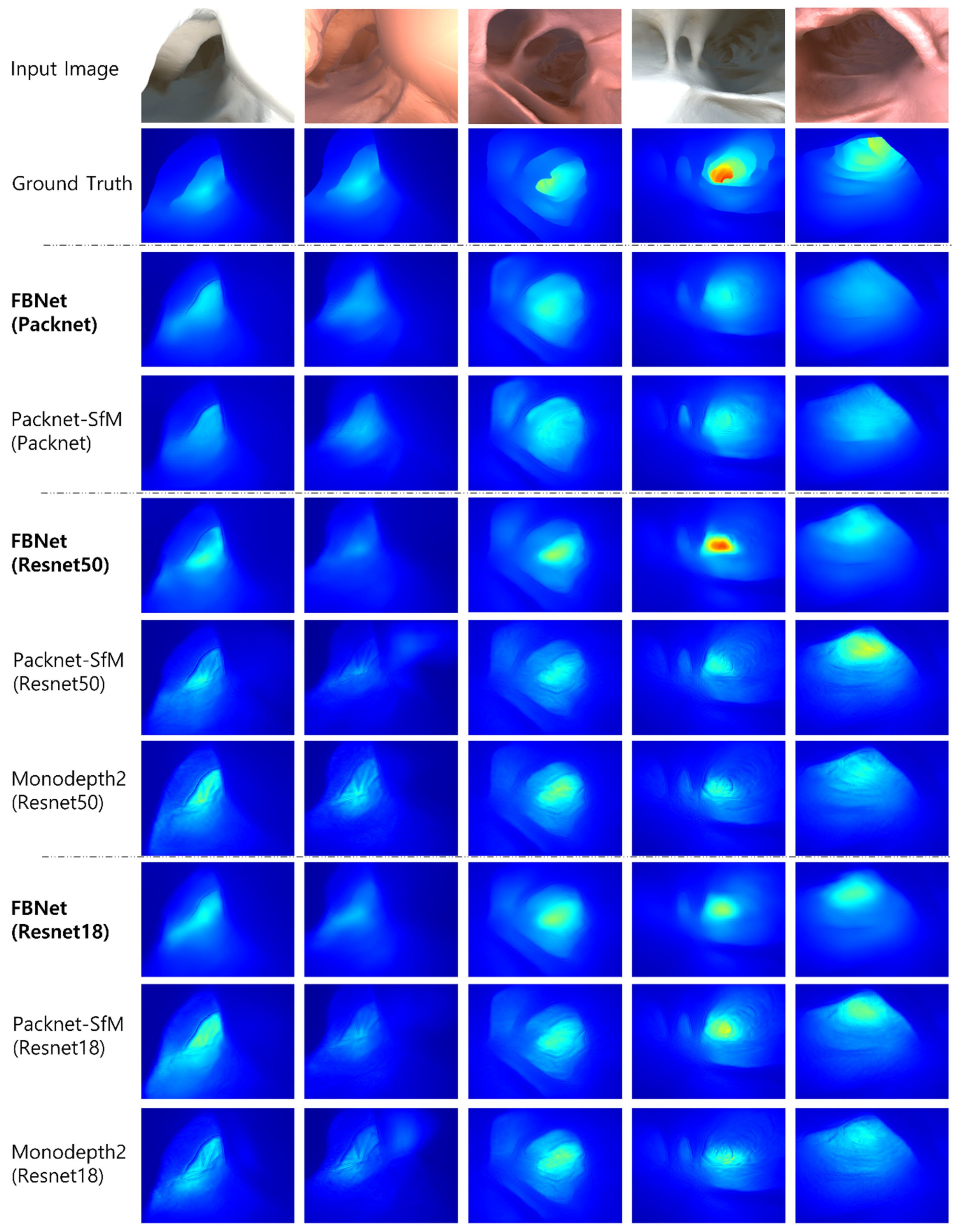
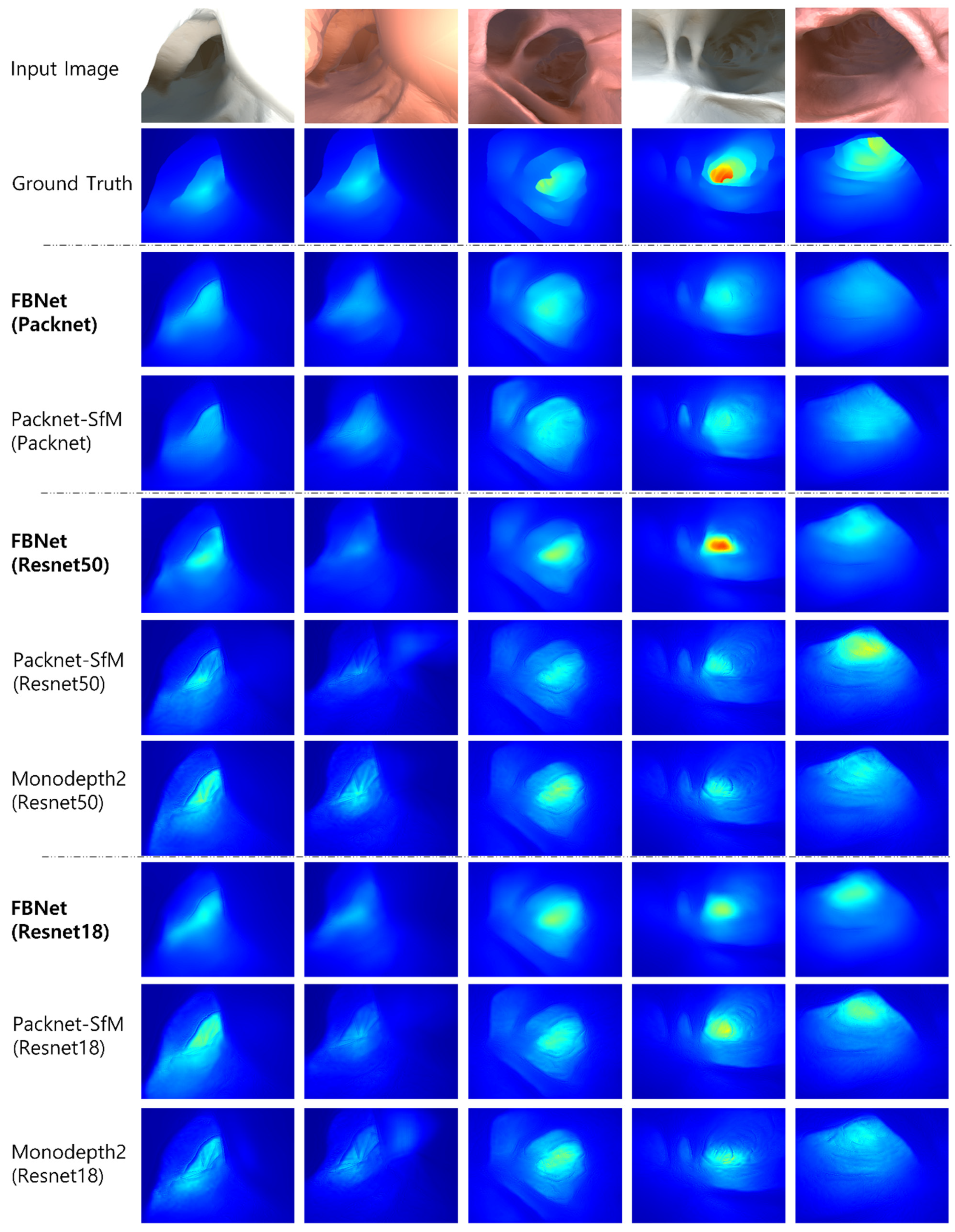
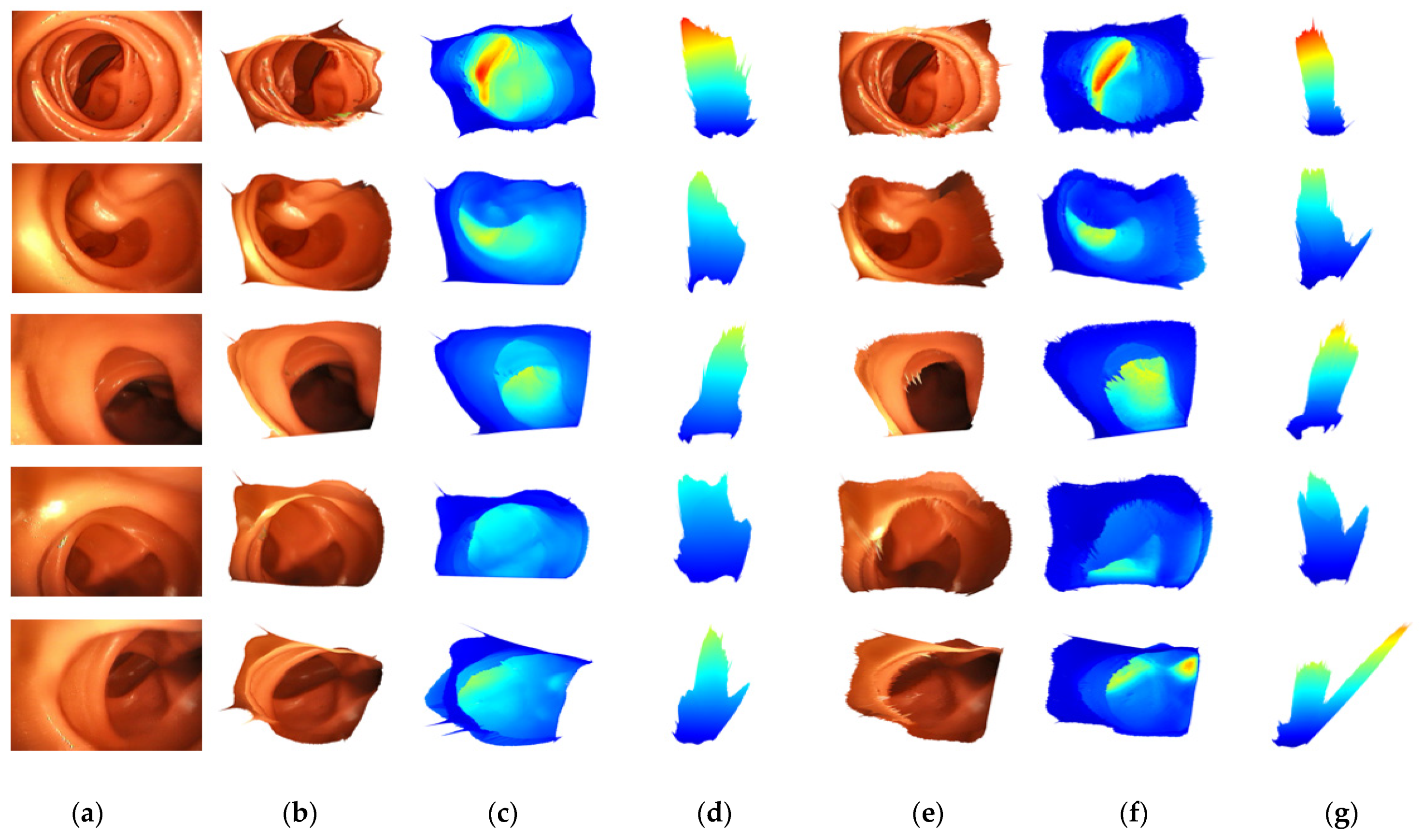
4.2. Comparison Study
4.3. Ablation Study
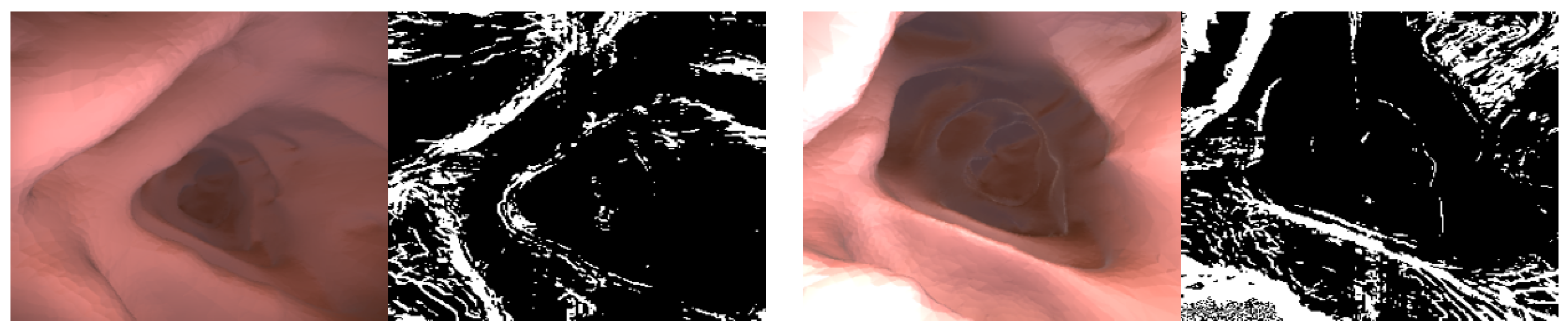
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Bray, F.; Ferlay, J.; Soerjomataram, I.; Siegel, R.L.; Torre, L.A.; Jemal, A. Global Cancer Statistics 2018: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA A Cancer J. Clin. 2018, 68, 394–424. [Google Scholar] [CrossRef] [Green Version]
- Rex, D.K. Polyp Detection at Colonoscopy: Endoscopist and Technical Factors. Best Pract. Res. Clin. Gastroenterol. 2017, 31, 425–433. [Google Scholar] [CrossRef]
- Ciuti, G.; Skonieczna-Z, K.; Iacovacci, V.; Liu, H.; Stoyanov, D.; Arezzo, A.; Chiurazzi, M.; Toth, E.; Thorlacius, H.; Dario, P.; et al. Frontiers of Robotic Colonoscopy: A Comprehensive Review of Robotic Colonoscopes and Technologies. J. Clin. Med. 2020, 37, 1648. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.Y.; Jeong, J.; Song, E.M.; Ha, C.; Lee, H.J.; Koo, J.E.; Yang, D.-H.; Kim, N.; Byeon, J.-S. Real-Time Detection of Colon Polyps during Colonoscopy Using Deep Learning: Systematic Validation with Four Independent Datasets. Sci. Rep. 2020, 10, 8379. [Google Scholar] [CrossRef] [PubMed]
- Itoh, H.; Roth, H.R.; Lu, L.; Oda, M.; Misawa, M.; Mori, Y.; Kudo, S.; Mori, K. Towards Automated Colonoscopy Diagnosis: Binary Polyp Size Estimation via Unsupervised Depth Learning. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2018; Lecture Notes in Computer Science; Frangi, A.F., Schnabel, J.A., Davatzikos, C., Alberola-López, C., Fichtinger, G., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11071, pp. 611–619. ISBN 978-3-030-00933-5. [Google Scholar]
- Freedman, D.; Blau, Y.; Katzir, L.; Aides, A.; Shimshoni, I.; Veikherman, D.; Golany, T.; Gordon, A.; Corrado, G.; Matias, Y.; et al. Detecting Deficient Coverage in Colonoscopies. IEEE Trans. Med. Imaging 2020, 39, 3451–3462. [Google Scholar] [CrossRef] [PubMed]
- Bernth, J.E.; Arezzo, A.; Liu, H. A Novel Robotic Meshworm With Segment-Bending Anchoring for Colonoscopy. IEEE Robot. Autom. Lett. 2017, 2, 1718–1724. [Google Scholar] [CrossRef] [Green Version]
- Formosa, G.A.; Prendergast, J.M.; Edmundowicz, S.A.; Rentschler, M.E. Novel Optimization-Based Design and Surgical Evaluation of a Treaded Robotic Capsule Colonoscope. IEEE Trans. Robot. 2020, 36, 545–552. [Google Scholar] [CrossRef]
- Kang, M.; Joe, S.; An, T.; Jang, H.; Kim, B. A Novel Robotic Colonoscopy System Integrating Feeding and Steering Mechanisms with Self-Propelled Paddling Locomotion: A Pilot Study. Mechatronics 2021, 73, 102478. [Google Scholar] [CrossRef]
- Visentini-Scarzanella, M.; Sugiura, T.; Kaneko, T.; Koto, S. Deep Monocular 3D Reconstruction for Assisted Navigation in Bronchoscopy. Int. J. CARS 2017, 12, 1089–1099. [Google Scholar] [CrossRef]
- Nadeem, S.; Kaufman, A. Depth Reconstruction and Computer-Aided Polyp Detection in Optical Colonoscopy Video Frames. arXiv 2016, arXiv:1609.01329. [Google Scholar]
- Mahmood, F.; Chen, R.; Durr, N.J. Unsupervised Reverse Domain Adaptation for Synthetic Medical Images via Adversarial Training. IEEE Trans. Med. Imaging 2018, 37, 2572–2581. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mahmood, F.; Durr, N.J. Deep Learning and Conditional Random Fields-Based Depth Estimation and Topographical Reconstruction from Conventional Endoscopy. Med. Image Anal. 2018, 48, 230–243. [Google Scholar] [CrossRef] [Green Version]
- Rau, A.; Edwards, P.J.E.; Ahmad, O.F.; Riordan, P.; Janatka, M.; Lovat, L.B.; Stoyanov, D. Implicit Domain Adaptation with Conditional Generative Adversarial Networks for Depth Prediction in Endoscopy. Int. J. CARS 2019, 14, 1167–1176. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, R.J.; Bobrow, T.L.; Athey, T.; Mahmood, F.; Durr, N.J. SLAM Endoscopy Enhanced by Adversarial Depth Prediction. arXiv 2019, arXiv:1907.00283. [Google Scholar]
- Mahjourian, R.; Wicke, M.; Angelova, A. Unsupervised Learning of Depth and Ego-Motion from Monocular Video Using 3D Geometric Constraints. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Salt Lake City, UT, USA, 2018; pp. 5667–5675. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G. Digging into Self-Supervised Monocular Depth Estimation. arXiv 2019, arXiv:1806.01260. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. arXiv 2018, arXiv:1611.07004. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised Learning of Depth and Ego-Motion from Video. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Honolulu, HI, USA, 2017; pp. 6612–6619. [Google Scholar]
- Gordon, A.; Li, H.; Jonschkowski, R.; Angelova, A. Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unknown Cameras. arXiv 2019, arXiv:1904.04998. [Google Scholar]
- Luo, X.; Huang, J.-B.; Szeliski, R.; Matzen, K.; Kopf, J. Consistent Video Depth Estimation. arXiv 2020, arXiv:2004.15021. [Google Scholar] [CrossRef]
- Patil, V.; Van Gansbeke, W.; Dai, D.; Van Gool, L. Don’t Forget the Past: Recurrent Depth Estimation from Monocular Video. arXiv 2020, arXiv:2001.02613. [Google Scholar]
- Teed, Z.; Deng, J. DeepV2D: Video to Depth with Differentiable Structure from Motion. arXiv 2020, arXiv:1812.04605. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Providence, RI, USA, 2012; pp. 3354–3361. [Google Scholar]
- Yoon, J.H.; Park, M.-G.; Hwang, Y.; Yoon, K.-J. Learning Depth from Endoscopic Images. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Québec City, QC, Canada, 16–19 September 2019; IEEE: Québec City, QC, Canada, 2019; pp. 126–134. [Google Scholar]
- Ma, R.; Wang, R.; Pizer, S.; Rosenman, J.; McGill, S.K.; Frahm, J.-M. Real-Time 3D Reconstruction of Colonoscopic Surfaces for Determining Missing Regions. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2019; Lecture Notes in Computer Science; Shen, D., Liu, T., Peters, T.M., Staib, L.H., Essert, C., Zhou, S., Yap, P.-T., Khan, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11768, pp. 573–582. ISBN 978-3-030-32253-3. [Google Scholar]
- Khan, F.; Salahuddin, S.; Javidnia, H. Deep Learning-Based Monocular Depth Estimation Methods—A State-of-the-Art Review. Sensors 2020, 20, 2272. [Google Scholar] [CrossRef] [Green Version]
- Garg, R.; BG, V.K.; Carneiro, G.; Reid, I. Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue. arXiv 2016, arXiv:1603.04992. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised Monocular Depth Estimation with Left-Right Consistency. arXiv 2017, arXiv:1609.03677. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. arXiv 2016, arXiv:1506.02025. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, C.; Qi, C.; Song, S.; Xiao, F. Unsupervised Monocular Depth Estimation Method Based on Uncertainty Analysis and Retinex Algorithm. Sensors 2020, 20, 5389. [Google Scholar] [CrossRef]
- Yin, Z.; Shi, J. GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose. arXiv 2018, arXiv:1803.02276. [Google Scholar]
- Mun, J.-H.; Jeon, M.; Lee, B.-G. Unsupervised Learning for Depth, Ego-Motion, and Optical Flow Estimation Using Coupled Consistency Conditions. Sensors 2019, 19, 2459. [Google Scholar] [CrossRef] [Green Version]
- Shu, C.; Yu, K.; Duan, Z.; Yang, K. Feature-Metric Loss for Self-Supervised Learning of Depth and Egomotion. arXiv 2020, arXiv:2007.10603. [Google Scholar]
- Guizilini, V.; Ambrus, R.; Pillai, S.; Raventos, A.; Gaidon, A. 3D Packing for Self-Supervised Monocular Depth Estimation. arXiv 2020, arXiv:1905.02693. [Google Scholar]
- Vasiljevic, I.; Guizilini, V.; Ambrus, R.; Pillai, S.; Burgard, W.; Shakhnarovich, G.; Gaidon, A. Neural Ray Surfaces for Self-Supervised Learning of Depth and Ego-Motion. arXiv 2020, arXiv:2008.06630. [Google Scholar]
- Grossberg, M.D.; Nayar, S.K. A General Imaging Model and a Method for Finding Its Parameters. In Proceedings of the Proceedings Eighth IEEE International Conference on Computer Vision, ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; IEEE Computer Society: Vancouver, BC, Canada, 2001; Volume 2, pp. 108–115. [Google Scholar]
- Palafox, P.R.; Betz, J.; Nobis, F.; Riedl, K.; Lienkamp, M. SemanticDepth: Fusing Semantic Segmentation and Monocular Depth Estimation for Enabling Autonomous Driving in Roads without Lane Lines. Sensors 2019, 19, 3224. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Learning | Method | Backbone | Abs Rel | Sq Rel | RMSE | RMSElog | |||
|---|---|---|---|---|---|---|---|---|---|
| S | Rau [14] | 0.054 | - | - | - | - | - | - | |
| SS | Freedman [6] | Resnet18 | 0.168 | - | - | - | - | - | - |
| Monodepth2 [17] | Resnet18 | 0.163 | 2.157 | 10.134 | 0.211 | 0.784 | 0.941 | 0.979 | |
| Packnet-SfM [37] | Resnet18 | 0.121 | 1.150 | 7.957 | 0.165 | 0.868 | 0.966 | 0.988 | |
| FBNet | Resnet18 | 0.108 | 1.060 | 7.369 | 0.149 | 0.904 | 0.974 | 0.991 | |
| Monodepth2 | Resnet50 | 0.123 | 1.357 | 7.710 | 0.157 | 0.880 | 0.969 | 0.989 | |
| Packnet-SfM | Resnet50 | 0.115 | 1.086 | 7.570 | 0.160 | 0.886 | 0.971 | 0.989 | |
| FBNet | Resnet50 | 0.098 | 0.751 | 6.432 | 0.134 | 0.919 | 0.981 | 0.993 | |
| Packnet-SfM | Packnet | 0.116 | 1.091 | 7.806 | 0.159 | 0.884 | 0.971 | 0.990 | |
| FBNet | Packnet | 0.096 | 0.843 | 7.147 | 0.139 | 0.912 | 0.977 | 0.992 |
| Method | Backbone | Abs Rel | Sq Rel | RMSE | RMSElog | |||
|---|---|---|---|---|---|---|---|---|
| FBNet | Resnet50 | 0.098 | 0.751 | 6.432 | 0.134 | 0.919 | 0.981 | 0.993 |
| FBNet w/o Depth Reconstruction Loss | 0.102 | 0.875 | 7.093 | 0.147 | 0.908 | 0.978 | 0.992 | |
| FBNet w/o Depth Feedback Network | 0.107 | 0.824 | 6.453 | 0.146 | 0.906 | 0.973 | 0.989 | |
| Baseline | 0.115 | 1.086 | 7.57 | 0.16 | 0.886 | 0.971 | 0.989 | |
| FBNet | Packnet | 0.096 | 0.843 | 7.147 | 0.139 | 0.912 | 0.977 | 0.992 |
| FBNet w/o Depth Reconstruction Loss | 0.1 | 0.846 | 7.144 | 0.143 | 0.909 | 0.978 | 0.992 | |
| FBNet w/o Depth Feedback Network | 0.106 | 1.029 | 7.941 | 0.146 | 0.894 | 0.975 | 0.992 | |
| Baseline | 0.116 | 1.091 | 7.806 | 0.159 | 0.884 | 0.971 | 0.99 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hwang, S.-J.; Park, S.-J.; Kim, G.-M.; Baek, J.-H. Unsupervised Monocular Depth Estimation for Colonoscope System Using Feedback Network. Sensors 2021, 21, 2691. https://doi.org/10.3390/s21082691
Hwang S-J, Park S-J, Kim G-M, Baek J-H. Unsupervised Monocular Depth Estimation for Colonoscope System Using Feedback Network. Sensors. 2021; 21(8):2691. https://doi.org/10.3390/s21082691
Chicago/Turabian StyleHwang, Seung-Jun, Sung-Jun Park, Gyu-Min Kim, and Joong-Hwan Baek. 2021. "Unsupervised Monocular Depth Estimation for Colonoscope System Using Feedback Network" Sensors 21, no. 8: 2691. https://doi.org/10.3390/s21082691
APA StyleHwang, S.-J., Park, S.-J., Kim, G.-M., & Baek, J.-H. (2021). Unsupervised Monocular Depth Estimation for Colonoscope System Using Feedback Network. Sensors, 21(8), 2691. https://doi.org/10.3390/s21082691