
Statistical and Machine Learning Models for Classification of Human Wear and Delivery Days in Accelerometry Data


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Processing
2.2. Model Development and Validation
3. Results
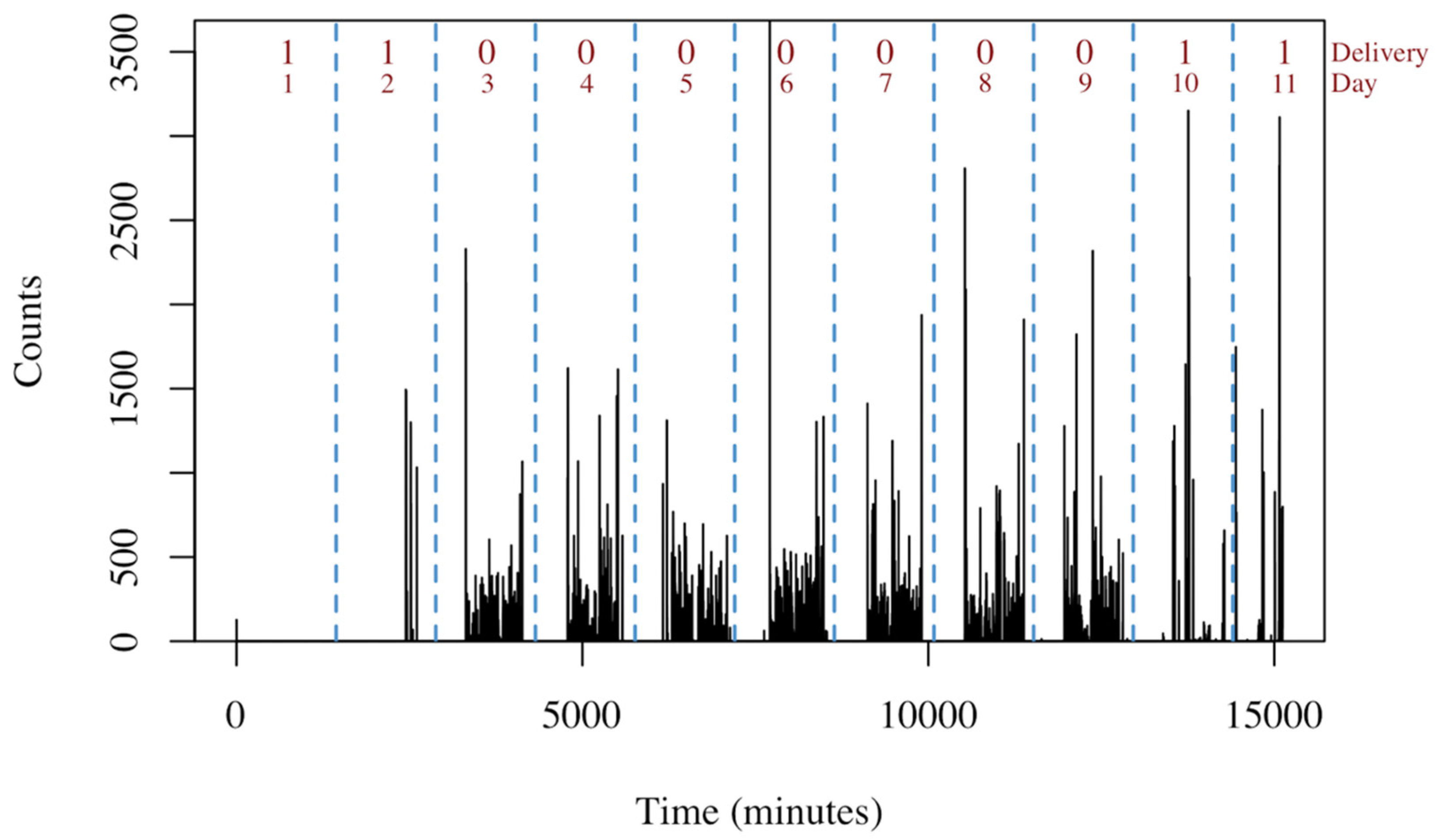
3.1. Data Description
3.2. Model Performance
4. Discussion
4.1. Model Performance
4.2. Limitations
4.3. Implementation
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Lee, I.-M.; Shiroma, E.J. Using accelerometers to measure physical activity in large-scale epidemiological studies: Issues and challenges. Br. J. Sports Med. 2014, 48, 197–201. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kohl, H.W.; Craig, C.L.; Lambert, E.V.; Inoue, S.; Alkandari, J.R.; Leetongin, G.; Kahlmeier, S. Lancet Physical Activity Series Working Group. The pandemic of physical inactivity: Global action for public health. Lancet 2012, 380, 294–305. [Google Scholar] [CrossRef] [Green Version]
- Benzo, R. Activity Monitoring in Chronic Obstructive Pulmonary Disease. J. Cardiopulm. Rehabil. Prev. 2009, 29, 341–347. [Google Scholar] [CrossRef] [PubMed]
- Coronado, R.A.; Robinette, P.E.; Henry, A.L.; Pennings, J.S.; Haug, C.M.; Skolasky, R.L.; Riley, L.H.; Neuman, B.J.; Cheng, J.S.; Aaronson, O.S.; et al. Bouncing back after lumbar spine surgery: Early postoperative resilience is associated with 12-month physical function, pain interference, social participation, and disability. Spine J. 2020, 21, 55–63. [Google Scholar] [CrossRef]
- Bagala, F.; Becker, C.; Cappello, A.; Chiari, L.; Aminian, K.; Hausdorff, J.M.; Zijlstra, W.; Klenk, J. Evaluation of accelerometer-based fall detection algorithms on real-world falls. PLoS ONE 2012, 7, e37062. [Google Scholar] [CrossRef] [Green Version]
- Staudenmayer, J.; Pober, D.; Crouter, S.; Bassett, D.; Freedson, P. An artificial neural network to estimate physical activity energy expenditure and identify physical activity type from an accelerometer. J. Appl. Physiol. 2009, 4, 1300–1307. [Google Scholar] [CrossRef]
- Keadle, S.K.; Shiroma, E.J.; Freedson, P.S.; Lee, I.-M. Impact of accelerometer data processing decisions on the sample size, wear time and physical activity level of a large cohort study. BMC Public Health 2014, 14, 1210. [Google Scholar] [CrossRef] [Green Version]
- Van Dyck, D.; Cerin, E.; De Bourdeaudhuij, I.; Hinckson, E.; Reis, R.S.; Davey, R.; Sarmiento, O.L.; Mitas, J.; Troelsen, J.; MacFarlane, D.; et al. International study of objectively measured physical activity and sedentary time with body mass index and obesity: IPEN adult study. Int. J. Obes. 2015, 39, 199–207. [Google Scholar] [CrossRef] [Green Version]
- Troiano, R.P.; Berrigan, D.; Dodd, K.W.; Mâsse, L.C.; Tilert, T.; McDowell, M. Physical activity in the United States measured by accelerometer. Med. Sci. Sports Exerc. 2008, 40, 181–188. [Google Scholar] [CrossRef]
- Choi, L.; Liu, Z.; Matthews, C.E.; Buchowski, M.S. Validation of Accelerometer Wear and Nonwear Time Classification Algorithm. Med. Sci. Sports Exerc. 2011, 43, 357–364. [Google Scholar] [CrossRef] [Green Version]
- Choi, L.; Ward, S.C.; Schnelle, J.F.; Buchowski, M.S. Assessment of Wear/Nonwear Time Classification Algorithms for Triaxial Accelerometer. Med. Sci. Sports Exerc. 2012, 44, 2009–2016. [Google Scholar] [CrossRef] [Green Version]
- Winkler, E.A.G.; Paul, A.; Healy Genevieve, N.; Clark Bronwyn, K.; Sugiyama Takemi Matthews Charles, E.; Owen Neville, G. Distinguishing true sedentary from accelerometer non-wearing time: Accuracy of two automated wear-time estimations. Med. Sci. Sports Exerc. 2009, 41, 171–172. [Google Scholar] [CrossRef]
- Kim, E.; Helal, S.; Cook, D. Human Activity Recognition and Pattern Discovery. IEEE Pervasive Comput. 2010, 9, 48. [Google Scholar] [CrossRef] [Green Version]
- Lara, O.D.; Labrador, M.A. A Survey on Human Activity Recognition using Wearable Sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity recognition using cell phone accelerometers. SIGKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ellis, K.; Kerr, J.; Godbole, S.; Lanckriet, G.; Wing, D.; Marshall, S. A random forest classifier for the prediction of energy expenditure and type of physical activity from wrist and hip accelerometers. Physiol. Meas. 2014, 35, 2191–2203. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Haffner, P.; Bottou, L.; Bengio, Y. Object Recognition with Gradient-Based Learning. In Shape, Contour and Grouping in Computer Vision; Springer: Berlin, Germany, 1999; pp. 319–345. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Ignatov, A. Real-time human activity recognition from accelerometer data using Convolutional Neural Networks. Appl. Soft Comput. 2018, 62, 915–922. [Google Scholar] [CrossRef]
- Ordóñez, F.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fridriksdottir, E.; Bonomi, A.G. Accelerometer-Based Human Activity Recognition for Patient Monitoring Using a Deep Neural Network. Sensors 2020, 20, 6424. [Google Scholar] [CrossRef] [PubMed]
- Santos, G.L.; Endo, P.T.; de Monteiro, K.H.C.; da Rocha, E.S.; Silva, I.; Lynn, T. Accelerometer-Based Human Fall Detection Using Convolutional Neural Networks. Sensors 2019, 19, 1644. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Archer, K.R.; Haug, C.M.; Pennings, J. Combining Two Programs to Improve Disability, Pain, and Health Among Patients Who Have Had Back Surgery; Patient-Centered Outcomes Research Institute (PCORI): Washington, DC, USA, 2020. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.; Woo, W.C. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. arXiv 2015, arXiv:1506.04214. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Brier, G.W. Verification of Forecasts Expressed in Terms of Probability. Mon. Weather Rev. 1950, 78, 1–3. [Google Scholar] [CrossRef]
- Chiu, J.P.C.; Nichols, E. Named Entity Recognition with Bidirectional LSTM-CNNs. Trans. Assoc. Comput. Linguist. 2016, 4, 357–370. [Google Scholar] [CrossRef]
- Choi, L.; Beck, C.; Liu, Z.; Matthews, C.E.; Buchowski, M.S. Physical Activity Process Accelerometer Data for Physical Activity Measurement. R Package Version 0.2-4. 2021. Available online: https://CRAN.R-project.org/package=PhysicalActivity (accessed on 12 April 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Minimally Processed | Fully Processed |
|---|---|
| Zeropad days with <1440 min | Zeropad days to = 1440 min |
| Remove days with <5000 total counts Remove days with <120 min human activity Remove days with <10 min delivery activity |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moore, R.; Archer, K.R.; Choi, L. Statistical and Machine Learning Models for Classification of Human Wear and Delivery Days in Accelerometry Data. Sensors 2021, 21, 2726. https://doi.org/10.3390/s21082726
Moore R, Archer KR, Choi L. Statistical and Machine Learning Models for Classification of Human Wear and Delivery Days in Accelerometry Data. Sensors. 2021; 21(8):2726. https://doi.org/10.3390/s21082726
Chicago/Turabian StyleMoore, Ryan, Kristin R. Archer, and Leena Choi. 2021. "Statistical and Machine Learning Models for Classification of Human Wear and Delivery Days in Accelerometry Data" Sensors 21, no. 8: 2726. https://doi.org/10.3390/s21082726