1. Introduction
In the traditional network, a plenty of network functions are relying on dedicated hardware deployment to form a variety of network services, this traditional deployment method can no longer meet the complex and changeable network requirements with the rapid growth of the number and diversity of network service requests. However, the emergence of network function virtualization (NFV) technology has solved that problem [
1]. NFV makes network equipment functions no longer depend on dedicated equipment through software and hardware decoupling and function abstraction, in addition, NFV can reduce the high cost of network equipment by sharing network resources fully and flexibly. Moreover, NFV can realize the rapid development and deployment of new business, and realize automatic deployment, elastic scaling, fault isolation and self-healing of new business, etc. [
2]. In NFV, several virtualized network functions (VNF) form a sequence of network functions that can handle specific network services by deploying on server nodes in a certain order, which is named as service function chain (SFC) [
3]. As an important form of network and service, the SFC can construct a complete end-to-end network service through rational orchestration of VNFs [
4].
Reliable deployment is an important concern for many SFCs, the traditional SFC deployment method relies on the routing strategy formulated by service providers, that makes network traffic go through several VNFs in a certain order to provide the required network functions [
5]. However, there are some defects need be solved. First, the method is lack of certain tolerance measure which is quite important for SFC deployment, so that it’s difficult to meet the reliable deployment requirements of SFC. Secondly, different SFC’s priority is not the same because of difference in resource requirements, so simple strategy is hard to meet all deployment requirements. Last but not least, it’s difficult to response active and complex SFC deployment requirements because VNF is pre-deployed on server node in traditional network, so that the VNFs are not flexible to satisfy the SFCs.
In view of the dynamic and reliable deployment of the service function chain, the existing deployment methods have some shortcomings. Previously, most SFC deployment models only solve the problem which is determining deployment location or achieving optimization targets [
6,
7,
8,
9]. However, the reliability requirements have increased with the development of NFV and increasing of SFC requests. To this end, reliable and fault-tolerant SFC deployment methods are proposed to achieve high reliability [
10,
11,
12,
13,
14,
15]. Specifically, reliable SFC deployment methods usually use backup scheme to deploy more VNF instances on different network nodes. However, traditional backup scheme is too simple to satisfy complex SFC requests. On the other hand, more advanced and powerful reinforcement learning models have significantly achieved performance gains in SFC deployment problem recently [
16,
17,
18]. However, Q-learning, a classical algorithm of reinforcement learning, needs to maintain a quite large Q-table because of large state and action set, so that the computing power of the algorithm will be affected with wasting of CPU and memory. To this end, the deep reinforcement learning which is more advanced than reinforcement learning is proposed to apply on SFC deployment problem [
19,
20,
21,
22]. Specifically, the deep reinforcement learning can choose better deployment and backup locations with learning process, and it can make accurate judgements about unknown situations in the sample.
To solve the dynamic and reliable SFC deployment problem, this paper formulates the reliable SFC deployment framework and proposes a novel priority awareness deep reinforcement learning (PA-DRL) algorithm to deploy and backup VNFs with high reliability and optimization performance. The main contributions of this paper are as follows.
Firstly, we propose the priority awareness framework to determine the priority of SFC and network node. On one hand, we calculate the SFC priority by average proportion of CPU resource and bandwidth resource requirements. On the other hand, we calculate the network node priority by average proportion of node resources and node degrees. It is the first time that determining the overall priority through SFC and node priority in our work.
Secondly, we design a determining scheme of backup location set for VNF. The determining scheme can predetermine the backup location set by SFC and node priority which are mentioned above. Specifically, the scheme can decide whether to backup and guarantee that deployment and backup locations are different of each VNF.
Lastly, we apply deep reinforcement learning algorithm on the process of VNF deployment and backup, then we propose PA-DRL model to deploy and backup VNFs with reliability requirement. Specifically, we design the feedback function with three factors including transmission delay, node balancing, and link balancing. Then, we evaluate the proposed PA-DRL model on the network topology which is randomly generated, and the extensive experimental results demonstrate that PA-DRL can effectively deploy SFC requests and achieve deployment performance compared with other four models including two widely used SFC deployment methods and other two backup schemes of PA-DRL.
The rest of this paper is organized as follows.
Section 2 surveys the related works. In
Section 3, the priority awareness framework used for determining backup scheme is described and then the proposed PA-DRL algorithm to solve reliable SFC deployment is discussed in details. In
Section 4, the experimental designs and simulation results are shown. Finally, the conclusion and discussion of future work are given in
Section 5.
2. Related Works
In the early studies, SFC deployment problem is usually modeled as an optimization problem, which is most solved by integer linear programming (ILP) and heuristic algorithm. On the one hand, a part of the author uses ILP algorithm or its deformation to solve the SFC deployment optimization problem. For example, Insun Jang et al. proposed a polynomial time algorithm based on linear relaxation and rounding to approximate the optimal solution of the mixed ILP [
6]. Although they increased SFC acceptance rate and the service capacity, yet more optimization targets are needed, including transmission delay, load balancing and so on. Zhong et al. orchestrated SFCs across multiple data centers and proposed an ILP model to minimize the total cost [
7]. They reduced the overall cost, however, the optimization result is too simple to apply in most cases. Although the ILP as a statical algorithm can solve most SFC deployment optimization problem, yet it is difficult to apply on dynamic and complex SFC requests. On the other hand, other authors solve the optimization problem by heuristic algorithm. For example, Li et al. described the SFC deployment as a multi-objective and multi-restriction problem and proposed a heuristic service function chain deployment algorithm based on longest function assignment sequence [
8]. Although they jointly optimized the number of VNF deployment and link bandwidth requirements, yet they ignored the dynamicity of the network. Mohammad Ali Khoshkholghi et al. formulated a multi-objective optimization model to joint VNF placement and link embedding in order to reduce deployment cost and service latency, then proposed two heuristic-based algorithms that perform close to optimal for large scale cloud/edge environments to solve the optimization problem [
9]. They optimized both cost and delay, however, the method was needed to improve to apply in dynamic network environment. Heuristic algorithm can solve the SFC deployment problem which is NP-hard effectively, however, the heuristic algorithm is easy to fall into the local optimum, and the parameter setting is affected by the experience value, the number of algorithm iterations and convergence speed are difficult to guarantee.
More recently, reinforcement learning and deep reinforcement learning models have shown their superior capabilities in SFC deployment due to their advanced feature extraction and data modeling abilities. For example, Wei et al. designed a service chain mapping algorithm based on reinforcement learning to reduce the average transmission delay and improve the load balancing, the algorithm determined location of each VNF according to the network status and reward value of feedback function after the deployment [
16], however, they did not improve the reliability of SFC which is significant in current network. Sang Il Kim et al. considered the consumption of CPU and memory resources, then utilized reinforcement learning to solve SFC optimization problem dynamically [
17], yet the algorithm was not satisfied with delay sensitive SFC. Sebastian Troia et al. investigated the application of reinforcement learning for performing dynamic SFC resources allocation in NFV-SDN enabled metro-core optical networks [
18], they decided how to reconfigure the SFCs according to state of the network and historical traffic traces. However, reinforcement learning exists the limitation that it cannot satisfy the networks which has large-scale states. To this end, deep reinforcement learning is proposed to solve the large-scale SFC deployment problem. For example, Fu et al. decomposed the complex VNFs into smaller VNF components to make more effective decisions and proposed a deep reinforcement learning-based scheme with experience replay [
19], although they solved dynamic and complex SFC deployment problem effectively, yet more optimization targets and reliability needed to be considered. Li et al. proposed an adaptive deep Q-learning based SFC mapping approach to improve CPU and bandwidth resource utilization rates [
20], they improved whole system resource efficiency, however, they ignored the transmission delay in SFC deployment problem. Pei et al. used deep reinforcement learning to improve network performance, including SFC acceptance rate, throughput, end-to-end delay, and load balancing [
21], the method optimized a variety of objectives, however, the SFC reliability was not considered in the optimization process, which may lead to SFC failure. Although these researches have solved the large-scale SFC deployment problem effectively, yet they ignored the reliability of SFC, and cannot satisfy to recovery SFC after network failure.
For reliability and fault-tolerance, several reliable SFC deployment models are proposed to achieve high reliability. For example, Francisco Carpio and Admela Jukan improved service reliability using jointly replications and migrations, and then proposed a N2N algorithm based on LP to improve reliability and network load balancing [
10]. However, N2N cannot solve dynamic SFC requests effectively, and it cannot guarantee performance of transmission delay in results. Abdelhamid Alleg et al. proposed a reliable placement solution of SFC modeled as a mixed ILP program, they designed the SFC availability level as a target and reduce the inherent cost which is affected by diversity and redundancy [
11]. However, the proposed model is only applied on statical placement and lack of adaptability of machine learning techniques, on the other hand, the algorithm does not distinguish SFC priority, so that all SFC requests applied the same scheme which would lead to low effective utilization of CPU resources. Tuan-Minh Pham et al. designed the UNIT restoration model and the PAR protection algorithm based on ILP framework, the proposed algorithms protect SFC requests from network failures in terms of both resource restoration and recovery time efficiently [
12]. Although the model achieves robustness of network, yet it does not guarantee the delay in a service demand, moreover, the solution needs to consider the dynamic parameters of online demands. Mohammad Karimzadeh-Farshbafan et al. proposed a polynomial time sub-optimal algorithm named VRSP which is based on mixed ILP in multi-infrastructure network provider environment [
13]. However, VRSP solves the reliable SFC deployment problem only by statical method, moreover, VRSP does not consider transmission delay and network balancing in the optimization process. Qu et al. formulated the reliable SFC deployment problem as a mixed ILP and proposed a delay-aware hybrid shortest path-based heuristic algorithm [
14]. Although they achieved high reliability and low latency through the model based on ILP and heuristic algorithm, yet the model is too simple to satisfy complex SFC deployment because it does not distinguish the priority of SFC, and the algorithm cannot predict deploy and backup scheme of unknown SFC requests accurately. Ye et al. proposed a novel heuristic algorithm to efficiently address the joint topology design and mapping of reliable SFC deployment problem [
15]. However, the model does not consider the delay and load balancing as optimization targets, and heuristic algorithm is easy to fall into the local optimum unlike machine learning algorithm such as reinforcement learning and deep reinforcement learning. Mao et al. proposed a deep reinforcement learning based online SFC placement method to guarantee seamless redirection after failures and ensure service reliability [
22]. Although the model automatically deploys both active and standby instances in real-time, yet it does not distinguish the priority of SFC and cannot guarantee transmission delay and network load balancing. Motivated by it, this paper will for the first-time design priority-awareness model, then applies deep reinforcement learning to solve reliable SFC deployment problem in NFV framework.
3. The Proposed PA-DRL Framework
In this section, we first formulate the reliable SFC deployment problem. Next, we discuss the priority awareness framework of SFC and network node in details, and then describe the rules for determining backup scheme of each VNF. Finally, the proposed deployment and backup algorithm based on deep reinforcement learning is explained.
3.1. Reliable SFC Deployment Formulation
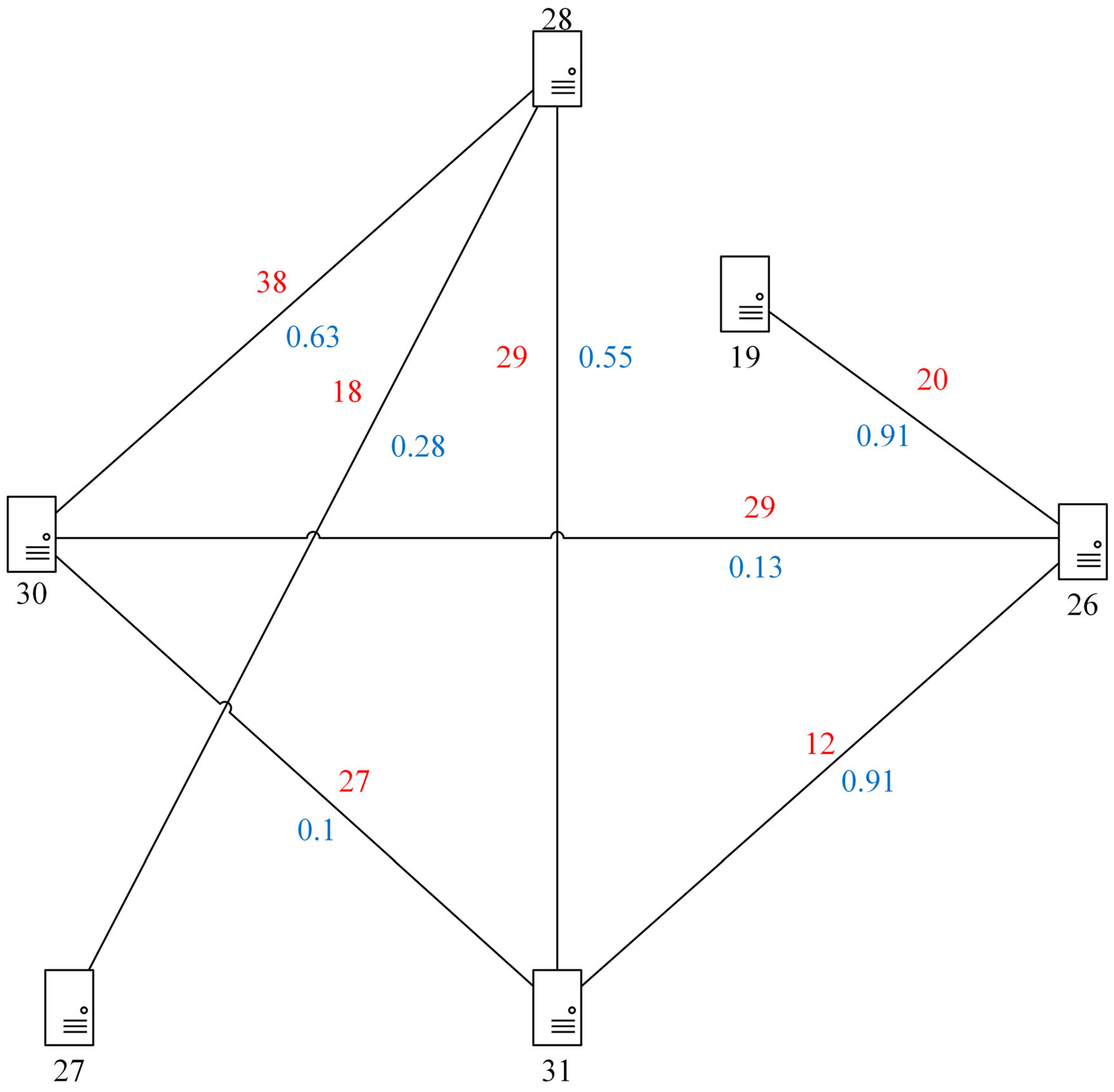
The reliability of SFC deployment is aimed to find a suitable backup scheme for each VNF. In this work, we define the physical network topology as an undirected graph, which is represented as , where is the set of network nodes and , E denotes the set of links that connect two network nodes directly and . In addition, we define the set of SFC requests as , and each SFC request consists of several different VNFs and virtual links between two adjacent VNFs.
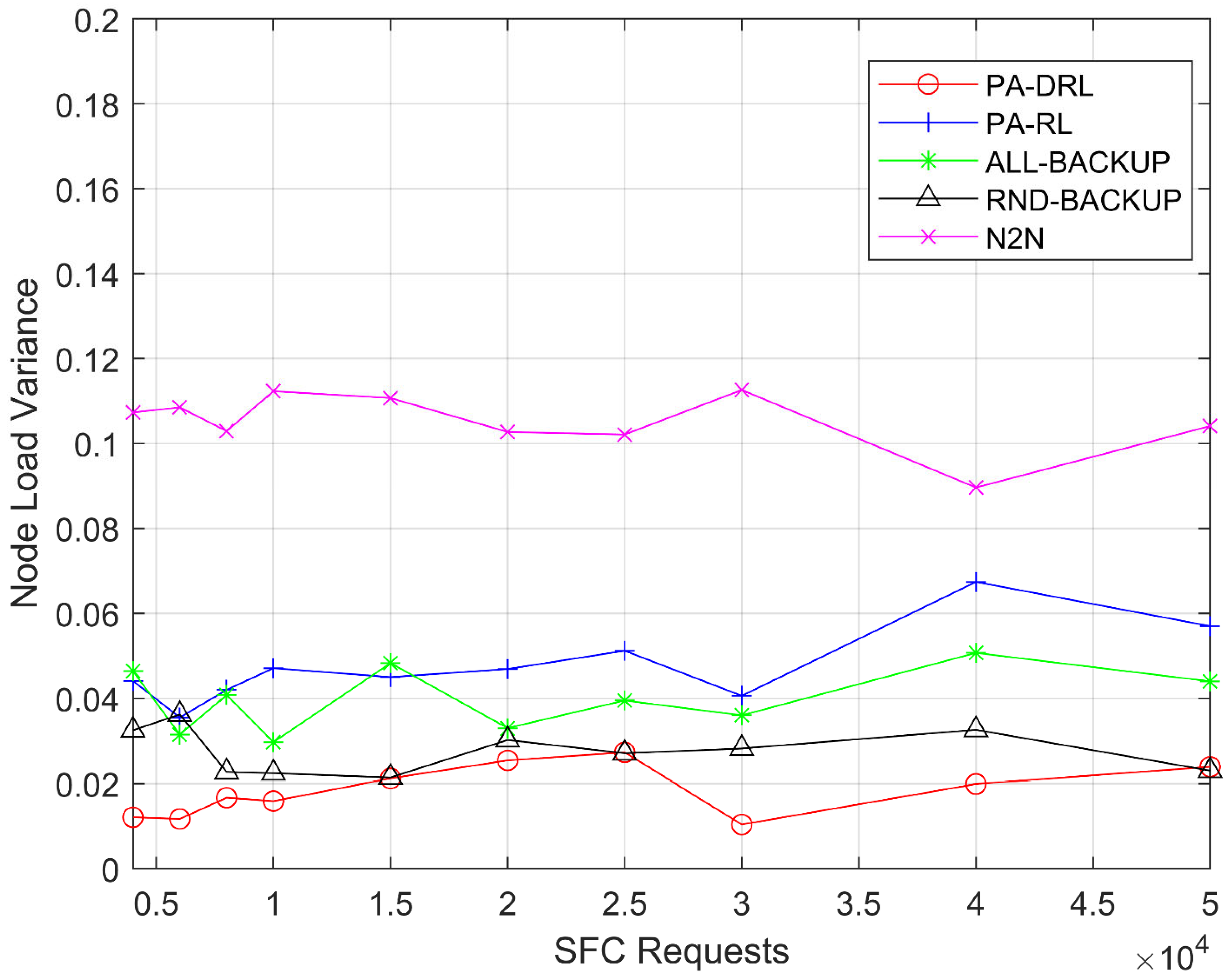
Because network hosts VNF and virtual link via CPU and bandwidth resources respectively, therefore we mainly consider CPU resources on network nodes and bandwidth resources on physical links. Due to the difference of computing power requirements, we assume that the number of CPUs occupied by different VNF is not same. Similarly, we assume that the amount of bandwidth resources occupied by different virtual link is different too. Moreover, in order to quantify the network load balancing, we define variance of CPU’ percentage occupied on all network nodes as an indicator,
where
and
indicate remaining and total vCPU resources on node
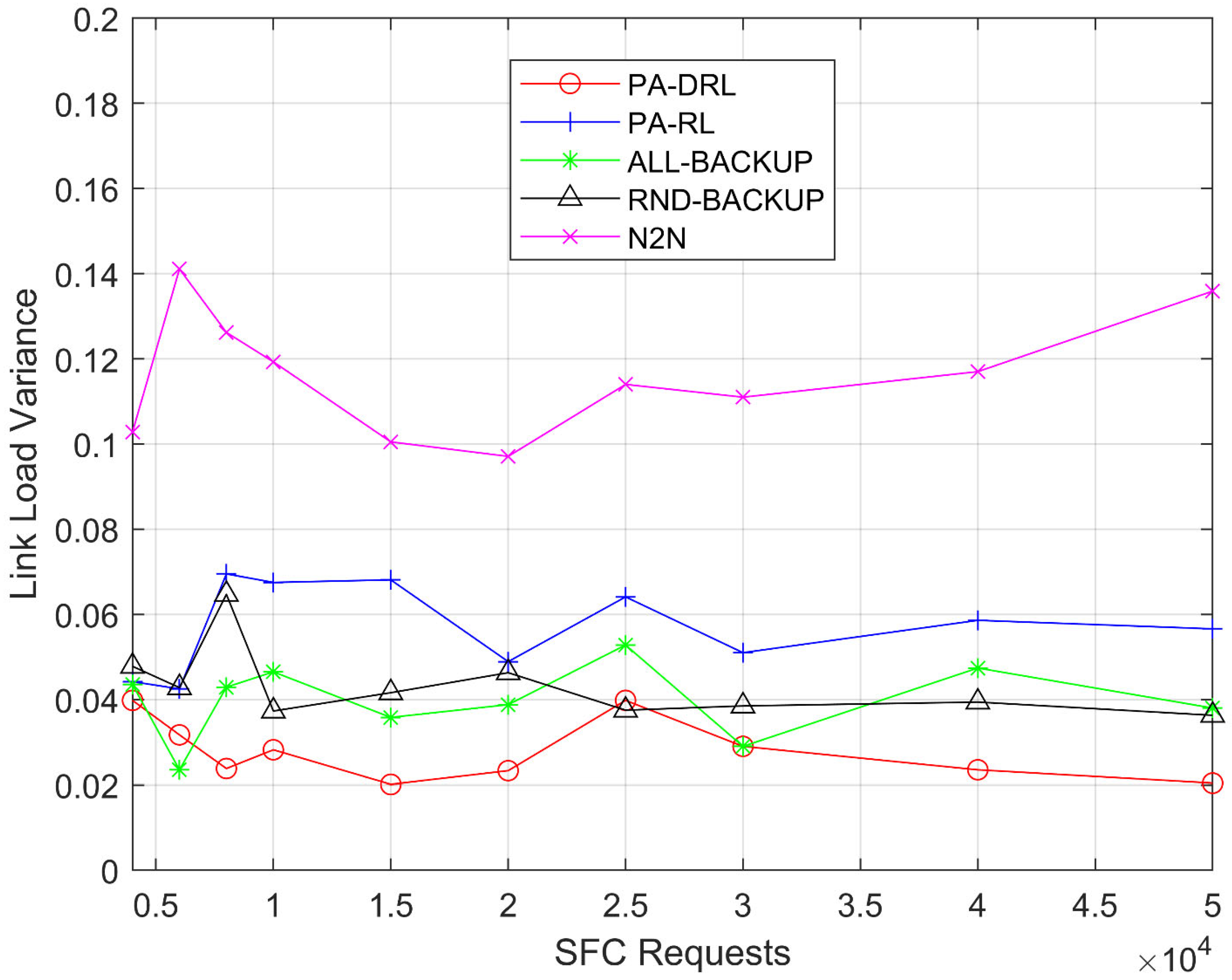
respectively. And then, we define variance of bandwidth’ percentage occupied on all physical links as an indicator too,
where
and
indicate remaining and total bandwidth resources on link
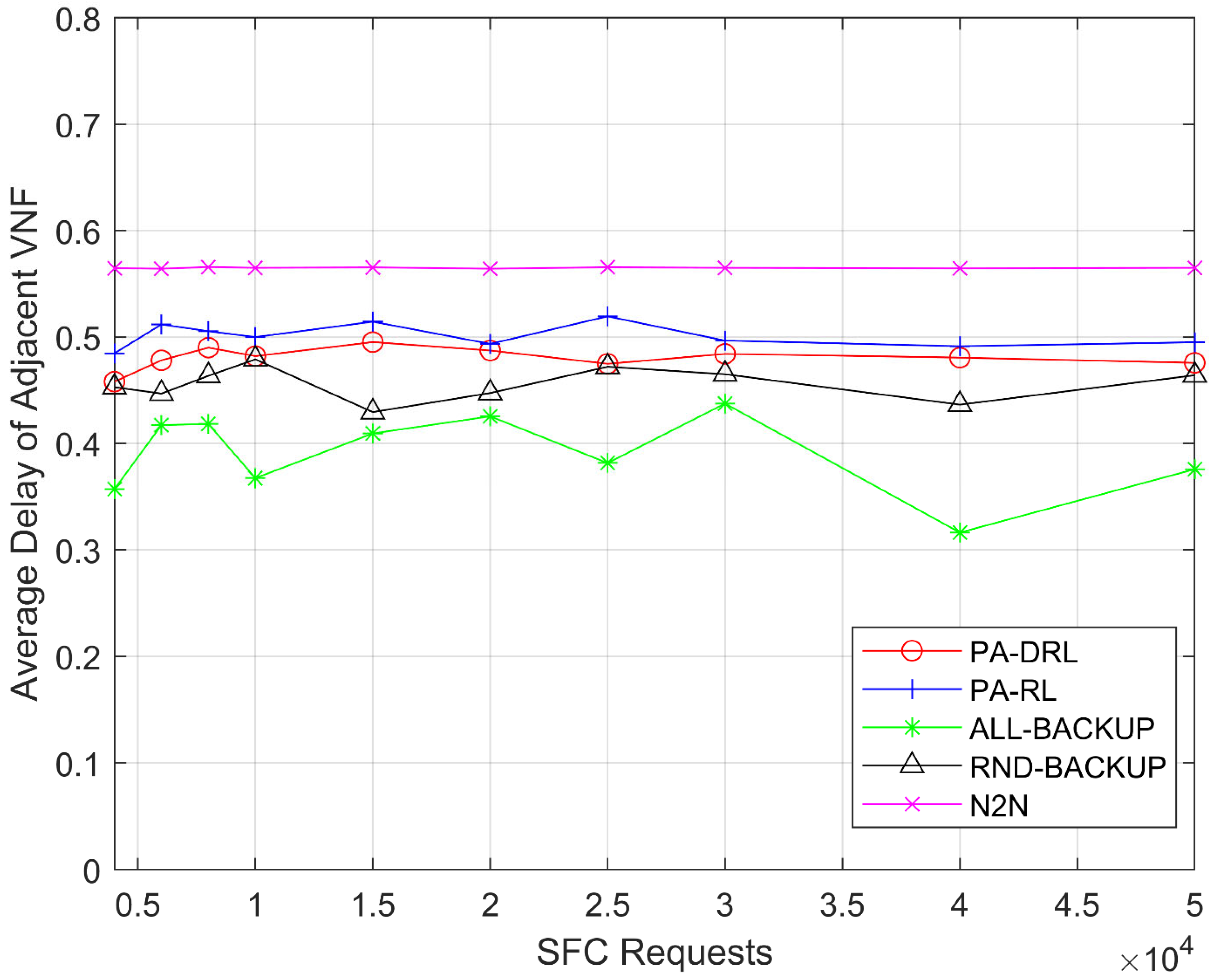
respectively. In addition, SFCs consist of several different VNFs, so the length of SFCs may has a difference, as a result the delay of different SFCs will be quite different. For that reason, we use average delay of adjacent VNFs to measure the performance of delay optimization,
where
denotes the length of
, and
represents the delay between VNF
and
. Besides, there are limits of the network resources, it means that the resource on each node and link is non-negative and no more than the maximum resource limit.
3.2. Priority Awareness of SFC and Network Node
Priority awareness is aimed to determine the important level of SFC and node through resource requirements and network status. Firstly, the algorithm determines the priority of SFC in high, medium, and low levels. Then, the algorithm judges the priority of nodes according to the network status. Finally, the model decides whether to allocate CPU resources to each VNF’s backup. The algorithm determines the backup scheme of each VNF through these steps, then, the deployment algorithm will deploy each VNF and its backup.
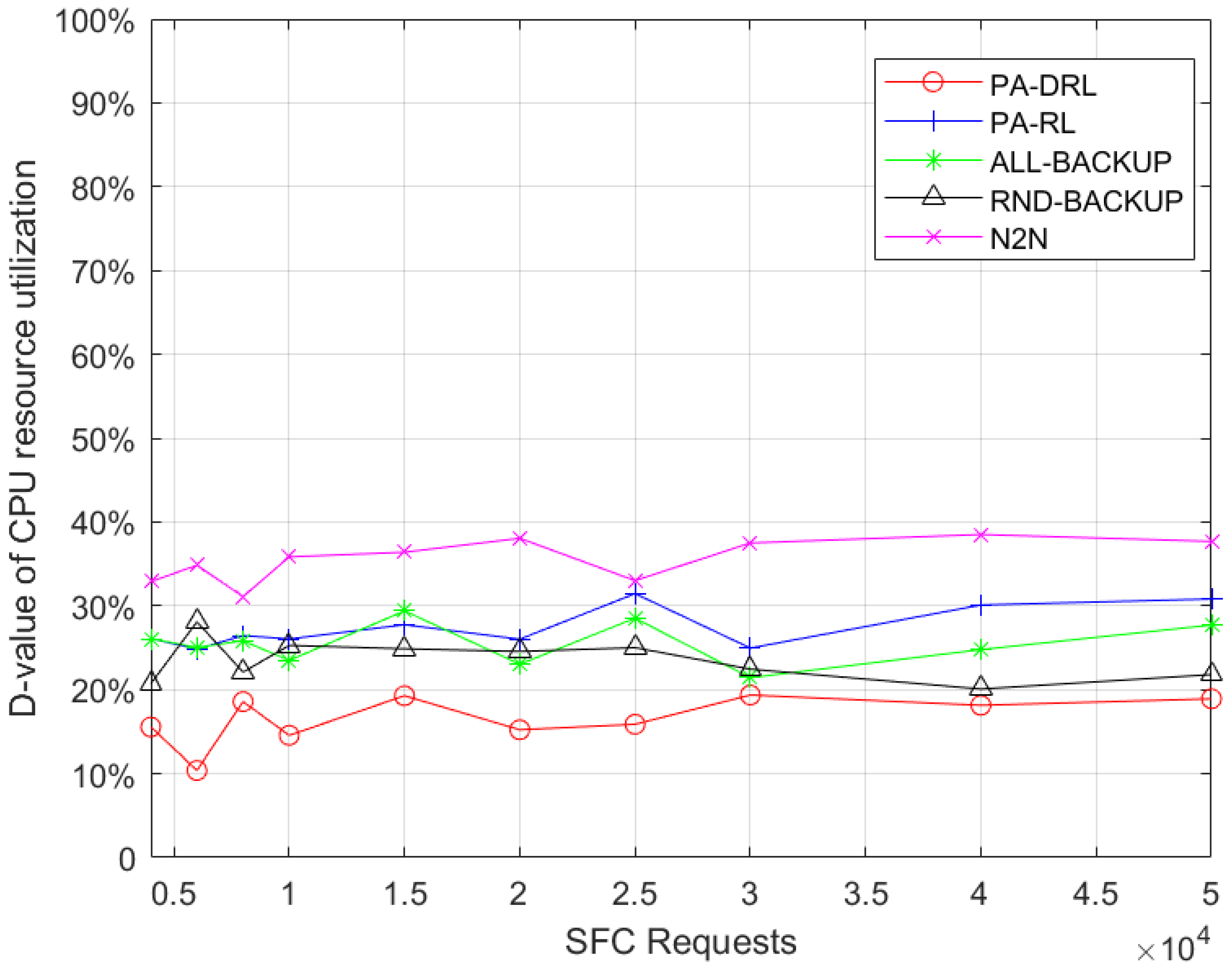
In this work, we define effective resource utilization as the proportion of deployment resources and backup resources, which is expressed as,
where
and
denote CPU resources which are occupied by VNF’s deployment and backup respectively. To improve the effective utilization of resource on network nodes, we propose the process of priority awareness, which aims to choose a suitable backup scheme for each VNF.
At first, we use the number of required resources to measure a SFC’s priority, which is defined as,
where
denotes the required CPU resources of VNF
,
denotes the required bandwidth resources of virtual link between
and
,
and
denote the maximum required CPU and bandwidth resources of all SFCs respectively.
Secondly, we use the resource state and node degree to measure a node’s priority, which is defined as,
where
denotes the node degree of node
.
Finally, we divide SFC into three priority levels, including high, medium, and low respectively. Specifically, the SFC has high priority level if , then the SFC has low priority level if , otherwise, the SFC has medium priority level. Further, we divide network node into two priority levels, including high and low respectively. Specifically, the node has high priority level if , otherwise its priority level is low.
3.3. Rules for Determining Backup Scheme
The backup scheme is choosing whether to backup for each VNF in our work, we define
as the node pair of deployment and backup node for each VNF, so that
if the VNF had no backup, otherwise
, besides, there is a constraint
to guarantee that each VNF’s deployment and backup nodes are different.
Table 1 presents the backup scheme in different situations, including three SFC’s priority levels and two node’s priority levels as mentioned above. Specifically, when SFC priority is high or SFC priority is medium and node priority is high, VNF is backed up, otherwise, when SFC priority is low or SFC priority is medium and node priority is low, VNF is not backed up.
3.4. Deep Reinforcement Learning Deployment Algorithm
Deep reinforcement learning algorithm aims to solve the problem which has large-scale state and action set. In this work, we define the state set as,
where
and
denote the remaining resources of all nodes and links at time
respectively, and
denotes the related information of VNF at time
, including current deployment location, species of VNF at time
, and the species of next VNF at time
. We define action set as the node pair
as mentioned before, which is represented as,
so, the number of all actions is
.
We aim to optimize the transmission delay of SFC and network load balancing, including load balancing of nodes and links. To this end, we optimize all optimization targets by minimizing the maximum value of delay, node, and link load balancing, so we define the feedback function as,
where
are the weight coefficients, and need to meet this constraint,
At first, we initialize all the parameter
of neural network. Then we choose action through
method, which is defined as,
where
is the exploration times. Finally, we store a 5-tuple
in replay memory buffer
after every action selection, where
is a binary indicates whether the state is terminated,
The network randomly selects several samples from
in each episode, then the
value will be calculated by,
where
is the parameter of neural network, which will be updated in each episode by backward gradient propagation, and
represents the learning rate. The training algorithm for our model is as Algorithm 1.
| Algorithm 1 PA-DRL training algorithm |
| Input: SFC request with the requirement of VNFs and virtual links |
| Output: Deployment and backup locations for each VNF of SFC |
| Initialize the neural network with the parameter , and clear the replay memory buffer . |
| whiledo |
| Calculate SFC priority level as (6) |
| Calculate node priority level as (7) |
| Determine action set by Table 1 |
| Select action by method |
| Calculate reward as (10) |
| Store the sample in memory |
| Randomly select samples from then calculate as (14) |
| Train the network and update by using back propagation of the loss function |
| end while |
5. Conclusions
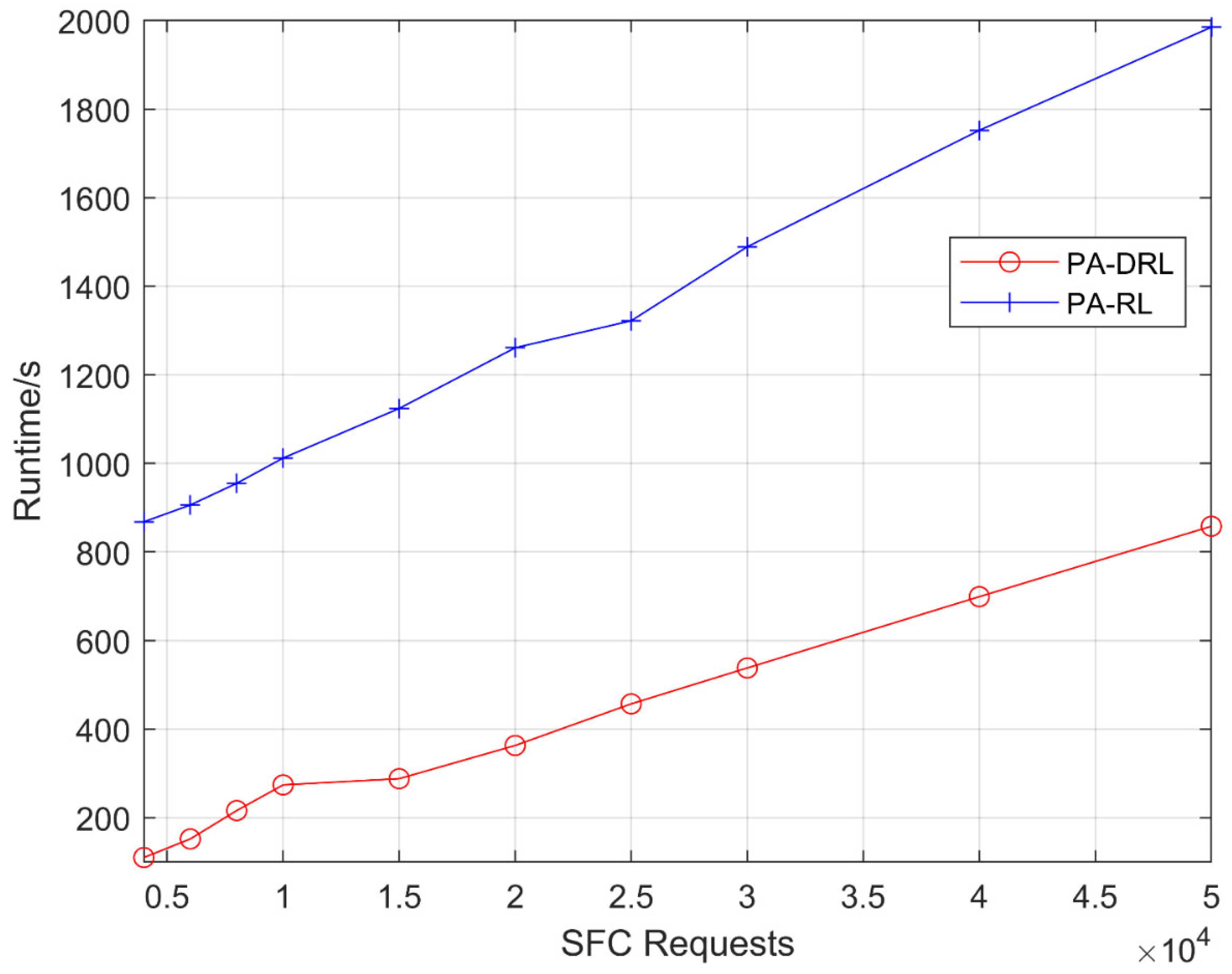
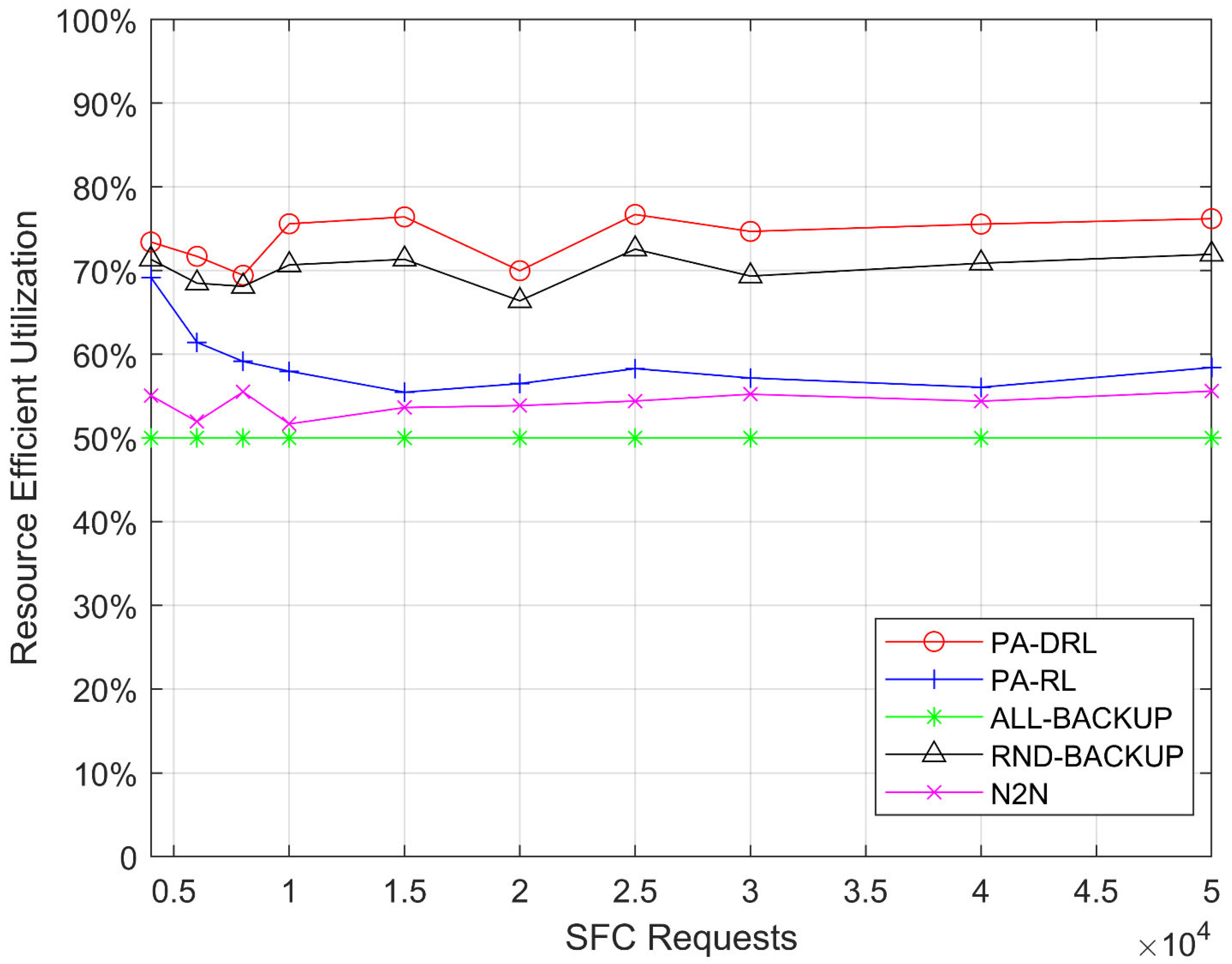
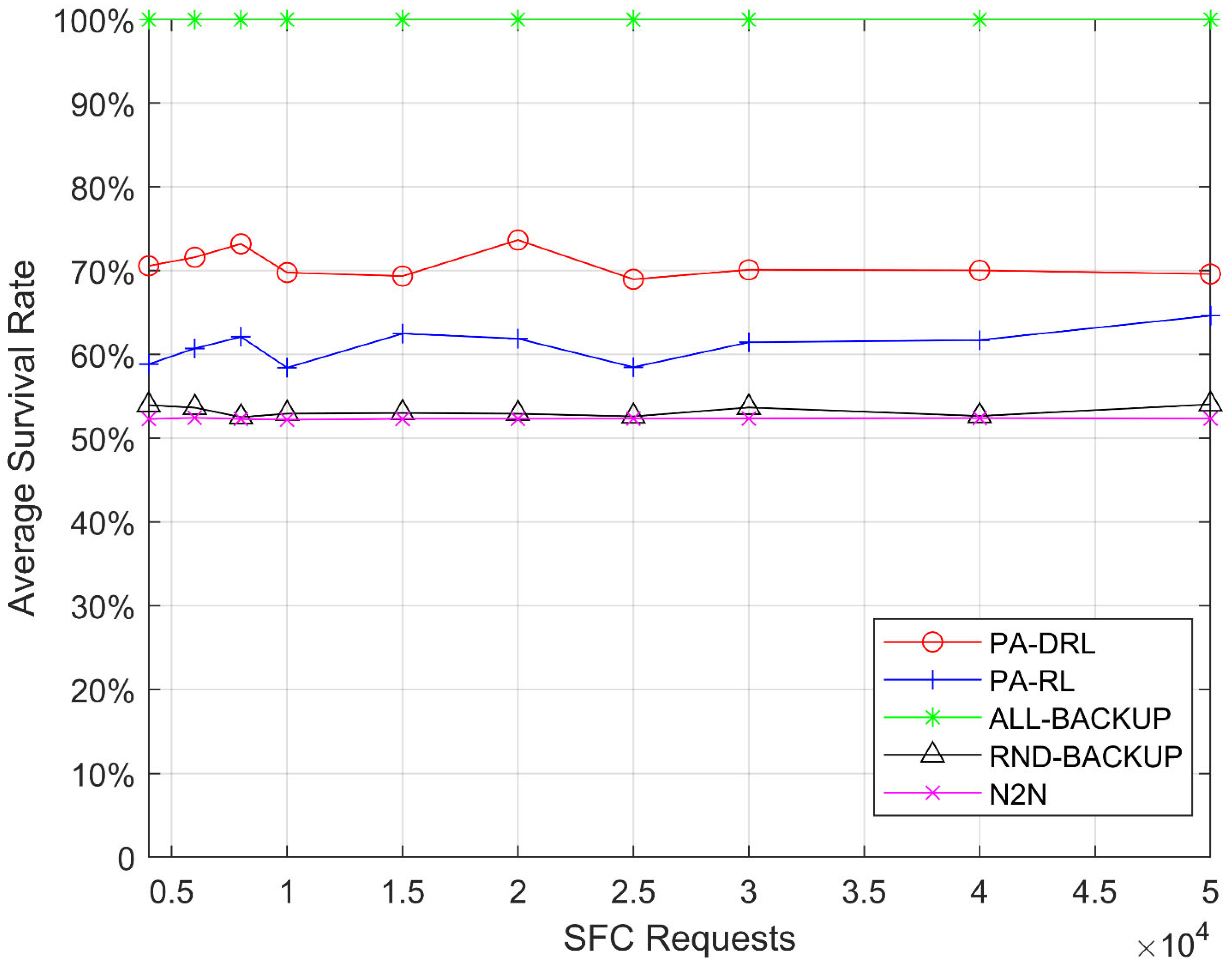
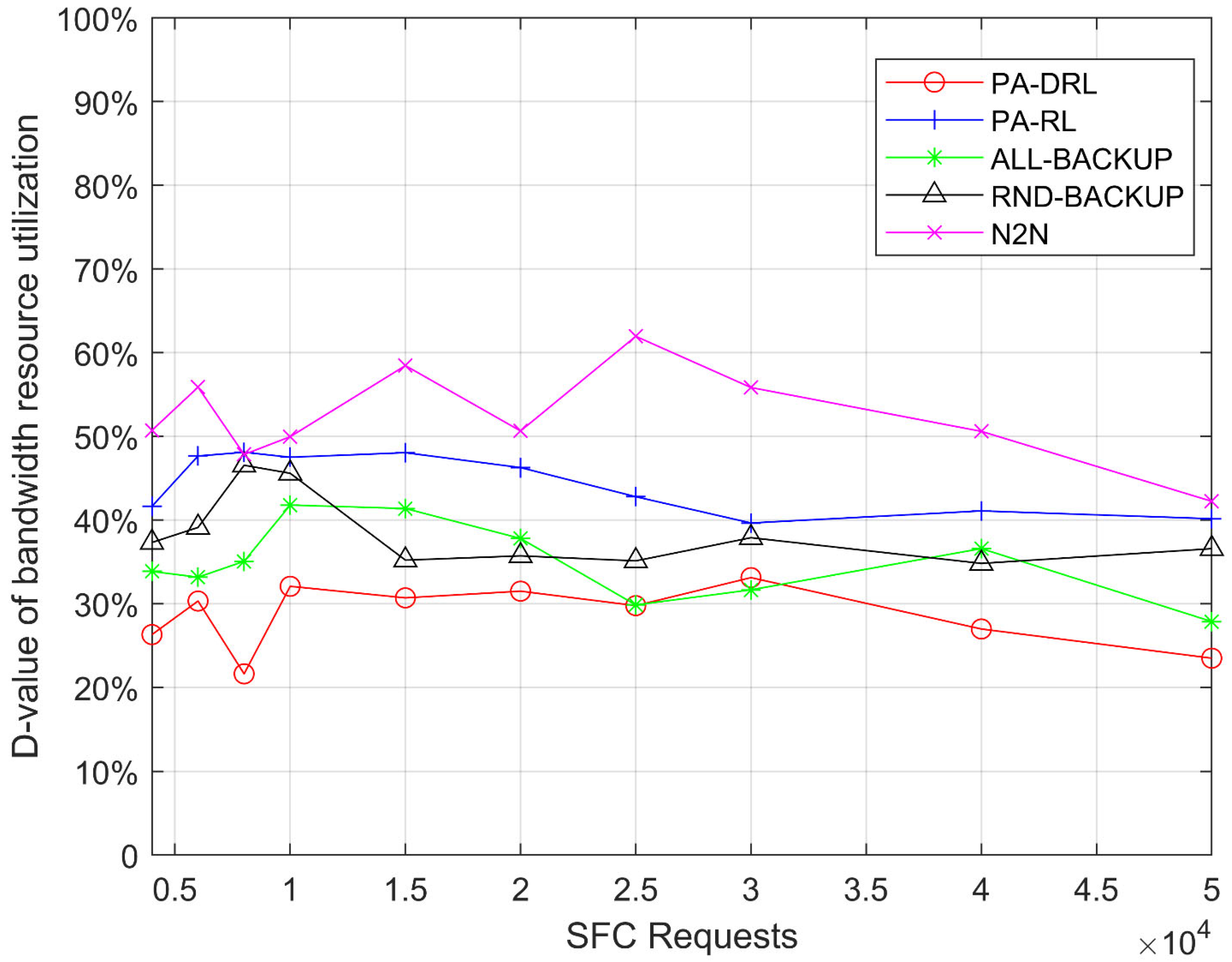
In this paper, we propose a novel PA-DRL for reliable SFC deployment. PA-DRL determines the backup scheme through the priority of SFC and network node, then PA-DRL use deep reinforcement learning algorithm to choose deployment and backup locations of VNF, and update the neural network dynamically. The results show that compared with the other four models (ALL-BACKUP, RND-BACKUP, PA-RL, and N2N), PA-DRL can improve the reliability of SFC and the efficient utilization of CPU resource. In addition, PA-DRL uses delay and network load balancing as feedback factors, so that it can reduce the transmission delay, and improve the load balancing of nodes and links to a certain extent.
Although our proposed PA-DRL method can achieve reliable SFC deployment, there are still some shortcomings that need to be resolved. At first, the PA-DRL deploys SFCs on the network topology which is designed in our work, the experiment results show that the performance of PA-DRL is better than others, however the network topology is too small to have limitations. Therefore, the PA-DRL model need to apply on another expanded network topology. Secondly, the parameters of neural network and deep reinforcement learning are designed through minor adjustments, including hidden layers, neurons number of neural networks, and weight coefficients of deep reinforcement learning, we can’t guarantee the performance is the best. Therefore, we need to adjust the parameters through more experimental comparison. Finally, we will apply PA-DRL method on actual network environment, deploy our algorithm on hardware devices to achieve the experimental results in line with actual conditions.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}