1. Introduction
Object detection is currently used in various applications, such as autonomous vehicles [
1], face detection [
2], medical imaging [
3], and security [
4]. Recently, the development of the convolutional neural networks (CNNs) concept [
5,
6,
7,
8] and the availability of large-scale datasets [
9,
10] have considerably improved the performance of object detection [
11,
12,
13,
14,
15,
16]. Researchers have expended numerous efforts to boost performance in various ways, such as optimizer design [
17,
18,
19], modification of architecture [
20], and scale variations [
21,
22] for computer vision. A fundamental approach used to effectively boost performance is based on the design of a good network. Since the introduction of the first deep neural network AlexNet [
5] in 2012, various architectures have emerged, including the visual geometry group network (VGGNet) [
6], GoogLeNet [
7], and residual neural network (ResNet) [
8]. With the development of graphics processing unit (GPU) power, these networks have yielded significant performance boosts by stacking the convolutional layers deeper, depending on their design choices. This allows us to obtain high-level semantic features that are extracted from the deep convolutional layers. These networks are being used in several computer vision models for applications such as object tracking [
23], domain adaptation [
24], and object detection.
The single-shot multibox detector (SSD) [
15] has achieved high performance in detection accuracy and speed. The SSD algorithm was proposed to solve the problem of low-detection accuracy of the you-only-look-once (YOLO) model [
14]. In SSD, the main goal is to detect multiple objects in an image. When detecting the objects, the object bounding box is predicted by prior boxes at different scales and aspect ratios followed by the generation of the feature map by CNN and the classification and regression of the objects in an image. The input image enters the network and then goes through the convolutional layers. Detection is performed using feature maps of different sizes in each of the six layers. The main idea of the SSD is to detect large objects based on the low-resolution feature maps of the deep layers, and detect small objects using the high-resolution feature maps of the shallow layers. The SSD detects large objects accurately, but its accuracy of small object detection is lower. We inferred that this problem is caused by two reasons, as described below.
First, in deep learning, the high-resolution feature maps of the shallow layers tend to contain fewer semantic information compared with the feature maps of the deep layers. This is attributed to the fact that the high-resolution feature maps pass through fewer convolutional layers compared with the feature maps of the deep layers. The methods employed to solve this problem in previous studies [
25,
26] involved the generation of a feature fusion module or the modification of the feature extraction network to develop an improved model. One of these studies [
25] created the trident feature and squeeze and excitation feature fusion modules to add semantic information to the feature maps of the shallow layers. Another study [
26] changed the network to DenseNet and used the residual prediction block. However, the problem associated with these methods relates to the detection speed degradation owing to the use of the complex network and the addition of complicated feature fusion modules. In order to extract more semantic information while concurrently maintaining the detection speed, we propose a lightweight feature map concatenation stream that splits the channels of the input feature map in half and performs three convolution operations on one of the half maps. Low-rank approximation is a representative method of compressing feature maps, which simplifies the network by reducing the parameter dimensions. Most methods [
27,
28] minimize the reconstruction error of original parameters to approximate a tensor. However, since these methods utilize the weight sparsity, they are useful when was applied to a limited resource environment such as a mobile platform, and the output feature map deviates far from the original values because errors tend to accumulate when multiple layers are compressed sequentially. Low-rank approximation has greatly improved the speed of CNNs, but it tends to decrease the accuracy. Also, the model cannot get a big gain in speed unless we apply it to the backbone of the SSD. However, our approach is to insert a module called enhanced map block (EMB) between the layers of the SSD, leaving the backbone of the SSD intact, therefore the low-rank approximation is not applied in our approach. Instead, we only use half of the weights of the feature map for convolutional layers to suppress the number of parameters increased by convolution. In this manner, the amount of learning is halved, compared to general convolution. Finally, the feature map that passed through the convolutional layers and the other feature map are concatenated with each other using skip connection.
Second, low-level features extracted from the shallow layers activate edges or background in an image. At this point, we have concluded that if the model can focus on an object, it can detect the region where small objects are captured. To execute this approach, we propose an efficient attention mechanism stream that employs the importance map. The importance map is produced by channel-wise average pooling and a sigmoid activation function. In this way, the pixels of the input feature map are averaged and then normalized to (0, 1). When generating the importance map, the model does not perform convolution operations. In this stream, the model only performs two simple operations with no additional learning. Therefore, it prevents degradation in the detection speed. Finally, we multiply the importance map and concatenated map element-wise, and add it to the input feature map. In this way, we propose the enhanced map block (EMB), which efficiently and effectively detects small objects.
In this study, an improved single-shot multibox detector (SSD) is proposed that employs novel and effective EMBs, called SSD-EMB. Although we used ideas from other methods, we created a new type of block, called the EMB, and applied it to the network to improve the accuracy without decreasing the detection speed. Object detectors using other types of feature map blocks have been studied. In [
29], the feature extraction capability of the model was improved by integrating four inception blocks in an SSD. Each inception block consists of eight convolutional layers and a concatenation layer. Ding et al. [
30] used four dense blocks in their SSD to enhance the features by integrating the features of the shallow layer and the features of the deep layer. These dense blocks contain eight convolutional layers and four concatenation layers, and they increase the network complexity and detection time. However, the proposed EMB is constructed more simply than other feature map blocks. We evaluate the efficiency of EMB on the detection task. Experimental datasets are the PASCAL visual object classes (VOC) 2007, the PASCAL VOC 2012 [
31], and the MS COCO [
10]. Our model is compared with the conventional object detection models, such as the faster region-based CNN (R-CNN) [
13], YOLO [
14], and SSD [
15]. The overall architecture of SSD-EMB is shown in
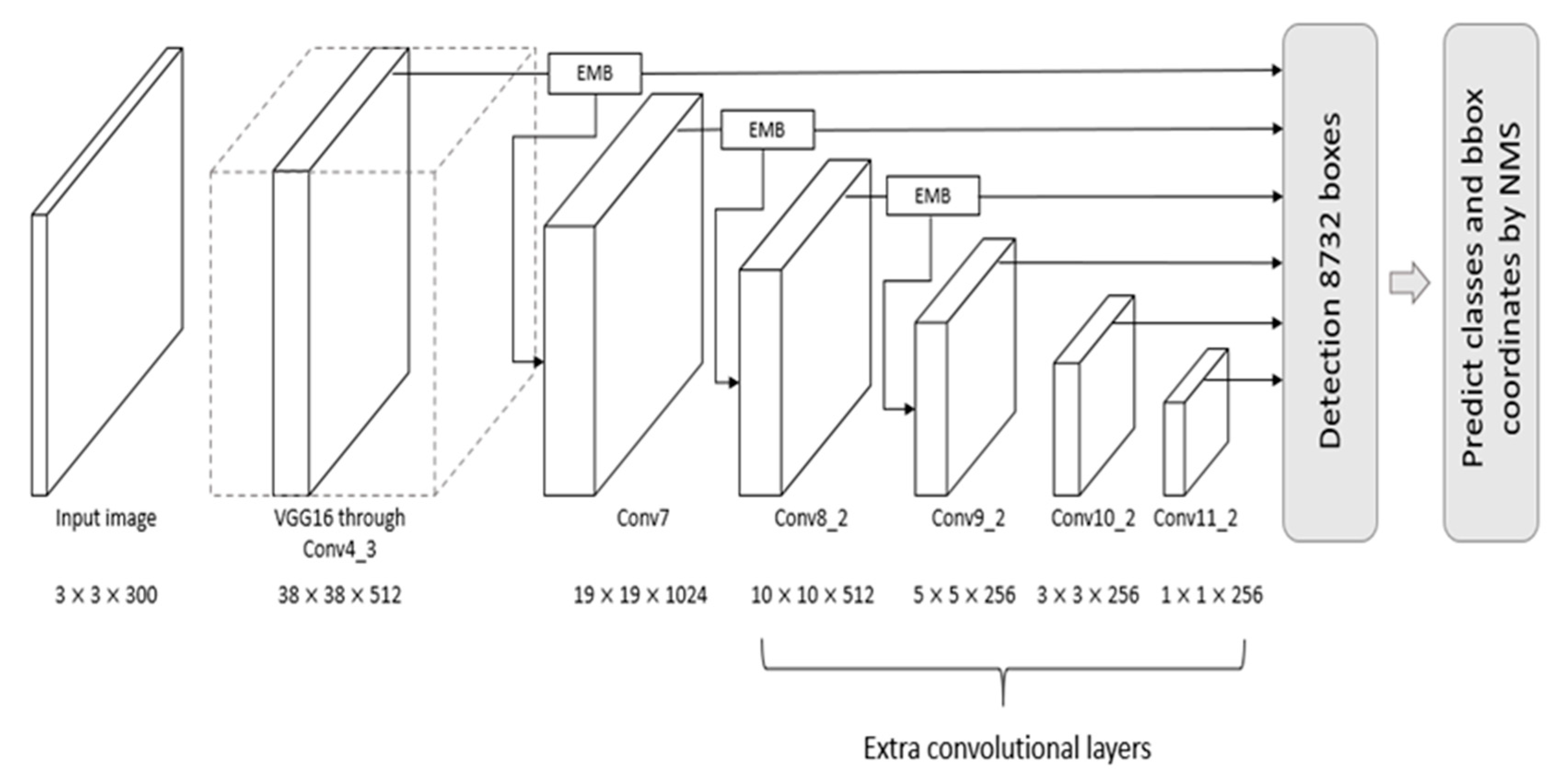
Figure 1. A detailed block diagram of the EMB is shown in
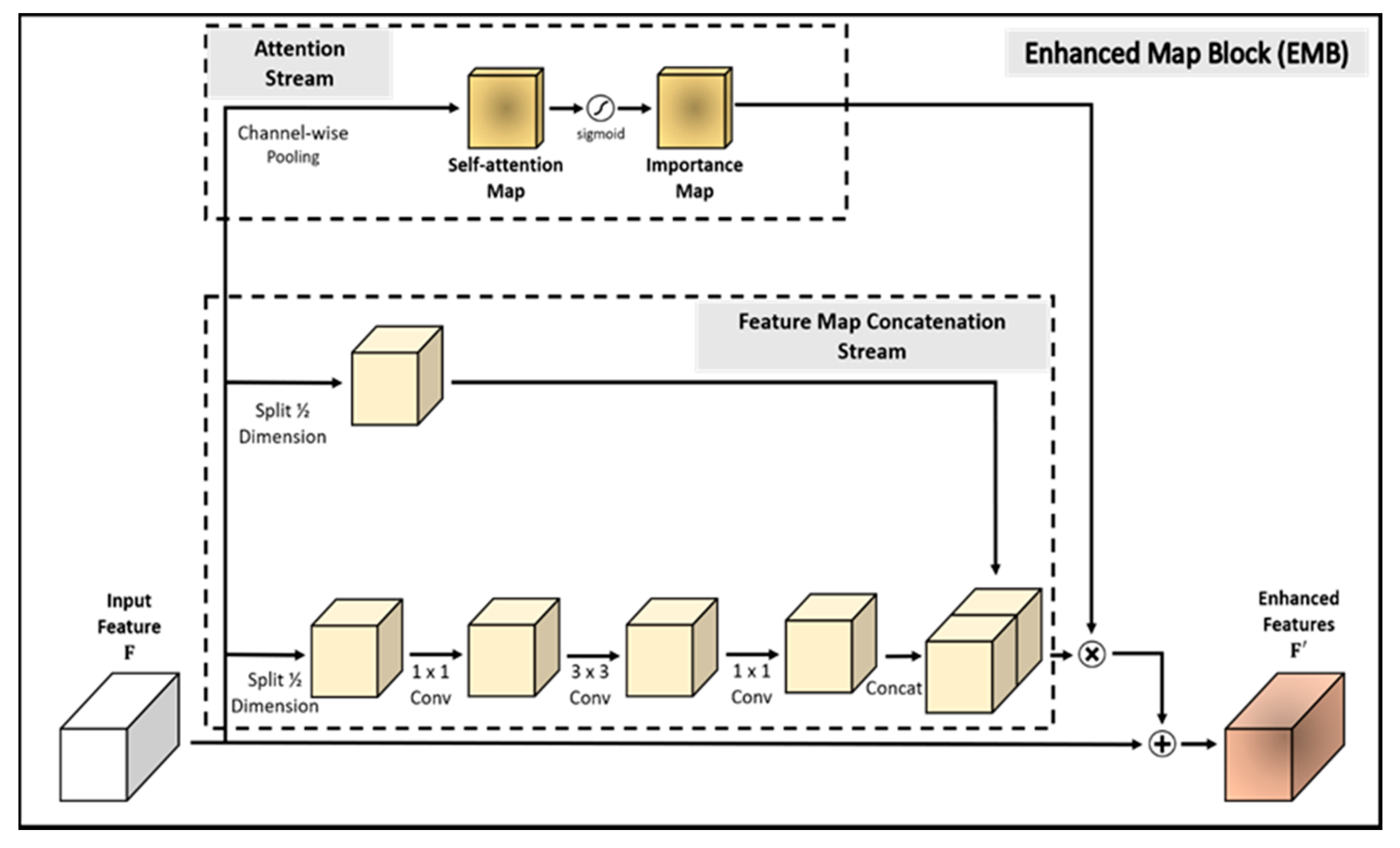
Figure 2. The main contributions of this study are as follows:
We propose a lightweight feature map concatenation stream, which consists of feature map split, three convolutional layers, and feature map concatenation.
We present an efficient attention mechanism stream that applies channel-wise average pooling and sigmoid activation function on the input feature map.
Combining the above two streams, the proposed model, SSD-EMB, solves the challenges associated with both small object detection and detection speed degradation.
We verify the effectiveness of the proposed model compared with various models (Faster R-CNN [
13], YOLO [
14], SSD [
15], etc.) based on the PASCAL VOC 2007, PASCAL VOC 2012, and MS COCO datasets. Our model detects objects with high accuracy and speed, and moreover, it effectively captures small objects.
The rest of this study is organized as follows:
Section 2 is a description of the related research.
Section 3 describes the proposed approach.
Section 4 shows the results of conducted experiments with the datasets and compares them to other models. The conclusions are listed in
Section 5.
3. Materials and Methods
In this section, we describe the proposed method in detail and introduce the evaluation datasets, metrics, and implementation details of the proposed model. The overall architecture of SSD-EMB and block diagram of EMB are shown in
Figure 1 and
Figure 2, respectively. Given an image, features are extracted by VGG [
6] and are sent to auxiliary convolutional layers. The six feature maps of different resolutions are generated in the layers of Conv4_3, Conv7, Conv8_2, Conv9_2, Conv10_2, and Conv11_2. The SSD utilizes these features independently to predict the classes and locations of objects. We add an EMB to the Conv4_3, Conv7, and Conv8_2 feature maps of the SSD300 to detect small objects, as shown in
Figure 1, and one more EMB to the Conv9_2 on the SSD512. Based on this approach, the feature maps, which applied the EMB, are used to obtain the final detection results by NMS. In this way, the feature map of the shallow layer includes the more semantic features, and small objects are accurately captured. The proposed method is constructed based on the attention stream and feature map concatenation stream. The former compresses the n-dimensional input feature map by channel-wise average pooling to produce the 1D self-attention map. The latter divides the channels of the input feature map in half, and executes the convolutions, and performs concatenation through skip connection. Feature maps enhanced by EMB are used as inputs to the subsequent convolutional layers of the network. By applying our block, we can efficiently detect small objects which can improve detection performance.
3.1. Attention Stream
In general, the high-resolution feature map of the shallow layer contains low-level features, as shown in the top of Conv3_1 of
Figure 3. However, the low-resolution feature map of the deep layer has high-level semantic features as shown in the top of the Conv5_3 of
Figure 3. The SSD employs three low-resolution feature maps and three high-resolution feature maps for object detection. In our model, the attention mechanism is used to focus the region of the object of the high-resolution feature maps activated by low-level features.
Specifically, in SSD300, EMB is applied to the feature map
on the Conv4_3, Conv7, Conv8_2 layers, as shown in
Figure 1. Note that
is the number of channels, and
and
are the height and width, respectively. First, the attention stream compresses all the channels of
by channel-wise average pooling, which sums all the pixels in the channels, and divides them by the number of channels to generate the self-attention map
. By averaging the pixel values of channels of the input feature map, a pixel with a high value is regarded as a high-level semantic feature. The produced map activates the object and the region around it. The importance map
is then produced by calculating a sigmoid activation function as shown in
Figure 2. In this way, the pixels in the importance map are normalized to (0, 1), smoothing out the transition of the pixel values of the feature map. Each pixel of the importance map close to 1 is regarded as the most discriminative part (foreground), while the pixel values close to 0 correspond to the less discriminative part (background). With these operations, the detector focuses on the object region. In brief, the importance map is computed as follows:
This component is inspired by [
40]. The attention stream simply averages pixels of channels and computes a sigmoid activation function. The importance map increases the localization accuracy of the model by a broader activation of the region where the object is located.
3.2. Feature Map Concatenation Stream
In general, the choice used to obtain more semantic information in the CNN-based models is to stack the convolutional layers deeper. Convolutional operation requires a lot of computation as the number of weights increases, which leads to the network complexity and to a slower detection speed. To address this problem, we propose to extract semantic features using only half weights of the input feature map, as shown in
Figure 2. To suppress the number of parameters increased via convolution, we split the input feature map in half to reduce the computational features and utilized a skip connection structure of ResNet. Therefore, the feature map concatenation stream splits the dimensions of the input feature map in half. One of the split feature maps
passes through three convolutional layers to extract more semantic features. Because the model uses half of the weights, the computational amount is reduced compared with the general convolutional operation. During this operation, there is no change in the feature map size. In the convolution operation, batch normalization and ReLU activation function are also performed. Finally, the other
is concatenated with the feature map
that has passed through the convolutional layers, as shown in
Figure 2. In brief, the concatenated feature map
is computed as follows:
where
denotes a convolutional operation,
denotes a concatenation operation,
are the split feature maps, respectively, and the superscripts denote the convolutional filter sizes. Generating a feature map in this stream is possible using half of the original convolution operation. We experimentally verified that splitting the input feature map in half is the most efficient approach, considering the trade-off between accuracy and speed. In this way, the model can efficiently detect small objects with preventing degradation in the detection speed.
3.3. Combination of Two Maps
After acquiring the importance map
and feature map concatenation
, we combine them to produce the final enhanced feature map
. The importance map
acts as an object-aware mask and is element-wise multiplied by the concatenated feature map
to generate an object-aware feature map. The final enhanced map
is created by adding the object-aware feature map and the original input feature map according to Equation (3). Note that the enhanced feature map
is used as an input of the next convolutional layer to share higher-level features compared with the existing model:
In this way, the SSD-EMB efficiently and effectively captures small objects. The EMB improves the detection accuracy and averts the detection speed of the model with simple extra computations. In addition, the proposed method can be plugged independently into each of the convolutional feature maps of the shallow layers.
3.4. Datasets and Evaluation Metrics
Two challenging and extensively used benchmark datasets in object detection, i.e., PASCAL VOC 2007 and 2012, are chosen to evaluate the proposed model. The PASCAL VOC datasets include 20 object categories. The PASCAL VOC 2007 and 2012 consist of 9963 and 22,531 images, respectively. For PASCAL VOC 2007, we used the VOC 2007 and 2012 trainval split (5011 images for 2007 and 11,540 images for 2012) to train our network and employed the test split (4952 images) for testing. To evaluate our model in VOC 2012, the model was trained with a total of 21,503 images of VOC 2007 trainval + test (9963 images) and VOC 2012 trainval (11,540 images). The proposed model was tested with the VOC 2012 test set (10,991 images).
We adopted the mean average precision (mAP) as the standard metric for object detection to evaluate our model in the test set. The metrics were obtained in accordance with the PASCAL VOC criterion in which the bounding box of a positive detection had an IoU > 0.5 with the ground truth annotation.
Finally, our model was tested on the MS COCO dataset. MS COCO consists of a total of 80 object categories and includes 118 k train images, 5 k validation images, and 20 k test images (test-dev). We used the train set for training and evaluated the detection results on test-dev 2015. Compared with PASCAL VOC, the MS COCO dataset contains more objects (small or general) in a single image. Therefore, COCO detection is a more difficult task.
3.5. Implementation Details
We adopted the SSD as our baseline detector. To evaluate the effectiveness in the same environment as the original SSD, our model also used the pre-trained VGG [
6] as a backbone. In this study, most training strategies, including data augmentation and optimization, follow the ones in [
15]. We plugged the EMB behind the convolutional layers. Our model was trained with 120,000 iterations for PASCAL VOC 2007. The batch size was set to 32 for SSD300 and SSD512 for PASCAL VOC 2007 and VOC 2012 based on consideration of our GPU specifications. The learning rate was
in the first 80,000 iterations,
in the next 20,000 iterations, and
in the remaining iterations in VOC 2007. In the VOC 2012 dataset, the number of training iterations increased to 150,000 because the amount of training images increased. The learning rate was
in the first 60,000 iterations,
in the next 60,000 iterations, and
in the remaining iterations. In the MS COCO dataset, the number of training iterations increased to 300,000 and the learning rate was
in the first 160,000 iterations,
in the next 40,000 iterations,
in the next 40,000 iterations, and
in the remaining iterations.
The entire network was optimized using stochastic gradient descent (SGD) with a momentum of 0.9 and a weight decay of 0.0005. In the training process, the proposed EMB was applied to the output of the three convolutional layers to capture small objects well, and other methods, such as data augmentation, were applied in the same manner as the original SSD. Other than those, there is no special treatment for small object detection alone. The loss function is a weighted sum of the localization loss (loc) and the confidence loss (conf). In object detection, the neural network must perform two tasks. We organize the two losses into a weighted sum so that one loss function does not wield too much influence. This means that if the localization loss is too large, the learning will be focused on localizing the object and the classification task will be vulnerable. We adjust this situation by defining the loss function as the form of a weighted sum. The weight term
is set to 1 by cross-validation. As in the other object detection literatures [
15,
26], the localization loss calculates the error between the predicted bounding box by our model and the ground-truth bounding box to determine how much the two boxes match, and the confidence loss calculates the error between the predicted object class and the ground-truth object class to determine how well our model classifies the object class. The equations below also adhere to the formulation described in [
15]:
where
is the number of positives of the default boxes, that is, it is the default box that can be matched with a ground-truth box. If objects are accurately predicted, it is treated as positives and the rest as negatives. Default boxes refer to boxes extracted from multiple feature layers of different scales. If
, we set the loss to 0. The localization loss was Smooth L1 loss between the predicted box (
) and the ground-truth box (
) parameters; thus, it is a curve when
. Therefore, if the error is small enough, it is judged to be almost correct and the loss decreases quickly. Similar to Faster R-CNN, we regressed to offsets for the center (
,
) of the default bounding box (
) and for its width (
) and height (
):
where
The confidence loss is the softmax loss over multiple classes confidences (
) given by:
where
In SSD300, EMB was added after the Conv4_3, Conv7, Conv8_2 layers. In SSD512, EMB was added after the Conv4_3, Conv7, Conv8_2, Conv9_2 layers. Our model was implemented using the PyTorch deep learning framework [
51] and executed on an Intel Xeon E5-2620V, Nvidia RTX 2080Ti GPU (Santa Clara, CA, USA). The source code is available at
https://github.com/HTCho1/SSD-EMB.Pytorch/ (accessed on 14 April 2021).
5. Conclusions and Future Work
The proposed EMB method used two streams, namely, attention and feature map concatenation streams. In the attention stream, we produced the 1D importance map by compressing the input feature map. In this way, the model focuses on the region wherein the small objects (or the whole objects) could exist without additional learning, and the localization accuracy was improved. In the feature map concatenation stream, one of the input feature maps (cut in half) was passed through three convolutional layers and was concatenated with the other. Based on this stream, the classification accuracy was improved. The EMB lets the high-resolution feature map of the shallow layer focus on the object regions while the accuracy of detecting small objects increases. The high accuracy of small object detection is expected to be used for satellite photo and traffic analysis. To evaluate the performance of the proposed method, the SSD-EMB was compared with the SSD [
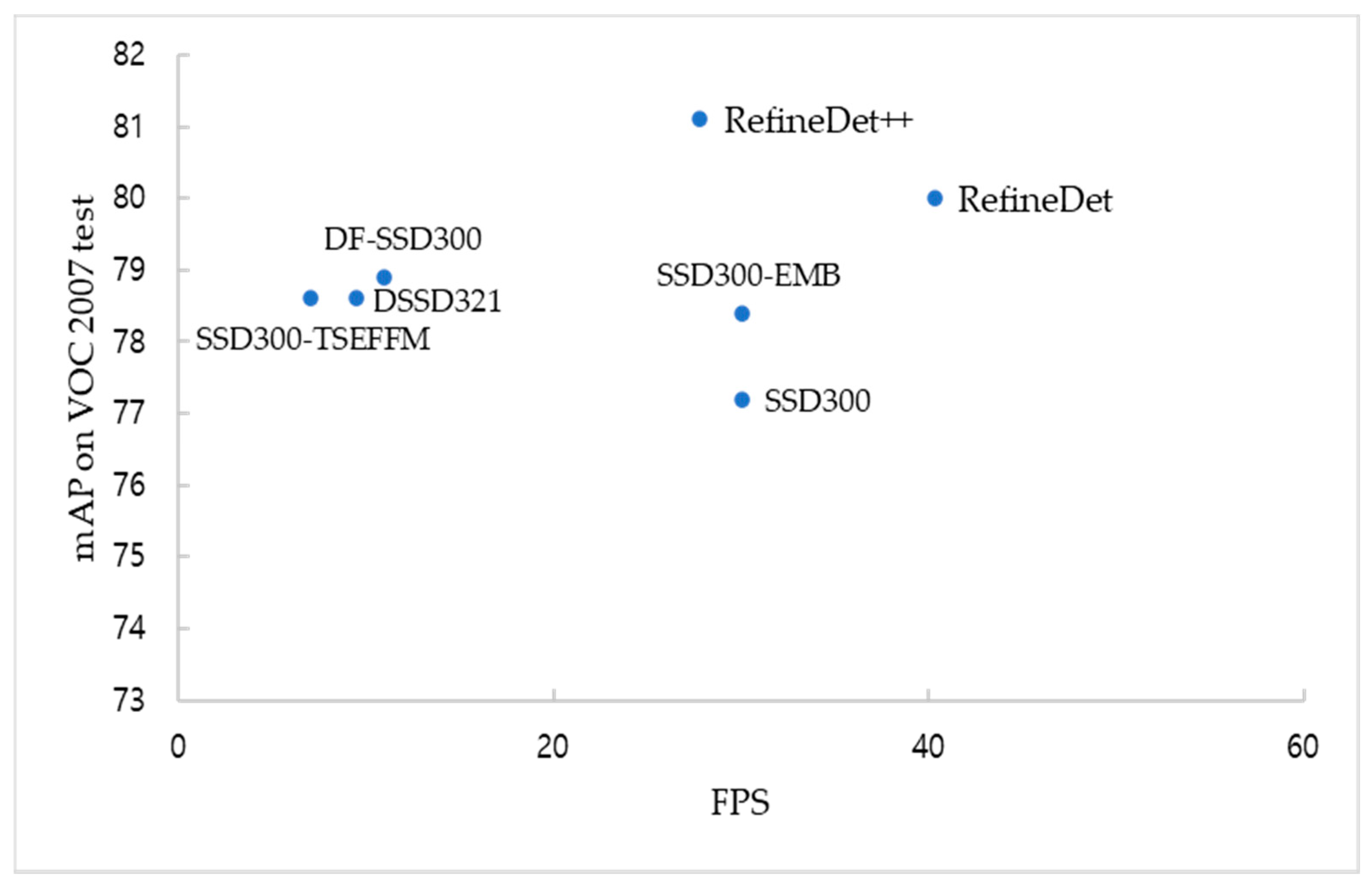
15], some SSD-based models, and state-of-the-art models. In the PASCAL VOC 2007 and 2012 benchmark datasets, the SSD-EMB enhanced the feature map of the shallow layer to improve the small object accuracy and overall accuracy. Additionally, it can be used in real-time detection. We further conducted an experiment on MS COCO. Through this experiment, we found that the performance of the model’s backbone considerably affects the overall accuracy.
In EMB, the attention stream simply focuses on the object region. In this way, localization accuracy is improved, but there is no significant effect on the classification accuracy. In this study, EMB was applied only to the SSD, but in the future work, we plan to evaluate the performance by applying the EMB to other state-of-the-art networks and will conduct research to further improve small object detection by creating a new attention mechanism and low-rank approximation that improve the classification accuracy. In our model, we utilized the fully annotated images to train the model. A fully annotated image has the class label and coordinates of the objects. However, it is a very difficult and challenging task to obtain or create these images in real life. Therefore, weakly supervised object detection, which trains model with weakly annotated images easily obtained on the web, is the focus of our future work.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}