
Non-Destructive Detection Pilot Study of Vegetable Organic Residues Using VNIR Hyperspectral Imaging and Deep Learning Techniques

 , , ,
, , ,
Abstract
:1. Introduction
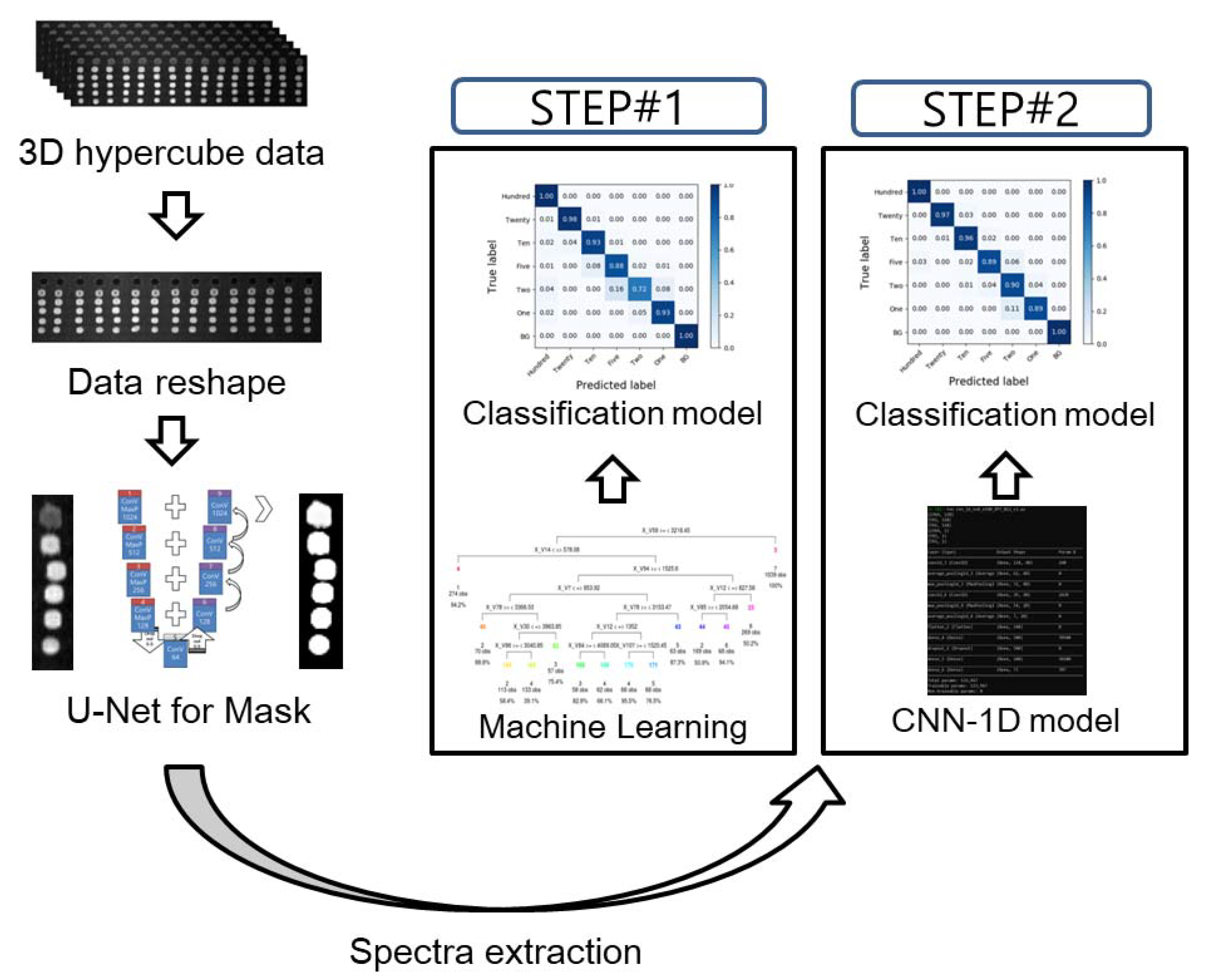
2. Materials and Methods
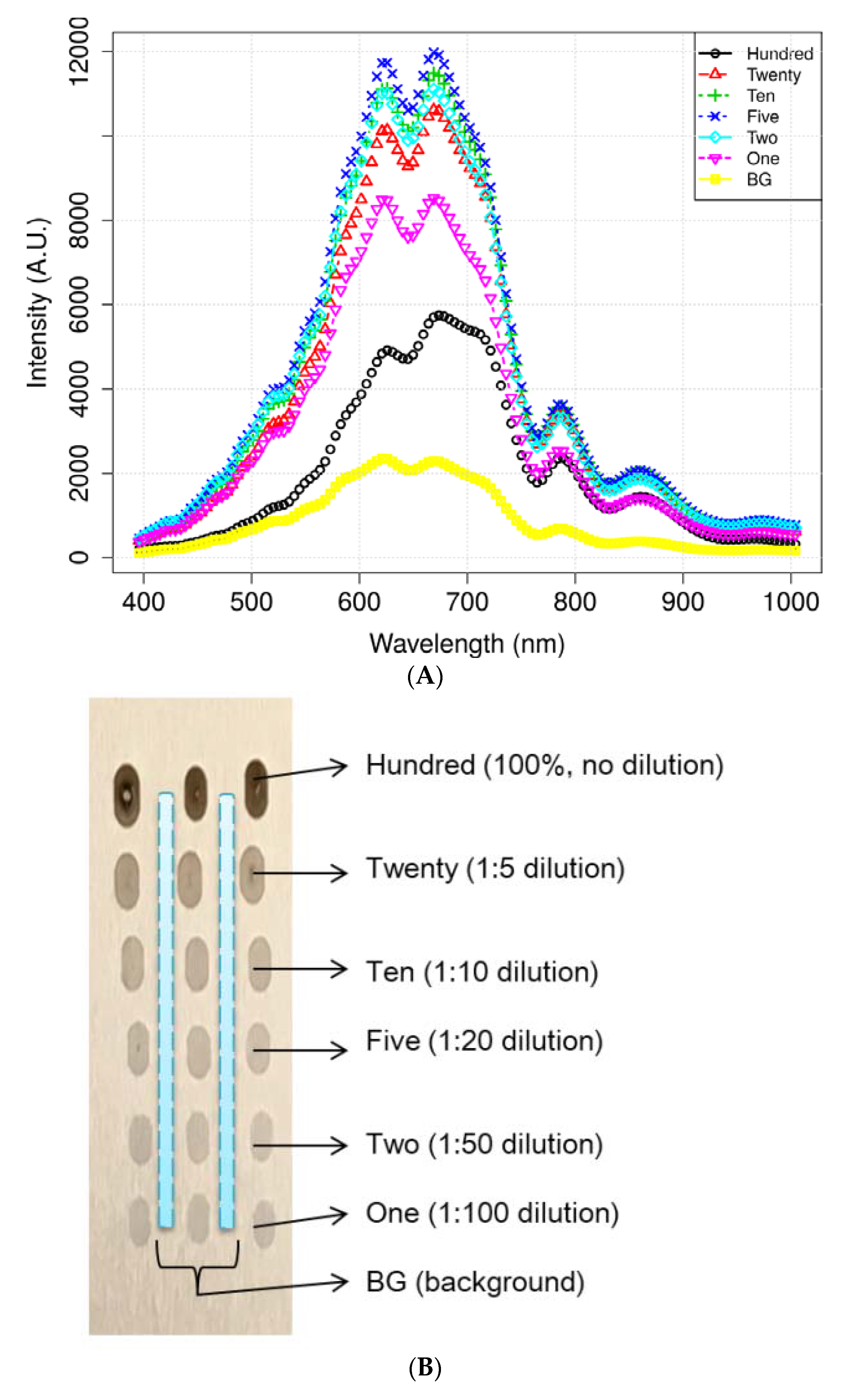
2.1. Sample Preparation
2.2. VNIR HSI System and Data Acquisition
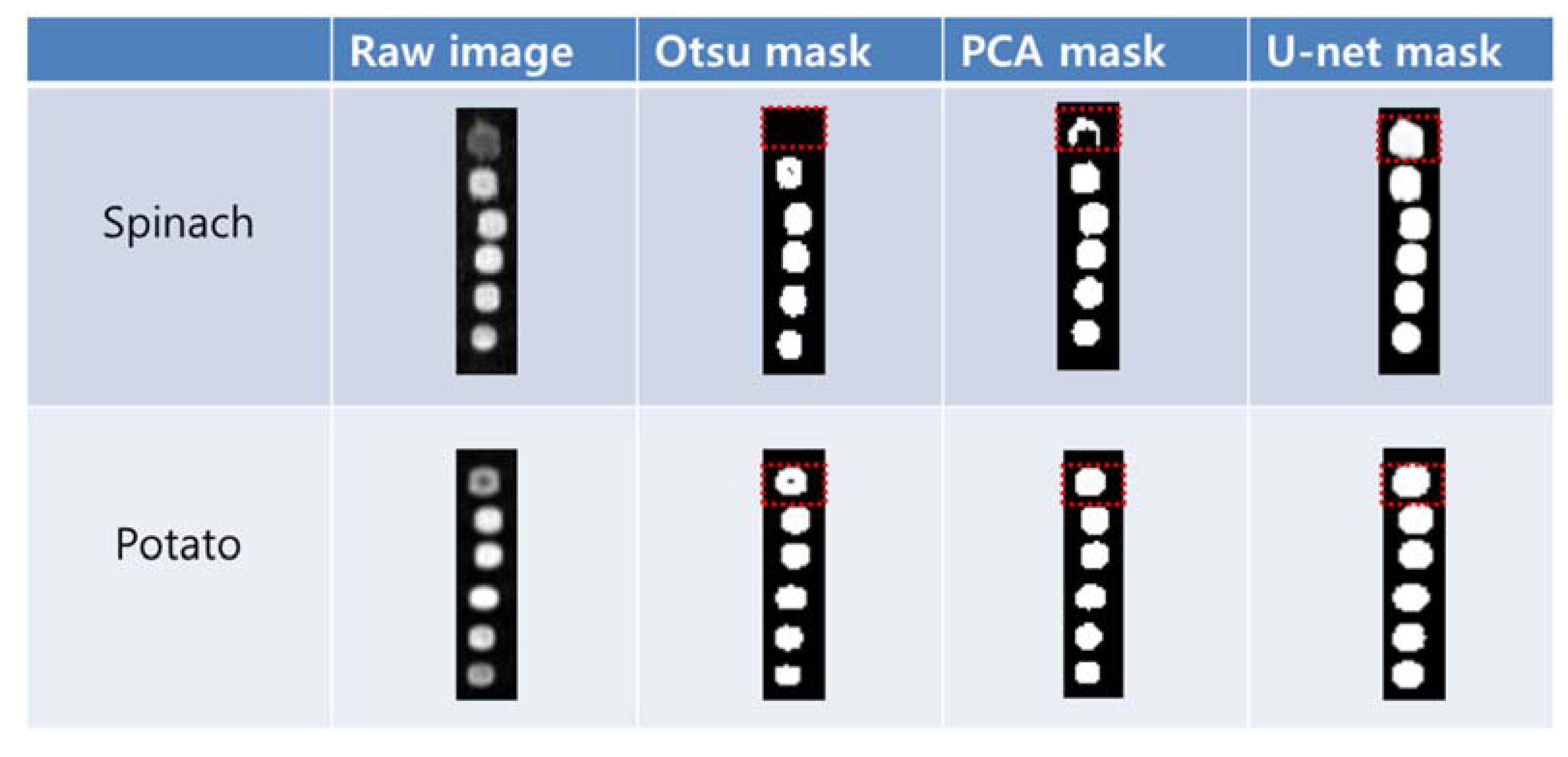
2.3. Region of Interest (ROI) Selection
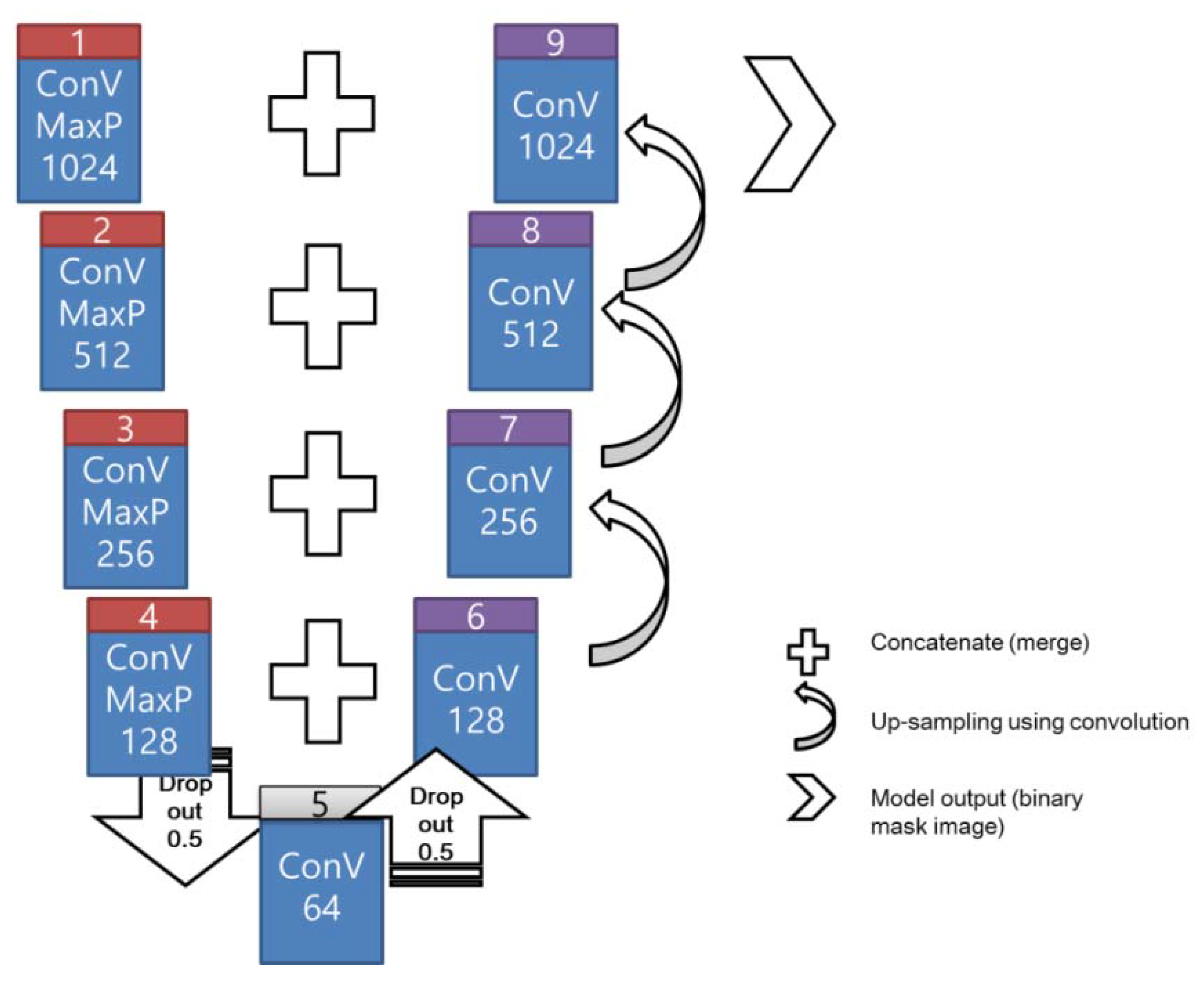
2.4. U-Net for Feature Segmentation
2.5. Development of the Classification Model
3. Results and Discussion
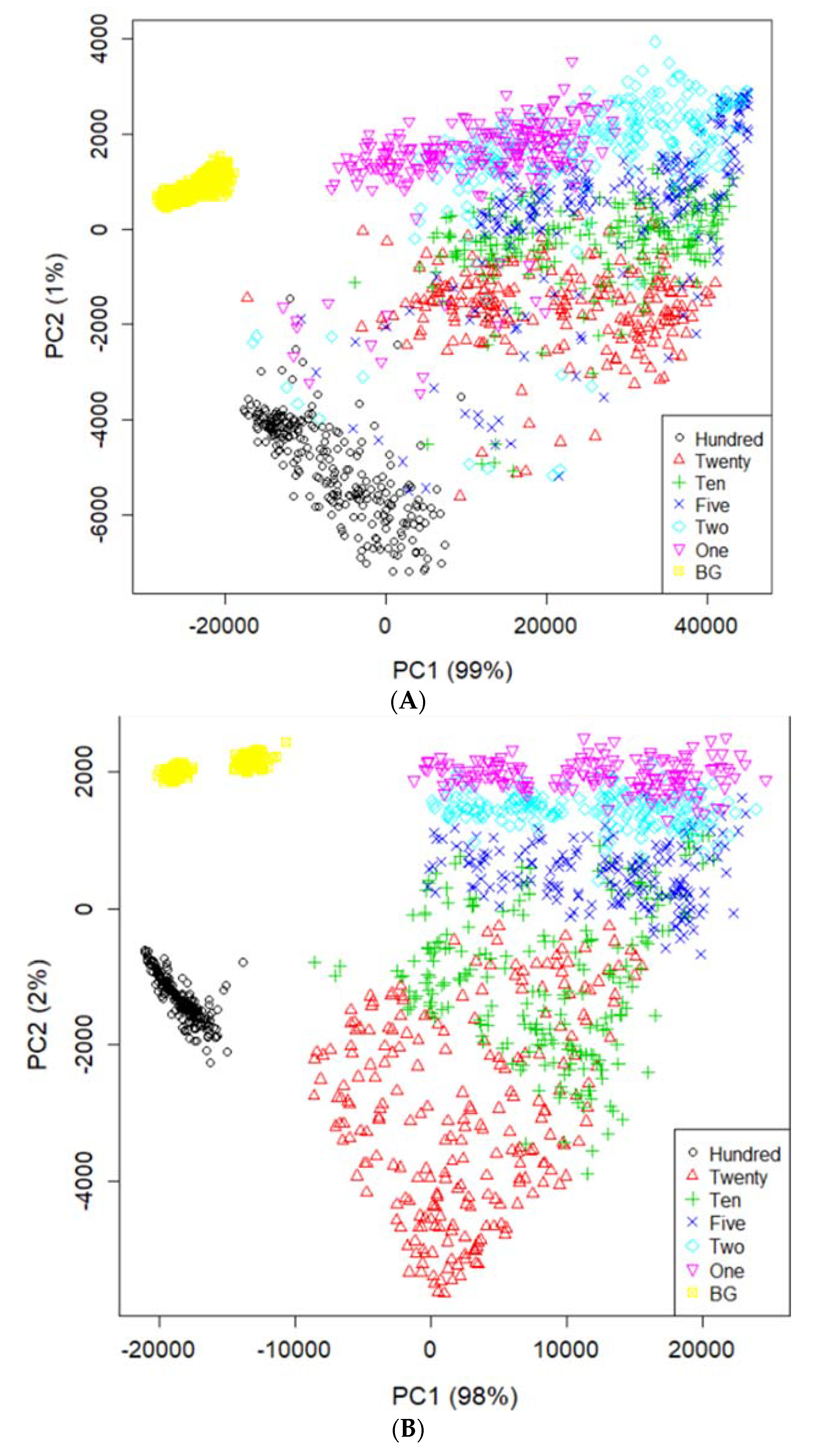
3.1. ROI Segmentation
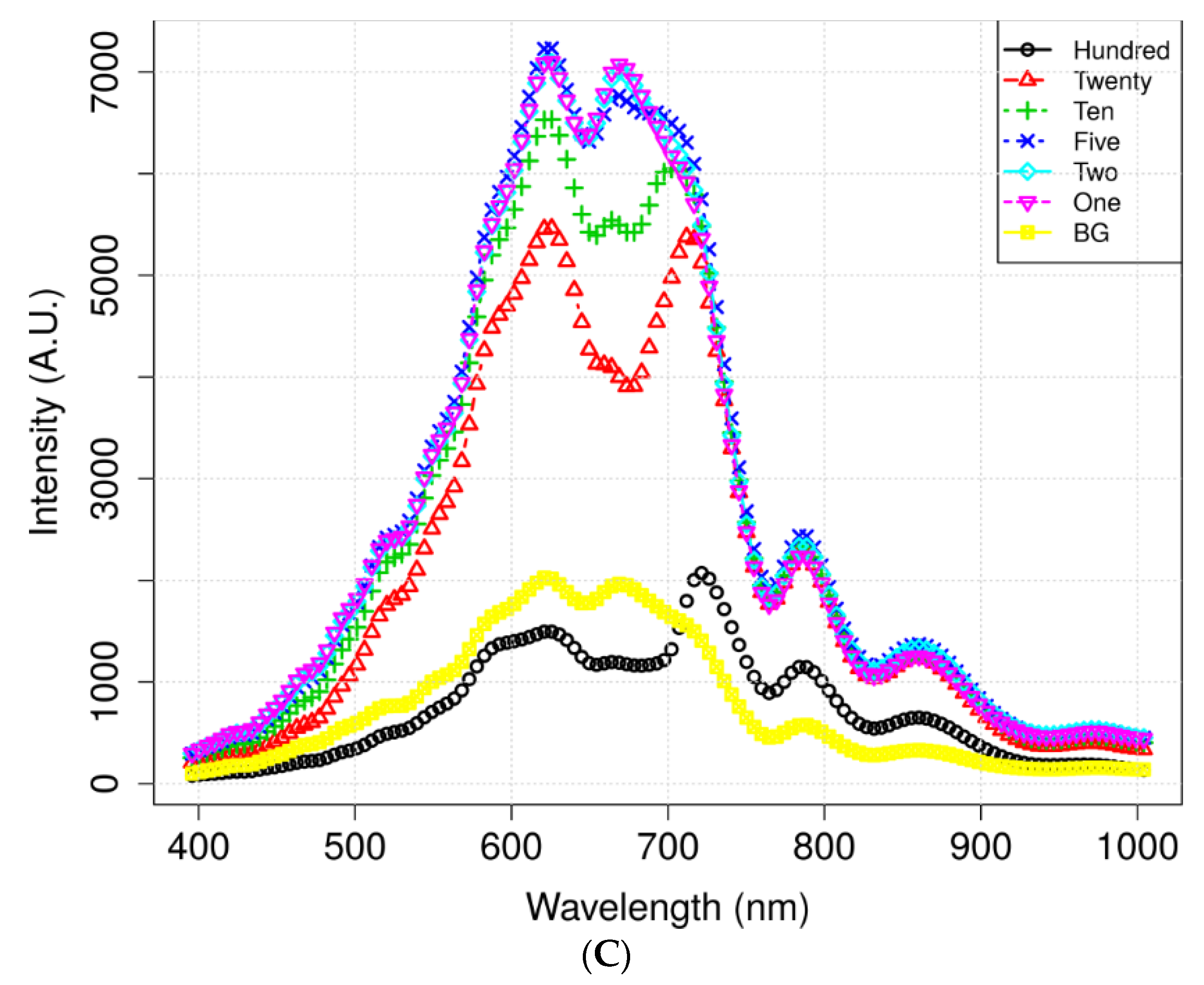
3.2. VNIR Spectral Characteristics
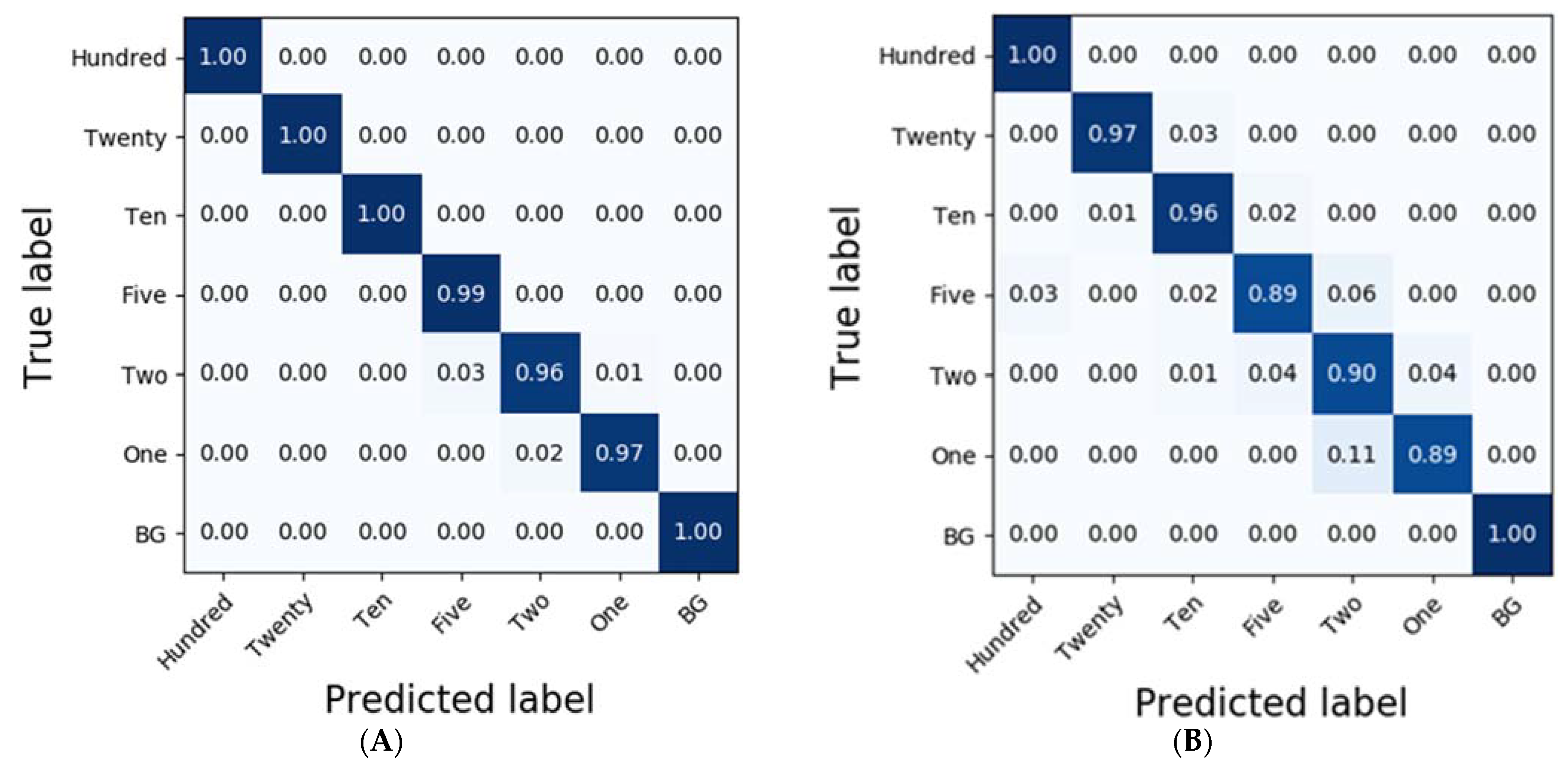
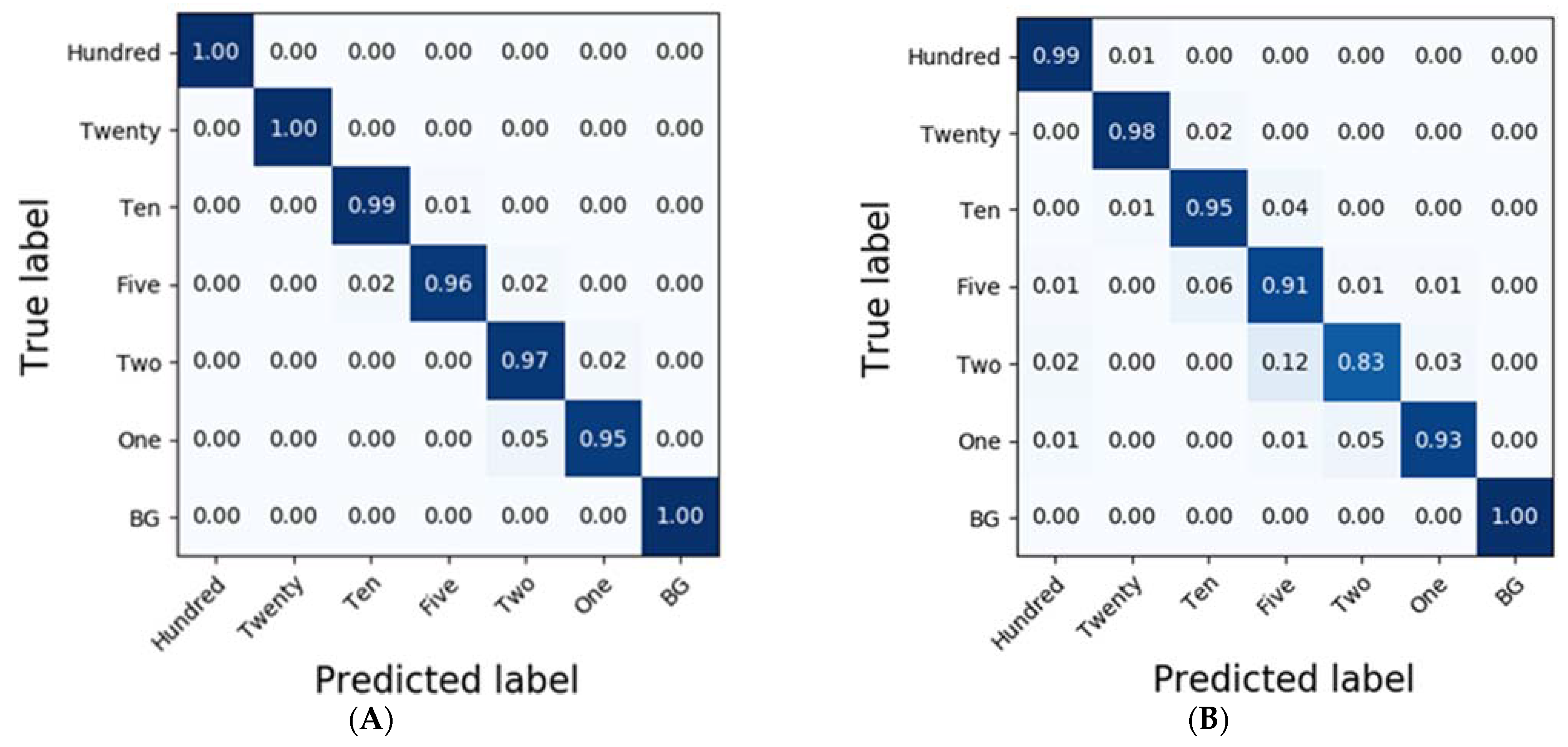
3.3. Classification Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Artes, F.; Gomez, P.A.; Artes-Hemandez, F. Physical, Physiological and Microbial Deterioration of Minimally Fresh Processed Fruits and Vegetables. Food Sci. Technol. Int. 2007, 13, 177–188. [Google Scholar] [CrossRef]
- Liu, N.T.; Lefcourt, A.; Nou, X.; Shelton, D.; Zhang, G.; Lo, Y.M. Native Microflora in Fresh-Cut Produce Processing Plants and Their Potentials for Biofilm Formation. J. Food Prot. 2013, 76, 827–832. [Google Scholar] [CrossRef]
- Lehto, M.; Kuisma, R.; Määttä, J.; Kymäläinen, H.-R.; Mäki, M. Hygienic level and surface contamination in fresh-cut vegetable production plants. Food Control 2011, 22, 469–475. [Google Scholar] [CrossRef]
- Jung, Y.; Jang, H.; Matthews, K.R. Effect of the food production chain from farm practices to vegetable processing on outbreak incidence. Microb. Biotechnol. 2014, 7, 517–527. [Google Scholar] [CrossRef]
- Jongenburger, I.; Reij, M.W.; Boer, E.P.J.; Gorris, L.G.M.; Zwietering, M.H. Factors influencing the accuracy of the plating method used to enumerate low numbers of viable micro-organisms in food. Int. J. Food Microbiol. 2010, 143, 32–40. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Zhang, C.; Zhao, J.; Ouyang, Q. Recent advances in emerging imaging techniques for non-destructive detection of food quality and safety. TrAC Trends Anal. Chem. 2013, 52, 261–274. [Google Scholar] [CrossRef]
- Zhang, B.; Huang, W.; Li, J.; Zhao, C.; Fan, S.; Wu, J.; Liu, C. Principles, developments and applications of computer vision for external quality inspection of fruits and vegetables: A review. Food Res. Int. 2014, 62, 326–343. [Google Scholar] [CrossRef]
- Lohumi, S.; Lee, S.; Lee, W.H.; Kim, M.S.; Mo, C.; Bae, H.; Cho, B.K. Detection of Starch Adulteration in Onion Powder by FT-NIR and FT-IR Spectroscopy. J. Agric. Food Chem. 2014, 62, 9246–9251. [Google Scholar] [CrossRef]
- Joshi, R.; Lohumi, S.; Joshi, R.; Kim, M.S.; Qin, J.; Baek, I.; Cho, B.-K. Raman spectral analysis for non-invasive detection of external and internal parameters of fake eggs. Sens. Actuators B Chem. 2020, 303, 127243. [Google Scholar] [CrossRef]
- Lim, J.; Kim, G.; Mo, C.; Kim, M.S.; Chao, K.; Qin, J.; Fu, X.; Baek, I.; Cho, B.K. Detection of melamine in milk powders using near-infrared hyperspectral imaging combined with regression coefficient of partial least square regression model. Talanta 2016, 151, 183–191. [Google Scholar] [CrossRef] [Green Version]
- Qin, J.; Vasefi, F.; Hellberg, R.S.; Akhbardeh, A.; Isaacs, R.B.; Yilmax, A.G.; Hwang, C.; Baek, I.; Schmidt, W.F.; Kim, M.S. Detection of fish fillet substitution and mislabeling using multimode hyperspectral imaging techniques. Food Control 2020, 114, 107234. [Google Scholar] [CrossRef]
- Lefcourt, A.M.; Kim, M.S.; Chen, Y.-R. Automated detection of fecal contamination of apples by multispectral laser-induced fluorescence imaging. Appl. Opt. 2003, 42, 3935–3943. [Google Scholar] [CrossRef] [Green Version]
- Qiu, Z.; Chen, J.; Zhao, Y.; Zhu, S.; He, Y.; Zhang, C. Variety Identification of Single Rice Seed Using Hyperspectral Imaging Combined with Convolutional Neural Network. Appl. Sci. 2018, 8, 212. [Google Scholar] [CrossRef] [Green Version]
- Pyo, J.; Duan, H.; Baek, S.; Kim, M.S.; Jeon, T.; Kwon, Y.S.; Lee, H.; Cho, K.H. A convolutional neural network regression for quantifying cyanobacteria using hyperspectral imagery. Remote Sens. Environ. 2019, 233, 111350. [Google Scholar] [CrossRef]
- Chen, X.; Kopsaftopoulos, F.; Wu, Q.; Ren, H.; Chang, F.-K. A Self-Adaptive 1D Convolutional Neural Network for Flight-State Identification. Sensors 2019, 19, 275. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, W.; Wu, G.; Zhang, F.; Du, Q. Hyperspectral Image Classification Using Deep Pixel-Pair Features. IEEE Trans. Geosci. Remote Sens. 2017, 55, 844–853. [Google Scholar] [CrossRef]
- Potena, C.; Narki, D.; Pretto, A. Fast and accurate crop and weed identification with summarized train sets for precision agriculture. Intell. Auton. Syst. 2017, 531, 105–121. [Google Scholar]
- Nagasubramanian, K.; Jones, S.; Singh, A.K.; Sarkar, S.; Singh, A.; Canapathysubramanian, B. Plant disease identification using explainable 3D deep learning on hyperspectral images. Plant Methods 2019, 15, 98. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Ince, T.; Abdeljaber, O.; Avci, O.; Gabbouj, M. 1-D Convolutional Neural Networks for Signal Processing Applications. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8360–8364. [Google Scholar]
- Abdoli, S.; Cardinal, P.; Lameiras Koerich, A. End-to-end environmental sound classification using a 1D convolutional neural network. Expert Syst. Appl. 2019, 136, 252–263. [Google Scholar] [CrossRef] [Green Version]
- Cho, H.; Yoon, S.M. Divide and Conquer-Based 1D CNN Human Activity Recognition Using Test Data Sharpening. Sensors 2018, 18, 1055. [Google Scholar]
- Kang, R.; Park, B.; Eady, M.; Ouyang, Q.; Chen, K. Classification of foodborne bacteria using hyperspectral microscope imaging technology coupled with convolutional neural networks. Appl. Microbiol. Biotechnol. 2020, 104, 3157–3166. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Manand Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Sattlecker, M.; Stone, N.; Smith, J.; Bessant, C. Assessment of robustness and transferability of classification models built for cancer diagnostics using Raman spectroscopy. J. Raman Spectrosc. 2011, 42, 897–903. [Google Scholar] [CrossRef]
- Wakholi, C.; Kandpal, L.M.; Lee, H.; Bae, H.; Park, E.; Kim, M.S.; Mo, C.; Lee, W.H.; Cho, B.K. Rapid assessment of corn seed viability using short wave infrared line-scan hyperspectral imaging and chemometrics. Sens. Actuators B Chem. 2018, 255, 498–507. [Google Scholar] [CrossRef]
- Svetnik, V.; Liaw, A.; Tong, C.; Culberson, J.C.; Sheridan, R.P.; Feuston, B.P. Random Forest: A Classification and Regression Tool for Compound Classification and QSAR Modeling. J. Chem. Inf. Comput. Sci. 2003, 43, 1947–1958. [Google Scholar] [CrossRef]
- Xia, J.; Ghamisi, P.; Yokoya, N.; Iwasaki, A. Random Forest Ensembles and Extended Multiextinction Profiles for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 202–216. [Google Scholar] [CrossRef] [Green Version]
- Vieira, S.M.; Kaymak, U.; Sousa, J.M.C. Cohen’s kappa coefficient as a performance measure for feature selection. In Proceedings of the International Conference on Fuzzy Systems, Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar]
- Gitelson, A.A.; Keydan, G.P.; Merzlyak, M.N. Three-band model for noninvasive estimation of chlorophyll, carotenoids, and anthocyanin contents in higher plant leaves. Geophys. Res. Lett. 2006, 33, L11402. [Google Scholar] [CrossRef] [Green Version]
- Siedliska, A.; Baranowski, P.; Zubik, M.; Mazurek, W.; Sosnowska, B. Detection of fungal infections in strawberry fruit by VNIR/SWIR hyperspectral imaging. Postharvest Biol. Technol. 2018, 139, 115–126. [Google Scholar] [CrossRef]
- Weng, S.; Tang, P.; Yuan, H.; Guo, B.; Yu, S.; Huang, L.; Xu, C. Hyperspectral imaging for accurate determination of rice variety using a deep learning network with multi-feature fusion. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2020, 234, 118237. [Google Scholar] [CrossRef] [PubMed]
- Chmielewski, R.A.N.; Frank, J.F. Biofilm Formation and Control in Food Processing Facilities. Compr. Rev. Food Sci. Food Saf. 2003, 2, 22–32. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Type | Output Shape | # of Parameter |
|---|---|---|---|
| Conv1d_1 | Conv1D | 124, 40 | 240 |
| Average_pooling1d_1 | AveragePooling1D | 62, 40 | 0 |
| Max_pooling1d_1 | MaxPooling1D | 31, 40 | 0 |
| Conv1d_2 | Conv1D | 29, 20 | 2420 |
| Average_pooling1d_2 | AveragePooling1D | 14, 20 | 0 |
| Max_pooling1d_2 | MaxPooling1D | 7, 20 | 0 |
| Flatten_1 | Flatten | 140 | 0 |
| Dense_1 | Dense | 500 | 70,500 |
| Dropout_1 | Dropout | 500 | 0 |
| Dense_2 | Dense | 100 | 50,100 |
| Dense_3 | Dense | 7 | 707 |
| Total parameters: 123,967, Trainable parameters: 123,967 | |||
| MA | PP | Hundred | Twenty | Ten | Five | Two | One | BG | A | K |
|---|---|---|---|---|---|---|---|---|---|---|
| LDA | NoP | 1.00 | 0.87 | 0.70 | 0.68 | 0.60 | 0.86 | 1.00 | 0.83 | 0.80 |
| D1 | 1.00 | 0.87 | 0.70 | 0.68 | 0.60 | 0.86 | 1.00 | 0.83 | 0.80 | |
| D2 | 1.00 | 0.87 | 0.70 | 0.68 | 0.60 | 0.86 | 1.00 | 0.83 | 0.80 | |
| MSC | 0.98 | 0.85 | 0.78 | 0.39 | 0.42 | 0.58 | 0.82 | 0.71 | 0.66 | |
| MA | 1.00 | 0.87 | 0.70 | 0.68 | 0.60 | 0.86 | 1.00 | 0.83 | 0.80 | |
| NM | 1.00 | 0.86 | 0.71 | 0.66 | 0.62 | 0.86 | 1.00 | 0.83 | 0.80 | |
| PLSDA | NoP | 0.99 | 0.73 | 0.22 | 0.63 | 0.36 | 0.54 | 1.00 | 0.68 | 0.62 |
| D1 | 0.99 | 0.64 | 0.01 | 0.71 | 0.19 | 0.07 | 1.00 | 0.57 | 0.49 | |
| D2 | 1.00 | 0.56 | 0.05 | 0.59 | 0.37 | 0.08 | 1.00 | 0.58 | 0.50 | |
| MSC | 0.99 | 0.80 | 0.67 | 0.70 | 0.25 | 0.65 | 0.96 | 0.60 | 0.52 | |
| MA | 0.99 | 0.73 | 0.22 | 0.63 | 0.36 | 0.54 | 1.00 | 0.68 | 0.62 | |
| NM | 1.00 | 0.75 | 0.24 | 0.67 | 0.36 | 0.56 | 1.00 | 0.69 | 0.63 | |
| SVM | NoP | 1.00 | 0.89 | 0.87 | 0.93 | 0.71 | 0.94 | 0.95 | 0.90 | 0.88 |
| D1 | 1.00 | 0.85 | 0.78 | 0.79 | 0.63 | 0.93 | 0.95 | 0.86 | 0.83 | |
| D2 | 1.00 | 0.86 | 0.71 | 0.82 | 0.60 | 0.92 | 0.95 | 0.85 | 0.82 | |
| MSC | 1.00 | 0.83 | 0.78 | 0.78 | 0.39 | 0.60 | 0.94 | 0.78 | 0.74 | |
| MA | 1.00 | 0.87 | 0.71 | 0.81 | 0.36 | 0.90 | 0.95 | 0.81 | 0.78 | |
| NM | 1.00 | 0.87 | 0.71 | 0.81 | 0.36 | 0.90 | 0.95 | 0.81 | 0.78 | |
| DT | NoP | 1.00 | 0.73 | 0.56 | 0.68 | 0.40 | 0.87 | 0.95 | 0.76 | 0.71 |
| D1 | 0.96 | 0.65 | 0.37 | 0.66 | 0.33 | 0.88 | 0.95 | 0.71 | 0.65 | |
| D2 | 0.99 | 0.70 | 0.32 | 0.61 | 0.31 | 0.90 | 0.95 | 0.70 | 0.65 | |
| MSC | 0.99 | 0.72 | 0.69 | 0.74 | 0.14 | 0.46 | 0.87 | 0.68 | 0.62 | |
| MA | 1.00 | 0.73 | 0.56 | 0.68 | 0.40 | 0.87 | 0.95 | 0.76 | 0.71 | |
| NM | 1.00 | 0.73 | 0.56 | 0.68 | 0.40 | 0.87 | 0.95 | 0.76 | 0.71 | |
| LSSVM | NoP | 1.00 | 0.87 | 0.81 | 0.90 | 0.74 | 0.95 | 0.95 | 0.89 | 0.87 |
| D1 | 1.00 | 0.86 | 0.66 | 0.81 | 0.67 | 0.98 | 0.95 | 0.85 | 0.83 | |
| D2 | 1.00 | 0.79 | 0.10 | 0.62 | 0.33 | 0.89 | 0.95 | 0.69 | 0.64 | |
| MSC | 0.99 | 0.80 | 0.67 | 0.70 | 0.25 | 0.65 | 0.96 | 0.74 | 0.69 | |
| MA | 1.00 | 0.88 | 0.81 | 0.88 | 0.73 | 0.94 | 0.95 | 0.89 | 0.87 | |
| NM | 1.00 | 0.87 | 0.78 | 0.87 | 0.69 | 0.94 | 0.95 | 0.88 | 0.86 | |
| RF | NoP | 0.98 | 0.93 | 0.83 | 0.77 | 0.67 | 0.88 | 1.00 | 0.88 | 0.86 |
| D1 | 0.98 | 0.92 | 0.73 | 0.76 | 0.74 | 0.94 | 1.00 | 0.88 | 0.86 | |
| D2 | 0.99 | 0.90 | 0.58 | 0.72 | 0.67 | 0.95 | 1.00 | 0.85 | 0.82 | |
| MSC | 0.98 | 0.91 | 0.72 | 0.59 | 0.43 | 0.49 | 0.99 | 0.76 | 0.72 | |
| MA | 0.98 | 0.93 | 0.83 | 0.77 | 0.67 | 0.88 | 1.00 | 0.88 | 0.86 | |
| NM | 0.98 | 0.88 | 0.81 | 0.76 | 0.67 | 0.88 | 1.00 | 0.87 | 0.84 |
| MA | PP | Hundred | Twenty | Ten | Five | Two | One | BG | A | K |
|---|---|---|---|---|---|---|---|---|---|---|
| LDA | NoP | 1.00 | 0.92 | 0.83 | 0.77 | 0.77 | 0.74 | 1.00 | 0.88 | 0.86 |
| D1 | 1.00 | 0.92 | 0.83 | 0.77 | 0.77 | 0.74 | 1.00 | 0.88 | 0.86 | |
| D2 | 1.00 | 0.92 | 0.83 | 0.77 | 0.77 | 0.74 | 1.00 | 0.88 | 0.86 | |
| MSC | 0.99 | 0.83 | 0.90 | 0.67 | 0.69 | 0.43 | 1.00 | 0.81 | 0.78 | |
| MA | 1.00 | 0.92 | 0.83 | 0.77 | 0.77 | 0.74 | 1.00 | 0.88 | 0.86 | |
| NM | 1.00 | 0.92 | 0.82 | 0.78 | 0.77 | 0.76 | 1.00 | 0.88 | 0.86 | |
| PLSDA | NoP | 1.00 | 0.96 | 0.87 | 0.37 | 0.66 | 0.74 | 1.00 | 0.83 | 0.80 |
| D1 | 1.00 | 0.93 | 0.87 | 0.09 | 0.46 | 0.56 | 1.00 | 0.75 | 0.70 | |
| D2 | 1.00 | 0.96 | 0.88 | 0.18 | 0.60 | 0.70 | 1.00 | 0.80 | 0.76 | |
| MSC | 1.00 | 0.86 | 0.73 | 0.75 | 0.56 | 0.74 | 0.97 | 0.81 | 0.78 | |
| MA | 1.00 | 0.96 | 0.87 | 0.37 | 0.66 | 0.74 | 1.00 | 0.83 | 0.80 | |
| NM | 1.00 | 0.97 | 0.87 | 0.38 | 0.65 | 0.74 | 1.00 | 0.83 | 0.80 | |
| SVM | NoP | 1.00 | 0.96 | 0.90 | 0.88 | 0.81 | 0.85 | 0.98 | 0.92 | 0.91 |
| D1 | 1.00 | 0.90 | 0.76 | 0.82 | 0.76 | 0.78 | 0.98 | 0.87 | 0.85 | |
| D2 | 1.00 | 0.92 | 0.80 | 0.84 | 0.79 | 0.81 | 0.98 | 0.89 | 0.87 | |
| MSC | 1.00 | 0.84 | 0.78 | 0.79 | 0.77 | 0.72 | 0.98 | 0.86 | 0.83 | |
| MA | 1.00 | 0.76 | 0.64 | 0.71 | 0.76 | 0.71 | 0.98 | 0.81 | 0.78 | |
| NM | 1.00 | 0.76 | 0.64 | 0.71 | 0.76 | 0.71 | 0.98 | 0.81 | 0.78 | |
| DT | NoP | 1.00 | 0.77 | 0.63 | 0.65 | 0.65 | 0.68 | 0.98 | 0.79 | 0.75 |
| D1 | 1.00 | 0.85 | 0.71 | 0.74 | 0.60 | 0.78 | 0.98 | 0.83 | 0.80 | |
| D2 | 1.00 | 0.94 | 0.70 | 0.84 | 0.62 | 0.71 | 0.98 | 0.84 | 0.82 | |
| MSC | 1.00 | 0.89 | 0.72 | 0.80 | 0.72 | 0.66 | 0.98 | 0.84 | 0.81 | |
| MA | 1.00 | 0.77 | 0.63 | 0.65 | 0.65 | 0.68 | 0.98 | 0.79 | 0.75 | |
| NM | 1.00 | 0.77 | 0.63 | 0.65 | 0.65 | 0.68 | 0.98 | 0.79 | 0.75 | |
| LSSVM | NoP | 1.00 | 0.89 | 0.82 | 0.79 | 0.70 | 0.75 | 0.98 | 0.86 | 0.84 |
| D1 | 1.00 | 0.86 | 0.72 | 0.64 | 0.55 | 0.75 | 0.98 | 0.81 | 0.77 | |
| D2 | 1.00 | 0.90 | 0.73 | 0.71 | 0.47 | 0.70 | 0.98 | 0.81 | 0.77 | |
| MSC | 1.00 | 0.86 | 0.73 | 0.75 | 0.56 | 0.74 | 0.97 | 0.82 | 0.79 | |
| MA | 1.00 | 0.85 | 0.79 | 0.73 | 0.71 | 0.73 | 0.98 | 0.84 | 0.81 | |
| NM | 1.00 | 0.90 | 0.85 | 0.77 | 0.75 | 0.76 | 0.98 | 0.87 | 0.85 | |
| RF | NoP | 1.00 | 0.86 | 0.84 | 0.78 | 0.82 | 0.84 | 1.00 | 0.89 | 0.87 |
| D1 | 1.00 | 0.86 | 0.81 | 0.85 | 0.85 | 0.86 | 1.00 | 0.90 | 0.88 | |
| D2 | 1.00 | 0.89 | 0.81 | 0.88 | 0.79 | 0.76 | 1.00 | 0.89 | 0.87 | |
| MSC | 1.00 | 0.87 | 0.84 | 0.87 | 0.92 | 0.85 | 1.00 | 0.91 | 0.90 | |
| MA | 1.00 | 0.86 | 0.84 | 0.78 | 0.82 | 0.84 | 1.00 | 0.89 | 0.87 | |
| NM | 1.00 | 0.88 | 0.82 | 0.79 | 0.82 | 0.83 | 1.00 | 0.89 | 0.87 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seo, Y.; Kim, G.; Lim, J.; Lee, A.; Kim, B.; Jang, J.; Mo, C.; Kim, M.S. Non-Destructive Detection Pilot Study of Vegetable Organic Residues Using VNIR Hyperspectral Imaging and Deep Learning Techniques. Sensors 2021, 21, 2899. https://doi.org/10.3390/s21092899
Seo Y, Kim G, Lim J, Lee A, Kim B, Jang J, Mo C, Kim MS. Non-Destructive Detection Pilot Study of Vegetable Organic Residues Using VNIR Hyperspectral Imaging and Deep Learning Techniques. Sensors. 2021; 21(9):2899. https://doi.org/10.3390/s21092899
Chicago/Turabian StyleSeo, Youngwook, Giyoung Kim, Jongguk Lim, Ahyeong Lee, Balgeum Kim, Jaekyung Jang, Changyeun Mo, and Moon S. Kim. 2021. "Non-Destructive Detection Pilot Study of Vegetable Organic Residues Using VNIR Hyperspectral Imaging and Deep Learning Techniques" Sensors 21, no. 9: 2899. https://doi.org/10.3390/s21092899