
Improved Light Field Compression Efficiency through BM3D-Based Denoising Using Inter-View Correlation


Abstract
:1. Introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target Applications | Denoising Algorithms |
|---|---|
| Single view | NLM [8] |
| BM3D [9,10] | |
| SGN [11] | |
| Real image denoising [12] | |
| Universal denoising networks [13] | |
| FFDNet [14] | |
| Video | VBM3D [15] |
| VBM5D [16] | |
| With optical flow estimation [17] | |
| Frame-to-frame training [18] | |
| SALT [19] | |
| Multi-view | NLM with PS [20] |
| With occlusion handling [21] | |
| MVCNN [22] | |
| LFBM5D [24,25] | |
| APA [26] |
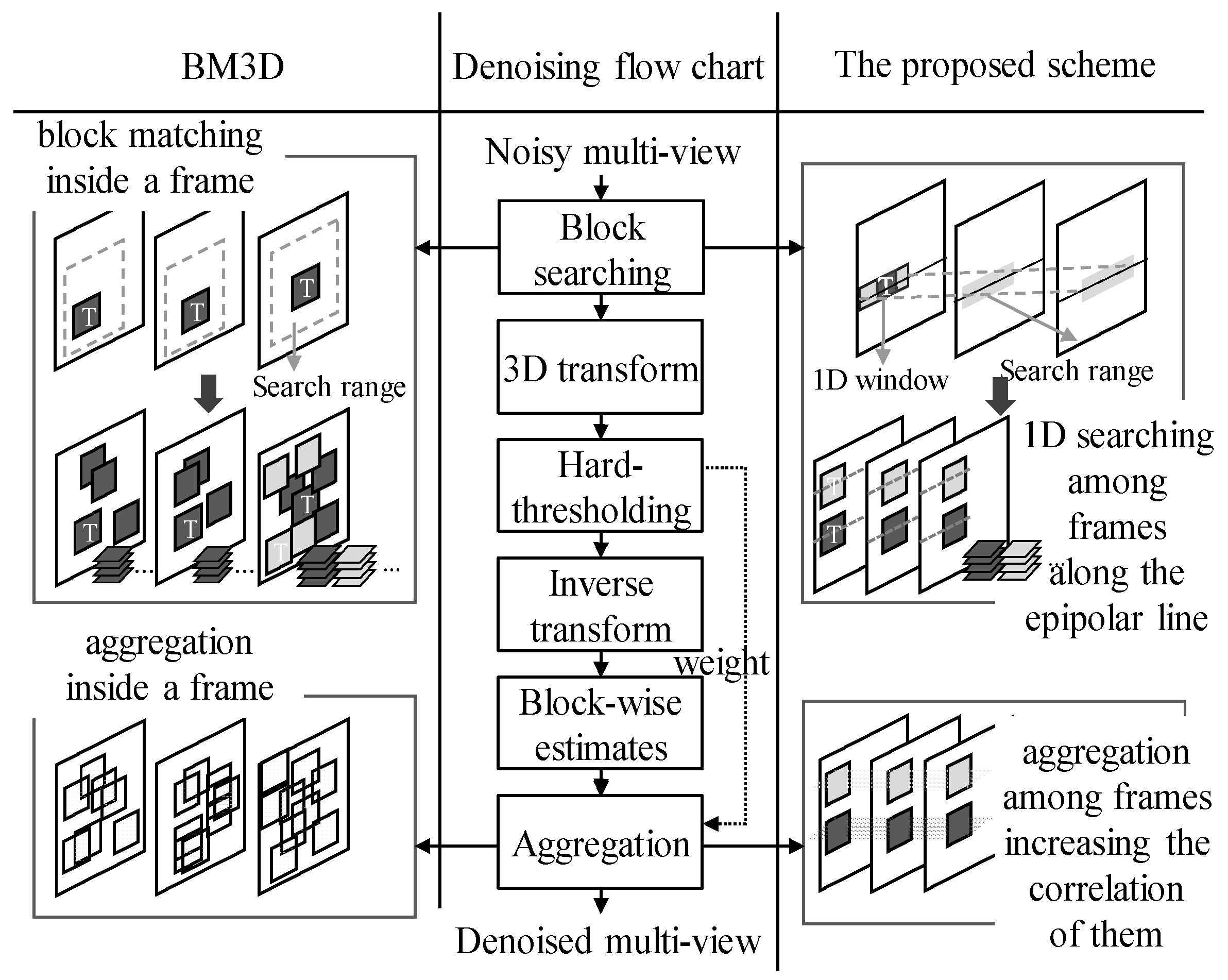
2. Overview
- Searching time accounts for nearly half of the total time in BM3D-like approaches such as BM3D, VBM3D, VBM4D and LFBM5D. In this paper, both the search area and the difference calculation are changed from 2D to 1D considering the characteristics of 1D linear geometry. Thus, the searching speed is increased.
- The naïve block-matching search used in the conventional BM3D-like approaches does not work well with noise. For an efficient search in the noisy views, the proposed 1D window-based search using EPI, which accurately reflects the characteristics of multi-view, reduces the risk of incorrect patches. In addition, the maximum disparity is reflected in the ELS range of the initial views (denoted as SR1step hereinafter) as meaningful searching guidance for noisy images. Subsequently, the remaining views limit the search range (denoted by SR2step hereinafter) around the best point found in the previous views to prevent an incorrect outcome due to noise.
- Most existing denoising algorithms simply consider the SAD in block search process. However, the proposed ELS plays the role of pre-processing for the block-based ME to be carried out for the denoised multi-view compression. When searching for the correspondence in each view, the slope similarity of the linecor-pixel with adjacent pixels as well as the pixel difference is considered together to reflect the rate-distortion optimization of ME. This has a positive effect in the subsequent compression stage of denoised multi-views.
- Aggregation using weighted summation helps denoised results to be spatially consistent within the image in BM3D-based approaches. Hereinafter, this is referred to as spatial aggregation. In this paper, both spatial and temporal aggregations are adopted. The correlation between the views is increased by performing inter-view level temporal aggregation from the filtering results for the patches of each view. This contributes to increasing the compression efficiency.
3. Proposed Compression-Friendly Denoising
3.1. Fast and Noise-Resistanti EPI Estimation
3.2. Temporal Aggregation
4. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xiong, Z.; Cheng, Z.; Peng, J.; Fan, H.; Liu, D.; Wu, F. Light field super-resolution using internal and external similarities. In Proceedings of the 2017 IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 1612–1616. [Google Scholar]
- Xiao, Z.; Si, L.; Zhou, G. Seeing beyond foreground occlusion: A joint framework for SAP based scene depth and appearance reconstruction. IEEE J. Sel. Top. Signal Process. 2017, 11, 979–991. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, J.; Guo, Y.; Xiao, C.; An, W. Selective light field refocusing for camera arrays using bokeh rendering and superresolution. IEEE Signal Process. Lett. 2019, 26, 204–208. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, L.; Yang, J.; An, W.; Yu, J.; Guo, Y. Spatial-angular interaction for light field image super-resolution. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 November 2020; pp. 290–308. [Google Scholar]
- Wang, Y.; Wu, T.; Yang, J.; Wang, L.; An, W.; Guo, Y. DeOccNet: Learning to See Through Foreground Occlusions in Light Fields. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 118–127. [Google Scholar]
- Jung, H.; Lee, H.-J.; Rhee, C.E. Ray-space360: An extension of ray-space for omnidirectional free viewpoint. In Proceedings of the IEEE International Symposium on Circuits and Systems, Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar]
- Jung, H.; Lee, H.-J.; Rhee, C.E. Flexibly Connectable Light Field System for Free View Exploration. IEEE Trans. Multimed. 2017, 22, 980–991. [Google Scholar] [CrossRef]
- Buades, A.; Coll, B.; Morel, J.-M. A non-local algorithm for image denoising. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 60–65. [Google Scholar]
- Lebrun, M. An Analysis and Implementation of the BM3D Image Denoising Method. Image Process. Line 2012, 2, 175–213. [Google Scholar] [CrossRef] [Green Version]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3d transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Gu, S.; Li, Y.; Van Gool, L.; Timofte, R. Self-guided network for fast image denoising. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 2511–2520. [Google Scholar]
- Anwar, S.; Barnes, N. Real image denoising with feature attention. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3155–3164. [Google Scholar]
- Lefkimmiatis, S. Universal denoising networks: A novel CNN architecture for image denoising. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 3204–3213. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef] [Green Version]
- Dabov, K.; Foi, A.; Egiazarian, K. Video denoising by sparse 3d transform-domain collaborative filtering. In Proceedings of the European Signal Processing Conference, Poznan, Poland, 2–7 September 2007; pp. 145–149. [Google Scholar]
- Maggioni, M.; Boracchi, G.; Foi, A.; Egiazarian, K. Video denoising using separable 4-D nonlocal spatiotemporal transforms. SPIE Electron. Imaging 2011, 7870, 787003-1–787003-11. [Google Scholar]
- Buades, A.; Lisani, J.-L.; Miladinović, M. Patch-based video denoising with optical flow estimation. IEEE Trans. Image Process. 2016, 25, 2573–2586. [Google Scholar] [CrossRef] [PubMed]
- Ehret, T.; Davy, A.; Morel, J.-M.; Facciolo, G.; Arias, P. Model-blind video denoising via Frame-To-Frame training. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11369–11378. [Google Scholar]
- Wen, B.; Li, Y.; Pfister, L.; Bresler, Y. Joint adaptive sparsity and low-rankness on the fly: An online tensor reconstruction scheme for video denoising. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 241–250. [Google Scholar]
- Miyata, M.; Kodama, K.; Hamamoto, T. Fast multiple-view denoising based on image reconstruction by plane sweeping. In Proceedings of the IEEE Visual Communications and Image Processing, Valletta, Malta, 7–10 December 2014; pp. 462–465. [Google Scholar]
- Zhou, S.; Hu, Y.H.; Jiang, H. Patch-based multiple view image denoising with occlusion handling. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017; pp. 1782–1786. [Google Scholar]
- Zhou, S.; Hu, Y.H.; Jiang, H. Multi-View Image Denoising Using Convolutional Neural Network. Sensors 2019, 19, 2597. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian Denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [Green Version]
- Alain, M.; Smolic, A. Light field denoising by sparse 5D transform domain collaborative filtering. In Proceedings of the IEEE 19th International Workshop on Multimedia Signal Processing, Luton, UK, 16–18 October 2017; pp. 1–6. [Google Scholar]
- Alain, M.; Smolic, A. Light field super-resolution via LFBM5D sparse coding. In Proceedings of the IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018; pp. 2501–2505. [Google Scholar]
- Chen, J.; Hou, J.; Chau, L.-P. Light field denoising via anisotropic parallax analysis in a CNN framework. IEEE Signal Process. Lett. 2018, 25, 1403–1407. [Google Scholar] [CrossRef] [Green Version]
- Premaratne, S.U.; Liyanage, N.; Edussooriya, C.U.S.; Wijenayake, C. Real-time light field denoising using a novel linear 4-D hyperfan filter. IEEE Trans. Circuits Syst. I 2020, 67, 2693–2706. [Google Scholar] [CrossRef]
- Wu, G.; Liu, Y.; Dai, Q.; Chai, T. Learning sheared EPI structure for light field reconstruction. IEEE Trans. Image Process. 2019, 28, 3261–3273. [Google Scholar] [CrossRef]
- Shin, C.; Jeon, H.-G.; Yoon, Y.; Kweon, I.S.; Kim, S.J. EPINET: A fully-convolutional neural network using epipolar geometry for depth from light field images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 4748–4757. [Google Scholar]
- Zhang, S.; Sheng, H.; Li, C.; Zhang, J.; Xiong, Z. Robust depth estimation for light field via spinning parallelogram operator. Comput. Vision Image Underst. 2016, 145, 148–159. [Google Scholar] [CrossRef]
- Calderon, F.C.; Parra, C.A.; Niño, C.L. Depth map estimation in light fields using an stereo-like taxonomy. In Proceedings of the IEEE Symposium on Image, Signal Processing and Artificial Vision, Armenia, Colombia, 17–19 September 2014; pp. 1–5. [Google Scholar]
- Li, J.; Lu, M.; Li, Z.-N. Continuous depth map reconstruction from light fields. IEEE Trans. Image Process. 2015, 24, 3257–3265. [Google Scholar] [PubMed] [Green Version]
- Lu, J.; Cai, H.; Lou, J.-G.; Li, J. An epipolar geometry-based fast disparity estimation algorithm for multiview image and video coding. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 737–750. [Google Scholar] [CrossRef]
- Micallef, B.W.; Debono, C.J.; Farrugia, R.A. Fast disparity estimation for multi-view video plus depth coding. In Proceedings of the Visual Communications and Image Processing, Tainan, Taiwan, 6–9 November 2011; pp. 1–4. [Google Scholar]
- Li, X.M.; Zhao, D.B.; Ma, S.W.; Gao, W. Fast disparity and motion estimation based on correlations for multiview video coding. IEEE Trans. Consum. Electron. 2008, 54, 2037–2044. [Google Scholar] [CrossRef] [Green Version]
- Wiegand, T.; Sullivan, G.J.; Bjontegaard, G.; Luthra, A. Overview of the H.264/AVC video coding standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef] [Green Version]
- Sullivan, G.J.; Ohm, J.-R.; Han, W.-J.; Wiegand, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1648–1667. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Wiegand, T. Rate-distortion optimization for video compression. IEEE Signal Process. Mag. 1998, 15, 74–90. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Oertel, N.; Hutter, A.; Kaup, A. Advanced Lagrange multiplier selection for hybrid video coding. In Proceedings of the 2007 IEEE International Conference on Multimedia and Expo (ICME), Beijing, China, 2–5 July 2007; pp. 364–367. [Google Scholar]
- Nagoya University Multi-View Sequences. Available online: http://www.fujii.nuee.nagoya-u.ac.jp/multiview-data/ (accessed on 24 January 2018).
- Multi-View Dataset. Available online: http://sydlab.net/wordpress/wp-content/uploads/2019/10/dataset.zip (accessed on 21 April 2021).
- Middlebury Stereo Vision Page. Available online: http://vision.middlebury.edu/stereo/data/ (accessed on 21 June 2017).
- Joint Collaborative Team on Video Coding (JCT-VC). High Efficiency Video Coding Reference Software. High Efficiency Video Coding Test Model 16.10 (HM16.10.). Available online: http://hevc.hhi.fraunhofer.de/ (accessed on 13 September 2018).
- Papyan, V.; Elad, M. Multi-scale patch-based image restoration. IEEE Trans. Image Process. 2016, 25, 249–261. [Google Scholar] [CrossRef] [PubMed]
- Source Codes Used in the Experiments of this PAPER. Available online: https://github.com/Digital-System-Design-Lab/Compression-Aware-Multi-view-Denoising.git (accessed on 21 April 2021).
- Bjøntegaard, G. Calculation of Average PSNR Differences between RD-Curves. In Proceedings of the Report VCEG-M33, ITU-T SG16/Q6, 13th Video Coding Experts Group (VCEG) Meeting, Austin, TX, USA, 2–4 April 2001; Available online: https://github.com/tbr/bjontegaard_etro (accessed on 21 April 2021).







| Sequence | σ | PSNR (dB) | BDBR (%) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BM3D | VBM4D | MS-EPLL | 3D-Focus | MVCNN | LFBM5D | Proposed | VBM4D | MS-EPLL | 3D-Focus | MVCNN | LFBM5D | Proposed | ||
| Champagne (1280 × 960) | 15 | 38.07 | 37.40 | 38.06 | 25.91 | 33.36 | 34.43 | 36.08 | −9.22 | +6.00 | −22.47 | −43.07 | +9.00 | −14.97 |
| 25 | 35.23 | 34.72 | 35.78 | 25.06 | 31.08 | 30.90 | 33.93 | −6.58 | −6.73 | −2.75 | −51.97 | +17.81 | −20.98 | |
| 35 | 33.33 | 32.57 | 34.20 | 23.79 | 28.12 | 29.32 | 32.18 | −0.88 | −26.92 | +12.83 | −55.81 | +9.94 | −25.32 | |
| Pantomime (1280 × 960) | 15 | 38.95 | 38.93 | 38.97 | 34.03 | 32.90 | 36.66 | 37.88 | −51.43 | +15.25 | +36.92 | −92.33 | −49.85 | −48.01 |
| 25 | 36.20 | 36.46 | 36.81 | 29.45 | 31.72 | 32.43 | 35.39 | −44.80 | −7.90 | +26.37 | −62.47 | −64.46 | −58.29 | |
| 35 | 34.46 | 34.32 | 35.27 | 22.74 | 30.45 | 31.02 | 33.23 | −54.02 | −48.38 | +62.43 | −68.22 | −77.88 | −51.64 | |
| Dog (1280 × 960) | 15 | 36.05 | 35.25 | 35.66 | 33.34 | 30.61 | 33.64 | 35.39 | −19.83 | +29.80 | −33.55 | −61.76 | −37.74 | −52.88 |
| 25 | 33.18 | 32.84 | 33.45 | 30.05 | 30.28 | 30.50 | 33.11 | −1.63 | +4.37 | +16.44 | −64.24 | −57.75 | −60.86 | |
| 35 | 31.13 | 30.91 | 31.92 | 26.09 | 29.93 | 28.32 | 31.35 | +47.82 | −25.89 | +13.24 | −69.20 | −61.28 | −60.77 | |
| Wall (1024 × 768) | 15 | 36.90 | 35.99 | 37.84 | 33.74 | 32.38 | 37.71 | 38.15 | −8.08 | +1.03 | +189.44 | −27.04 | −55.88 | −48.61 |
| 25 | 33.81 | 33.42 | 35.47 | 31.60 | 32.07 | 34.60 | 35.38 | +19.00 | −36.03 | +406.64 | −33.56 | −75.27 | −65.42 | |
| 35 | 31.61 | 31.31 | 33.83 | 29.84 | 31.76 | 32.44 | 33.06 | +148.10 | −62.21 | +167.57 | −41.74 | −83.41 | −76.05 | |
| Piano (1024 × 768) | 15 | 37.42 | 35.89 | 37.29 | 35.60 | 31.17 | 37.88 | 38.20 | −13.02 | +35.02 | +522.99 | −11.58 | −50.05 | −39.49 |
| 25 | 34.46 | 33.14 | 34.90 | 32.38 | 30.87 | 34.27 | 35.35 | +10.33 | −4.02 | +131.63 | −19.55 | −72.39 | −55.59 | |
| 35 | 32.36 | 31.01 | 33.15 | 30.24 | 30.56 | 31.86 | 33.07 | +130.98 | −41.80 | +127.47 | −34.40 | −79.18 | −65.27 | |
| Kendo (1024 × 768) | 15 | 37.73 | 35.88 | 38.14 | 33.47 | 31.23 | 36.28 | 36.71 | +5.70 | −23.47 | +1891.84 | −37.20 | −39.03 | −28.46 |
| 25 | 34.82 | 33.13 | 36.21 | 30.14 | 30.95 | 33.11 | 34.68 | +47.63 | −43.35 | +2218.42 | −46.27 | −41.51 | −39.68 | |
| 35 | 32.69 | 30.97 | 34.81 | 27.83 | 30.66 | 30.71 | 33.05 | +162.93 | −58.75 | +1902.10 | −57.39 | −41.56 | −47.12 | |
| Balloons (1024 × 768) | 15 | 36.84 | 34.56 | 36.91 | 32.12 | 31.13 | 34.86 | 36.88 | +3.10 | −14.68 | +1071.66 | −37.88 | −21.85 | −30.60 |
| 25 | 33.96 | 31.92 | 34.77 | 28.97 | 30.54 | 31.73 | 34.03 | +37.70 | −30.12 | +1220.68 | −45.56 | −30.30 | −42.88 | |
| 35 | 31.92 | 29.86 | 33.27 | 26.80 | 30.14 | 28.42 | 32.30 | +100.48 | −47.50 | +1060.70 | −54.66 | −35.73 | −49.21 | |
| 2D Sequence | σ | PSNR (dB) | BDBR (%) | ||
|---|---|---|---|---|---|
| LFBM5D | Proposed | LFBM5D | Proposed | ||
| Ohta (384 × 288) | 15 | 33.58 | 34.17 | −40.00 | −25.93 |
| 25 | 29.79 | 31.21 | −46.15 | −30.24 | |
| 35 | 27.52 | 29.31 | −43.21 | −31.39 | |
| Ohta2 (384 × 288) | 15 | 29.71 | 33.64 | +40.45 | −10.75 |
| 25 | 26.45 | 30.99 | +84.44 | −11.18 | |
| 35 | 24.40 | 29.21 | +129.02 | −10.14 | |
| Sideboard (512 × 512) | 15 | 34.08 | 33.92 | −48.22 | −20.90 |
| 25 | 30.91 | 30.63 | −60.90 | −36.17 | |
| 35 | 28.77 | 27.15 | −69.21 | −40.67 | |
| Sequence | σ | PSNR (dB) | |||
|---|---|---|---|---|---|
| BM3D | MS-EPLL | MVCNN | Proposed | ||
| Champagne (640 × 480) | 15 | 36.33 | 36.02 | 19.59 | 35.83 |
| 25 | 33.70 | 33.37 | 18.97 | 33.36 | |
| 35 | 31.52 | 31.62 | 18.19 | 31.37 | |
| Pantomime (640 × 480) | 15 | 37.35 | 37.22 | 24.00 | 37.20 |
| 25 | 34.73 | 34.63 | 22.78 | 34.51 | |
| 35 | 32.40 | 32.88 | 21.25 | 32.27 | |
| Dog (640 × 480) | 15 | 34.24 | 33.41 | 23.48 | 34.44 |
| 25 | 31.81 | 30.84 | 22.15 | 31.85 | |
| 35 | 29.99 | 29.10 | 20.84 | 29.89 | |
| Wall (512 × 384) | 15 | 37.34 | 36.30 | 24.57 | 37.76 |
| 25 | 34.58 | 33.71 | 23.04 | 34.47 | |
| 35 | 32.57 | 32.04 | 21.37 | 32.11 | |
| Piano (512 × 384) | 15 | 36.75 | 35.43 | 24.36 | 37.98 |
| 25 | 33.88 | 32.70 | 22.77 | 34.66 | |
| 35 | 31.85 | 30.95 | 21.09 | 32.34 | |
| Kendo (512 × 384) | 15 | 34.29 | 36.40 | 25.36 | 33.74 |
| 25 | 30.93 | 34.01 | 23.66 | 30.92 | |
| 35 | 29.59 | 32.37 | 21.92 | 29.63 | |
| Balloons (512 × 384) | 15 | 32.94 | 34.79 | 24.16 | 32.72 |
| 25 | 31.20 | 32.22 | 22.61 | 31.27 | |
| 35 | 28.44 | 30.51 | 21.04 | 29.70 | |
| Cotton (512 × 512) | 15 | 30.30 | 30.77 | −47.96 | −47.01 |
| 25 | 29.48 | 30.56 | −58.82 | −63.30 | |
| 35 | 28.57 | 30.02 | −60.34 | −77.45 | |
| Sequence | σ | BDBR (%) | ||
|---|---|---|---|---|
| MS-EPLL | MVCNN | Proposed | ||
| Champagne (640 × 480) | 15 | +15.94 | −79.30 | −8.97 |
| 25 | +7.31 | −84.80 | −15.52 | |
| 35 | −13.03 | −88.78 | −20.52 | |
| Pantomime (640 × 480) | 15 | +36.13 | −69.17 | −21.72 |
| 25 | +19.17 | −81.63 | −28.50 | |
| 35 | −16.65 | −89.32 | −33.21 | |
| Dog (640 × 480) | 15 | +80.70 | −85.09 | −28.40 |
| 25 | +50.12 | −91.92 | −35.59 | |
| 35 | +0.67 | −94.77 | −35.37 | |
| Wall (512 × 384) | 15 | +43.53 | −63.18 | −21.32 |
| 25 | +7.02 | −80.57 | −30.45 | |
| 35 | −30.01 | −89.55 | −29.00 | |
| Piano (512 × 384) | 15 | +67.55 | −65.07 | −36.21 |
| 25 | +18.96 | −83.73 | −48.27 | |
| 35 | −29.12 | −91.97 | −47.86 | |
| Kendo (512 × 384) | 15 | +3.15 | −58.87 | −22.19 |
| 25 | −40.66 | −80.85 | −21.46 | |
| 35 | −37.12 | −70.09 | −10.17 | |
| Balloons (512 × 384) | 15 | +14.29 | −60.74 | −8.91 |
| 25 | −7.93 | −74.25 | −16.88 | |
| 35 | −46.64 | −86.79 | −20.83 | |
| Sequence | σ | BDBR (%) | |
|---|---|---|---|
| Only Spatial | Spatial + Temporal | ||
| Champagne (1280 × 960) | 15 | −9.23 | −14.97 |
| 25 | −19.32 | −20.98 | |
| 35 | −25.38 | −25.32 | |
| Pantomime (1280 × 960) | 15 | −30.38 | −48.01 |
| 25 | −46.67 | −58.29 | |
| 35 | −55.87 | −51.64 | |
| Dog (1280 × 960) | 15 | −35.00 | −52.88 |
| 25 | −16.43 | −60.86 | |
| 35 | −49.92 | −60.77 | |
| Wall (1024 × 768) | 15 | −25.42 | −48.61 |
| 25 | −40.50 | −65.42 | |
| 35 | −46.90 | −76.05 | |
| Piano (1024 × 768) | 15 | −37.10 | −39.49 |
| 25 | −57.28 | −55.59 | |
| 35 | −66.83 | −65.27 | |
| Kendo (1024 × 768) | 15 | −22.93 | −28.46 |
| 25 | −34.98 | −39.68 | |
| 35 | −39.48 | −47.12 | |
| Balloons (1024 × 768) | 15 | −20.55 | −30.60 |
| 25 | −31.83 | −42.88 | |
| 35 | −38.02 | −49.21 | |
| Matlab | C++ | |
|---|---|---|
| BM3D | 1.00 | 9.00 |
| VBM4D | 3.59 | - |
| MS-EPLL | 1618.90 | - |
| 3D-focus | 127.33 | - |
| MVCNN | 29.33 | - |
| LFBM5D | - | 35.27 |
| Proposed | - | 1.80 |
| Searching | Number of Patches | |
|---|---|---|
| BM3D | 100.60 × 107 | 8.49 × 106 |
| VBM4D | 951.58 × 107 | 2.21 × 106 |
| MS-EPLL | - | - |
| 3D-focus | 2.06 × 107 | 98.30 × 106 |
| MVCNN | - | - |
| LFBM5D | 7.86 × 107 | 10.78 × 106 |
| Proposed | 0.06 × 107 | 4.34 × 106 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, Y.-N.; Rhee, C.-E. Improved Light Field Compression Efficiency through BM3D-Based Denoising Using Inter-View Correlation. Sensors 2021, 21, 2919. https://doi.org/10.3390/s21092919
Jin Y-N, Rhee C-E. Improved Light Field Compression Efficiency through BM3D-Based Denoising Using Inter-View Correlation. Sensors. 2021; 21(9):2919. https://doi.org/10.3390/s21092919
Chicago/Turabian StyleJin, You-Na, and Chae-Eun Rhee. 2021. "Improved Light Field Compression Efficiency through BM3D-Based Denoising Using Inter-View Correlation" Sensors 21, no. 9: 2919. https://doi.org/10.3390/s21092919