
Estimation of 6D Object Pose Using a 2D Bounding Box



Abstract
:1. Introduction
- Our approach requires no depth information and works on textured and texture-free images. It also has practical significance and can be used in everyday life.
- Compared to previous 2D detection systems, our approach worked robustly and more easily.
- We designed a channel normalize layer for uniting n-dimensional feature vectors formed by neurons in n feature maps. The calculation layer can directly output the attitude quaternion of the target. At the same time, we defined a new quaternion pose loss function for measuring the similarity of pose between models to predict and ground truth.
- We implement the Bounding Box Equation, a new algorithm for the effective and accurate 3D translation using the R and 2D bounding box.
2. Materials and Methods
2.1. Data
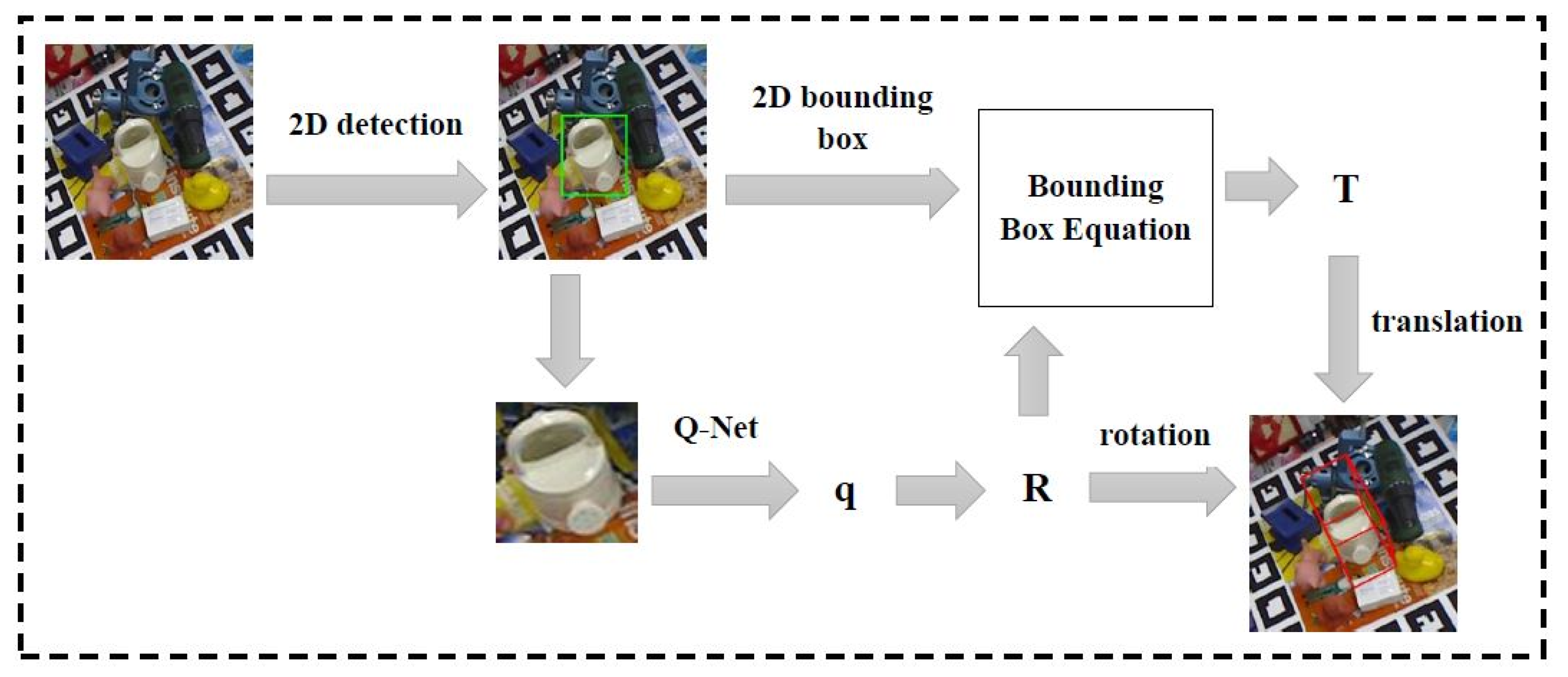
2.2. Framework of the Study
2.3. Q-Net Architecture
2.4. Loss Function for Quaternions
- L2 loss
- dot loss 2
2.5. Backward of Quaternions Loss
2.6. Bounding Box to 3D (BB3D)
2.6.1. Step 1: The Four Point-to-Side Correspondence Constraints Determination
- Method 1, Indirect comparison: According to predictions from various viewpoints.
- Method 2 Direct conversion: In the case of the n points on the surface,
2.6.2. Step 2: 3D Translation Determination
3. Results
3.1. Experiments on LineMod
3.1.1. Implementation Details
3.1.2. Visualization Results
3.1.3. Performance Evaluation
- Both BB8 and SSD were trained based on the pixel projection error, and the same length of pixel error has an entirely different influence on the attitude error of the small-scale object and the large-scale object. The biggest problem of traditional projection errors was that they could not balance the weight between small-scale objects and large-scale objects. Our method avoided this problem.
- Q-net uses a more reasonable quaternion to predict attitude and a more reasonable loss object function: Equation = 1−< q, q’ >2.
- Bb8 and SS6D only consider the projection of the eight corners of the rectangular cube of the target, while our BB3D considers the projection constraint of the n >8 points of the 3D model of the object in 3D space.
3.2. Computation Times
3.3. Experimental Results on the KITTI Dataset
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Hodăn, T.; Matas, J.; Obdržálek, Š. On evaluation of 6D object pose estimation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Collet, A.; Martinez, M.; Srinivasa, S.S. The MOPED framework: Object recognition and pose estimation for manipulation. Int. J. Rob. Res. 2011. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999. [Google Scholar]
- Rothganger, F.; Lazebnik, S.; Schmid, C.; Ponce, J. 3D object modeling and recognition using local affine-invariant image descriptors and multi-view spatial constraints. Int. J. Comput. Vis. 2006, 66, 231–259. [Google Scholar] [CrossRef] [Green Version]
- Martinez, M.; Collet, A.; Srinivasa, S.S. MOPED: A scalable and low latency object recognition and pose estimation system. In Proceedings of the IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–8 May 2010. [Google Scholar]
- Lowe, D.G. Local feature view clustering for 3D object recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Krull, A.; Brachmann, E.; Michel, F.; Yang, M.Y.; Gumhold, S.; Rother, C. Learning analysis-by-synthesis for 6d pose estimation in RGB-D images. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Michel, F.; Kirillov, A.; Brachmann, E.; Krull, A.; Gumhold, S.; Savchynskyy, B.; Rother, C. Global hypothesis generation for 6D object pose estimation. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. PoseCNN: A convolutional neural network for 6D object pose estimation in cluttered scenes. arXiv 2017, arXiv:1711.00199. [Google Scholar]
- Hinterstoisser, S.; Cagniart, C.; Ilic, S.; Sturm, P.; Navab, N.; Fua, P.; Lepetit, V. Gradient response maps for real-time detection of textureless objects. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 876–888. [Google Scholar] [CrossRef] [Green Version]
- Hinterstoisser, S.; Lepetit, V.; Ilic, S.; Holzer, S.; Bradski, G.; Konolige, K.; Navab, N. Model based training, detection and pose estimation of texture-less 3D objects in heavily cluttered scenes. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Zach, C.; Penate-Sanchez, A.; Pham, M.T. A dynamic programming approach for fast and robust object pose recognition from range images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. A large-scale hierarchical multi-view RGB-D object dataset. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Kehl, W.; Milletari, F.; Tombari, F.; Ilic, S.; Navab, N. Deep learning of local RGB-D patches for 3D object detection and 6D pose estimation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Choi, C.; Christensen, H.I. RGB-D object pose estimation in unstructured environments. Robot. Auton. Syst. 2016, 75, 595–613. [Google Scholar] [CrossRef]
- Choi, C.; Christensen, H.I. 3D textureless object detection and tracking: An edge-based approach. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012. [Google Scholar]
- Brachmann, E.; Krull, A.; Michel, F.; Gumhold, S.; Shotton, J.; Rother, C. Learning 6D object pose estimation using 3D object coordinates. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Sock, J.; Hamidreza Kasaei, S.; Lopes, L.S.; Kim, T.K. Multi-view 6D Object Pose Estimation and Camera Motion Planning Using RGBD Images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cao, Q.; Zhang, H. Combined Holistic and Local Patches for Recovering 6D Object Pose. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Kendall, A.; Grimes, M.; Cipolla, R. PoseNet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015. [Google Scholar]
- Kendall, A.; Cipolla, R. Geometric loss functions for camera pose regression with deep learning. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Tekin, B.; Sinha, S.N.; Fua, P. Real-Time Seamless Single Shot 6D Object Pose Prediction. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Mahendran, S.; Ali, H.; Vidal, R. 3D Pose Regression Using Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Kehl, W.; Manhardt, F.; Tombari, F.; Ilic, S.; Navab, N. SSD-6D: Making RGB-Based 3D Detection and 6D Pose Estimation Great Again. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Rad, M.; Lepetit, V. BB8: A Scalable, Accurate, Robust to Partial Occlusion Method for Predicting the 3D Poses of Challenging Objects without Using Depth. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Mousavian, A.; Anguelov, D.; Košecká, J.; Flynn, J. 3D bounding box estimation using deep learning and geometry. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; He, L.; Tu, Z.; Zhang, S.; Han, F.; Yang, B. Learning motion representation for real-time spatio-temporal action localization. Pattern Recognit. 2020, 103, 107312. [Google Scholar] [CrossRef]
- Doumanoglou, A.; Balntas, V.; Kouskouridas, R.; Kim, T.-K. Siamese Regression Networks with Efficient mid-level Feature Extraction for 3D Object Pose Estimation. arXiv 2016, arXiv:1607.02257. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object Class | 5 Pixels Accuracy | Averaged Pixel Projection Error (Pixels) | |||
|---|---|---|---|---|---|
| Our Method | SS6D [24] | BB8 [27] | Euler Angle | Our Method | |
| Ape | 0.9894 | 0.9210 | 0.9530 | 0.912 | 1.980852 |
| Cam | 0.9658 | 0.9324 | 0.809 | 0.431 | 2.642408 |
| Glue | 0.9680 | 0.9653 | 0.890 | 0.693 | 2.673251 |
| Box | 0.9457 | 0.9033 | 0.879 | 0.682 | 2.543196 |
| Can | 0.9130 | 0.9744 | 0.841 | 0.625 | 3.171883 |
| Lamp | 0.9347 | 0.7687 | 0.744 | 0.504 | 2.506023 |
| bench | 0.7152 | 0.9506 | 0.800 | 0.802 | 4.251370 |
| Cat | 0.9826 | 0.9741 | 0.970 | 0.931 | 2.534734 |
| hole | 0.9352 | 0.9286 | 0.905 | 0.782 | 2.613619 |
| Duck | 0.9534 | 0.9465 | 0.812 | 0.679 | 2.583827 |
| Iron | 0.9015 | 0.8294 | 0.789 | 0.645 | 2.522091 |
| Driller | 0.8985 | 0.7941 | 0.7941 | 0.465 | 2.604456 |
| phone | 0.9458 | 0.8607 | 0.776 | 0.469 | 2.698741 |
| avg | 0.926831 | 0.9037 | 0.839 | 0.663077 | 2.717419 |
| bowl | 0.956204 | - | - | 2.672496 | |
| Cup | 0.932546 | - | - | 2.987507 | |
| Object Class | eRE (Degrees) | eTE (cm) | ||||
|---|---|---|---|---|---|---|
| Our Method | BB8 [27] | SS6D [24] | Our Method | BB8 [27] | SS6D [24] | |
| Ape | 2.451113 | 2.946983 | 2.75364 | 1.865379 | 1.854367 | 1.867834 |
| Cam | 2.412643 | 2.550849 | 2.82091 | 1.842576 | 1.897132 | 1.792546 |
| Glue | 2.512097 | 2.382351 | 2.63785 | 1.632802 | 1.980421 | 1.872435 |
| Box | 2.103465 | 2.400987 | 2.56307 | 1.543097 | 1.784109 | 1.637091 |
| Can | 2.281664 | 2.139032 | 2.89345 | 1.809013 | 1.976015 | 1.873506 |
| Lamp | 2.26914 | 2.109743 | 2.76324 | 1.506136 | 1.679213 | 1.612308 |
| Bench | 2.45763 | 2.834509 | 2.81533 | 1.637125 | 1.789204 | 1.738479 |
| Cat | 2.25131 | 2.436078 | 2.89530 | 1.534072 | 1.563078 | 1.853047 |
| Hole | 2.314566 | 2.765301 | 2.91036 | 1.613631 | 1.659056 | 1.635032 |
| Duck | 2.471108 | 2.535874 | 2.74382 | 1.583450 | 1.723480 | 1.710795 |
| Iron | 2.537642 | 2.540321 | 2.62139 | 1.522011 | 1.553201 | 1.542103 |
| Driller | 2.344567 | 2.395455 | 2.65937 | 1.594294 | 1.663067 | 1.653411 |
| Phone | 2.290789 | 2.415276 | 2.673854 | 1.698068 | 1.703409 | 1.699508 |
| Average | 2.3613642 | 2.496366 | 2.750122 | 1.644743 | 1.755827 | 1.729853 |
| Object Class | Angle Error eRE | ||
|---|---|---|---|
| Quaternion with Eq Loss | Quaternion with L2 Loss | Euler Angle Model | |
| Ape | 2.451113 | 2.73248 | 2.68213 |
| Cam | 2.412643 | 2.76312 | 2.79362 |
| Glue | 2.512097 | 2.80914 | 2.84532 |
| box | 2.103465 | 2.64539 | 2.39451 |
| Can | 2.281664 | 2.71356 | 2.50638 |
| Lamp | 2.26914 | 2.59823 | 2.43572 |
| bench | 2.45763 | 2.67291 | 2.7918 |
| Cat | 2.25131 | 2.63078 | 2.58342 |
| hole | 2.314566 | 2.62335 | 2.70135 |
| Duck | 2.471108 | 2.71123 | 2.70816 |
| Iron | 2.537642 | 2.86204 | 2.88425 |
| Driller | 2.344567 | 2.63417 | 2.67134 |
| phone | 2.290789 | 2.58392 | 2.58239 |
| average | 2.3613642 | 2.690794 | 2.66003 |
| Cost Time 1000 Instances (MS) | Average Cost Time (MS) | |
|---|---|---|
| BB3D (n points) | 34,000 | 34 |
| BB3D (8 points) | 1273 | 1.273 |
| Algorithm in [28] (8 points) | 3,786,923 | 3786.923 |
| Method | Cost Time for One Object (MS) | ||
|---|---|---|---|
| SS6D [24] | 18.67 | ||
| BB8 [27] | 91.45 | ||
| Q-Net | BB3D | total | |
| Q-Net | 5.68 | 1.2 | 6.88 |
| Model Technical Index | Value | Description | Changes in the Training Process |
|---|---|---|---|
| Avgerage_loss | 0.882620 | The overall loss in the training process. | In the training process, loss decreases with the increase of iteration times, which indicates that the learning process of the model can converge |
| IOU | 0.811207 | The average value of IOU between the predicted box and the ground truth box. | In the training process, with the increase of iterations, the IOU is increasing, which indicates that the object box prediction is gradually accurate |
| Pose_dot | 0.974438 | The dot product between Q-net predicted object attitude quaternion and true value attitude quaternion | In the training process, with the increase of the number of iterations, the value of poses dot increases and Approaches 1. This indicates that the quaternion of object attitude obtained by Q-net is approaching the true value. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, Y.; Liu, J.; Jahangir, Z.; He, S.; Zhang, Q. Estimation of 6D Object Pose Using a 2D Bounding Box. Sensors 2021, 21, 2939. https://doi.org/10.3390/s21092939
Hong Y, Liu J, Jahangir Z, He S, Zhang Q. Estimation of 6D Object Pose Using a 2D Bounding Box. Sensors. 2021; 21(9):2939. https://doi.org/10.3390/s21092939
Chicago/Turabian StyleHong, Yong, Jin Liu, Zahid Jahangir, Sheng He, and Qing Zhang. 2021. "Estimation of 6D Object Pose Using a 2D Bounding Box" Sensors 21, no. 9: 2939. https://doi.org/10.3390/s21092939
APA StyleHong, Y., Liu, J., Jahangir, Z., He, S., & Zhang, Q. (2021). Estimation of 6D Object Pose Using a 2D Bounding Box. Sensors, 21(9), 2939. https://doi.org/10.3390/s21092939