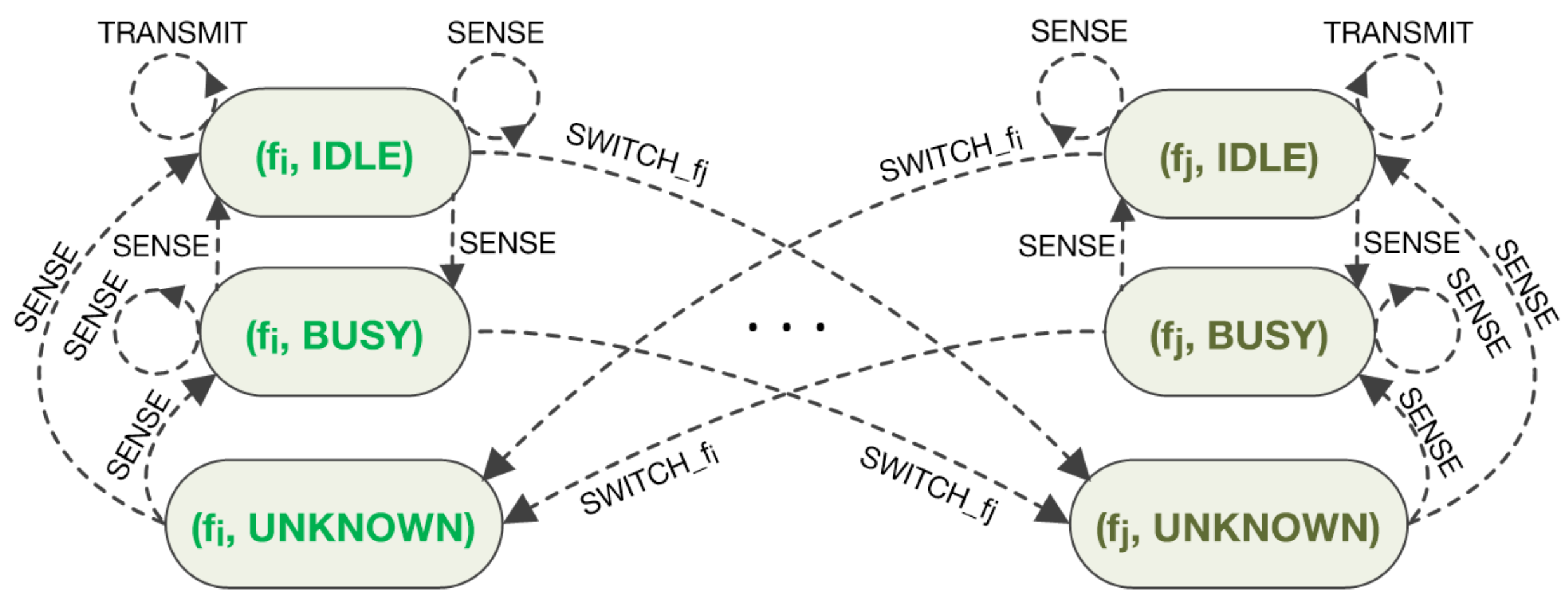
In this section, we propose novel, truly decentralized and distributed, networked MARL solutions to the problem of JSS in CRNs, which exploit possibility of cooperation among neighboring nodes, while preserving scalability and robustness properties. Specific adaptations and extensions of the MARL schemes presented in References [
12,
19,
20] are proposed to tackle the JSS problem. The proposed decentralized scheme can be regarded through three main aspects: (1) as a tool for organizing coordination of actions of multiple nodes/agents, covering complementary parts of the state space, but contributing to a common goal, (2) as a parallelization tool, allowing faster convergence, useful particularly in the problems with large dimensions (e.g., large number of available frequency channels), and (3) as a denoising tool, exploiting a possibility to average agents’ different noise realizations, including the cases in which some agents may have large spectrum sensing probabilities of error, or are faced with higher PER on certain channels (e.g., due to the fading and shadowing effects); in such cases, their decisions will be, in average, corrected by typically larger number of nodes with better sensing conditions.
Specifically, we focus on a MARL setting where
N autonomous SUs/nodes/agents are connected through a dedicated (typically low bandwidth) network (independent or dependent on the CSC) and are able to communicate information in real time only with the neighboring nodes (e.g., mobile ad hoc networks and sensor networks [
1,
28,
36,
37]). We formally model this dedicated communication network by a directed graph
where
is the set of nodes, and
the set of directed links
. Denote as
the set of neighboring nodes of the node
i (i.e., the set of nodes which can send information to the node
i, including node
i itself). For large scale networks, it is typically expected that
.
4.1. Distributed Consensus-Based Policy Evaluation
In this subsection, we treat the problem of distributed policy evaluation in the above described multi-agent setting. It is assumed that each
has a different behavior policy
so that each MDP (corresponding to each
) reduces to a plane Markov chain with a different state transition matrix
which is obtained from function
T by fixing the policy to
. We consider the problem of decentralized evaluation of a particular target policy
(inducing a Markov chain with the transition matrix
P). The value function of policy
is given in Equation (
3). Hence, each agent seeks to learn the vector
(since the total number of states is
, see the assumed model above). Let the Markov chain under the target policy
be irreducible, for which there exists a limiting distribution
, and a unique value function
. For our concrete model, this implies that, under the target policy
, the agents should “visit” each channel infinitely often (see the next section for discussion on relaxation of this condition). We further introduce the local importance sampling ratios
for all
(with
), where
and
are the probabilities of transiting from state
s to
under
and
, respectively. We denote each agent’s estimate of the value function vector by
. Introduce the global vector of all the agents’ estimates by
.
Based on the results from Reference [
12], we define a global constrained minimization problem for the whole network, indicating how closely the estimates of the value function satisfy the Bellman equation:
where
are the
local objective functions,
,
, a priori defined weighting coefficients, and
invariant probability distributions of each agent’s Markov chain (induced by the local behavior policies),
R is the vector of the expected immediate rewards (for all states).
Based on the above setup, we propose a distributed and decentralized consensus-based algorithm for the estimation of
aimed at minimization of (
7), which is an adaptation to our specific problem of the general algorithm proposed in References [
11,
12]. The scheme is based on a construction of a distributed stochastic gradient scheme, resulting in the TD+consensus iterations:
where
is (typically small) step size,
is the TD error,
and
denote the value function estimates at state
s before and after local update (
8), respectively,
is the reward received by node
i at step
k,
is the state of
at time
k,
, and
is the importance sampling ratio at step
k for agent
i. The initial conditions for the recursions are arbitrary. The parameter
represents the gain at step
k which agent
i uses to weight the estimates received from agent
j (note again that this communication takes place through the dedicated, signaling network defined above, and not through the licensed spectrum being explored by the SUs). These parameters are random in general; they are equal to some predefined constants if the consensus communication at step
k succeeded (with probability
), and equal to zero if the communication failed (with probability
). In addition,
if
, i.e., if node
j is not a neighbor of node
i.
The algorithm consists of two steps: (1) local parameter updating (
8) based on a locally observed MDP transition and a locally received reward; (2) consensus step (9) at which the local neighbors-based communication happens (along the dedicated network). The second step is aimed at achieving (in the decentralized way) the global parameter estimation based on distributed agreement between the agents, see Algorithm 1 for the implementation details.
In References [
11,
12], the convergence of the above algorithm has been proved under several general assumptions. For our specific problem setup, the convergence of the above algorithm is guaranteed under the following conditions on the agents behavior policies:
(A1) The transition matrices are irreducible and such that for all , ⇒, .
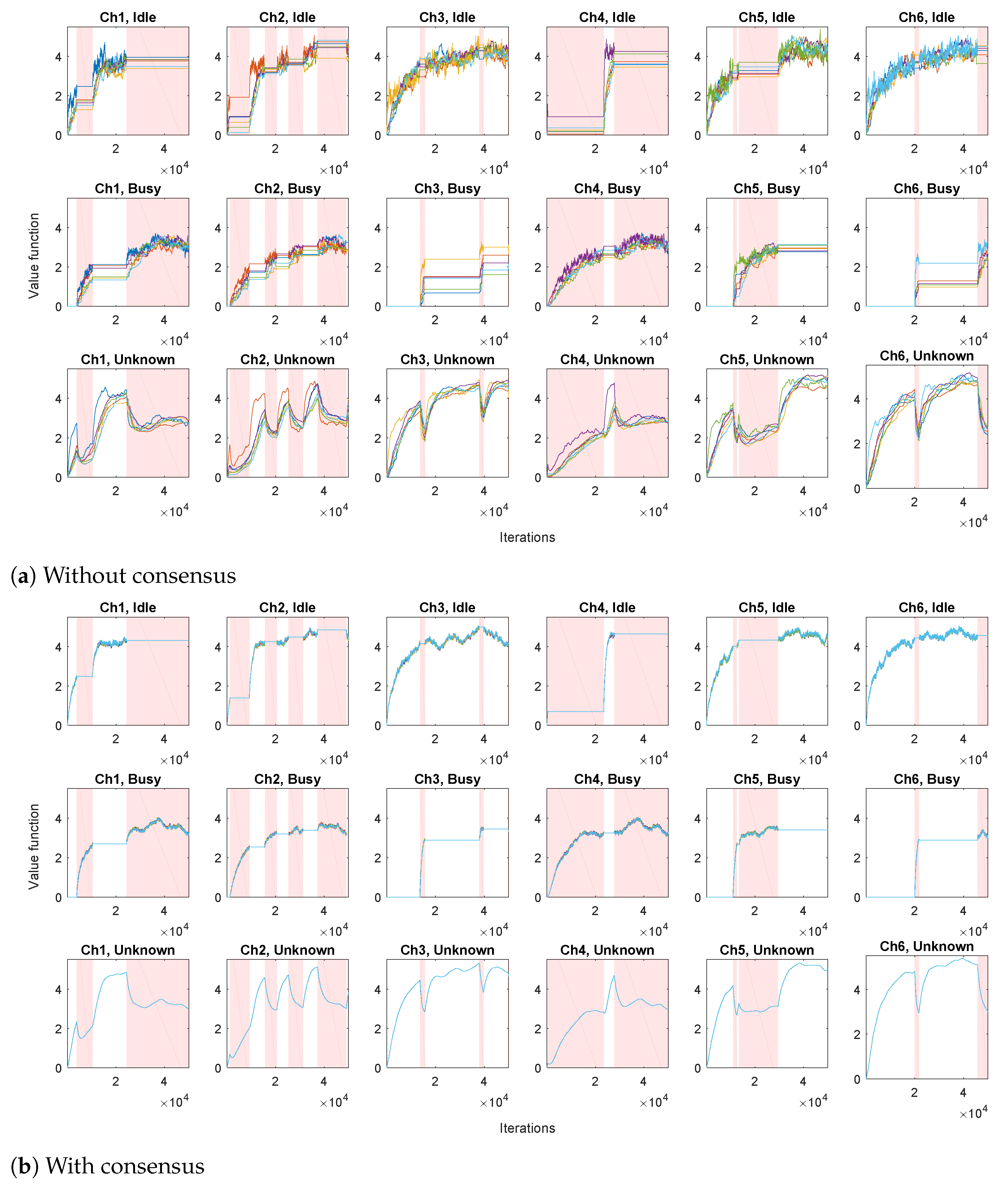
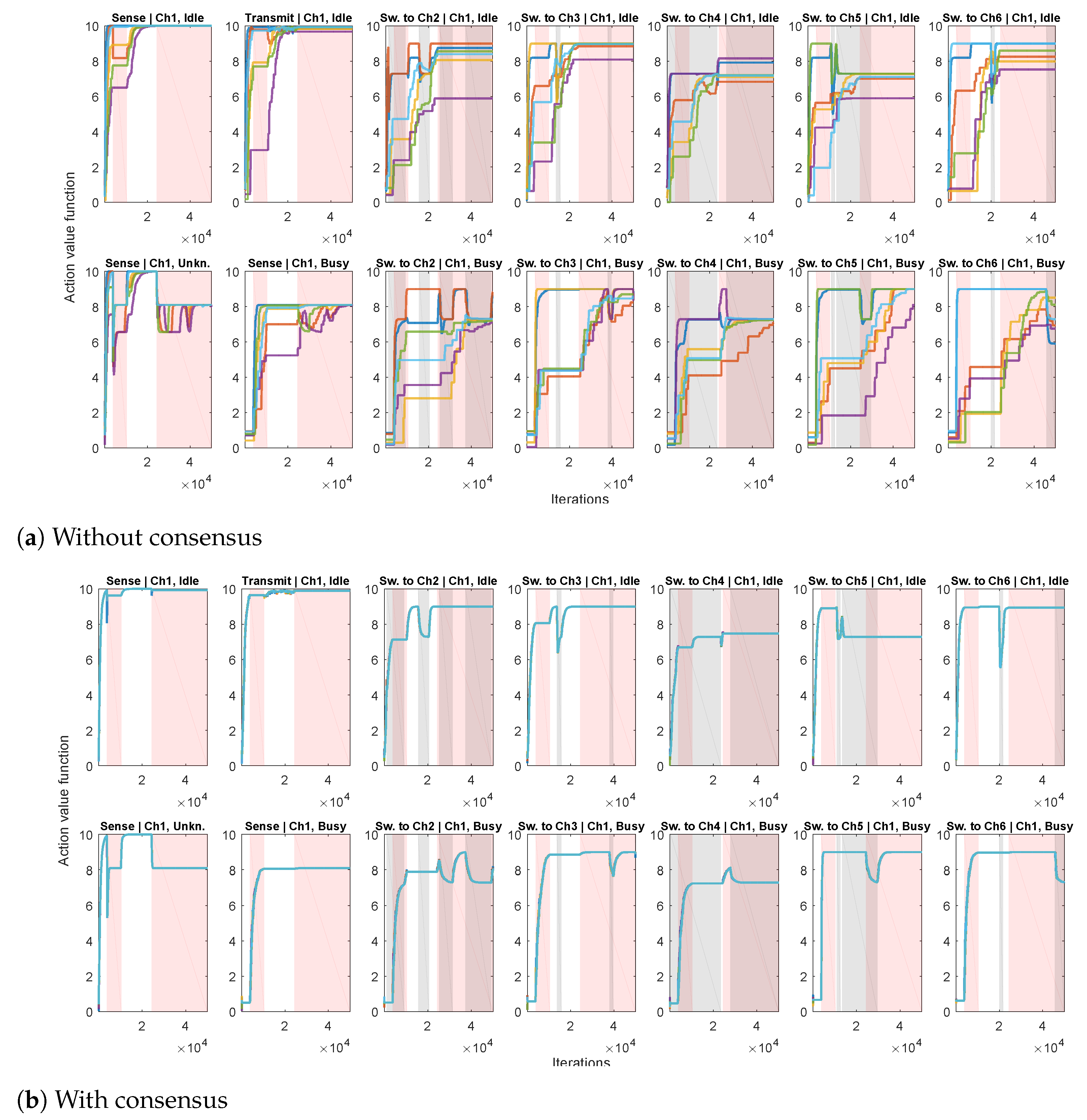
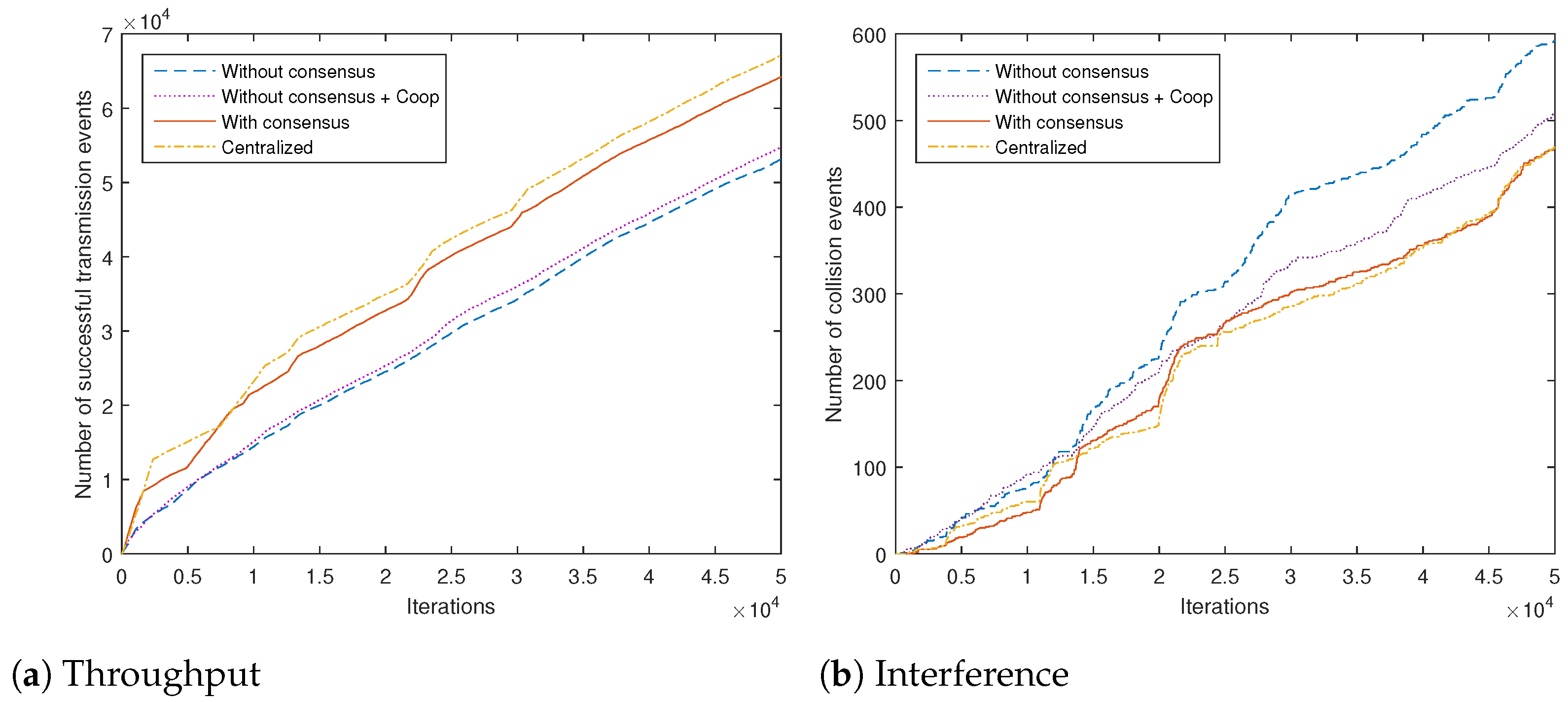
The condition of irreducibility essentially means that the underlying MDPs (under all the behavior policies) are such that all the agents should be able to explore all the states. The second part ensures that the importance sampling ratios are well defined. Note that, in practice, according to our multi-agent setup, each agent is typically focused only on a part of the overall spectrum, by assigning high probabilities of visiting these parts of the state (channels), and low probability to the others. This complementarity can drastically improve the overall rate of convergence, as will be demonstrated in the simulations section.
The following conditions deal with the inter-node communication structure:
(A2) There exist a scalar and an integer such that
, for all k, and , .
(A3) The digraph is strongly connected.
(A4) Random sequences
,
(consensus communication gains) are independent of the Markov chain processes induced by the agents’ behavior policies.
| Algorithm 1: Distributed consensus-based policy evaluation. |
 |
Assumption (A2) formally requires existence of a finite upper bound (uniformly in
k) on the duration of any time interval (number of iterations) in which the neighboring SUs are not able to communicate with positive probability of communication success. Hence, it allows a very wide class of possible models of communication outages, such as the randomized gossip protocol with the simple Bernoulli outage model [
38]. (A3) defines the minimal inter-agent network connectivity. The requirement is that there is a path between each pair of nodes in the digraph, which is needed to ensure the proper flow of information through the network (see, e.g., References [
38,
39]). Assumption (A4) is, in general, required for successful stochastic convergence, i.e., for proper averaging within the consensus-based schemes [
12]. We consider all the conditions to be logical and typically satisfied in practice.
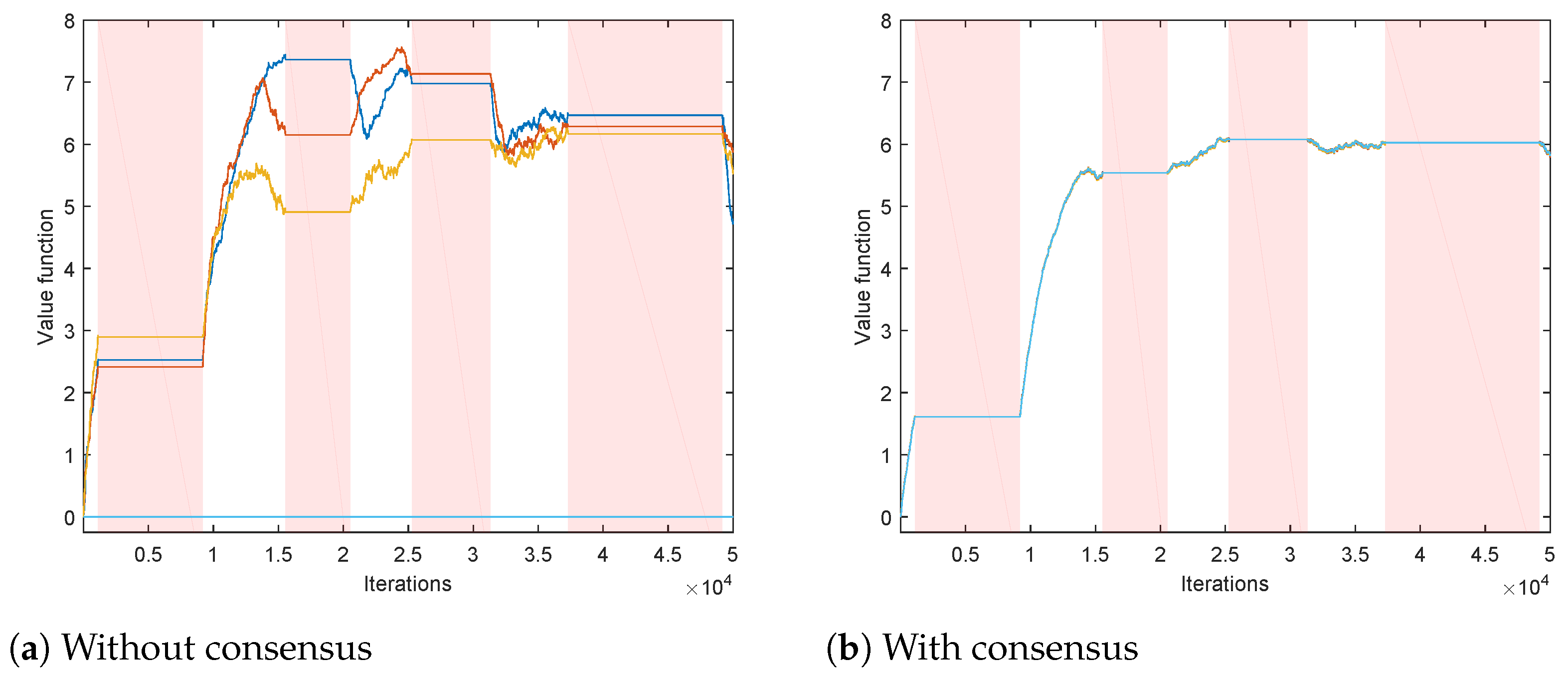
Careful selection of weighting factors
and
enables the user to emphasize contribution of certain nodes which have larger confidence in correct sensing of PU activities at certain channels compared to the remaining nodes. Furthermore, significant improvement of the overall rate of convergence of the algorithm can be achieved by a proper design strategy that would facilitate a form of overlapping decomposition of the global states (frequencies) leading to complementary nodes’ behavior policies. Another point to be considered are the time constants of information flow throughout the network. Implementation of multi-step consensus among the nodes within time intervals between successive measurements might be beneficial in cases when the possible inter-nodes communication rates are larger, allowing such a scheme [
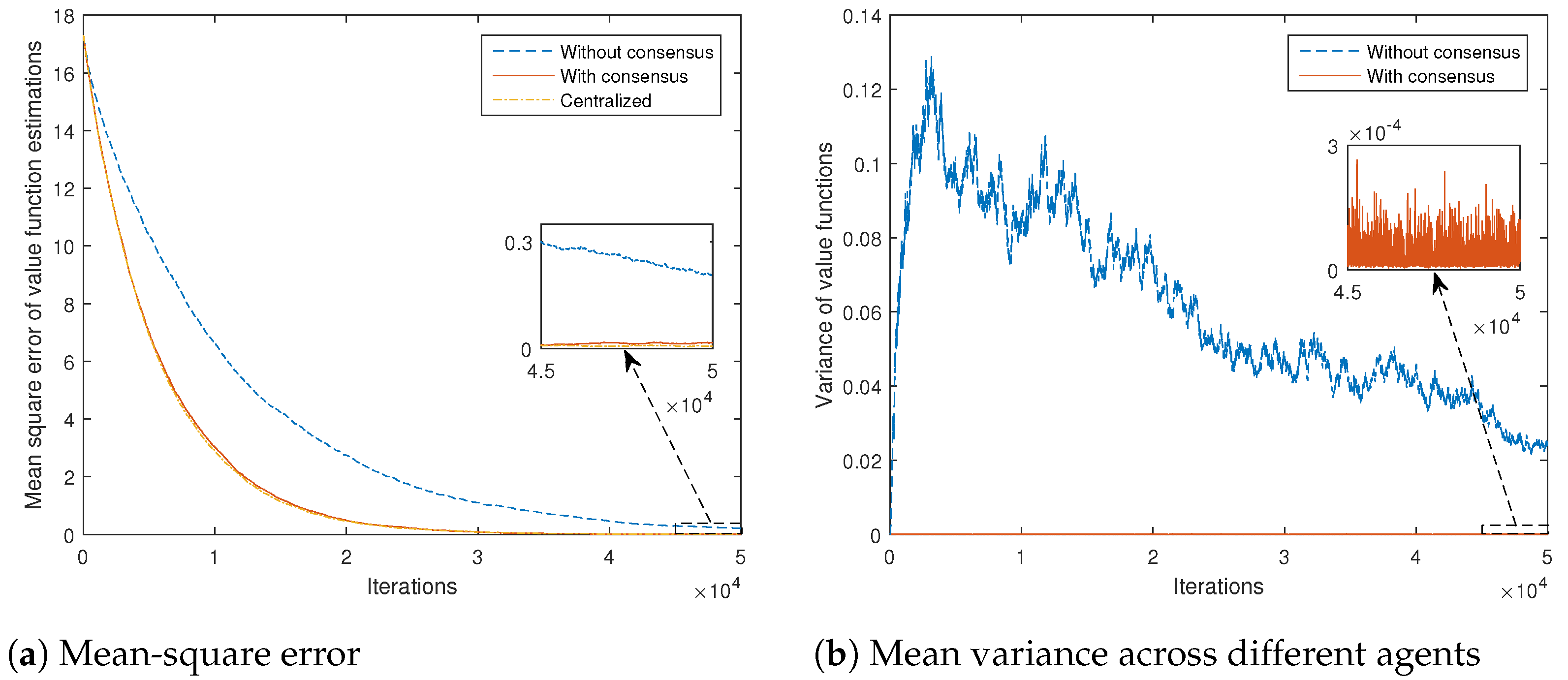
37]. Even if the agents’ behaviors are not selected in a complementary fashion, i.e., the visited states largely overlap among the agents, the “denoising” phenomenon represents another motivation for adopting the proposed consensus-based approach. In general, estimation algorithms based on consensus are characterized by nice “denoising” properties, i.e., by reduction of the asymptotic covariance of the estimates [
40,
41]. Recall that the variance reduction is one of the fundamental problems in TD-based algorithms, in general, e.g., References [
8,
42], and that in References [
11,
12], wherein the denoising effect was proved for consensus-based schemes similar to the above proposed.
4.2. Distributed Consensus-Based Q-Learning
The policy evaluation scheme described in details in the previous subsection naturally generalizes to the case of the action-value function (Q-function) learning, from which an optimal policy can be directly obtained. The popular Q-learning algorithm [
8] is a single-agent algorithm, derived from (
5) by applying TD-based reasoning, similar to the state-value function TD-based learning in (
8). Since the objective is now to find the optimal policy, the main difference is that, in each step, an action is typically not selected based on a fixed policy (as in the policy evaluation problem), but by applying some exploration/exploitation strategy.
Hence, for the purpose of distributed searching of optimal policy in our CRN JSS model, we propose to use the same setup as in the previous subsection, while replacing local iterations in (
8) with the local Q-learning iterations:
where
and
are the matrices of
i-th node’s estimates (before and after the local update (
10) is applied, respectively) of the Q values (
5) for all the possible state-action pairs,
is the
i-th node’s estimate of the optimal action value (after the consensus update has been applied) for the particular state-action pair
, and
and
are the same as in the previous section. Hence, in each time step, an agent performs the local iteration (
10), locally updating only the estimate of the Q-function for the current state
and applied action
, receives the estimates of all the Q values from its neighbors, and performs the consensus iteration on Q estimates for all the state-action pairs. The initial conditions can be set arbitrary; however, it should be kept in mind that high values of the initial conditions will encourage exploration if a greedy policy is applied. It is also possible to reset initial conditions once the first reward is received for a particular state-action pair [
8].
In the typical Q-learning setup, the action at step
k is chosen using a form of
-greedy strategy [
8]. In our multi-agent case, we propose a modified
-greedy strategy, where, for the overall performance, it is beneficial that each agent, when exploring (with probability
) has a different set of channels of preference. This way the convergence speed can be drastically improved by exploiting the complementary state space coverage by different agents (similar to the case of complementary behavior policies in the above case of policy evaluation). This has been demonstrated in the simulations section.
The consensus step in the algorithm is the same as in (9), except that the agents must communicate, in each iteration, their Q-function estimates for all the pairs of possible states and actions (see Algorithm 2 for details). A similar general scheme has been proposed in Reference [
19], with rigorous convergence analysis, but under a considerably limiting assumption that the actions selection strategy is a priori fixed and independent of the current agents’ Q-function estimates.
All the other appealing properties discussed in the previous sections still hold for the above proposed distributed Q-learning algorithm.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}