1. Introduction
With the development of network technologies and the popularity of smartphones, crowdsourcing has become a popular distributed paradigm for problem-solving, which is applied to address problems that are too complex for computer programs or of high cost for an organization. An early typical example of crowdsourcing is captcha. ReCAPTCHA [
1], a project initiated by Carnegie Mellon University, uses the wisdom of the masses to help the digitization of ancient books in the form of crowdsourcing. This project scans the text, which cannot be recognized by the optical character recognition technology accurately, and displays it in the captcha question, so that a human can recognize it when answering the captcha question.
In the era of big data, the amount of data is increasing, and the forms of data are more diversified, which leads to increasing demand for crowdsourcing and the increasing forms of tasks. Crowdsourcing platforms such as Amazon Mechanical Turk (AMT) [
2], crowdflower and upwork of Amazon came into being. On these platforms, tens of millions of workers from more than 100 countries are involved in solving problems. It has inspired the collective imagination of researchers in numerous fields such as human–computer interaction, machine learning, artificial intelligence, information retrieval, database community, etc.
The openness and sharing of crowdsourcing make it more vulnerable to various attacks since it allows attackers to join crowdsourcing systems freely as requesters or workers. When task requesters have tasks to crowdsource, they need to set some parameters, including task pricing, answer time, task worker quality, etc. After that, they can publish tasks on the crowdsourcing platform, and then the tasks will be assigned to workers. When a task is answered by a worker, the requester can choose to accept or reject the answer. If the requester accepts the answer, he/she will pay the worker accordingly. In this process, combined with the task constraints, task content and worker authentication information, the attacker may infer the important private information of the participants, including identity, age, occupation, residence, and so on. If such kind of information cannot be properly kept, it will reduce the enthusiasm of users to participate in the task and further affect the completion of the task.
In the process of task release and matching, since different workers have their own specialties, unsuitable or malicious workers may randomly answer questions to get the reward, or deliberately submit wrong answers to distort the true value. To ensure the quality of answers, the requester should set up task constraints for different tasks so as to match appropriate workers. There are many ways of keyword matching. The flexibility of accurate matching is poor. The matching method that supports multiple policy expressions is more in line with diverse requirements, e.g., ((major = (art ∨ artificial intelligence)) ∧ (age ≥ 30)), etc. Under the premise of privacy protection, how to achieve flexible task-matching has become a thorny issue.
In most previous mutual privacy-preserving task allocation research, the homomorphism [
3] is adopted to realize multiple types of ciphertext policy matching without revealing task constraints and workers’ private attributes, which cause the downgrade of efficiency. Moreover, content confidentiality is closely related to the privacy of participants. For the privacy of the task content, the proxy re-encryption algorithm or other technologies is needed. Then the computation and communication cost is further increased. However, based on inner-product encryption the relevant work [
4] considered flexible matching of encrypted keywords and fine-grained access control of task content simultaneously. With the expansion of the network scale, it is difficult for a single authentication center to manage workers’ keys efficiently. The multi-authority model [
5] could better adapt to a large-scale distributed network. However, at this time, there are not only collusion problems of workers but also collusion or damage problems of some attribute authorities in the system.
After the task is assigned, the worker will perform the task and submit task data. At this phase, we should first ensure that it is the right workers who meet the requirements submit the answers. However, similarly, the workers may not wish to be tracked by the server. Since the platform is not completely credible, it may expose the worker’s privacy because of interest-driven. Due to the flexible matching requirements set by the task requester, an attribute-based signature could be used. It allows signers to sign a message under policies that satisfying their attributes. In a crowdsourcing system, the worker obtains the attribute-based private key from the authority. When his/her attributes satisfy the constraint policy set by the requester, the signature can be verified to be valid. With anonymous attribute-based signature authentication, it is possible to prevent inappropriate workers from submitting, while avoiding the leakage of worker’s privacy. However, dishonest qualified workers may submit multiple answers to a task for more rewards. Moreover, if a greedy participant submits similar or identical results with different pseudonyms many times, it will also reduce the diversity and credibility of the data, and further produce bias to the results that should have been perceived by numerous participants. Actually, a privacy-preserving submission detection scheme is needed, which ensures that only qualified workers can participate in answering and cannot submit repeatedly, and the worker’s identity and history of participating in the task will not be disclosed.
In this paper, we first analyze the potential security threats to the privacy and quality assurance issues of crowdsourcing during the task allocation and task submission phase, and then propose a security and privacy protection model of the system. After that, a scheme based on multi-authority inner-product encryption (MIPE) and zero-knowledge proof protocol, called zk-MIPE, is designed. With MIPE, the scheme can realize secure sharing of task content and the flexible assignment of tasks based on encrypted task constraints and workers’ attributes. With the repeated submission detection algorithm constructed by zero-knowledge proof protocol, it ensures that the requester and platform can only verify that a worker who has submitted an answer about a task meets the corresponding task constraints but cannot judge his/her specific identity or attribute information. Also, if the worker performs multiple tasks, no one can link them. At the same time, when workers submit repeatedly for the same task, they can be identified by association. Under the premise of protecting the participants’ privacy, the scheme selects suitable workers to submit an answer honestly with more professional skills, thus further improve the quality of aggregated task data. In summary, the technical innovation of the proposed system is: we designed a novel MIPE scheme and a one-time anonymous inner-product authentication protocol based on zero-knowledge proof, and proved the confidentiality, one-time authentication, anonymity and unlinkability of the solution. In terms of application, we achieved the innovative features in function and security for crowdsourcing privacy protection: (1). it supports flexible task-matching based on inner-product with mutual privacy; (2). it supports anonymously inner-product-based authentication and duplicate submission detection without revealing identity and attributes privacy.
2. Related Work
Crowdsourcing Privacy
Presently, for a variety of data processing and analysis tasks, only relying on machine algorithms cannot achieve desired results. Fortunately, crowdsourcing provides an efficient and low-cost paradigm to solve this problem with the advantage of distributed mode. However, security and privacy issues are still thorny. In past research on privacy-preserving, some researchers analyzed the privacy threats of the whole crowdsourcing process to propose an overall security framework [
6]. Meanwhile, blockchain is applied to deal with potential security issues (e.g., single point of failure, sensitive leakage) without a trusted third party, such as SecBCS [
7], MCS-chain [
8], CrowdBC [
9]. Also, novel fog-based computing framework is proposed [
10] for low latency vehicular crowdsensing networks.
Still, there are researchers in-depth discussing crowdsourcing security threats at each phase, and designing differentiated privacy protection schemes for specific security objectives using diversified technologies. Among them, location privacy is the first concern of researchers. The methods used to solve location privacy include k-anonymity [
11], differential privacy [
12,
13], game theory [
14], commitment [
15], machine-learning-based obfuscation [
16,
17], encryption [
18,
19], etc. However, most of them focus on protecting the workers’ privacy. To provide mutual privacy for both requesters and workers, Liu [
3] proposed a privacy-preserving protocol based on homomorphic encryption with a dual-server setting. After that, Shu [
20] constructs a task-matching scheme over the encrypted location with a single server by applying searchable encryption. Actually, in the scenes they mainly concern, the privacy requirements of task content are not high, which are usually public to all participants. However, the need for content privacy protection still exists. For some sensitive task content involving address, occupation and purpose, it can help attackers to further infer participants’ privacy by combining other information. In the privacy-aware task assignment schemes proposed by Liu et al. [
21] and Yuan et al. [
22], attribute-based encryption is applied to protect content privacy and realize fine-grained access control. Extending to more complex multi-keyword crowdsourcing allocation scenario, our prior work [
4] introduced inner-product encryption (IPE) to support flexible matching policies without disclosing task privacy and worker privacy. However, as the worker scale increases, centralized single authority mode has obvious disadvantages in efficiency and security.
Moreover, most of these schemes mainly discussed privacy protection in the task allocation phase. While in the data submission phase, the platform should verify the identity or attribute information of the participants to evaluate whether the appropriate workers have performed the task. At this time, if we do not provide effective privacy protection, the secure closed-loop still cannot be constructed. Based on signature and other technologies, Ni [
23] and Shu [
24] presented Sybil detection schemes respectively. Nevertheless, they are concerned about the deduplication of encrypted data content rather than the identity privacy of workers. Though Lu [
25] proposed a blockchain-based private and anonymous repetition detection scheme for task submission, the introduction of zk-SNARK increases the computational overhead of the scheme. Compared with the previous scheme, we focus on the privacy protection of task releasing and task submission. In the task releasing stage, the scheme requires privacy of task content and constraint conditions, and should realize flexible ciphertext task-matching. In the task submission phase, workers could submit perceptual data anonymously and cannot submit it repeatedly.
Inner-Product Cryptosystems
In 1984, Shamir [
26] proposed the concept of ID-based public key cryptography and constructed the first ID-based digital signature scheme based on the large integer decomposition problem. However, it was not until 2001 that Boneh and Franklin [
27] presented the first secure and practical ID-based encryption scheme based on elliptic curve bilinear pairings. After that, Sahai and Waters [
28] designed a fuzzy identity-based encryption scheme based on key sharing theory in 2005, and further proposed the concept of attribute-based encryption (ABE). Since then, research on ABE has covered privacy protection, richer access policy types, efficiency, security assumptions, attribute revocation, and other directions [
29,
30,
31]. To implement policy hiding, Boneh and Waters [
32] introduced a hidden vector encryption scheme supporting conjunctive, subset and range queries in 2007. Then Katz [
33] raised the concept of IPE for the first time and proved its security under the standard model in 2008. The scheme allows conjunctive disjunction, polynomial and inner-product queries. However, the length of ciphertext increases linearly with the increase of vector dimension. Afterwards, Attrapadung and Libert [
34] developed a scheme to reduce the length of ciphertext to a constant. Furthermore, Okamoto [
35] realized a scheme with constant key length. On the other hand, to reduce the management cost of a single authentication server, Chase [
5] presented an encryption scheme that enables the implementation of the AND access policy in a multi-authority environment. On this basis, to reduce the complexity of user decryption, Li [
36] constructed a multi-authority outsourcing attribute encryption system based on linear secret-sharing schemes (LSSS). However, the IPE scheme in multi-authority environment still needs to be proposed. For anonymous authentication, Yuen [
37] adopted
k times attribute signature (
k-ABS) to restrict access times. The data is still stored remotely in plaintext. Ning presented an outsourced
-time attribute-based encryption (
-ABE) scheme [
38], in which users apply attributes as identity without using real names. Although the server cannot know a user’s identity, it can associate a user’s previous and subsequent access through the proxy key. Moreover, due to the lack of association between the attribute-related private key and the validation tags for times, there is a risk that the attacker will steal the other’s validation tag, and then send his own attribute-related private key to access the data illegally. Inner-product cryptosystems enables the realization of flexible and diverse policies. Compared with cryptosystems supporting LSSS policy, it allows policy hiding. However, presently, neither the IPE encryption for multi-authority nor the k-time inner-product-based authentication scheme has been proposed. Therefore, in this article, we intend to solve this problem and apply the design scheme to crowdsourcing privacy protection.
3. Preliminary
3.1. System Assumption
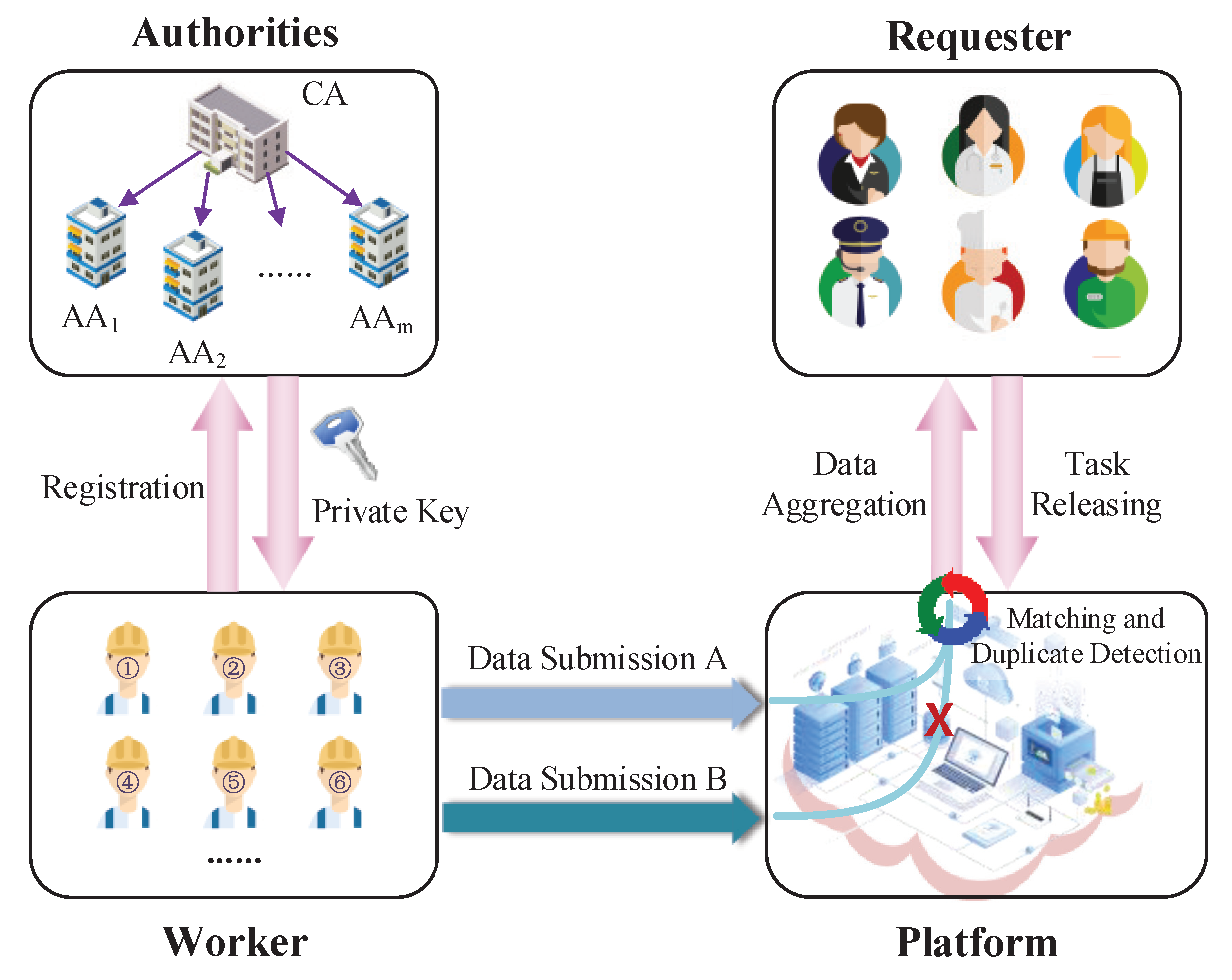
As shown in
Figure 1, the proposed crowdsourcing system contains the following entities: central authority
, multiple attribute authorities
, the crowdsourcing server
, requesters and workers. As a trusted third party,
initializes the system, generates global parameters and supervises each
. Suppose there are
m attribute authorities, denoted as
,...,
. They are responsible for managing disjoint attribute sets. The requester is an enterprise or individual who publishes the task on the system platform. The worker is a user who performs tasks and submits perception data.
verifies whether workers meet the requirements and submit repeatedly. Let the sets of vectors
and
be the task constraint and the worker’s attribute-based vector. Only if
holds for all
, the worker could decrypt the corresponding task ciphertext.
For system security, we need at least one attribute authority is honest and secure in such a system. The requester is also considered to be honest. is considered to be honest-but-curious, i.e., it will honestly execute the protocol and screen out suitable workers, but it will also be curious about more information, such as task content and participant identity. The worker is considered to be honest but greedy, i.e., he will execute the protocol honestly but may submit data multiple times to get more rewards.
The specific security objectives of the zk-MIPE scheme are as follows.
(1) Content and constraints privacy. Task content and constraints should be released in the form of ciphertext. Only suitable workers could learn the corresponding task plaintext.
(2) One-time attribute-based authentication. If the worker’s attributes meet the task constraints, he/she can provide a valid proof to the CS. If not, he/she cannot forge a valid proof.
(3) Identity and attribute privacy. Although the CS enables the filtering out of suitable workers and the restriction of multiple submission, it cannot know the worker’s identity and attributes, or even associate the previous and subsequent tasks that a worker participates in.
3.2. Inner-Product Access Structure
The inner product is a generalization of the concept of point multiplication. In a vector space, it is a method of multiplying vectors, and the product is a scalar. For a real vector space, let be vectors and r be a scalar, then the inner product satisfies the following properties.
(1) ;
(2) ;
(3) ;
(4) , and only when the equal sign holds.
3.3. Bilinear Group
Definition 1. Bilinear Map [27]: A group generator takes a security parameter λ as input. It outputs a group of prime order q, where is an additional group and is a multiplication group. Let g be a generator of . The bilinear map e has the following properties. (1) Bilinearity: For random and , we have ;
(2) Nondegeneracy: ;
(3) Computability: For random , there exists an efficient algorithm to compute .
Definition 2. Computational Diffie-Hellman (CDH) Problem: A challenger runs to generate . Then it chooses a random generator g and random . Given a tuple as input, we say that the CDH assumption holds if there is no polynomial-time algorithm can compute the element .
Definition 3. Decisional Diffie-Hellman (DDH) Problem: A challenger runs to generate . Then it chooses a random generator g and random . Given a tuple as input, we say that the DDH assumption holds if there is no polynomial-time algorithm can distinguish from a random value with nonnegligible advantage in .
Definition 4. q-Decisional Diffie-Hellman Inversion (DDHI) Problem: A challenger runs to generate . Then it chooses a random generator g and a random . Given a tuple as input, we say that the q-DDHI assumption holds if there is no polynomial-time algorithm can distinguish from a random value with nonnegligible advantage in .
3.4. Zero-Knowledge Proof Protocol
The zero-knowledge proof (ZKP) protocols have been applied to numerous fields, including both traditional secure multiparty computation and emerging privacy protection projects in distributed ledger and blockchain, such as Zcash [
39], hawk [
40], and so on.
A ZKP system is a protocol between a computationally bounded prover and a verifier. Let R be an NP relation. Set and the language . During the protocol, the verifier is convinced by the prover that x belongs to L, i.e., there exists a witness w such that for x. However, in proof of knowledge (PoK), the prover cannot only prove the exists of some witness but also be convinced that he/she indeed know a specific witness w.
The main properties of ZKP for a relation R are as follows.
Completeness: Given a witness
that satisfies
, the prover could convince the verifier of his knowledge. i.e.,
Soundness: Given a witness
that does not satisfy
, for any polynomial-time prover, the probability that the verification can be accepted is negligible. i.e.,
Zero knowledge: The interaction between a prover and a verifier is called a view. The zero-knowledge property could be captured by the existence of a simulator E that could access to the verifier’s input but not the prover’s: with the assumption , if the simulated view, i.e., the transcript, is indistinguishable from the original view between the honest prover and the verifier, whether honest or cheating. We say the ZKP scheme has the property of zero knowledge. Moreover, in PoK, there exists a knowledge extractor, which has rewindable access to the prover, and could extract the witness with nonnegligible probability.
4. Model of zk-MIPE
Definition 5. A privacy-preserving task-matching and multi-submission detection scheme zk-MIPE is defined by a tuple of the following algorithms:
CA Setup. The algorithm is executed by the central authority . It takes a security parameter and several attribute authorities m as inputs. It then publishes a system public key and keeps a system master key secretly.
AA Setup. Run by the attribute authorities , the algorithm takes a security parameter and several intra-domain attributes n as inputs. It then outputs a public key and an attribute-related secret key for each .
Task Releasing. Executed by the requester, the algorithm takes the public key, a message and a constraint as inputs. Then it outputs an inner-product ciphertext C.
Registration. According to the identity u and attributes , the secret key for the registrant is generated by and .
Decryption. Executed by the worker u, the algorithm takes the ciphertext C and the private key as inputs. It then outputs the message M.
Matching and Multi-Submission Verification. Executed by and workers, this algorithm takes as inputs the public parameter , the private key and the ciphertext C. It then runs a zero-knowledge proof to verify the compliance of attributes and submission times between and the worker. It then outputs accept or reject.
5. zk-MIPE Scheme
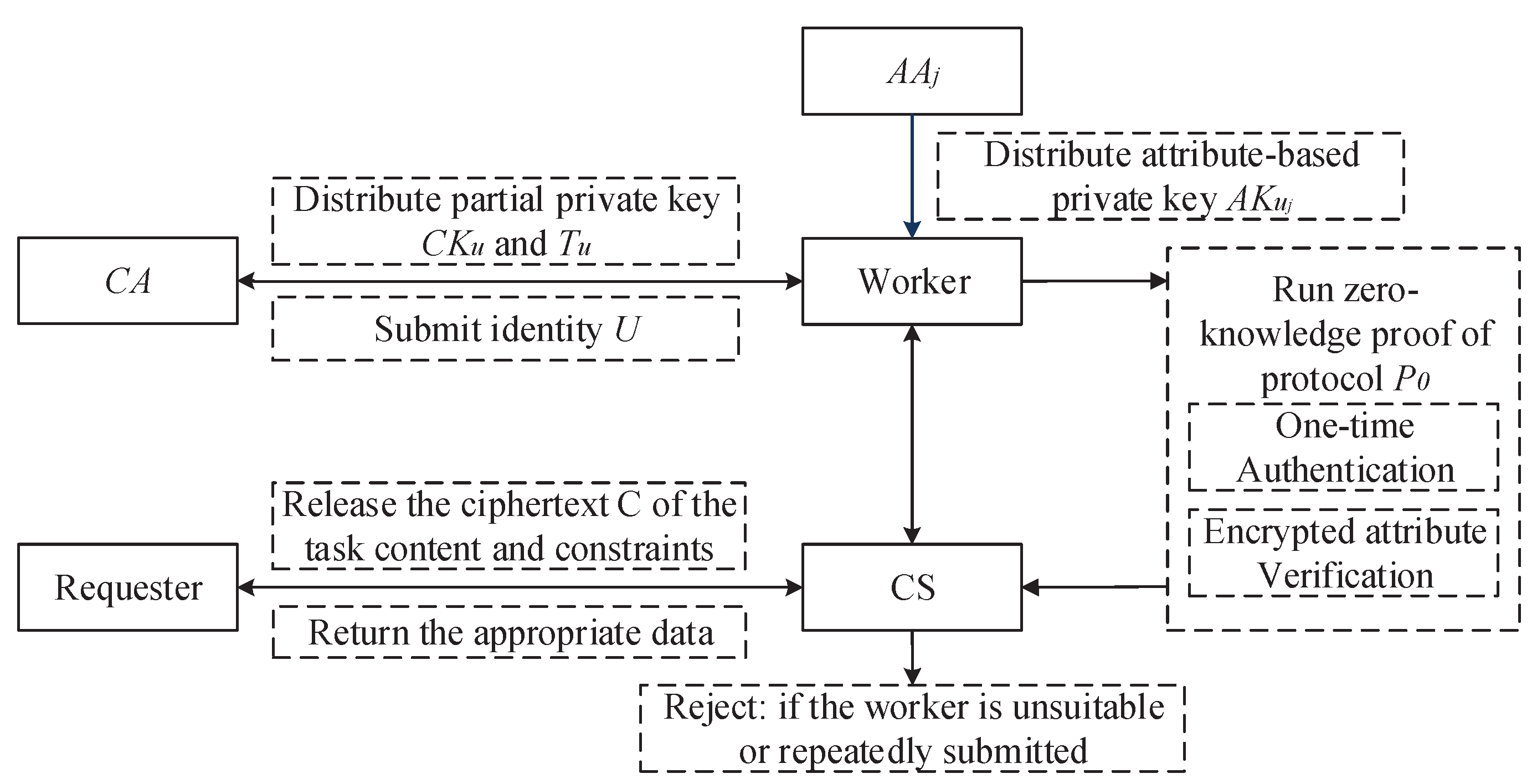
Based on the difficult problems of bilinear pairings and a specific zero-knowledge proof protocol, we propose a zk-MIPE algorithm to deliver task-matching and multiple data submissions detection services in crowdsourcing. The scheme is roughly described in
Figure 2.
For instance, suppose the task content is to collect some physical indicators, and the task constraint is: male, 48 years old, and suffering from hypertension or arthritis. Let , , be three attributes, which represent gender, age and disease. Let , , be the specific attribute values for workers. We quantify gender and disease in task constraints, e.g., for attribute , set male = 1 and female = 2, and for attribute , set hypertension = 1, arthritis = 2, gastritis = 3. Then the restriction is which could be further denoted as for . The worker’s attribute vector is defined as . To make the equation hold if and only if the inner product is zero, the vector is defined as .
Given a task ciphertext encrypted with restriction , if a worker’s attribute is: male, 45 years old, with hypertension, he will be able to decrypt the task ciphertext and be eligible to participate in the task. In the task submission stage, he could generate a proof in the form of zero-knowledge and sends it to the CS together with his collected data. In the process of verification, the CS can verify whether the worker meets the constraints and whether the submission is repeated, but cannot get the explicit attribute information of the worker. Each worker could select a random number as his identity-based private key. For each task, he sends the calculated , where H is a one-way hash function, and the proof of the attribute private key to the CS. Through a zero-knowledge proof protocol he will prove to the CS that it is the first time to submit, and he is a suitable worker without disclosing , and the private key of . The value of S is unique for one task. If the CS detects the same S, it means duplicate submission. Moreover, if a worker chooses another random number as his identity-based private key, since the attribute private key, generated by the authorities, is bound with the information of , he will not be able to pass the verification of matching attributes and constraints.
Furthermore, a crowdsourcing task usually involves multiple workers. IPE just solves the problem of one to many. A ciphertext can be decrypted by many users, which is suitable for multi-user scenarios. Once the crowdsourcing requester encrypts a task, it can be decrypted by any worker who meets the requirements. For the crowdsourcing server with mighty computing power, it is also feasible to handle the task requests issued by multiple requesters in parallel. The introduction of multiple authorities further increases the scalability of the scheme.
Specifically, the scheme is as follows.
CA Setup. Executed by , the algorithm takes a security parameter as input and runs to output a symmetric group of prime order q. It picks a random generator , a random and a one-way hash function . Then it sets the public key as and the system master key as .
AA Setup. The attribute authority randomly picks and computes as the public key for each attribute belonging to . Then publishes and sets as its secret key.
Task Releasing. The algorithm, executed by the requester, takes the public key , (for ), description of constraints in which and the message as input. It randomly chooses and computes
Then it outputs the task ciphertext as
Registration. Users can either register as requesters or workers. Both and are responsible for generating private keys for registered users by calling the following algorithms.
- (1)
If a user registers as a worker, he/she first selected a random , computes as the public key, and sends U to . Then randomly picks , sets and distributes to secretly. In particular, corresponds uniquely with the worker u. Then computes
After that, sends to the worker. For each registered requester, sends the system public key to the requester.
- (2)
After receiving from , chooses a random and computes for the worker u. Then it creates the secret key about the attribute-based vector as
The algorithm outputs the worker secret key as .
Decryption. The algorithm, executed by the worker, takes the ciphertext C and the secret key as input. It first computes
Then it could recover message M by computing .
When , the computation is correct since
Thus, .
Matching and Multi-Submission Verification. The algorithm tasks the system public, the worker secret key
and the task ciphertext
C as inputs. In the interaction protocol between the worker and the platform, if
for
, the worker
u first computes
and sends
S to
. Then
checks whether
S has been used once. If used,
rejects the request. If not,
will allow
u to run the following zero-knowledge proof of knowledge protocol
with it to prove the knowledge of
:
To implement the protocol , u will calculate some auxiliary inputs and use some tricks to convert the protocol equivalently. Specifically, u interacts with as follows.
(1)
randomly picks two generators
and sends them to
u, where the discrete logarithm of
with respect to
is unknown to
u. Then
u picks random
and computes
After that,
u returns auxiliary values
to
. In this case, the protocol can be expressed as the following zero-knowledge proof of knowledge protocol
to prove the knowledge of
:
Assume that the auxiliary value calculated by u has been sent to . Next, we will describe the implementation details of the honest-verifier zero-knowledge protocol below.
(1)
Commitment.
u picks random
and computes
Then the worker sends these auxiliary values to .
(2) Challenge. picks a random and sends to the worker.
(3)
Response. the worker computes the following auxiliary value at first.
Then u sends the sets of to .
(4)
Verification.
checks whether the following equation holds:
Through the above interactive process, verifies whether the workers meet the constraints and submit repeatedly. If the verification is valid, CS returns the task answer submitted by the worker to the requester. As follows, we discuss the soundness of the protocol.
Soundness of :
is a 3-move protocol, where the prover sends the commitment, the verifier chooses a random challenge, and the prover response to the challenge based on elliptic curve discrete logs. It is straightforward to show that
is of soundness, i.e., there exists an extractor
, which is given rewindable black-box access to the prover, could output some witness
or a halting symbol ⊥ to indicate "failure". By running
and calling
, we can construct an extractor
. When
outputs ⊥,
outputs ⊥ and stops. If
outputs the witness
, the extractor could further output some valid witness
with the same probability. Based on the outputs of
,
computes
We show how these values satisfy the equation relation of as follows.
Due to soundness of ,
Rearranging the terms, where :
Due to soundness of ,
Rearranging the terms:
Then could output as the witnesses satisfying . Therefore is of soundness.
6. Security Proof
In this section, we analyze the security of our scheme and show that it has the properties of task confidentiality, one-time authentication and anonymity.
Assume there exists a PPT adversary that wins the following games in our scheme, we can construct a PPT simulator that solves the CDH problem, DDH problem or the q-DDHI problem with nonnegligible advantage.
Theorem 1. Assume the DDH assumption holds, then the proposed zk-MIPE scheme is IND-CPA secure.
Proof. Against an adversary who wants to learn task content, the security algorithms are designed as follows. □
Algorithm I
Init. The challenger sets and randomly chooses . It flips a coin outside of ’s view and sets T as follows:
If , it computes ; otherwise, it chooses a random . Then it sends to . After that, submits the challenge access structure to .
CA Setup. Given the secure parameter , randomly chooses and sets . Then it gives the public key to .
AA Setup. randomly chooses at first. Here, we suppose is one of the honest attribute authority.
- (1)
For , sets , and lets for . Then it computes and sends the public key to .
- (2)
For , sets , and lets for . Then it computes and sends to .
Registration Queries I. repeatedly makes registration queries with respect to attribute key value such that . Notice that for any other honest , will also respond the corresponding secret key even if .
chooses a user u and sets U as his/her public key. It sends U to . Then chooses random , sets and computes , . After that computes the attribute related secret key as follows.
- (1)
For , chooses a random and computes
- (2)
For , randomly chooses a and computes
Challenge. submits two challenge messages to . flips a coin and computes the ciphertext as follows.
chooses a random , sets and computes
, , , , , , .
Then computes as follows.
- (1)
For , chooses a random , sets and computes
- (2)
For , chooses a random , sets and computes
.
Registration Queries II. submits a polynomially bounded number of registration queries with respect to attribute sets . responds as it did in Registration Queries I.
Guess. outputs a guess of b. If , will guess T is a DDH tuple, i.e., ; otherwise, it guesses T is a random tuple, i.e., . It indicates that if the adversary wins this game with nonnegligible advantage, then the simulator will have obviously advantage in the DDH game.
Theorem 2. Assume the CDH assumption holds, then the proposed zk-MIPE scheme is one-time authenticate.
Proof. Against an adversary who wants to forge a valid proof for the attributes he/she does not possess, the security algorithms are designed as follows.
In our scheme, for each task, the value of a tag submitted by a user u is different and unique fixed. If submitting a tag twice will be forbidden. Thus, as follows, we show that it is difficult for unsuitable workers to forge a valid authentication message based on the CDH assumption. □
Algorithm II
Init. The challenger sets and randomly chooses . Then it sends to . After that, submits the challenge access structure and message .
CA Setup. Running the CA setup algorithm, does as in Algorithm I.
AA Setup. Running the AA setup algorithm, does as in Algorithm I.
Registration Queries I. Running the registration algorithm, does as in Algorithm I.
Verification Queries I. submits a series of queries about to . It requires that , and , and if not, it aborts. runs matching and detection verification algorithm, interacts with , and generates proof transcript for .
Forgery. For the specified , chooses a worker public key and an attribute vector such that . In this algorithm, we will not consider the privacy of . Based on , computes ciphertext about message . Then interacts with to generate a transaction of the protocol , proving that it has the private key about a suitable vector. If outputs a valid forged proof and the protocol is sound, could then obtain from the forgery.
Theorem 3. Suppose that the q-DDHI assumption holds and the protocol is zero-knowledge, then the proposed scheme is private and unlinkable.
Proof. To prove the privacy of the scheme, we first summarize the zero-knowledge of .
Zero-knowledgeness of . For the implementation of , we introduced some auxiliary inputs and protocol . Based on the Logarithm assumption and the DDH assumption, the zero-knowledge property of is guaranteed for honest verifier, i.e., there exists a simulator on imputing a random challenge , the simulator could output a transcript for , ,,...,,,...,,,. For any adversary, the distribution of the output is indistinguishable. By invoking the simulator of protocol , protocol could further prove its zero-knowledge property. □
Then we define the game between an adversary and a simulator which is given a q-DDHI instance as follows.
Algorithm III
Init. The challenger sets and randomly chooses . It flips a coin . If , it computes ; otherwise, it chooses a random . After that, submits two challenge users with attribute vector , to .
CA Setup. Given the secure parameter , chooses a random and sets . Then it gives the public key to .
AA Setup. randomly chooses , sets , and lets for . Then it computes and sends the public key to .
Registration Queries I. sets for a user and receives the value , which may equal to or a random element in , from the challenger initially. issues registration queries repeatedly. generates the secret key honestly except for . If , it aborts. Moreover, it is required that does not make secret key queries for both and .
Challenge. Without loss of generality, assumes . It flips a coin and runs registration queries to obtain the corresponding . Then, operates Task Releasing with an attribute vector (with restrictions that and ) to acquire the ciphertext . After receiving , issues Verification and receives a valid proof from by applying the zero-knowledge protocol .
Registration Queries II. submits a polynomially bounded number of registration queries repeatedly. responds as it did in Registration Queries I.
Guess. outputs a guess of b. If , will guess T is a q-DDHI tuple, i.e., ; otherwise, it guesses T is a random tuple, i.e., . Observe that if H is a one-way pseudo-random hash function and the q-DDHI assumption holds, the adversary will know nothing about . By the zero-knowledge property of protocol , the information about the identity U, the policy and the attribute will not be leaked. Thus, the algorithm could protect identity privacy and submission unlinkability.
7. Performance Evaluation
In reality, we implement the ZK-MIPE scheme on a Linux desktop with 6-core Intel(R) Xeon(R) Platinum 8369HC CPU 3.40 GHz processor and 32 GB of RAM. We use the PBC library to simulate the group operations. The symmetric elliptic curve SS512 is chosen with embedding degree 2 and a 512-bit base field.
Table 1 and
Table 2 show the comparison between our scheme and other solutions in terms of functionality and security. Compared with [
24], zk-MIPE supports more flexible matching poly and supports worker identity privacy. Compared with [
23,
25], zk-MIPE provides privacy for task constraints and worker attributes. As follows, we analyze the computational complexity of each participant in our scheme and test the running time to demonstrate scheme’s effectiveness. The notations applied in the proposed scheme are summarized in
Table 3. Ignoring the operations of equality comparison, hash and multiplication, the communication and computation comparison of the schemes is shown in
Table 4 and
Table 5.
In our scheme, the main overhead on and are from system setup and user registration. In setup, the computation complexity of is . In setup, the computation complexity of is . In user registration, the computation complexity of and are and , respectively. The total communication complexity of the authorities for distributing a key to a registered user is .
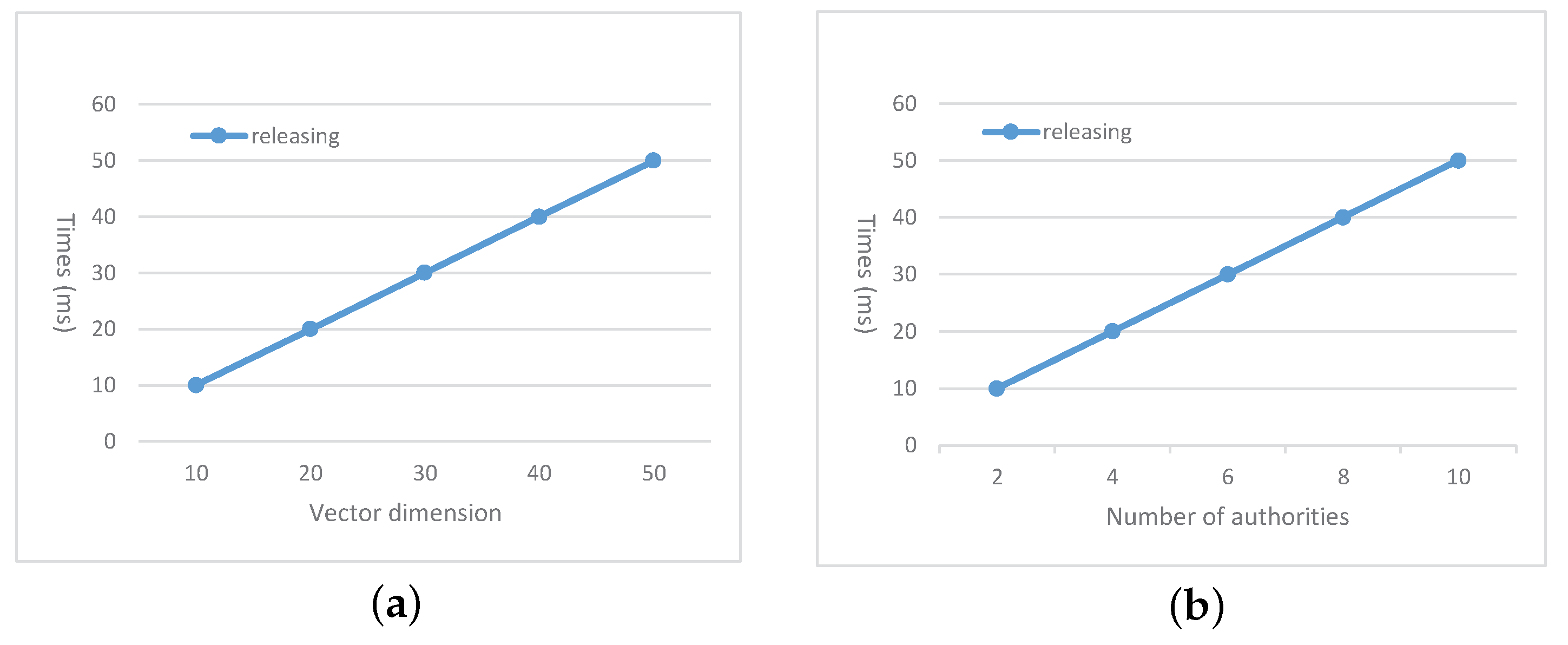
The main overhead on the requester is from task releasing. In this step, the requester expresses the task requirements with vector
and encrypt the task based on
such that only the suitable worker could decrypt the task content. Meanwhile, the requester is required to blind the vector
for the
to perform matching verification in the matching and submission verification phase. The computation complexity of the requester is
. The total communication complexity of the requester for task releasing is
. To test the time cost of the requester, we set the number of attribute authorities as
, and vary the number of attributes
n in
Figure 3a. In
Figure 3b, we set
and vary the number of attribute authorities
m.
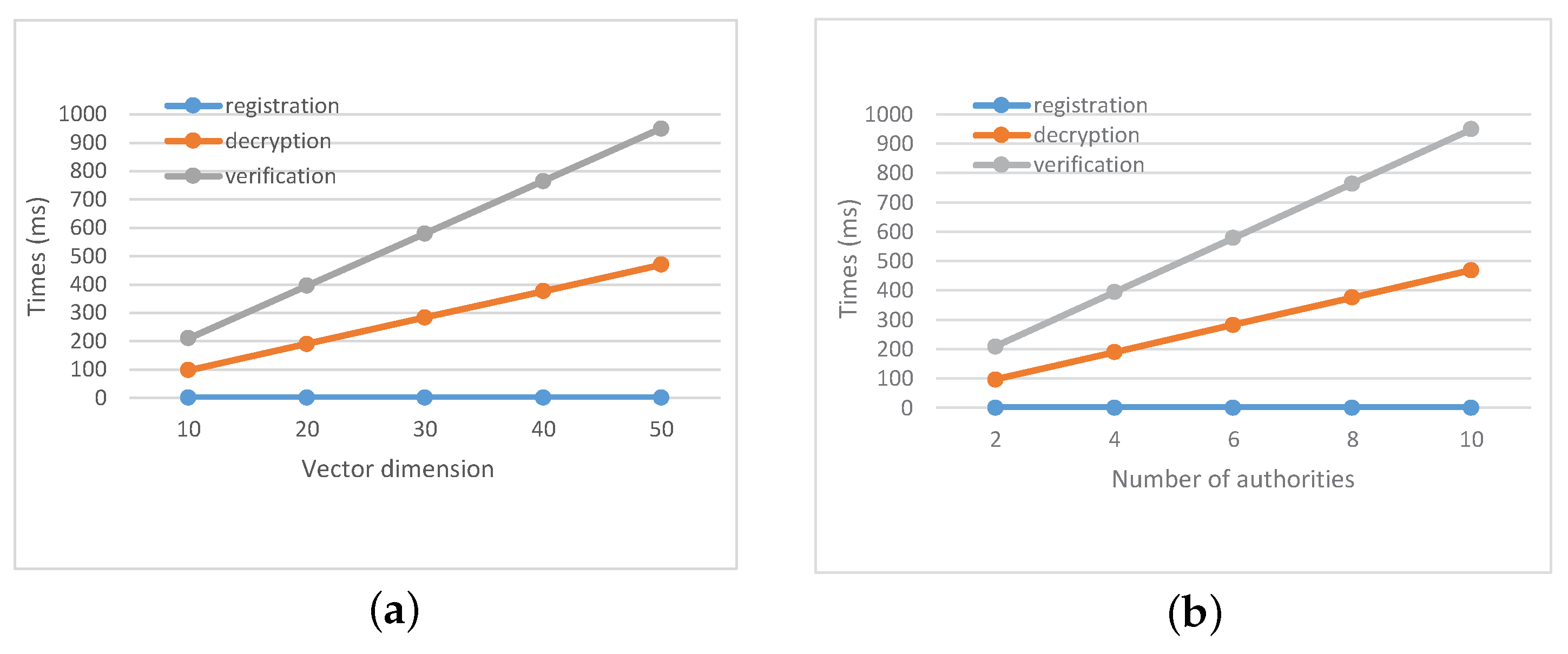
The main overhead on the worker is from registration, decryption and verification. As shown in
Figure 4a, we set
, and vary the number of attributes to test the time cost on the worker. In
Figure 4b, we set
and vary the number of attribute authorities. In user registration and decryption, the computation complexity of the worker is
. Although in decryption algorithm, the computing cost for the worker increases linearly with the number of attributes, most of the computing overhead can be transferred to the
by outsourcing computing. In this case, the worker only needs to carry out a small amount of calculation.
In the stage of submission and verification, the worker and
achieve privacy-preserving matching and multi-submission verification through a zero-knowledge proof protocol. The interactive proof protocol consists of 3 rounds. The total computation and communication complexity of the worker are
and
respectively. In
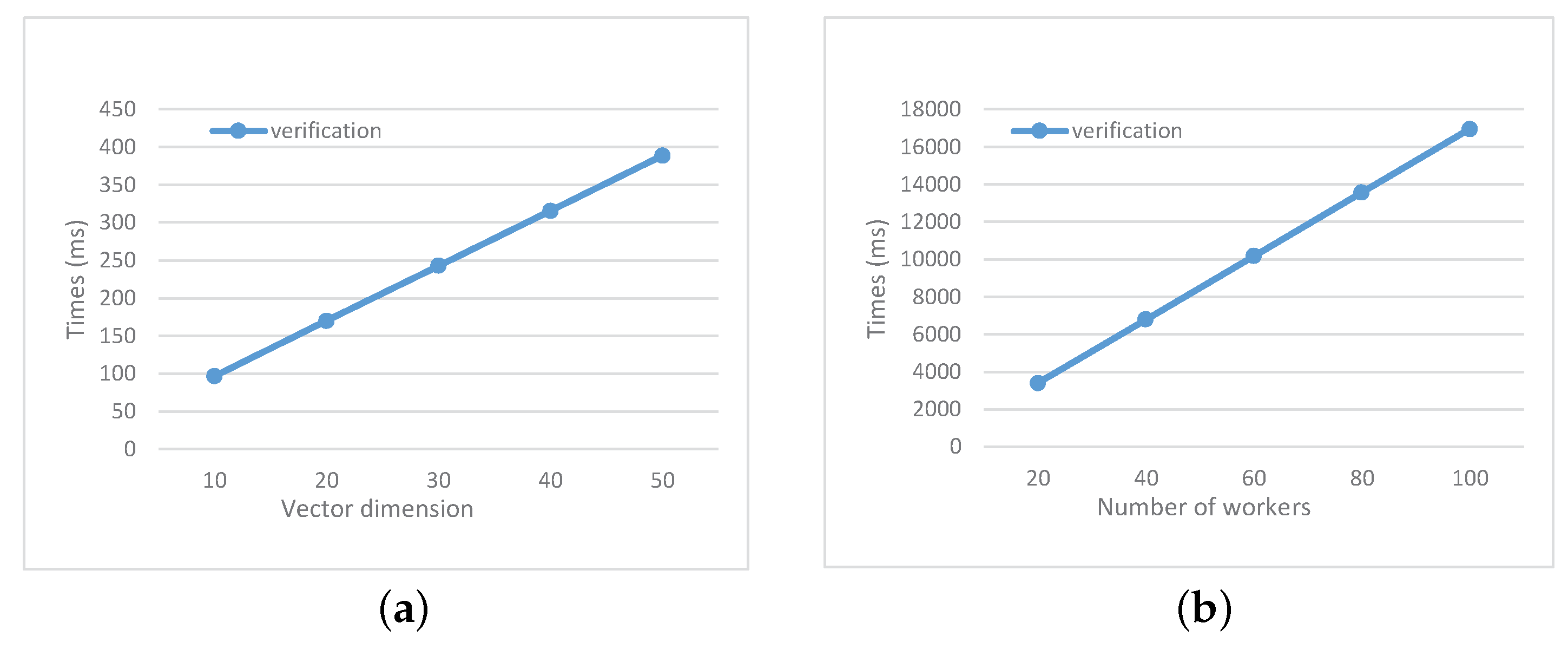
Figure 5, we take
, and vary
n as well as the number of workers
k to test the time cost of verification for
. The total computation and communication complexity of
are
and
, respectively.
8. Conclusions
In this paper, we present a novel multi-authorities inner-product encryption and one-time anonymous authentication scheme to realize privacy-preserving task-matching and multi-submission detection. In the system, both the user attributes and the number of submissions will be applied as authorization factors. By combining zero-knowledge proof technology and our anti-collusion multi-authorities inner-product encryption, the task confidentiality, worker attribute and unlinkability between different tasks participated by the same worker are guaranteed simultaneously. Moreover, the security of the scheme is proved based on bilinear difficulty assumptions and zero-knowledge of the protocol. For the sake of completeness, we finally analyze the function and efficiency of the scheme and show that it is practical for crowdsourcing environments. In addition to crowdsourcing privacy protection, our method could also play its role in the fields of searchable encryption, nearest neighbor search, fine-grained access control, electronic voting, electronic payment, and anonymous authentication.
In future work, we will continue to improve the algorithm itself and try to construct privacy protection schemes in a distributed crowdsourcing scenario without a trusted third party. Furthermore, we will study the integration of cryptography and other technologies, such as machine learning technology, to further improve the flexibility and efficiency of the solution.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}