
Quantification of Blood Flow Velocity in the Human Conjunctival Microvessels Using Deep Learning-Based Stabilization Algorithm

Abstract
:1. Introduction
2. Materials and Methods
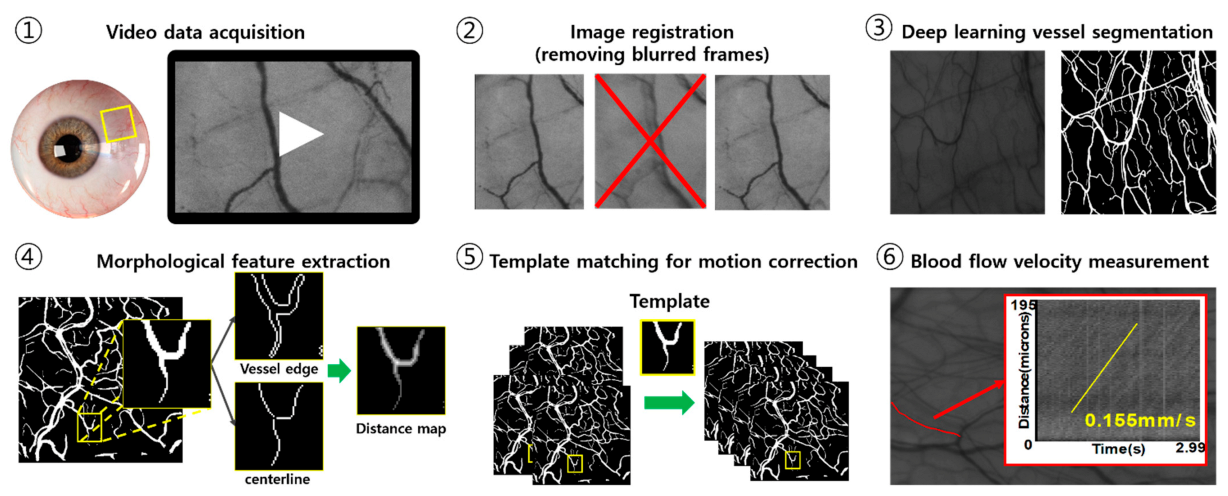
2.1. Process of Quantifying Blood Flow Velocity
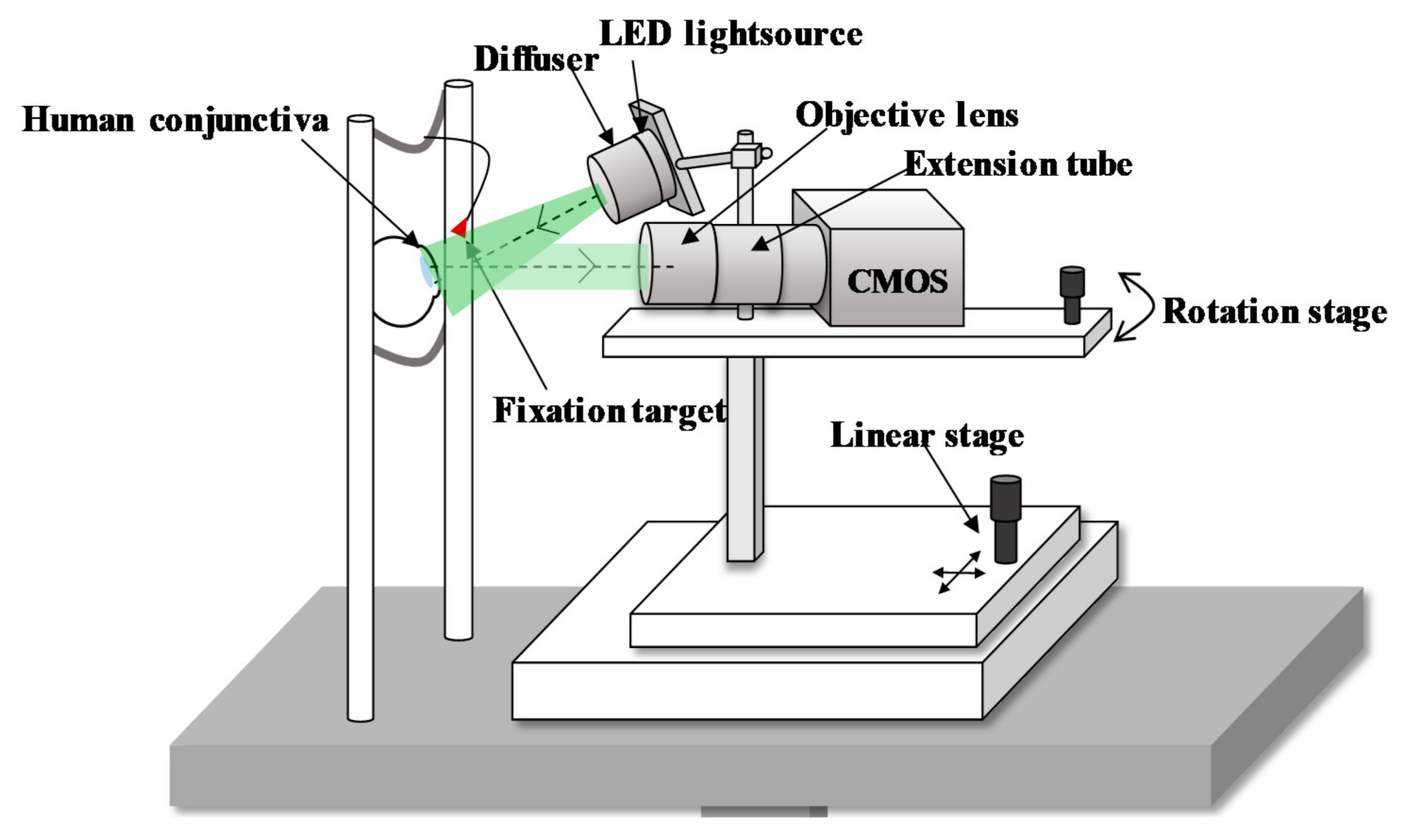
2.2. Image Acquisition
2.3. Image Registration
2.4. Deep Learning Vessel Segmentation
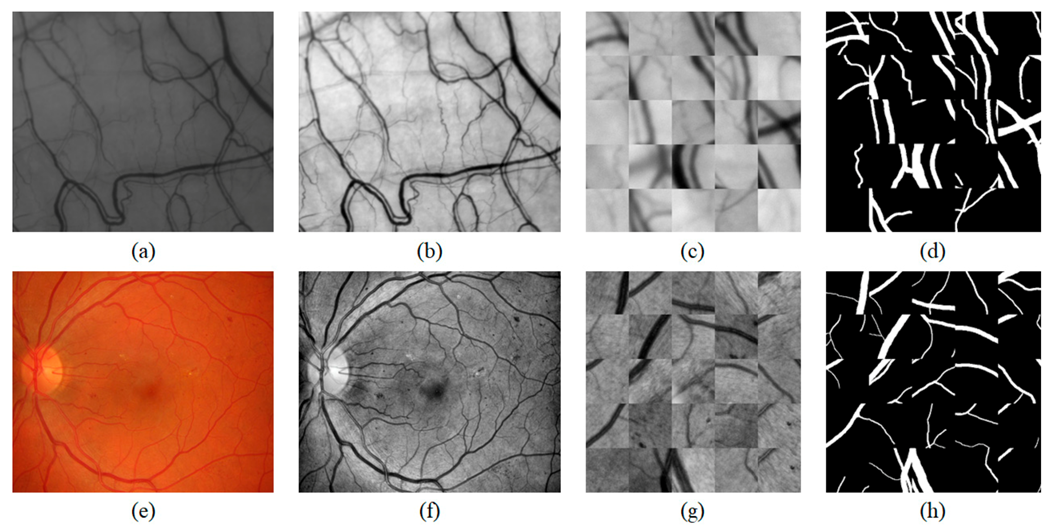
2.4.1. Dataset
2.4.2. Image Preprocessing and Preparation
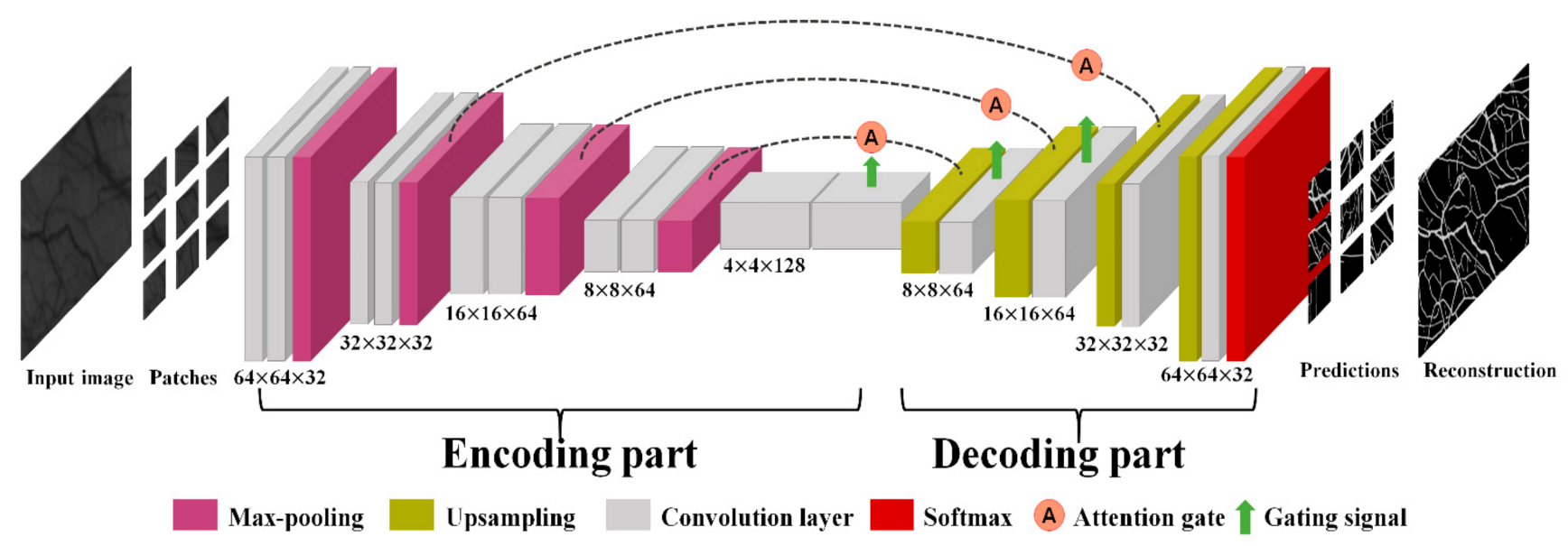
2.4.3. Network Architecture
2.4.4. Model Training and Testing
2.5. Morphological Feature Extraction
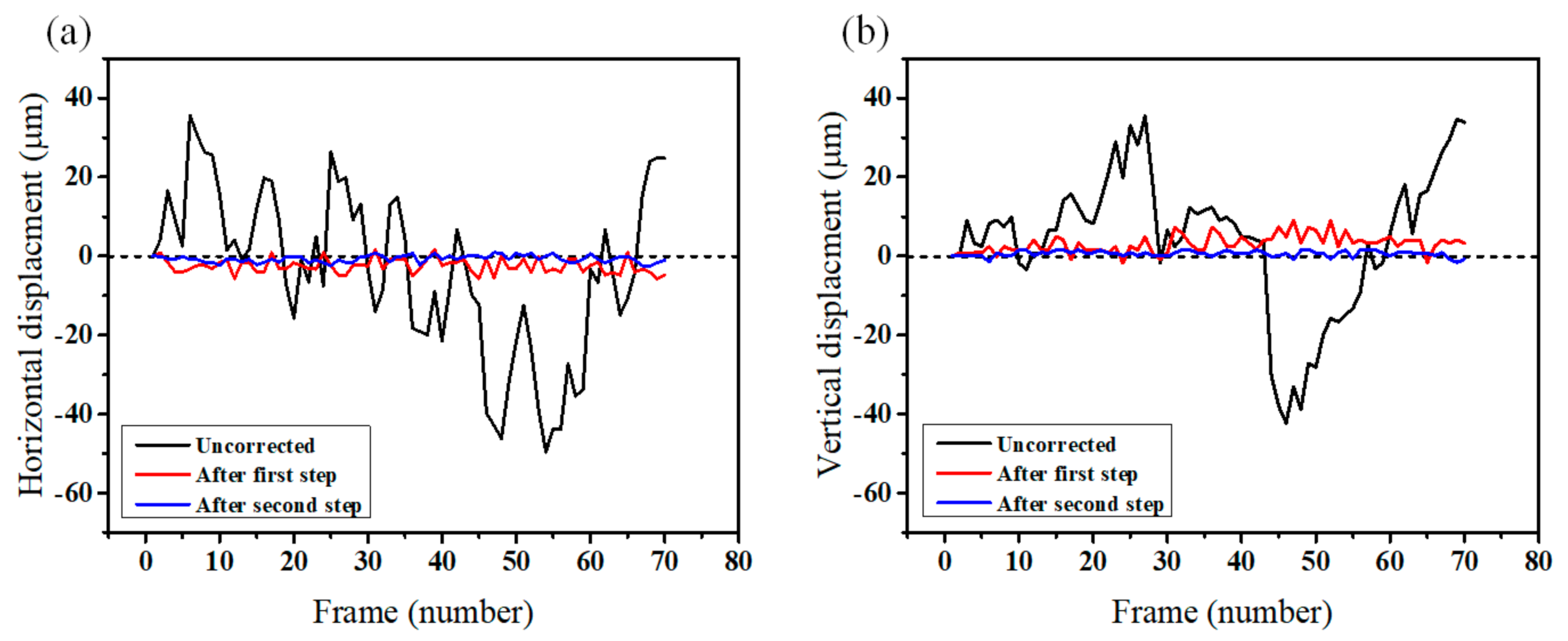
2.6. Template Matching for Motion Correction
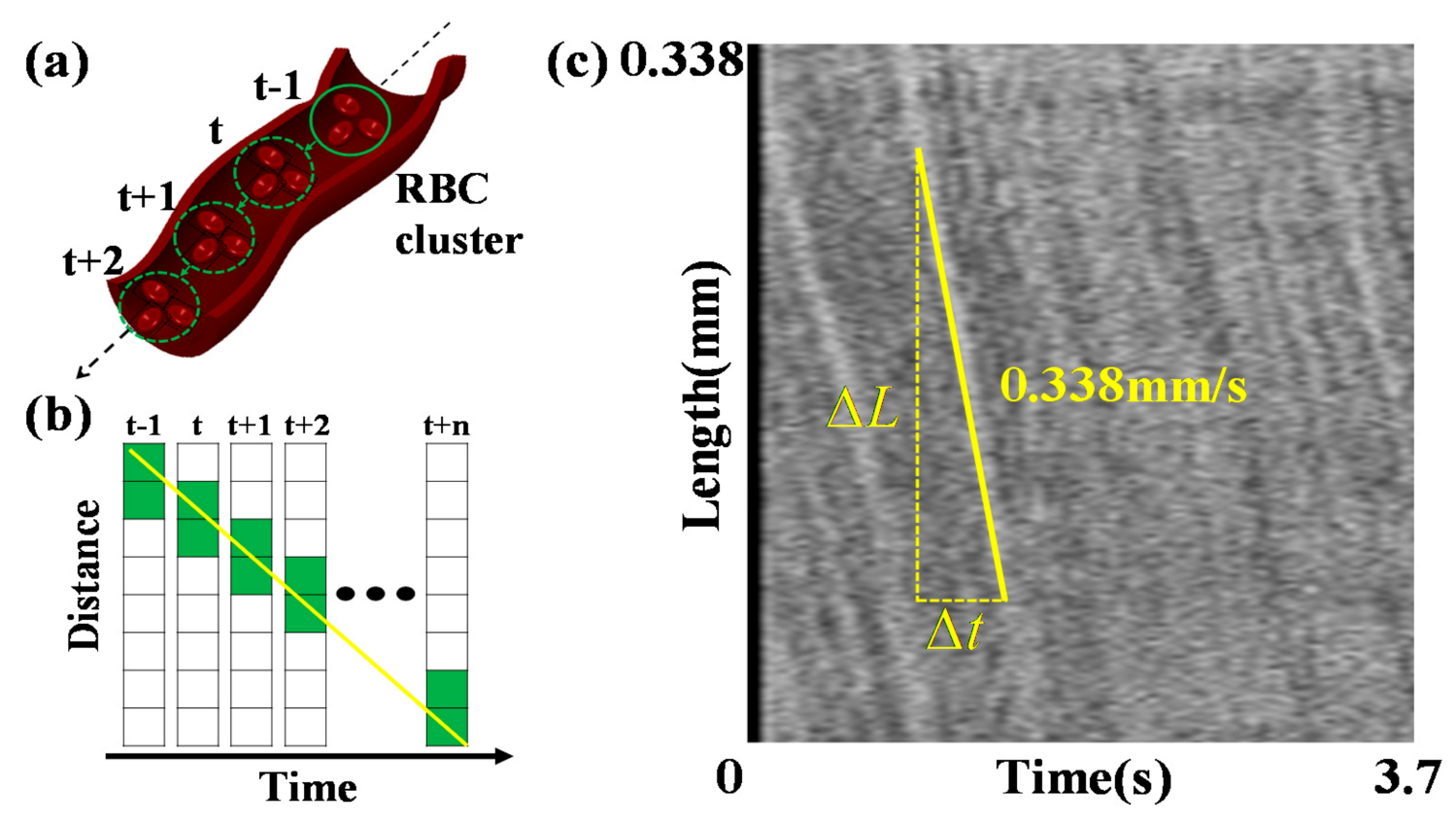
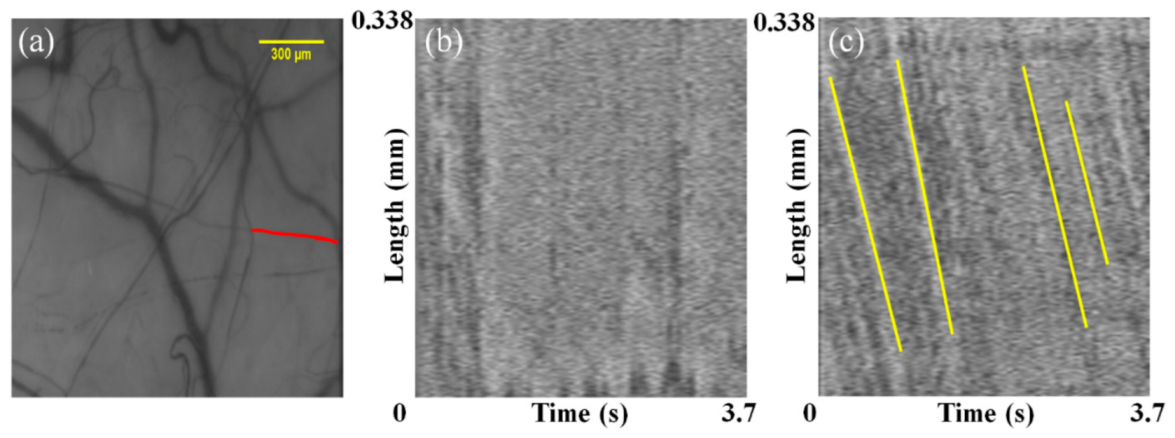
2.7. Blood Flow Velocity Measurements
3. Results
3.1. Segmentation
3.2. Motion Correction
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khansari, M.M.; Wanek, J.; Tan, M.; Joslin, C.E.; Kresovich, J.K.; Camardo, N.; Blair, N.P.; Shahidi, M. Assessment of conjunctival microvascular hemodynamics in stages of diabetic microvasculopathy. Sci. Rep. 2017, 7, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, W.; Batawi, H.I.M.; Alava, J.R.; Galor, A.; Yuan, J.; Sarantopoulos, C.D.; McClellan, A.L.; Feuer, W.J.; Levitt, R.C.; Wang, J. Bulbar conjunctival microvascular responses in dry eye. Ocul. Surf. 2017, 15, 193–201. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, J.; Jiang, H.; Tao, A.; DeBuc, D.; Shao, Y.; Zhong, J.; Pineda, S. Limbal capillary perfusion and blood flow velocity as a potential biomarker for evaluating dry eye. Investig. Ophthalmol. Vis. Sci. 2013, 54, 4335. [Google Scholar]
- Chen, W.; Deng, Y.; Jiang, H.; Wang, J.; Zhong, J.; Li, S.; Peng, L.; Wang, B.; Yang, R.; Zhang, H. Microvascular abnormalities in dry eye patients. Microvasc. Res. 2018, 118, 155–161. [Google Scholar] [CrossRef]
- Valeshabad, A.K.; Wanek, J.; Mukarram, F.; Zelkha, R.; Testai, F.D.; Shahidi, M. Feasibility of assessment of conjunctival microvascular hemodynamics in unilateral ischemic stroke. Microvasc. Res. 2015, 100, 4–8. [Google Scholar] [CrossRef] [Green Version]
- Karanam, V.C.; Tamariz, L.; Batawi, H.; Wang, J.; Galor, A. Functional slit lamp biomicroscopy metrics correlate with cardiovascular risk. Ocul. Surf. 2019, 17, 64–69. [Google Scholar] [CrossRef]
- Jiang, H.; Zhong, J.; DeBuc, D.C.; Tao, A.; Xu, Z.; Lam, B.L.; Liu, C.; Wang, J. Functional slit lamp biomicroscopy for imaging bulbar conjunctival microvasculature in contact lens wearers. Microvasc. Res. 2014, 92, 62–71. [Google Scholar] [CrossRef] [Green Version]
- Shahidi, M.; Wanek, J.; Gaynes, B.; Wu, T. Quantitative assessment of conjunctival microvascular circulation of the human eye. Microvasc. Res. 2010, 79, 109–113. [Google Scholar] [CrossRef] [Green Version]
- van Zijderveld, R.; Ince, C.; Schlingemann, R.O. Orthogonal polarization spectral imaging of conjunctival microcirculation. Graefe’s Arch. Clin. Exp. Ophthalmol. 2014, 252, 773–779. [Google Scholar] [CrossRef]
- Khansari, M.M.; Wanek, J.; Felder, A.E.; Camardo, N.; Shahidi, M. Automated assessment of hemodynamics in the conjunctival microvasculature network. IEEE Trans. Med Imaging 2015, 35, 605–611. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Yuan, J.; Jiang, H.; Yan, W.; Cintrón-Colón, H.R.; Perez, V.L.; DeBuc, D.C.; Feuer, W.J.; Wang, J. Vessel sampling and blood flow velocity distribution with vessel diameter for characterizing the human bulbar conjunctival microvasculature. Eye Contact Lens 2016, 42, 135. [Google Scholar] [CrossRef] [Green Version]
- Goobic, A.P.; Tang, J.; Acton, S.T. Image stabilization and registration for tracking cells in the microvasculature. IEEE Trans. Biomed. Eng. 2005, 52, 287–299. [Google Scholar] [CrossRef]
- Brennan, P.F.; McNeil, A.J.; Jing, M.; Awuah, A.; Finlay, D.D.; Blighe, K.; McLaughlin, J.A.; Wang, R.; Moore, J.; Nesbit, M.A. Quantitative assessment of the conjunctival microcirculation using a smartphone and slit-lamp biomicroscope. Microvasc. Res. 2019, 126, 103907. [Google Scholar] [CrossRef]
- Frangi, A.F.; Niessen, W.J.; Vincken, K.L.; Viergever, M.A. Multiscale vessel enhancement filtering. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, MICCAI 98, Cambridge, MA, USA, 11–13 October 1998; pp. 130–137. [Google Scholar]
- Doubal, F.; MacGillivray, T.; Patton, N.; Dhillon, B.; Dennis, M.; Wardlaw, J. Fractal analysis of retinal vessels suggests that a distinct vasculopathy causes lacunar stroke. Neurology 2010, 74, 1102–1107. [Google Scholar] [CrossRef] [Green Version]
- Soares, J.V.; Leandro, J.J.; Cesar, R.M.; Jelinek, H.F.; Cree, M.J. Retinal vessel segmentation using the 2-D Gabor wavelet and supervised classification. IEEE Trans. Med. Imaging 2006, 25, 1214–1222. [Google Scholar] [CrossRef] [Green Version]
- Luo, Z.; Zhang, Y.; Zhou, L.; Zhang, B.; Luo, J.; Wu, H. Micro-vessel image segmentation based on the AD-UNet model. IEEE Access 2019, 7, 143402–143411. [Google Scholar] [CrossRef]
- Delori, F.C.; Webb, R.H.; Sliney, D.H. Maximum permissible exposures for ocular safety (ANSI 2000), with emphasis on ophthalmic devices. JOSA A 2007, 24, 1250–1265. [Google Scholar] [CrossRef]
- Persons, E.L. Studies on red blood cell diameter: III. The relative diameter of immature (reticulocytes) and adult red blood cells in health and anemia, especially in pernicious anemia. J. Clin. Investig. 1929, 7, 615–629. [Google Scholar] [CrossRef]
- Webb, R.H.; Dorey, C.K. The pixilated image. In Handbook of Biological Confocal Microscopy; Springer: Boston, MA, USA, 1995; pp. 55–67. [Google Scholar]
- Deneux, T.; Takerkart, S.; Grinvald, A.; Masson, G.S.; Vanzetta, I. A processing work-flow for measuring erythrocytes velocity in extended vascular networks from wide field high-resolution optical imaging data. Neuroimage 2012, 59, 2569–2588. [Google Scholar] [CrossRef]
- Vincent, O.R.; Folorunso, O. A descriptive algorithm for sobel image edge detection. In Proceedings of the Informing Science & IT Education Conference (InSITE 2009), Macon, GA, USA, 12–15 June 2009; pp. 97–107. [Google Scholar]
- Wang, Z.; Feng, C.; Ang, W.T.; Tan, S.Y.M.; Latt, W.T. Autofocusing and polar body detection in automated cell manipulation. IEEE Trans. Biomed. Eng. 2016, 64, 1099–1105. [Google Scholar] [CrossRef]
- Shih, L. Autofocus survey: A comparison of algorithms. In Proceedings of the Digital Photography III, Electronic Imaging 2007, San Jose, CA, USA, 28 January–1 February 2007; p. 65020B. [Google Scholar]
- Dubbs, A.; Guevara, J.; Yuste, R. moco: Fast motion correction for calcium imaging. Front. Neuroinformatics 2016, 10, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Odstrcilik, J.; Kolar, R.; Budai, A.; Hornegger, J.; Jan, J.; Gazarek, J.; Kubena, T.; Cernosek, P.; Svoboda, O.; Angelopoulou, E. Retinal vessel segmentation by improved matched filtering: Evaluation on a new high-resolution fundus image database. IET Image Process. 2013, 7, 373–383. [Google Scholar] [CrossRef]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vis. Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Yamanakkanavar, N.; Lee, B. Using a Patch-Wise M-Net Convolutional Neural Network for Tissue Segmentation in Brain MRI Images. IEEE Access 2020, 8, 120946–120958. [Google Scholar] [CrossRef]
- Wang, C.; Zhao, Z.; Ren, Q.; Xu, Y.; Yu, Y. Dense U-net based on patch-based learning for retinal vessel segmentation. Entropy 2019, 21, 168. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yan, Z.; Yang, X.; Cheng, K.-T. Joint segment-level and pixel-wise losses for deep learning based retinal vessel segmentation. IEEE Trans. Biomed. Eng. 2018, 65, 1912–1923. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Zou, K.H.; Warfield, S.K.; Bharatha, A.; Tempany, C.M.; Kaus, M.R.; Haker, S.J.; Wells III, W.M.; Jolesz, F.A.; Kikinis, R. Statistical validation of image segmentation quality based on a spatial overlap index1: Scientific reports. Acad. Radiol. 2004, 11, 178–189. [Google Scholar] [CrossRef] [Green Version]
- Lee, T.-C.; Kashyap, R.L.; Chu, C.-N. Building skeleton models via 3-D medial surface axis thinning algorithms. Cvgip Graph. Models Image Process. 1994, 56, 462–478. [Google Scholar] [CrossRef]
- Klingler, J.W.; Vaughan, C.L.; Fraker, T.; Andrews, L.T. Segmentation of echocardiographic images using mathematical morphology. IEEE Trans. Biomed. Eng. 1988, 35, 925–934. [Google Scholar] [CrossRef]
- Bradski, G.; Kaehler, A. Learning OpenCV: Computer Vision with the OpenCV Library; O’Reilly Media, Inc.: Newton, MA, USA, 2008. [Google Scholar]
- Xiao, P.; Duan, Z.; Wang, G.; Deng, Y.; Wang, Q.; Zhang, J.; Liang, S.; Yuan, J. Multi-modal Anterior Eye Imager Combining Ultra-High Resolution OCT and Microvascular Imaging for Structural and Functional Evaluation of the Human Eye. Appl. Sci. 2020, 10, 2545. [Google Scholar] [CrossRef] [Green Version]
- Duncan, J.; Ward, R.; Shapiro, K. Direct measurement of attentional dwell time in human vision. Nature 1994, 369, 313–315. [Google Scholar] [CrossRef]
- Koutsiaris, A.G.; Tachmitzi, S.V.; Papavasileiou, P.; Batis, N.; Kotoula, M.G.; Giannoukas, A.D.; Tsironi, E. Blood velocity pulse quantification in the human conjunctival pre-capillary arterioles. Microvasc. Res. 2010, 80, 202–208. [Google Scholar] [CrossRef]
- Strain, W.D.; Paldánius, P. Diabetes, cardiovascular disease and the microcirculation. Cardiovasc. Diabetol. 2018, 17, 1–10. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vessel | Diameter (μm) | Length (mm) | Blood Flow Velocity (mm/s) |
|---|---|---|---|
| V1 | 13.158 | 0.414 | 0.086 |
| V2 | 15.282 | 0.356 | 0.097 |
| V3 | 8.172 | 0.338 | 0.338 |
| V4 | 9.878 | 0.330 | 0.090 |
| V5 | 10.170 | 0.318 | 0.270 |
| V6 | 8.682 | 0.220 | 0.141 |
| V7 | 9.574 | 0.250 | 0.078 |
| V8 | 15.422 | 0.246 | 0.137 |
| V9 | 15.620 | 0.128 | 0.114 |
| V10 | 9.934 | 0.214 | 0.153 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jo, H.-C.; Jeong, H.; Lee, J.; Na, K.-S.; Kim, D.-Y. Quantification of Blood Flow Velocity in the Human Conjunctival Microvessels Using Deep Learning-Based Stabilization Algorithm. Sensors 2021, 21, 3224. https://doi.org/10.3390/s21093224
Jo H-C, Jeong H, Lee J, Na K-S, Kim D-Y. Quantification of Blood Flow Velocity in the Human Conjunctival Microvessels Using Deep Learning-Based Stabilization Algorithm. Sensors. 2021; 21(9):3224. https://doi.org/10.3390/s21093224
Chicago/Turabian StyleJo, Hang-Chan, Hyeonwoo Jeong, Junhyuk Lee, Kyung-Sun Na, and Dae-Yu Kim. 2021. "Quantification of Blood Flow Velocity in the Human Conjunctival Microvessels Using Deep Learning-Based Stabilization Algorithm" Sensors 21, no. 9: 3224. https://doi.org/10.3390/s21093224
APA StyleJo, H.-C., Jeong, H., Lee, J., Na, K.-S., & Kim, D.-Y. (2021). Quantification of Blood Flow Velocity in the Human Conjunctival Microvessels Using Deep Learning-Based Stabilization Algorithm. Sensors, 21(9), 3224. https://doi.org/10.3390/s21093224