
Enabling Fine Sample Rate Settings in DSOs with Time-Interleaved ADCs

 , , , and
, , , and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Sample Rate Selection in a Single Channel Architecture
| Algorithm 1: Algorithm for computing the weighting coefficients. |
| if then { } else } end |
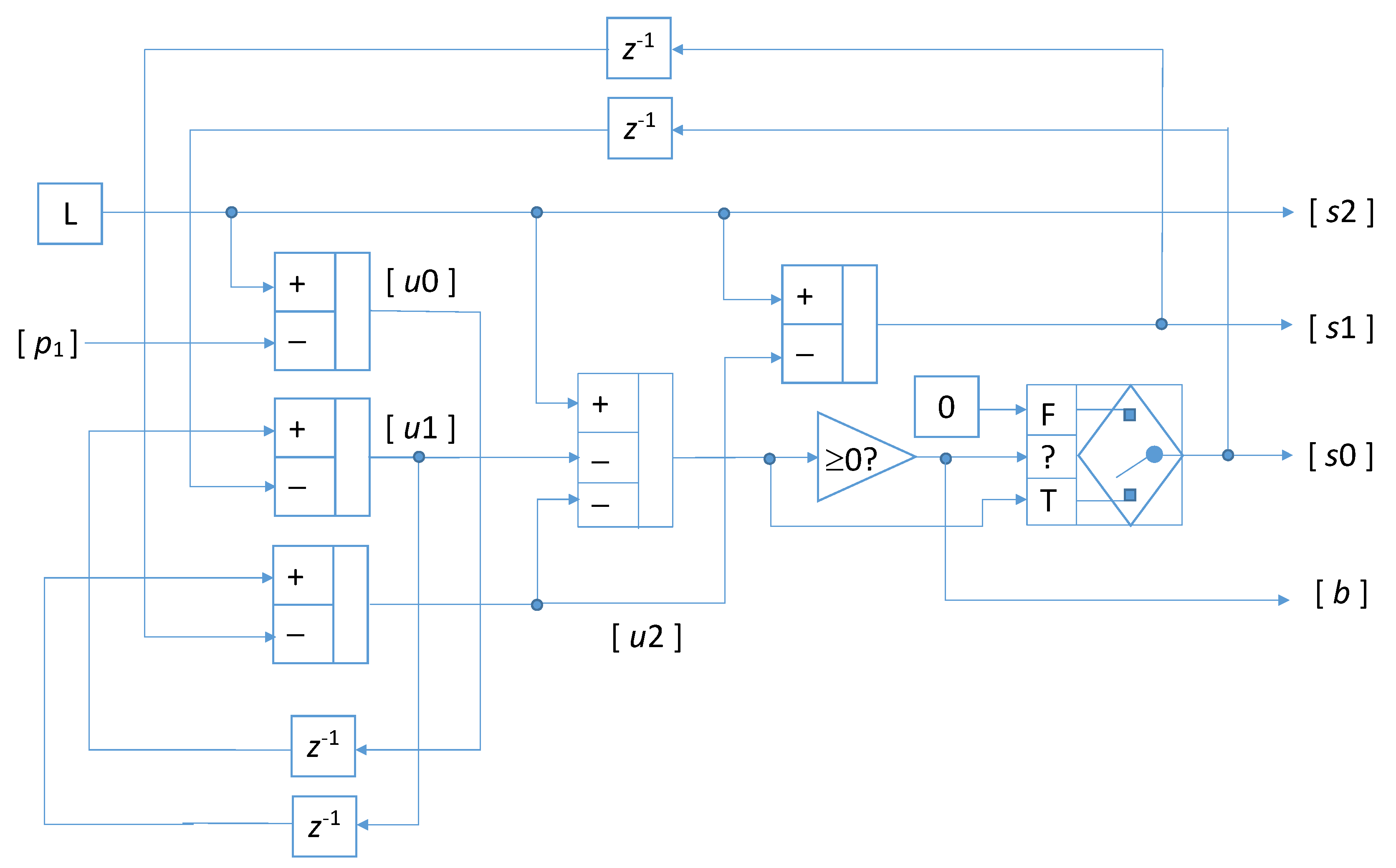
3. Sample Rate Selection in Multi-Channel Time-Interleaved Architectures
- a filtering stage, where the bunched signal is filtered with a filter characterized by dynamically varying coefficients;
- a defragmentation stage, where the useful samples are separated from the dummy samples;
- a packing stage where a suitable memory management approach assures the acquisition of the useful samples at the selected sample rate.
3.1. Filtering Stage
3.2. Defragmentation Stage
3.3. Packing Stage
- the 3 arrays are extended with L zeros in the bottom part;
- shifts are operated to align the useful values;
- the bottom halves of the arrays are summed and sent to memory;
- the topmost halves are moved to the next step of the pipeline, thus discarding the older half;
- the triples {, , } and {, , } are updated.
3.4. Further Remarks
4. Numerical Results and Synthesis of the Circuit
- the circuit can run at a clock equal to 3.42 GHz, that allows a maximum sample rate equal to 218.88 GHz;
- the silicon area occupation is less than 16,650 m, that are divided as 58% for the filtering stage, 27% for the defragmentation stage, and 15 % for the packing stage;
- the dissipated power at the maximum clock frequency is 853 mW, including leakage power equal to 106 W and dynamic power 249 W/MHz.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khan, S.A.; Agarwala, A.K.; Shahani, D.T.; Alam, M.M. Advance oscilloscope triggering. IEEE Trans. Instrum. Meas. 2007, 56, 944–953. [Google Scholar] [CrossRef]
- Lapuh, R.; Pinter, B.; Voljc, B.; Svetik, Z.; Lindic, M. Digital oscilloscope calibration using asynchronously sampled signal estimation. IEEE Trans. Instrum. Meas. 2011, 60, 2570–2577. [Google Scholar] [CrossRef]
- D’Arco, M.; Genovese, M.; Napoli, E.; Vadursi, M. Design and implementation of a preprocessing circuit for bandpass signals acquisition. IEEE Trans. Instrum. Meas. 2014, 63, 287–294. [Google Scholar] [CrossRef]
- Wang, C.M.; Hale, P.D.; Coakley, K.J.; Clement, T.S. Uncertainty of oscilloscope timebase distortion estimate. IEEE Trans. Instrum. Meas. 2002, 51, 53–58. [Google Scholar] [CrossRef]
- Wang, C.M.; Hale, P.D.; Coakley, K.J. Least-squares estimation of time-base distortion of sampling oscilloscopes. IEEE Trans. Instrum. Meas. 1999, 48, 1324–1332. [Google Scholar] [CrossRef]
- Ivchenko, V.G.; Kalashnikov, A.N.; Challis, R.E.; Hayes-Gill, B.R. High-speed digitizing of repetitive waveforms using accurate interleaved sampling. IEEE Trans. Instrum. Meas. 2007, 56, 1322–1328. [Google Scholar] [CrossRef]
- Zhao, Y.; Hu, Y.H.; Wang, H. Enhanced random equivalent sampling based on compressed sensing. IEEE Trans. Instrum. Meas. 2012, 61, 579–586. [Google Scholar] [CrossRef]
- Baccigalupi, A.; D’Arco, M.; Liccardo, A. Parameters and methods for adcs testing compliant with the guide to the expression of uncertainty in measurements. IEEE Trans. Instrum. Meas. 2017, 66, 424–431. [Google Scholar] [CrossRef]
- Pupalaikis, P.J.; Yamrone, B.; Delbue, R.; Khanna, A.S.; Doshi, K.; Bhat, B.; Sureka, A. Technologies for very high bandwidth real-time oscilloscopes. In Proceedings of the IEEE Bipolar/BiCMOS Circuits and Technology Meeting (BCTM), Coronado, CA, USA, 28 September–1 October 2014; pp. 128–135. [Google Scholar]
- Baccigalupi, A.; D’Arco, M.; Liccardo, A. Evaluating the uncertainty of digitizing waveform recorders coherently with the gum. IEEE Trans. Instrum. Meas. 2018, 67, 2294–2302. [Google Scholar] [CrossRef]
- Angrisani, L.; D’Arco, M.; Ianniello, G.; Vadursi, M. An efficient pre-processing scheme to enhance resolution in band-pass signals acquisition. IEEE Trans. Instrum. Meas. 2012, 61, 2932–2940. [Google Scholar] [CrossRef]
- Gori, S.; Narduzzi, C. Application of a phase measurement algorithm to digitizing oscilloscope characterization. IEEE Trans. Instrum. Meas. 2000, 49, 1211–1215. [Google Scholar] [CrossRef]
- Baccigalupi, A.; D’Arco, M.; Liccardo, A.; Moriello, R.S.L. Compressive sampling-based strategy for enhancing adcs resolution. Measurement 2014, 56, 95–103. [Google Scholar] [CrossRef]
- Wang, D.; Zhu, X.; Guo, X.; Luan, J.; Zhou, L.; Wu, D.; Liu, H.; Wu, J.; Liu, X. A 2.6 GS/s 8-Bit Time-Interleaved SAR ADC in 55 nm CMOS Technology. Electronics 2019, 8, 305. [Google Scholar] [CrossRef] [Green Version]
- Jiang, X.; Wu, L.; Ma, Y. Synchronous Mixing Architecture for Digital Bandwidth Interleaving Sampling System. Electronics 2021, 10, 1998. [Google Scholar] [CrossRef]
- Monsurrò, P.; Trifiletti, A.; Angrisani, L.; D’Arco, M. Streamline calibration modelling for a comprehensive design of ati-based digitizers. Measurement 2018, 125, 386–393. [Google Scholar] [CrossRef]
- Attivissimo, F.; Nisio, A.D.; Giaquinto, N.; Savino, M. Measuring time base distortion in analog-memory sampling digitizers. IEEE Trans. Instrum. Meas. 2008, 57, 55–62. [Google Scholar] [CrossRef]
- D’Apuzzo, M.; D’Arco, M. A wide-band DSO architecture based on three time interleaved channels. J. Instrum. 2016, 11, 08003. [Google Scholar] [CrossRef]
- Lou, P.; Shi, L.; Zhang, X.; Xiao, Z.; Yan, J. A Data-Driven Adaptive Sampling Method Based on Edge Computing. Sensors 2020, 20, 2174. [Google Scholar] [CrossRef] [Green Version]
- D’Arco, M.; Napoli, E.; Angrisani, L. A time base option for arbitrary selection of sample rate in digital storage oscilloscopes. IEEE Trans. Instrum. Meas. 2020, 69, 3936–3948. [Google Scholar] [CrossRef]
- Napoli, E.; Zacharelos, E.; D’Arco, M.; Strollo, A.G.M. Real-time downsampling in digital storage oscilloscopes with multichannel architectures. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 1–14. [Google Scholar] [CrossRef]
- Li, J.; Pan, J.; Zhang, Y. Automatic Calibration Method of Channel Mismatches for Wideband TI-ADC System. Electronics 2019, 8, 56. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Xu, H.; Wang, Y.; Dai, Y.; Li, N.; Liu, G. Calibration for Sample-And-Hold Mismatches in M-Channel TIADCs Based on Statistics. Appl. Sci. 2019, 9, 198. [Google Scholar] [CrossRef] [Green Version]
- Bai, S.; Wan, Z.; Wan, P.; Zhang, H.; Ma, Y.; Zhang, X.; Liu, X.; Chen, Z. A 9-Bit 1-GS/s Hybrid-Domain Pseudo-Pipelined SAR ADC Based on Variable Gain VTC and Segmented TDC. Electronics 2021, 10, 2650. [Google Scholar] [CrossRef]
- D’Arco, M.; Napoli, E.; Zacharelos, E. Digital circuit for seamless resampling adc output streams. Sensors 2020, 20, 1619. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- D’Apuzzo, M.; D’Arco, M. Sampling and time–interleaving strategies to extend high speed digitizers bandwidth. Measurement 2017, 111, 389–396. [Google Scholar] [CrossRef]
- Seong, K.; Jung, D.; Yoon, D.; Han, J.; Kim, J.; Kim, T.; Lee, W.; Baek, K. Time-Interleaved SAR ADC with Background Timing-Skew Calibration for UWB Wireless Communication in IoT Systems. Sensors 2020, 20, 2430. [Google Scholar] [CrossRef] [Green Version]
- Han, Y.; Ni, K.; Li, X.; Wu, G.; Yu, K.; Zhou, Q.; Wang, X. An FPGA Platform for Next-Generation Grating Encoders. Sensors 2020, 20, 2266. [Google Scholar] [CrossRef] [PubMed]
- Monsurrò, P.; Trifiletti, A.; Angrisani, L.; D’Arco, M. Two novel architectures for 4-channel mixing/filtering/processing digitizers. Measurement 2019, 142, 138–147. [Google Scholar] [CrossRef]
- Kim, G.; Kull, L.; Luu, D.; Braendli, M.; Menolfi, C.; Francese, P.; Yueksel, H.; Aprile, C.; Morf, T.; Kossel, M.; et al. A 161-mW 56-Gb/s ADC-based discrete multitone wireline receiver data-path in 14-nm finfet. IEEE J. Solid-State Circuits 2020, 55, 38–48. [Google Scholar] [CrossRef]
- Xu, B.; Zhou, Y.; Chiu, Y. A 23-mw 24-gs/s 6-bit voltage-time hybrid time-interleaved adc in 28-nm cmos. IEEE J. Solid-State Circuits 2017, 52, 1091–1100. [Google Scholar] [CrossRef]
- Sun, K.; Wang, G.; Zhang, Q.; Elahmadi, S.; Gui, P. A 56-Gs/s 8-bit time-interleaved ADC with ENOB and BW enhancement techniques in 28-nm CMOS. IEEE J. Solid-State Circuits 2019, 54, 821–833. [Google Scholar] [CrossRef]
- Zahrai, S.A.; Onabajo, M. Review of Analog-To-Digital Conversion Characteristics and Design Considerations for the Creation of Power-Efficient Hybrid Data Converters. J. Low Power Electron. Appl. 2018, 8, 12. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Li, S.; Li, L.; Huang, Z. A Novel Time Delay Estimation and Calibration Method of TI-ADC Based on a Coherent Optical Communication System. Photonics 2021, 8, 398. [Google Scholar] [CrossRef]
- Ta, V.-T.; Hoang, V.-P.; Pham, V.-P.; Pham, C.-K. An Improved All-Digital Background Calibration Technique for Channel Mismatches in High Speed Time-Interleaved Analog-to-Digital Converters. Electronics 2020, 9, 73. [Google Scholar] [CrossRef] [Green Version]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
D’Arco, M.; Napoli, E.; Zacharelos, E.; Angrisani, L.; Strollo, A.G.M. Enabling Fine Sample Rate Settings in DSOs with Time-Interleaved ADCs. Sensors 2022, 22, 234. https://doi.org/10.3390/s22010234
D’Arco M, Napoli E, Zacharelos E, Angrisani L, Strollo AGM. Enabling Fine Sample Rate Settings in DSOs with Time-Interleaved ADCs. Sensors. 2022; 22(1):234. https://doi.org/10.3390/s22010234
Chicago/Turabian StyleD’Arco, Mauro, Ettore Napoli, Efstratios Zacharelos, Leopoldo Angrisani, and Antonio Giuseppe Maria Strollo. 2022. "Enabling Fine Sample Rate Settings in DSOs with Time-Interleaved ADCs" Sensors 22, no. 1: 234. https://doi.org/10.3390/s22010234