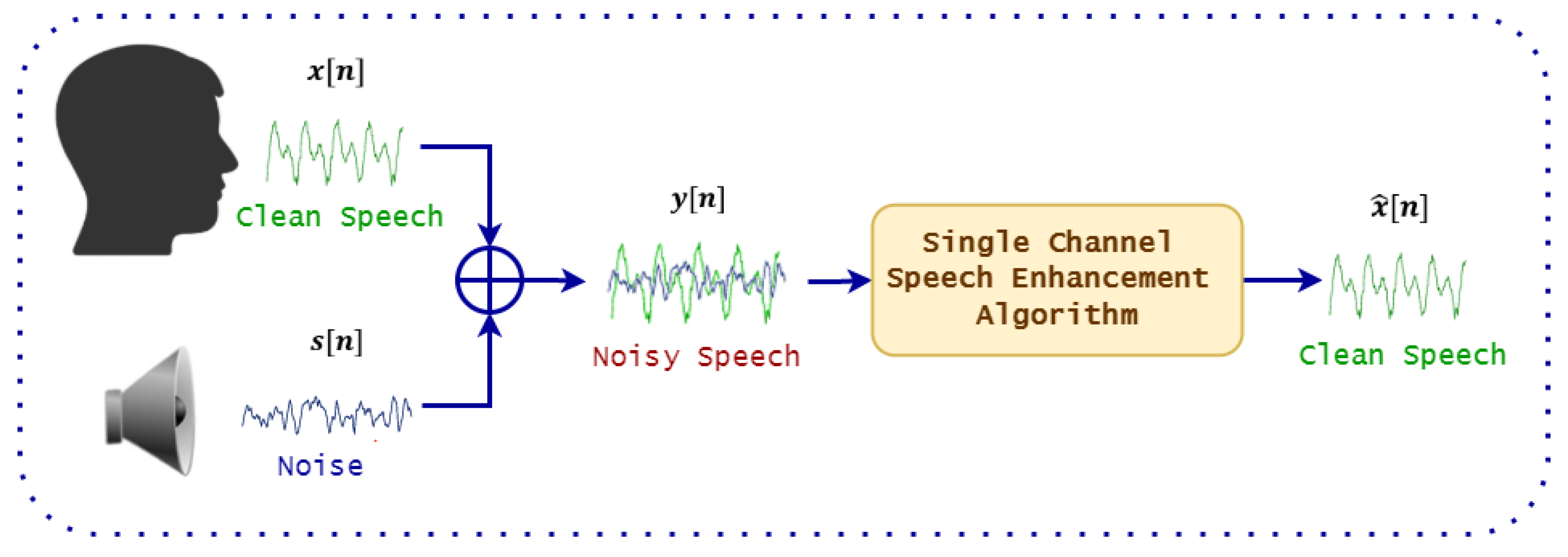
1. Introduction
Recently, the use of audio-visual platforms e.g., Microsoft Teams, Google Meet, Zoom, etc., for smart-working, remote collaborations and many other applications has been growing exponentially. In these cases, the speech signal is the predominant tool used for communication, and sharing ideas between people [
1]. Unfortunately, in these application scenarios, speech signals are usually corrupted by environmental noises or by the presence of other sound sources, e.g., TV, or other speakers in cocktail party scenarios [
2,
3]. Despite the presence of this interference, humans have the ability to extract the target speech signals, while ignoring noises and other interfering signals [
4,
5]. Unlike humans, many speech applications, like Automatic Speech Recognition (ASR), suffer in the presence of these adverse noisy conditions which deteriorate the speech quality and intelligibility, leading to considerable performance drops [
6,
7], especially in low level of signal-to-noise ratio (SNR).
In recent years, substantial progress has been made to mitigate the noise effect. A possible approach is to train, or adapt the models on the noisy data [
8]. This can be done either by collecting application specific data or through the usage of data augmentation strategies [
9]. However, it has to be considered that gathering large noisy datasets is costly and time consuming while, in general, all possible noisy conditions cannot be known a-priori making unfeasible the data augmentation based approach. Therefore, an alternative method is to use a speech enhancement (SE) front-end to improve the speech quality and intelligibility. SE, which is implemented as computer algorithms able to extract the target speech from noisy mixtures, is a fundamental task in the field of speech processing, and is currently integrated in wide range of applications such as: mobile telecommunication, speaker recognition and ASR systems. During the last decades, tremendous growth has been observed in the speech enhancement research area, in particular towards improving the robustness of ASR systems in noisy conditions.
Figure 1 shows a general diagram of a speech enhancement system.
Mathematically, denoting
as the clean speech signal and
as the additive noise (the environmental noise is also hypothesized to be additive) at time index
n, then the noisy speech signals
can be expressed as:
The goal of speech enhancement algorithms is to estimate the enhanced signal
from the noisy signal
, such that:
Classic techniques based on signal processing are, for example, spectral subtraction, Wiener filter for single channel scenario and beamformers, which employ microphone arrays to further reduce the noise effect [
10]. In particular, the minimum variance distortion-less response (MVDR) beamformer [
11] is the most common solution, that employs a multi-channel Wiener filter [
12] as post-filter. Unfortunately, the effectiveness of these techniques in reducing the impact of noise, i.e., improving the signal-to-distortion ratio (SDR) and the SNR, often does not lead to an improvement of ASR accuracy in terms of the word error rate (WER). In addition, signal processing methods perform poorly in presence of highly non-stationary noise, mainly because they rely on estimating of static spectral properties of the noise component [
13].
Recently, the progress of deep learning algorithms has brought substantial improvements also in the SE field [
14,
15,
16,
17,
18,
19]. Deep learning techniques are data-driven approaches that frames the SE task as a supervised learning problem aiming at reconstructing the target speech signals from the noisy mixture. A very popular set of neural spectral-based methods employ neural networks to estimate Time-Frequency (T-F) masks which are then used to separate the T-F bins associated to the target source and the noise. The network is trained using either ideal binary mask (IBM) or ideal ratio mask (IRM) as training targets [
20,
21]. Typically, the networks are trained using the mean squared error (MSE) either on the masks or on the reconstructed signal [
22,
23]. Despite the promising performance achievable in terms of SDR and intelligibility, the presence of artifacts in the reconstructed signals compromises the performance of further processing stages. In addition, only the magnitude of the spectrogram is enhanced, while the phase is left unprocessed.
One solution that can mitigate these issues is to implement the enhancement task in the time domain and process the raw waveforms [
24]. In this work, we aim at investigating possible ways to optimize the front-end speech enhancement not only in terms of signal quality but also to take into account the performance of the subsequent back-end component.
In particular, we address the intent classification task on noisy data and we propose a pipeline that integrates Wave-U-Net [
25], a time-domain enhancement approach, with an end-to-end intent classifier implemented with a time-convoluted neural model.
Our contribution to this task is to investigate methods to jointly optimize the front-end speech enhancement for noise removal and the back-end intent classification task. To the best of our knowledge, this the first attempt to jointly train an end-to-end neural model for both speech enhancement and intent classification in the time domain. This paper extends our previous preliminary work published in [
26], where we investigated the use of pre-trained speech enhancement models in combinations with intent classification. With respect to this work, the previous paper does not consider joint training of the two model. Moreover, the back-end operates in the frequency domain.
The rest of the paper is organized as follows:
Section 2, we survey the recent joint training approaches for different speech tasks.
Section 3, we explain each component in the proposed system description. In
Section 4, we report and discuss our experimental results. Finally, in
Section 5 we conclude our work.
2. Related Work on Jointly Training of Speech Enhancement with Different Speech Tasks
Three main strategies can be considered to incorporate a speech enhancement front-end into different speech-based applications. The first one consists in training the back-end based component (i.e., the IC classifier in the case of this work) on clean speech signals, while at inference stage a speech enhancement front-end is integrated for noise removal [
27]. The main disadvantage of this approach is represented by distortions introduced by the front-end (i.e., the speech enhancement module) that didn’t occur in the training data of the back-end. However, this strategy is still beneficial in different noise-robust speech based applications.
To overcome this limitation, the second strategy filters the training data of the back-end with speech enhancement, so that the back-end component works on the enhanced features. This strategy is useful in strengthen the back-end against noise, but it is highly dependent on the speech enhancement performance [
28]. In general, it was found to be better training the back-end on noisy data-sets, if they contain enough samples of the noise present in the operating conditions on the field.
The third strategy is to make the back-end component work on the noisy speech, while at inference noisy features are fed either to the back-end directly or, first, to the speech enhancement module. These multi-condition training strategy has shown promising results in [
29], but its performance in unmatched conditions is poor [
30]. Each strategy has its own advantages and disadvantages, and it is highly dependent on the application domain.
Jointly training, the strategy proposed in this paper aims to jointly adjusting the parameters of a neural (front-end) speech enhancement model and a neural (back-end) model designed for a specific task (e.g., ASR, voice activity detection, or intent classification). Thus, the speech enhancement front-end provides the “enhanced speech” desired by the back-end model. In this way the back-end model guides the front-end towards the execution of a better discriminative enhancement.
Figure 2 shows the schematic diagram of a conventional joint training approach including speech enhancement and an end-to-end (E2E) back-end. Note in the figure the two different losses defined for the front-end and the back-end that will be combined in a global loss as will be explained in
Section 3.3.
In the next sub-sections, we survey the most recent research based on joint training speech enhancement with other back-ends e.g., ASR and voice activity detection.
2.1. Jointly Training Speech Enhancement with Voice Activity Detection (VAD)
Many research works had been conducted to improve the VAD performance in low SNR environments. Typically the basic solution is to integrate a SE front-end as a pre-processing stage to eliminate noise [
31].
The authors of [
32,
33] trained the VAD based on the the denoised speech signals obtained from the SE front-end in which both the front-end model and the VAD model are jointly optimized and fine-tuned. Later it was observed that, training VAD directly based on the denoised signals resulting from the SE front-end may decrease the VAD performance, especially when the performance of the SE is poor [
34]. To mitigate this effect several researches integrates advanced SE front-end to extract the denoised features for VAD training [
35].
Inspired by the performance of U-Net in the field of medical imaging segmentation [
36], the authors in [
37] integrated a SE front-end based on U-Net to estimate both clean and noise spectra simultaneously, while the the VAD is trained directly on the enhanced signals.
Another contribution is done in [
38], in which a variational auto-encoder (VAE) is used to denoise the speech signals while the VAD is trained on the latent representation of the VAE. The authors of [
34], instead of training the VAD on the latent representation of the VAE, concatenate the noisy acoustic features with the enhanced features estimated from a convolutional recurrent neural network.
Finally, Refs. [
39,
40] proposes the use of a multi-objective network to jointly train SE and VAD to boost their performance. In this system both modules share the same network with different loss functions. Unfortunately, this technique weaken the performance of the VAD module.
2.2. Jointly Training Speech Enhancement with ASR
An early attempt for jointly training speech enhancement with ASR was proposed in [
41], where a front-end based feature extraction was jointly trained with a Gaussian Hidden Markov Model back-end and optimized with a maximum mutual information criterion. Towards this direction, the authors in [
42] proposed a novel jointly training approach by concatenating a deep neural network (DNN) based speech separation module, a feature extractor based on a filter-bank and an acoustic model, and train these models jointly.
The authors of [
43], beside investigating feature mapping based on DNN, jointly trained a single DNN for both feature mapping and acoustic modelling. The proposed approach showed a clear improvement in the ASR performance.
In [
44] the authors addressed the problem of joint training when the front-end output distribution change dramatically during model optimization, noticing a performance drawback on the ASR task due to the fact that the back-end needs to deal with a non-stationary input. To mitigate this effect, the authors proposed a a joint-training approach based on a fully batch-normalized architecture.
Inspired by its performance in the computer vision, the authors of [
45] investigated the usage of generative adversarial networks (GAN) in the speech enhancement area. They proposed a joint training framework based on adversarial training with self-attention mechanism for ASR noise robustness. The proposed system consists of a self-attention GAN for speech enhancement with a self-attention end-to-end ASR model. Finally, a recent research in [
46] proposes a joint training approach based on a gated recurrent fusion (GRF) for ASR noise robustness.
5. Conclusions
In this paper we proposed an end-to-end joint training approaches to robust intent classification in noisy environment. The jointly compositional scheme consists of a neural speech enhancement front-end based on Wave-U-Net combined with an end-to-end intent classification scheme. In particular, we investigate three different joint training strategies which combine the two components in different ways, namely JT, BN, and BN-Mix.
All experiments are conducted on the FSC dataset contaminated with a set of noises from MS-SNSD. Contrary to what observed in other speech related classification tasks, experimental results validate the efficacy of the proposed joint training approach, in which de-noising actually is beneficial in terms of final classification accuracy when models are trained on matched noisy material. We observed that equally balancing the enhancement and classification losses gives the best results. In addition, it is worth noting that injecting an intermediate loss is always beneficial, also with clean data. The motivation could be that given the large size of the model and the relatively small amount of training material the intermediate loss guides the network towards its optimal configuration. Finally, we also observed that the sequential nature of JT is better than the multi-task structure used in BN and BN-mix.
Future Directions
One future direction is to evaluate the proposed approach on different more complex datasets, as for example the ATIS corpus [
68], the Almawave-SLU corpus [
69], the SLURP corpus [
70]. In addition, to better assess the robustness and flexibility of the proposed approach, we plan to apply the same joint training scheme to other speech processing tasks, eventually involving seq2seq or regression tasks. One option is also to include multiple parallel tasks and jointly train the model in a multi-task learning fashion. Finally, we plan to investigate the joint training approach in combination with speech embedding. In particular, wav2vec pre-trained models [
71] can be used as an intermediate stage between the front-end and back-end models i.e., to extract the speech embedding form the enhanced speech signals and train the back-end based on these embedding. An alternative approach, is to integrate the wav2vec model on top of the speech enahncement front-end i.e., the front-end estimates the enhanced speech embedding, that will be later used to train the back-end.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}