The dimensions of the environment for training and evaluation were 20 m × 20 m. In each training episode, a new scenario was randomly created, with 20 passive agents and 1 active agent. All the velocities and starting positions of the agents were also random. In 20% of these scenarios, all the passive agents had null linear velocity, simulating a scenario with static agents. The density of moving obstacles in each scenario was maintained during the simulations.
For the system evaluation, four different types of scenarios were created, having different number of active and passive agents, and random velocities and starting positions. For each of the four types, 100 scenarios were randomly created, but they were the same for each of the three methods, in order to achieve a realistic comparison of the three methods.
6.1. RL-DOVS-A Training
The RL-DOVS-A navigation system was trained during 2500 episodes with a learning factor
and a discount factor
. Given the variability of the environment, a constant learning rate factor was applied [
17]. A reduced learning factor was chosen to slowly update the Q-table over time to ensure convergence.
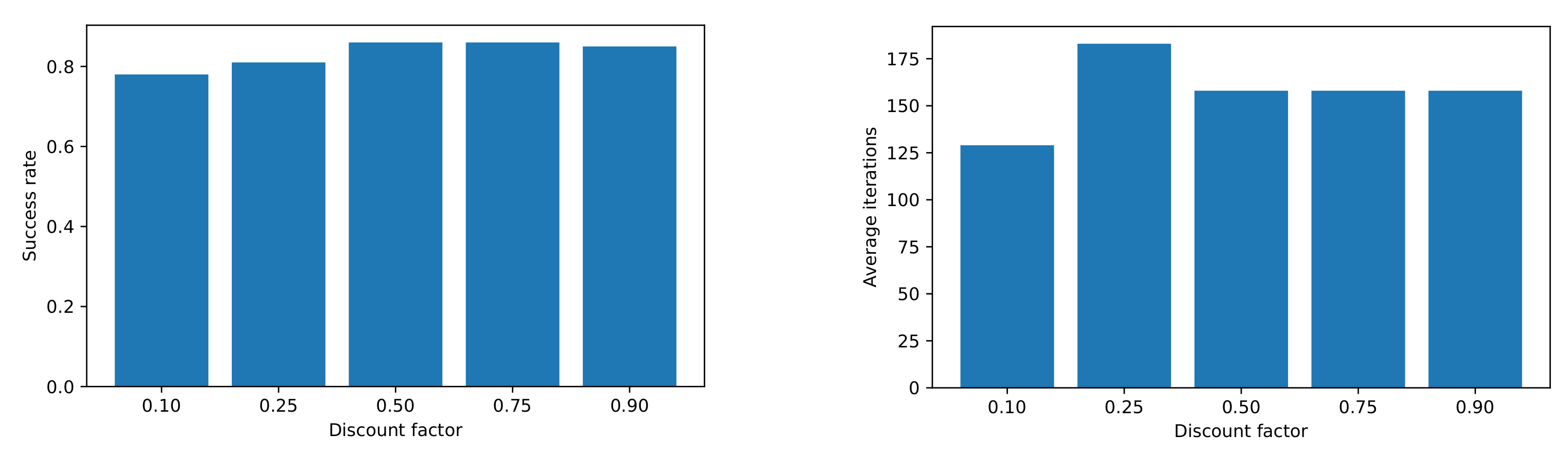
Different discount factor (
) values were tested; the results can be seen in
Figure 4. We conclude that using from intermediate to high values, we obtained good results in terms of success rate and average iterations.
Initially, exploration rate = 1, and it was reduced by 0.0005 with each episode. This way, after 2000 episodes, no more states were explored, and the agent only exploited. Optimized learning for different scenarios was considered, obtaining different Q-tables. However, only one Q-table was trained and later applied to all types of scenarios for the following reasons:
States related to mobile and static obstacles are distinguished, so there is no advantage in training two separate Q-tables for each type of obstacle;
A similar success rate can be obtained in training scenarios with 20 agents and scenarios with 10 agents if more training time is applied in the latter case;
Given the variability and unpredictability of possible scenarios, it is more convenient to apply only one Q-table learned for a wide variety of scenarios than to have several specialized Q-tables.
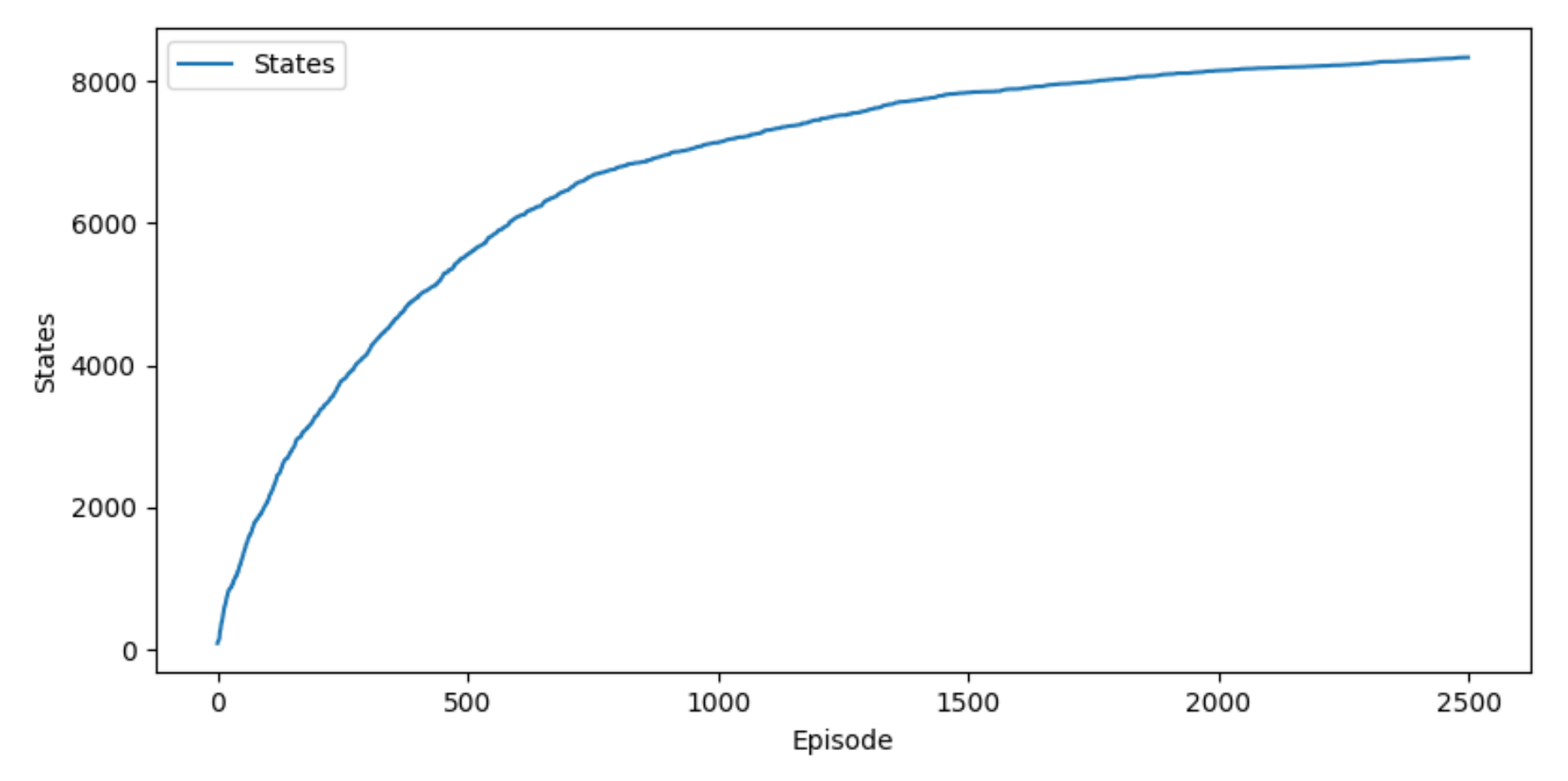
The training took approximately 595,000 iterations for 2500 episodes. In each episode, a new scenario was randomly created and launched, with 20 passive agents and 1 active agent with random starting positions, goals and velocities. In 20% of these scenarios, the passive agents were static. The total number of states after the training was 8329 states, as seen in
Figure 5. The total number of states incremented rapidly at the beginning and then more slowly until converging in a total number of states. This was expected because most of the states had already been explored.
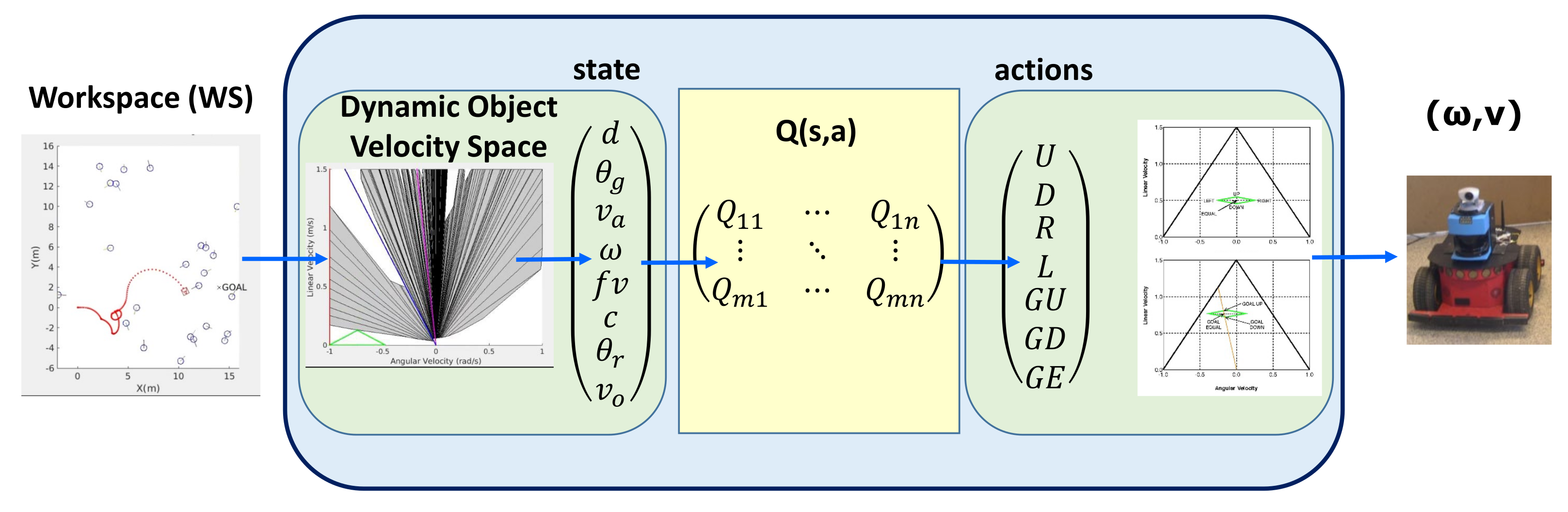
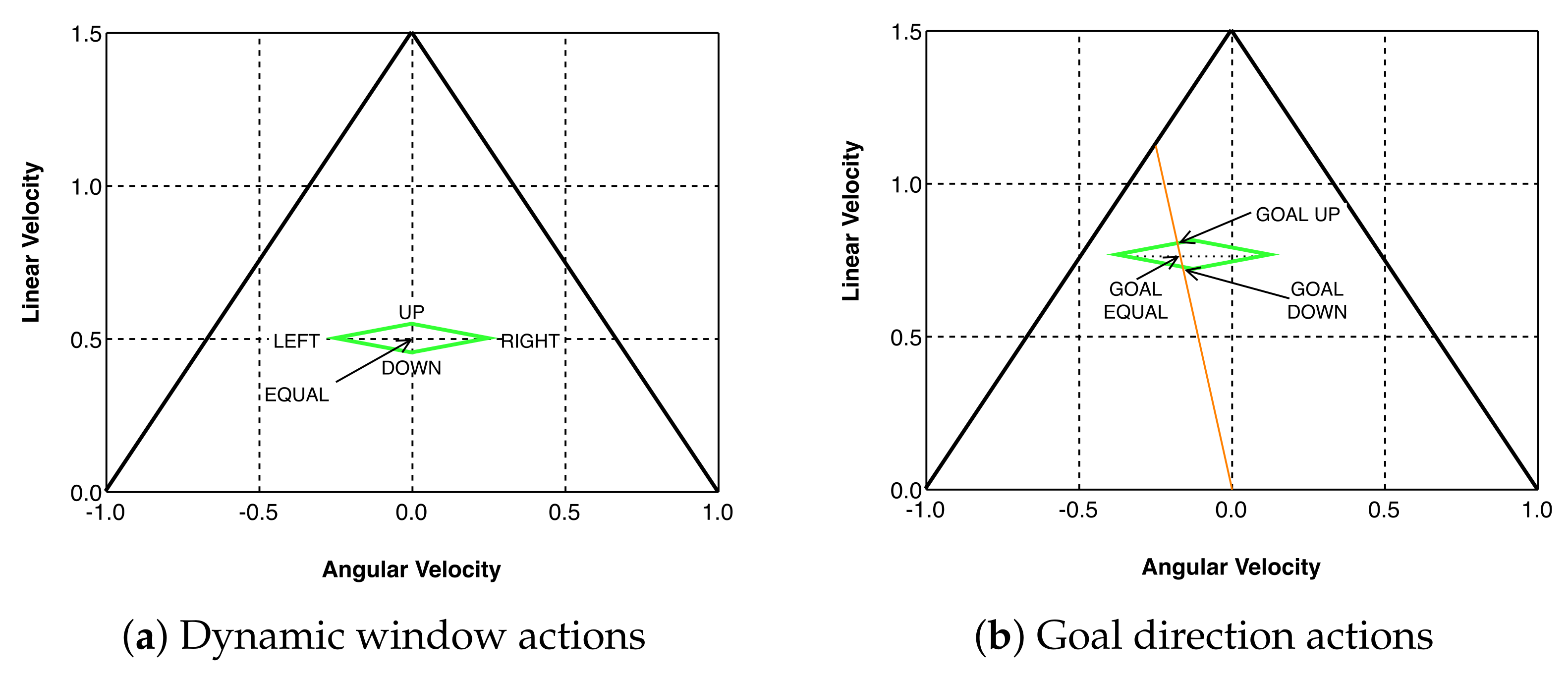
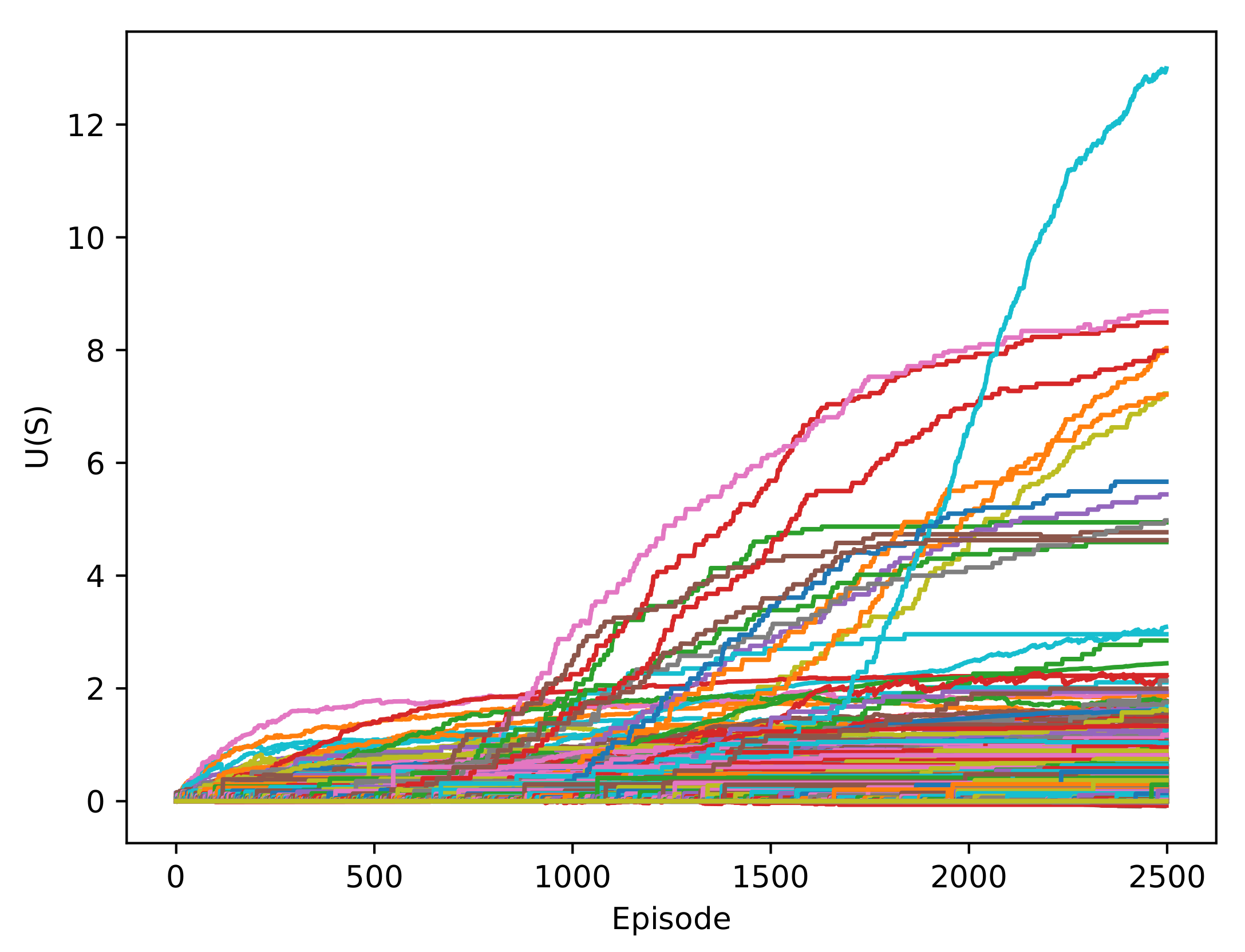
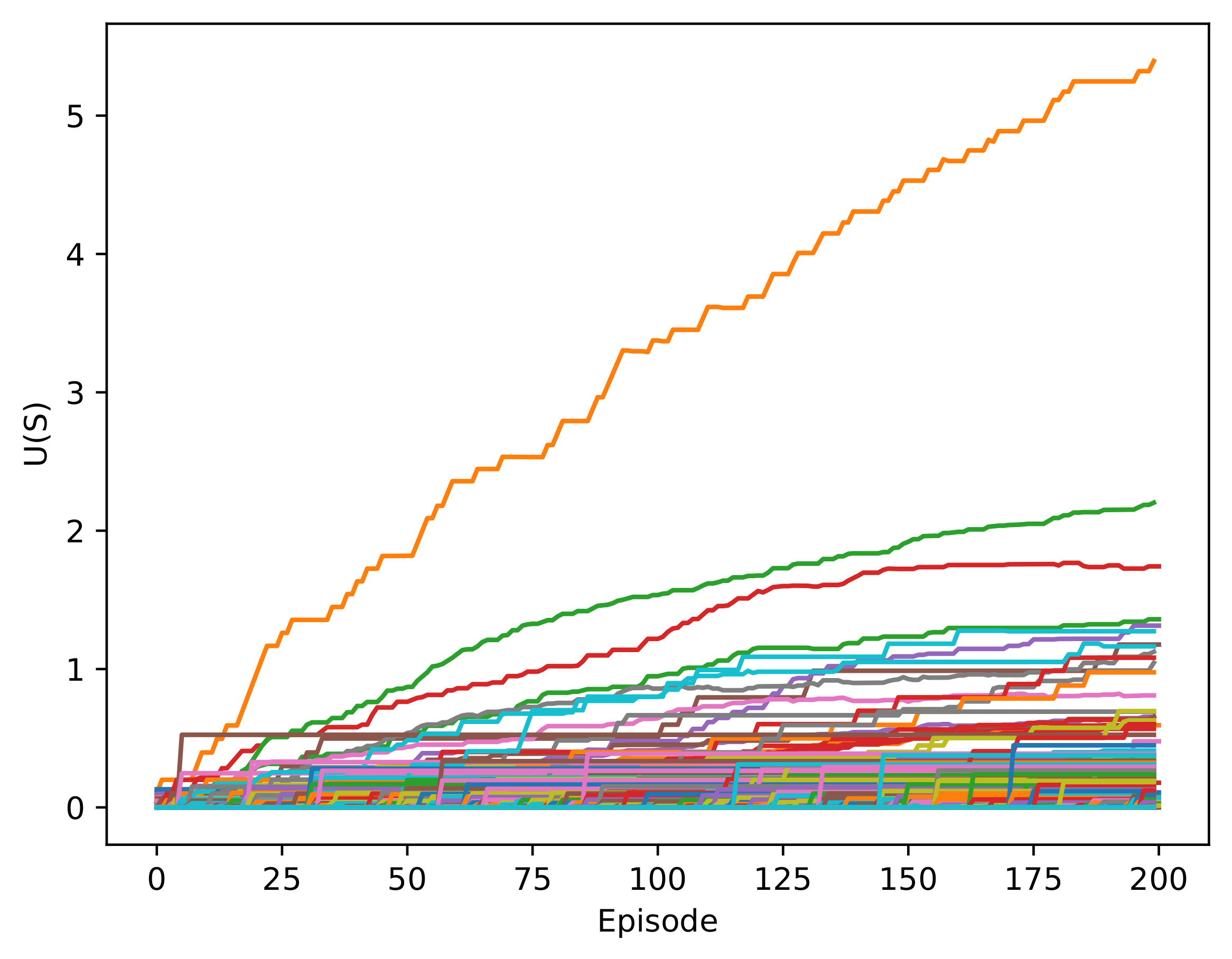
The utility of a state is given by the highest value of the Q-values for a state, which corresponds to an action. In
Figure 6, the utility of the states was initially low, but at the end of the training, the values of a few states increased substantially. This is because a policy was chosen, and the high-value states were continuously repeated. These increments were produced in the 1000-episode area, which was expected because the agent began to exploit more than explore.
Table 4 describes the 10 states with the highest utility
once the system was trained. The first column represents the states, and the other columns represent the values of each, from the highest to the lowest values. From this table, we can conclude that the states with higher utility value were the states where the agent was on the objective, had a linear velocity close to null, was aligned with its goal and was in a no-collision situation.
was the state with the highest value for the system. This was expected because braking in these states would have ended the episode, and the action taken would have received a great reward.
6.3. Evaluation and Comparison of Systems
Once the two systems were trained, some tests were run to compare the results with the S-DOVS system. The following scenarios were simulated:
One active agent and ten passive mobile agents;
One active agent and twenty passive mobile agents;
One active agent and twenty passive static agents;
Three active agents and eighteen passive mobile agents.
For each type of scenario, 100 completely random scenarios were created, with random velocities and agent starting positions. The scenarios were the same for the different systems to obtain a realistic comparison of the results. The following metrics are defined:
Success rate: the percentage of scenarios tested in which the agent reached its goal;
Iterations: average number of iterations;
: average distance to the closest obstacle;
v: average linear velocity;
: average distance to the goal;
: average alignment with the goal.
Table 6 (a–d) shows the results for four scenarios. The mean values and the standard deviation for the last four metrics are represented. Only values where the scenario was a success were considered for these metrics. The best values for each metric is highlighted.
With a low number of passive agents, the success rate was high, but the systems with RL ended up being safer, with a higher success rate and larger average distance to the closest obstacle. The RL-DOVS-A system obtained the shortest times to goal, as seen in the number of iterations, because the RL-DOVS-A typically maintained higher linear velocities. The RL-DOVS-D also applied high linear velocities but obtained the longest times to goal, so we can conclude that it realized longer trajectories. The original strategy-based method was more conservative with respect to the maximum velocities applied, maintaining a slightly lower Success rate than RL-DOVS-A.
Table 6a shows the results.
The systems with RL presented a higher standard deviation in the number of iterations than S-DOVS, so this technique was more consistent with the length of trajectories it made. This difference in standard deviations repeated itself during all the tests. The average distance to the closest obstacle was similar in the different systems, but RL-DOVS-D maintained more distance from the closest obstacle, because the driver was more conservative about moving away from obstacles.
However, the average distance from and alignment with the goal tended to be larger in the systems with RL. RL-DOVS-A tended to move further away from the goal, and RL-DOVS-D tended to deviate from the goal more. This outcome is compatible with the highest maximum velocities for these systems whilst moving away from the obstacles, leading to longer trajectories with more curvature.
Table 6b shows the results with 1 active agent and 20 passive mobile agents.
As expected, adding more passive agents reduced the success rate in general, slightly incremented the average iterations and reduced the average distances to the nearest obstacle. With this said, the success rate of the RL-DOVS-A system was higher, except for the less-dense scenario, which means it is a safer system. The average distance to the closest obstacle of the RL-DOVS-D was the highest, but this system had the lowest success rate.
Adding more passive agents increased the average iterations in the RL-DOVS-A system, making that count larger than in the original system, even though the average linear velocity was still greater. The RL-DOVS-D system continued to be the worst system with respect to iterations. As in the first test run, the distance and deviation with respect to the goal were much higher in the trained systems. The results with 1 active agent and 20 static passive agents are shown in
Table 6c. The average velocity was similar for both RL-DOVSs and higher than in S-DOVS. The highest number of iterations in RL-DOVS-D means that the trajectories are longer for this technique in general.
The results are similar to those of the previous scenario type, but in this case, the success ratio of RL-DOVS-A was the same as that of the S-DOVS system. A problem that the new systems have is that they are restricted to only apply safe velocities, that is, the ones out of the DOVS, unless all velocities are unsafe, so they can become blocked if the obstacles do not move. In the case of the S-DOVS system, the selection of temporally unsafe velocities inside dynamic obstacles is allowed in order to maneuver to reach safer velocities.
The results with 3 active agents and 18 moving passive agents are represented in
Table 6d. After adding three active agents, the success rate was greatly reduced for all systems, which was expected, because a scenario is only considered successful if all active agents reach their goal. However, the comparison of results is similar to the scenarios with 20 passive mobile agents and 1 active agent, whereby the success rate and the average distance to the closest obstacle were greater for RL-DOVS-A, but the average iterations were lower in the S-DOVS system.
To summarize, the RL systems always keep higher average velocities than the strategy-based ones but achieve longer trajectories and time to goal in dense scenarios due to the fact that they execute safer trajectories farther from the obstacles. RL-DOVS-A kept average velocities higher than S-DOVS, obtaining a time to goal only greater due to longer trajectories. There were no large standard deviations with respect to the mean values of velocities and distance to the obstacles for the three methods.
The RL-DOVS-A technique exhibited the best success ratio with respect to the other two techniques. Although in RL-DOVS-D the actions selected by the driver led to theoretically safer trajectories farther from the obstacles than RL-DOVS-A, its success ratio was lower. It is likely that it is due to the more-reduced training time devoted to the RL-DOVS-D technique.
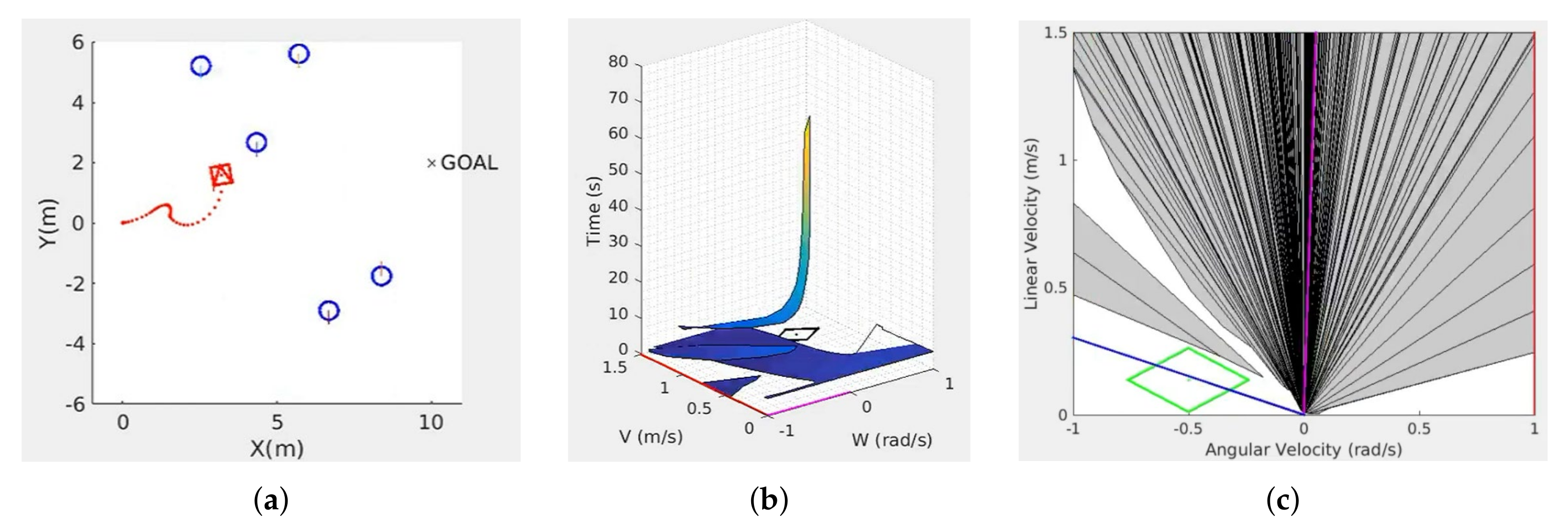
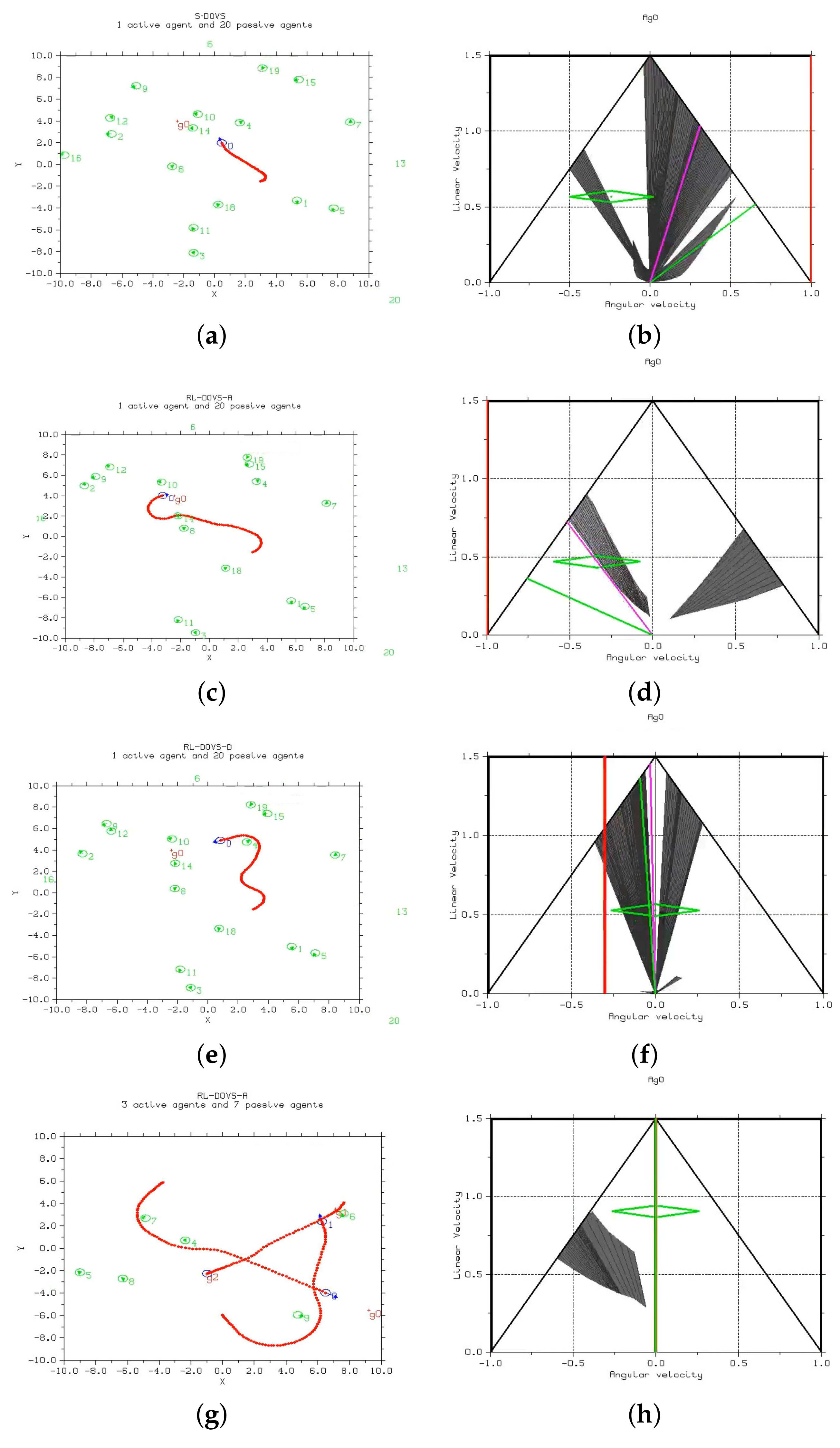
Figure 8 shows the scenarios at a given time step for the three methods. The execution of the three methods can be seen in the following videos: S-DOVS (
https://youtu.be/kBxtYju9Qug; accessed on 6 April 2022), RL-DOVS-A (
https://youtu.be/fIrwtF95v0Y; accessed on 6 April 2022) and RL-DOVS-D (
https://youtu.be/irlmyGbREaM; accessed on 6 April 2022). The three methods were applied in scenarios with up to 10 and up to 20 moving and static passive agents with 1 active agent and others with 3 active agents.
One and three active agents were represented in these scenarios. In the active multi-agent scenario, the same technique was applied to all the agents, and the navigation method also worked correctly in this case. Each active agent considered the other agents as an obstacle; they did not need an explicit cooperation strategy to reach their goals.
The videos show that, in general, for the same scenario, the systems based on RL tended to create more circular and larger trajectories, whereas the strategy-based system tended to navigate to the goal more directly. However, the new systems compensated for these long trajectories by applying high linear velocities. RL-DOVS-D took more iterations than the other two techniques due to longer trajectories. The video shows that the active agents were not able to slow down to stop at the goal in one case. It could be due to the driver not braking on time; the driver might brake too late during the training phase. Therefore, the robot must come back to reach the goal. It does not occur in RL-DOVS-A because the system automatically applies braking when needed.
In scenarios with few obstacles, the models with RL had more room to maneuver; thus, they arrived at the goal sooner. This can be checked by comparing the average iterations of the results with 10 and 20 obstacles.
In scenarios with a larger number of obstacles, the S-DOVS system took more risks. If obstacles were between the active agent and its objective, the agent tended to traverse the area with obstacles. The systems with RL are more conservative by design and try to circle around the area with obstacles, because unsafe velocities are forbidden. This way, the RL-DOVS-A system obtained a higher success rate and larger average distance to the closest obstacle. However, increasing the number of obstacles left less space for the systems with RL to maneuver, so they took longer to reach the goal.
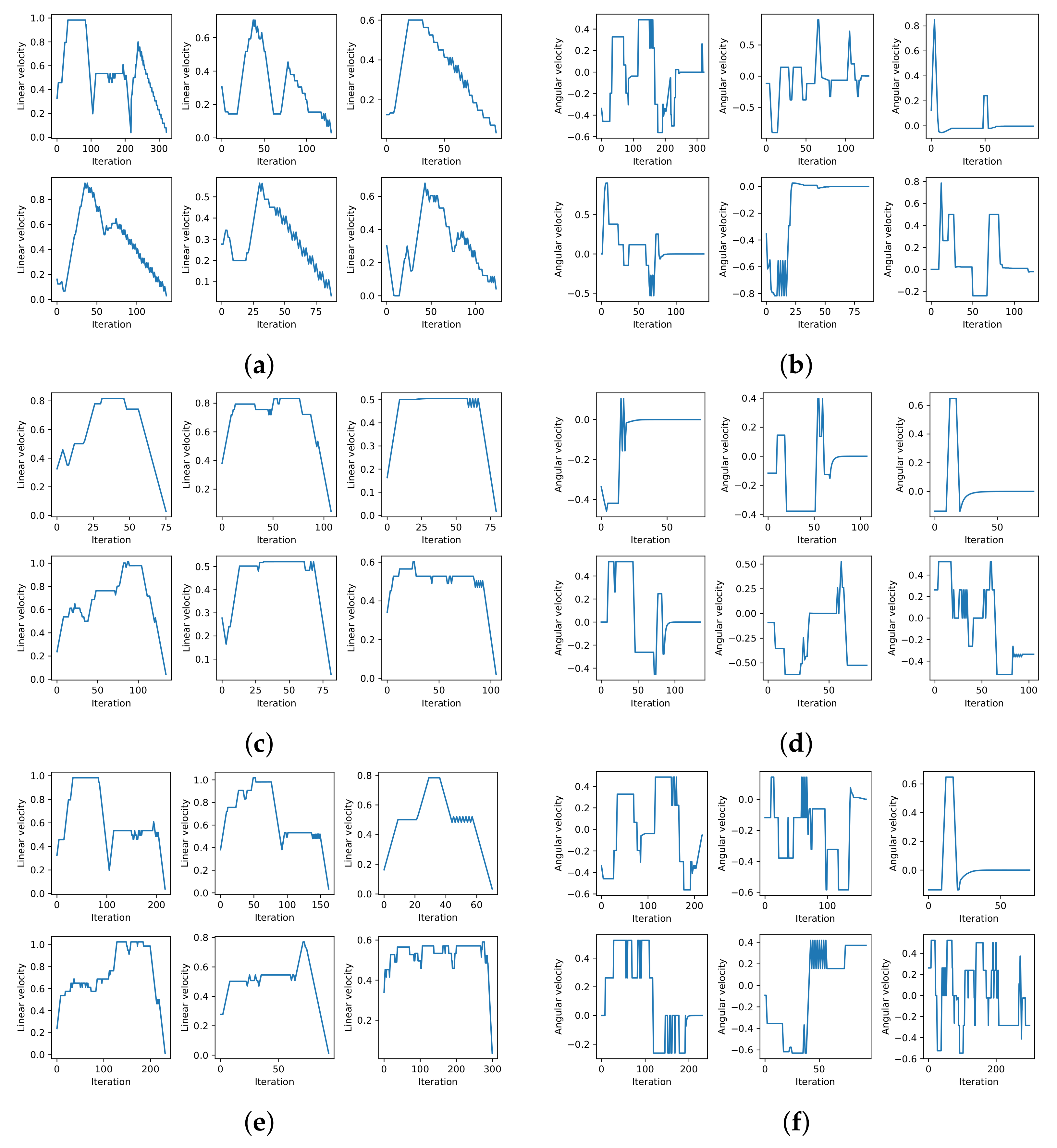
The linear and angular velocity profiles for six different scenarios and for the three methods are shown in
Figure 9. The figure shows that each method, in general, exhibited a similar velocity profile for the six scenarios. The linear velocity profiles show that the systems with RL tended to maintain elevated linear velocities for longer. The S-DOVS system initially strongly accelerated until it reached the maximum velocity; then, it slowly reduced its speed until it reached the goal. This is the defined strategy for deceleration when approaching the goal. RL-based systems learned the best acceleration–deceleration behavior, accelerating until reaching a very high linear velocity, maintaining it during a long period and, finally, slowing down at maximum deceleration in the case of RL-DOVS-A. This way, this system reached the goal faster than the others. It can be also observed that RL-DOVS-A reached the goals with less oscillations that the other two techniques in several of the scenarios. This suggests that this method is able to better plan the motion of the next steps, reducing the more reactive behavior of the other techniques.
The angular velocity profiles show that S-DOVS applied high angular accelerations to re-orient the agent towards the goal. RL-DOVS-A obtained a smoother motion, computing lower maximum angular velocities. RL-DOVS-D provoked a more oscillatory motion to avoid the obstacles and re-orient towards the objective. This shows a more reactive behavior of the driver compared with a more planned motion using the utilities learned by RL-DOVS-A.
In summary, RL-DOVS-A exhibited a better global performance than the other two techniques. The system automatically learns the actions to apply in every state, needing neither prefixed strategies based on rules as S-DOVS does nor a driver to learn the actions, which increases the length and difficulty of the training. Note that the RL-based techniques are more restrictive regarding the velocities permitted, always applying safe velocities in the free velocity space. If these restrictions were relaxed, greater maneuverability would be obtained, possibly improving the results with respect to the rule-based technique. This investigation is left for future work.
The tests were performed using an Intel i5-10300H (8) @ 4.500 GHz CPU with 8 GB of RAM. The new reinforcement learning systems were built on top of the already existing DOVS system, which was developed in C++. The Q-learning algorithm was implemented without the use of pre-existing machine learning libraries in order to adapt the algorithm to the already existing system, offering more flexibility and control over the process. The average iteration time was calculated over a set of 100 different scenarios with 1 active agent and 20 passive agents, obtaining 2150 ± 472 s for S-DOVS, 3617 ± 1338 s for RL-DOVS-A and 3951 ± 1360 s for RL-DOVS-D. A positive aspect of the developed Q-learning algorithm is that, once the system is trained, the agents only need to look up the best action to take in the Q-table depending on their current state. Even though the computation times are slightly higher for the reinforcement learning systems than for the strategy-based original method, they are small enough to be suitable for real-time applications. A higher standard deviation is expected, since computation time can vary depending on where the sought state is positioned on the Q-table.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}