
Human Activity Recognition by Sequences of Skeleton Features

 ,
,  ,
, 
 and
and
Abstract
:1. Introduction
- The use of several frames of a video to recognize an activity is proposed. This approach allows us to correctly detect those activities that require a time greater than the period required to capture a frame. The use of several frames of a video is proposed to recognize an activity. Note that this approach allows performing two kinds of classification problems: bi-classification (fall/not fall), and multi-classification (recognition of more than two activities). The proposed method provides better results than those reported in previous works, including those activities that were recognized with only one frame. That is why the method represents a global improvement in the detection of activities.
- This approach differs from many existing works in that the effort is made in the feature extraction stage by proposing to use skeleton features to estimate the human pose in a frame. Unlike previous works, the feature vector is formed by combining skeleton features from several consecutive frames. In this paper, we describe a study to specifically determine the frames needed to detect activities.
- To show the improved detection performance, the approach is validated using different ML methods to build an activity classifier. Better results are obtained for most of the machine learning methods used.
- Finally, the robustness and versatility of the approach have been validated with two different datasets, achieving in both cases better results compared to those previously reported in the literature.
2. Fall Detection Datasets and Related Work
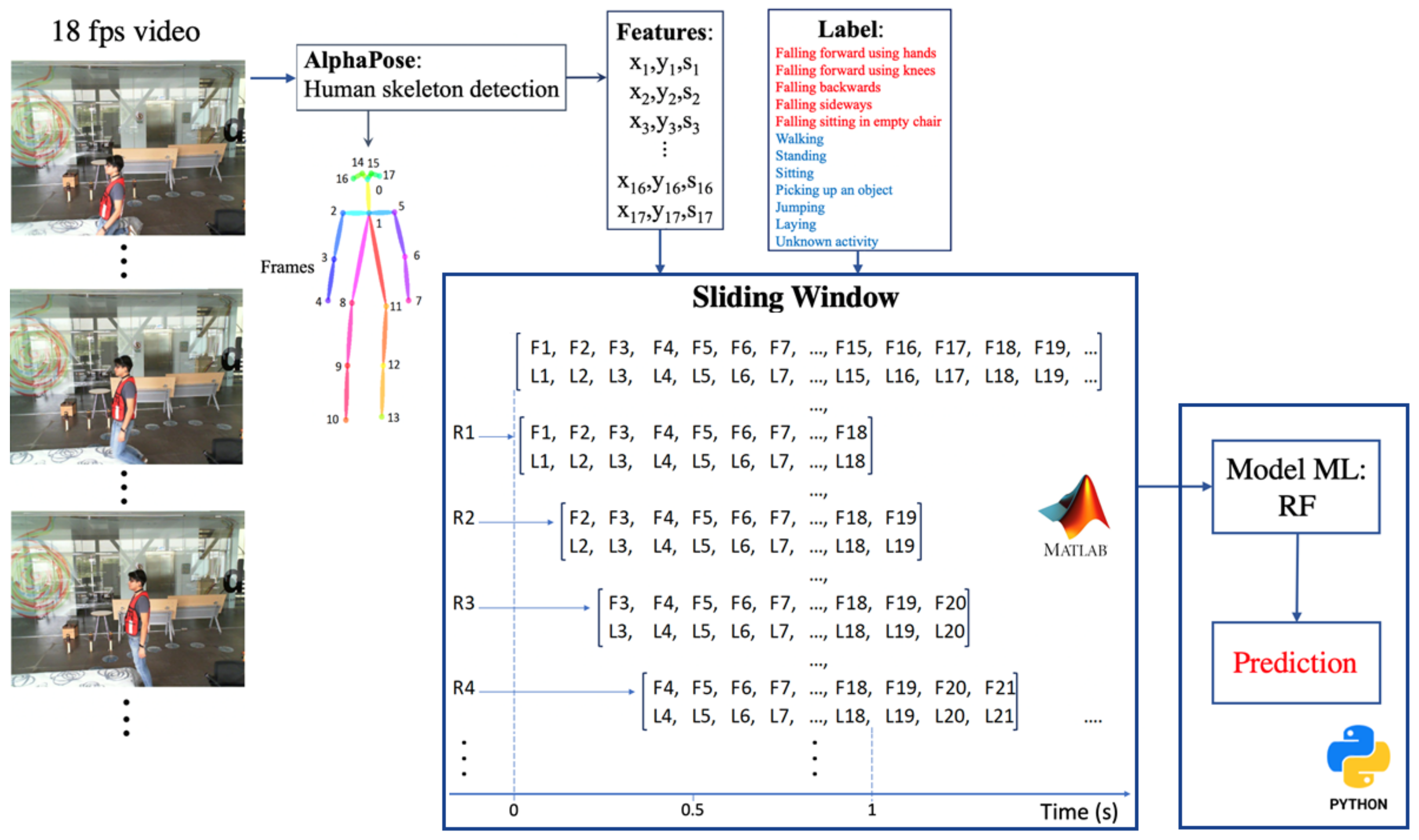
3. Methodology of the Proposed Approach
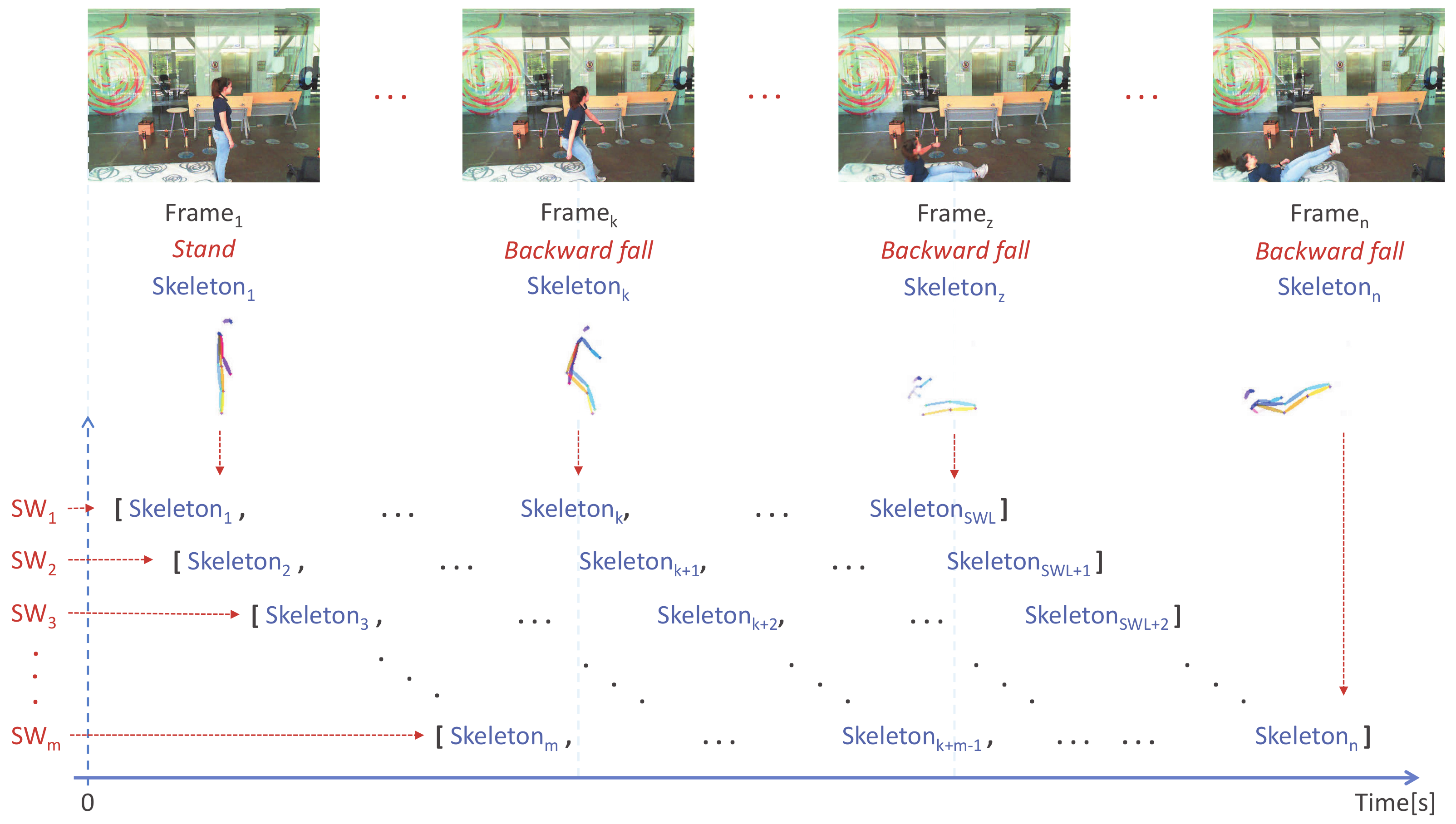
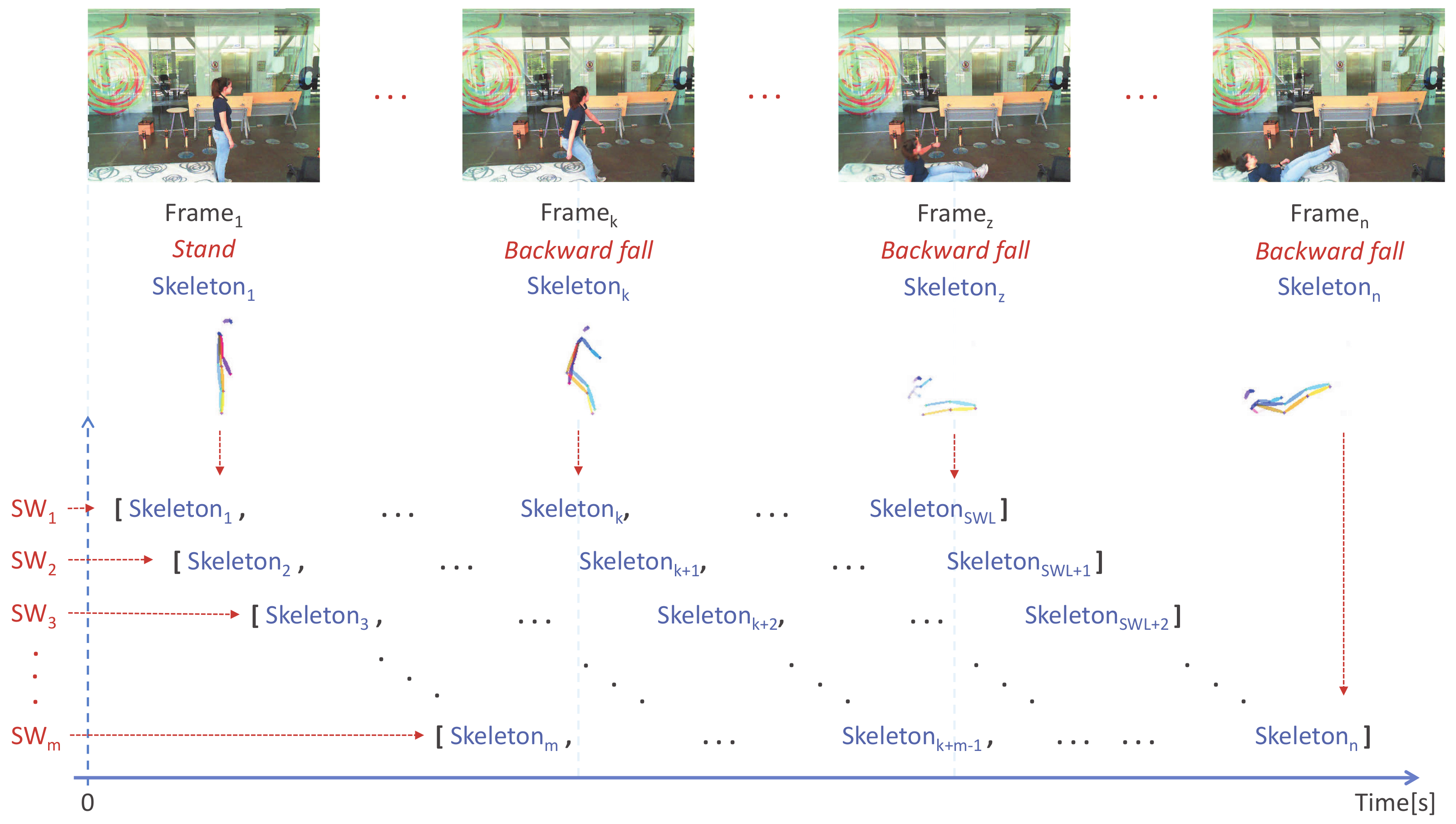
3.1. Selection of Sliding Windows
3.2. Feature Vector Construction
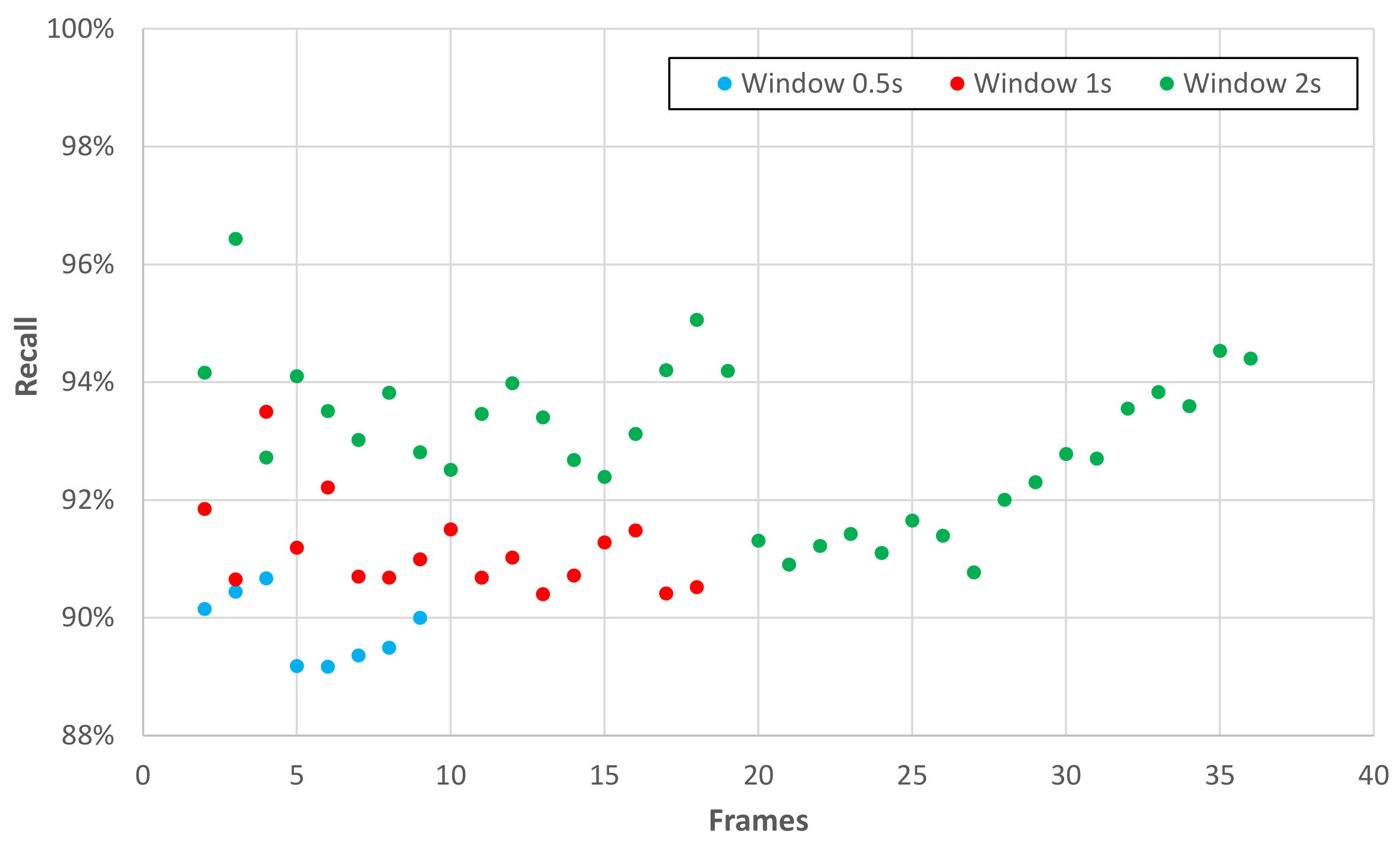
4. Study of Feature Vector Parameters Settings
4.1. Exhaustive Search
- Videos or images must have only one person; so if there is more than one person in the scene, only the characteristics of the person of interest are used, and the skeletons of the other people are discriminated.
- The duration of the video must be longer than the window size (W).
- The duration of the activity must be longer than or equal to the window size (W).
- When obtaining the skeleton features for each video frame, the key-points must always be 17 per person.
4.2. Data Acquisition
4.3. Skeletons Selection
- For s: .
- For s: .
- For s: .
| for ws in {0.5, 1.0, 2.0} do |
| for s in {1...FPS} do |
| feature_vector = new Matrix{ frames_of_video.size \ |
| - (ws ∗ FPS) + 1 , 51 ∗ (s+1) } |
| frames = new Vector{ s+1 } |
| for x in {0...s} do |
| frames[x] = (x / s) ∗ ((ws ∗ FPS) - 1) |
| frames[s] = (ws ∗ FPS) - 1 |
| i = 0 |
| while (i <= (frames_of_video.size - (ws ∗ FPS))) do |
| f = 0 |
| for frame in frames do |
| feature_vector[i][f] = frames_of_video[frame+i] |
| f++ |
| i++ |
- : Initial position of the skeleton.
- : Position of the skeleton to be selected.
- F: The data number of the feature vector ().
4.4. Best Solution
- Recall = .
- Window size (W) = 2 s.
- Number of skeletons for window (S) = 3.
- Number of features (F) = 153.
5. Metrics and Associated Parameters
5.1. Models
5.2. Metrics
- TP (True positives) = “fall” detected as “fall”;
- FP (False positives) = “not fall” detected as “fall”;
- TN (True negatives) = “not fall” detected as “not fall”;
- FN (False negatives) = “fall” detected as “not fall”.
6. Experimental Results
6.1. Fall Detection and Activity Recognition Using an LSTM
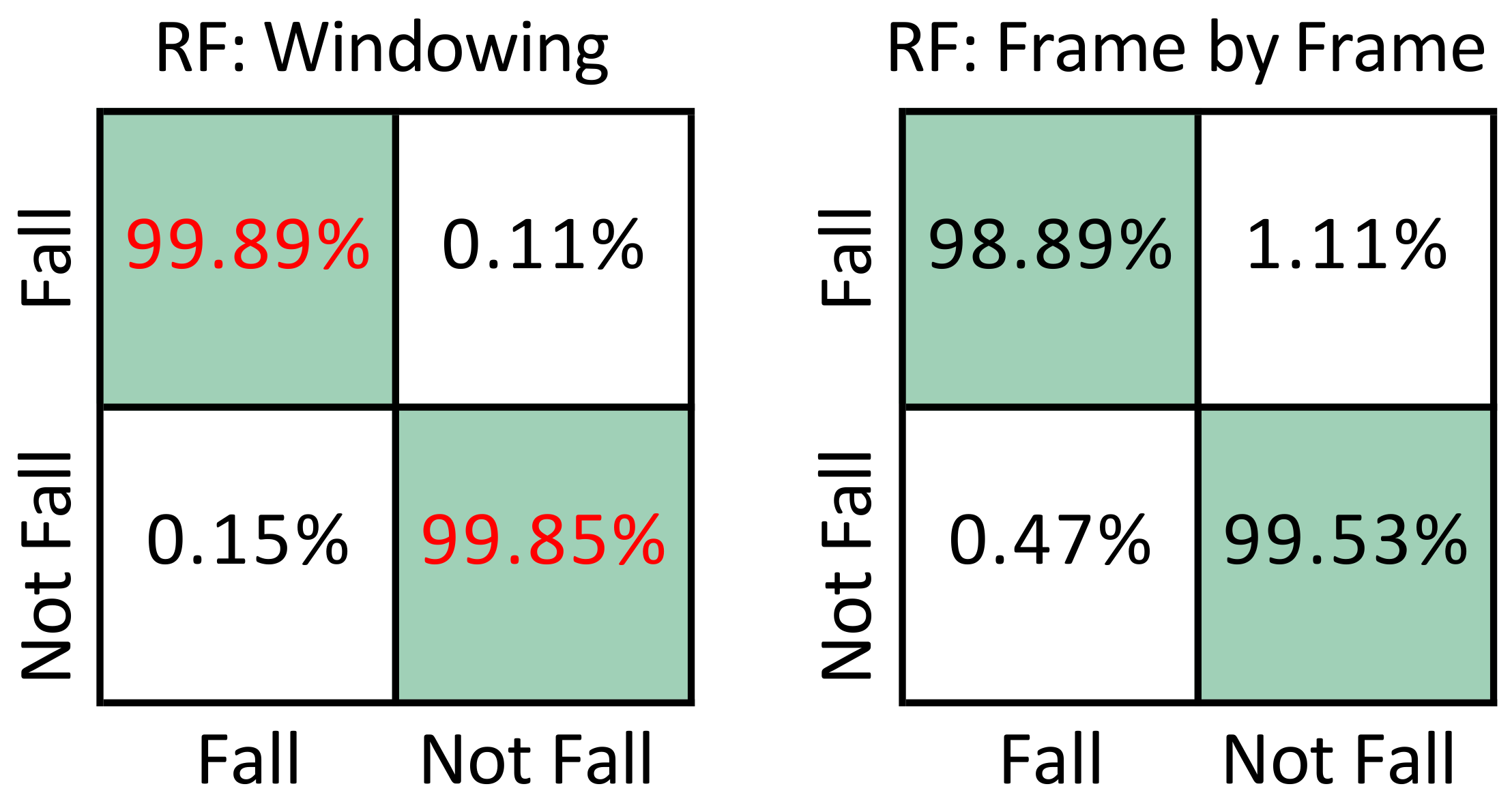
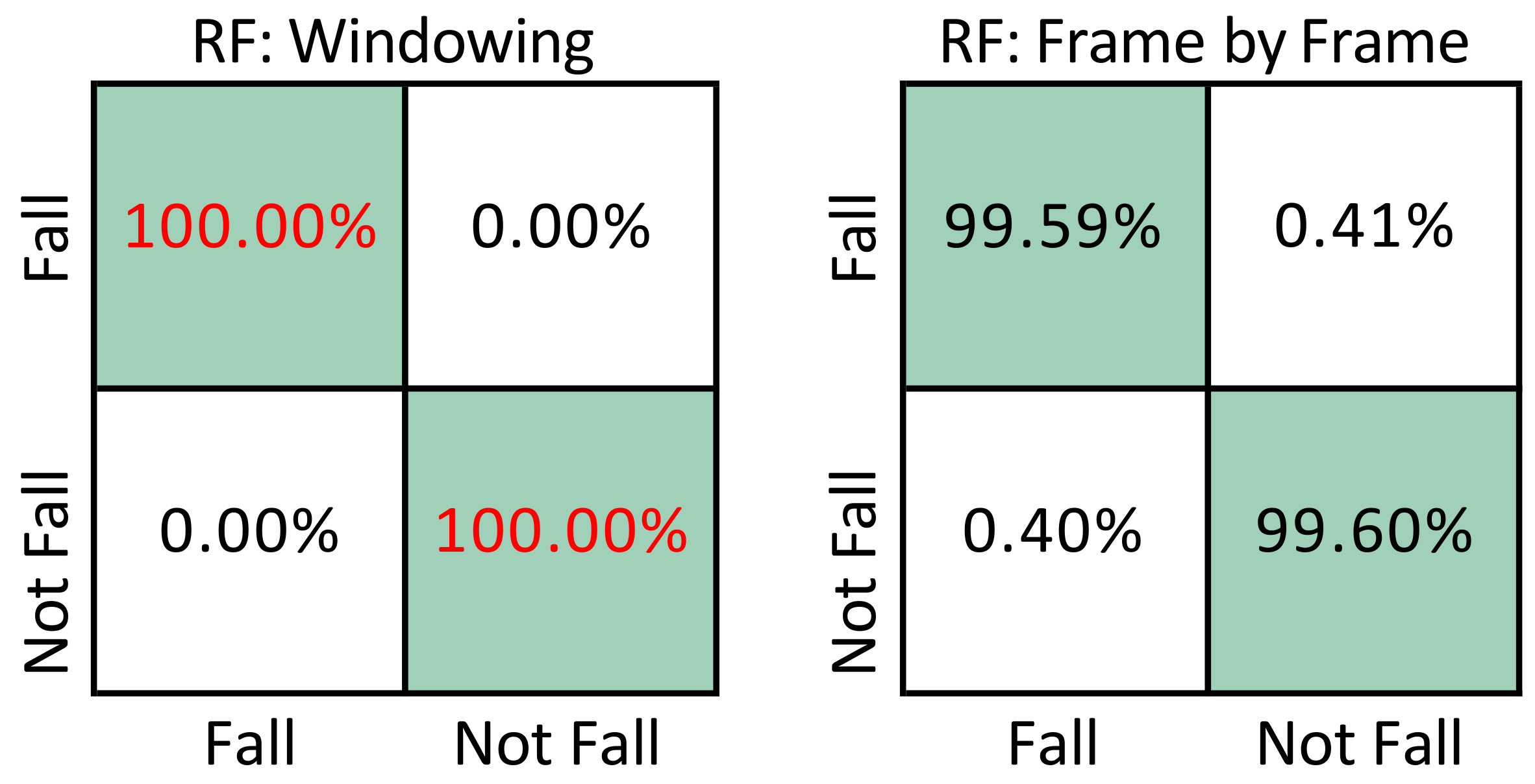
6.2. Fall Detection with UP-Fall
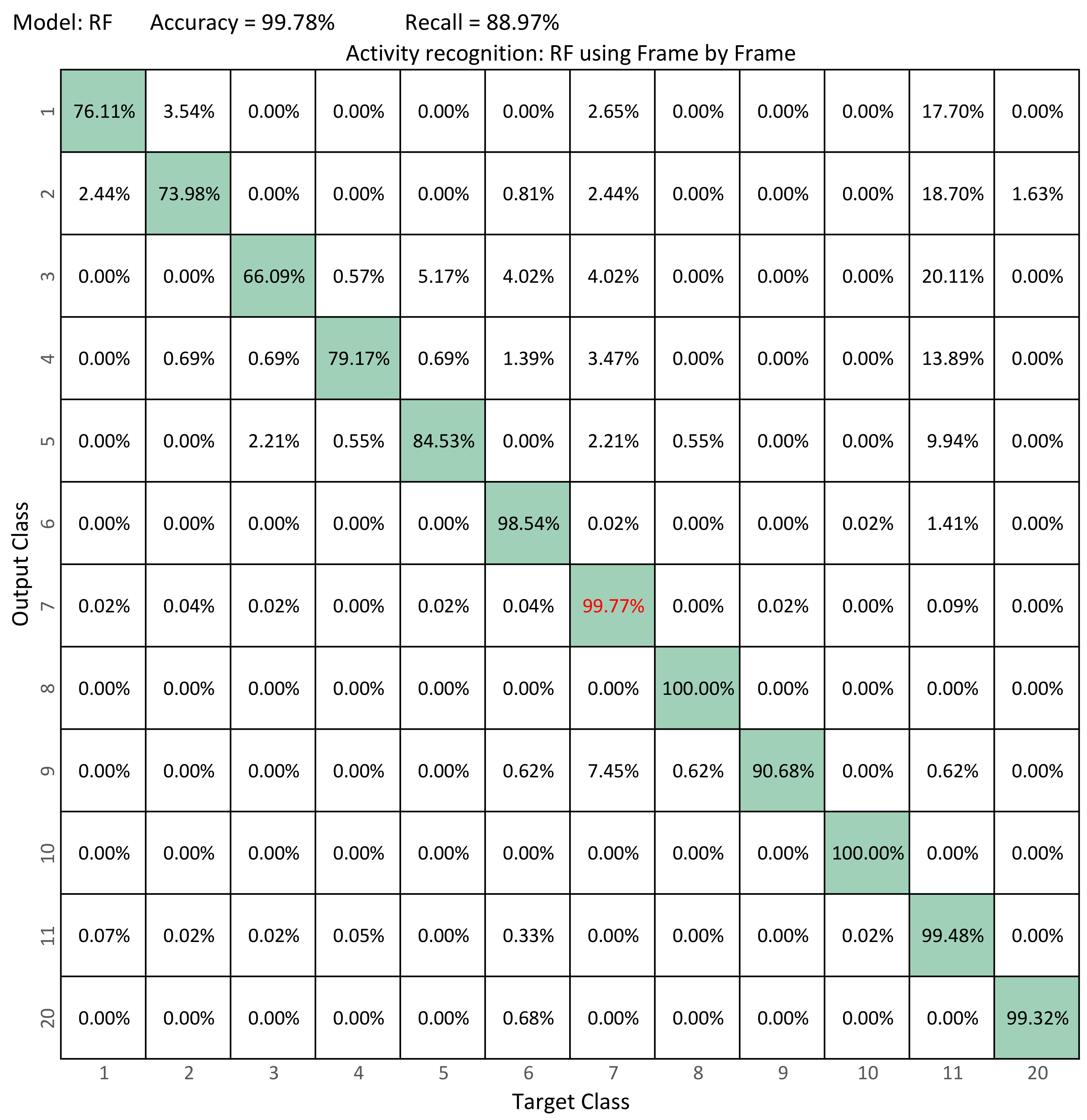
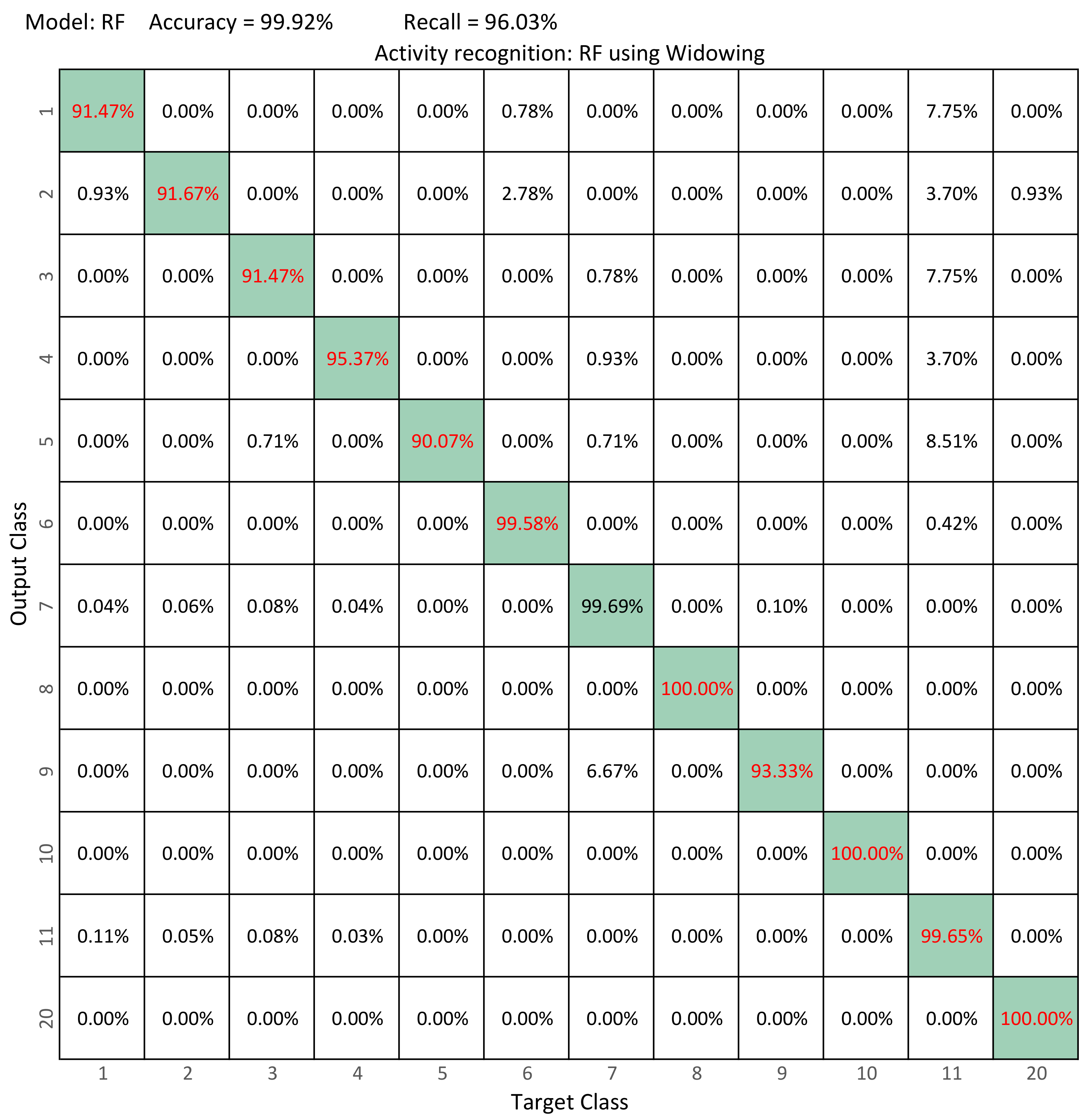
6.3. Activity Recognition with UP-Fall
6.4. Fall Detection with UR-Fall
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pham, T.N.; Vo, D.H. Aging population and economic growth in developing countries: A quantile regression approach. Emerg. Mark. Financ. Trade 2021, 57, 108–122. [Google Scholar] [CrossRef]
- Usmani, S.; Saboor, A.; Haris, M.; Khan, M.A.; Park, H. Latest research trends in fall detection and prevention using machine learning: A systematic review. Sensors 2021, 21, 5134. [Google Scholar] [CrossRef] [PubMed]
- Palestra, G.; Rebiai, M.; Courtial, E.; Koutsouris, D. Evaluation of a rehabilitation system for the elderly in a day care center. Information 2018, 10, 3. [Google Scholar] [CrossRef] [Green Version]
- Khojasteh, S.B.; Villar, J.R.; Chira, C.; González, V.M.; De la Cal, E. Improving fall detection using an on-wrist wearable accelerometer. Sensors 2018, 18, 1350. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Z.; Cao, Y.; Cui, L.; Song, J.; Zhao, G. A benchmark database and baseline evaluation for fall detection based on wearable sensors for the Internet of medical things platform. IEEE Access 2018, 6, 51286–51296. [Google Scholar] [CrossRef]
- Kwon, S.B.; Park, J.H.; Kwon, C.; Kong, H.J.; Hwang, J.Y.; Kim, H.C. An energy-efficient algorithm for classification of fall types using a wearable sensor. IEEE Access 2019, 7, 31321–31329. [Google Scholar] [CrossRef]
- Alarifi, A.; Alwadain, A. Killer heuristic optimized convolution neural network-based fall detection with wearable IoT sensor devices. Measurement 2021, 167, 108258. [Google Scholar] [CrossRef]
- Kavya, G.; CT, S.K.; Dhanush, C.; Kruthika, J. Human Fall Detection Using Video Surveillance. ACS J. Sci. Eng. 2021, 1, 1–10. [Google Scholar] [CrossRef]
- Jeong, S.; Kang, S.; Chun, I. Human-skeleton based fall-detection method using LSTM for manufacturing industries. In Proceedings of the 2019 34th International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC), Jeju Island, Korea, 23–26 June 2019; pp. 1–4. [Google Scholar]
- Guan, Z.; Li, S.; Cheng, Y.; Man, C.; Mao, W.; Wong, N.; Yu, H. A Video-based Fall Detection Network by Spatio-temporal Joint-point Model on Edge Devices. In Proceedings of the 2021 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 1–5 February 2021; pp. 422–427. [Google Scholar]
- Bogdan, K.; Kepski, M. Human fall detection on embedded platform using depth maps and wireless accelerometer. Comput. Methods Prog. Biomed. 2014, 117, 489–501. [Google Scholar] [CrossRef]
- Ramirez, H.; Velastin, S.A.; Meza, I.; Fabregas, E.; Makris, D.; Farias, G. Fall Detection and Activity Recognition Using Human Skeleton Features. IEEE Access 2021, 9, 33532–33542. [Google Scholar] [CrossRef]
- Martínez-Villaseñor, L.; Ponce, H.; Brieva, J.; Moya-Albor, E.; Núñez-Martínez, J.; Peñafort-Asturiano, C. UP-Fall Detection Dataset: A Multimodal Approach. Sensors 2019, 19, 1988. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ramirez, H.; Velastin, S.A.; Fabregas, E.; Meza, I.; Makris, D.; Farias, G. Fall detection using human skeleton features. In Proceedings of the 11th International Conference of Pattern Recognition Systems (ICPRS 2021), Online, 17–19 March 2021; pp. 73–78. [Google Scholar] [CrossRef]
- Khan, S.S.; Nogas, J.; Mihailidis, A. Spatio-temporal adversarial learning for detecting unseen falls. Pattern Anal. Appl. 2021, 24, 381–391. [Google Scholar] [CrossRef]
- Fan, Y.; Levine, M.D.; Wen, G.; Qiu, S. A deep neural network for real-time detection of falling humans in naturally occurring scenes. Neurocomputing 2017, 260, 43–58. [Google Scholar] [CrossRef]
- Taufeeque, M.; Koita, S.; Spicher, N.; Deserno, T.M. Multi-camera, multi-person, and real-time fall detection using long short term memory. In Medical Imaging 2021: Imaging Informatics for Healthcare, Research, and Applications; International Society for Optics and Photonics: Bellingham, WA, USA, 2021; Volume 11601, p. 1160109. [Google Scholar]
- Chen, Z.; Wang, Y. Infrared–ultrasonic sensor fusion for support vector machine–based fall detection. J. Intell. Mater. Syst. Struct. 2018, 29, 2027–2039. [Google Scholar] [CrossRef]
- De Miguel, K.; Brunete, A.; Hernando, M.; Gambao, E. Home camera-based fall detection system for the elderly. Sensors 2017, 17, 2864. [Google Scholar] [CrossRef] [Green Version]
- Agrawal, S.C.; Tripathi, R.K.; Jalal, A.S. Human-fall detection from an indoor video surveillance. In Proceedings of the 2017 8th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Delhi, India, 3–5 July 2017; pp. 1–5. [Google Scholar]
- Chhetri, S.; Alsadoon, A.; Al-Dala’in, T.; Prasad, P.; Rashid, T.A.; Maag, A. Deep learning for vision-based fall detection system: Enhanced optical dynamic flow. Comput. Intell. 2021, 37, 578–595. [Google Scholar] [CrossRef]
- Chen, G.; Duan, X. Vision-Based Elderly Fall Detection Algorithm for Mobile Robot. In Proceedings of the 2021 IEEE 4th International Conference on Electronics Technology (ICET), Chengdu, China, 7–10 May 2021; pp. 1197–1202. [Google Scholar]
- Cai, X.; Liu, X.; An, M.; Han, G. Vision-Based Fall Detection Using Dense Block With Multi-Channel Convolutional Fusion Strategy. IEEE Access 2021, 9, 18318–18325. [Google Scholar] [CrossRef]
- Sultana, A.; Deb, K.; Dhar, P.K.; Koshiba, T. Classification of indoor human fall events using deep learning. Entropy 2021, 23, 328. [Google Scholar] [CrossRef]
- Leite, G.V.; da Silva, G.P.; Pedrini, H. Three-stream convolutional neural network for human fall detection. In Deep Learning Applications; Springer: Berlin/Heidelberg, Germany, 2021; Volume 2, pp. 49–80. [Google Scholar]
- Shu, F.; Shu, J. An eight-camera fall detection system using human fall pattern recognition via machine learning by a low-cost android box. Sci. Rep. 2021, 11, 1–17. [Google Scholar] [CrossRef]
- Keskes, O.; Noumeir, R. Vision-based fall detection using ST-GCN. IEEE Access 2021, 9, 28224–28236. [Google Scholar] [CrossRef]
- Tran, T.H.; Nguyen, D.T.; Nguyen, T.P. Human Posture Classification from Multiple Viewpoints and Application for Fall Detection. In Proceedings of the 2020 IEEE Eighth International Conference on Communications and Electronics (ICCE), Phu Quoc, Vietnam, 13–15 January 2021; pp. 262–267. [Google Scholar]
- Hasib, R.; Khan, K.N.; Yu, M.; Khan, M.S. Vision-based Human Posture Classification and Fall Detection using Convolutional Neural Network. In Proceedings of the 2021 International Conference on Artificial Intelligence (ICAI), Islamabad, Pakistan, 5–7 April 2021; pp. 74–79. [Google Scholar]
- Nguyen, V.D.; Pham, P.N.; Nguyen, X.B.; Tran, T.M.; Nguyen, M.Q. Incorporation of Panoramic View in Fall Detection Using Omnidirectional Camera. In The International Conference on Intelligent Systems & Networks; Springer: Berlin/Heidelberg, Germany, 2021; pp. 313–318. [Google Scholar]
- Berlin, S.J.; John, M. Vision based human fall detection with Siamese convolutional neural networks. J. Ambient. Intell. Humaniz. Comput. 2021, 2021, 1–12. [Google Scholar] [CrossRef]
- Galvão, Y.M.; Portela, L.; Ferreira, J.; Barros, P.; De Araújo Fagundes, O.A.; Fernandes, B.J.T. A Framework for Anomaly Identification Applied on Fall Detection. IEEE Access 2021, 9, 77264–77274. [Google Scholar] [CrossRef]
- Kang, Y.K.; Kang, H.Y.; Weon, D.S. Human Skeleton Keypoints based Fall Detection using GRU. J. Korea Acad.-Ind. Coop. Soc. 2021, 22, 127–133. [Google Scholar]
- Lin, C.B.; Dong, Z.; Kuan, W.K.; Huang, Y.F. A Framework for Fall Detection Based on OpenPose Skeleton and LSTM/GRU Models. Appl. Sci. 2021, 11, 329. [Google Scholar] [CrossRef]
- Dentamaro, V.; Impedovo, D.; Pirlo, G. Fall Detection by Human Pose Estimation and Kinematic Theory. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 2328–2335. [Google Scholar]
- Chang, W.J.; Hsu, C.H.; Chen, L.B. A Pose Estimation-based Fall Detection Methodology Using Artificial Intelligence Edge Computing. IEEE Access 2021, 9, 129965–129976. [Google Scholar] [CrossRef]
- Kang, Y.k.; Kang, H.Y.; Kim, J.B. A Study of Fall Detection System Using Context Cognition Method. In Proceedings of the 2021 21st ACIS International Winter Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD-Winter), Ho Chi Minh City, Vietnam, 28–30 January 2021; pp. 79–83. [Google Scholar]
- Apicella, A.; Snidaro, L. Deep Neural Networks for real-time remote fall detection. In Proceedings of the International Conference on Pattern Recognition, Virtual, 10–15 January 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 188–201. [Google Scholar]
- Liu, C.; Lv, J.; Zhao, X.; Li, Z.; Yan, Z.; Shi, X. A Novel Key Point Trajectory Model for Fall Detection from RGB-D Videos. In Proceedings of the 2021 IEEE 24th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Dalian, China, 5–7 May 2021; pp. 1021–1026. [Google Scholar]
- Kang, Y.; Kang, H.; Kim, J. Fall Detection Method Based on Pose Estimation Using GRU. In Proceedings of the International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing, Hochimin City, Vietnam, 28–30 January 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 169–179. [Google Scholar]
- Varshney, N.; Bakariya, B.; Kushwaha, A.K.S.; Khare, M. Rule-based multi-view human activity recognition system in real time using skeleton data from RGB-D sensor. Soft Comput. 2021, 2021, 1–17. [Google Scholar] [CrossRef]
- Zhu, H.; Du, J.; Wang, L.; Han, B.; Jia, Y. A vision-based fall detection framework for the elderly in a room environment using motion features and DAG-SVM. Int. J. Comput. Appl. 2021, 2021, 1–9. [Google Scholar] [CrossRef]
- Wang, K.; Li, X.; Yang, J.; Wu, J.; Li, R. Temporal action detection based on two-stream You Only Look Once network for elderly care service robot. Int. J. Adv. Robot. Syst. 2021, 18, 17298814211038342. [Google Scholar] [CrossRef]
- Zhu, N.; Zhao, G.; Zhang, X.; Jin, Z. Falling motion detection algorithm based on deep learning. IET Image Process. 2021. [Google Scholar] [CrossRef]
- Yin, J.; Han, J.; Xie, R.; Wang, C.; Duan, X.; Rong, Y.; Zeng, X.; Tao, J. MC-LSTM: Real-Time 3D Human Action Detection System for Intelligent Healthcare Applications. IEEE Trans. Biomed. Circ. Syst. 2021, 15, 259–269. [Google Scholar] [CrossRef]
- Ma, X.; Wang, H.; Xue, B.; Zhou, M.; Ji, B.; Li, Y. Depth-based human fall detection via shape features and improved extreme learning machine. IEEE J. Biomed. Health Inform. 2014, 18, 1915–1922. [Google Scholar] [CrossRef] [PubMed]
- Aziz, O.; Musngi, M.; Park, E.J.; Mori, G.; Robinovitch, S.N. A comparison of accuracy of fall detection algorithms (threshold-based vs. machine learning) using waist-mounted tri-axial accelerometer signals from a comprehensive set of falls and non-fall trials. Med. Biol. Eng. Comput. 2017, 55, 45–55. [Google Scholar] [CrossRef] [PubMed]
- Tran, T.H.; Le, T.L.; Pham, D.T.; Hoang, V.N.; Khong, V.M.; Tran, Q.T.; Nguyen, T.S.; Pham, C. A multi-modal multi-view dataset for human fall analysis and preliminary investigation on modality. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1947–1952. [Google Scholar] [CrossRef]
- Adhikari, K.; Bouchachia, H.; Nait-Charif, H. Activity recognition for indoor fall detection using convolutional neural network. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; pp. 81–84. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Hu, Y.; Li, Y.; Song, S.; Liu, J. PKU-MMD: A large scale benchmark for continuous multi-modal human action understanding. arXiv 2017, arXiv:1703.07475. [Google Scholar]
- Yu, X.; Jang, J.; Xiong, S. A Large-Scale Open Motion Dataset (KFall) and Benchmark Algorithms for Detecting Pre-impact Fall of the Elderly Using Wearable Inertial Sensors. Front. Aging Neurosci. 2021, 2021, 399. [Google Scholar] [CrossRef] [PubMed]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2334–2343. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Multi Activity | Skeleton | Sequence | Cam RGB | Model | Dataset |
|---|---|---|---|---|---|---|
| [21] | X | X | ✓ | ✓ | CNN | UR-Fall |
| [22] | X | X | ✓ | ✓ | NanoDet-Lite | UR-Fall |
| [23] | X | X | ✓ | ✓ | MCCF | UR-Fall |
| [24] | X | X | ✓ | Depth | 2D CNN-GRU | UR-Fall |
| [25] | X | X | ✓ | Depth | CNN-SVM | UR-Fall |
| [26] | X | X | ✓ | Depth | RVM | own |
| [27] | X | X | ✓ | Depth | ST-GCN | TST-Fall |
| [28] | X | X | X | ✓ | CNN-YOLO | CMD-Fall |
| [29] | X | X | X | ✓ | CNN | own |
| [30] | X | X | X | ✓ | KNN-SVM | BOMNI |
| [31] | X | X | X | ✓ | CNN | own |
| [17] | X | own | ✓ | ✓ | LSTM | UP-Fall |
| [32] | X | own | ✓ | ✓ | AutoEncoder | UP-Fall |
| [10] | X | OpenPose | ✓ | ✓ | LSTM | UR-Fall |
| [33] | X | PoseNet | ✓ | ✓ | GRU | UR-Fall |
| [34] | X | OpenPose | ✓ | ✓ | LSTM-GRU | UR-Fall |
| [21] | X | OpenPose | ✓ | ✓ | SVM | UR-Fall |
| [35] | X | OpenPose | ✓ | ✓ | SVM | UR-Fall |
| [36] | X | OpenPose | ✓ | ✓ | LSTM | CMU |
| [37] | X | PoseNet | ✓ | ✓ | CNN | own |
| [38] | X | PoseNet | ✓ | ✓ | CNN-RNN | own |
| [39] | X | OpenPose | ✓ | Depth | RF | SDU-Fall |
| [40] | X | own | ✓ | ✓ | GRU | SDU-Fall |
| [41] | - | OpenPose | ✓ | - | - | - |
| [14] | X | AlphaPose | X | ✓ | KNN | UP-Fall |
| [42] | ✓(5) | X | X | ✓ | DAG-SVM | own |
| [43] | ✓(7) | Yolo v3 | ✓ | ✓ | 3D CNN | PKU-MMD |
| [44] | ✓(4) | OpenPose | ✓ | Depth | DNN | FDD |
| [45] | ✓(8) | own | ✓ | Depth | MC-LSTM | TST-Fall |
| [12] | ✓(12) | AlphaPose | X | ✓ | RF-SVM MLP-KNN | UP-Fall |
| Dataset | Fall Types | Other Activities | Trials | ML Method | Performance |
|---|---|---|---|---|---|
| SDUFall [46] | Fall to the floor | Sitting, walking, squatting, lying, bending | 6 actions 10 times | Bag of words model built upon curvature scale space features | Accuracy: , Sensitivity , Specificity |
| SFU-IMU [47] | 15 types of falls | Walking, Standing, Rising, Ascending stairs, Picking up an object | 3 repetitions | SVM | Sensitivity , Specificity |
| UR-Fall [11] | From standing, from sitting on a chair | Lying, walking, sitting down, crouching down | 70 sequences | SVM | Accuracy: , Precision , Sensitivity , Specificity |
| CMD-FALL [48] | While walking, lying on the bed, sitting on the chair | Horizontal movement | 20 actions | CNN: Res-TCN | F1-Score (Activity): , F1-Score (Fall): |
| Fall-Dataset [49] | Fall to the floor | Standing, sitting, lying, bending and crawling | CNN | Accuracy: | |
| PKU-MMD [50] | Drinking, waving hand, putting on the glassed, hugging, shaking... | 6 sequences | RNN SVM LSTM | -Score: | |
| K-Fall [51] | 15 types of falls | 21 types of activities | Conv-LSTM | Accuracy: , Recall: | |
| UP-Fall [13] | Forward using hands, forward using knees, backward, sideward, sitting | Walking, standing, sitting, picking up an object, jumping, laying, kneeling down | 3 repetitions | RF SVM MLP KNN | Accuracy: |
| Performance Ramirez et al. [12] | |||||
| Model | Accuracy (%) | Precision (%) | Recall (%) | Specificity (%) | -Score (%) |
| RF | 99.34 ± 0.03 | 98.23 ± 0.17 | 98.82 ± 0.10 | 99.48 ± 0.05 | 98.52 ± 0.08 |
| SVM | 98.81 ± 0.07 | 98.15 ± 0.19 | 96.50 ± 0.27 | 99.47 ± 0.05 | 97.32 ± 0.17 |
| MLP | 97.39 ± 0.10 | 93.87 ± 0.85 | 94.57 ± 1.15 | 98.21 ± 0.29 | 94.21 ± 0.27 |
| KNN | 98.84 ± 0.06 | 97.53 ± 0.15 | 97.30 ± 0.24 | 99.29 ± 0.04 | 97.41 ± 0.16 |
| Performance of the Proposed Method | |||||
| Model | Accuracy (%) | Precision (%) | Recall (%) | Specificity (%) | -Score (%) |
| RF | 99.81 ± 0.04 | 99.30 ± 0.17 | 99.81 ± 0.07 | 99.81 ± 0.05 | 99.56 ± 0.09 |
| SVM | 93.37 ± 0.15 | 99.76 ± 0.05 | 69.12 ± 0.80 | 99.95 ± 0.01 | 81.66 ± 0.57 |
| MLP | 98.95 ± 0.14 | 97.62 ± 0.49 | 97.47 ± 0.86 | 99.35 ± 0.14 | 97.54 ± 0.33 |
| KNN | 99.69 ± 0.04 | 99.17 ± 0.18 | 99.39 ± 0.12 | 99.77 ± 0.05 | 99.28 ± 0.10 |
| AdaBoost | 99.71 ± 0.04 | 99.11 ± 0.14 | 99.52 ± 0.11 | 99.76 ± 0.04 | 99.31 ± 0.10 |
| Methods | Dataset | CAM | Skeleton Sequences | Accuracy |
|---|---|---|---|---|
| Taufeeque et al. [17] | UP-Fall | RGB | ✓ | 98.28% |
| Galvão et al. [32] | UP-Fall | RGB | ✓ | 98.62% |
| Ramirez et al. [12] | UP-Fall | RGB | X | 99.34% |
| Our method | UP-Fall | RGB | ✓ | 99.81% |
| Performance in Ramirez et al. [12] | |||||
| Model | Accuracy (%) | Precision (%) | Recall (%) | Specificity (%) | -Score (%) |
| RF | 99.45 ± 1.02 | 96.60 ± 0.48 | 88.99 ± 0.56 | 99.70 ± 0.50 | 92.34 ± 0.39 |
| SVM | 99.65 ± 0.01 | 93.85 ± 0.65 | 87.29 ± 0.83 | 99.79 ± 0.01 | 90.20 ± 0.59 |
| MLP | 98.93 ± 0.17 | 85.39 ± 1.69 | 71.44 ± 2.30 | 99.34 ± 0.11 | 75.95 ± 1.84 |
| KNN | 99.60 ± 0.01 | 91.65 ± 0.55 | 84.17 ± 0.81 | 99.76 ± 0.01 | 87.35 ± 0.63 |
| Performance of the Proposed Method | |||||
| Model | Accuracy (%) | Precision (%) | Recall (%) | Specificity (%) | -Score (%) |
| RF | 99.91 ± 0.01 | 97.73 ± 0.28 | 95.60 ± 0.39 | 99.95 ± 0.01 | 96.63 ± 0.33 |
| SVM | 98.60 ± 0.04 | 95.60 ± 0.67 | 57.40 ± 0.60 | 99.14 ± 0.02 | 62.87 ± 0.81 |
| MLP | 99.28 ± 0.17 | 82.71 ± 2.23 | 78.97 ± 2.01 | 99.58 ± 0.10 | 79.89 ± 1.96 |
| KNN | 99.81 ± 0.01 | 92.49 ± 0.40 | 91.50 ± 0.37 | 99.89 ± 0.01 | 91.95 ± 0.35 |
| AdaBoost | 99.81 ± 0.03 | 95.53 ± 0.50 | 92.56 ± 0.38 | 99.89 ± 0.02 | 93.97 ± 0.39 |
| Methods | Dataset | CAM | Activities | Skeleton Sequences | Accuracy |
|---|---|---|---|---|---|
| Wang et al. [43] | PKU-MMD | RGB | 7 | ✓ | 95.00% |
| Zhu et al. [44] | FDD | Depth | 4 | ✓ | 99.04% |
| Yin et al. [45] | TST-Fall | Depth | 8 | ✓ | 93.90% |
| Ramirez et al. [12] | UP-Fall | RGB | 12 | X | 99.65% |
| Our method | UP-Fall | RGB | 12 | ✓ | 99.91% |
| Performance in Ramirez et al. [12] | |||||
| Model | Accuracy (%) | Precision (%) | Recall (%) | Specificity (%) | -Score (%) |
| RF | 99.11 ± 0.43 | 99.18 ± 0.59 | 97.53 ± 1.81 | 99.71 ± 0.21 | 98.34 ± 0.80 |
| SVM | 98.60 ± 0.30 | 96.50 ± 0.88 | 98.37 ± 0.88 | 98.69 ± 0.32 | 97.42 ± 0.60 |
| MLP | 90.79 ± 4.14 | 86.63 ± 13.60 | 83.06 ± 11.61 | 93.69 ± 8.15 | 83.19 ± 5.55 |
| KNN | 98.88 ± 0.31 | 98.41 ± 0.96 | 97.41 ± 1.11 | 99.43 ± 0.33 | 97.90 ± 0.60 |
| AdaBoost | 98.95 ± 0.31 | 98.42 ± 0.98 | 97.67 ± 1.12 | 99.43 ± 0.34 | 98.04 ± 0.59 |
| Performance of the Proposed Method | |||||
| Model | Accuracy (%) | Precision (%) | Recall (%) | Specificity (%) | -Score (%) |
| RF | 99.51 ± 0.33 | 99.35 ± 0.68 | 99.15 ± 0.71 | 99.69 ± 0.32 | 99.25 ± 0.51 |
| SVM | 96.39 ± 0.92 | 90.60 ± 2.17 | 99.36 ± 0.55 | 94.94 ± 1.34 | 94.77 ± 1.23 |
| MLP | 92.18 ± 4.71 | 88.53 ± 8.62 | 89.42 ± 17.04 | 93.39 ± 5.82 | 87.39 ± 10.58 |
| KNN | 99.28 ± 0.39 | 98.88 ± 0.64 | 98.95 ± 0.84 | 99.45 ± 0.31 | 98.91 ± 0.58 |
| AdaBoost | 99.42 ± 0.34 | 99.25 ± 0.63 | 98.99 ± 0.80 | 99.64 ± 0.30 | 99.12 ± 0.52 |
| Methods | Dataset | CAM | Skeleton Sequences | Accuracy |
|---|---|---|---|---|
| Guan et al. [10] | UR-Fall | RGB | ✓ | 99.00% |
| Kang et al. [33] | UR-Fall | RGB | ✓ | 99.46% |
| Lin et al. [34] | UR-Fall | RGB | ✓ | 98.20% |
| Chhetri et al. [21] | UR-Fall | RGB | ✓ | 95.11% |
| Dentamaro et al. [35] | UR-Fall | RGB | ✓ | 99.00% |
| Ramirez et al. [12] | UR-Fall | RGB | X | 99.11% |
| Our method | UR-Fall | RGB | ✓ | 99.51% |
| Training and Validation Times [s] | |||
|---|---|---|---|
| Model | Fall Detection with UP-Fall | Activity Recognition with UP-Fall | Fall Detection with UR-Fall |
| RF | 1644.32 | 2262.06 | 23.54 |
| SVM | 64,696.15 | 120,464.13 | 31.04 |
| MLP | 981.78 | 4913.33 | 317.17 |
| KNN | 376.60 | 439.88 | 1.23 |
| AdaBoost | 3148.76 | 3936.27 | 49.81 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramirez, H.; Velastin, S.A.; Aguayo, P.; Fabregas, E.; Farias, G. Human Activity Recognition by Sequences of Skeleton Features. Sensors 2022, 22, 3991. https://doi.org/10.3390/s22113991
Ramirez H, Velastin SA, Aguayo P, Fabregas E, Farias G. Human Activity Recognition by Sequences of Skeleton Features. Sensors. 2022; 22(11):3991. https://doi.org/10.3390/s22113991
Chicago/Turabian StyleRamirez, Heilym, Sergio A. Velastin, Paulo Aguayo, Ernesto Fabregas, and Gonzalo Farias. 2022. "Human Activity Recognition by Sequences of Skeleton Features" Sensors 22, no. 11: 3991. https://doi.org/10.3390/s22113991