
Application of Improved CycleGAN in Laser-Visible Face Image Translation


Abstract
:1. Introduction
2. Dataset Acquisition and Processing
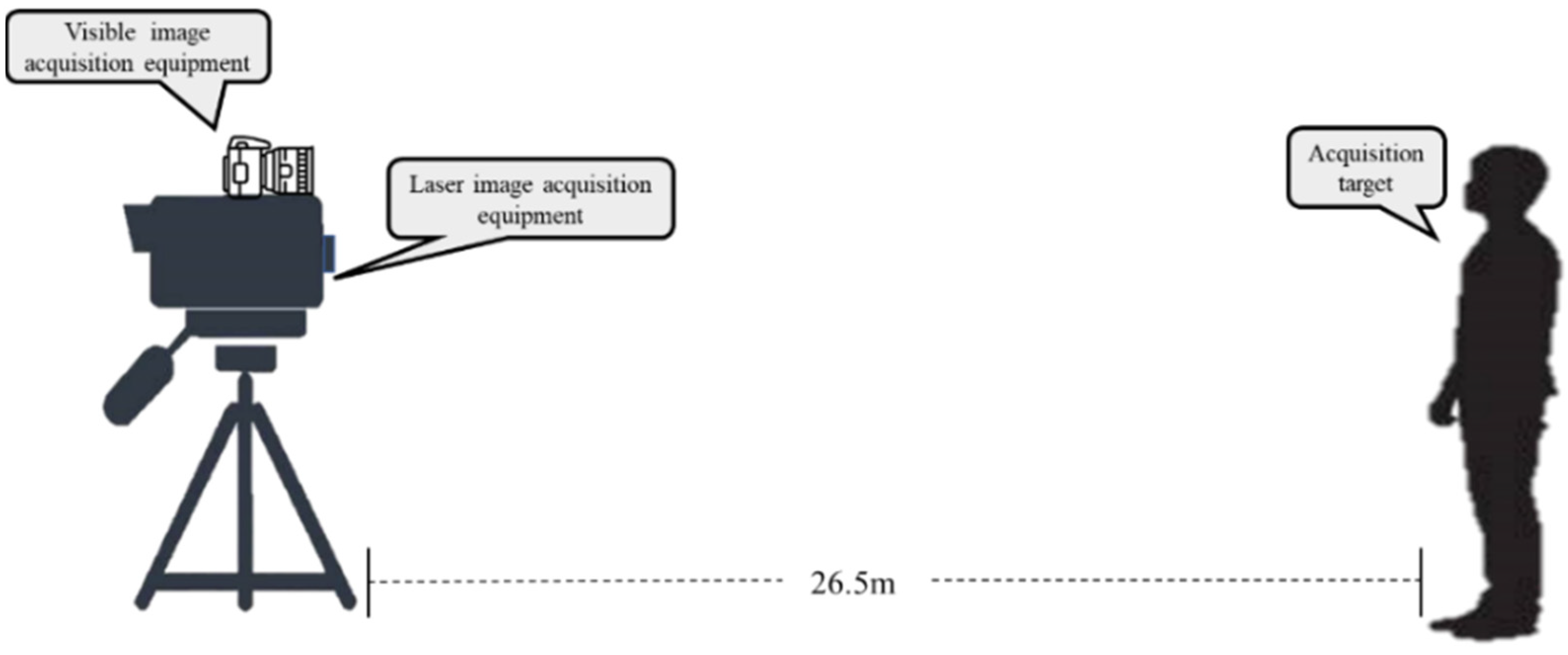
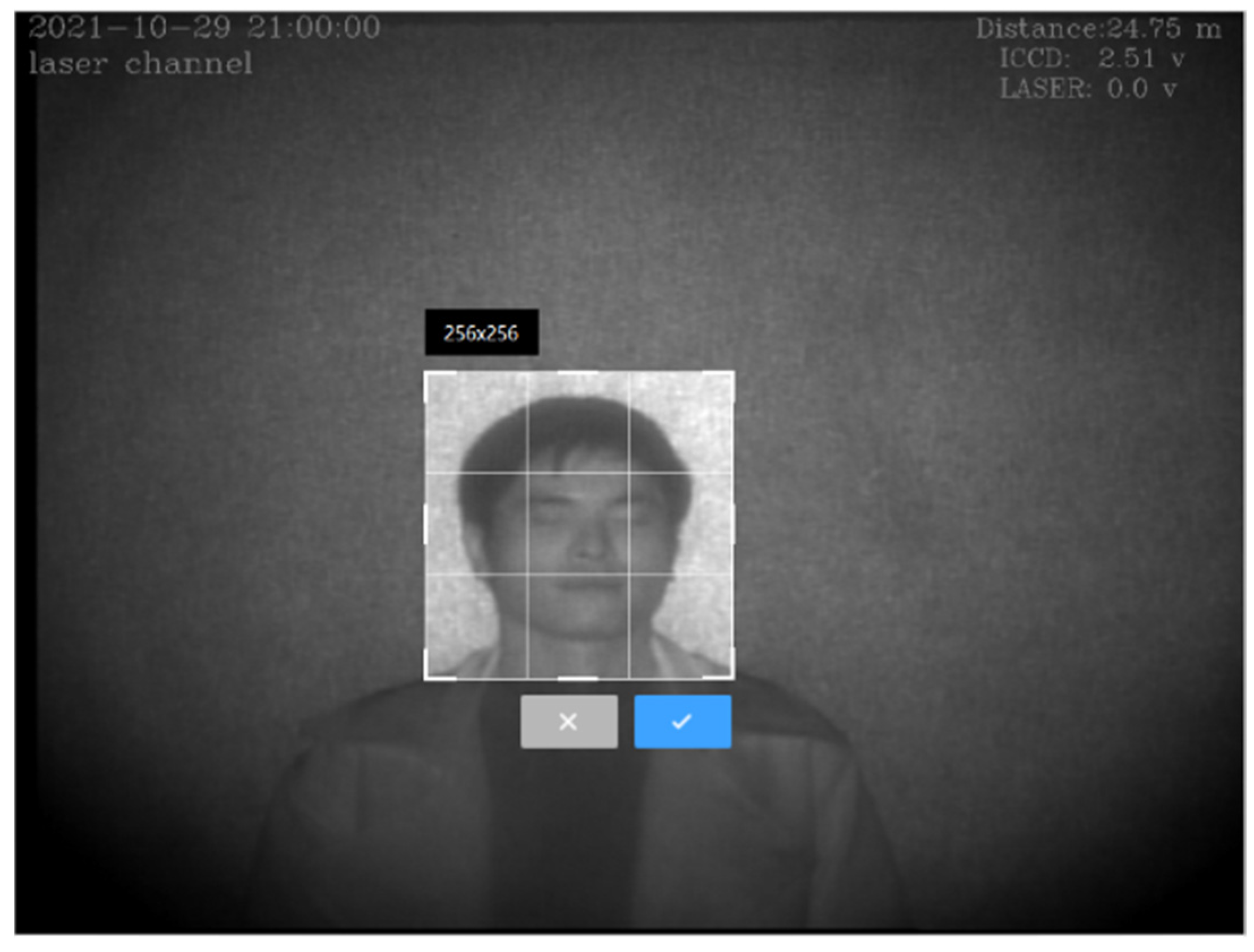
2.1. Data Acquisition
2.2. Data Processing
3. Image Translation with Generative Adversarial Network
3.1. Analysis of Generative Adversarial Networks Characteristics
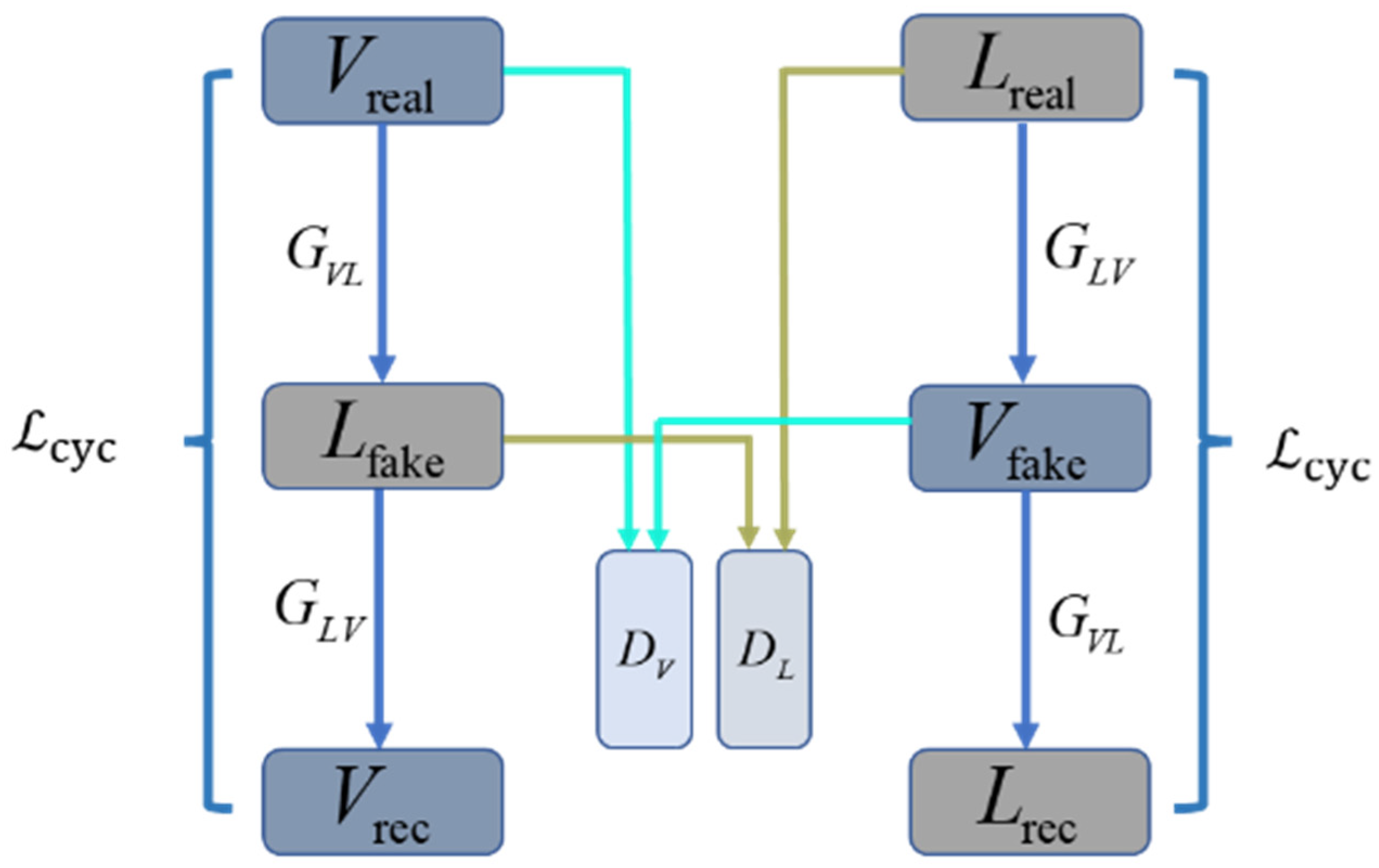
3.2. CycleGAN Model
3.3. Experimental Results and Analysis
4. Improved CycleGAN
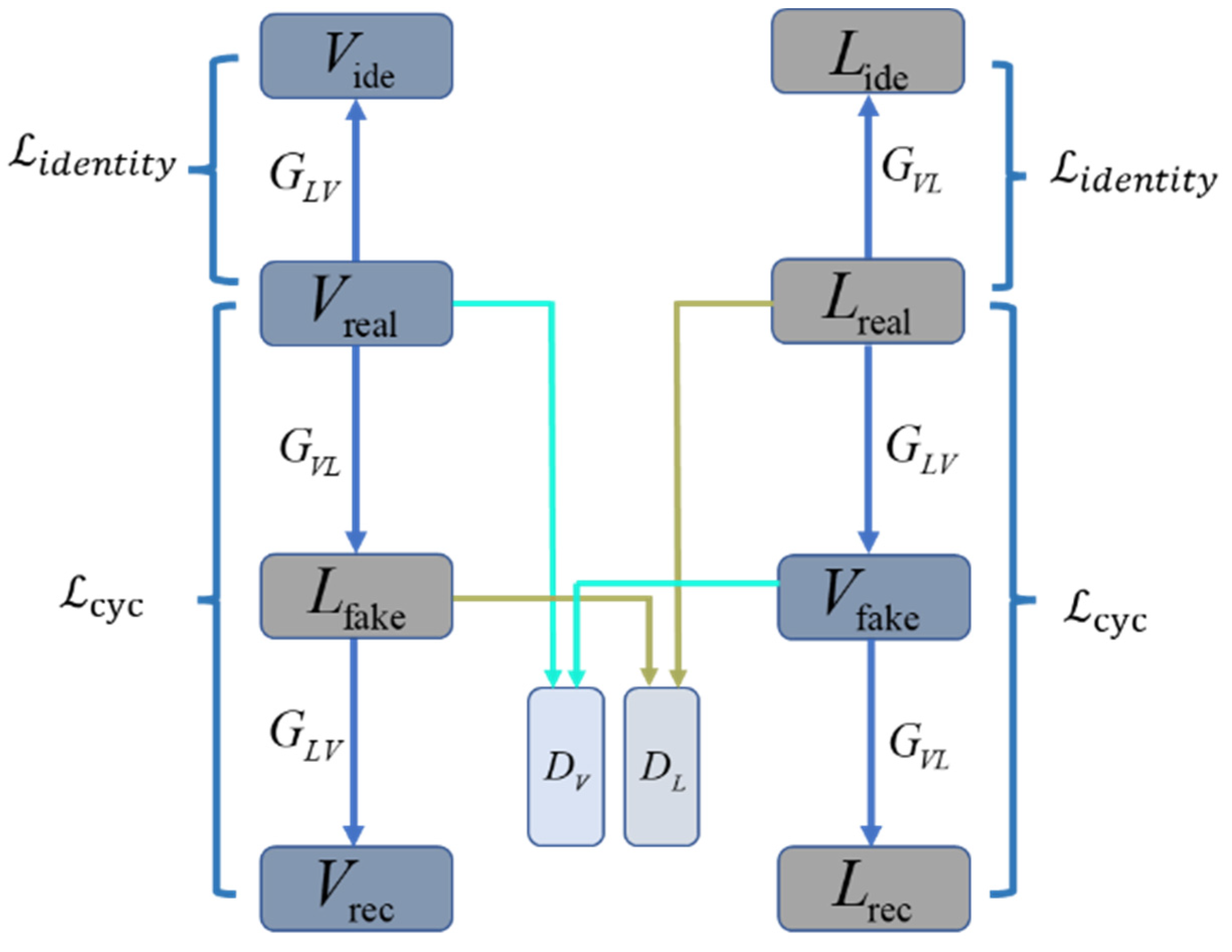
4.1. Improvement of the Adversarial Loss Objective Function
4.2. Add Identity Loss Function
4.3. Experimental Results and Analysis
5. Profile Image Translation
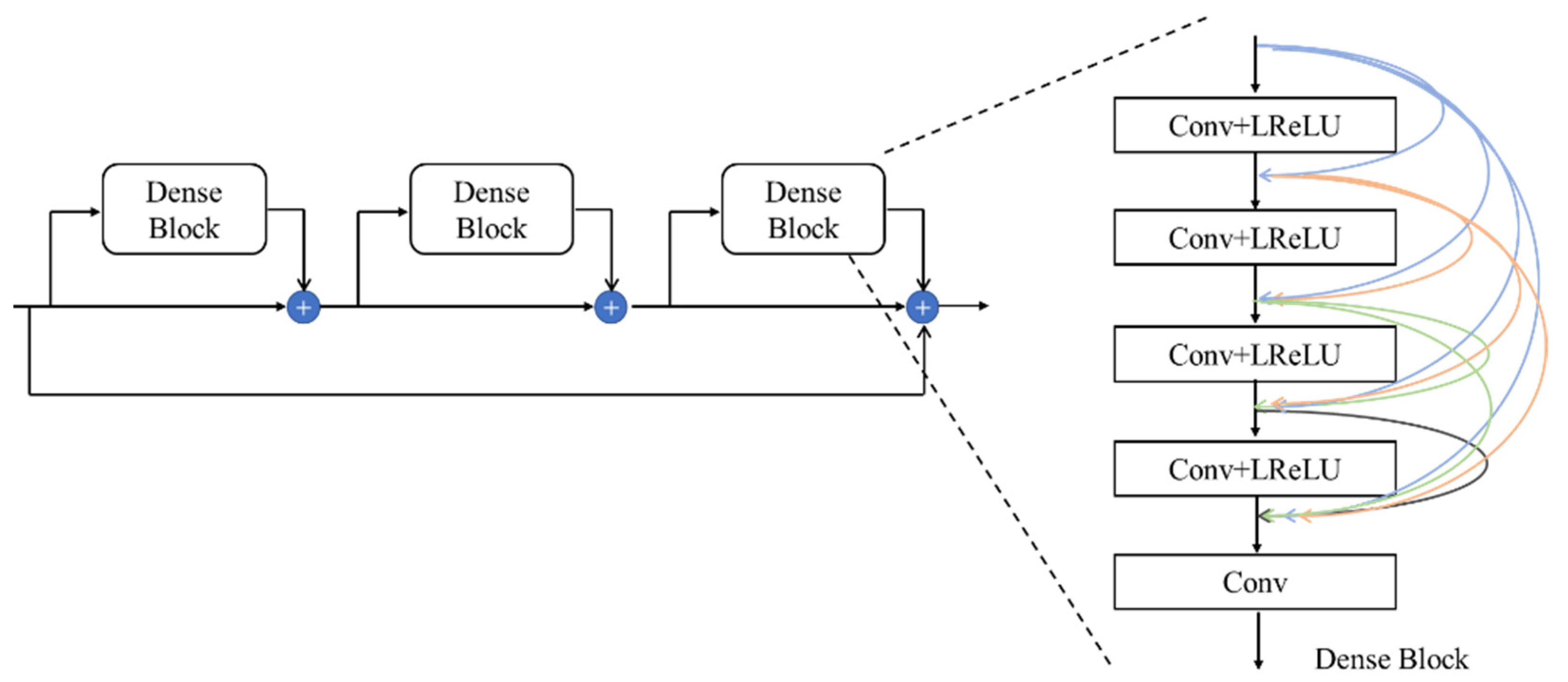
5.1. Improved Feature Extraction Part
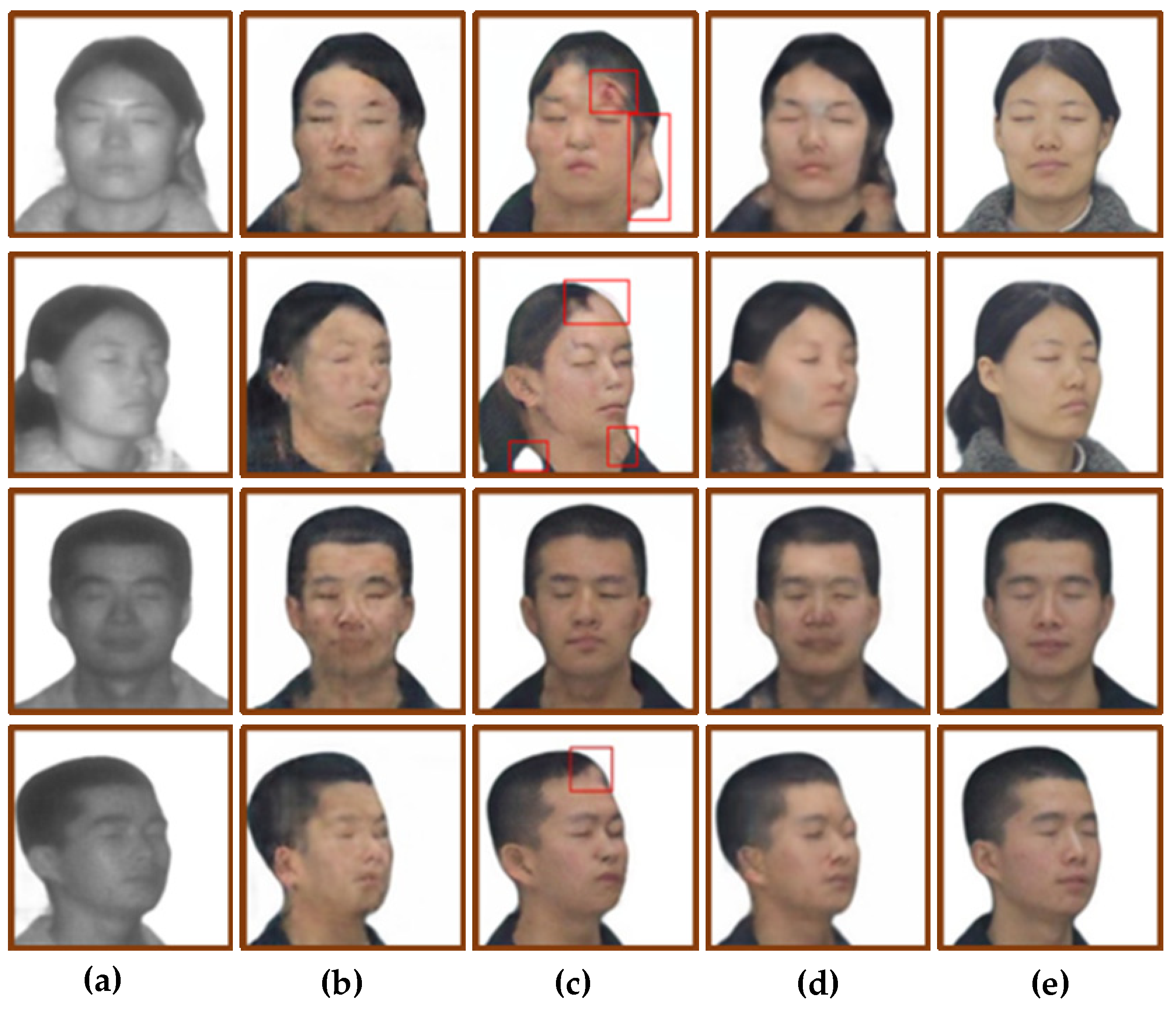
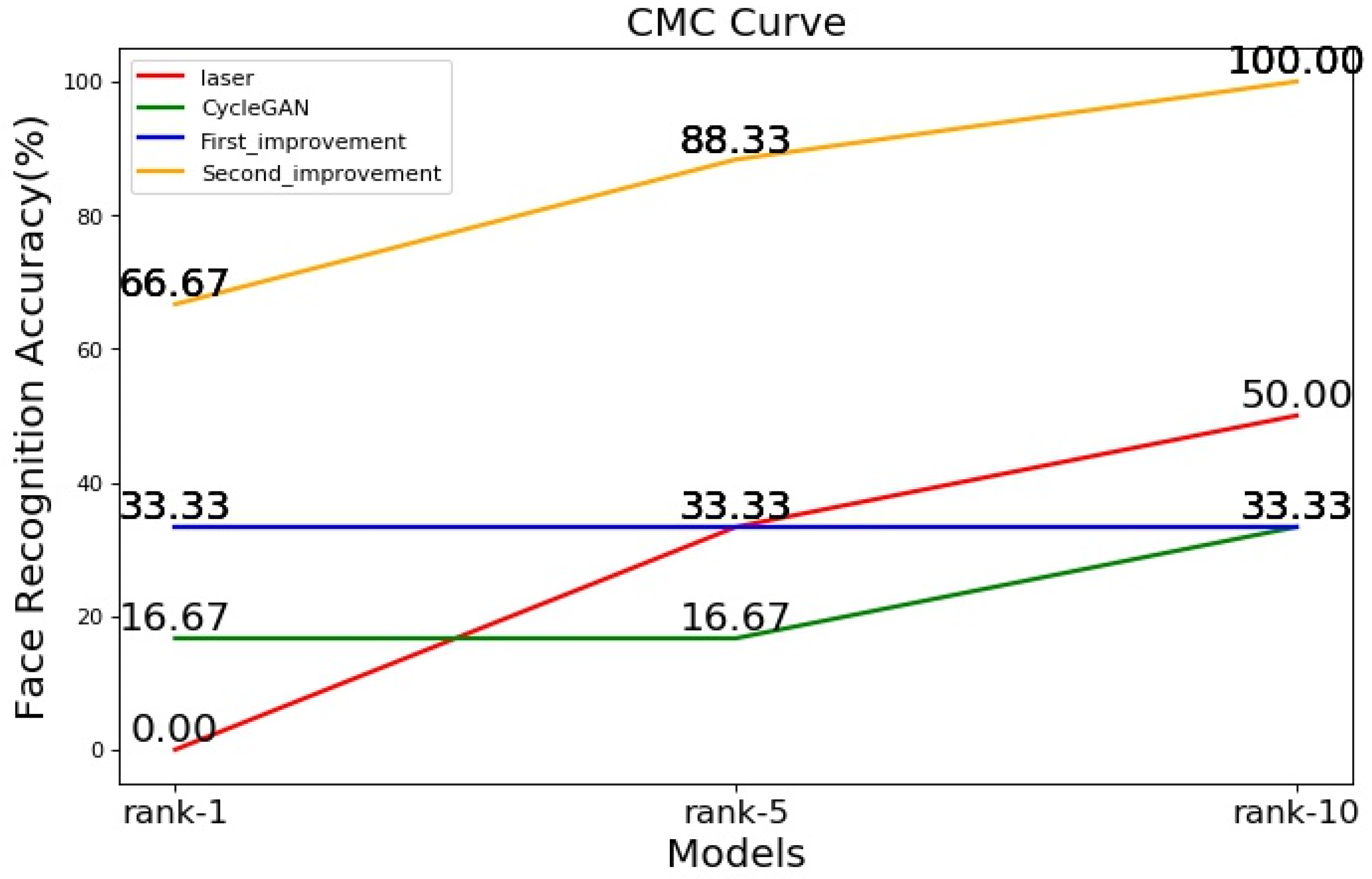
5.2. Experimental Results and Analysis
6. Conclusions
7. Prospect
7.1. High-Resolution Image Translation
7.2. Improve Face Recognition Accuracy
7.3. Others
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, Z. Research on Object Detection Based on Convolutional Neural Network under Laser Active Imaging. Master’s Thesis, University of Chinese Academy of Sciences, Beijing, China, 2021. [Google Scholar]
- Hu, L.; Zhang, Y. Facial Image Translation in Short-Wavelength Infrared and Visible Light Based on Generative Adversarial Network. Acta Optica Sinica. 2020, 40, 75–84. [Google Scholar]
- Goodfellow, I.; Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A Neural Algorithm of Artistic Style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8789–8797. [Google Scholar]
- Kim, J.; Kim, M.; Kang, H.; Lee, K. U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation. arXiv 2019, arXiv:1907.10830. [Google Scholar]
- Hu, L.M. Research on Key Technologies of Face Image Enhancement and Recognition Based on Shortwave-Infrared Imaging System. Ph.D. Thesis, University of Chinese Academy of Sciences, Beijing, China, 2020. [Google Scholar]
- Xu, J.; Lu, K.; Shi, X.; Qin, S.; Wang, H.; Ma, J. A DenseUnet generative adversarial network for near-infrared face image colorization. Signal Process. 2021, 183, 108007–108016. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Wang, Y.; Lu, H. Densely connected deconvolutional network for semantic segmentation. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3085–3089. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Shen, F.P. Measurements and Calculations of Important Safe Parameters for Lasers in Medicine. Stand. Test. 2014, 21, 5. [Google Scholar]
- Pan, Q.J.; Yang, Y.; Guang, L.; Wang, Y. Eye safety analysis for 400~1400 nm pulsed lasers systems. Laser Infrared 2010, 40, 4. [Google Scholar]
- Huang, F. Heterogeneous Face Synthesis via Generative Adversarial Networks. Master’s Thesis, Hangzhou Dianzi University, Hangzhou, China, 2020. [Google Scholar]
- Jabbar, A.; Li, X.; Assam, M.; Khan, J.A.; Obayya, M.I.; Alkhonaini, M.A.; Al-Wesabi, F.N.; Assad, M. AFD-StackGAN: Automatic Mask Generation Network for Face De-Occlusion Using StackGAN. Sensors 2022, 22, 1747. [Google Scholar] [CrossRef] [PubMed]
- Jia, R.; Chen, X.; Li, T.; Cui, J.L. V2T-GAN: Three-Level Refined Light-Weight GAN with Cascaded Guidance for Visible-to-Thermal Translat. Sensors 2022, 22, 2219. [Google Scholar] [CrossRef] [PubMed]
- Zhou, W.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 6629–6640. [Google Scholar]
- Mao, X.D.; Li, Q.; Xie, H.R.; Lau, R.Y.; Wang, Z.; Smolley, S.P. Least Squares Generative Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2813–2821. [Google Scholar]
- Wang, X.T.; Yu, K.; Wu, S.X.; Gu, J.J.; Liu, Y.H.; Dong, C.; Qiao, Y.; Loy, C.C. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In Computer Vision-ECCV 2018 Workshops; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; pp. 63–79. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware or Software | Technical Parameter |
|---|---|
| Operating system | Windows 10 Home Chinese |
| GPU | NVIDIAGTX-3090 |
| CPU | Intel(R)Xeon(R)Silver4116 |
| Memory | 24 GB |
| Deep learning library | Pytorch 1.8.0 |
| Programming language | Python 3.7.6 |
| Method | SSIM | PSNR | FID | |
|---|---|---|---|---|
| Model | ||||
| CycleGAN | 0.80 | 15.27 | 124.56 | |
| Pix2pix | 0.75 | 13.55 | 126.19 | |
| U-GAN-IT | 0.81 | 15.97 | 156.71 | |
| StarGAN | 0.75 | 15.63 | 185.53 | |
| Method | SSIM | PSNR | FID | |
|---|---|---|---|---|
| Model | ||||
| CycleGAN | 0.80 | 15.27 | 124.56 | |
| Add identity loss | 0.79 | 15.14 | 119.02 | |
| Least squares loss | 0.81 | 15.85 | 115.03 | |
| Ours | 0.81 | 16.27 | 113.34 | |
| Method | SSIM | PSNR | FID | |
|---|---|---|---|---|
| Model | ||||
| CycleGAN | 0.76 | 12.60 | 186.10 | |
| Add identity loss | 0.76 | 12.67 | 165.12 | |
| Least squares loss | 0.77 | 13.36 | 145.59 | |
| Ours | 0.79 | 15.10 | 162.35 | |
| Method | SSIM | PSNR | FID | |
|---|---|---|---|---|
| Model | ||||
| CycleGAN | 0.80 | 15.27 | 124.56 | |
| First improvement | 0.81 | 16.27 | 113.34 | |
| Second improvement | 0.83 | 16.29 | 98.24 | |
| Method | SSIM | PSNR | FID | |
|---|---|---|---|---|
| Model | ||||
| CycleGAN | * 0.80/0.82 | * 15.27/13.23 | * 124.56/184.47 | |
| First Improvement CycleGAN | * 0.83/0.84 | * 16.29/14.85 | * 98.24/128.36 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, M.; Fan, Y.; Guo, H.; Wang, M. Application of Improved CycleGAN in Laser-Visible Face Image Translation. Sensors 2022, 22, 4057. https://doi.org/10.3390/s22114057
Qin M, Fan Y, Guo H, Wang M. Application of Improved CycleGAN in Laser-Visible Face Image Translation. Sensors. 2022; 22(11):4057. https://doi.org/10.3390/s22114057
Chicago/Turabian StyleQin, Mingyu, Youchen Fan, Huichao Guo, and Mingqian Wang. 2022. "Application of Improved CycleGAN in Laser-Visible Face Image Translation" Sensors 22, no. 11: 4057. https://doi.org/10.3390/s22114057
APA StyleQin, M., Fan, Y., Guo, H., & Wang, M. (2022). Application of Improved CycleGAN in Laser-Visible Face Image Translation. Sensors, 22(11), 4057. https://doi.org/10.3390/s22114057