1. Introduction
A current challenge related to industrial systems is transferring manufacturing processes to the Internet of Things (IoT) or cyber–physical systems (CPS), which means that objects and their virtual representation should be networked with others [
1]. The IoT is a network of physical objects embedded with sensors, software, and other technologies for the purpose of connecting and exchanging data with other devices and systems over the internet; it thus collects and shares data between smart devices to carry out data monitoring and control in cyber–physical systems (CPS). Artificial intelligence (AI) solutions applied to CPSs allow for machine learning (ML) inference on numerous data that can be acquired with ever-increasing accuracy, thanks to the possibility of training ML models with massive amounts of information generated by IoT devices [
2]. With the introduction of ML techniques in the Industry 4.0 paradigm, each industrial field can take advantage of real-time monitoring and control of the production processes, thanks to the effective data analysis and prediction enabled by these techniques. Combined with the development of IoT and data analysis technologies, CPS has massively increased the performance of industrial processes [
3].
The development of a digital environment, commonly known as a digital twin (DT) and envisioned as a replica of a physical system, is a valuable supporting technique for predicting system parameters and checking the effectiveness of a ML model. A DT describes a system in analytic form, with the aim of mirroring the effective status of its physical counterpart. CPS integration, data sharing, and system communication in a DT involve a series of tasks that have to mediate hardware reliability, model robustness, and secure, real-time data communications with low latency. Nevertheless, the hardware requirements, software developed, network infrastructure, communication protocols, and the data analysis chosen can affect the concrete usability of the developed DT.
In turn, ML techniques in industry have been applied successfully in various sectors, such as predictive maintenance, quality management, and zero-defect manufacturing [
4]. In the context of predictive maintenance, IoT sensors are typically used for collecting raw data that allow to monitor different operating parameters (such as temperature, pressure, product flow, etc.) of industrial machines during their functioning. These raw data can then be processed and analyzed using ML tools that, thanks to the training previously received, are typically able to discover an underlying relationship between the different parameters of the system. On the basis of said relationships and on the output predicted by the ML model, a decision maker can, for instance, understand if a part of the equipment must be replaced or forecast its probability of failure in the medium term [
5]. As the amount of data and case studies increase, ML techniques can improve their performance and provide more accurate predictions. This process can radically change the traditional way of organizing industrial maintenance; indeed, maintenance activities have been typically organized as interventions at regular time intervals, often without the opportunity of knowing the real conditions of the machines in advance. Such an approach, however, does not prevent the possibility of sudden failures of the plant, which in turn would lead to unplanned interventions and consequent production downtime. Besides predictive maintenance, ML systems can also be used in quality control to detect the possible defects of a final product, with a margin of error close to zero [
6]. ML has also been widely used in the field of anomaly detection [
7] due to its ease of use, and in the field of fault detection [
8]. In the field of predictive maintenance, Çınar et al. [
9] reviewed the ML approaches suitable for implementation when trying to minimize downtime and maximize the utilization rate and the useful life of equipment.
Although DT, IoT, and ML are all quite popular in literature, some research gaps remain for their practical application, and need to be addressed. First, the combined usage of DT, IoT, and ML is quite unexplored. Only a few architectures have been developed to integrate DT and ML techniques. For instance, neural networks (NN) have been integrated into a DT environment to evaluate surface roughness of a mill, using real-time data acquisition [
10]. Similarly, a DT driven by ML algorithms has been proposed by [
11] to be implemented in a petrochemical factory. These few studies have proposed an integrated software and hardware solution grounded on information and digital data exchange. As a second point, looking at real case applications, in the food industry there are just a few examples of practical implementation of ML algorithms. The multiple linear regression algorithm and support vector machine have been recently implemented in a dry system [
12], to predict the drying kinetics of a solar drier, or to perform quality control on fruits aided by NN [
13]. Once again, however, none of the analyzed studies has proposed a ML-driven DT model. On the contrary, in food plants, traditional control systems are typically used [
14], while DT models, which are more user friendly, are rarely available [
15]. For the same reason, applications of these tools for predicting machine anomalies in food plants also are lacking in the literature.
Based on these premises and on the gaps highlighted, this work aims to describe a straightforward solution for anomaly detection, suitable to be adopted in industrial plants not directly designed for Industry 4.0 applications. To be more precise, the basic idea of the manuscript is to delineate an approach for implementing various ML tools into a DT environment and applying them to a real plant. As such, this paper starts from two previous studies; in the first one, the DT environment was developed for the industrial plant under investigation [
16], while the second one discussed the results obtained with the DT for monitoring some selected plant parameters [
17]. This paper integrates the previous findings into an online tool, and at the same time, introduces the advancements achieved compared to the previous studies, thanks to the implementation of various ML algorithms. Indeed, because of the relatively small number of studies that have applied ML techniques to the area of anomaly detection, this study is exploratory in nature, and aims to evaluate the performance of different algorithms and search for the best solution for anomaly detection in a real plant. In line with this aim, three ML models were selected for implementation, choosing tools representative of various ML categories. In particular, the selected ML models reflect a supervised regressor (i.e., a multiple linear regression), a supervised classifier (a multi-layer perceptron), and an unsupervised algorithm (the k-means clustering).
The remainder of the paper is organized as follows.
Section 2 describes the materials and methods used in carrying out the research; these include the pilot plant, the procedure followed for data collection, and the ML algorithms developed.
Section 3 describes the testing procedure followed for evaluating the effectiveness of the proposed ML algorithms, both using the sample data and online data from the plant. Conclusions and future research directions are discussed in
Section 4.
2. Materials and Methods
2.1. Pilot Plant
The system under examination is a pilot plant that consists of a pasteurization system equipped with a counter-flow tube-in-tube heat exchanger used for pre-heating fluid foods (process fluids) via the transfer of heat by water (service fluid), in turn, pre-heated with steam provided by a steam generator. This latter part is able to provide heated steam at up to 11 bar, while the pasteurization system can process up to 5 m
3/h of product. For this plant, a DT model was developed and tested in previous studies [
16,
18].
A set of probes mounted on the pasteurization system provide an analog signal via a current loop of 4–20 mA, useful for describing the machine status by monitoring the product flow and the pressure at the inlet and outlet of the heat exchanger. Due to the low pressure generated by the fluid, some precision probes have been installed on the plant (model S11 manufactured by Wika, Klingenberg, Germany;
www.wika.com, accessed on 1 March 2022); these probes are designed for being used with viscous fluids, which would occlude the probe channel.
Table 1 reports the main characteristics and models of the sensors installed. All the sensors have a response time of less than 2 ms, a high accuracy evaluated in 0.5% of the span (i.e., the difference between the lowest and the actual output signal), and a non-linearity lower than 0.2% of the best-fit straight line.
For measuring the flow of products with possible pieces, a mass flowmeter (model Optimass manufactured by Krohne, Duisburg, Germany;
https://krohne.com/en, accessed on 1 March 2022) was installed after a twin-screw pump (manufactured by Bornemann, Obernkirchen, Germany,
https://www.bornemann.com, accessed on 1 March 2022). The chosen sensor has an accuracy of ±0.15% of the measured flow rate.
2.2. System Architecture
In line with the aim of this study, as previously mentioned, this paper proposes the integration of ML tools into a DT environment, which models the functioning of the system detailed above.
The DT model developed consists of:
A physical layer, which includes the pilot plant, the hardware for data acquisition and signal generation, and a wireless adapter.
A digital layer developed using LabVIEW software and Python language. LabVIEW, in turn, makes use of two software development environments. The first one, called “front panel”, reflects the human–machine interface (HMI) in which the user can monitor the system, change the input parameters, and generate the output signals. The second, called “block diagram”, is the background of the software; it is coded in G-language and is embodied in the so-called virtual instruments.
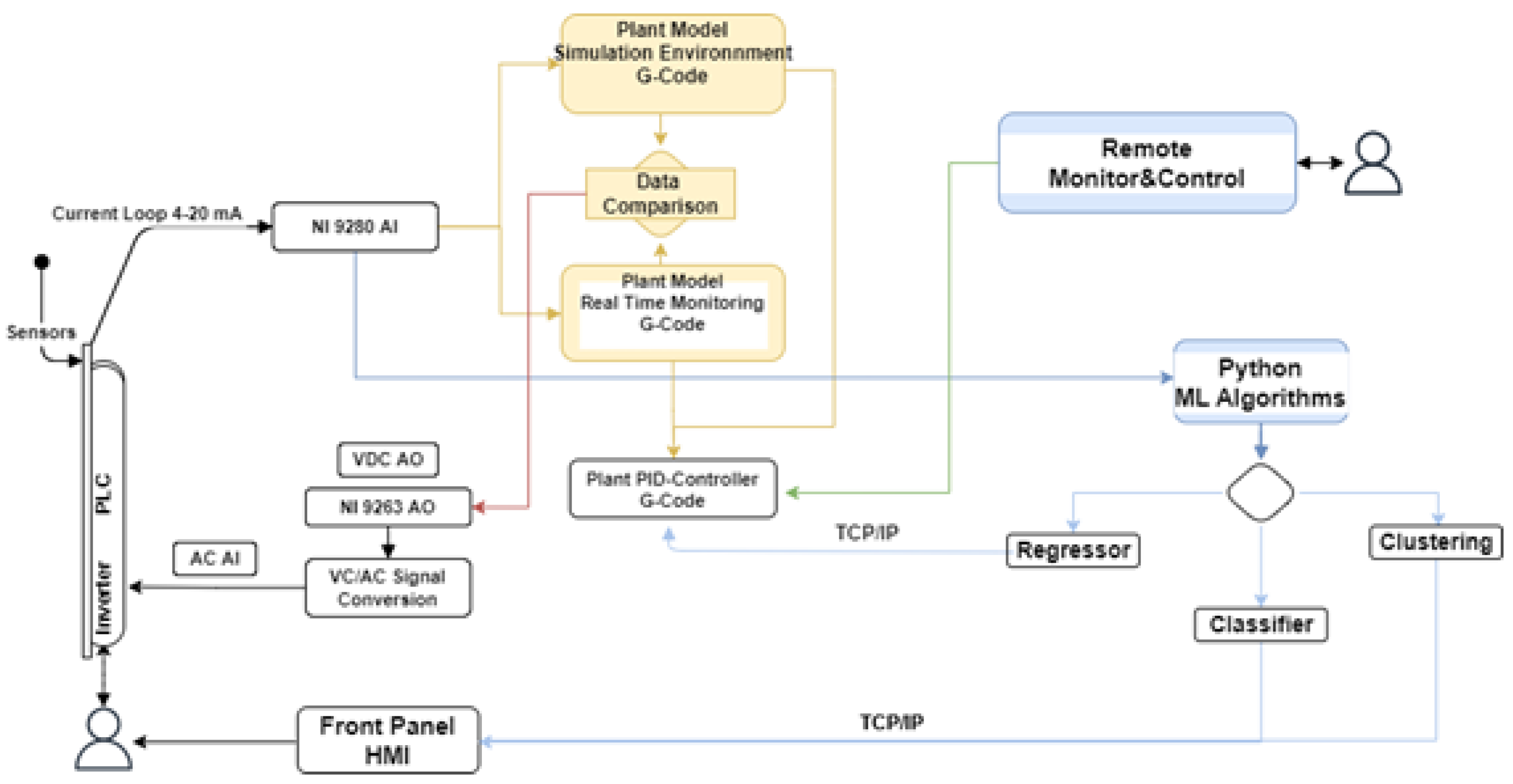
The overall architecture of the solution developed, highlighting the integration of ML and DT, is proposed in
Figure 1.
As can be seen from
Figure 1, the system can work in four different modes. The first scenario involves the usage of the system as a “Plant model simulation environment”. This basically means that the equations implemented in DT model are used to reproduce the physical properties of a product as a function of its flow and temperature, and evaluate, as output, the heat exchanger pressure drop on the basis of the geometry of the pasteurization system and the rheological properties of the fluid. Using this tool, the user can simulate the machine status by varying the process parameters, and if needed, trigger an analog signal by adjusting the analog voltage output or the proportional–integral–derivative (PID) controller setpoint. The second functionality refers to a fully automated condition called “Real-time monitoring”, in which the signals are directly acquired from the plant sensors. On the basis of the signals acquired and on the manual adjustment of the PID setpoint, the digital environment returns an analog output to drive the motor pump and control the product flow. Then, using the “Data comparison” tool, the system can trigger an analog output signal by comparing the pressure drop analytically computed via DT with the one evaluated by the signal acquired, and adjusts the product flow according to the current machine status. The third setting, labeled, “Remote monitor and control”, allows for controlling the machine status and generating a voltage output via remote connection to the digital environment. Finally, the fourth mode assumes an ML-based algorithm is embodied in the system and developed to drive the motor pump autonomously, or to display a message on the front panel, i.e., the HMI of the pilot plant. This environment, which will be referred to as “ML algorithm”, has been built with the combined usage of Python and G-Code (see
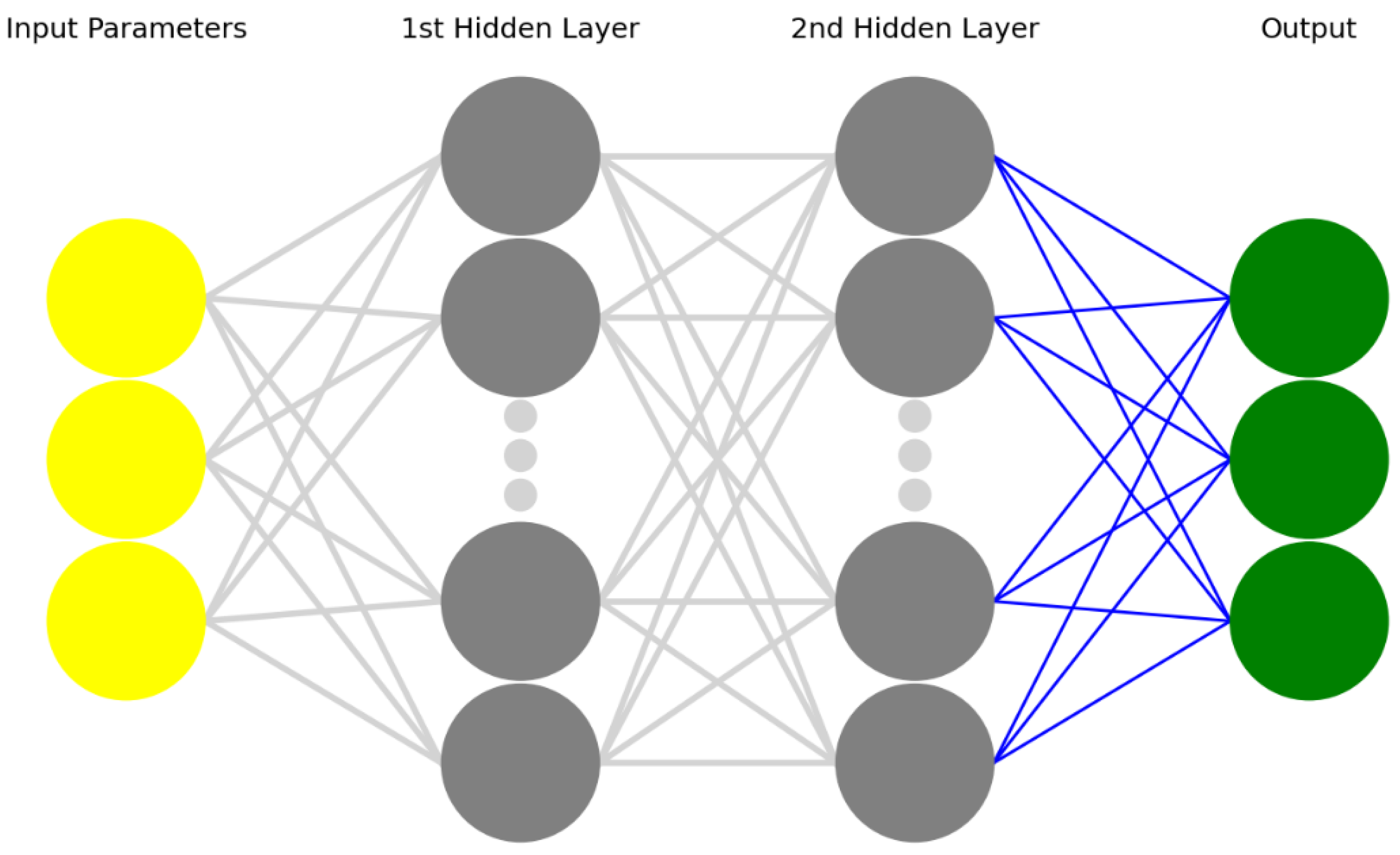
Figure 1). In an attempt to evaluate various solutions, their performance, and their capability for providing useful information to the user, three ML models have been implemented, namely, a linear regressor, a classifier, and a clustering algorithm.
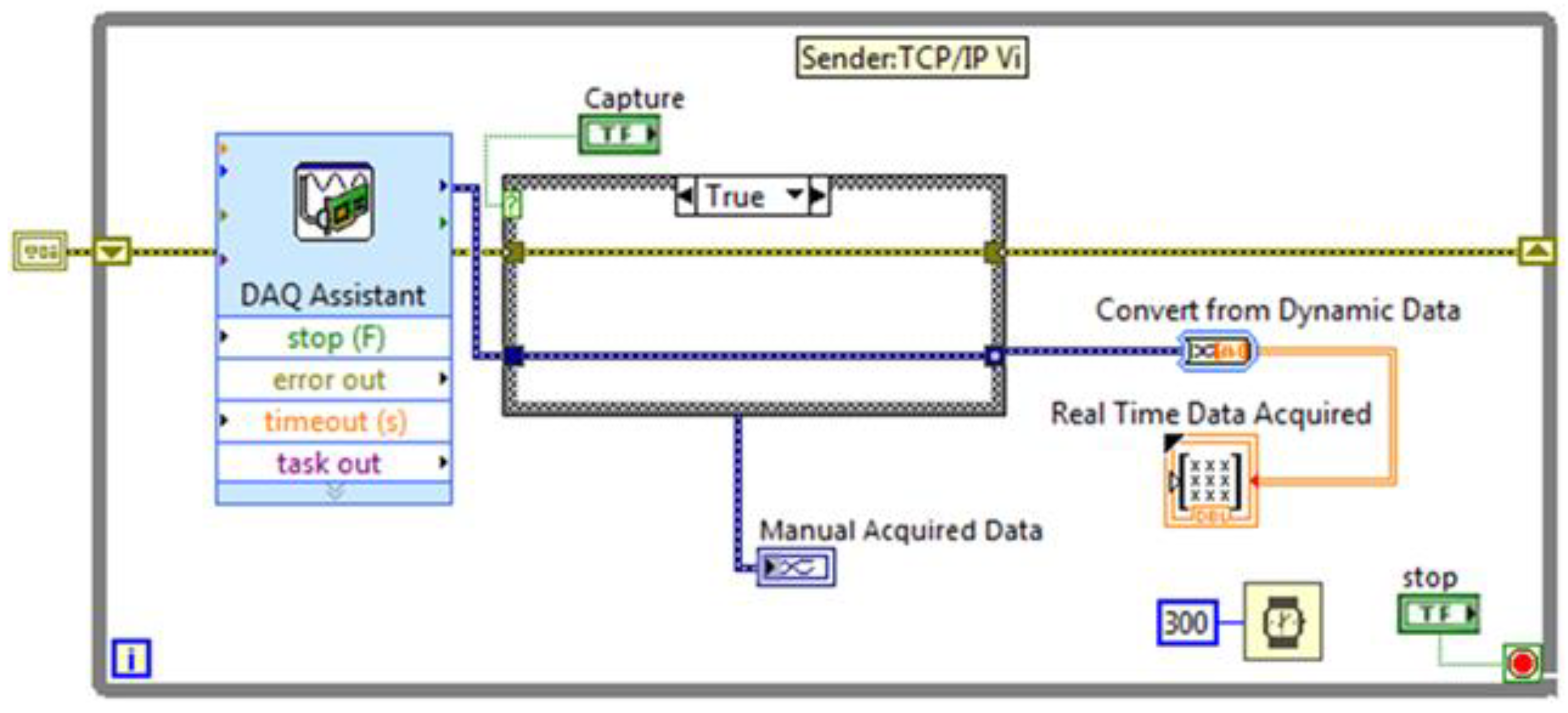
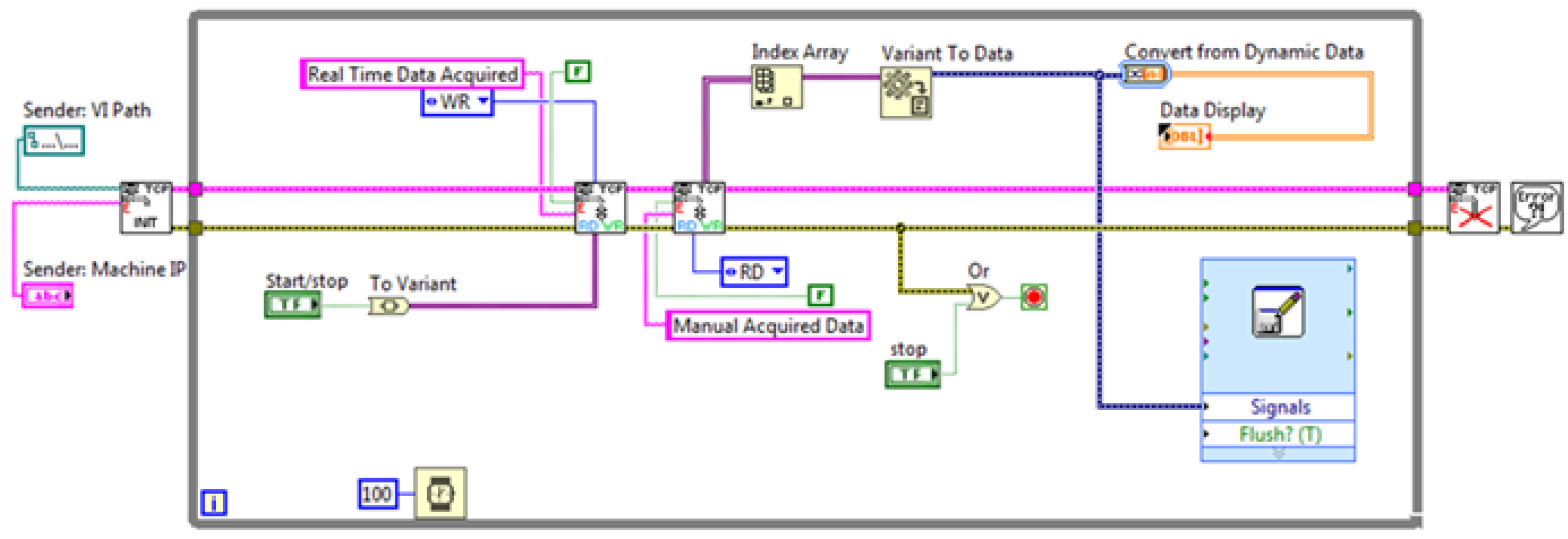
Among the variety of communication protocols that have been suggested as standard for data sharing with the host involved in the DT environments, the TCP/IP (Transmission Control Protocol/Internet Protocol) suite was chosen for implementation. This protocol provides syntactic and semantic rules for communication, contains the details of the message formats, and describes how a computer responds when a message arrives and how it handles errors or other abnormal conditions. In addition, it allows for describing the communication between various computers independently on the network hardware. In the case under examination, the protocol adopted allows for data communication between the NI-9208 and a host computer that can perform the data analysis without affecting the computational complexity of the embedded system. To this end, two G-Code programs have been developed. The first program for data sending is installed on the data acquisition module, while the second one, i.e., the TCP/IP receiver, has been embodied as a sub-VI in the block diagram of the digital layer (
Figure 2 and
Figure 3).
This TCP/IP infrastructure has been built with the specific aim of enabling real-time data acquisition from the plant, its storage on a client host, and the possibility of forecasting the output on the basis of the real-time input acquired and the elaboration made by the ML algorithms. The forecast will be obtained using the ML algorithms implemented in the solution; depending on the chosen algorithm and on the elaborations made, this layer can provide two different outputs.
To be more precise, the classification and the clustering algorithms return a message box in which the machine status is displayed. In particular, the evaluation of the inlet pressure has been carried out using the data comparison module of the DT [
18] by inserting the rheological properties of each fluid (taken from [
19]) and analytically computing the pressure drop of the pasteurization system at different flow rates. On the basis of the combined evaluation of the flow rate (F), inlet pressure (P1), and outlet pressure (P2), the system status can fall into one of the following categories:
Ok: The parameters are in the correct range of values and therefore the machine is working correctly. Based on the result obtained via the DT model, the “correct” functioning is assumed to be described by values that deviate between 0 and 10% (in absolute terms) from the value computed by the DT;
Warning: One or more parameters are out of the correct range of functioning as previously defined, and in particular, the numerical value of the parameter deviates by 10–25% (in absolute terms) from the value computed by the DT. Under this circumstance, possible working anomalies could arise. This status could also describe a transitory phase, in which the plant moves from an original steady-state condition to a subsequent one, and therefore some parameters deviate from the normal values;
Failure: The machine is experiencing a working problem and its functioning needs to be stopped. This circumstance occurs when the absolute deviation between the real and computed values is greater than 25%.
The range for the values of the three categories above has been defined on the basis of previous studies carried out by the authors on the plant under examination [
16,
17,
18,
19], as well as exploiting the developed knowledge about the plant functioning. It is worth mentioning that, although a classification of the various statuses of machine functioning has been proposed by various authors in literature, to the best of the authors’ knowledge there are no recognized criteria for defining those statuses in a rigorous way. Nonetheless, the ranges used in this study are similar to those found in previously published studies (cf., e.g., [
20]). Moreover, for enhancing the possibility of detecting the plant malfunctioning (i.e., the failure condition) against the warning and ok statuses (which are obviously less problematic), a wider range of possible values has been assigned to the former category (75% of the cases) compared to the remaining two categories.
The corresponding information, i.e., the status detected, will be displayed on the front panel HMI via TCP/IP receiver G-Code on the server.
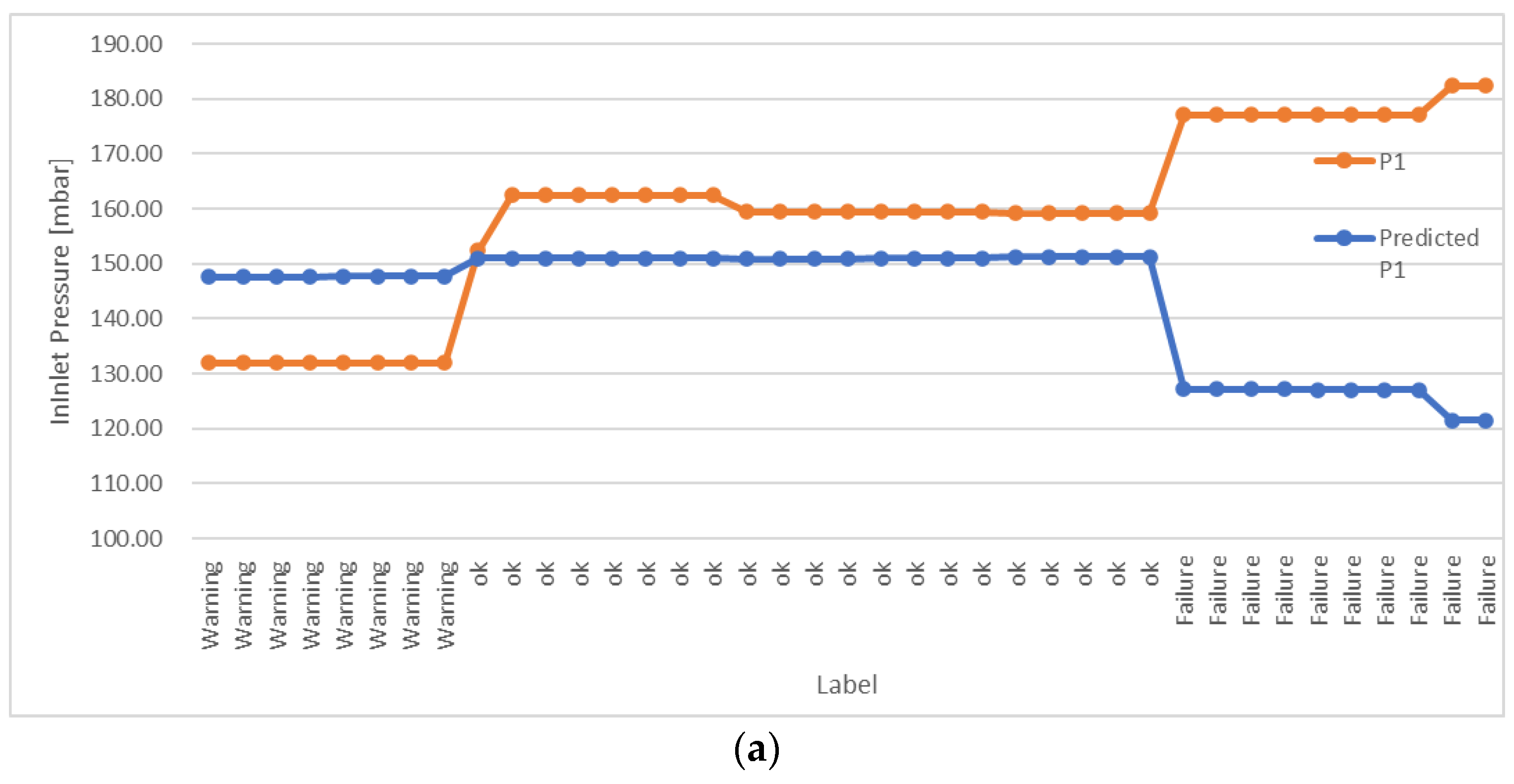
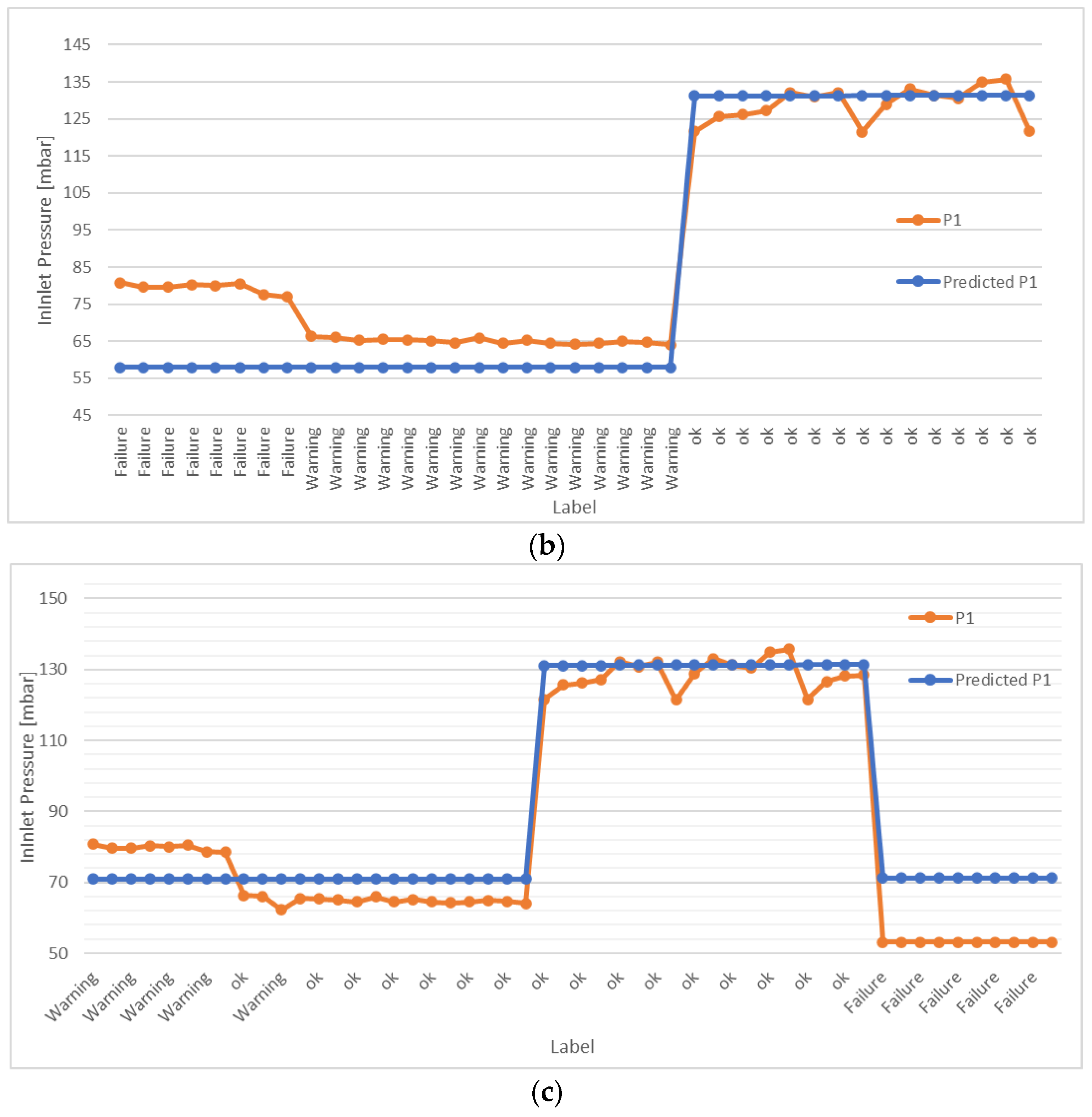
The linear regression model, instead, returns a discrete value, which reflects the estimate of the (selected) output variable (i.e., the outlet pressure in this study); this value can be sent to the plant PID controller to adjust the setpoint based on the current machine status.
2.3. Data Collection
For building the dataset used for applying the ML algorithms, a series of machine tests were carried out using three different fluids. To be more precise, the machine was tested with water (fluid 1), and then, to emulate the behavior of two non-Newtonian food fluids, we used two mixtures of water and a food additive as a gelling agent (i.e., Gellan Gum) in different percentages. Fluid 2 had a Gellan Gum percentage of 0.1% while fluid 3 had a 0.15% mass composition (
w/
w). The signals returned by each sensor were acquired with a sampling rate of one sample per second. The testing phase was run by varying the process flow acting on an inverter frequency with a 10% step (
Table 2) and setting three different operating temperatures, owing to the dependency of the rheological properties of the additive on temperature [
19].
For collecting data relating to the various conditions of functioning (i.e., ok, warning, or failure), the machine was stressed by varying one process parameter at a time and maintaining the remaining parameters at a steady state. To achieve a variation in the inlet pressure in a range between 0 and 185 mbar, without varying the outlet pressure or the product flow, manual actions were made on the inlet valve mounted immediately next to the product pump. Such actions involve increasing the inlet pressure due to the pipe section reduction, without simultaneously affecting the product flow and outlet pressure. To vary the outlet pressure, the outlet section of the heat exchanger was gradually closed by acting on the manual valve mounted at the outlet of the heat exchanger. To avoid unsafe conditions for the operator or corrupted machine functioning, the outlet valve was opened once the outlet pressure achieved the maximum measurable value of 250 mbar. Finally, the product flow was varied by gradually closing the inlet product valve mounted at the outlet section of the product tank.
The data acquired during the machine test were collected in a dedicated database for each fluid and preprocessed before using them as input for the ML algorithms. The preprocessing phase was carried out following the steps listed below:
Checking each triplet of collected data (flow, inlet pressure, and outlet pressure);
Adding a new column, named “label”, to each triplet of values collected. The label was used to describe the machine status on the basis of the values of the considered parameters and knowing the testing scenario. For a triplet of values describing a normal condition, the label assigned is “ok”, while for values collected during a transitory phase, the label assigned is “warning”. Anomalous situations, according to the description provided above, were labeled as “failure”;
Describing the data collected by evaluating their average, standard deviation, maximum and minimum read values, and percentiles for the first quartile (25%) and third quartile (75%). These values are summarized in
Table 3 for the three fluids, in order to provide the reader with an overview of the data collected. The whole dataset is available in the
Supplementary Materials of this paper;
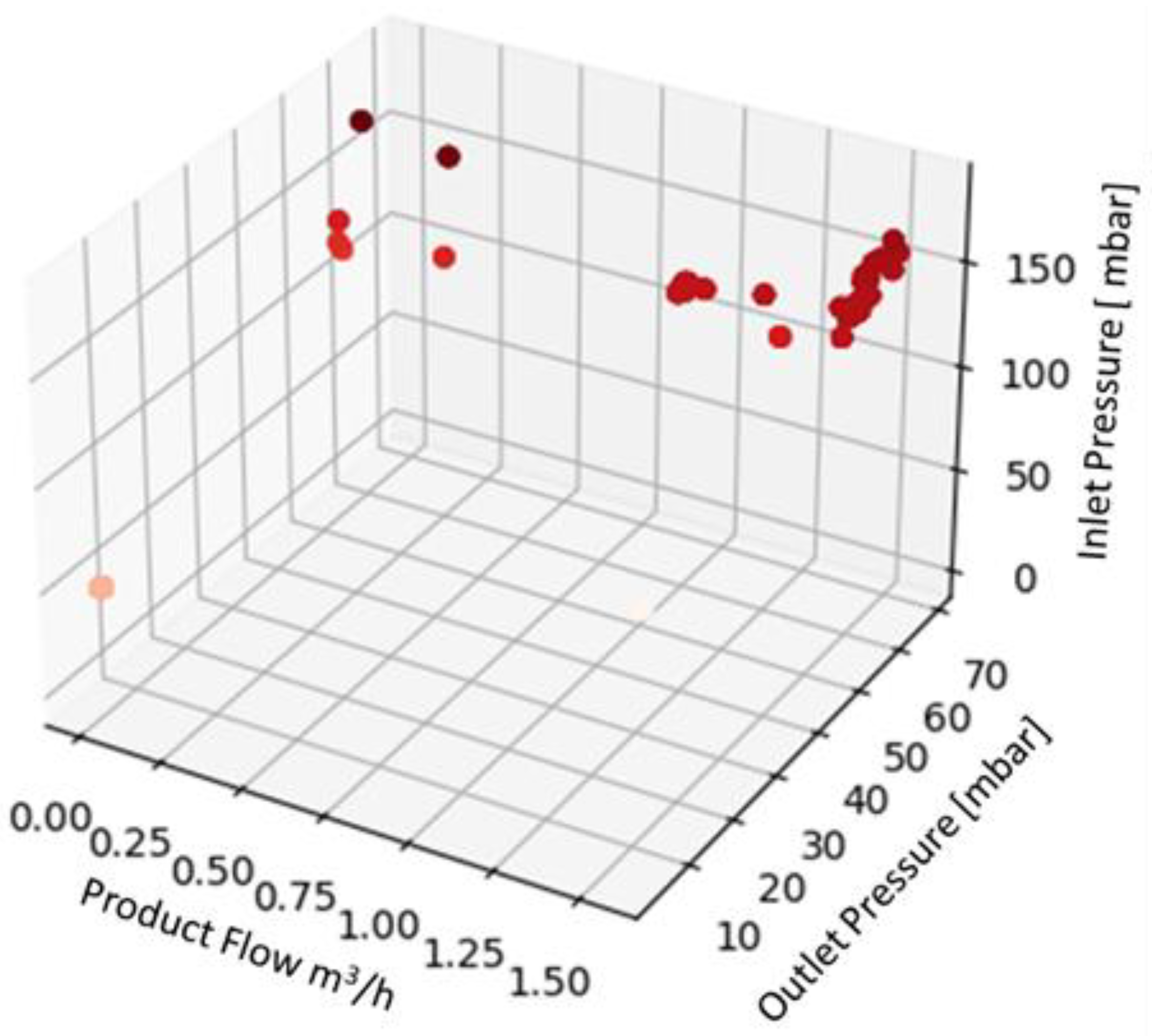
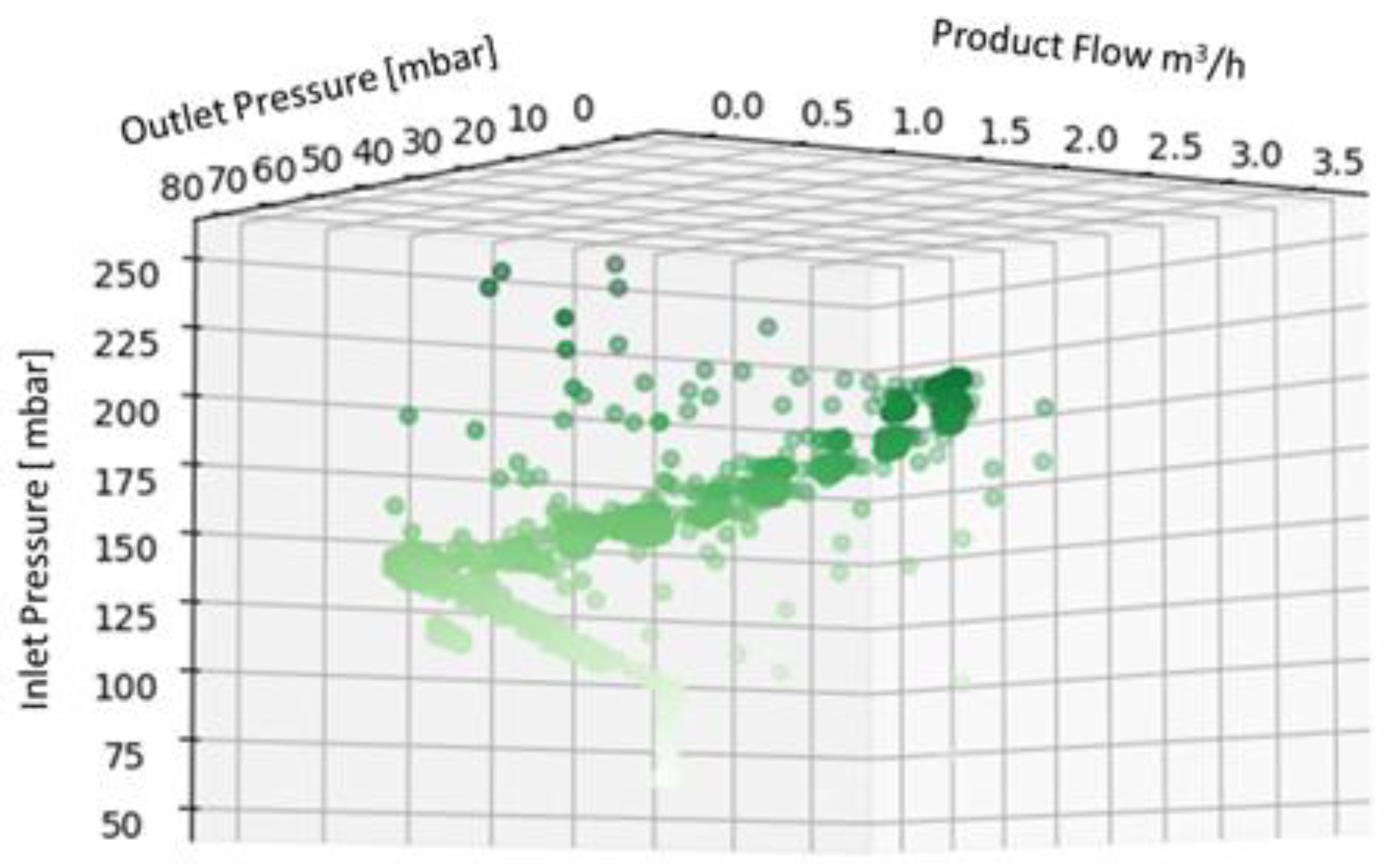
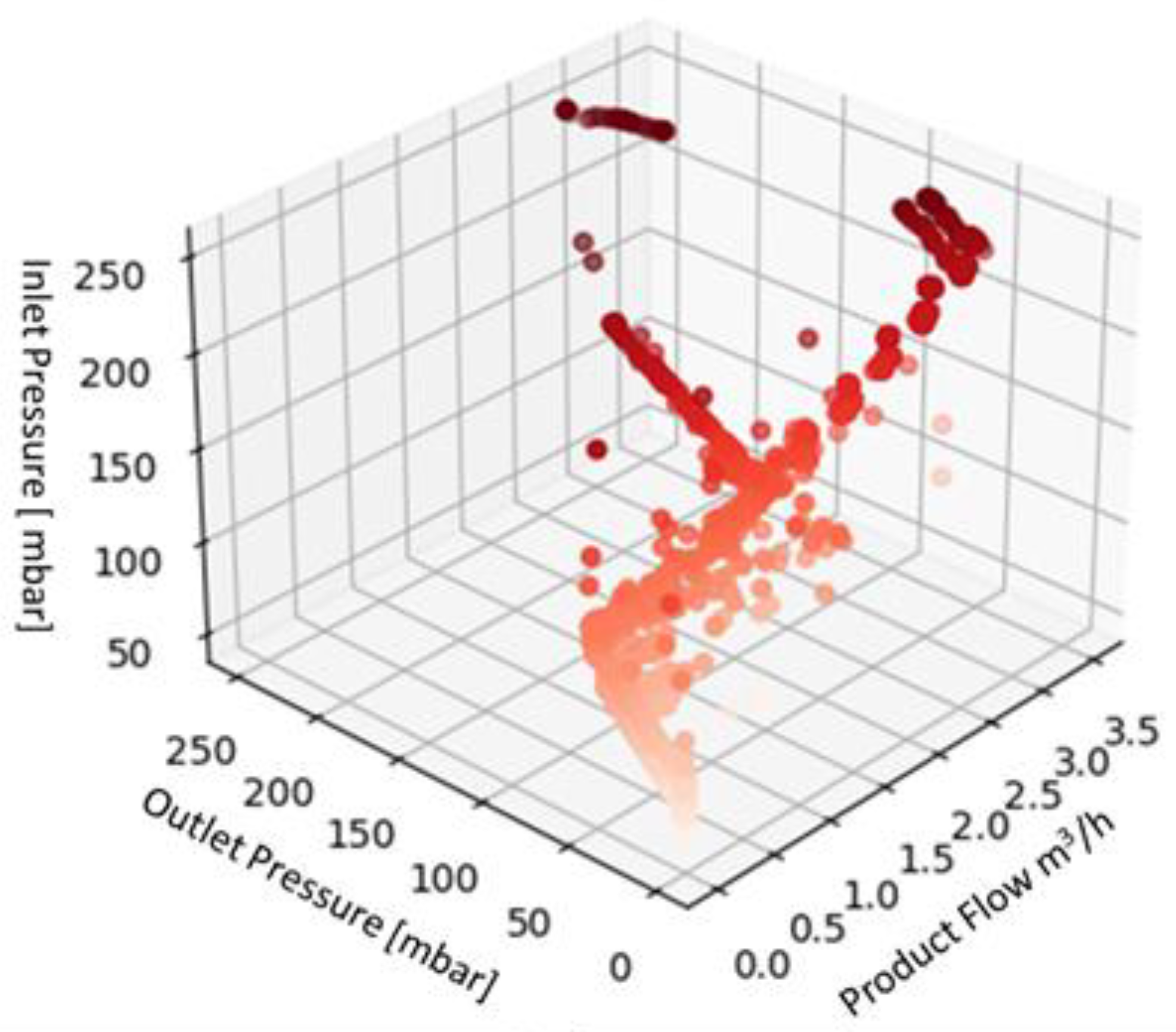
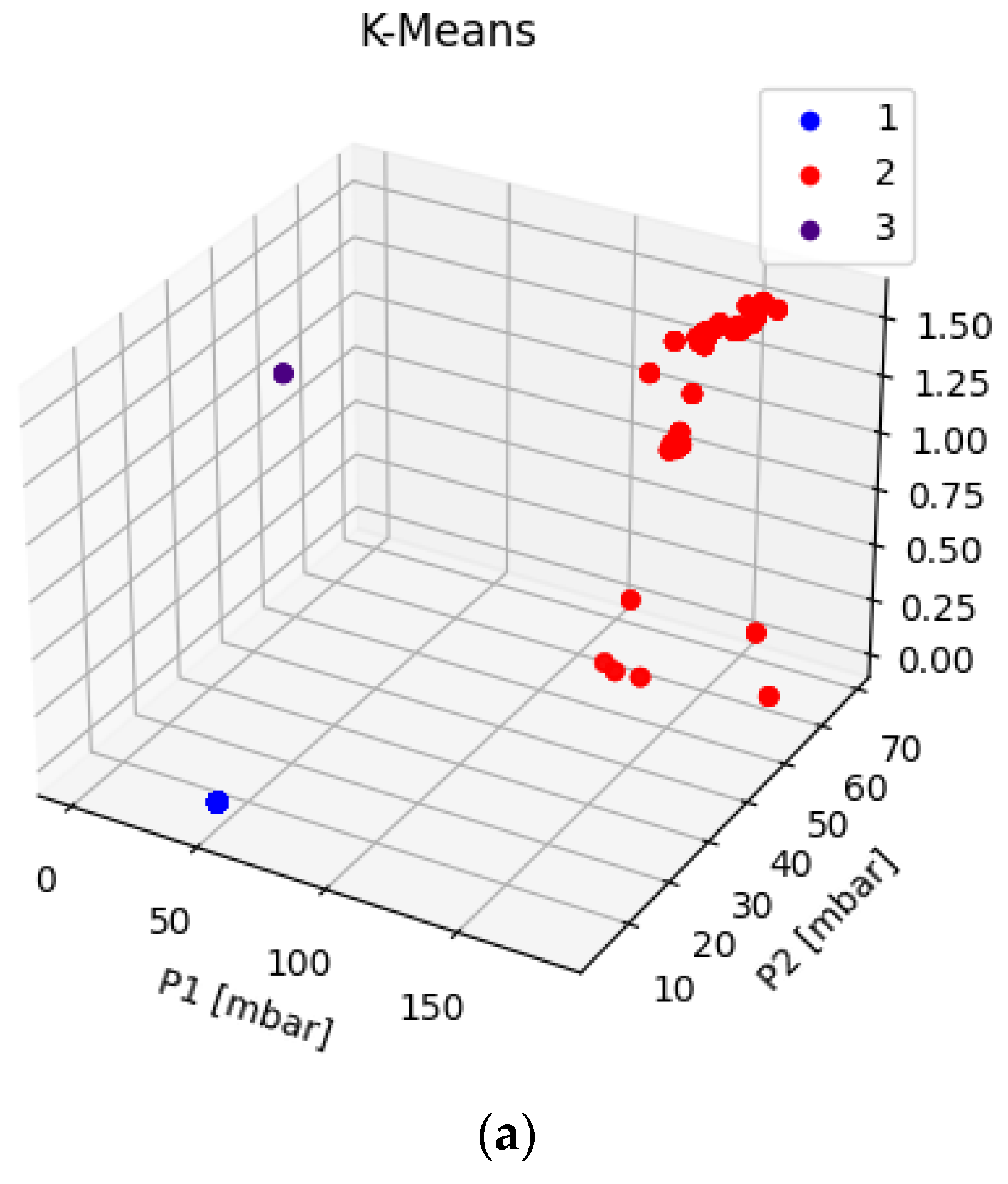
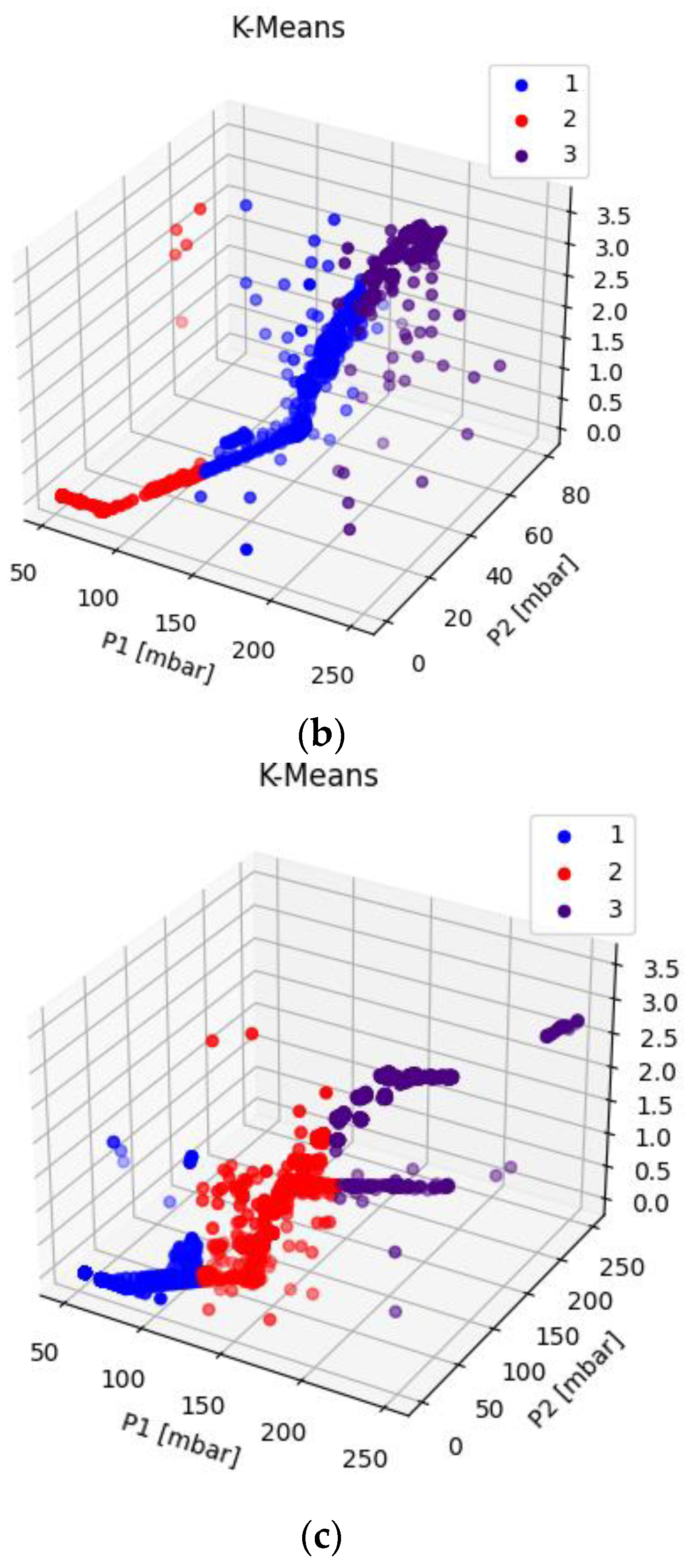
Displaying the data in 3D plot using Python in order to provide a preliminary overview of the distribution of the data collected (
Figure 4,
Figure 5 and
Figure 6), aided by colors’ graduation which highlights the density of data in the 3D graph’ space.
Overall, the dataset resulting from preprocessing consists of 6256 rows and 4 columns for each fluid. The four columns reflect the machine status and the process parameters considered; in particular, the first and the second list the inlet pressure and the outlet pressure of the process fluid in mbar, as they were measured at the inlet and outlet sections of the heat exchanger. The third column lists instead the values of the product flow in m3/h. The data were saved in the form of a .csv file in Microsoft ExcelTM release 2016 for Windows (Microsoft Corporation, Redmond, WA, USA).
2.4. Machine-Learning Algorithms
The selected ML algorithms were programmed and implemented using the scikit-learn package (
https://scikit-learn.org/stable/; accessed on 18 January 2022) of Python as the development environment.
The script of the supervised ML algorithms, namely, multiple linear regression and artificial neural network, follows the same structure and consists of three sections. In the first section, the data are imported from the dataset of values collected during the tests. Some preliminary elaborations are also made on the set of data to make them suitable for processing by the algorithms. As an example, the data format was converted into the appropriate type (object-type data), while the process parameters variables were converted into floating-type data. A second section of the script is used for splitting the dataset into two subsets, namely, the training and the testing sets, accounting for 70% and 30% of the original set of data, respectively. Then, the ML model is trained on the first sub-set of data. Once the algorithm has been trained, the last section of the script carries out the model prediction. A cross-validation step was carried out, by varying the composition of the sets used for training and testing (while keeping their percentages unchanged), to check whether the results of the supervised algorithms could be somehow dependent on the specific elements belonging to these sets. The result was negative, meaning that the algorithm performance does not depend on the selected training and testing sets.
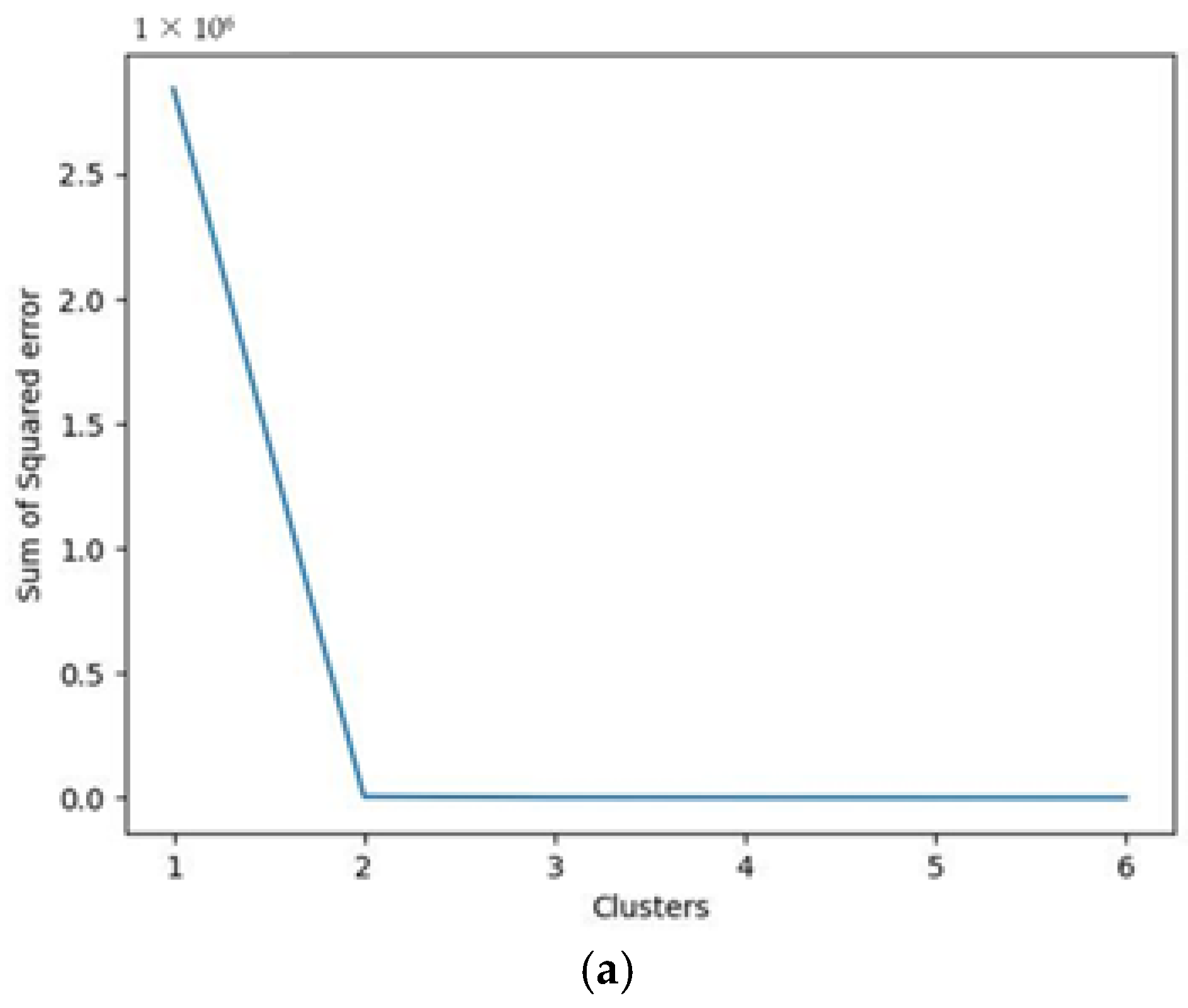
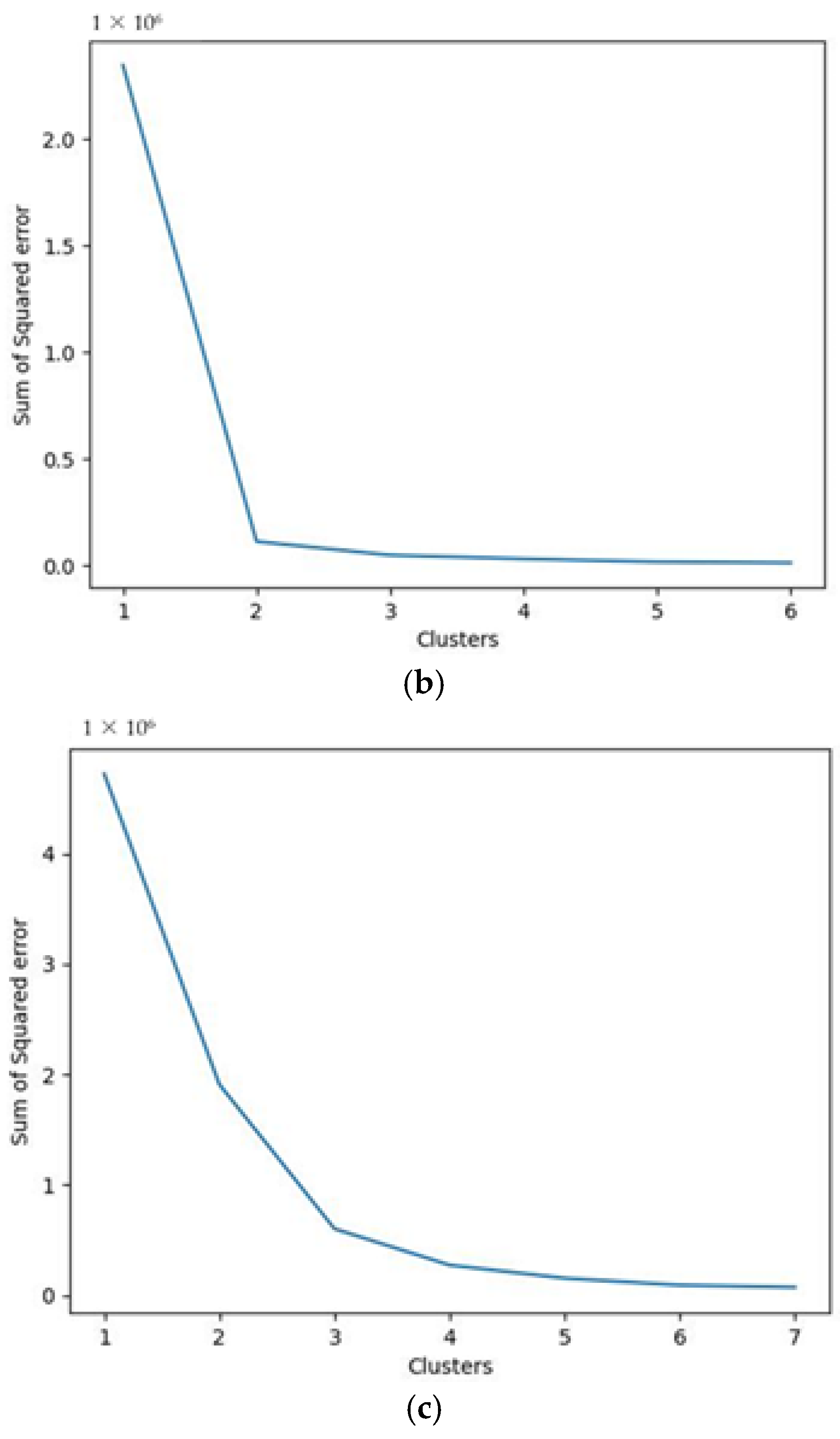
The third algorithm developed is instead an unsupervised clustering model. This kind of model does not require an output on which to be trained; rather, the training and testing phases are not carried out at all. For the purpose of our application, the expected outcome of this algorithm is the classification of the triplets of data collected into the appropriate status of “ok”, “warning”, or “failure”. Due to the lack of a testing phase, the only way to check whether the result of the algorithm can be considered as correct is to compare the clusters identified for the triplets of data with the real status of the machine as it was preliminary set in the database. This means that, ideally, the algorithm should group the triplets of the dataset into 3 clusters, corresponding to the “ok”, “warning”, or “failure” status. The possible advantage of an unsupervised algorithm, therefore, is that, in the case of exact classification of the clustered data, in future applications there would be no need to preliminarily classify the data into the “ok”, “warning”, or “failure” categories.
4. Discussion and Conclusions
This work has proposed an application whose aim is to integrate digital twin models, machine-learning algorithms, and Industry 4.0 technologies, to design a comprehensive tool for detecting anomalies in the functioning of an industrial system. The proposed solution has been designed to be suitable for implementation in a tube-in-tube indirect machine for fluid food pasteurization. To achieve good results with the available technologies, four different modes of functioning have been developed and implemented in the digital twin of the plant. The series of tests carried out aimed at demonstrating which operating mode fits best the real condition of the system.
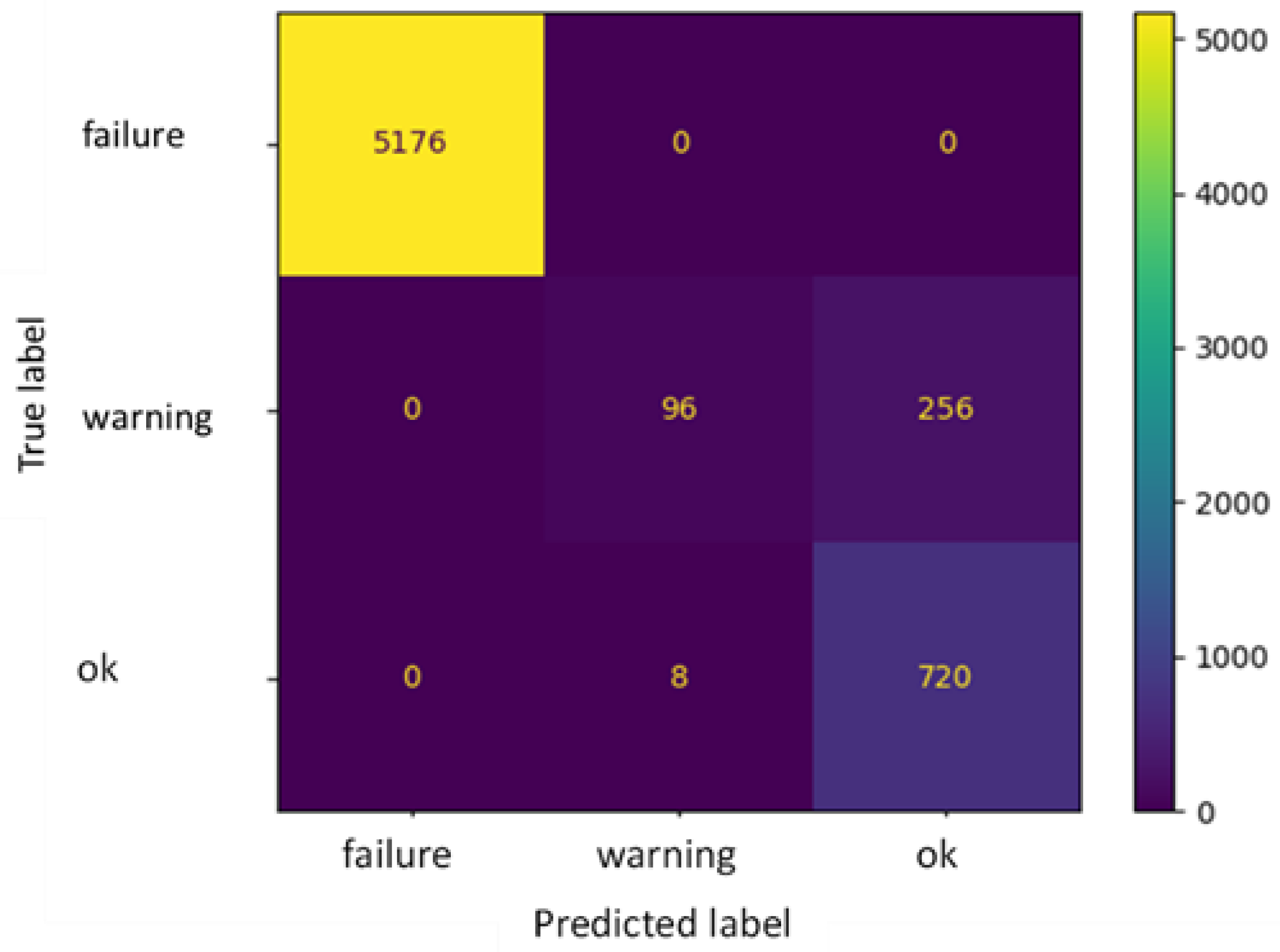
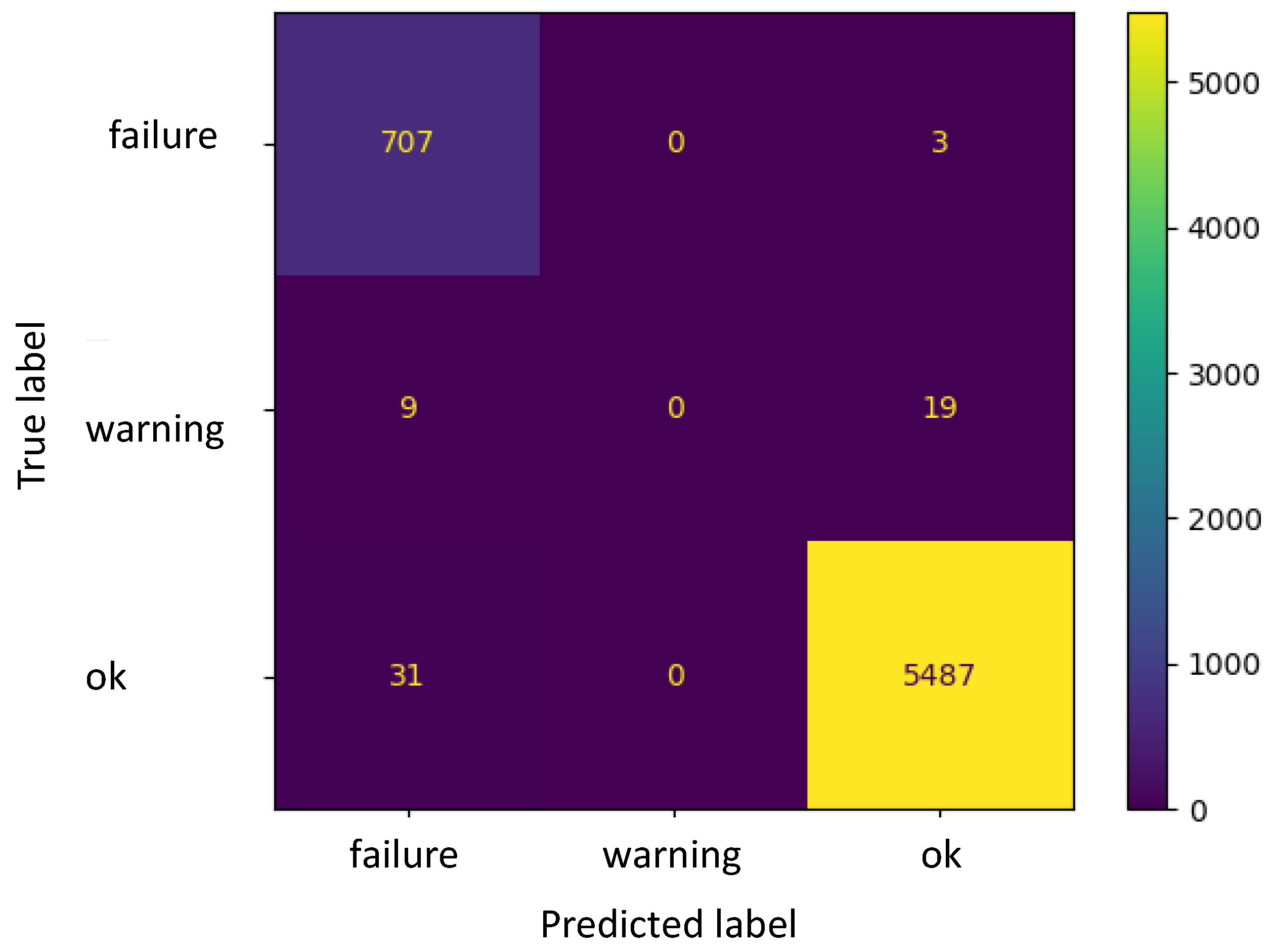
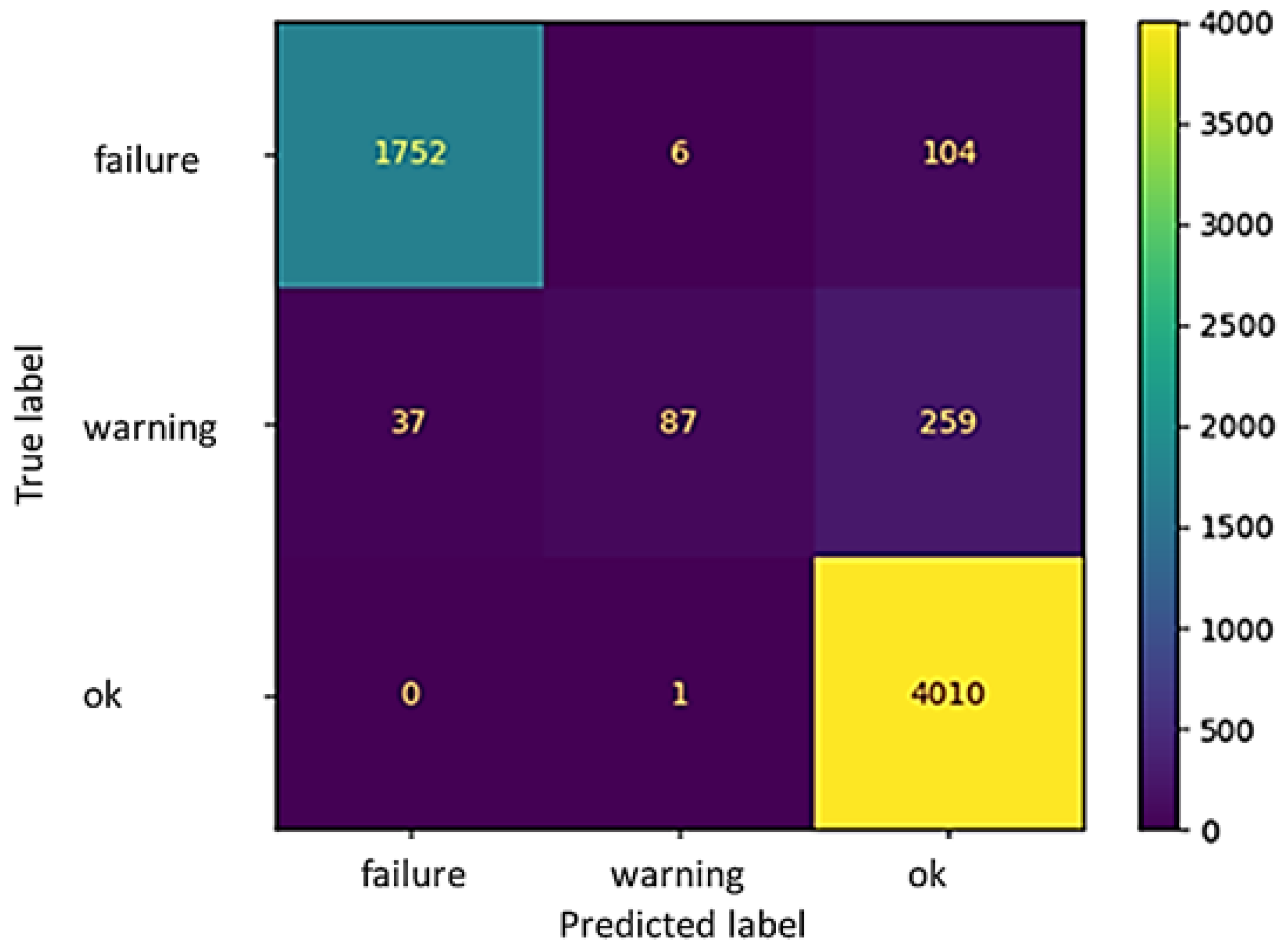
The DT environment, via the tools developed in previous studies, can be used for monitoring and controlling the system, both in situ and via remote connection. However, the need to manually adjust the setpoint of the controller and set the fluid characteristics in the software can represent a limitation compared to the fully automated functioning of the tool. To overcome this issue, three ML approaches (namely, a linear regression model, an artificial neural network, and a clustering algorithm) have been embodied in the solution developed and implemented for the online monitoring of the plant. In this respect, this study was exploratory in nature, and aimed to test various ML algorithms in an attempt to find the most effective one for anomaly detection; in this field of application, research on ML adoption is still limited. The results obtained using these ML tools showed that the regression algorithm, once integrated into a DT environment, could be a suitable way to obtain automatic control of the system. Indeed, the dependent variable predicted by the algorithm (P1) on the basis of multiple independent variables (P2 and F) and returned as an output in the form of a discrete value, can directly be used as a setpoint for the PID. At the same time, the DT model operates as a mirror of the machine behavior, supervises system functioning, and can even stop the machine from functioning in case a “failure” is detected, by displaying the machine status on the HMI. The artificial neural network and clustering algorithms, instead, returned slightly worse performances. In particular, the MLPC algorithm had a high accuracy as an anomaly prediction tool when used for classifying the “ok” or “failure” status of the different fluids tested, while a lower precision was reached in the classification of the “warning” status. Similar conclusions can be made for the k-means clustering algorithm, which is generally able to group the “failure” and “ok” status, while the “warning” status is often confused with the correct functioning of the plant. This outcome can be justified based on the definition of the “warning” status itself, which includes situations in a quite limited range of values, and therefore, it is difficult to precisely detect them. At the same time, the “failure” status is not always correctly captured by the artificial neural network and clustering algorithms tested. This is a current limitation of the proposed approaches and deserves attention in future studies. False-negative classifications of the “failure” status have to be avoided, if possible, as they denote situations in which, if using the classification returned by the MPLC and k-means algorithms, the machine would continue to work, while it actually needs to be stopped. Although these false-negative values are quite few in number, they are also the most dangerous for the employee safety; therefore, for being used to the “failure” status of the machine, the MPLC and k-means algorithms need some preliminary refinements. Otherwise, in practical cases, it could be advisable to use both approaches and couple their results; indeed, the possibility that both methods return false negative values for the “failure” status is obviously lower than that of each method being used singly.
In view of an in-field implementation, therefore, the usage of the clustering or classification algorithms for anomaly detection would need to be limited to the identification of the “ok” situations, which are typically correctly captured. This means that anytime the operating conditions deviate from this status, a message should be displayed on the HMI to alert an employee about a possible need for intervention at the plant. In addition, there are some further aspects that need to be addressed in practical cases. One of these aspects is that a clustering algorithm can return bad performance values if used on a dataset that includes outliers or noisy data. Although this is not the case for our study, this circumstance could always be observed in real cases, and would involve some preliminary activities and checks to be made on the data collected.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}