
Wide Residual Relation Network-Based Intelligent Fault Diagnosis of Rotating Machines with Small Samples



Abstract
:1. Introduction
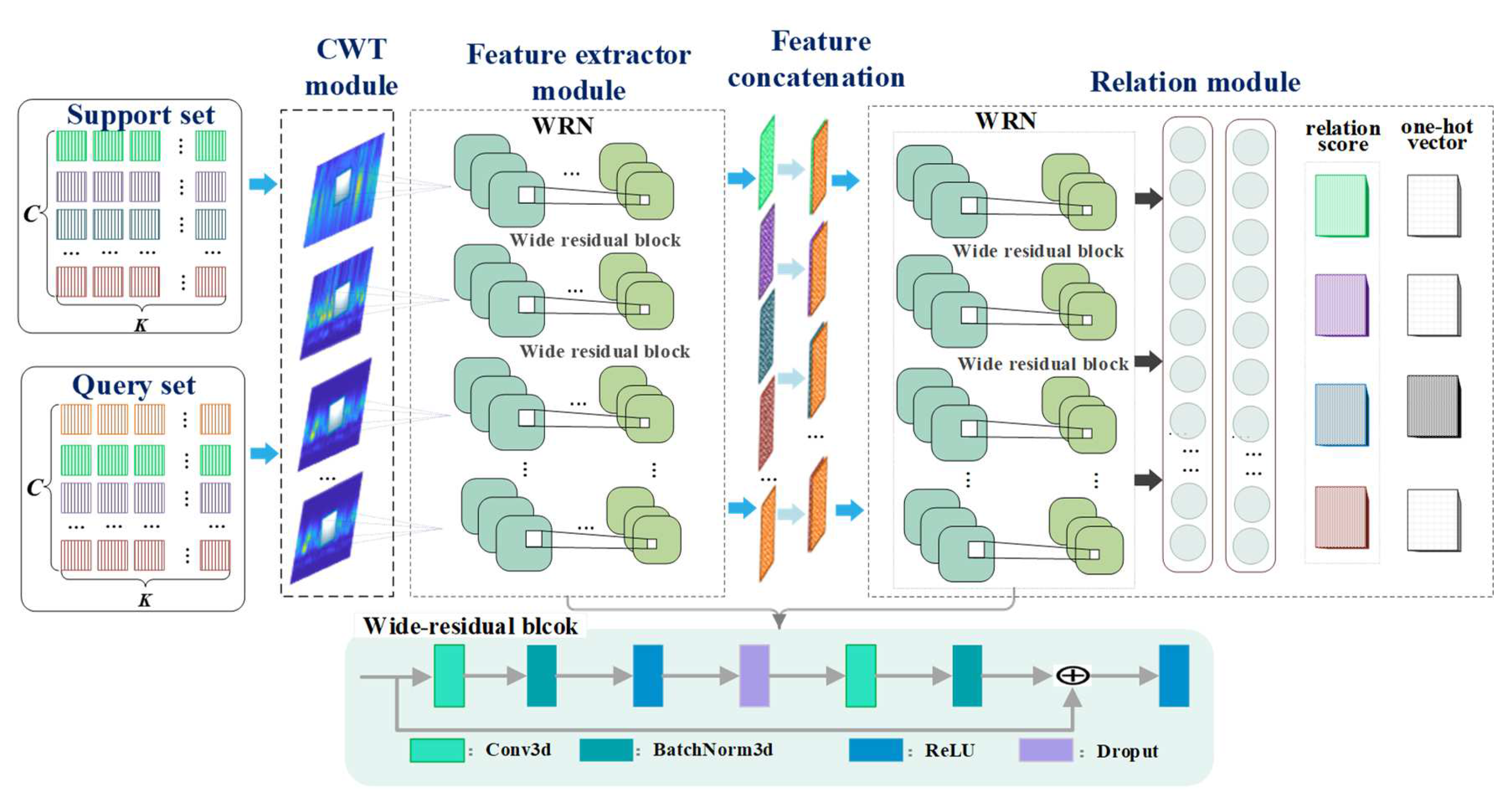
- A WRRN method is first proposed to exploit the fault knowledge learned from the lab machine for fault diagnosis in several real-case machines with small fault data, whereas only lab machine datasets are used for training.
- The built wide residual network can generate more representative fault features from input samples compared to traditional CNN methods.
- The relation module can reveal the similarity relations between the sample pairs to determine their categories, which can improve diagnostic performance.
2. Proposed Method
2.1. Problem Formulation
- The different RMs have the same machine health states.
- The training dataset comes from a RMLE. The test dataset is from a RMRE, which is not required to be involved in the training process.
2.2. Wide Residual Relation Network
2.3. Optimization Objective of the WRRN
| Algorithm 1. Mini-batch training algorithm for the WRRN. and epochs denote the batch size and the number of iterations |
| Input: support set ; query set ; Feature extractor module ; relation module . |
|
3. Fault Diagnosis Procedure Based on WRRN
4. Experimental Studies
4.1. Experimental Setup and Dataset Description
4.2. Results and Discussion
4.3. Comparative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, G.Q.; Deng, C.; Wu, J.; Xu, X.B.; Shao, X.Y.; Wang, Y.H. Sensor data-driven bearing fault diagnosis based on deep convolutional neural networks and s-Transform. Sensors 2019, 19, 2750. [Google Scholar] [CrossRef] [Green Version]
- Wu, H.; Ma, X.; Wen, C.L. Multilevel fine fault diagnosis method for motors based on feature extraction of fractional fourier transform. Sensors 2022, 22, 1310. [Google Scholar] [CrossRef] [PubMed]
- Lang, X.; Steven, C.; Paolo, P. Rolling element bearing diagnosis based on singular value decomposition and composite squared envelope spectrum. Mech. Syst. Signal Process. 2021, 148, 107174. [Google Scholar]
- Kanizo, Y.; Rottenstreich, O.; Segall, I.; Yallouz, J. Designing optimal middlebox recovery schemes with performance guarantees. IEEE J. Sel. Area Commun. 2018, 36, 2373–2383. [Google Scholar] [CrossRef]
- Kim, D.; Nelson, J.; Ports, D.R.K.; Sekar, V.; Seshan, S. RedPlane: Enabling fault-tolerant stateful in-switch applications. In Proceedings of the 2021 ACM SIGCOMM 2021 Conference, Virtual Event, 23–27 August 2021; pp. 223–244. [Google Scholar]
- Lei, Y.G.; Yang, B.; Jiang, X.W.; Jia, F.; Li, N.P.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Cheng, Y.W.; Zhu, H.P.; Wu, J.; Shao, X.Y. Machine health monitoring using adaptive kernel spectral clustering and deep long short-term memory recurrent neural networks. IEEE Trans. Ind. Inform. 2019, 15, 987–997. [Google Scholar] [CrossRef]
- Stetco, A.; Dinmohammadi, F.; Zhao, X.Y.; Robu, V.; Flynn, D.; Barnes, M.; Keane, J.; Nenadic, G. Machine learning methods for wind turbine condition monitoring: A review. Renew. Energy 2019, 133, 620–635. [Google Scholar] [CrossRef]
- Wu, J.; Wu, C.Y.; Cao, S.; Or, S.W.; Deng, C.; Shao, X.Y. Degradation data-driven time-to-failure prognostics approach for rolling element bearings in electrical machines. IEEE Trans. Ind. Electron. 2019, 66, 529–539. [Google Scholar] [CrossRef]
- Wang, Y.X.; Xiang, J.W.; Markert, R.; Liang, M. Spectral kurtosis for fault detection, diagnosis and prognostics of rotating machines: A review with applications. Mech. Syst. Signal Process. 2016, 66–67, 679–698. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, Y.; Wu, J.; Deng, C.; Hu, K. Sensor data-driven structural damage detection based on deep convolutional neural networks and continuous wavelet transform. Appl. Intell. 2021, 51, 5598–5609. [Google Scholar] [CrossRef]
- Wu, J.; Guo, P.; Cheng, Y.; Zhu, H.; Wang, X.-B.; Shao, X. Ensemble generalized multiclass support-vector-machine-based health evaluation of complex degradation systems. IEEE-ASME Trans. Mechatron. 2020, 25, 2230–2240. [Google Scholar] [CrossRef]
- Jiang, Q.C.; Yan, X.F.; Huang, B.A. Performance-driven distributed PCA process monitoring based on fault-relevant variable selection and bayesian inference. IEEE Trans. Ind. Electron. 2016, 63, 377–386. [Google Scholar] [CrossRef]
- Zheng, J.D.; Pan, H.Y.; Cheng, J.S. Rolling bearing fault detection and diagnosis based on composite multiscale fuzzy entropy and ensemble support vector machines. Mech. Syst. Signal Process. 2017, 85, 746–759. [Google Scholar] [CrossRef]
- Li, G.Q.; Wu, J.; Deng, C.; Xu, X.B.; Shao, X.Y. Deep reinforcement learning-based online Domain adaptation method for fault diagnosis of rotating machinery. IEEE-ASME Trans. Mechatron. 2021. [Google Scholar] [CrossRef]
- Pang, X.Y.; Xue, X.Y.; Jiang, W.W.; Lu, K.B. An Investigation into fault diagnosis of planetary gearboxes using a bispectrum convolutional neural network. IEEE-ASME Trans. Mechatron. 2021, 26, 2027–2037. [Google Scholar] [CrossRef]
- Cheng, Y.W.; Wu, J.; Zhu, H.P.; Or, S.W.; Shao, X.Y. Remaining useful life prognosis based on ensemble long short-term memory neural network. IEEE Trans. Instrum. Meas. 2021, 70, 3503912. [Google Scholar] [CrossRef]
- Li, G.Q.; Wu, J.; Deng, C.; Chen, Z.Y.; Shao, X.Y. Convolutional neural network-based bayesian gaussian mixture for intelligent fault diagnosis of rotating machinery. IEEE Trans. Instrum. Meas. 2021, 70, 3517410. [Google Scholar] [CrossRef]
- Cheng, Y.W.; Lin, M.X.; Wu, J.; Zhu, H.P.; Shao, X.Y. Intelligent fault diagnosis of rotating machinery based on continuous wavelet transform-local binary convolutional neural network. Knowl.-Based Syst. 2021, 216, 106796. [Google Scholar] [CrossRef]
- Zhao, M.H.; Zhong, S.S.; Fu, X.Y.; Tang, B.P.; Pecht, M. Deep residual shrinkage networks for fault diagnosis. IEEE Trans. Ind. Inform. 2020, 16, 4681–4690. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, J.; Deng, C.; Wang, C.; Wang, Y. Residual deep subdomain adaptation network: A new method for intelligent fault diagnosis of bearings across multiple domains. Mech. Mach. Theory 2022, 169, 104635. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Xu, N.X.; Ding, Q. Deep learning-based machinery fault diagnostics with domain adaptation across sensors at different places. IEEE Trans. Ind. Electron. 2020, 67, 6785–6794. [Google Scholar] [CrossRef]
- Wu, Z.H.; Jiang, H.K.; Zhao, K.; Li, X.Q. An adaptive deep transfer learning method for bearing fault diagnosis. Measurement 2020, 151, 107227. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Ding, Q.; Li, X. Diagnosing rotating machines with weakly supervised data using deep transfer learning. IEEE Trans. Ind. Inform. 2020, 16, 1688–1697. [Google Scholar] [CrossRef]
- Xu, G.W.; Liu, M.; Jiang, Z.F.; Shen, W.M.; Huang, C.X. Online fault diagnosis method based on transfer convolutional neural networks. IEEE Trans. Instrum. Meas. 2020, 69, 509–520. [Google Scholar] [CrossRef]
- Wen, L.; Gao, L.; Li, X.Y. A new deep transfer learning based on sparse auto-encoder for fault diagnosis. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 136–144. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.G.; Jia, F.; Xing, S.B. An intelligent fault diagnosis approach based on transfer learning from laboratory bearings to locomotive bearings. Mech. Syst. Signal Process. 2019, 122, 692–706. [Google Scholar] [CrossRef]
- Shao, S.Y.; McAleer, S.; Yan, R.Q.; Baldi, P. Highly Accurate Machine Fault Diagnosis Using Deep Transfer Learning. IEEE Trans. Ind. Inform. 2019, 15, 2446–2455. [Google Scholar] [CrossRef]
- Guo, L.; Lei, Y.G.; Xing, S.B.; Yan, T.; Li, N.P. Deep convolutional transfer learning network: A new method for intelligent fault diagnosis of machines with unlabeled data. IEEE Trans. Ind. Electron. 2019, 66, 7316–7325. [Google Scholar] [CrossRef]
- Xiao, D.Y.; Huang, Y.X.; Zhao, L.J.; Qin, C.J.; Shi, H.T.; Liu, C.L. Domain adaptive motor fault diagnosis using deep transfer learning. IEEE Access 2019, 7, 80937–80949. [Google Scholar] [CrossRef]
- Sun, C.; Ma, M.; Zhao, Z.B.; Tian, S.H.; Yan, R.Q.; Chen, X.F. Deep transfer learning based on sparse autoencoder for remaining useful life prediction of tool in manufacturing. IEEE Trans. Ind. Inform. 2019, 15, 2416–2425. [Google Scholar] [CrossRef]
- Li, L.J.; Han, J.W.; Yao, X.W.; Cheng, G.; Guo, L. DLA-MatchNet for few-shot remote sensing image scene classification. IEEE Trans. Geosci. Remote 2021, 59, 7844–7853. [Google Scholar] [CrossRef]
- Li, Y.; Chao, X.W. Semi-supervised few-shot learning approach for plant diseases recognition. Plant Methods 2021, 17, 68. [Google Scholar] [CrossRef] [PubMed]
- Li, F.F.; Fergus, R.; Perona, P. One-shot learning of object categories. IEEE Trans. Pattern Anal. 2006, 28, 594–611. [Google Scholar]
- Gregory, K.; Zemel, R.; Salakhutdinov, R. Siamese Neural Networks for One-Shot Image Recognition. Master’s Thesis, University of Toronto, Toronto, ON, Canada, 2015. [Google Scholar]
- Sung, F.; Yang, Y.X.; Zhang, L.; Xiang, T.; Torr, P.H.S.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 2016; pp. 770–778. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching networks for one shot learning. In Proceedings of the Advances in Neural Information Processing Systems 29, Barcelona, Spain, 5–10 December 2016. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Group Name | Block Type = B (3,3) |
|---|---|---|
| Feature extractor | Conv_1 | |
| Conv_2 | ||
| Conv_3 | ||
| Conv_4 | ||
| Avg-pool | ||
| Relation module | Conv_1 | |
| Conv_2 | ||
| Avg-pool | ||
| FC 1 | 8 | |
| FC 2 | 1 |
| Datasets | Health State | Operating Conditions | Number of Samples |
|---|---|---|---|
| Shafting machine | N I B MS | L1–200 r/min | 3 × 1000 |
| L2–250 r/min | 3 × 1000 | ||
| L3–300 r/min | 3 × 1000 | ||
| L4–350 r/min | 3 × 1000 | ||
| L5–400 r/min | 3 × 1000 | ||
| Steam turbine | N IB MS | 6680 r/min 1300 L/min | 3 × 1000 |
| Task | Training Dataset from Shafting Machine | Testing Dataset |
|---|---|---|
| A1 | L1 | Steam turbine |
| A2 | L1, L2 | Steam turbine |
| A3 | L1, L2, L3 | Steam turbine |
| A4 | L1, L2, L3, L4 | Steam turbine |
| A5 | L1, L2, L3, L4, L5 | Steam turbine |
| Task | Classification Time (ms) |
|---|---|
| 1-shot | 4.1 |
| 3-shot | 19.5 |
| 5-shot | 44.5 |
| 8-shot | 64.25 |
| 10-shot | 90.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Wang, Y.; Wu, J.; Deng, C.; Jiang, W. Wide Residual Relation Network-Based Intelligent Fault Diagnosis of Rotating Machines with Small Samples. Sensors 2022, 22, 4161. https://doi.org/10.3390/s22114161
Chen Z, Wang Y, Wu J, Deng C, Jiang W. Wide Residual Relation Network-Based Intelligent Fault Diagnosis of Rotating Machines with Small Samples. Sensors. 2022; 22(11):4161. https://doi.org/10.3390/s22114161
Chicago/Turabian StyleChen, Zuoyi, Yuanhang Wang, Jun Wu, Chao Deng, and Weixiong Jiang. 2022. "Wide Residual Relation Network-Based Intelligent Fault Diagnosis of Rotating Machines with Small Samples" Sensors 22, no. 11: 4161. https://doi.org/10.3390/s22114161