1. Introduction
Modern fruit harvesting is mainly conducted by human labor and is roughly the same in different regions of the world. However, it requires human involvement and thus, complexity and labor hiring from overseas. The globalization of the COVID-19 pandemic and its economic impact has wreaked havoc on all economies around the world, pushing many into recession and possibly even economic depression [
1]. Furthermore, the aging and availability of labor are concerns. Among common fruits, the pear stands out as an essential fruit type for daily life. For example, the Japanese pear (such as
Pyrus pyrifolia Nakai) is one of the most widely grown fruit trees in Japan and has been used throughout the country’s history [
2]. Regardless of the harvest season, due to the need for a large number of laborers for picking and a shortage of labor, the cost of pear picking has gradually increased.
The world labor force is predicted to decline by approximately 30% between 2017 and 2030 [
3]. With the development of agricultural machinery, modern agricultural technology has gradually evolved from manual planting and picking to full automation and intelligence. Since the 1990s, with the development of computers and information technology, artificial intelligence and machine vision in agricultural machinery have become more effective and popular [
4]. Since most agricultural work involves repetitive content operations, one of the most popular agricultural robots is the picking robot. Over time, most countries in the world have developed intelligent picking robots through different methods and techniques to load and unload agricultural products and detect fruit and positioning issues [
5]. Therefore, for relatively delicate and soft fruits such as pears, the use of picking robots can greatly increase productivity. However, in recent studies, object detection in picking robots was reported to cause injuries due to grasping or using shear to detach the fruit from the branch [
6]. The successful picking of soft pears depends on the recognition of the shape of the pears to understand the curved surface of the fruit. In classical image processing, it is challenging to recognize fruits, as shapes and sizes vary in orchards. In addition, illumination is a concern in dense canopies. Variability occurs in the detection of pears due to their size, shape, and illumination. Therefore, a large number of training datasets including size, shape, and illumination variabilities are needed to address the challenges of pear detection in complex orchard environments.
Deep learning has become a potential method to overcome the limitation of conventional segmentation in image analysis. It is one of the subfields of machine learning and has now developed a variety of different architectures [
7]. Self-Organizing Feature Map (SOFM) is the ability of the discussed neural network to determine the degree of similarity that occurs between classes. It is also a method that belongs to deep learning. Among other things, SOFM networks can be used as detectors that indicate the emergence of a widely understood novelty. Such a network can also look for similarities between known data and noisy data. [
8] Additionally, deep learning includes artificial neural networks (ANNs) [
9] and neural networks extracted by convolutional neural networks (CNNs) by fully connected layers (FCNs), where CNNs preserve the spatial relationships between pixels by learning internal features using small pictures of the input data [
10].
Intelligent robot vision processing of target plants has become an indispensable step in agricultural intelligence and many excellent target detection methods are now widely used in the development of agricultural robots as target detection continues to develop. The first types included Fast R-CNN [
11] and Faster R-CNN [
12], which have roughly the same principle of selecting the region of interest by region feature network (RPN) [
13] and then transmitting to the head layer to generate the edges as well as the species. With the demand for accuracy in target detection, Mask R-CNN [
13] was introduced, which adds FPN [
13] to the backbone layer based on Faster R-CNN and adds a new branch in the head layer to generate more accurate masks. The second type is You Only Look Once (YOLO) [
14], which focuses on the detection of targets; all detection results are lower than the above models but faster than the above models. However, due to the demand for accuracy in target detection, the Mask R-CNN detection speed is slower than that of other detection models [
15].
Some identification techniques identify by evaluating, extracting, and recognizing color, because, in the food industry, color is an identifier used by producers and processing engineers as well as consumers and is the most direct way of identification [
16]. Therefore, color extraction is also widely used in identification technology. Boniecki et al. 2010 analyzed the classification ability of Kohonen-type neural models learned using “unsupervised” methods. Classification of three selected apple varieties frequently found in Polish orchards was carried out. The neural classification was based on information encoded in the form of a set of digital images of apples and dried carrots. Representation in the form of a palette of the main colors occurring in fruits and dried vegetables and selected shape coefficients were used as a basis for the classification [
17].
However, it is not enough for deep learning. Most of the deep learning methods were limited to RGB images which have a limitation of depth information. In a recent study, a thermal camera was used to detect tree trunks in a complex orchard. However, in comparing a tree trunk to some fruit, there is more complexity in detecting and measuring the distance for picking information [
18]. A 3D stereo camera has further advantages in addition to conventional camera sensors. The 3D stereo camera mimics and imitates the human eye imaging principle. With the powerful visual system of the human eye, the perception of the third dimension (depth) is derived from the difference between the image formed by the left eye and the right eye. Because of this difference, the human eye visual system introduces the third dimension (depth), and the 3D stereo camera receives biological inspiration to detect the depth information of an object by extracting three dimensions of information from the digital image and using it for 3D reconstruction. In addition, the camera perceives the depth of objects in the range of 1 to 20 m at 100 FPS [
19]. By detecting complex situations in orchards with a 3D stereo camera combined with Mask R-CNN vision algorithms, specified fruits can be detected.
Mask R-CNN is conceptually simple and was proposed by Kaiming et al (2017). It is a flexible, pass-through object instance segmentation framework. This method can efficiently detect objects in images while generating high-quality segmentation masks for each instance. Mask R-CNN was also used for instance segmentation of detected objects and the evaluation of human poses [
13]. Several studies have shown that Mask R-CNN can be used for the detection of some fruits. Jia et al (2020) used a series of apple images with a size of 6000 × 4000 -pixel resolution under natural light using a Canon camera for cloudy and sunny weather conditions [
20]. Yu et al (2019) proposed a Mask R-CNN-based algorithm to detect and quantify wild strawberries, and the fruit detection results of 100 test images showed an average detection accuracy of 95.78% and a recall rate of 95.41% [
21]. All of the above results showed that Mask R-CNN can be used for instance segmentation. In the above study, RGB images were used, which did not cover the depth information of the distance. However, Mask R-CNN with a 3D stereo camera can be further used for complex canopy and the weight files produced by the dataset produced by the common dataset. However, the 3D stereo camera has problems such as recognition errors and difficulty in obtaining depth information when detecting in real time. If the additional function has the depth information of the garden, then masking in terms of shape and size is still possible.
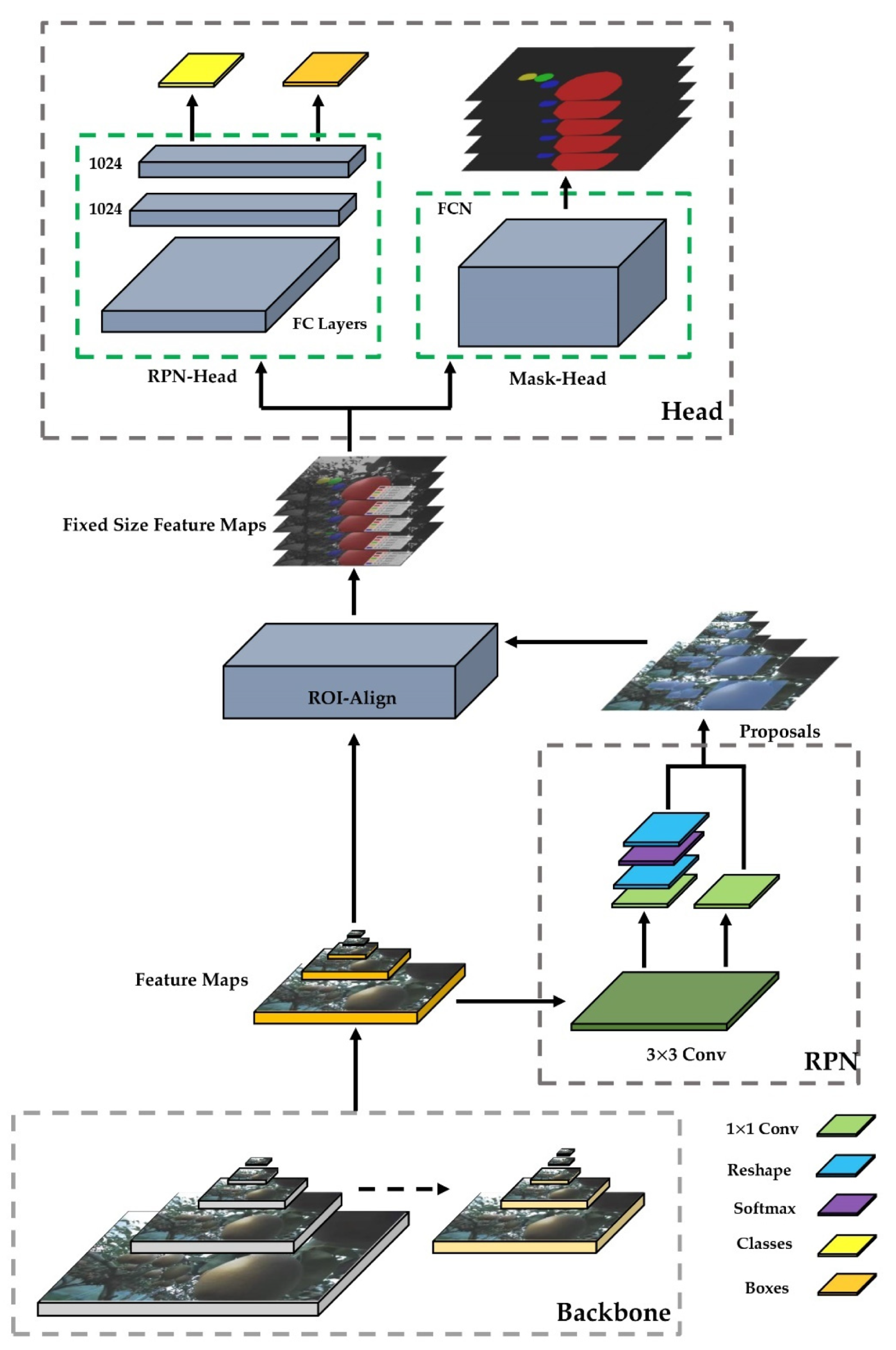
Mask R-CNN extended the object detection framework of Faster R-CNN by adding an additional branch at the end of the model, thus achieving instance segmentation for each output suggestion frame using a fully connected layer [
22]. Unlike ROI-Pooling of Faster R-CNN, ROI-Pooling inputs an image and multiple regions of interest (ROIs) into a feature map of fixed size, which was then mapped to a feature vector by a fully connected network (FCN) [
11]. However, ROI-Align in Mask R-CNN canceled the quantization of ROI-Pooling twice and retained the decimals, and then used bilinear interpolation [
23] to obtain the image values on pixel points with floating-point coordinates. This was because although the quantization did not affect the classification in the work, it had a significant negative impact on predicting the exact mask for pears in the orchard [
13].
However, the complexity of orchards causes difficulty in detection, such as the presence of leaf shading, overlapping fruits, insufficient light, interruption of light due to nets over the canopy, and more shadows in orchards, which affect the detection results. Faster R-CNN was used to detect peppers, melons, and apples using multiple vision sensors [
24], and although high detection accuracy was achieved, the detection of overlapping fruits was greatly reduced. Mask R-CNN has the potential to help overcome problems with size, shape, and illumination. Since the Mask R-CNN uses instance segmentation, it can over detect different individuals of the same species, so overlapping parts of the fruit can also be detected precisely and variability in shape can be adjusted, thus improving the accuracy of detection. Therefore, the purpose of this research is to develop a pear recognition system using instance segmentation based on a Mask RCNN from 3D camera datasets. The expected recognition of pears can be implemented as a fruit picking mechanism with fewer injuries to the surface with the recent advancements of manipulators and robots.
3. Results
3.1. Training Details
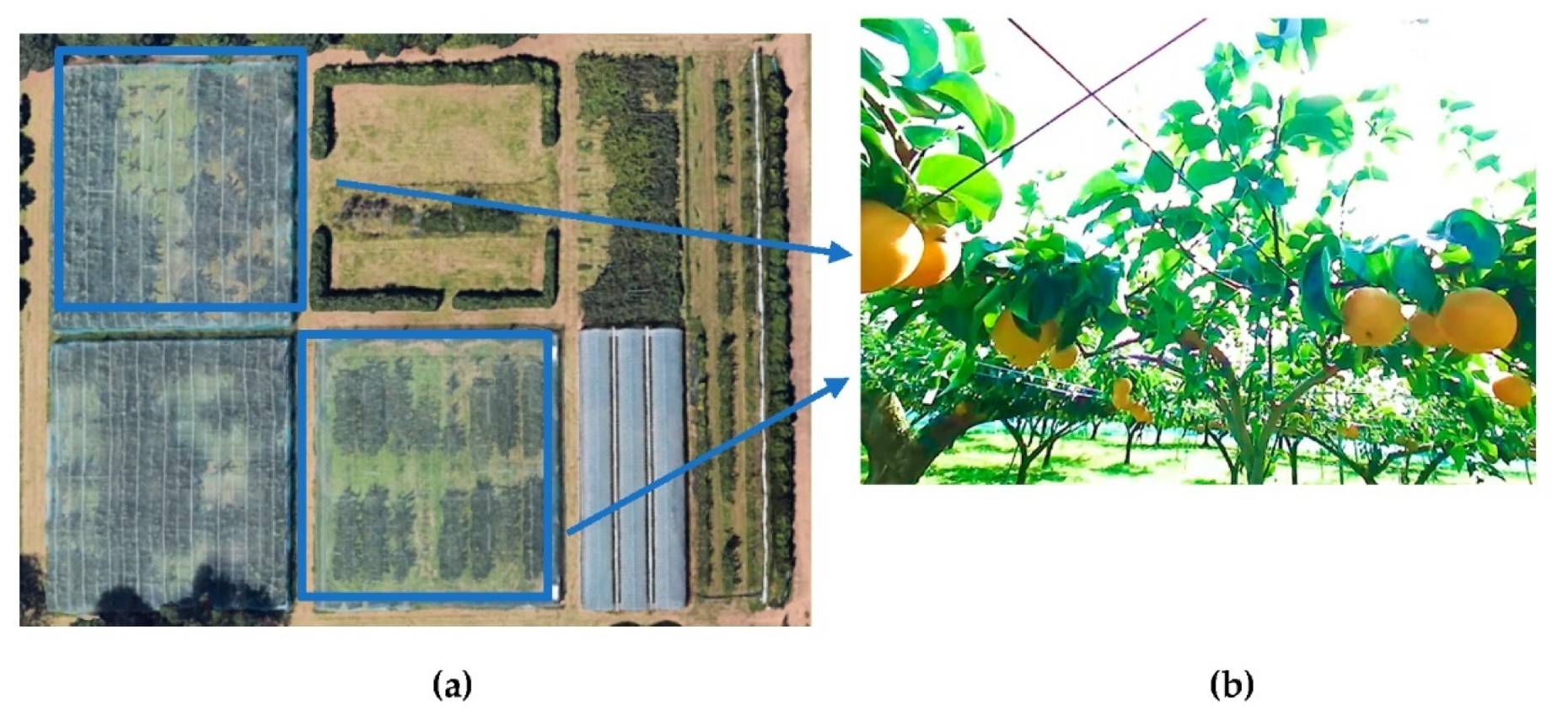
In this research, 9054 four-channel RGBA images (3018 images were original images and 6036 images were augmented images) in PNG format were used, and all images were taken by the same 3D stereo camera. The size of the validation set was adjusted by the loss function of the validation set. Initially, the training, validation, and testing sets were divided into a ratio of 6:3:1, that is, 5054 images for the training set, 2700 images for the validation set, and 900 images for the test set. The epoch was set to 80 with 500 steps in each epoch. During the experiment, since the Mask-RCNN could only use three-channel RGB images for the predicted images, the channels of the test set of 900 RBGA images were modified to RGB after the error was found. The following figures show the loss diagram of each partial function for this study (
Figure 11a–f).
In this research, comparison experiments were conducted on the same datasets at different learning rates. From the training results, when the learning rate was set to 0.001, the training loss dropped to 0.3099 and the validation set loss dropped to 0.4637. Additionally, the Mask R-CNN head bounding box loss dropped to 0.0434 in the training set and the validation loss dropped to 0.0601 and the Mask R-CNN head class loss dropped to 0.0656 in the training set and the validation loss dropped to 0.1119; the Mask R-CNN mask loss dropped to 0.1260 in the training set and the validation loss dropped to 0.1310; the RPN bounding box loss dropped to 0.0677 in the training set and the validation loss was 0.1077; the RPN class loss in the training set was 0.0071 and the validation loss was 0.0432 (
Figure 11a–f).
Figure 11a indicates the overall loss; by 80 epochs, each epoch was trained with 500 steps, which indicates that the model was good for this training. The Mask R-CNN bounding box loss denoted the loss of Mask R-CNN bounding box refinement, Mask R-CNN class loss denoted the head layer loss of classifier of Mask R-CNN, Mask R-CNN mask loss denoted the head layer mask binary cross-entropy loss of Mask, the RPN bounding box loss denoted the RPN bounding box loss, and the RPN class loss denoted anchor classifier loss.
Classification loss indicated how close the training model was to predicting the correct class. Mask R-CNN class loss was used as the head layer, and all objects were covered, while RPN class loss only covered the foreground and background of images. The border loss, on the other hand, responded to the distance between the real boxes and the predicted boxes. The Mask R-CNN mask loss responds to how close the model was to the predicted correct class mask. The sum of the above five losses constituted the overall loss.
3.2. Evaluation of Model Metrics
A series of weight files were obtained from the Mask R-CNN training and were used to evaluate the Mask R-CNN training model. The weight files left from the last training in the training process were selected to evaluate the test set.
The Precision (P), Recall (R), Average Precision (AP), and mean Average Precision (mAP) were used as the main parameters to evaluate the model in this research. We tested the different performances of the test set using the weights obtained from the training set after 80 epochs at different learning rates and the response plots of the Precision-Recall (PR) curves at a learning rate of 0.001. We also tested the same operation on the validation set with the weight trained by training sets, with overall mAP (IoU = 0.5). In addition, we tested different parts of the validation set, which was divided into three sections. One was original image datasets in the validation set, and another two were datasets after doing augmentation. We found that the results were nearly similar using the same weight tested in three sets: the original images (89.76%), rotation augmentation (84.47%), and flipped augmentation images (89.67%). However, while using all the datasets, including originals and two other augmented imageries in the validation process, the accuracy was increased (92.02%).
Table 2 shows the comparison of mAPs in Mask R-CNN and Faster R-CNN. The Precision-recall curve of Faster R-CNN and Mask R-CNN from the testing set at different learning rates after 80 epochs (
Figure 12).
3.3. Evaluation of Model Effectiveness
In this study, by creating a dataset and Mask R-CNN model using a 3D stereo camera, we found the best weights by comparing the fit of Mask R-CNN and Faster R-CNN with the same learning rate at lr = 0.001. By testing 900 images of the test set taken at different times, we obtained the following results by comparing the different effects of aggregating pears and separating pears under different illumination. Due to the problem of the light, branch, and leaf shading in the orchard, this research compared the test results of Mask R-CNN and Faster R-CNN under the light intensity from multiple pears in gathering and individual situations (
Figure 13 and
Figure 14).
The results showed that in the case of independent pear detection, the difference between the two was that Mask R-CNN generates both masks and bounding boxes, while Faster R-CNN detects pear-only generated bounding boxes. The detection accuracy of Mask R-CNN was significantly higher than that of Faster R-CNN under dark light conditions, and the accuracy of the bounding box of Mask R-CNN was higher than that of Faster R-CNN when pears were aggregated, or when the detection target is incomplete pears. Under bright light conditions, for the accuracy of independent pears, there was only a slight difference between the two. However, in the case of aggregated pears, Mask R-CNN had a higher correct recognition rate than Faster R-CNN.
We also tested the comparison of the recognition of pears in different situations for both after image rotation. When the pears were separated, the accuracy of the two only shows a small difference in the size of the borders. However, when the pears were aggregated, Faster R-CNN failed to recognize individual pears; Mask R-CNN had a higher recognition rate than Faster R-CNN in this case.
4. Discussion
Machine vision technology has become very popular due to the robust identification of objects and classification in industrial and agricultural technological applications. This approach can be implemented to future fruit picking robots or mechanical devices as machines replace human labor. Thus, the cost of population labor will be significantly reduced; in terms of detection, with the development of vision technology, the detection accuracy will also improve. In our study, we compared this technology with other deep learning models. The average precision of the YOLOv4 model for pear recognition in complex orchards was 93.76% and that of YOLOv4-tiny for pear recognition was 94.09% [
32]. Moreover, by comparing the datasets using Faster R-CNN between apples, mangoes, and oranges, the mAP of apples was 86.87%, mangoes was 89.36%, and oranges was 87.39% [
33]. The mAPs of this research were decreased when the camera field of view included fruit covered with leaves for the recognition of fruit with the Faster R-CNN algorithm. Even by labeling the fruit with different shading objects as different classes, mAPs for different classes did not significantly improve. The mAPs of leaf-occluded fruit, branch-occluded fruit, non-occluded fruit, and fruit-occluded fruit were 89.90%, 85.80%, 90.90%, and 84.80%, respectively [
34]. By comparing the same dataset, which was taken by the same ZED camera, we knew that the mAPs of Faster R-CNN reached 87.52% on the testing set and 87.90% on the validation set. We also found that the performance of Faster-RCNN became less accurate when testing aggregated pears compared with Mask R-CNN. Therefore, Faster R-CNN achieved good results in detection and distinguished the types and individuals of objects while the mAPs of Faster R-CNN, in the case of recognizing one kind of fruit, were hardly a huge improvement even by data augmentation. Due to the complex environment of the orchard, for example, the color of the pears changed when the light intensity was different; because there were many branches, the pears and the leaves overlapped; or when multiple pears were clustered together, it was difficult to detect a single pear. Though Faster R-CNN had difficulties improving the accuracy of detection to a higher level and was prone to inaccurate detection results when testing aggregated pears, Mask R-CNN solved this problem perfectly. Mask R-CNN used instance segmentation technology and had advanced improvements in detecting aggregated pears and their accuracy. In this research, by using Mask R-CNN for the 3D stereo dataset, mAP (lr = 0.001) was 99.45% in the testing set and mAP(lr = 0.001) was 95.22%, which was much higher than that of Faster R-CNN. Due to this series of factors, Mask R-CNN has made great progress in detection. The mask generated by the Mask R-CNN network distinguished individual pears well when there were pear clusters in the environment.
We chose to use a 3D stereo camera for data acquisition. Traditional monocular cameras obtained better resolution for images; however, they had limitations in extended measurement. Although the principle of the monocular camera measurement method was simple, its accuracy was much lower than that of the 3D stereo camera. The ZED camera was different from ordinary traditional cameras; it obtained depth information by generating point clouds to calculate the actual distance between the camera and the pear. Using the ZED camera with Mask R-CNN combined instance segmentation and depth ranging to identify each of individual pears in complex orchards and calculate their actual distance. We also compared Faster R-CNN, which was a traditional visual recognition model that had an advantage in recognition speed, but Mask R-CNN had an advantage in accuracy. Furthermore, Mask R-CNN provided an increase in accuracy based on by adding a new mask branch. However, the disadvantage was also obvious: its detection speed was only 5 fps and there was a delay with the agricultural picking robots running at high speed. However, in slow picking, its effect was obviously remarkable at the development stages with high recognition accuracy. Since the ZED camera’s PERFORMANCE format was used, the resolution of the pictures it took was reduced compared to that of a regular camera. Therefore, while detecting, the dark leaves of shadows were detected as dark pears due to the influence of light. In this respect, the dataset accuracy needs to be improved.
However, in this study, the ranging module was not added, and only the ZED camera was used to make RGBA datasets. The ZED camera measured the distance through the depth point cloud. In future research, adding the comparison of the ranging module can further contribute to the development of agricultural robots for complex orchard work such as robotic picking machines using an end-effector or manipulator.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}