
Noise2Kernel: Adaptive Self-Supervised Blind Denoising Using a Dilated Convolutional Kernel Architecture


Abstract
:1. Introduction
- We propose a dilated convolutional invariant network using a donut-shaped kernel and dilated convolutional layers. We no longer need a special training scheme (e.g., random masking) for blind denoising with self-supervision loss.
- We propose an adaptive self-supervision loss, which is the pixel-level nonlinear energy, to suppress incorrect learning from unconventional noise. We demonstrate that the proposed adaptive loss is highly effective on corrupted noisy images (for example, images with speckle noise, salt-and-pepper noise, and fusion noise) without any prior knowledge of the noise model.
- We demonstrate that the total variation regularization term can help to restore the pixel-wise artifact, which is a drawback of the proposed method.
2. Related Work
2.1. Conventional Denoising Methods
2.2. Non-Blind Denoising Methods
2.3. Blind Denoising Methods
3. Method
3.1. Formulations
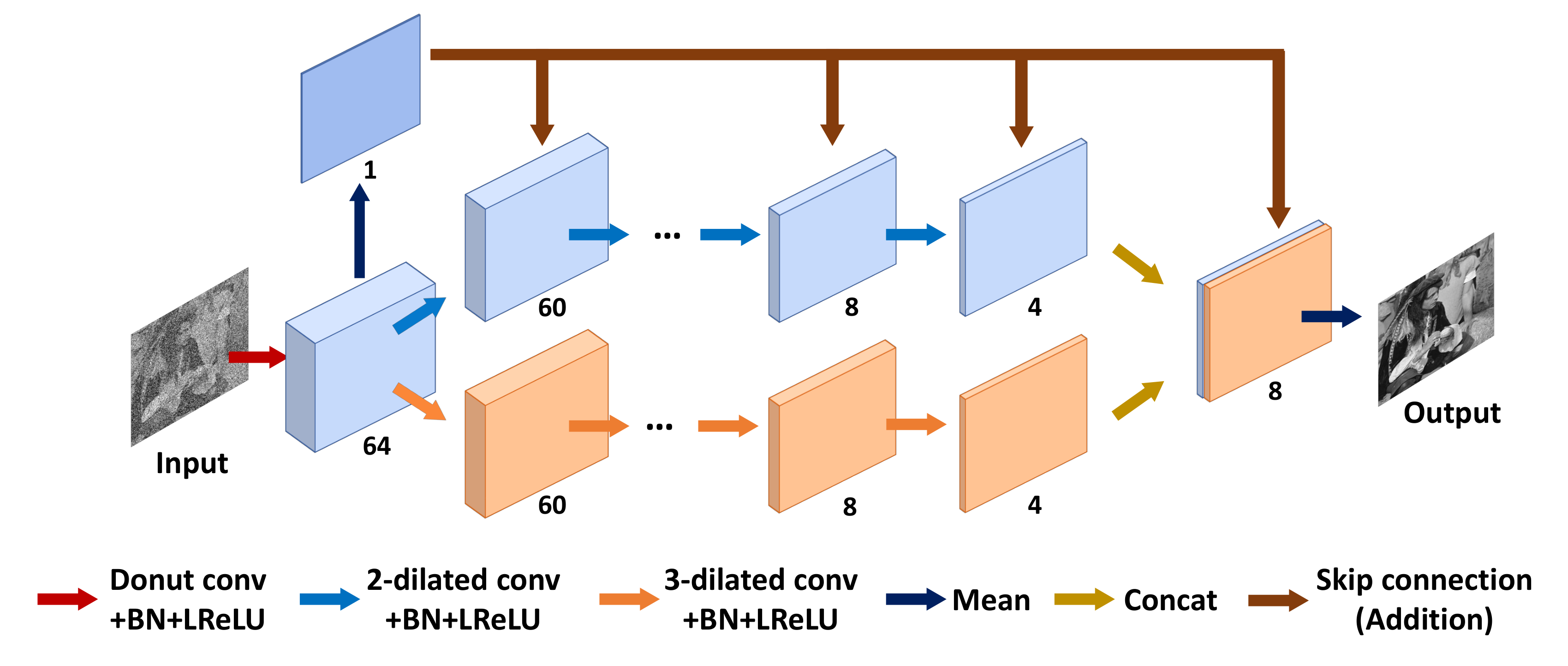
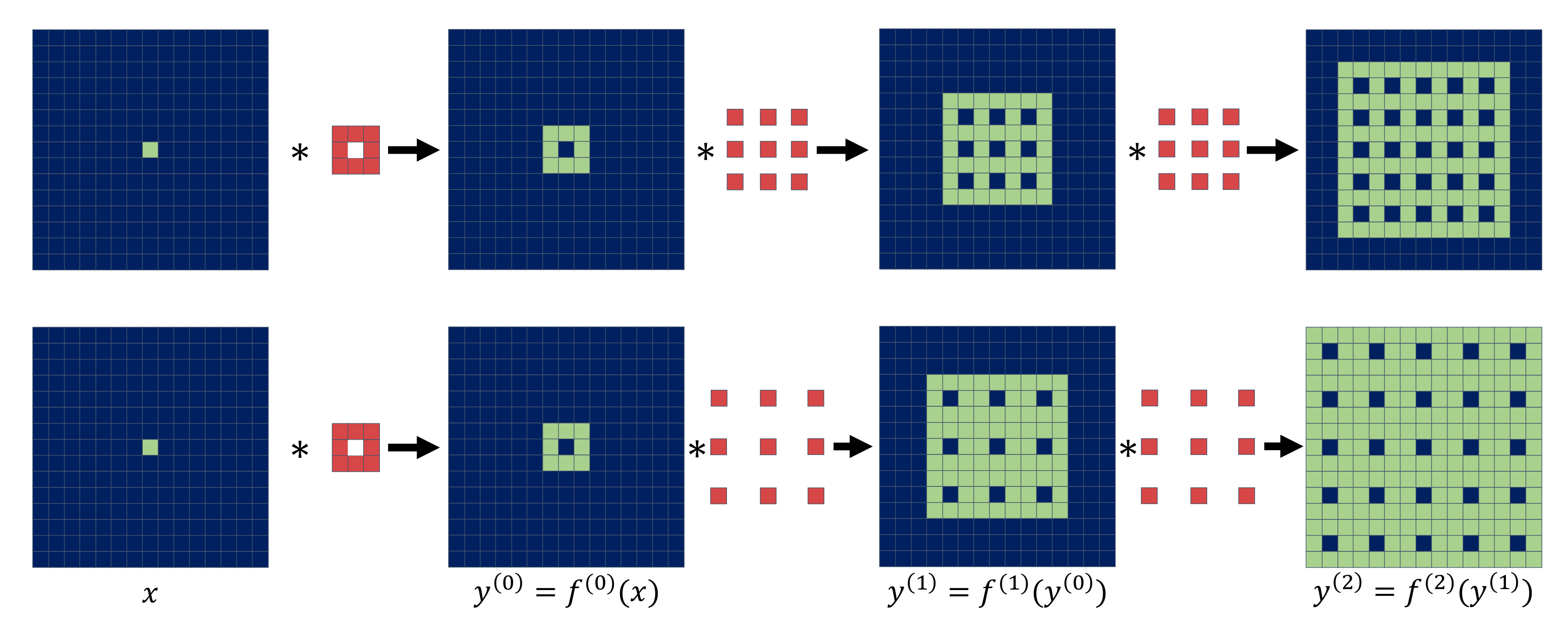
3.2. Dilated Convolutional - Network
3.3. Adaptive Self-Supervision Loss
4. Results
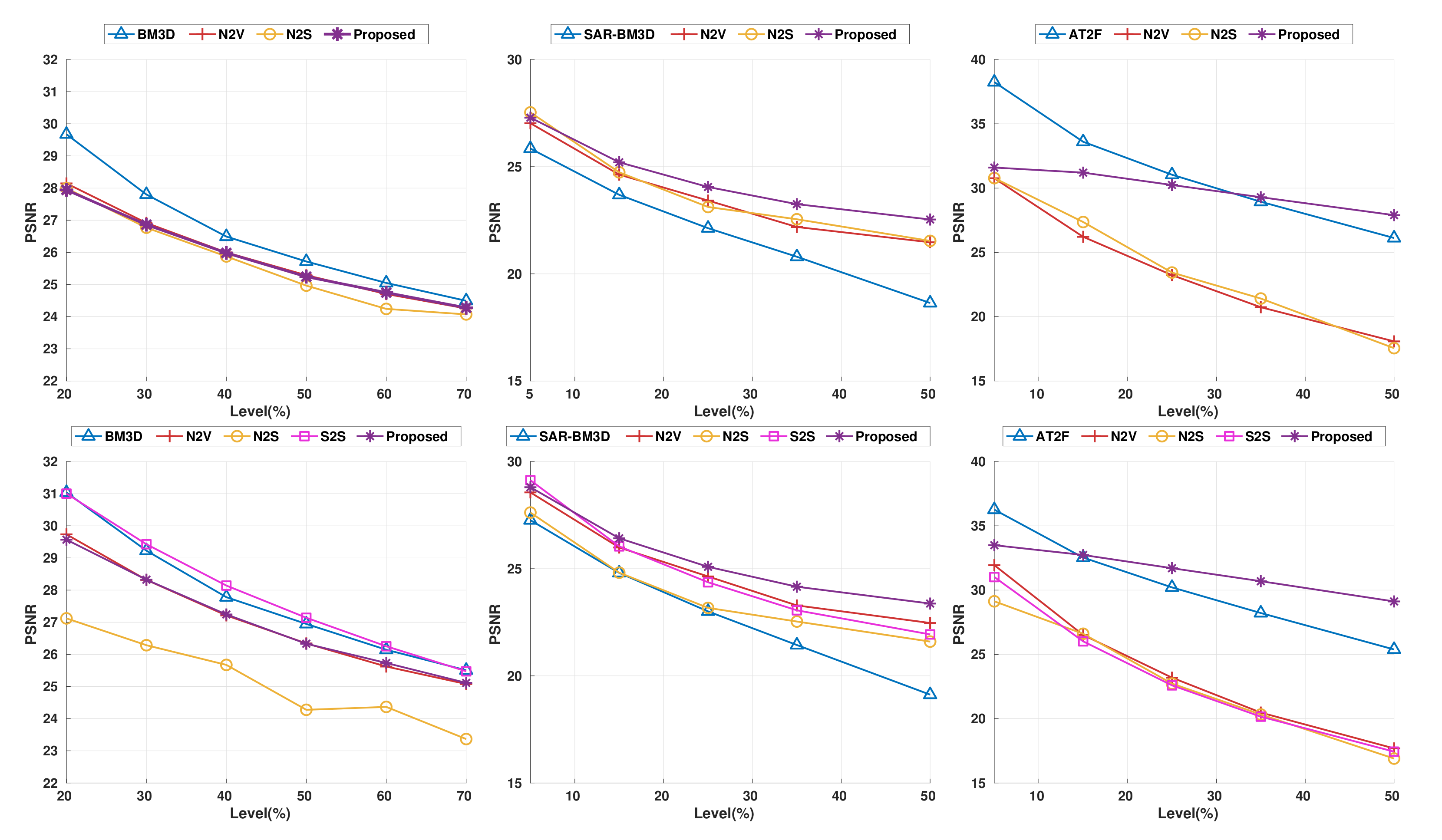
4.1. Denoising Results on Known Noise Models
4.1.1. Additive White Gaussian Noise (AWGN)
4.1.2. Speckle Noise
4.1.3. Salt-and-Pepper Noise
4.2. Denoising Results on Fusion Noise (Unknown Noise Statistics)
4.3. Ablation Study
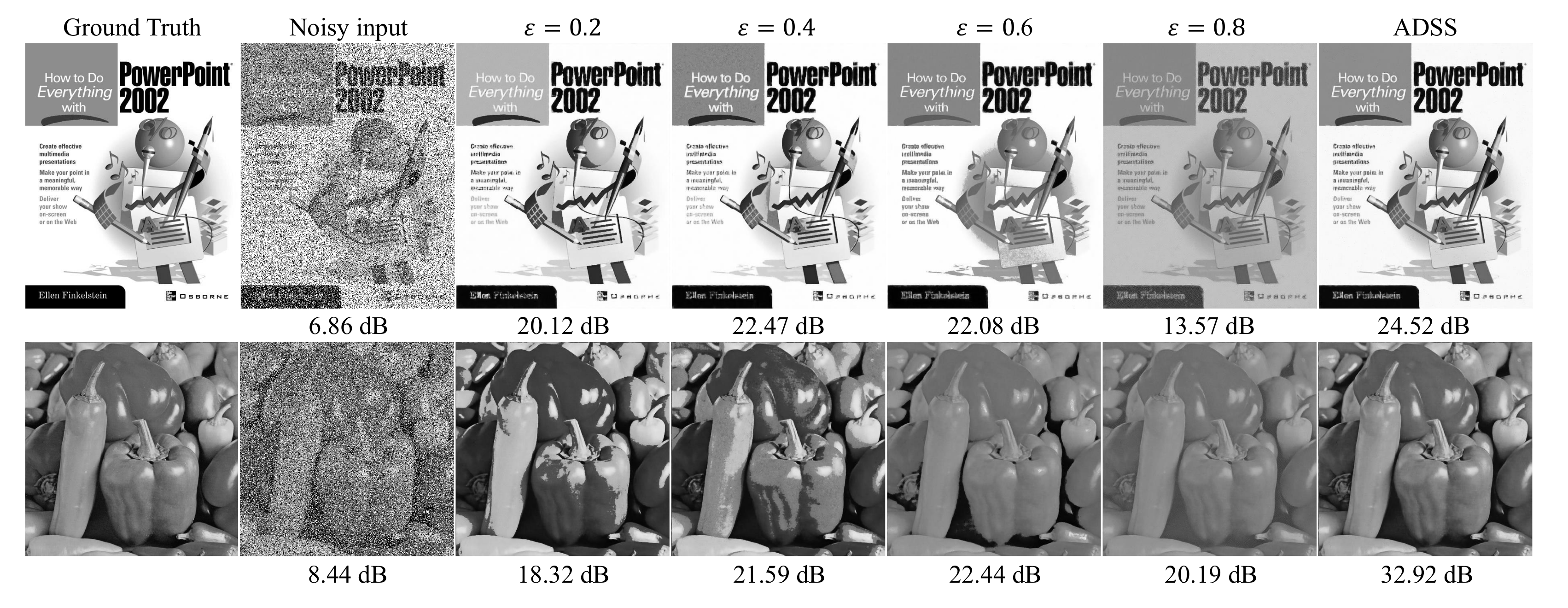
4.4. Analysis for ADSS
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 60–65. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G.; Zisserman, A. Non-local sparse models for image restoration. In Proceedings of the IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2272–2279. [Google Scholar]
- Dong, W.; Zhang, L.; Shi, G.; Li, X. Nonlocally centralized sparse representation for image restoration. IEEE Trans. Image Process. 2013, 22, 1620–1630. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X. Weighted nuclear norm minimization with application to image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2862–2869. [Google Scholar]
- Minh Quan, T.; Grant Colburn Hildebrand, D.; Lee, K.; Thomas, L.A.; Kuan, A.T.; Allen Lee, W.C.; Jeong, W.K. Removing Imaging Artifacts in Electron Microscopy using an Asymmetrically Cyclic Adversarial Network without Paired Training Data. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Varga, D. No-reference video quality assessment using multi-pooled, saliency weighted deep features and decision fusion. Sensors 2022, 22, 2209. [Google Scholar] [CrossRef] [PubMed]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lefkimmiatis, S. Universal denoising networks: A novel CNN architecture for image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3204–3213. [Google Scholar]
- Lehtinen, J.; Munkberg, J.; Hasselgren, J.; Laine, S.; Karras, T.; Aittala, M.; Aila, T. Noise2Noise: Learning Image Restoration without Clean Data. In Proceedings of the International Conference on International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; Volume 80, pp. 2965–2974. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep image prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9446–9454. [Google Scholar]
- Krull, A.; Buchholz, T.O.; Jug, F. Noise2Void-learning denoising from single noisy images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 2129–2137. [Google Scholar]
- Batson, J.; Royer, L. Noise2Self: Blind denoising by self-supervision. In Proceedings of the International Conference on International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 524–533. [Google Scholar]
- Quan, Y.; Chen, M.; Pang, T.; Ji, H. Self2Self With Dropout: Learning Self-Supervised Denoising From Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 1890–1898. [Google Scholar]
- Vogel, C.R.; Oman, M.E. Iterative methods for total variation denoising. SIAM J. Sci. Comput. 1996, 17, 227–238. [Google Scholar] [CrossRef]
- Vese, L.A.; Osher, S.J. Modeling textures with total variation minimization and oscillating patterns in image processing. J. Sci. Comput. 2003, 19, 553–572. [Google Scholar] [CrossRef]
- Vese, L.A.; Osher, S.J. Image denoising and decomposition with total variation minimization and oscillatory functions. J. Math. Imaging Vis. 2004, 20, 7–18. [Google Scholar] [CrossRef] [Green Version]
- Getreuer, P. Rudin-Osher-Fatemi total variation denoising using split Bregman. Image Process. Line 2012, 2, 74–95. [Google Scholar] [CrossRef]
- Tomasi, C.; Manduchi, R. Bilateral filtering for gray and color images. In Proceedings of the International Conference on Computer Vision IEEE, Bombay, India, 7 January 1998; pp. 839–846. [Google Scholar]
- Djurović, I. BM3D filter in salt-and-pepper noise removal. EURASIP J. Image Video Process. 2016, 2016, 13. [Google Scholar] [CrossRef] [Green Version]
- Parrilli, S.; Poderico, M.; Angelino, C.V.; Verdoliva, L. A nonlocal SAR image denoising algorithm based on LLMMSE wavelet shrinkage. IEEE Trans. Geosci. Remote Sens. 2012, 50, 606–616. [Google Scholar] [CrossRef]
- Wohlberg, B. SPORCO: A Python package for standard and convolutional sparse representations. In Proceedings of the Python in Science Conference, Austin, TX, USA, 10–16 July 2017; pp. 1–8. [Google Scholar]
- Bao, C.; Cai, J.F.; Ji, H. Fast sparsity-based orthogonal dictionary learning for image restoration. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 3384–3391. [Google Scholar]
- Bao, C.; Ji, H.; Quan, Y.; Shen, Z. Dictionary learning for sparse coding: Algorithms and convergence analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1356–1369. [Google Scholar] [CrossRef] [PubMed]
- Elad, M.; Aharon, M. Image denoising via sparse and redundant representations over learned dictionaries. IEEE Trans. Image Process. 2006, 15, 3736–3745. [Google Scholar] [CrossRef] [PubMed]
- Papyan, V.; Romano, Y.; Sulam, J.; Elad, M. Convolutional dictionary learning via local processing. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5296–5304. [Google Scholar]
- Mao, X.; Shen, C.; Yang, Y.B. Image Restoration Using Very Deep Convolutional Encoder-Decoder Networks with Symmetric Skip Connections. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 2802–2810. [Google Scholar]
- Lefkimmiatis, S. Non-local color image denoising with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3587–3596. [Google Scholar]
- Laine, S.; Karras, T.; Lehtinen, J.; Aila, T. High-quality self-supervised deep image denoising. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 6968–6978. [Google Scholar]
- Xu, J.; Huang, Y.; Cheng, M.M.; Liu, L.; Zhu, F.; Xu, Z.; Shao, L. Noisy-As-Clean: Learning Self-supervised Denoising from Corrupted Image. IEEE Trans. Image Process. 2020, 29, 9316–9329. [Google Scholar] [CrossRef] [PubMed]
- Moran, N.; Schmidt, D.; Zhong, Y.; Coady, P. Noisier2Noise: Learning to Denoise from Unpaired Noisy Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12064–12072. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Singh, V.; Dev, R.; Dhar, N.K.; Agrawal, P.; Verma, N.K. Adaptive type-2 fuzzy approach for filtering salt and pepper noise in grayscale images. IEEE Trans. Fuzzy Syst. 2018, 26, 3170–3176. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]
- Plotz, T.; Roth, S. Benchmarking denoising algorithms with real photographs. In Proceedings of the IEEE Transactions on Pattern Analysis and Machine Intelligence, Honolulu, HI, USA, 21–26 July 2017; pp. 1586–1595. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
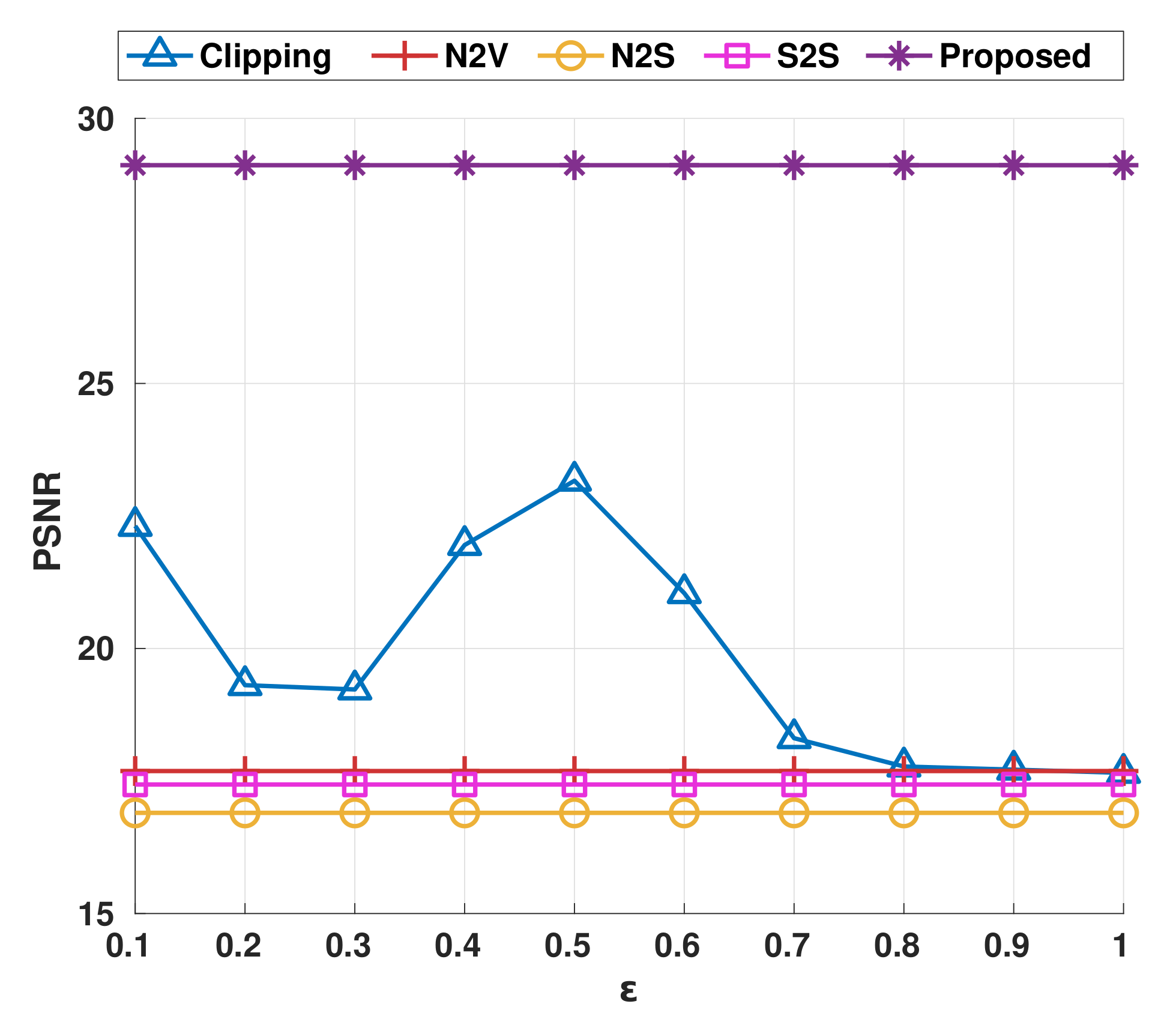{kind=link}
| Noise Level | = 25, = 5, d = 5 | = 25, = 5, d = 25 | = 25, = 25, d = 5 | = 25, = 25, d = 25 | ||||
|---|---|---|---|---|---|---|---|---|
| Method\Metric | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM |
| N2C | 26.99 | 0.7588 | 26.24 | 0.7303 | 24.68 | 0.6673 | 23.96 | 0.6353 |
| N2V | 24.61 | 0.6817 | 20.96 | 0.5908 | 21.88 | 0.5940 | 19.29 | 0.5111 |
| N2S | 24.42 | 0.6789 | 21.16 | 0.5879 | 21.49 | 0.5727 | 19.03 | 0.4896 |
| N2K (ours) | 25.28 | 0.6892 | 24.52 | 0.6435 | 22.42 | 0.5580 | 21.46 | 0.4869 |
| N2K+TV (ours) | 25.13 | 0.6853 | 24.42 | 0.6513 | 22.61 | 0.6043 | 21.86 | 0.5673 |
| Noise Level | = 50,= 5,= 5 | = 50,= 5,= 25 | = 50,= 25,= 5 | = 50,= 25,= 25 | ||||
| Method\Metric | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM |
| N2C | 25.21 | 0.6782 | 24.38 | 0.6391 | 23.85 | 0.6225 | 22.96 | 0.5810 |
| N2V | 22.64 | 0.5930 | 19.83 | 0.5337 | 20.57 | 0.5444 | 18.48 | 0.4794 |
| N2S | 22.00 | 0.5746 | 19.71 | 0.4999 | 19.95 | 0.5141 | 18.41 | 0.4404 |
| N2K (ours) | 23.40 | 0.6038 | 22.55 | 0.5471 | 20.49 | 0.5063 | 19.73 | 0.4321 |
| N2K+TV (ours) | 23.40 | 0.6149 | 22.67 | 0.5786 | 20.59 | 0.5635 | 19.82 | 0.5195 |
| Noise Level | = 25, = 5, d = 5 | = 25, = 5, d = 25 | = 25, = 25, d = 5 | = 25, = 25, d = 25 | ||||
|---|---|---|---|---|---|---|---|---|
| Method\Metric | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM |
| N2C | 28.06 | 0.7749 | 27.23 | 0.7476 | 25.61 | 0.6918 | 24.79 | 0.6615 |
| N2V | 25.51 | 0.7074 | 20.93 | 0.6089 | 22.59 | 0.6199 | 19.32 | 0.5335 |
| N2S | 24.06 | 0.6683 | 20.40 | 0.5805 | 21.34 | 0.5797 | 18.68 | 0.4971 |
| S2S | 25.72 | 0.7256 | 20.88 | 0.5951 | 22.58 | 0.6252 | 19.27 | 0.5149 |
| N2K (ours) | 26.42 | 0.7169 | 25.46 | 0.6674 | 23.25 | 0.5782 | 22.19 | 0.4992 |
| N2K+TV (ours) | 26.26 | 0.7163 | 25.33 | 0.6791 | 23.52 | 0.6372 | 22.67 | 0.5966 |
| Noise Level | = 50,= 5,= 5 | = 50,= 5,= 25 | = 50,= 25,= 5 | = 50,= 25,= 25 | ||||
| Method\Metric | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM |
| N2C | 26.16 | 0.7029 | 25.19 | 0.6631 | 24.66 | 0.6497 | 23.62 | 0.6082 |
| N2V | 23.01 | 0.6192 | 19.67 | 0.5572 | 20.88 | 0.5699 | 18.31 | 0.5005 |
| N2S | 21.65 | 0.5714 | 19.07 | 0.4994 | 19.26 | 0.5103 | 17.76 | 0.4438 |
| S2S | 23.31 | 0.6441 | 19.64 | 0.5361 | 21.04 | 0.5725 | 18.35 | 0.4748 |
| N2K (ours) | 24.24 | 0.6305 | 23.22 | 0.5708 | 21.20 | 0.5248 | 20.38 | 0.4438 |
| N2K+TV (ours) | 24.24 | 0.6471 | 23.35 | 0.6076 | 21.31 | 0.5944 | 20.49 | 0.5452 |
| Model | Baseline | ADSS | ADSS + TV | |||
|---|---|---|---|---|---|---|
| Noise Level\Metric | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM |
| = 25, = 5, d = 5 | 24.54 | 0.6761 | 25.28 | 0.6892 | 25.13 | 0.6853 |
| = 25, = 5, d = 25 | 20.93 | 0.5577 | 24.52 | 0.6435 | 24.42 | 0.6513 |
| = 25, = 25, d = 5 | 21.66 | 0.5679 | 22.42 | 0.5580 | 21.61 | 0.6043 |
| = 25, = 25, d = 25 | 19.22 | 0.4850 | 21.46 | 0.4869 | 21.86 | 0.5673 |
| = 50, = 5, d = 5 | 22.54 | 0.5872 | 23.40 | 0.6038 | 23.40 | 0.6149 |
| = 50, = 5, d = 25 | 19.71 | 0.5162 | 22.55 | 0.5471 | 22.67 | 0.5786 |
| = 50, = 25, d = 5 | 20.59 | 0.5390 | 20.49 | 0.5063 | 20.59 | 0.5635 |
| = 50, = 25, d = 25 | 19.22 | 0.4850 | 21.46 | 0.4869 | 21.86 | 0.5673 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K.; Jeong, W.-K. Noise2Kernel: Adaptive Self-Supervised Blind Denoising Using a Dilated Convolutional Kernel Architecture. Sensors 2022, 22, 4255. https://doi.org/10.3390/s22114255
Lee K, Jeong W-K. Noise2Kernel: Adaptive Self-Supervised Blind Denoising Using a Dilated Convolutional Kernel Architecture. Sensors. 2022; 22(11):4255. https://doi.org/10.3390/s22114255
Chicago/Turabian StyleLee, Kanggeun, and Won-Ki Jeong. 2022. "Noise2Kernel: Adaptive Self-Supervised Blind Denoising Using a Dilated Convolutional Kernel Architecture" Sensors 22, no. 11: 4255. https://doi.org/10.3390/s22114255
APA StyleLee, K., & Jeong, W.-K. (2022). Noise2Kernel: Adaptive Self-Supervised Blind Denoising Using a Dilated Convolutional Kernel Architecture. Sensors, 22(11), 4255. https://doi.org/10.3390/s22114255