1. Introduction
COVID-19 is a well-known contagious infectious disease caused by the new Severe Acute Respiratory Syndrome Coronavirus 2 (SARS-CoV-2) [
1]. Since its first detection in 2019, new variants of SARS-CoV-2 have emerged [
2], such as the United Kingdom (UK) variant (B.1.1.7), the Brazilian variants (P.1, P.2, and N.9), the South Africa variant (B.1.325) [
3,
4], omicron (B.1.1.529), firstly detected in Africa, ihu (B.1.640.2), detected in France, the recent hybrid variant deltacron (AY.4/BA.1), which is a combination of the variants delta and omicron, and the newer recombination of variants BA.1 and BA.2 of the omicron variant (named XE), firstly detected in the UK in April 2022. Current official data, from 2 June 2022, provided by the Center for Systems Science and Engineering (CSSE) at John Hopkins University (JHU), shows that COVID-19 has affected more than 531 million people worldwide, killing almost 6.3 million people, including more than 666,800 Brazilians, 41,100 Canadians, and 35,600 Ecuadorians [
5].
It is a fact that massive vaccination (reaching more than 90% in some countries) has prevented or attenuated the effects of this infection, strongly decreasing the number of deaths [
6]. However, the COVID-19 pandemic is not over yet, as evidenced by recent lockdowns in Shanghai and Beijing. In addition, the average worldwide vaccinated population is only 60% (some countries have vaccinated less than 10% of their populations) [
7], and the current number of deaths is more than 3000 people daily [
5].
Depending on the SARS-CoV-2 variant, the symptoms of COVID-19 can include fever or chills, cough, shortness of breath or difficulty breathing, headache, muscle or body aches, dizziness or fatigue, sore throat, congestion or runny nose, new loss of smell or taste, nausea, vomiting, diarrhoea, abdominal pain or anorexia, confusion or impaired consciousness, and rash, among others [
8]. Currently, according to the Centers for Disease Control and Prevention (CDC), persons infected with the omicron variant, which represents 99.8% of infection worldwide, can present with symptoms similar to previous variants.
These infected persons may be asymptomatic or symptomatic, the latter varying among mild, severe, and critical. There are risk factors that increase the chance of developing the severe and critical version of the disease, such as advanced age, smoking, and comorbidities (diabetes, hypertension, cardiovascular disease, obesity, chronic lung disease, and kidney disease) [
8]. Reverse-Transcription Polymerase Chain Reaction (RT-PCR) is the gold-standard to detect SARS-CoV-2 infection [
9]; however, its high cost limits access in countries such as Ecuador and Brazil, where this exam costs between USD 45 and 65 (and more than USD 100 in Canada and other countries). In addition, RT-PCR is only more reliable when the sample is obtained up to three days after getting the infection, and if there is a high demand, test results can be delayed by some days.
Due to the high transmission rate of the omicron variant (much higher than the previous ones), specific measures are still needed to reduce the spread of the pandemic, such as alternative diagnostic methods for asymptomatic and symptomatic individual detection using Artificial Intelligence (AI) [
10]. It is worth mentioning that about 40 to 45% of individuals with COVID-19 are asymptomatic [
11], which is a big concern to prevent the virus’s spread, as such individuals keep transmitting the virus without realizing that they are.
Thus, a very strong effort has also been made by researchers and industries worldwide to develop low-cost wearable devices and user-friendly mobile applications to detect the symptoms of COVID-19 using information from some biomedical signals and markers, such as cough, heart rate variability, blood pressure, body temperature, and oxygen saturation level [
10,
12,
13]. However, these biomedical data are not decisive to confirm infection by COVID-19, but could open avenues to be used as a screening tool for telemedicine or remote monitoring. For instance, although the sound of forced cough is able to provide a COVID-19 diagnosis, such as claimed by [
13,
14], another study [
15] computed that only 59% of people infected by COVID-19 have a dry cough. On the other hand, the heart rate variability is another separate factor able to indicate possible infection by the virus even in asymptomatic people [
16,
17].
Body temperature is measured to check fever in individuals, which is another symptom that affects 99% of symptomatic individuals with COVID-19, although it does not occur in asymptomatic ones [
15]. Another symptom of COVID-19 is the decrease in oxygen saturation level in blood (abbreviated as SpO2—peripheral capillary oxygen saturation), and when it is below 95%, this may cause serious health issues; hence, there is a need to regularly monitor it. However, other respiratory diseases such as cold and flu also reduce the SpO2 level within the range 90–95% without causing any major health concerns.
The use of Artificial Intelligence (AI) based on biomedical data for the diagnosis of respiratory diseases is quite recent. For instance, ref. [
18] presented a systematic review of works that address the diagnosis of pneumonia through several biomedical signals (including the most common ones: body temperature, abnormal breathing, and cough) and using different techniques of AI, such as Logistic Regression (LR), Deep Learning (DL), Least Absolute Shrinkage and Selection Operation (LASSO), Random Forest, Classification and Regression Trees (CART), Support Vector Machine (SVM), fuzzy logic, and k-Nearest Neighbour (K-NN), among others. The study found that AI could help to reduce the misdiagnosis of COVID-19, since there is significant overlap in COVID-19’s and other respiratory diseases’ symptoms.
Recent research has been conducted using samples of sounds from individuals to infer infection by COVID-19 [
19,
20,
21,
22,
23]. For instance, in [
22], a public crowdsourced Coswara dataset, consisting of coughing, breathing, sustained vowel phonation, and one to twenty sounds recorded on a smartphone, was used for this purpose. In another study, data from the INTERSPEECH 2021 Computational Paralinguistics (ComPaRe) challenge were used to infer COVID-19, in a binary classification, through coughing sounds and speech using two subsets from the Cambridge COVID-19 Sound database [
22]. The first subset is the COVID-19 Cough Sub-Challenge (CCS), which consists of cough sounds from 725 audio recordings, and the second subset is the COVID-19 Speech Sub-Challenge (CSS), with only speech sounds of 893 audio recordings. In another study [
21], an analysis of a crowdsourced dataset of respiratory sounds was performed to correctly classify healthy and COVID-19 sounds using 477 handcrafted features, such as Mel Frequency Cepstral Coefficients (MFCCs), zero-crossing, and spectral centroid, among others. In [
23], an audio texture analysis was performed on three different signal modalities of COVID-19 sounds (cough, breath, and speech signal), using Local Binary Patterns (LBPs) and Haralick’s method as the feature extraction methods. Unlike cough sounds, another study [
24] used biomedical data (body temperature, heart rate, and SpO2), collected from 1085 quarantined healthy and unhealthy individuals, through a wearable device, to infer COVID-19 infection.
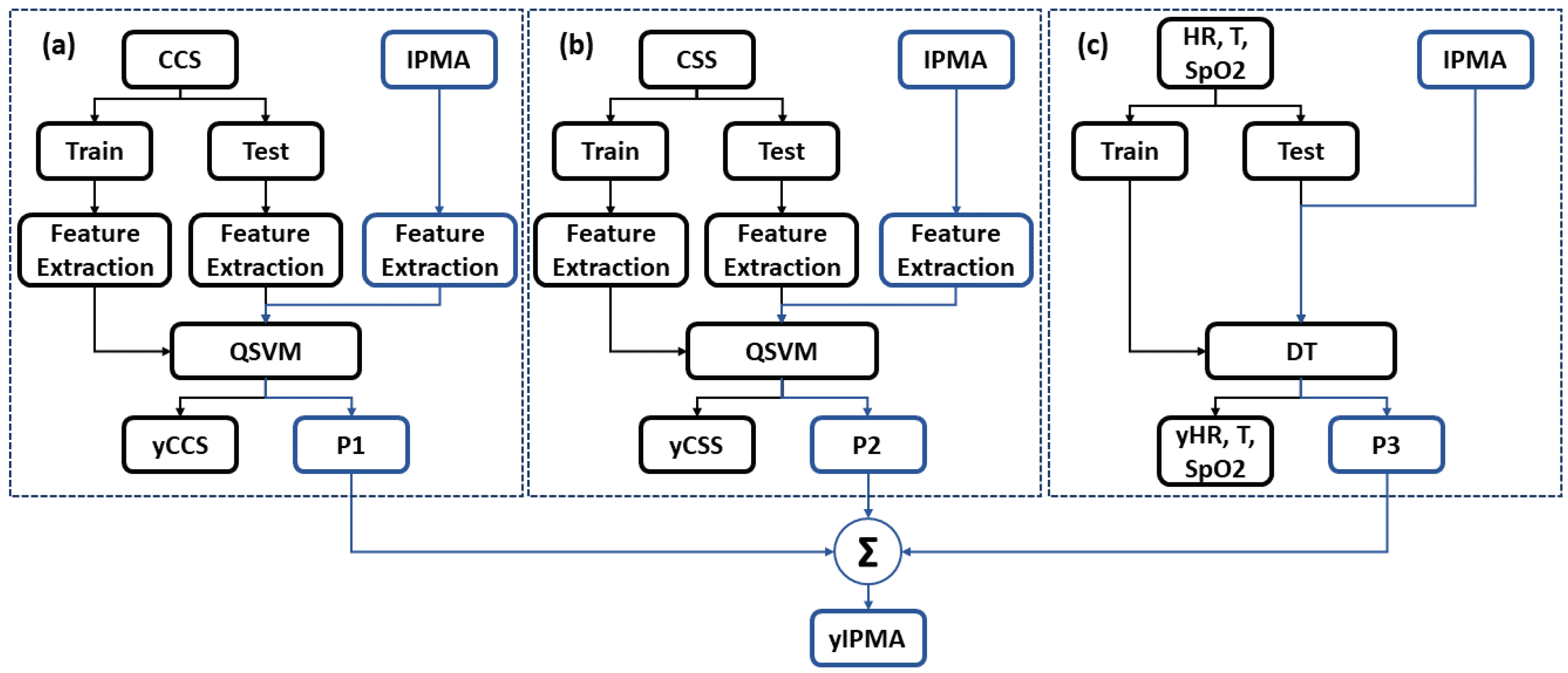
In contrast with the aforementioned studies, the all-in-one Integrated Portable Medical Assistant (IPMA) equipment introduced here uses all these measurements taken together from the individual to improve the diagnosis accuracy of a possible infection due to SARS-CoV-2, instead of using isolated measurements. Thus, this work introduces the IPMA, which is a piece of non-invasive, real-time, any-time equipment for large-scale COVID-19 screening that can be used for daily screening of large populations, such as students at school, employees at work, and other people in general public areas, such as parks, public transit, and more. The IPMA uses four bio-markers (cough, heart rate variability, oxygen saturation level, and body temperature) to infer SARS-CoV-2 infection through machine learning algorithms.
It is worth mentioning that some wearable devices (such as smartwatches and fitness bands), as well as mobile apps have been launched to measure cough, heart rate, body temperature, and oxygen saturation levels. Yet, some of these apps and devices lack clinical validity due to their inaccurate measurements without significant correlation with the measurements of certified clinical devices [
25]. In fact, these devices are usually sold as approximate information products that show discrete measurements, indicating that their purpose is to be used as preventive alert devices, to “increase users’ awareness of their general well-being” [
26], having no clinical validation or medical certification, nor even indicating the possibility of COVID-19 infection (as they do not have embedded algorithms to do that). In addition, such wearable devices present inconsistency in the quality of data acquisition, and there is no standardization for data collection or sensor placement [
27]. Unlike these wearable devices and apps, the IPMA houses medically certified devices and takes their measurements in a row to be stored in a database. In addition, as previously mentioned, although some recent studies have used separately, in different research, human sounds [
19,
20,
28,
29,
30] and some biomedical data [
21] to infer infection by COVID-19, in our study, we used all these signals together to be input into machine learning algorithms, in order to gain a higher accuracy rate. Furthermore, we verified the usability of our equipment with volunteers in terms of the device itself, by using the System Usability Scale (SUS), and of the user interface, by using the Post Study System Usability Questionnaire (PSSUQ).
Goals
There were three main goals in this study. First was the development of multimodal equipment to automatically acquire data from medically certified devices, without opening them, thus keeping their medical certification, using linear actuators to turn them on, as well as cameras and an algorithm based on a VGG16 pre-trained network to read the devices’ displays. Second was the development of machine learning algorithms to help infer COVID-19 infection. Third was the creation of a database with collected biomedical measurements, which can be further used to infer other respiratory diseases.
4. Evaluation Metrics Applied to the IPMA
The methodology used to evaluate the IPMA is based on its ease of use and if the GUI is engaging for the volunteer. In order to evaluate the IPMA and the GUI, two scales were used here, which were the System Usability Scale (SUS) and the Post Study System Usability Questionnaire (PSSUQ).
The SUS is a methodology to evaluate the usability, effectiveness, and efficiency of a system, which was developed by Brooke in 1986 as a 10-question survey [
34]. In the SUS, the volunteer gives a score for each question, ranging from 1 to 5. The value 1 means the volunteer totally disagrees with the sentence being asked, whereas 5 means the individual totally agrees. The SUS sentences are shown below [
35]:
I think that I would like to use this system frequently.
I found the system unnecessarily complex.
I thought the system was easy to use.
I think that I would need the support of a technical person to be able to use this system.
I found the various functions in this system were well integrated.
I thought there was too much inconsistency in this system.
I would imagine that most people would learn to use this system very quickly.
I found the system very cumbersome to use.
I felt very confident using the system.
I needed to learn a lot of things before I could get going with this system.
The way the sentences are organized has even questions, with a positive view of the system, and odd questions, with a negative view. There is a similar odd question for each even question, but written in a different way. The Total SUS score (T) is calculated using Equation (
1), where
p is the score of each question. Note that the parity of the question influences its contribution to the total score.
Although the SUS scale ranges from 0 to 100, it is not a percentile scale; there is a graph used to correlate the percentile scale with the SUS score, with the average (50%) represented by the score 68 [
36]. In addition, according to [
37], scores of the SUS above average are associated with “Good” products.
As previously mentioned, another important aspect of usability that should be evaluated is the user experience with the computational application, which is addressed by the PSSUQ. This scale is a 19-element standardized questionnaire, which can be scored from 1 (“I strongly agree”) to 7 (“I totally disagree”), 4 being “neutral”. It is used to evaluate the user experience with computer systems and applications and was developed by IBM in 1988 from a project called System Usability Metrics (SUMS) [
36]. It follows a 7-point Likert scale, and the result is the average score of the questions.
An interesting aspect of this scale is that it can be split into three subcategories to evaluate three different aspects of the user experience, which are the System Usefulness (SYSUSE), Information Quality (INFOQUAL), and Interface Quality (INTERQUAL). The SYSUSE is calculated by averaging the results from Questions 1 to 6, whereas the INFOQUAL and INTERQUAL average the results for Questions 7 to 12 and 13 to 15, respectively. Additionally, there is the overall score, which is the average of all questions, including the 16th question.
In the PSSUQ, lower scores mean better evaluations, thus indicating a higher level of usability. The neutral value is 4, whereas values closer to 1 represent better usability and closer to 7 represent worse usability. The sentences in the PSSUQ scale are [
38]:
Overall, I am satisfied with how easy it is to use this system.
It was simple to use this system.
I was able to complete the tasks and scenarios quickly using this system.
I felt comfortable using this system.
It was easy to learn to use this system.
I believe I could become productive quickly using this system.
The system gave error messages that clearly told me how to fix problems.
Whenever I made a mistake using the system, I could recover easily and quickly.
The information (such as online help, on-screen messages, and other documentation) provided with this system was clear.
It was easy to find the information I needed.
The information was effective in helping me complete the tasks and scenarios.
The organization of information on the system screens was clear.
The interface of this system was pleasant.
I liked using the interface of this system.
This system has all the functions and capabilities I expect it to have.
Overall, I am satisfied with this system.
Evaluation Protocol
Following [
39], testing a large number of participants does not necessarily provide much more information than testing just a few people, since even a few participants are able to find most of the usability issues. According to them, a usability test performed by five users should be enough to detect up to 80% of the potential problems of a product or website. Thus, the probability of a user finding an issue is about 31%. After those five users, the same findings continue to be observed repeatedly without discovering anything new. Thus, based on their study, we selected 18 people for the tests of each IPMA (from Ecuador and Brazil), resulting in a total of 36 individuals.
In the evaluations, the volunteer had to follow the instructions to have his/her biological data collected, and after using the equipment, he/she filled out the SUS and PSSUQ forms. Therefore, it was possible to know their opinion about the usability of the IPMA. Due to the current sanitary restrictions, the equipment was only evaluated with volunteers that did not have ongoing COVID-19 infection, which means they were either recovered or had never had the disease. The evaluation protocol consists of the following steps:
Volunteers were given an explanation about the whole process of the use of the equipment.
They filled out a questionnaire that included their birthday, gender, and health questions.
The system asked the volunteer to open the IPMA’s door and make a 10 s forced cough.
Afterwards, the system asked the volunteer to speak a phonetically balanced sentence.
Next, the volunteer was informed that the system would take the measurements. The volunteer was asked to place his/her arm properly inside the IPMA. Then, measurements took place after pressing the start button
Once the measurements were finished, the IPMA asked the volunteer to remove his/her arm from the IPMA.
Further, the system acknowledged the volunteer and started the UV-C disinfection process.
Finally, the volunteer was asked to fill out two forms (SUS and PSSUQ).
6. Conclusions
This work introduced the all-in-one Integrated Portable Medical Assistant (IPMA), which is a piece of equipment that allows biomedical data acquisition from individuals, infected or not with COVID-19, through sounds of coughing and three biomedical signals (heart rate, oxygen saturation level, and body temperature) acquired from medically certified devices. The values of these biomedical data were obtained through their displays’ readings by cameras and using a 100% efficient VGG16 ANN. All these signals collected from the individual by the IPMA feed pre-trained machine learning algorithms (which achieved approximately ACC = 88.0% and AUC = 0.85 and ACC = 99% and AUC = 0.94, respectively, using QSVM and DT) to allow inferring possible COVID-19 infection, with 100% accuracy, thus indicating to the individual when it is time to seek medical care. It is important to say that although the data collected by the IPMA were all from individuals without COVID-19 infection, our machine learning algorithms showed a good performance to infer COVID-19 from different databases.
Regarding the evaluation from the individuals who used the IPMA, it was considered successful, since it achieved an average score over 68 on the SUS, which means the equipment was considered “above average” (or, in other words, good equipment). Additionally, the PSSUQ presented low scores for both IPMA versions, which means high overall usability.
It is worth mentioning that the IPMA has great advantages as it is a non-invasive, real-time, any-time equipment for large-scale data acquisition for screening and may be used for daily screening of students, workers, and people in public places, such as schools, jobs, and public transportation, to quickly alert that there are group outbreaks. Furthermore, due to its portability, it is suitable to be used in hospitals, in clinics, or at home. Additionally, the IPMA was designed to be user-friendly, with a comprehensive GUI, and safe, since it uses UV-C light to disinfect it.
With the widespread use of the IPMA and collection of data, a new database is being created, which will be quite useful for new studies about alternative parameters to infer COVID-19 infection and other respiratory diseases, mainly because, more than two years after its outbreak, COVID-19 is still strongly threatening the world with its new variants. Mobile applications (apps) were also developed here to allow the compilation of the main physiological signals captured by the equipment and, then, visualize them in mobile phones.
The IPMA was also proven to be functional, and the evaluations conducted with individuals showed that the measurements can be performed easily, while the results can be stored for further analysis and for machine learning training. As future works, we expect to use this equipment to evaluate other respiratory diseases, such as cold, flu, or pneumonia, by training the machine learning with more data.
Regarding a comparison between the IPMA with other equipment with the same purpose, this was not possible, since, as far as we know, there is no other equipment that tries to perform data acquisition from medically certified devices, create a database, and apply machine learning algorithms in the same way as we did here. Additionally, we tested our equipment with known scales to evaluate usability and user interface quality, in order to validate our research.
The limitations of our work are mainly the need for an AC outlet near the equipment to power the UV-C lamps, as well as the need for batteries for each medical device, since we could not power them directly with the main IPMA battery due to the risk of losing their medical certification. Additionally, the structure became bigger because of the need for linear actuators and cameras, as we could not obtain the measurement signals directly from the electronic board of the medically certified devices, to avoid losing their medical certification.
As future works, we plan to perform more trials in different geographical areas to collect more data and verify the usability with people of different regions. Furthermore, we will add some improvements to the user interface to make it more user-friendly and to improve the visualization in the mobile application. Finally, tests will be performed at public healthcare institutions to evaluate the use of the device.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







