1. Introduction
The submerged part of a ship’s hull is susceptible to biofouling in the form of pollutants or organisms such as water mosses and seagrass that attach themselves to the bottom and sides of the submerged surfaces. This phenomenon not only damages the surface of ships but also provides unwanted resistance during normal operation, resulting in inferior performance [
1,
2,
3]. In addition, when a ship enters a port, the various pollutants attached to the hull surface can contaminate the seawater in the port. In the case of ships traveling abroad, aquatic alien creatures that are transported to a different region can disrupt local marine ecosystems [
4]. Thus, hull surfaces must be cleaned periodically while ships are anchored in a port.
Conventional hull cleaning is performed by divers. Recently, however, studies have been conducted on cleaning hull surfaces using a remotely operated underwater vehicle (ROUV) [
5,
6,
7,
8,
9]. A human operator observes the submerged hull surface through a camera mounted on the ROUV and checks its condition. The ROUV is subsequently remotely controlled to clean the affected parts of the hull. However, autonomous hull cleaning without human intervention requires ROUVs capable of recognizing the hull condition. In addition, since the hull condition should be immediately fed back to the ROUV, the process of recognition must occur in real-time.
However, owing to underwater conditions, the images observed by an ROUV through its camera are not clear. In addition, the images may differ depending on the depth of operation, underwater conditions, and lighting; consequently, existing image-processing methods are insufficient for the accurate recognition of hull conditions. Therefore, this study proposes a classification method to recognize the hull condition using convolutional neural networks (CNNs) [
10] with images of the hull surface acquired through the ROUV camera. Based on the image, the hull condition is categorized into two classes: (1) positive class: the hull surface is contaminated enough to require cleaning; and (2) negative class: the hull surface is clean enough to not require cleaning.
When using CNN models, both models and training datasets are important. The models used in this study were trained using a publicly available dataset called ImageNet [
11]. Therefore, they cannot be used to classify hull surface conditions. Instead, we collected hull surface images under various underwater conditions using our ROUV. However, collecting underwater hull images is difficult because it requires permission from ship owners. In addition, less-than-optimal underwater conditions complicate the process of collecting the images of submerged hull surfaces. Therefore, in this study, we used a transfer learning [
12,
13] technique to retrain pretrained models for image classification to enable high accuracy with a small number of images. Furthermore, the required training time is short. However, several well-known pretrained models exist for image classification. These can present different classifications for the same image. To overcome this problem and increase accuracy, we used a soft voting ensemble [
14] technique comprising transfer-learned models. Finally, to the best of our knowledge, this is the first study on hull surface inspection using machine learning techniques.
The major contributions of this study are as follows:
The condition of the hull surface was classified with high accuracy by using CNN models with hull surface images.
Our own training dataset was obtained under various underwater conditions using the developed ROUV.
Transfer learning of the pretrained models was used to adapt the pretrained models to classification of the hull surface.
A higher accuracy was obtained using a soft voting ensemble technique comprising several transfer-learned models.
The remainder of this paper is organized as follows.
Section 2 describes previous related studies.
Section 3 describes the soft voting ensemble classifier used in this study, and
Section 4 describes the generation of the dataset used for training the CNNs.
Section 5 discusses the proposed method and experimental results. Finally,
Section 6 concludes the paper.
3. Architecture for the Classification of Underwater Hull Surface Condition
3.1. Problem Definition
The problem to be solved in this study is defined as follows:
Given a two-dimensional imageof hull surfaces that is input through the ROUV’s camera and labeled as clean (negative class) or unclean (positive class), define a binary classifierthat can classify the hull condition via image ,
where the output of indicates the probability that the input image is unclean. For a given threshold , if , is classified as unclean, and if , is classified as clean.
3.2. Soft Voting Ensemble Architecture
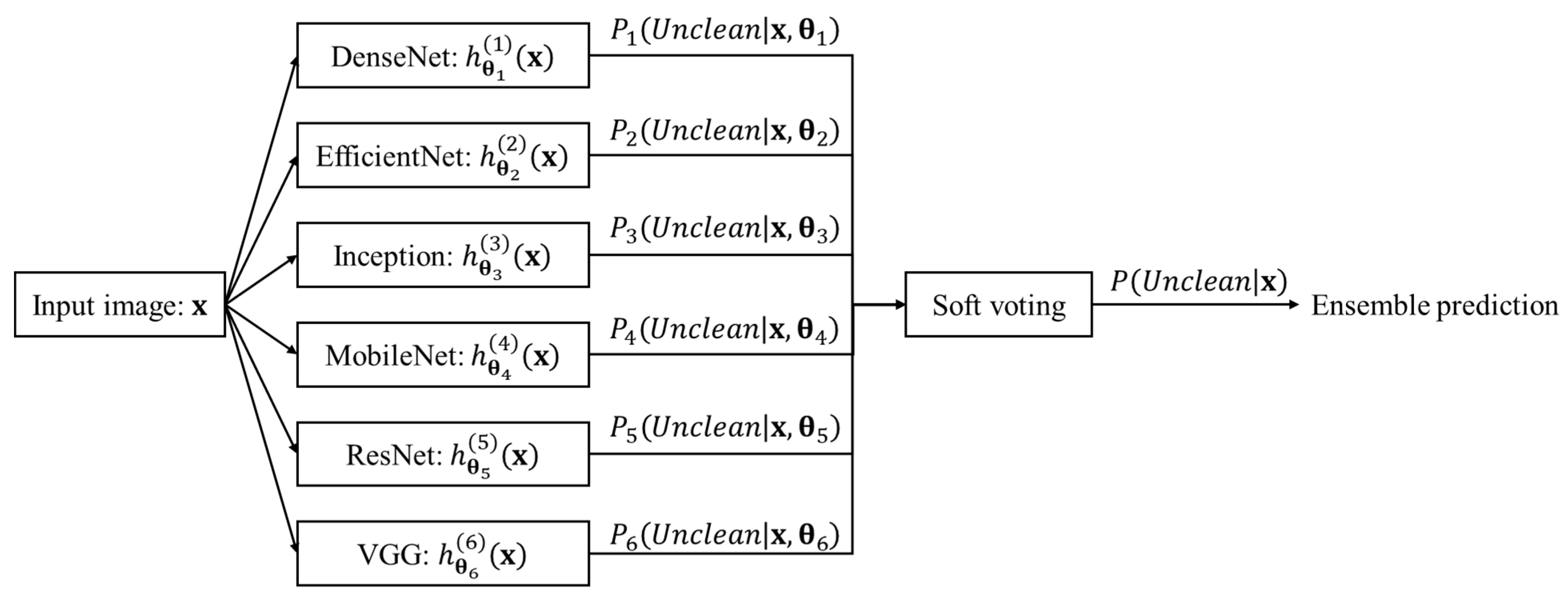
In this study, we defined a classifier using a soft voting ensemble of the well-known CNN models DenseNets [
46], EfficientNets [
47], Inceptions [
48,
49,
50], MobileNets [
51,
52,
53], ResNets [
54,
55], and VGGs [
56], as shown in
Figure 1. The soft voting ensemble classifier is a combination of multiple models. In these models, decisions are made by combining individual decisions based on probability values to specify that the data belong to a particular class. [
14] In the soft voting ensemble, predictions are weighted based on the classifier’s importance and merged to obtain the sum of weighted probabilities.
The classification method using the soft voting ensemble is as follows:
Step 1. Each of the six models is represented by Equation (1):
where
is the number representing each model participating in the soft voting,
represents the
-th model for classification,
is the weights of the
-th model,
is the input image, and
—the output value of the
-the model—is the probability that the input image
is clean. In this study,
represent DenseNet, EfficientNet, Inception, MobileNet, ResNet, and VGG, respectively.
Step 2. Each model is retrained with our dataset using transfer learning to determine the weights
. The dataset creation and transfer learning method are described in
Section 3.3 and
Section 4, respectively.
Step 3. is evaluated for each model. is the probability that input image x is clean by the -th classification model.
Step 4. By averaging all
s, the final prediction value
is evaluated using Equation (2):
Step 5. Finally, for a given threshold , image is classified as clean if .
Even if the number of models participating in soft voting changes, the overall process does not change. Only the number six in Equation (2) changes to the number of models.
3.3. Transfer Learning of the Pretrained Models
The optimal weights of the six models comprising the soft voting ensemble were selected using transfer learning of the pretrained models. Transfer learning [
12,
13] is a machine learning technique in which a model developed for a task is reused as the starting point for a model for a second task. The six models used in this study comprised 26 sub-models, as shown in
Table 1, and they were pretrained for the ImageNet dataset [
11]. For each model, optimal hyperparameters and weights were selected through transfer learning and hyperparameter tuning.
Transfer learning is applied as follows. First, the input size of the pre-learned models is redefined to the size of the input image. Subsequently, the pixel values of the input image are normalized to ensure that each pixel value is between 0 and 1. Second, the layers for multiclass classification used in the pretrained models are replaced with layers for binary classification. For this purpose, a global average pooling [
57] layer and dropout layer [
58] are appended to the last convolution layer of the pretrained model. Finally, a fully connected layer with one node is appended using a sigmoid function as an activation function, as defined in Equation (3):
The redefined models are trained as follows. First, only the weights of the newly appended layers among the layers of the redefined models are tuned by training. Training lasts for 20 epochs with a given learning rate
for the training dataset, for which the mini-batch gradient descent method is used. The Adam optimizer [
59] (with momentum parameters,
,
,
) is used as an optimizer. For the loss function, the average of the binary cross-entropy values between the actual label values,
, and predicted values,
, of the images is evaluated, as defined in Equation (4):
where
is the number of the images used for training.
Following this, the weights of all the layers are fine-tuned for 10 epochs at a new learning rate that is obtained by reducing the learning rate by a factor of . Finally, the weights corresponding to the highest validation accuracy among all the epochs are selected.
Optimal hyperparameters such as dropout rate, learning rates, batch size, and sub-models are selected using hyperparameter tuning. First, the hyperparameters are tuned for each sub-model in
Table 1. Subsequently, the optimal hyperparameters are selected using a random search method [
60]. In this method, the value of each hyperparameter is randomly sampled from the search space comprising them, and the validation accuracy is measured. This is repeated dozens of times for each sub-model. Finally, among the sub-models of each model, the model with the highest validation accuracy was selected.
5. Implementation and Experiments
In this study, the proposed soft voting ensemble classifier was implemented using Python and Google’s TensorFlow 2 and was run on computers with an Intel Xeon 3.00 GHz CPU, 128 GB RAM, and two NVIDIA TITAN RTX graphic cards. The pretrained models and weights provided by TensorFlow 2 were used. Retraining and hyperparameter tuning were performed according to the methods described in
Section 4. The average time for retraining each model is shown in
Table 4.
Table 5 lists the search space for hyperparameter tuning. Some of the values of the batch size in
Table 5 may have been selected owing to the memory limitations of the graphic cards.
To determine the optimal values of the hyperparameters for each sub-model in
Table 1, 50 samples per sub-model were randomly selected from the values in
Table 5. Subsequently, the sub-model was trained with the selected hyperparameter values. For the validation set, the sub-model with the highest accuracy was selected as the optimal model. The accuracy is defined as:
where the threshold for classification,
, is set to 0.5.
Table 6 lists the optimal hyperparameter values for each model.
Table 7 shows that the training and validation accuracies are greater than 98% and 97%, respectively.
Table 8 presents the classification results of the test set using the soft voting ensemble classifier that comprises six optimal models. The precision, recall, and F
1-score were calculated as:
Table 8 shows that both the test accuracies and F
1-scores of the six models are higher than 96%. Therefore, even if used independently for classification, the six models can achieve an accuracy of 96% or higher. The soft voting ensemble classifier has a higher accuracy, precision, and F
1-score than the six models. Only the recall value of the soft voting ensemble classifier comes behind that of one of the models, i.e., EfficientNet. Therefore, we verified that the images of hull surfaces can be classified with higher accuracy when using the soft voting ensemble classifier.
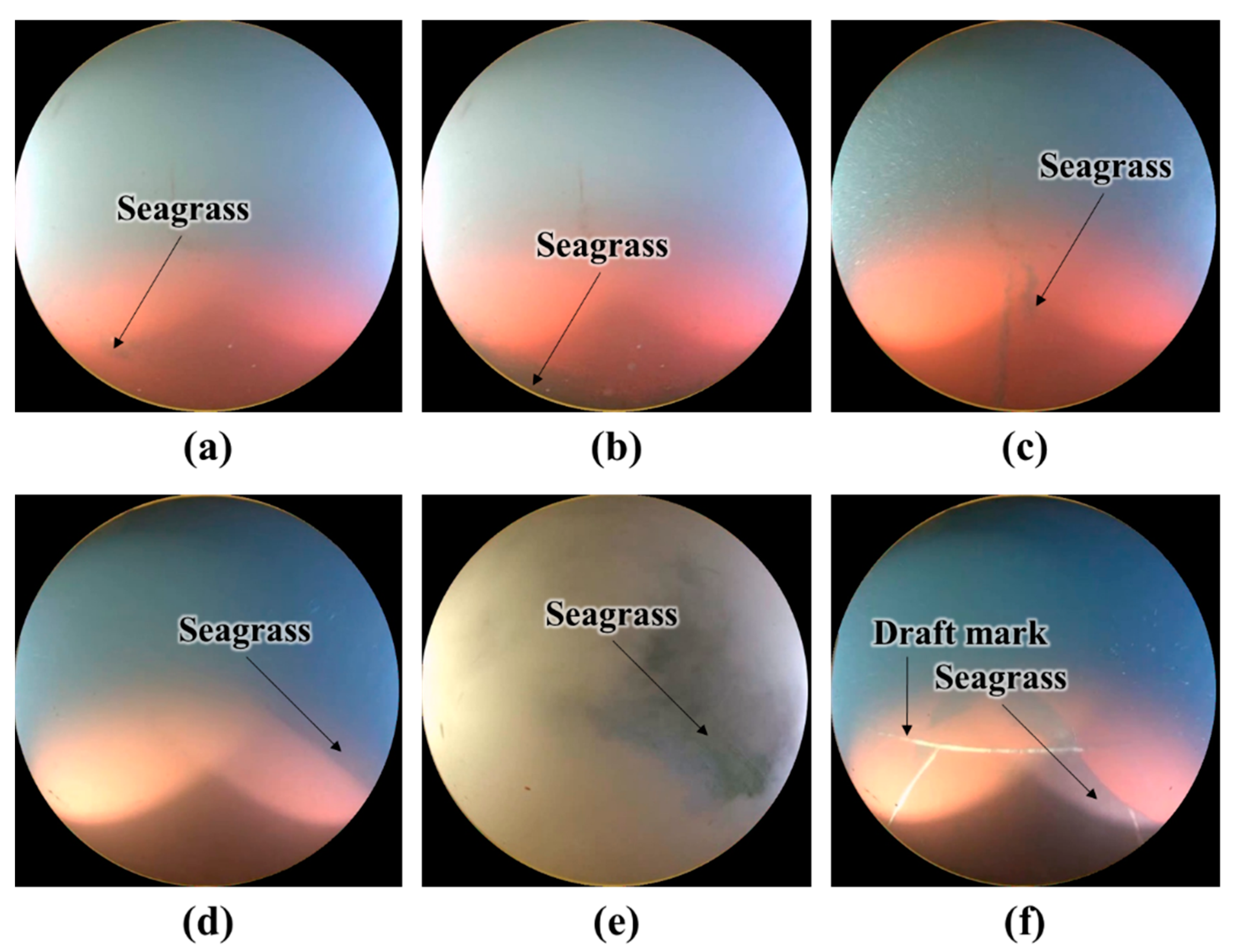
Figure 6 shows examples of the classification of the images of the underwater hull surfaces using the soft voting ensemble classifier. The soft voting ensemble classifier correctly classifies the images with seagrass and barnacles, shown in
Figure 6a–d, as unclean. The images with draft marks, floating matter, and peeled surfaces, shown in
Figure 6e–g, were correctly classified as clean. Furthermore, in
Figure 6h, the dark surface color due to lighting is not recognized as seagrass but as a clean surface.
Figure 7 shows examples of the mis-classified images. Since
Figure 7a–c only contain a small area of seagrass, the images were labeled as clean. However, the soft voting classifier seems to classify these images as unclean because of the seagrass. In
Figure 7d, the dark colored seagrass and seawater overlap; consequently, the hull surface was erroneously identified as seawater. In
Figure 7e, the seagrass was not correctly recognized owing to the disturbance caused by the floating matter. The image in
Figure 7f has draft marks and seagrass; however, only the seagrass was recognized.
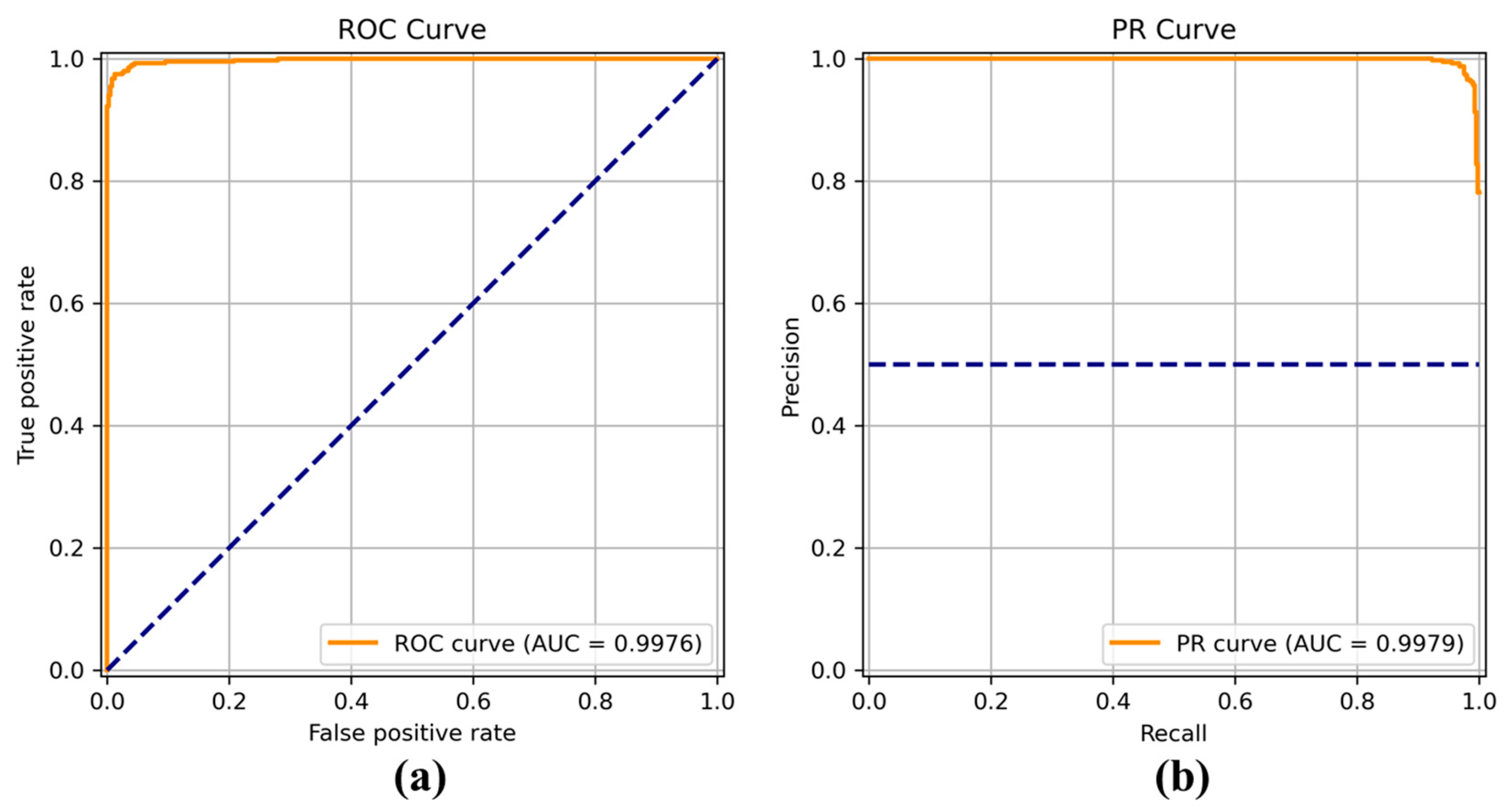
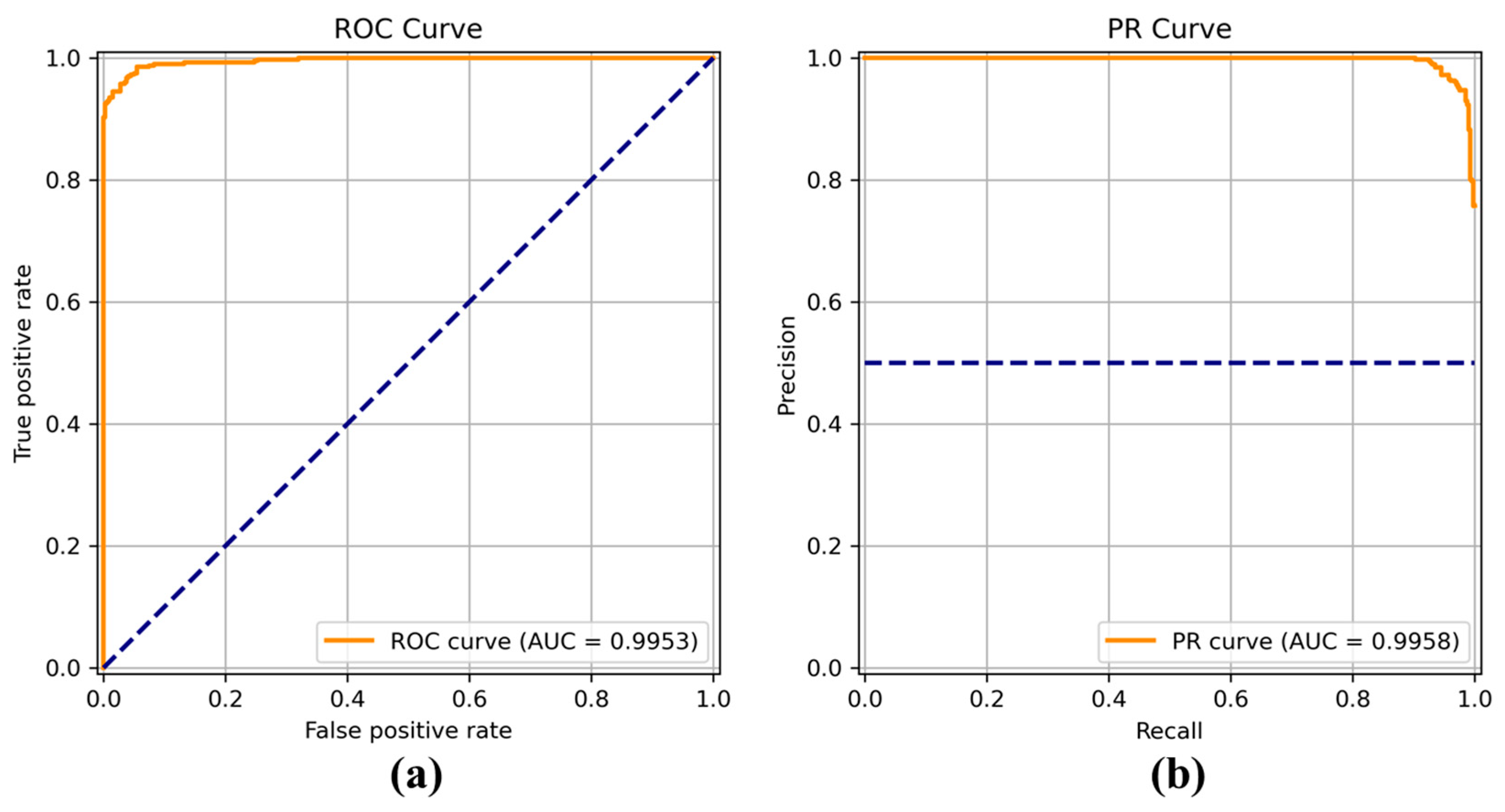
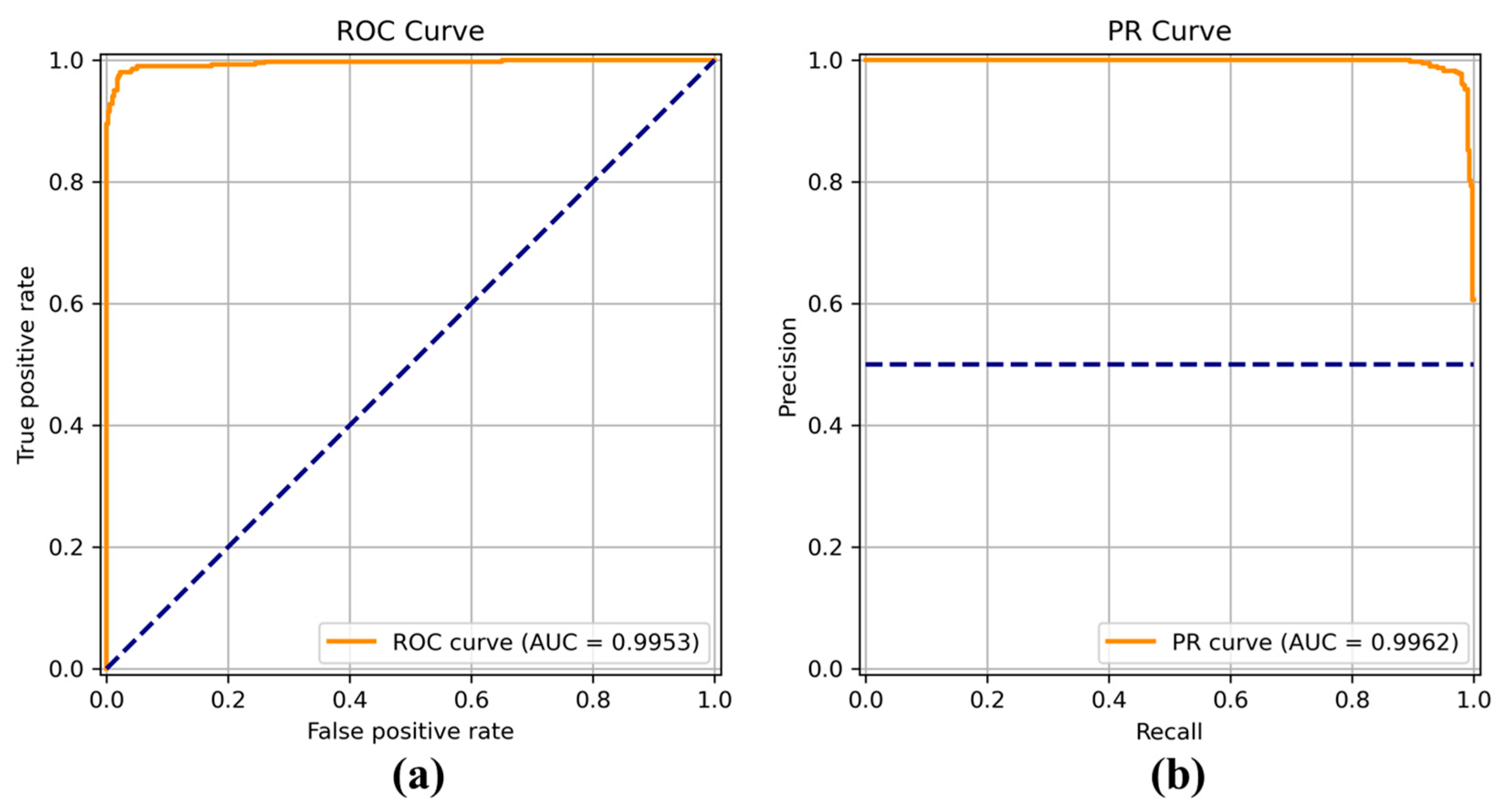
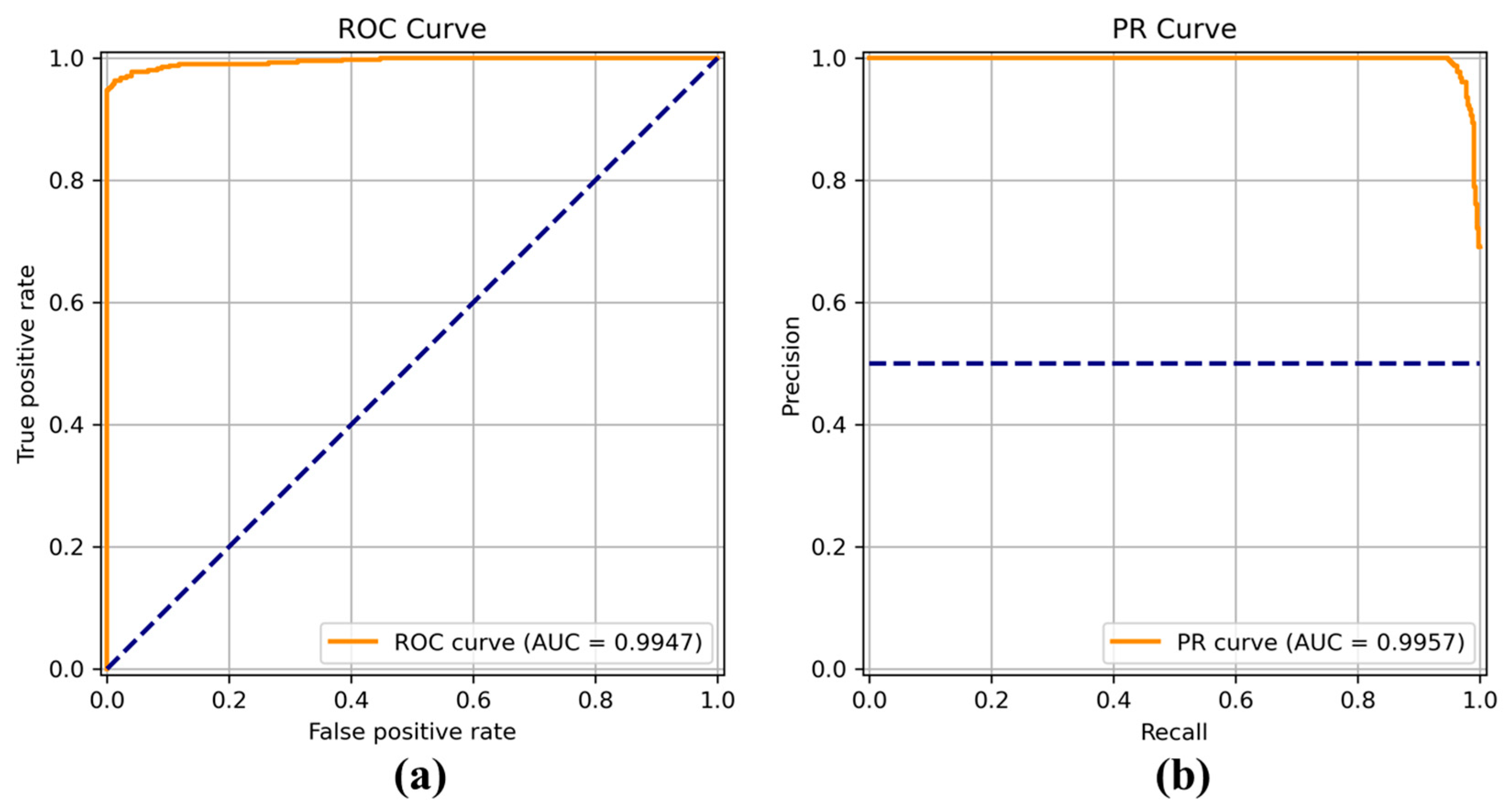
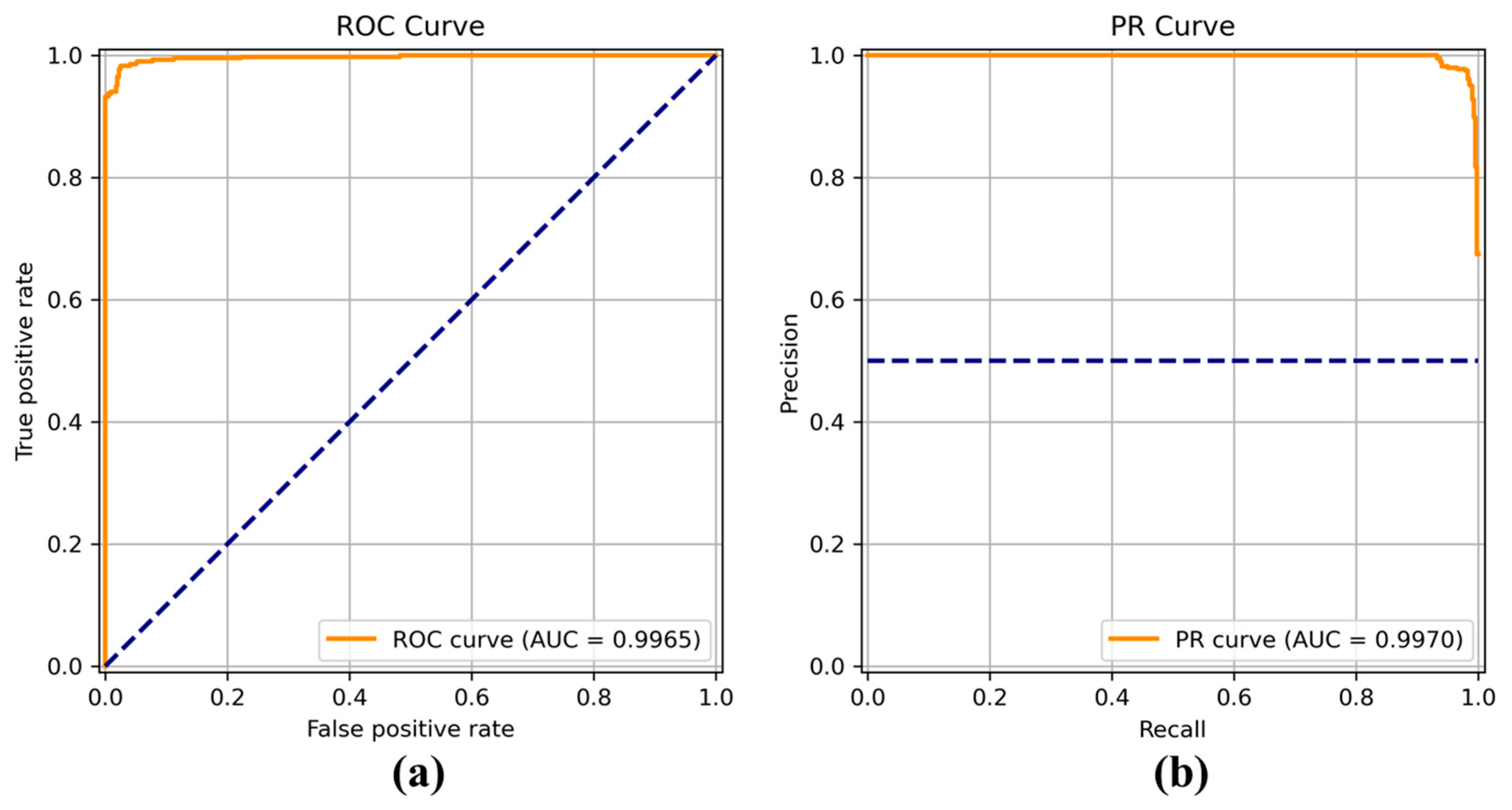
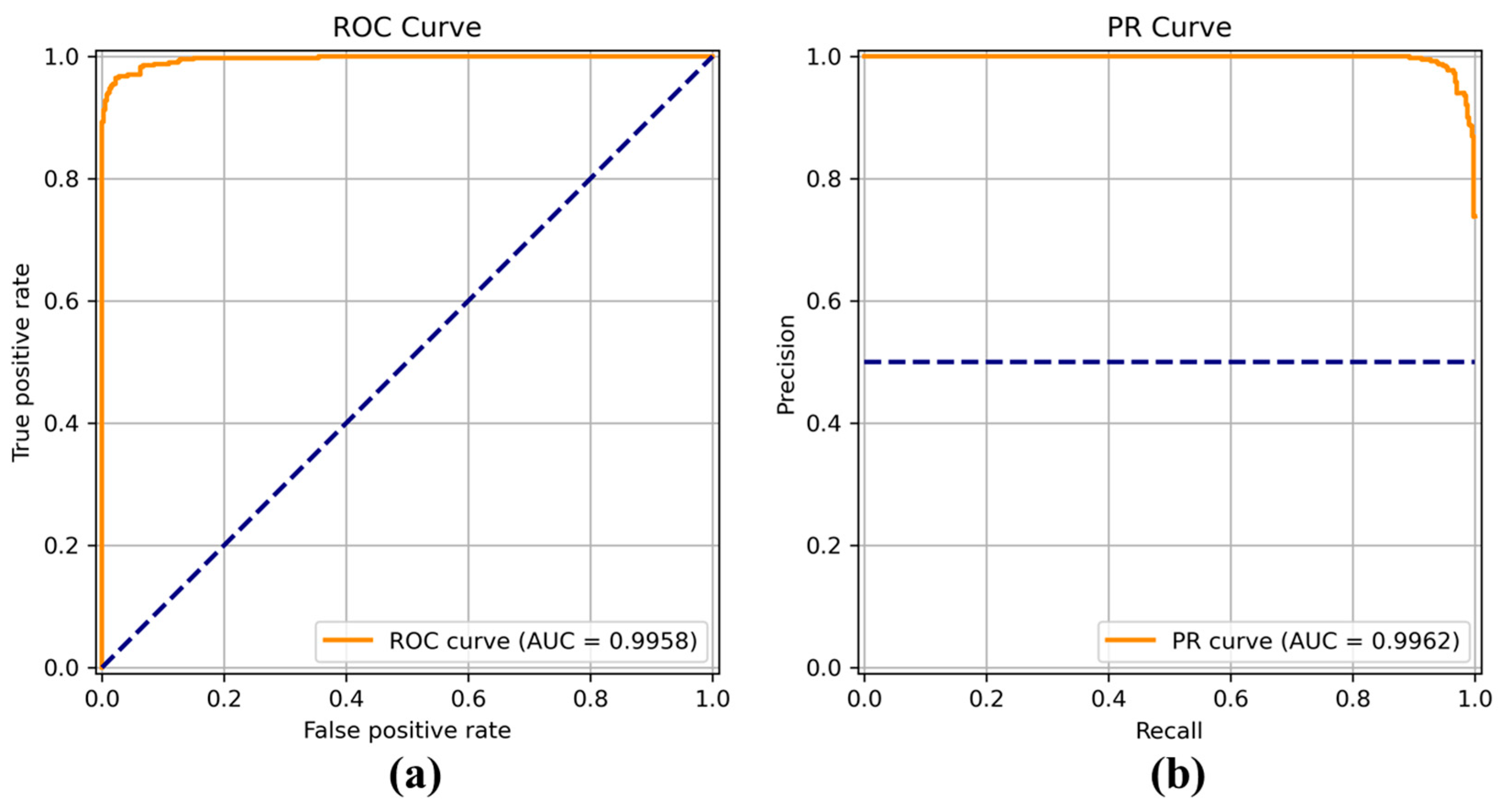
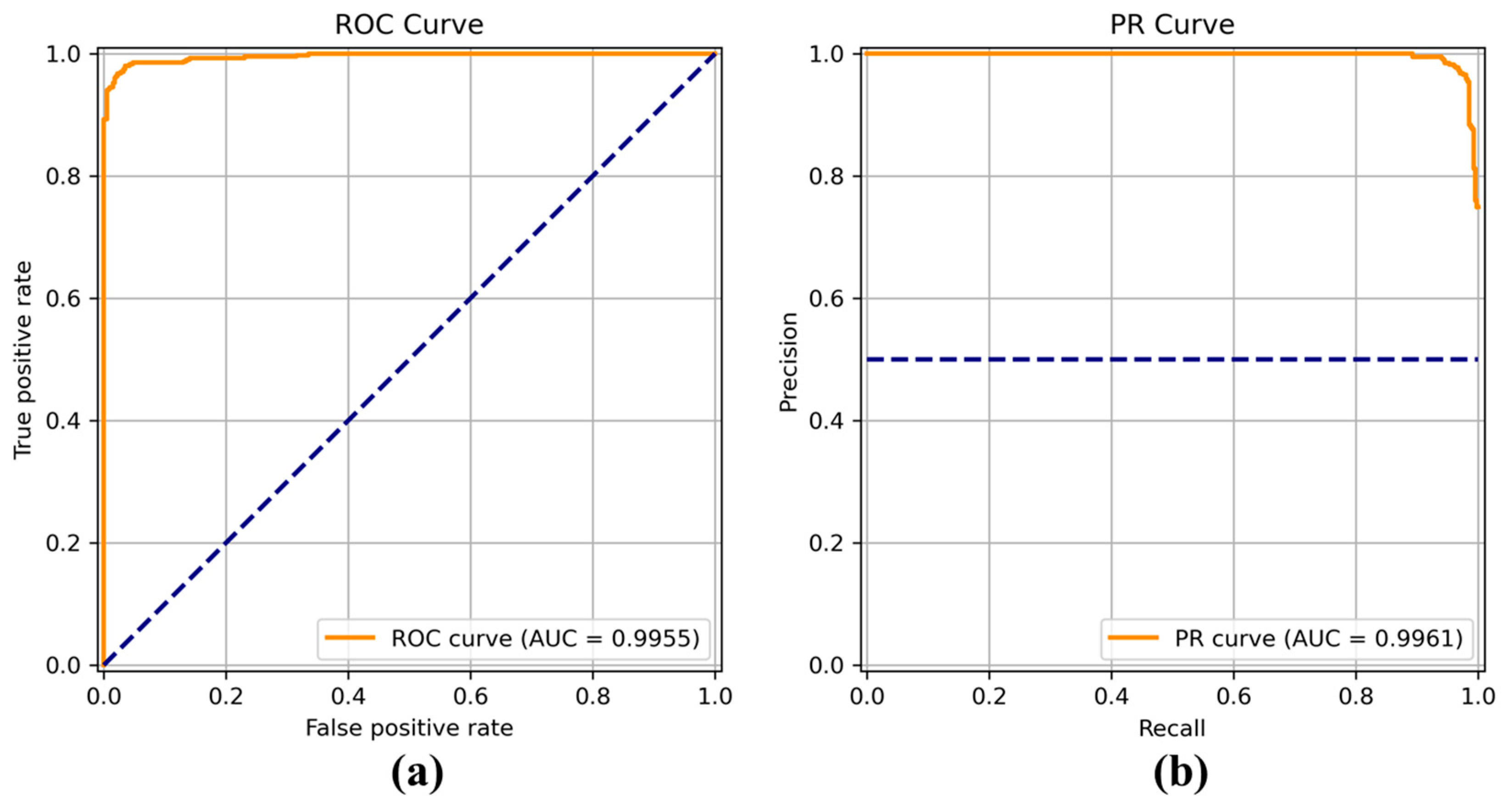
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12,
Figure 13 and
Figure 14 show the receiver operating characteristic (ROC) and precision call (PR) curves for varying classification threshold. For the soft voting ensemble classifier in
Figure 8, the area under the curve (AUC) was almost one, and the highest over the other six models. This indicates that the soft voting ensemble classifier has the best ability to classify the conditions of the hull surface among the other six models.
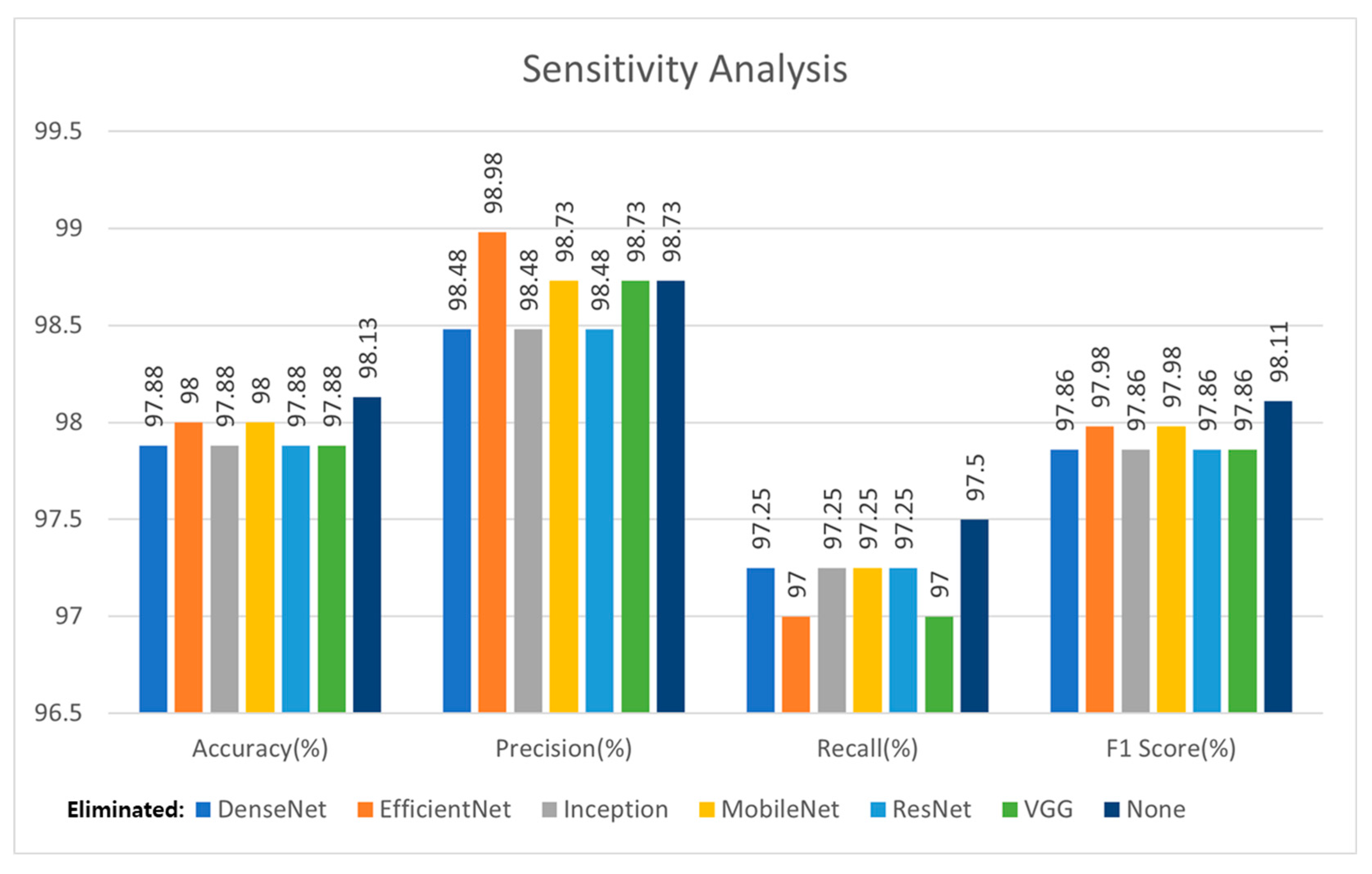
Figure 15 shows the results of the sensitivity analysis, in which one of the models was eliminated. Compared with the results in
Table 7, the cases using the five models among the six models were also superior to using only one model. Compared with the case using the six models, except for precision, using the six models (depicted as None in
Figure 15) is superior in terms of accuracy, recall, and F
1-score. The case eliminating EfficientNet is superior in terms of precision but inferior in accuracy, recall, and F
1-score. Specifically, the F
1-score, which is the harmonic mean of the precision and recall, of the six models was higher than that of the five models. In conclusion, the case using the six models was superior to that using the five models.
The processing speed for the classification is a key factor for real-time applications. To verify this, the time required to classify an image was measured.
Table 9 presents the results of this study. Classifying one image in the test set requires an average of 56.25 ms using only the CPU, which equates to approximately 17 FPS. Based on the speed of the ROUV, images can be sufficiently processed in real-time, even with ROUVs possessing a relatively low CPU performance.
6. Conclusions
In this study, a method for inspecting the condition of hull surfaces using images from an ROUV camera was proposed. The classification of images was achieved using a soft voting ensemble classifier comprising six well-known CNN models. To tune the models, they were retrained with images of the hull surfaces. The results of the implementation and experiments showed that the classification accuracy and F1-score of the test set were approximately 98.13% and 98.11%, respectively. Furthermore, the proposed method was found to be highly applicable to ROUVs, which require real-time inspection performance.
However, the proposed method requires further improvement. As the dataset used in this study was collected from only a small number of inspection videos, the scope of the results of this study is limited. Therefore, many images that include various types of ships, underwater conditions, and lighting are needed. However, because ship owners are reluctant to provide hull images of their ships, collecting images is difficult. Therefore, in future studies, we plan to apply a data augmentation method using generative models to generate artificial images of the hull surfaces.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}