
Instance Segmentation Based on Improved Self-Adaptive Normalization

Abstract
:1. Introduction
- 1.
- We propose an adaptive normalization method that can autonomously assign weights by learning, and verify the effectiveness of our method on YOLACT++;
- 2.
- Our proposed adaptive normalization method can overcome the batch normalization problem under mini-batch sensitive conditions.
2. Related Work
2.1. Normalization Method
2.1.1. Batch Normalization
2.1.2. Instance Normalization
2.1.3. Layer Normalization (LN)
2.1.4. Self-Adaptation Normalization (SN)
3. Methodology
4. Experiments
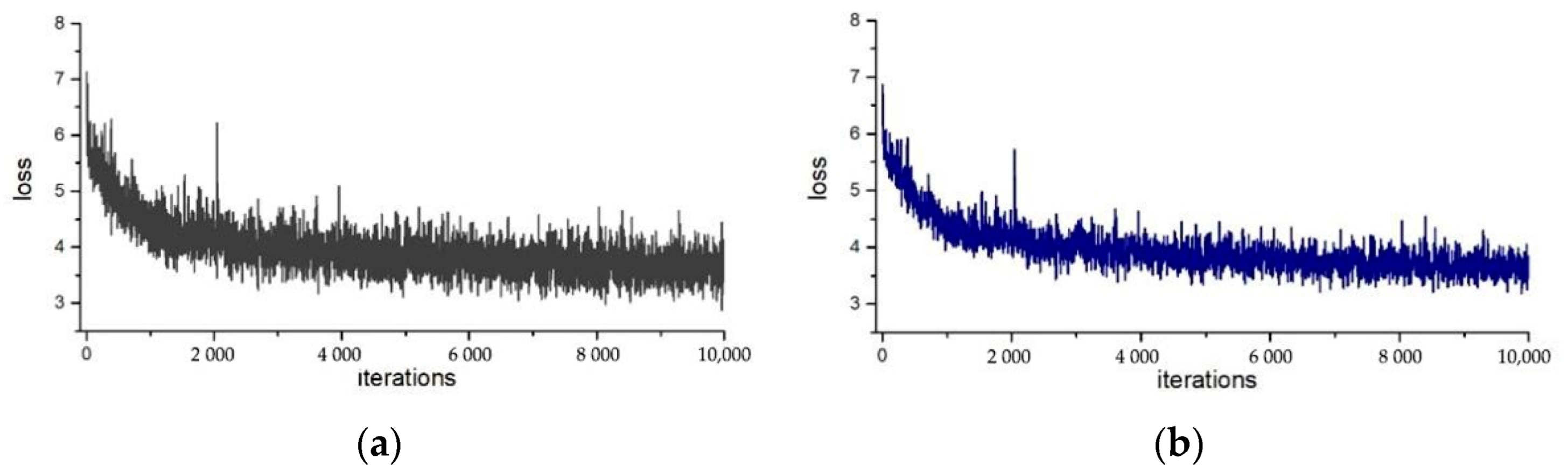
4.1. Model Training
4.2. Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Sultana, F.; Sufian, A.; Dutta, P. Evolution of image segmentation using deep convolutional neural network: A survey. J. Knowl. Based Syst. 2020, 201, 106062. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Dmitry, U.; Andrea, V.; Victor, L. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Luo, P.; Ren, J.; Peng, Z. Differentable learning-to-normalize via Switchable normalize. arXiv 2018, arXiv:1607.05024. [Google Scholar]
- Peng, C.; Xiao, T.; Li, Z.; Jiang, Y.; Zhang, X.; Jia, K.; Yu, G.; Sun, J. Megdet: A large mini-batch object detector. arXiv 2017, arXiv:1711.07240. [Google Scholar]
- Ren, M.; Liao, R.; Urtasun, R.; Sinz, F.H.; Zemel, R.S. Normalizing the normalizers: Comparing and extending network normalization schemes. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sergey, I. Batch renormalization: Towards reducing minibatch dependence in batch-normalized models. arXiv 2017, arXiv:1702.03275. [Google Scholar]
- Wang, G.; Peng, J.; Luo, P.; Wang, X.; Lin, L. Batch kalman normalization: Towards training deep neural networks with micro-batches. arXiv 2018, arXiv:1802.03133. [Google Scholar]
- Gülçehre, Ç.; Bengio, Y. Knowledge matters: Importance of prior information for optimization. J. Mach. Learn. Res. 2016, 17, 226–257. [Google Scholar]
- Jiang, J. A Literature Survey on Domain Adaptation of Statistical Classifiers. Available online: http://sifaka.cs.uiuc.edu/jiang4/domainadaptation/survey (accessed on 24 May 2022).
- Salimans, T.; Diederik, P.K. Weight normalization: A simple reparameterization to accelerate training of deep neural networks. arXiv 2016, arXiv:1602.07868. [Google Scholar]
- Kingma, D.; Ba, J.L. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using rnn encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the diffificulty of training dee feedforward neural networks. In Proceedings of the AISTATS 2010, Sardinia, Italy, 13–15 May 2010; Volume 9, pp. 249–256. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ping, L. Eigennet: Towards fast and structural learning of deep neural networks. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Ping, L. Learning deep architectures via generalized whitened neural networks. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shao, W.; Li, J.; Ren, J.; Zhang, R.; Wang, X.; Luo, P. SSN: Learning Sparse Switchable Normalization via SparsestMax. Int. J. Comput. Vis. 2019, 128, 2107–2125. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. arXiv 2016, arXiv:1612.03144. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-Time Instance Segmentation. In Proceedings of the 2019 IEEE/CVF In-ternational Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- He, K.; Georgia, G.; Piotr, D.; Ross, G. Mask RCNN. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wu, U.; He, K. Group normalization. arXiv 2018, arXiv:1803.08494. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | FPS | mAP | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|---|---|
| PA-Net | R-50-FPN | 4.7 | 36.6 | 58.0 | 39.3 | 16.3 | 38.1 | 53.1 |
| RetinaMask | R-101-FPN | 6.0 | 34.7 | 55.4 | 36.9 | 14.3 | 36.7 | 50.5 |
| FCIS | R-101-C5 | 6.6 | 29.5 | 51.5 | 30.2 | 8.0 | 31.0 | 49.7 |
| Mask R-CNN | R-101-FPN | 8.6 | 35.7 | 58.0 | 37.8 | 15.5 | 38.1 | 52.4 |
| MS R-CNN | R-101-FPN | 8.6 | 38.3 | 58.8 | 41.5 | 17.8 | 40.4 | 54.4 |
| YOLACT++ | R-101-FPN | 33.5 | 29.5 | 47.0 | 30.6 | 9.9 | 30.1 | 46.2 |
| YOLACT-SN | R-101-FPN | 33.5 | 31.2 | 48.5 | 31.2 | 10.0 | 31.3 | 47.7 |
| YOLACT-SN | R-50-FPN | 45.0 | 28.2 | 46.6 | 29.2 | 9.2 | 29.3 | 44.8 |
| YOLACT-SN | D-50-FPN | 40.7 | 28.7 | 46.8 | 30.0 | 9.5 | 29.6 | 45.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Wang, X.; Yang, Q.; Dong, E.; Du, S. Instance Segmentation Based on Improved Self-Adaptive Normalization. Sensors 2022, 22, 4396. https://doi.org/10.3390/s22124396
Yang S, Wang X, Yang Q, Dong E, Du S. Instance Segmentation Based on Improved Self-Adaptive Normalization. Sensors. 2022; 22(12):4396. https://doi.org/10.3390/s22124396
Chicago/Turabian StyleYang, Sen, Xiaobao Wang, Qijuan Yang, Enzeng Dong, and Shengzhi Du. 2022. "Instance Segmentation Based on Improved Self-Adaptive Normalization" Sensors 22, no. 12: 4396. https://doi.org/10.3390/s22124396