Abstract
In this study, to further improve the prediction accuracy of coal mine gas concentration and thereby preventing gas accidents and improving coal mine safety management, the standard whale optimisation algorithm’s (WOA) susceptibility to falling into local optima, slow convergence speed, and low prediction accuracy of the single-factor long short-term memory (LSTM) neural network residual correction model are addressed. A new IWOA-LSTM-CEEMDAN model is constructed based on the improved whale optimisation algorithm (IWOA) to improve the IWOA-LSTM one-factor residual correction model through the use of the complete ensemble empirical model decomposition with adaptive noise (CEEMDAN) method. The population diversity of the WOA is enhanced through multiple strategies and its ability to exit local optima and perform global search is improved. In addition, the optimal weight combination model for subsequence is determined by analysing the prediction error of the intrinsic mode function (IMF) of the residual sequence. The experimental results show that the prediction accuracy of the IWOA-LSTM-CEEMDAN model is higher than that of the BP neural network and the GRU, LSTM, WOA-LSTM, and IWOA-LSTM residual correction models by 47.48%, 36.48%, 30.71%, 27.38%, and 12.96%, respectively. The IWOA-LSTM-CEEMDAN model also achieves the highest prediction accuracy in multi-step prediction.
1. Introduction
Coal resources have long played an important role in economic development and the livelihood of people in China and will remain as the main source of energy in China for quite some time. However, coal production is a typical high-risk industry [1]. This is especially so, as the coal resources in Chinese mines continues to extend to greater depths at which the complex geological conditions under the mines result in frequent coal mine accidents. Coal mine accidents are the most frequently occurring and deadly disasters among the various types of mine accidents. Because the occurrence of coal mine gas accidents and changes in gas concentration are closely related, accurate predictions of changes in gas concentration are important for preventing gas accidents [2].
To date, many researchers have conducted extensive research on coal mine gas concentration prediction. Some results have been achieved and a number of prediction methods have been proposed, including methods based on mathematical models of gas geology as well as those based on deep learning. However, the accuracy and applicability of existing prediction methods requires further optimisation, as changes in gas concentrations in underground coal mines are influenced by a variety of complex factors, the variation trends are more complex and exhibit extreme instability and non-linearity, making it difficult to describe and predict gas transformation trends through linear relationships.
The basic principles of predicting gas concentration based on gas mathematical models are as follows: the geological rules of gas, analysis of the change rule of gas concentration, and screening of the main factors affecting the change of gas concentration. Based on these principles, according to the measured data collected in the working face and relevant geological data and considering various influencing factors comprehensively, a multi-variable mathematical model is established to predict the gas concentration in the unexploited working face of the mining area by a mathematical method. For example, based on the theory of gas geology, Lang [3] constructed a mathematical model of gas concentration from geological factors and mining factors. Liu [4] deduced the dynamic model equation of porosity and permeability from the definition of porosity, and obtained the mathematical model of coal and gas outburst by establishing the central equation of gas pressure field. Zhang [5] established a multi-variable mathematical model of gas concentration using the measured data of gas emissions in the mined area of the mine, considering various influencing factors such as the geological conditions and mining depth. However, when using the gas concentration prediction method, it is difficult to obtain the necessary input data; therefore, it is unable to realize real-time prediction. In addition, in the process of building the mathematical model, gas concentration time sequence correlation is not considered and the prediction equation requires artificial adjustment according to experience; therefore, the demand on related professional knowledge is higher. It is difficult to meet the requirements of accuracy and real-time prediction in practical production applications.
With the application of machine learning in many fields, machine learning has been applied to gas concentration prediction. For example, Lei [6] used the back propagation (BP) algorithm to construct a gas concentration prediction model based on the analysis of the nonlinear characteristics of the various factors affecting gas concentration. Peng et al. [7] used sliding Lagrange interpolation to fill in missing values and then applied the ARIMA model to predict gas concentration in real time. Cong et al. [8] used collected multidimensional gas data and environmental parameters as input features to obtain a dataset of gas data based on a sampling strategy for the construction of a feature-aware long short-term memory (LSTM) model to predict gas concentration. Dey et al. [9] predicted the gas concentration by recovering the internal features of low-dimensional data and constructing a Bi-LSTM model. Cheng [10] used a deep learning algorithm in combined with a fully connected neural network to construct an LSTM-FC gas concentration prediction model for spatiotemporal sequences using the spatiotemporal properties of gas data. Although these algorithms improve the prediction accuracy, the structure and parameters of the models can only be set artificially using empirical laws without considering the temporal correlation of the input data during the construction and training of the models.
Some intelligent optimisation algorithms have also been applied to gas concentration prediction. Liu et al. [11] constructed a hybrid GA-BP model to predict the gas concentration by exploiting the global search capability of the genetic algorithm and optimising the weights and thresholds of a BP neural network. Wang [12] et al. improved the global optimisation capability of the locust optimisation algorithm by combining multiple strategies, such as linear reduction factor reconstruction and optimal neighbourhood perturbation to optimise the relevant parameters of the LSTM model in the construction of a gas concentration prediction model. Ma [13] used the particle swarm optimization algorithm and the Adam algorithm to optimize the hyperparameters of a GRU model, so as to build a gas concentration prediction model based on PSO-Adam-GRU, which improved the prediction accuracy and robustness of the model. Fu [14] used the artificial bee colony algorithm to optimize the grid parameters of the generalized regression neural network and established a gas concentration prediction model which improved the overall generalization ability of the model. However, the above models have long hyperparameter iteration times and low convergence accuracy. They may also suffer from insufficient fitting ability when the hyperparameters are not set accurately. This will also result in insufficient prediction accuracy to meet the safety needs of underground coal mines.
To address the shortcomings of the above models, an improved whale optimisation algorithm (IWOA) is proposed in this study to optimise the LSTM residual correction model. Data processing is first performed on the gas multiparameter time series to obtain the input variables. To address the susceptibility of the whale optimisation algorithm (WOA) algorithm to local optima and slow convergence [15], the WOA algorithm is next optimised jointly through four strategies: applying a Gaussian mapping to the initial population, an elite backward learning mechanism, a reconstructed nonlinear convergence factor, and a Levy flight strategy for position updating [16]. The IWOA is then used to optimise the LSTM hyperparameters and the residual dataset of the IWOA-LSTM gas concentration prediction model is multimodally decomposed using the complete ensemble empirical model decomposition with adaptive noise (CEEMDAN) method [17]. The IWOA-LSTM model is finally used to predict the multidimensional eigenmodal components of the residual series. The optimal weights of each eigenmodal component are determined through residual assignment to construct the IWOA-LSTM-CEEMDAN residual correction model to further improve the gas concentration prediction accuracy. This model can provide strong technical support for subsequent gas risk assessment and gas accident early warning, cultivate effective safety risk analyses, enhance the reliability and efficiency of early warning, and is of great significance to improving the safety management of coal mine enterprises and reduction of the occurrence of gas accidents.
2. Date Source
The working face of a gas mine generates a large amount of gas during production. With reference to the sample sizes in previous gas concentration prediction studies [18,19], data were selected from 11 different measurement points at the working face of a coal mine in Guizhou from 18 March 2021 to 27 March 2021. Approximately 20,000 sets of data were obtained for short-term prediction over the next 12 h. The data attributes are summarized in Table 1.

Table 1.
Data attributes of each measurement point at the working face.
The acquisition of high-quality underground monitoring data from coal mines has always been a concern in gas concentration prediction models. Despite the large improvements to the performance of current data collection equipment, data transmission reliability, and data storage security, a series of problems such as missing and redundant data still remain. These problems, if left unaddressed, will impact the accuracy of the subsequent gas concentration prediction models.
2.1. Missing Data Processing
Missing data bring serious obstacles to subsequent model training and prediction. Therefore, the Lagrange interpolation method is adopted in this paper to fill the missing data. The interpolation formula is shown as follows:
Find the th degree polynomial such that all interpolation nodes satisfy the conditions of Formula (1).
To solve , we construct the interpolation basis function , which is polynomial to the th degree and satisfies Formula (2).
This means that all nodes are zeros of (except ).
Then, determine the coefficient in Formula (3) according to Formula (2).
The solution of can be obtained by using Formula (4):
2.2. PCA Data Dimensionality Reduction
With the increasing dimensionality of the data collected, the sparsity of the data become increasingly higher. Therefore, principal component analysis (PCA) was used in this study to eliminate the redundant features of the original data set. The specific steps are detailed in the following sections.
2.2.1. Dataset Standardization Processing
First, assume that the data matrix composed of -dimensional variables of group is:
where is the -dimensional vector for the th sample. is normalized to obtain Formula (7):
where is the normalized value of , is the average value of the -dimensional variables, and is the variance of the -dimensional variables.
2.2.2. Computation of the Coefficient Matrix R
2.2.3. Calculation of the Cumulative Contribution Rate
2.3. Data Normalization
In order to eliminate the dimensional influence between the gas multi-parameter time series, the data need to be normalized. The original time series is processed with the min-max standardized method, and the formula is as follows:
where , , …, is the original data, and the normalized data is , , …, ∈ [0,1] and is dimensionless.
3. Research Methodology
3.1. Whale Optimisation Algorithm
The WOA is a new intelligent population optimisation algorithm proposed by Mirjalili et al., in 2016 [20]. The algorithm is widely used because of its various advantages, which include its few adjustment parameters and simple operation. The WOA is an intelligent optimisation algorithm that simulates the predation behaviour of humpback whales. Humpback whales only hunt their prey using bubble nets. Each humpback whale position represents a feasible solution, and the principles of the algorithm are as follows:
3.1.1. Surrounding the Prey
Humpback whales need to surround their prey when hunting, but the globally optimal position in the search space in practical problems is unknown. Therefore, in WOA, the initial optimal solution is set as the position of the individual whale with the highest current fitness. The other individuals will then try to approach the optimal solution and update their positions. This behaviour is described mathematically by:
where is the current number of iterations, and are the coefficient vectors, is the current position vector of the best individual whale, and is the current position vector of the whale. and are given by:
where and are random vectors within [0,1] and decreases linearly from 2 to 0 during the iteration process.
3.1.2. Hunting Behaviour
Whales hunt their prey by travelling in a spiral as they contract the envelope around the prey. This behaviour of prey enclosure by the whale is realized by decreasing the value of over the iterations. As decreases, the value of is taken as a random value within [−,]. When is restricted to [−1,1], the new position vector will be at the initial position and the current optimal position at , and the encircling behaviour of the prey is realized. The spiral behaviour of the whale as it hunts and swims towards the prey is mathematically represented as:
where denotes the distance between the whale and its prey, is a constant used to define the logarithmic spiral motion, and is a random number within [−1,1].
To simulate the behaviour of a whale shrinking its envelope as it travels in a spiral, it is assumed that there is a random choice between the two equally probable options of shrinking the envelope and travelling in a spiral. This manner in which the whale updates its position is mathematically represented as:
where is a randomly generated random number within [0,1].
3.1.3. Searching for Prey
In addition to approaching a known prey, the whales will also search randomly for a new location based the positions of other whales. When is set to more than 1 in the algorithm, the whales are forced to move away from the prey and find a more suitable prey, which enhances the global search capability of the algorithm. This behaviour is represented in mathematically as:
where represents the position vector of a randomly selected individual whale.
3.2. Improved Whale Optimisation Algorithm
Although WOA has achieved good results in many practical applications, the common WOA still has problems with local optimization and a low convergence accuracy. Therefore, in order to further improve the performance of the WOA algorithm, four improvement strategies are introduced, and an improved whale optimization algorithm (IWOA) is proposed.
3.2.1. Gaussian Mapping
The global convergence speed and quality of the WOA optimal solution are influenced by the quality of the initial population. A population with a higher degree of diversity can improve the overall performance of the algorithm in finding the optimal solution. A Gaussian mapping is therefore used in this study to generate a more uniformly distributed initial population to improve the performance of the algorithm [21]. The Gaussian mapping is defined as:
The Gaussian mapping allows the states within a certain range of the search space to be maximally traversed without repetition. This ensures the diversity of the population and makes it easier for the improved algorithm to avoid local optima and therefore improving the ability of the algorithm to find the best solution.
3.2.2. Elite Reverse Learning Strategy
To avoid the problem of the algorithm entering early maturity as the population diversity is increased, the elite reverse learning strategy is adopted in this study to optimise the global search ability of the algorithm. An elite group of individuals with larger fitness values among the original solution and its reverse solution are selected. The reverse solution of the elite group is solved to increase the population diversity. The best individuals from the current population and the reverse population of the elite group are then selected as the child individuals for the next iteration round [22].
Suppose is an elite individual in the -dimensional search space. The reverse solution of this individual is defined as:
where represents the -dimensional vector of the elite solution , is a random value in the interval [0,1], and and define the dynamic boundary. The dynamic boundary not only overcomes the difficulties of preserving search experience with the fixed boundary, but also locates the elite reverse solution in the search space, which is conducive to the convergence of the algorithm. If crosses the boundary, it needs to be reset:
where represents a random value within the interval [].
3.2.3. Nonlinear Adaptive Weights
Because the WOA shows a nonlinear trend in the overall optimisation process, the use of a linear inertia weight descent strategy in WOA does not provide a good representation of the actual situation during the iterative process of the algorithm. Inspired by the use of inertia weights to optimise the particle swarm optimisation (PSO) algorithm in a previous study [23], this idea is adapted for WOA by introducing a nonlinearly varying inertia weight in this study:
In the equation, and represent the maximum and minimum values of , respectively, is the current number of iterations, and is the maximum number of iterations. When is small at the beginning of the iterations, the value of is large, and the rate of decrease of is slow, thereby ensuring the global search ability of the algorithm in the first iteration. As the number of iterations increases, the value of decreases in a nonlinear manner and the rate of decrease of increases rapidly, thereby ensuring good local search ability in the later stages. The use of the nonlinear varying inertia weight therefore allows the algorithm to flexibly adjust its global and local search abilities.
Substituting Equation (24) into Equations (17) and (19), the improved mathematical model for updating the position of the whale is obtained as:
3.2.4. Levy Flight Strategy
To prevent the diversity of the WOA algorithm from decaying too quickly, which causes the algorithm to tend towards local optima, the Levy flight strategy is applied in the updating of the whale position [24]. This allows the algorithm to exit the local optima to improve its global search ability. The strategy is mathematically expressed as:
where is the minimum jump step and is a parameter greater than 0. However, the actual process for actually calculating the search path of a Levy flight is very complicated. Yang et al. [25] simplified and applied the Fourier transform to the Levy distribution function to obtain its probability density function in power form and then used the Mantegna algorithm to model the flight path as:
where is the current position of the individual whale, the updated position, and is the step scaling factor. is the random step size of the Levy flight, which is expressed as:
where both and obey the normal distribution, , . and are defined as:
where Γ is the standard Gamma function.
3.3. LSTM
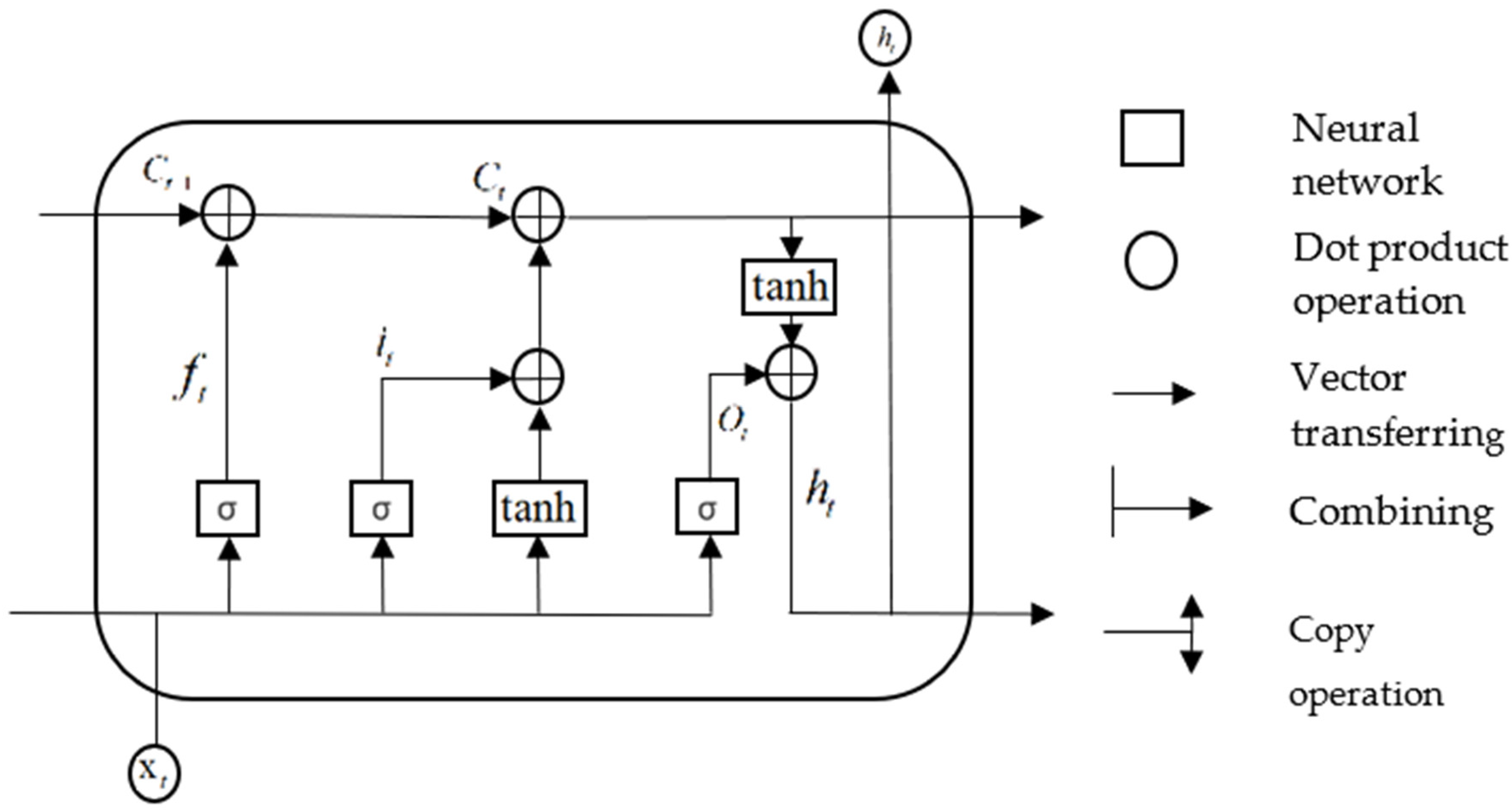
Gradient disappearance and explosion may occur after multiple iterations when recurrent neural networks (RNN) are used to process time series [26]. To overcome this issue, Hochreiter et al. [27] proposed a LSTM network to improve the traditional RNN model. Compared to the hidden cells of a RNN, the hidden cells of a LSTM are more complex. The LSTM can selectively add or reduce the information content as information flows through the structure of the hidden cells. Each memory block of the LSTM consists of one or more self-connected memory cells and three gating units comprising the input, output, and forget gates. A schematic of the LSTM structure for a single cell is shown in Figure 1.
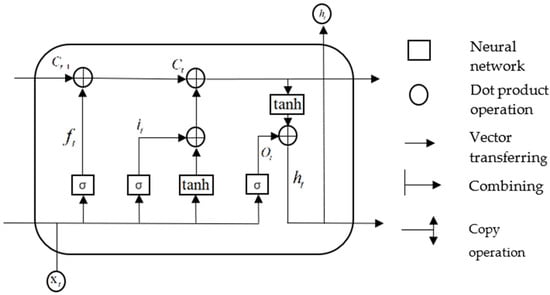
Figure 1.
LSTM structure diagram.
In the above structure diagram, represents the forget gate, which controls whether the hidden cellular state of the upper layer in the LSTM is filtered. represents the input gate, represents the cell state at the previous moment, represents the cell state at the present moment, and represents the output gate. and represent the input and output at the current moment, respectively, and and tanh represent the sigmoid and hyperbolic tangent functions, respectively. The forget gate, input gate, output gate, and weight matrix of the cell state are denoted by ,, and respectively. , , and represent the offset vectors of the forget gate, input gate, output gate, and cell state, respectively. The calculation principles for each control gate are described below.
The value of the input gate and the candidate state value of the input cell at moment are first calculated:
The activation value for the forget gate at moment is then calculated:
Using the values obtained in the above two steps, the cell state at moment can be obtained:
After obtaining the cell state update values, the output gate values can be obtained:
Through the above calculations, the LSTM can effectively use the input function as long-term memory [28].
Overfitting is a common problem in machine learning. When the model is overfitting, the loss function of the model on the test set data is large and the prediction accuracy is low. To solve the overfitting problem, this study adds a Dropout layer to the LSTM neural network. With this, the LSTM neural network will not depend too much on specific local features so as to improve the overall generalization ability of the model and avoid the occurrence of overfitting.
3.4. Residual Sequence Decomposition and Reconstruction
3.4.1. Residual Series Decomposition
A residual sequence is constructed from the differences between the predicted and true values of the IWOA-LSTM model and used as the raw data for the subsequent multimodal decomposition.
Empirical mode decomposition (EMD) [29] is a method for dealing with the time-frequency dependence of adaptive signals by decomposing the signal into individual components that are independent of one another. Compared to the Fourier and wavelet transforms, EMD is very adaptive and powerful because it leaves the basic functions behind and only decomposes the signal based on the time-scale characteristics of the data themself. However, in practice, the time signals obtained are often anomalous, which inevitably affects the choice of the extrema and results in the envelope being a combination of anomalous and real signals. The intrinsic mode function (IMF) components filtered by this envelope are then inevitably affected by the anomalous signals and suffer from pattern overlap.
To solve the problem of mode aliasing in the EMD algorithm, Huang [30] proposed the ensemble empirical mode decomposition (EEMD) method. In this noise-assisted processing method, the uniform spectrum distribution of zero-mean noise is used in the signal analysis. When the signal is consistent with the time-frequency distribution of the white noise background throughout, the different time scales in the signal are automatically distributed to the appropriate reference scale. Because of the nature of zero-mean noise, after many repetitions the impact of the reconstruction error can be reduced by the average noise. However, the computation time of the algorithm is also greatly increased. The CEEMDAN algorithm adds a finite amount of adaptive white noise to the EMD decomposition stage to ensure that the reconstruction error is essentially zero even when the number of integration averages is small. Therefore, the CEEMDAN algorithm not only solves the modal mixing problem of the EMD algorithm, but also overcomes the shortcomings of the EEMD algorithm, which requires multiple integration averages and has low computational efficiency [31].
The detailed steps of the CEEMDAN algorithm are as follows:
- Random white noise of a certain amplitude is added to the original signal to form a new signal ( is the number of averaging processes).
- The new signal is decomposed using EMD as where is the number of EMD-decomposed IMF components, the individual IMF components, and the residual vector.
- The overall average of the resultant modal components gives the first eigenmodal component of the CEEMDAN decomposition: .
- The residual when the first modal component is removed is calculated: .
- Using as a carrier for the new signal, steps (1), (2), and (3) are repeated until the obtained residual signal cannot be further decomposed. Assuming that the number of eigenmodal components obtained at this point is , the original signal is decomposed as .
The flow chart of the signal decomposition process in the CEEMDAN method is shown in Figure 2.
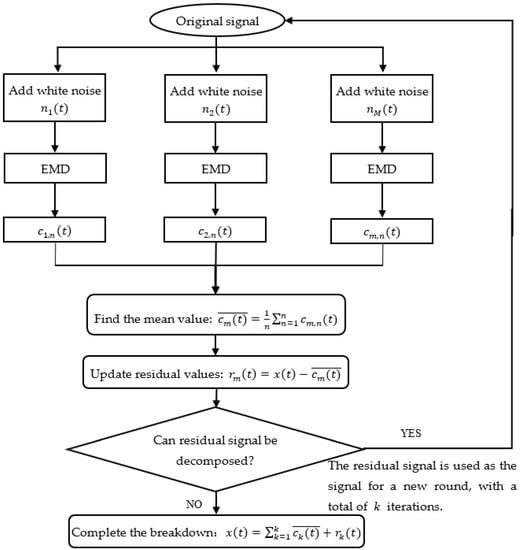
Figure 2.
CEEMDAN decomposition flow chart.
3.4.2. Combination of Residual Assignments of Multidimensional Eigenmodal Components
The residual sequence is decomposed using the CEEMDAN method to subseries, consisting of the eigenmodal components. The subseries are re-divided into training and test sets and predicted using the IWOA-LSTM model. The final residual correction sequence obtained by directly adding up the prediction results of the k subseries will not be impacted by differences in the accuracies between different subseries. A combined residual assignment model for the subseries is therefore used in this study. Because the range of each subseries is different, it is necessary to first normalise each subseries before residual assignment. The model is expressed as:
where represents the weight of the prediction result of the th sub-series; the mean absolute error between the true and predicted values of the th subseries; and the true and predicted values of the th data of the th sub-series, respectively; the prediction result of the th sub-series; and represents the data after residual correction.
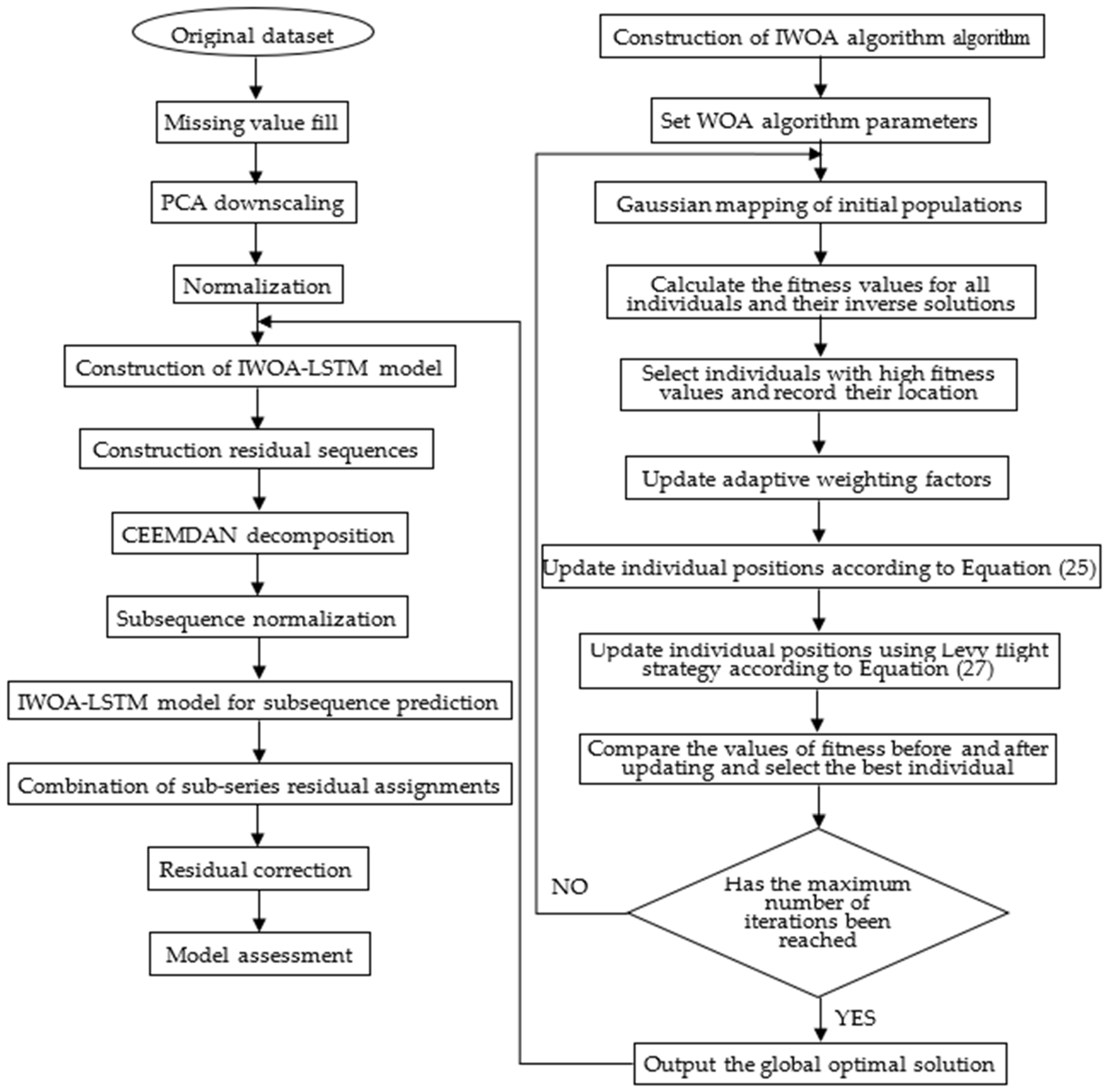
3.5. IWOA-LSTM-CEEMDAN Residual Correction Model Construction Process
A flow chart for the construction of the prediction model is shown in Figure 3. The main process is comprised of data pre-processing, improvement of the WOA, construction of the IWOA-LSTM model, decomposition and reconstruction of the residual series, and evaluation and analysis of the model’s prediction values.
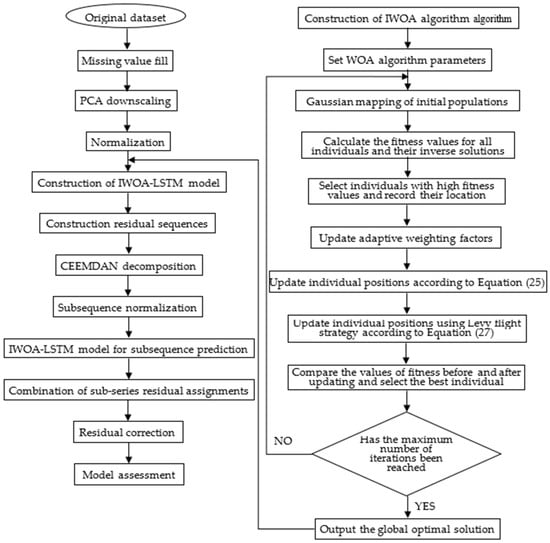
Figure 3.
IWOA-LSTM-CEEMDAN residual correction model prediction flow chart.
- Data pre-processing. Data pre-processing is an important process prior to data modelling because it fundamentally determines the quality of all subsequent data work and output values. The dataset for this study was sourced from a working face in a coal mine in Guizhou province. There are some missing values in the collected dataset because of network transmission issues. Therefore, the missing values in the data need to be filled, following which data downscaling and normalisation are applied on the data before suitable data are finally selected from the dataset for model training.
- Improvement of WHO. Gaussian mapping is performed on the initialised population to produce a more uniformly distributed initial population. Elite backward learning is then performed on all the individuals in the solution space to select the optimal individual based on the fitness value. This is followed by the updating of the adaptive weight factor ω in the WOA algorithm to update the positions of the individual whales. The optimal individual is finally updated using Levy flight strategy optimisation. The fitness value of the optimised individual obtained using these four strategies is then judged to determine if the individual should be retained. This approach increases the likelihood for the algorithm to exit local optima and improve its convergence accuracy.
- Construction of the IWOA-LSTM model. The dataset is divided into training, validation, and test sets. The IWOA-LSTM model is trained using the training set. The data from the validation set is used to monitor the model for overfitting. The data from the test set is input to the model to obtain the prediction results from the model. The differences between the true and predicted values are used as the initial data of the residual series.
- Decomposition and reconstruction of residual sequences. Multimodal decomposition of the residual sequence is performed using the CEEMDAN method described in Section 3.4.1. The training, validation, and test sets are divided into individual eigenmodal components separately. The IWOA-LSTM model is then used to predict each eigenmodal component, and the residuals are assigned to each subsequence to obtain the predicted value of the residual-corrected sequence. This predicted value is added to the predicted value from the IWOA-LSTM model in step 3 to obtain the prediction of the final IWOA-LSTM-CEEMDAN residual-corrected model.
- Model evaluation analysis. The forecasting ability before and after the model improvement is compared based on model evaluation indicators. The changes in the model forecasting effectiveness are analysed.
3.6. Evaluation Indicators
The evaluation indicators used in this study are the mean absolute error and root mean square error. Because absolute values are taken for the error values in the mean absolute error, there is no possibility of positive and negative errors cancelling one another out. The mean absolute error can therefore better reflect the actual prediction error. The existence of large errors in the predicted value will cause the value of the root mean square error to become larger; therefore, the root mean square error can effectively reflect the degree of dispersion in the error value. The explicit formulae for the errors are given by:
where is the number of samples, is the true value, and is the prediction result. Obviously, a smaller value of the evaluation indicator indicates a smaller error between the real and predicted values and a higher prediction accuracy of the model.
4. Results and Discussion
The characteristics of the dataset used in this study to verify the reliability and practicality of the proposed model are listed in Table 1, and the structure of the constructed model is shown in Figure 3. The single-step and multi-step experimental prediction results are compared with those from the BP neural network and the GRU, LSTM, WOA-LSTM, and IWOA-LSTM residual correction models, and the prediction results are analysed to show that the proposed model has higher prediction accuracy.
4.1. Data Dimensionality Reduction Analysis
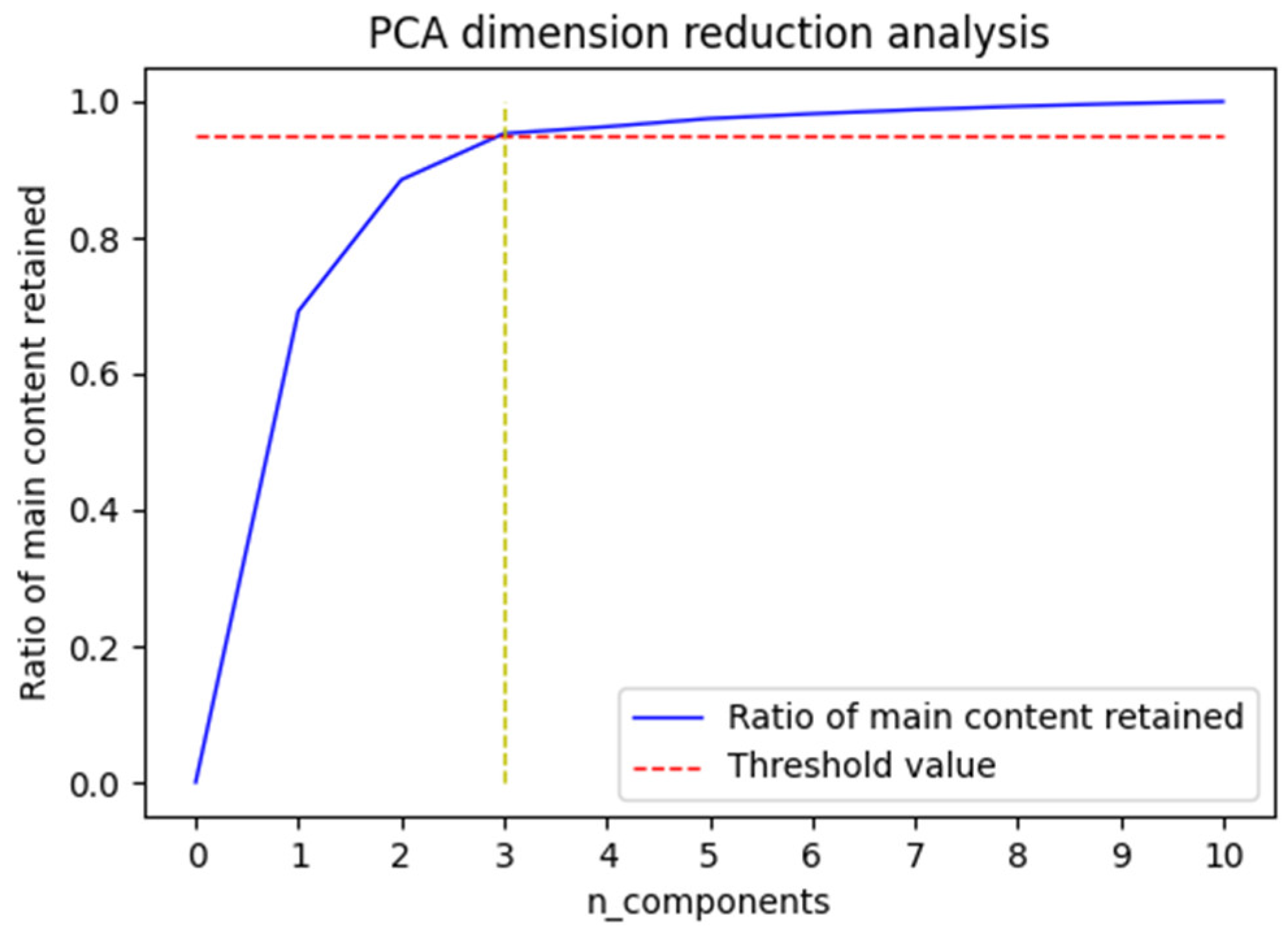
Missing data may exist in spatio-temporal sequence data from underground coal mines because of communication errors or network transmission delays. Because missing data can affect the prediction accuracy of the model, the missing data in the raw data were filled in using the missing data treatment method proposed in Section 2.1. After obtaining the complete dataset, PCA downscaling was performed on the dataset. Figure 4 shows the cumulative contributions of the downhole multidimensional monitoring data to the gas concentration. To cover the main components of the dataset, 98% of the main content of the original dataset needs to be retained in the data. As shown in Figure 4, the threshold value set could already be reached when the original data was downscaled from multiple dimensions to three dimensions.
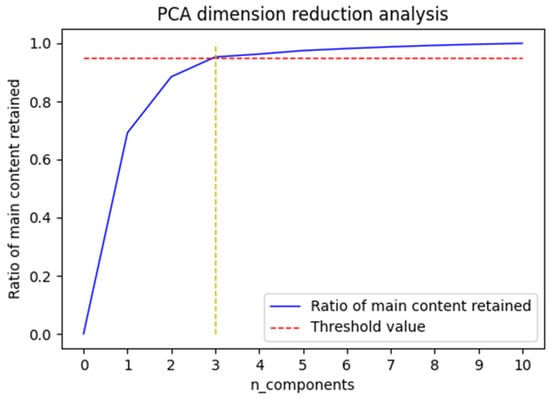
Figure 4.
Line chart of cumulative contribution of parameters.
To verify the necessity and validity of dimensionality reduction, the original dataset and the dataset after PCA dimensionality reduction were used as the input data for the BP, GRU, LightGBM, and LSTM models. The mean absolute errors of the prediction results from the different models are compared in Table 2.
Table 2.
Comparison of data prediction errors before and after dimensionality reduction for each model.
The results of the above experiment show that the prediction accuracy of each model was significantly improved after dimensionality reduction was applied on the input dataset. The necessity and effectiveness of data dimensionality reduction were therefore verified.
4.2. Analysis of IWOA Algorithm
To evaluate the performance of the proposed IWOA algorithm, the 10 typical benchmark test functions shown in Table 3 were used for simulation experiments in this study [32].
Table 3.
Functional expressions of benchmark functions.
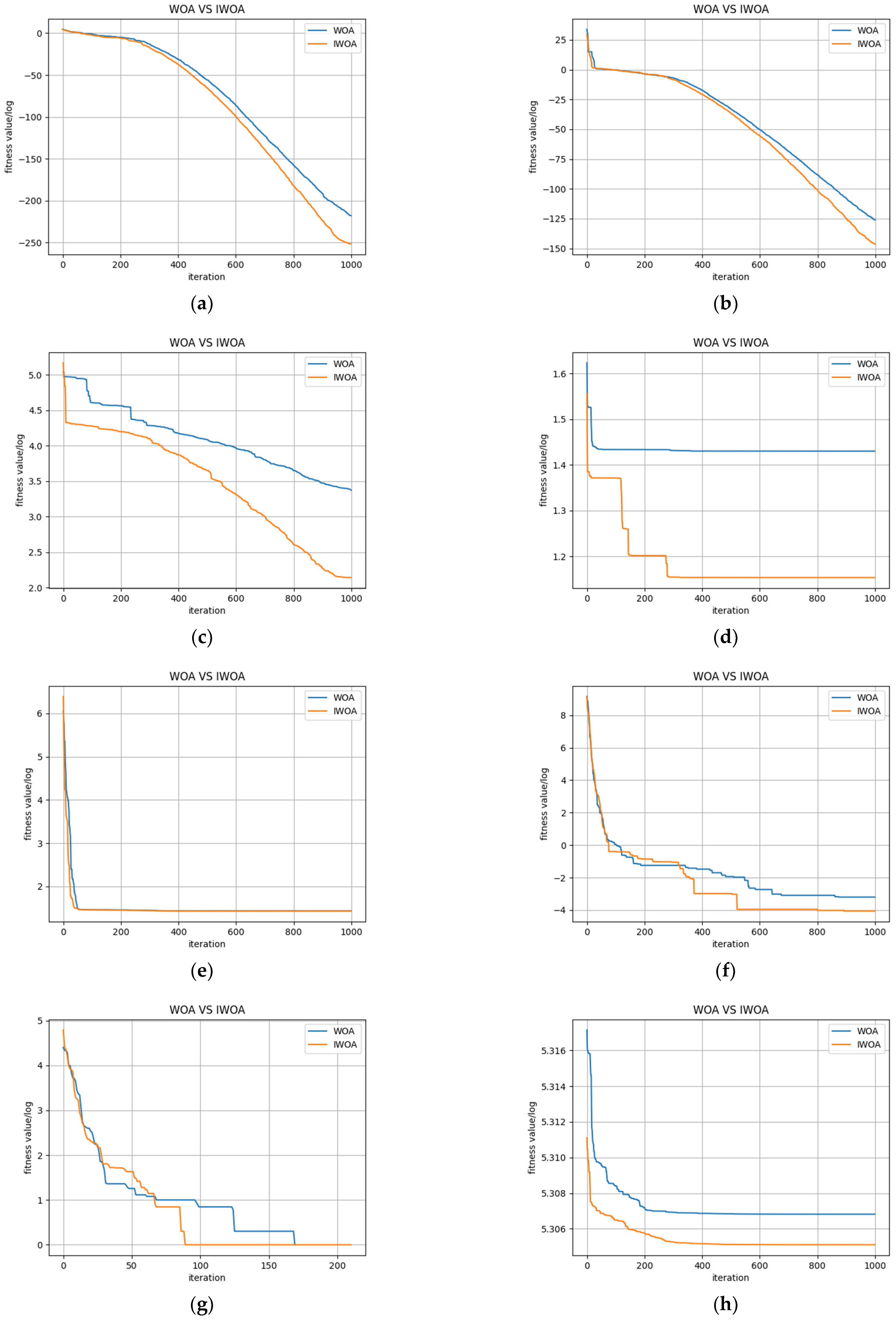
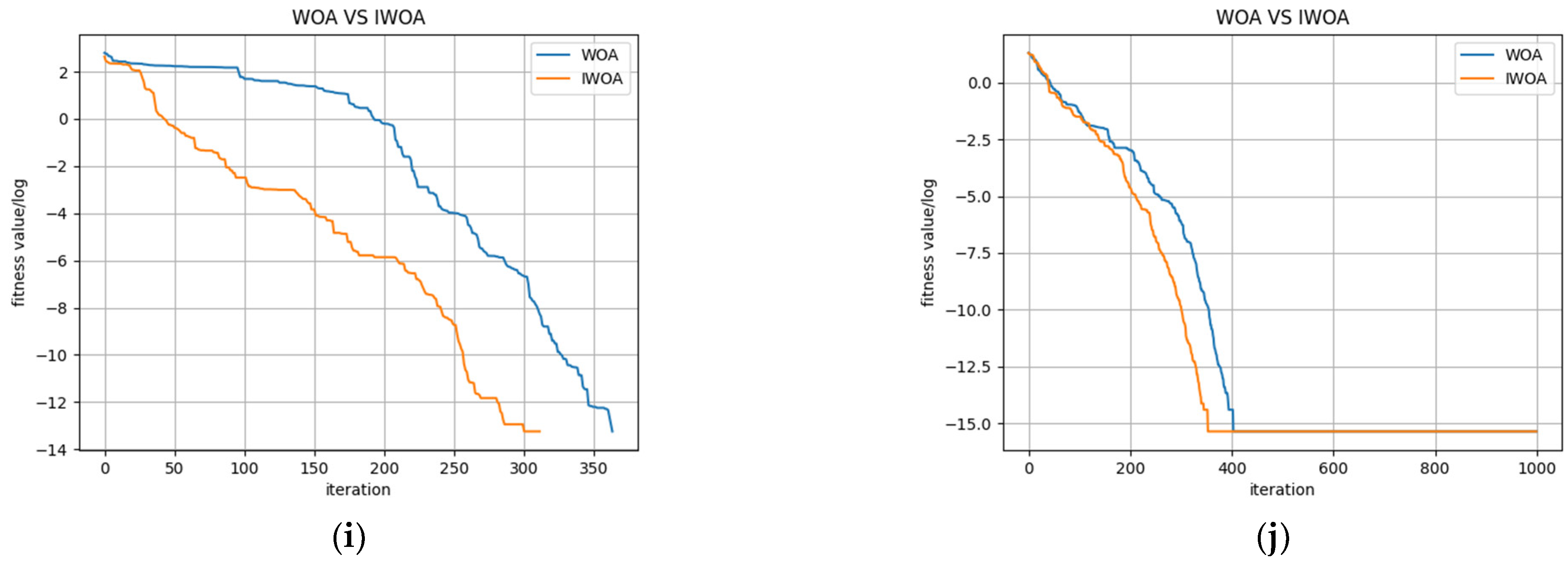
To verify the validity and effectiveness of the multi-strategy improvement of the WHO, simulations were carried out for each test function in which the maximum number of algorithm iterations was set to 1000 and the number of populations was set to 30. The optimal iterative convergence curves for each test function are shown in Figure 5.
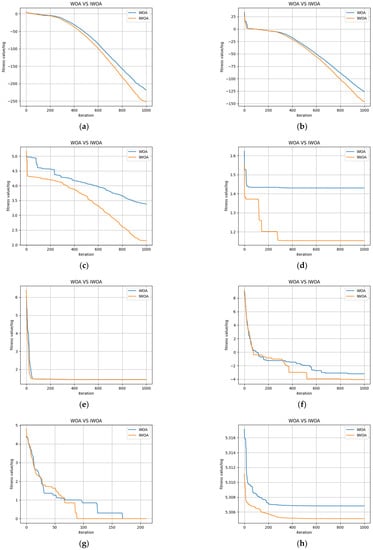
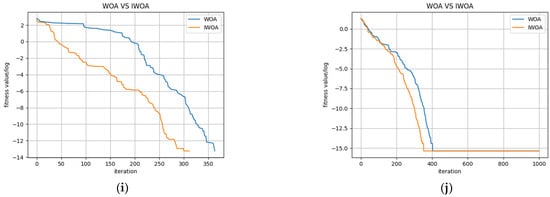
Figure 5.
Convergence curves of each test function. (a) Comparison of the two algorithms on f1; (b) Comparison of the two algorithms on f2; (c) Comparison of the two algorithms on f3; (d) Comparison of the two algorithms on f4; (e) Comparison of the two algorithms on f5; (f) Comparison of the two algorithms on f6; (g) Comparison of the two algorithms on f7; (h) Comparison of the two algorithms on f8; (i) Comparison of the two algorithms on f9; (j) Comparison of the two algorithms on f10.
The optimised values of the test functions used for this study were all 0. The horizontal coordinate of each curve in Figure 5 is the number of iterations, and the vertical coordinate the is value of the logarithm of the fitness value. A smaller value of the vertical coordinate corresponds to a higher convergence accuracy of the model. As shown in Figure 5, IWOA not only had high convergence accuracy but also a faster convergence speed throughout the entire search process for each given benchmark test set. These results show that IWOA has benefitted from the higher degree of diversity in the initial population and nonlinear adaptive weights, as well as the Levy flight strategy. These improvements allow the weights in IWOA to change adaptively with the current population and individual fitness values. Regions in the search space where optimal solutions may exist can therefore be rapidly searched for during the initial iterations while balancing global search and local exploitation capabilities in the process of finding the optimal solution. This avoids the process of ineffective iterations in WOA and effectively increases the convergence speed of the algorithm.
In this study, IWOA algorithm was used to optimize the hyperparameters of the LSTM network. The optimized hyperparameters of LSTM model were set as follows:” Hidden layers =2”, ”Number of neurons in the first layer = 115”, “Number of second layer neurons = 55”, ”Dropout = 0.2”, ”epoch = 11”, and ”batch-size = 256”.
4.3. CEEMDAN Decomposition and Reconstruction of Residual Sequences
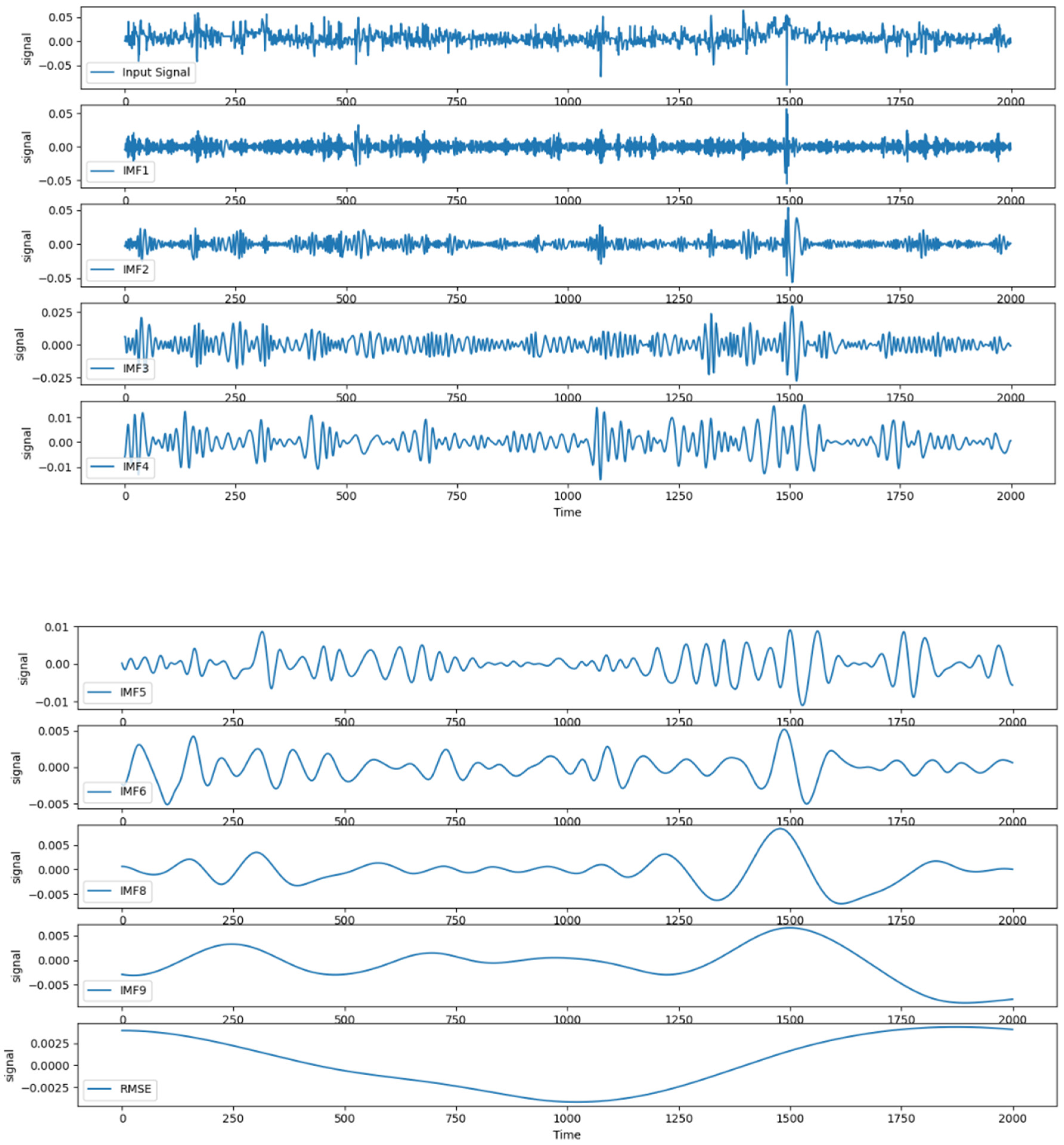
Considering the non-smoothness of the residual series, the residual series was first decomposed using the CEEMDAN method. The results are shown in Figure 6.
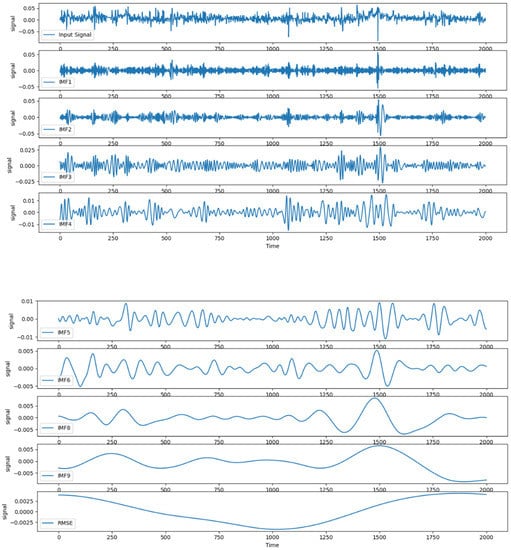
Figure 6.
CEEMDAN decomposition of residual sequences.
Because the non-smoothness of the residual series results in the existence of more IMF components in the CEEMDAN decomposition, the residual assignment method was used to calculate the weights of the prediction errors of each eigenmodal component during the assignment of weights to the predicted values of each eigenmodal component. This resulted in the restructuring and merger of the subseries. The dataset of each sub-series was divided into training, validation, and test sets at a ratio of 7:2:1. The divided dataset was input into the IWOA-LSTM model for training and the data in the test set used for testing. The mean absolute errors of the true and predicted values and the weights were calculated using Equations (37) and (40), respectively, and are shown in Table 4.
Table 4.
Prediction errors and weights of each subsequence.
Using the weights obtained from Table 4 and Equation (29), the value of the normalised reconstructed sequence could be obtained. Inverse normalisation was then performed to obtain the CEEMDAN reconstructed residual correction sequence, which was added to the predicted values from the IWOA-LSTM model to obtain the final prediction values of the IWOA-LSEM-CEEMDAN residual correction model.
4.4. Model Prediction Analysis and Comparison
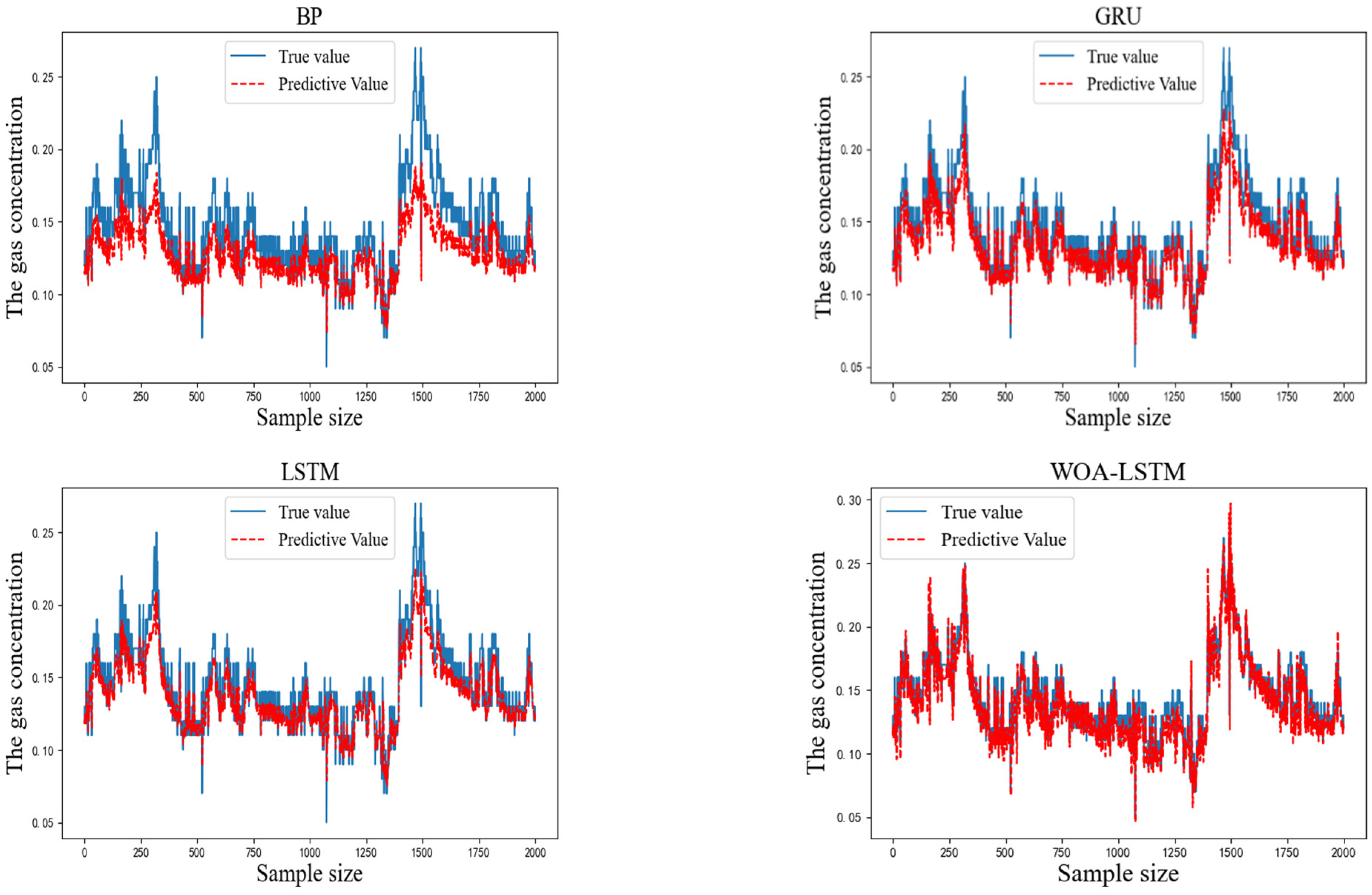
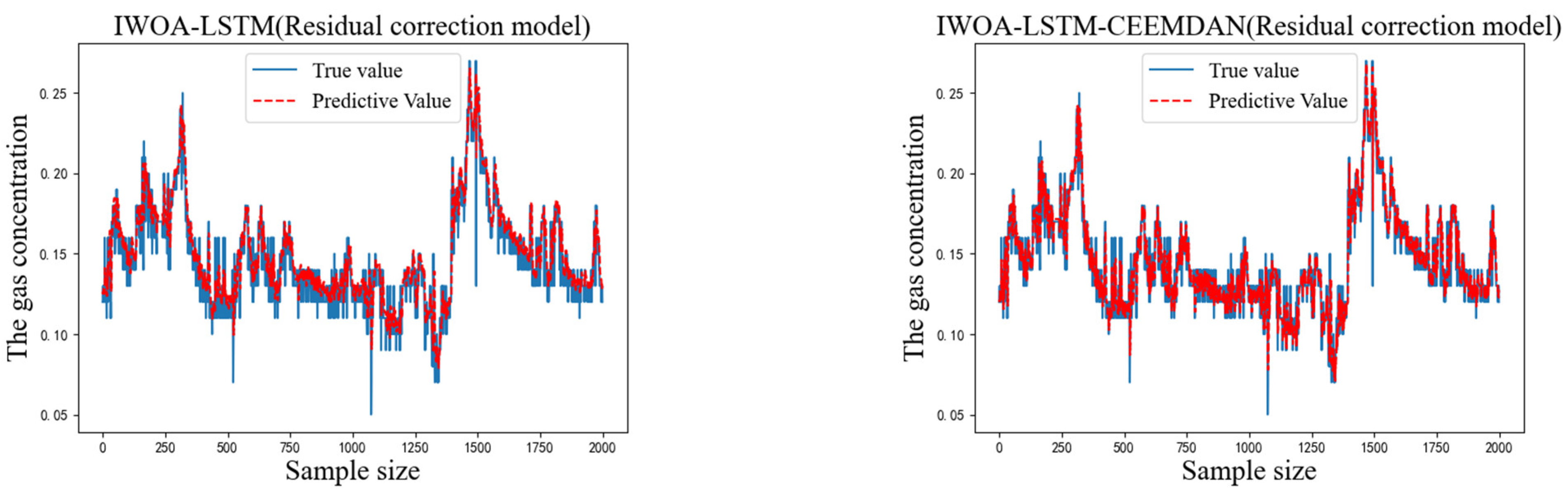
To verify the accuracy of the proposed IWOA-LSTM-CEEMDAN residual correction model, the BP, GRU, LSTM, WOA-LSTM, and IWOA-LSTM (residual correction) models were used for comparison tests. The prediction results from the different models are shown in Figure 7.
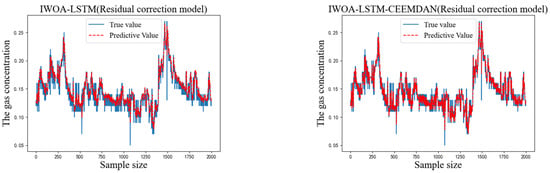
Figure 7.
Predicted and actual results for each model.
As can be seen from the above graphs, the IWOA-LSTM-CEEMDAN residual correction model achieved a higher prediction accuracy than the traditional machine learning, WOA-LSTM, and IWOA-LSTM residual correction models. A comparison of the single-step prediction values and the multi-step prediction MAE and RMSE values (prediction step of 3) for each model is shown in Table 5.
Table 5.
Comparison of model evaluation indicators.
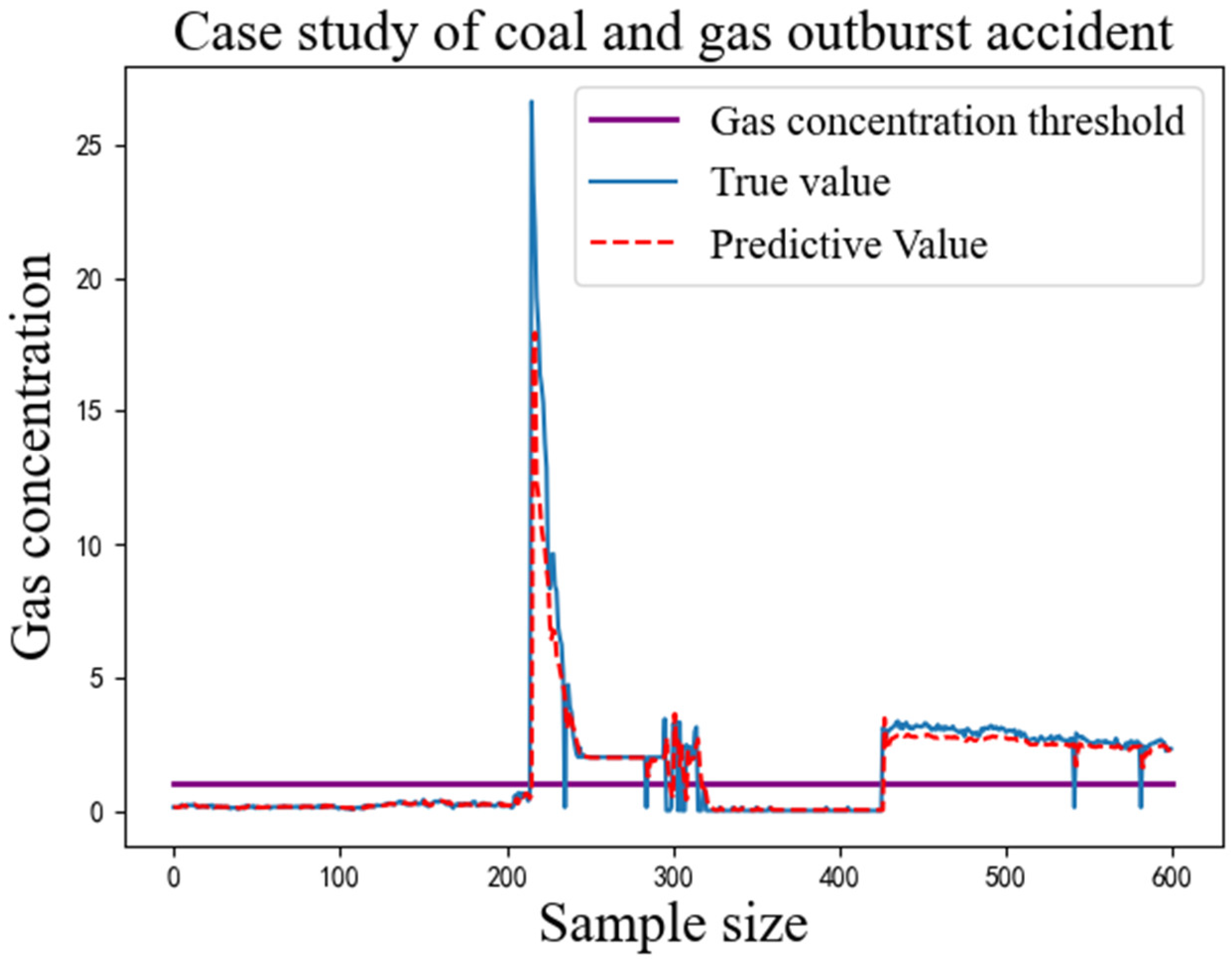
The MAE and RMSE values of each model are the average values obtained from the model trained ten times with the same parameters. The MAE and RMSE values of the IWOA-LSTM-CEEMDAN residual correction model proposed in this study are the smallest among all models for both single-step and multi-step prediction. This proves that the gas concentration prediction model proposed in this study has a higher prediction accuracy. Because the purpose of the above models is to predict gas concentrations for safe operation of gas mines, the ability of the proposed model to act as an early warning indicator for actual gas accidents was verified using the data recorded by detection equipment for the mine gas concentration on the eve of a coal and gas outburst accident in 2021. The prediction results obtained by inputting these data into the proposed model are shown in Figure 8.
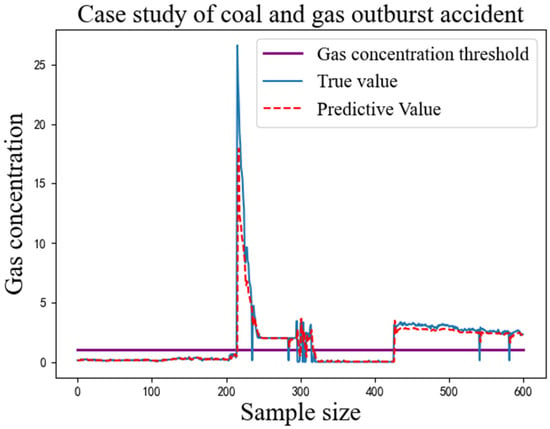
Figure 8.
Case study of coal and gas outburst accident.
As can be seen in Figure 8, the proposed model was able to replicate the gas concentration trends over a period of time before the coal and gas protrusion accident occurred. When the predicted value of the gas concentration is greater than a threshold, the manager can inform the underground operators to stop work immediately and withdraw from the mine. The gas concentration can be artificially reduced through means such as gas extraction and the spraying of water mist and the gas concentration waited to stabilise to a safe value before resuming operations.
4.5. Model Generalisability Analysis
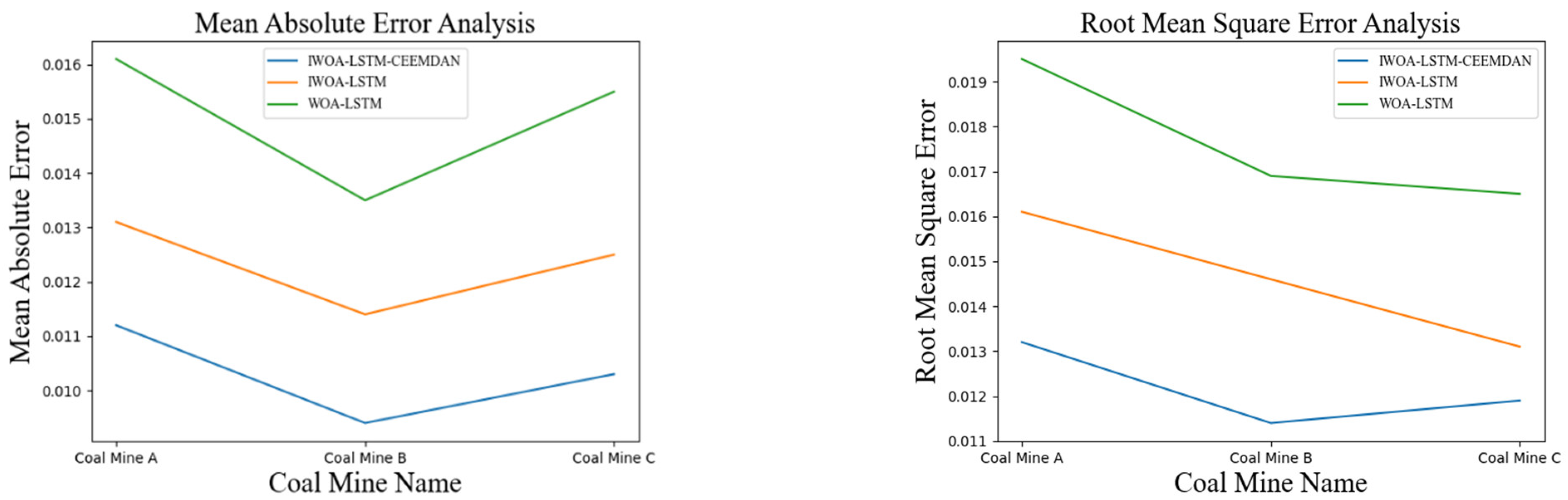
During the selection of the study area, it was found that different regional coal mines have strong local characteristics. Coal and gas protrusion is a phenomenon involving the sudden destruction of gas-containing media in which the destroyed solids become the subject of the protrusion event. The coal structure in each coal mine is the main factor that determines the coal seam [33]. Therefore, to verify the generality of the proposed algorithm, a prediction analysis was carried out for the gas concentrations at three different coal mines comprising of the Shanxi (A), Yunnan (B), and Anhui (C) mines. The results of the comparison are shown in Figure 9.
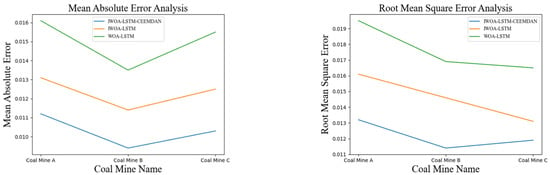
Figure 9.
Model evaluation indicators for different coal mines.
As shown in Figure 9, the IWOA-LSTM-CEEMDAN model proposed in this study was compared with the WOA-LSTM model and the IWOA-LSTM residual correction model and validated on several coal mine datasets. The IWOA-LSTM-CEEMDAN achieved the smallest MAE and RMSE values, which further illustrates the good generalisability of the proposed prediction model.
5. Conclusions
To improve the accuracy of predicted gas concentrations, a multi-strategy IWOA algorithm was proposed in this study to address the shortcomings of the standard WOA algorithm. Deep learning techniques were applied for gas concentration prediction. An LSTM network model based on the IWOA algorithm was proposed, and the CEEMDAN algorithm was used to perform a multimodal decomposition and reconstruction of the prediction error of the LSTM model. The IWOA-LSTM-CEEMDAN residual correction model was then established by assigning weights to the residuals and reconstructing the residual-corrected sequences based on the prediction errors of each normalised subsequence. The following contributions were achieved in this study:
- A multi-strategy optimisation of the WOA algorithm was proposed to improve the convergence speed and convergence accuracy of the algorithm. Through the use of benchmark test functions, the convergence accuracy and convergence speed of the improved algorithm were verified to be improved compared with those of the original model.
- To improve the prediction accuracy of the residual correction model, a multimodal decomposition of the residual series was performed using the CEEMDAN algorithm. Each sub-series was then predicted separately, and weights were assigned to each sub-series through residual assignment. The reorganized residual correction series resulted in an obvious improvement in the prediction accuracy of the model.
A gas accident is a serious safety incident in coal mining. It endangers the safety of coal mining enterprises, causes huge economic losses and, more importantly, puts the lives of workers at risk. Therefore, it is imperative that gas concentration forecasts are undertaken. The results in this study show that it is entirely feasible to apply the IWOA-LSTM-CEEMDAN residual correction model to analyse and predict gas concentrations. These predictions can effectively reflect the future development trends of the gas concentration and provide a scientific basis for coal mining enterprises to take safety measures in advance [34]. Because of the limitations of the data in this study, the properties of the mine itself, such as the seam thickness and roof pressure, were not taken into account. In future research, more comprehensive data attributes will be collected to improve the prediction accuracy of the model, and the time step will be extended while maintaining the accuracy of the model prediction to give underground workers more time to escape in the event of a gas incident.
Author Contributions
Conceptualization, X.W. and N.X.; methodology, N.X.; software, N.X.; validation, X.M. and X.W.; formal analysis, H.C.; investigation, X.W.; resources, X.W.; data curation, N.X.; writing—original draft preparation, N.X.; writing—review and editing, X.W.; visualization, H.C.; supervision, X.W.; project administration, X.M.; funding acquisition, X.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Natural Science Foundation of China (51874003, 51474007) and the Academic Funding Projects for Top Talents in Disciplines and Majors of Anhui (gxbjZD2021051).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are available in a publicly accessible repository. The partial data presented in this study are openly available in [Gas concentration prediction dataset, Mendeley Data], doi:10.17632/p3n7k6hxgw.1.
Acknowledgments
Many people have offered me valuable help in my thesis writing, including my students, my family, and the National Natural Science Foundation of China. They have been of great help for me to successfully finish this article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Xu, Y.; Meng, R.T.; Zhao, X. Research on a gas concentration prediction algorithm based on stacking. Sensors 2021, 21, 1597. [Google Scholar] [CrossRef] [PubMed]
- Deng, G. Current status and prospects of coal and gas outburst prediction and prevention technology. IOP Conf. Ser. Earth Environ. Sci. 2021, 651, 032096. [Google Scholar] [CrossRef]
- Lang, X.M. Prediction of mine gas content and emission amount based on gas geology theory. Coal Technol. 2016, 35, 210–211. [Google Scholar] [CrossRef]
- Liu, X.Q. Mathematical model and 3D numerical simulation of coal and gas outburst. Eng. Res. 2016, 21–24. [Google Scholar] [CrossRef]
- Zhang, Z.X. Development of mathematical model software for gas geology. Coalf. Geol. Explor. 2002, 2, 28–30. [Google Scholar]
- Jiang, L. Construction and simulation of coal mine gas concentration prediction model based on BP neural network. Min. Saf. Environ. Prot. 2010, 37, 37–39. [Google Scholar]
- Wang, P.; Wu, Y.P. Study on Lagrange-ARIMA real-time prediction model of mine gas concentration. Coal Sci. Technol. 2019, 47, 141–146. [Google Scholar] [CrossRef]
- Cong, Y.; Zhao, X.; Tang, K. FA-LSTM: A novel toxic gas concentration prediction model in pollutant environment. IEEE Access 2022, 10, 1591–1602. [Google Scholar] [CrossRef]
- Dey, P.; Saurabh, K.; Kumar, C.; Pandit, D.; Chaulya, S.K.; Ray, S.K.; Prasad, G.M.; Mandal, S.K. t-SNE and variational auto-encoder with a bi-LSTM neural network-based model for prediction of gas concentration in a sealed-off area of underground coal mines. Soft Comput. 2021, 25, 14183–14207. [Google Scholar] [CrossRef]
- Cheng, Z.J.; Ma, L.Z. Spatial and temporal distribution prediction of gas concentration based on LSTM-FC. Comput. Eng. Appl. 2020, 56, 258–264. [Google Scholar]
- Liu, Y.J.; Zhao, Q. Research on gas concentration prediction based on BP neural network optimized by Genetic algorithm. Min. Saf. Environ. Prot. 2015, 42, 56–60. [Google Scholar]
- Wang, Y.H.; Wang, S.Y. Research on multi-parameter gas concentration prediction model based on improved locust algorithm and optimized long and short time memory neural network. J. Sens. Technol. 2021, 34, 1196–1203. [Google Scholar]
- Ma, L. Prediction model of coal mine gas concentration based on PSO-Adam-GRU. J. Xi’an Univ. Sci. Technol. 2020, 40, 363–368. [Google Scholar] [CrossRef]
- Fu, H. Prediction of coal mine gas concentration based on improved ABC-GRNN model. Control Eng. 2017, 24, 881–887. [Google Scholar]
- Kaur, G.; Arora, S. Chaotic whale optimization algorithm. J. Comput. Des. Eng. 2018, 5, 275–284. [Google Scholar] [CrossRef]
- Jiang, R.; Yang, M.; Wang, S.; Chao, T. An improved whale optimization algorithm with armed force program and strategic adjustment. Appl. Math. Model. 2020, 81, 603–623. [Google Scholar] [CrossRef]
- Li, J.; Li, Q. Research on medium term power load prediction based on CEEMDAN-permutation entropy and Leakage integral ESN. J. Electr. Mach. Control 2015, 19, 70–80. [Google Scholar] [CrossRef]
- Zhang, T.J.; Song, S.; Li, S.; Ma, L.; Pan, S.; Han, L. Research on gas concentration prediction models based on LSTM multidimensional time series. Energies 2019, 12, 161. [Google Scholar] [CrossRef]
- Lyu, P.Y.; Chen, N.; Mao, S.; Li, M. LSTM based encoder-decoder for short-term predictions of gas concentration using multi-sensor fusion. Process Saf. Environ. Prot. 2020, 137, 93–105. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, D.M. Whale optimization algorithm based on Gaussian mapping and keyhole imaging learning strategy. Comput. Appl. Res. 2020, 37, 3271–3275. [Google Scholar] [CrossRef]
- Zhou, X.Y.; Wu, Z.J. An elite reverse learning particle swarm optimization algorithm. Electron. J. 2013, 41, 1647–1652. [Google Scholar]
- Wang, L.; Wang, X.K. A particle swarm optimization algorithm for nonlinear changing inertial weights. Comput. Eng. Appl. 2007, 4, 47–48, 92. [Google Scholar]
- Ma, W.; Zhu, X. Sparrow search algorithm based on Levy flight disturbance strategy. J. Appl. Sci. 2022, 40, 116–130. [Google Scholar]
- Yang, X.S.; Deb, S. Multiobjective cuckoo search for design optimization. Comput. Oper. Res. 2013, 40, 1616–1624. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Shu, X.; Zhang, L.; Sun, Y.; Tang, J. Host–parasite: Graph LSTM-in-LSTM for group activity recognition. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 663–674. [Google Scholar] [CrossRef]
- Lei, Y.J.; Lin, J.; He, Z.; Zuo, M.J. A review on empirical mode decomposition in fault diagnosis of rotating machinery. Mech. Syst. Signal Process. 2013, 35, 108–126. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R. A new view of nonlinear water waves: The Hilbert spectrum. Annu. Rev. Fluid Mech. 1999, 31, 417–457. [Google Scholar] [CrossRef]
- Hassan, A.R.; Bhuiyan, M.I.H. Computer-aided sleep staging using Complete Ensemble Empirical Mode Decomposition with Adaptive Noise and bootstrap aggregating. Biomed. Signal Process. Control 2016, 24, 1–10. [Google Scholar] [CrossRef]
- Long, W.; Cai, S.H. Improved whale optimization algorithm for solving large scale optimization problems. Syst. Eng. Theory Pract. 2017, 37, 2983–2994. [Google Scholar]
- Zhang, Z.M.; Zhang, Y.G. Gas geological analysis of superlarge coal and gas outburst in Daping Coal Mine. J. Coal 2005, 2, 137–140. [Google Scholar] [CrossRef]
- Wang, S.Q. Gas Time Series Prediction and Anomaly Detection Based on Deep Learning; China Mining University: Beijing, China, 2018. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).