
Pangea: An MLOps Tool for Automatically Generating Infrastructure and Deploying Analytic Pipelines in Edge, Fog and Cloud Layers




Abstract
:1. Introduction
1.1. Problem Statement
- 1.
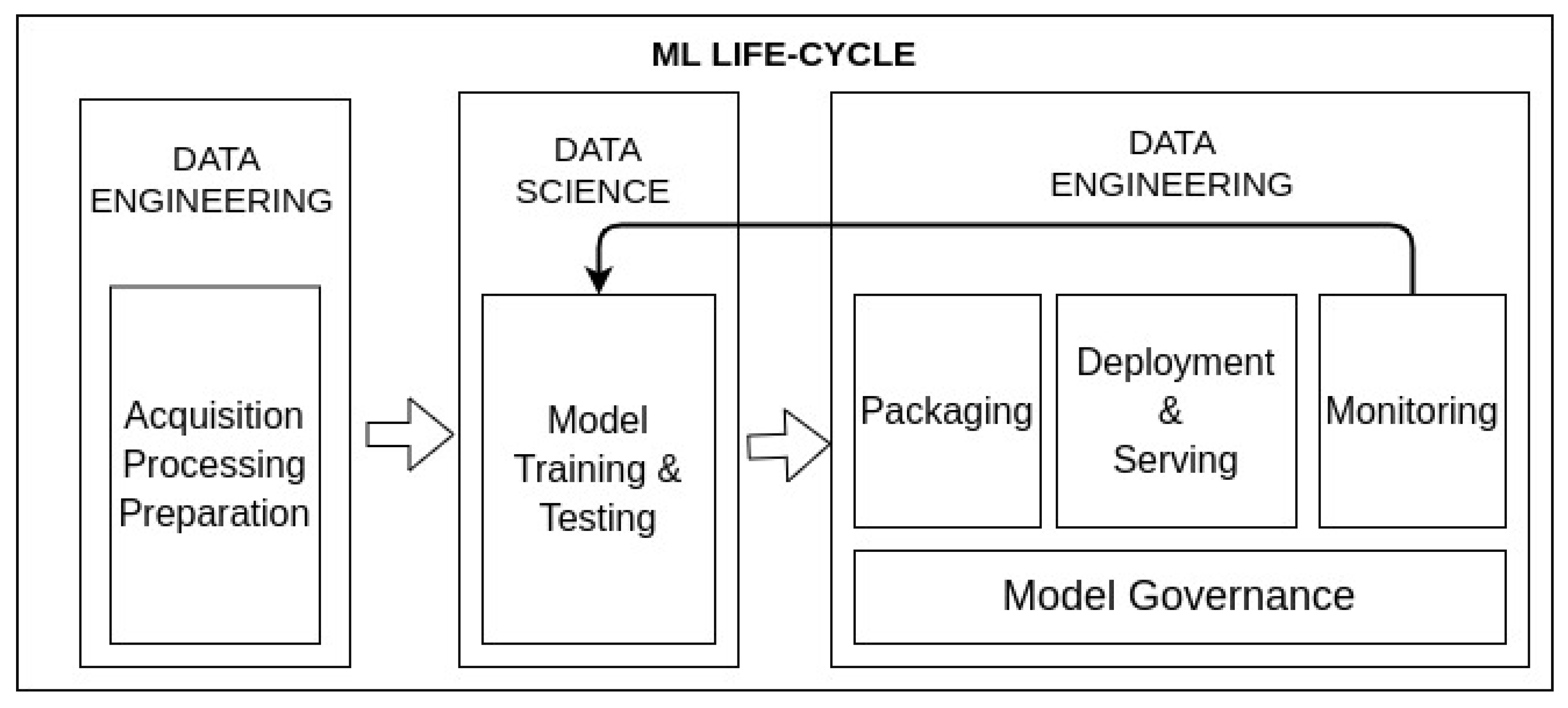
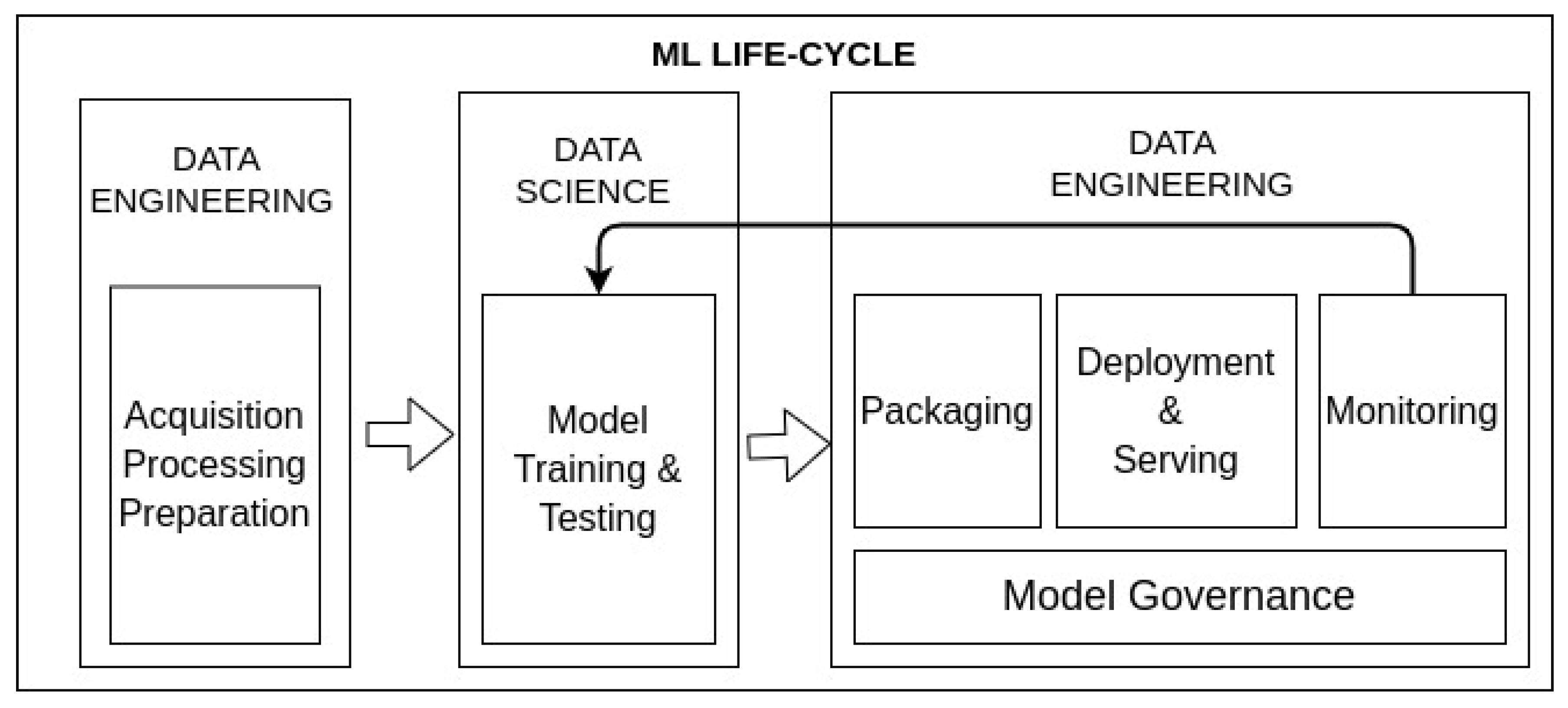
- Model packaging must be considered to enable automatising the ML life cycle where an enormous tool ecosystem is offered.
- 2.
- Model deploying involves providing the model built to production environments and serve it to be accessible from software clients and applications.
- 3.
- Model monitoring must be conducted to automatically detect model degradation and performance issues. As such, when anomaly behaviours are identified, models can be re-trained.
- 4.
- Model governance allows the tracking of models. The main approach is the provision of a model catalogue where related metainformation could be associated. Thus, models can be easily identified and found. In addition, having a suitable model catalogue paves the way for establishing authentication and authorisation policies over the models, as well as supporting auditing mechanisms.
1.2. Contribution
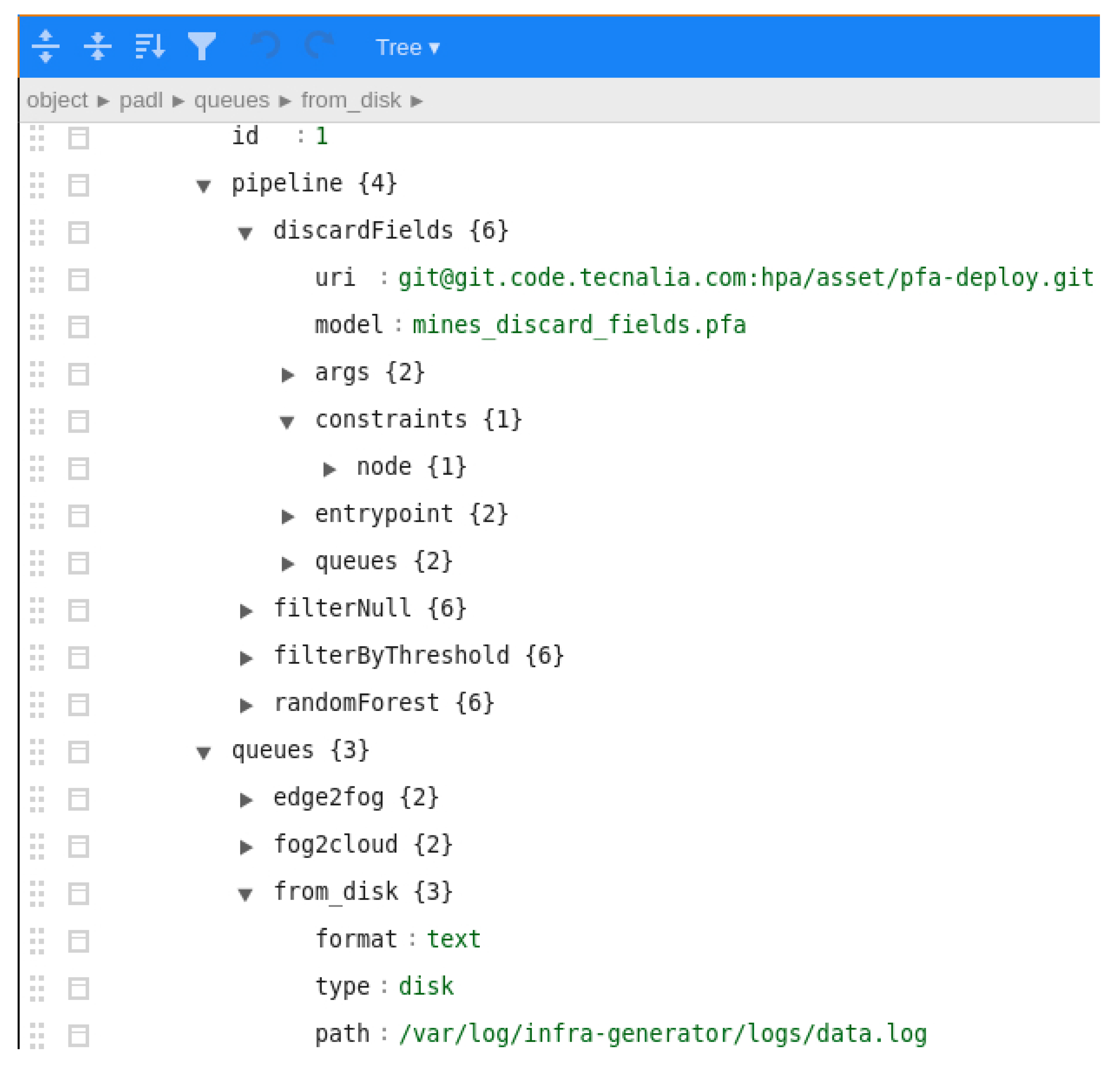
1.3. Motivation Example
- 1.
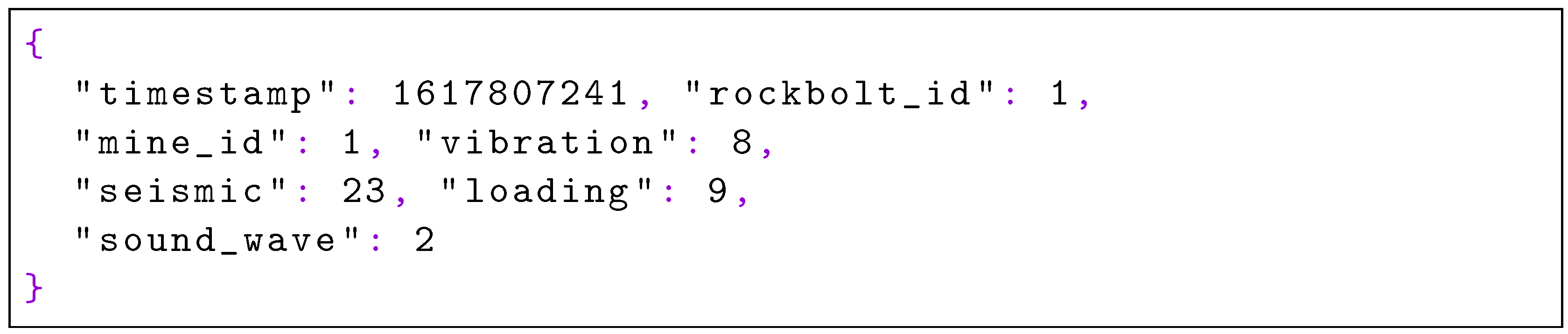
- Acquisition phase: data from intelligent rock bolts are collected.
- 2.
- Data cleaning phase: non-necessary fields are discarded to minimise the amount of data to transfer.
- 3.
- Data cleaning phase: both null values and bad readings, not covering a defined pattern, are filtered.
- 4.
- Data analysis phase: a previously trained classification model is executed to identify the non-safe areas in the mines.
1.4. Structure
2. Background
2.1. Infrastructure Automation
2.2. Analytic Pipelines
3. Related Works
- Generate infrastructure: the ability to create the necessary but not previously available infrastructure in cloud providers.
- Provision machines: being able to remotely configure, prepare and install libraries and software.
- Deployment of analytic pipelines in distinct machines: some approaches can deploy a model in a machine or deploy the whole analytic pipeline in the same machine. In this category, the objective seeks to be able to deploy each step of a pipeline in a separate machine.
- Edge, fog, cloud support: the possibility to somehow deal with these three computing layers.
4. Pangea in Deep
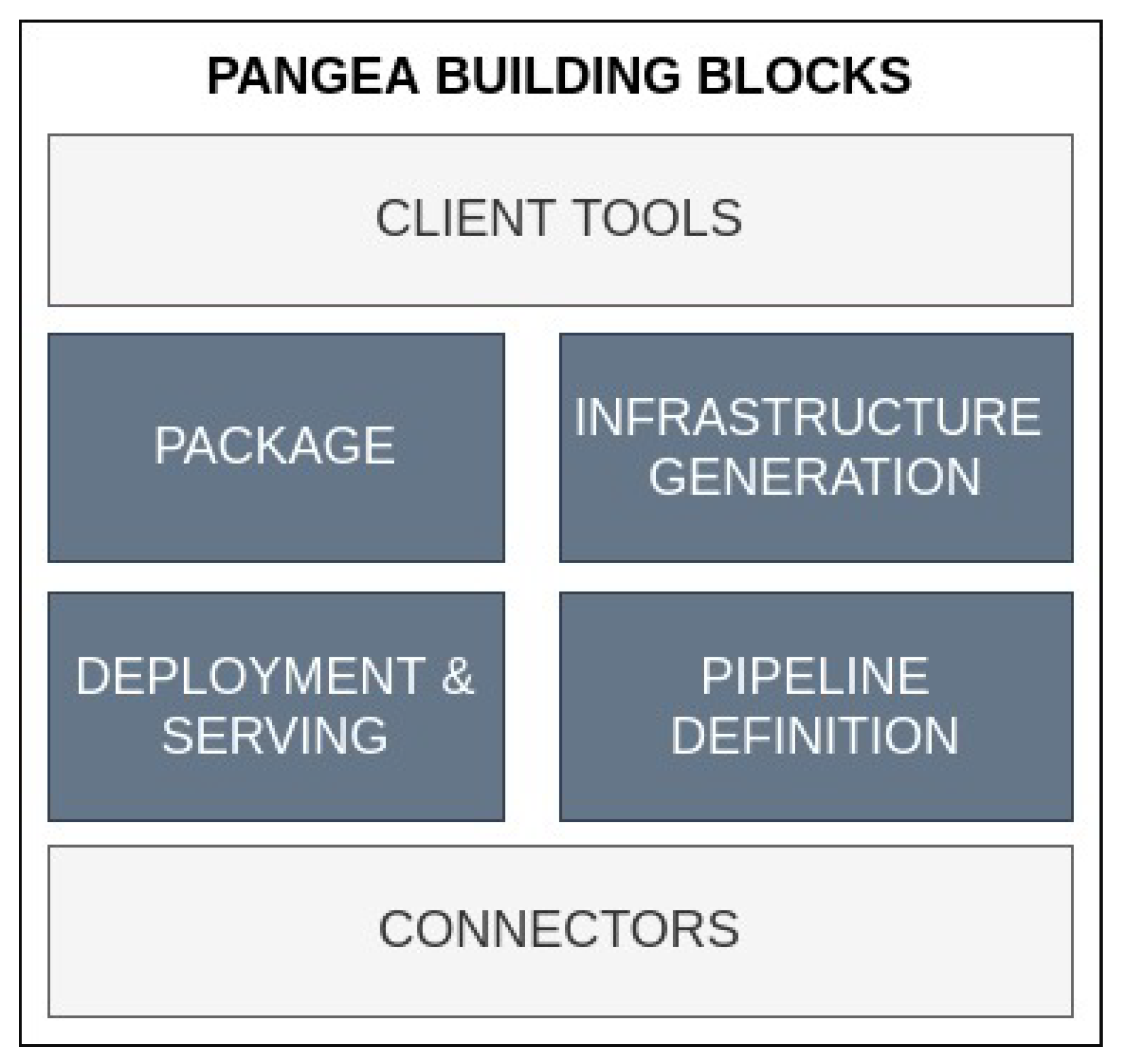
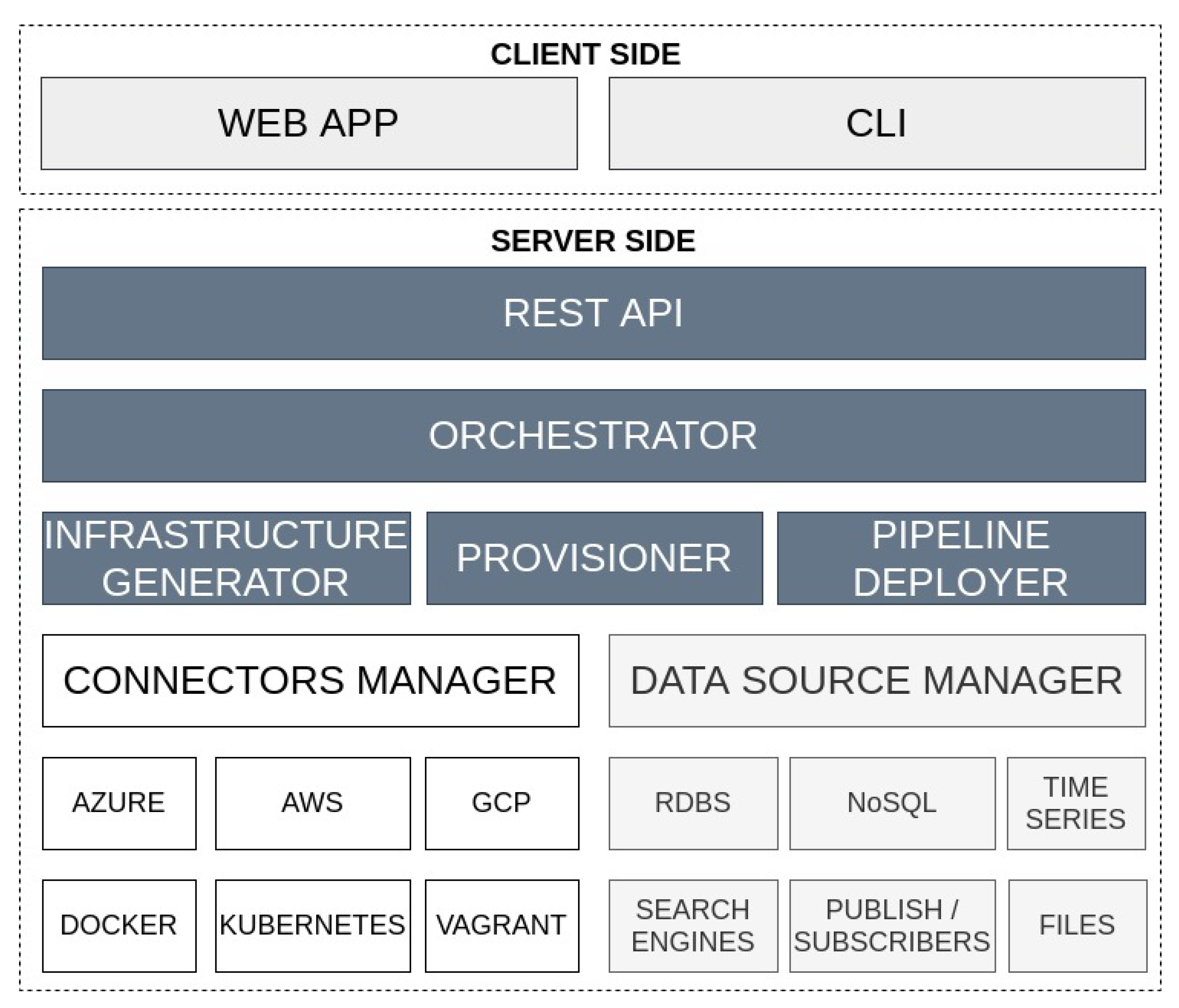
4.1. Overview
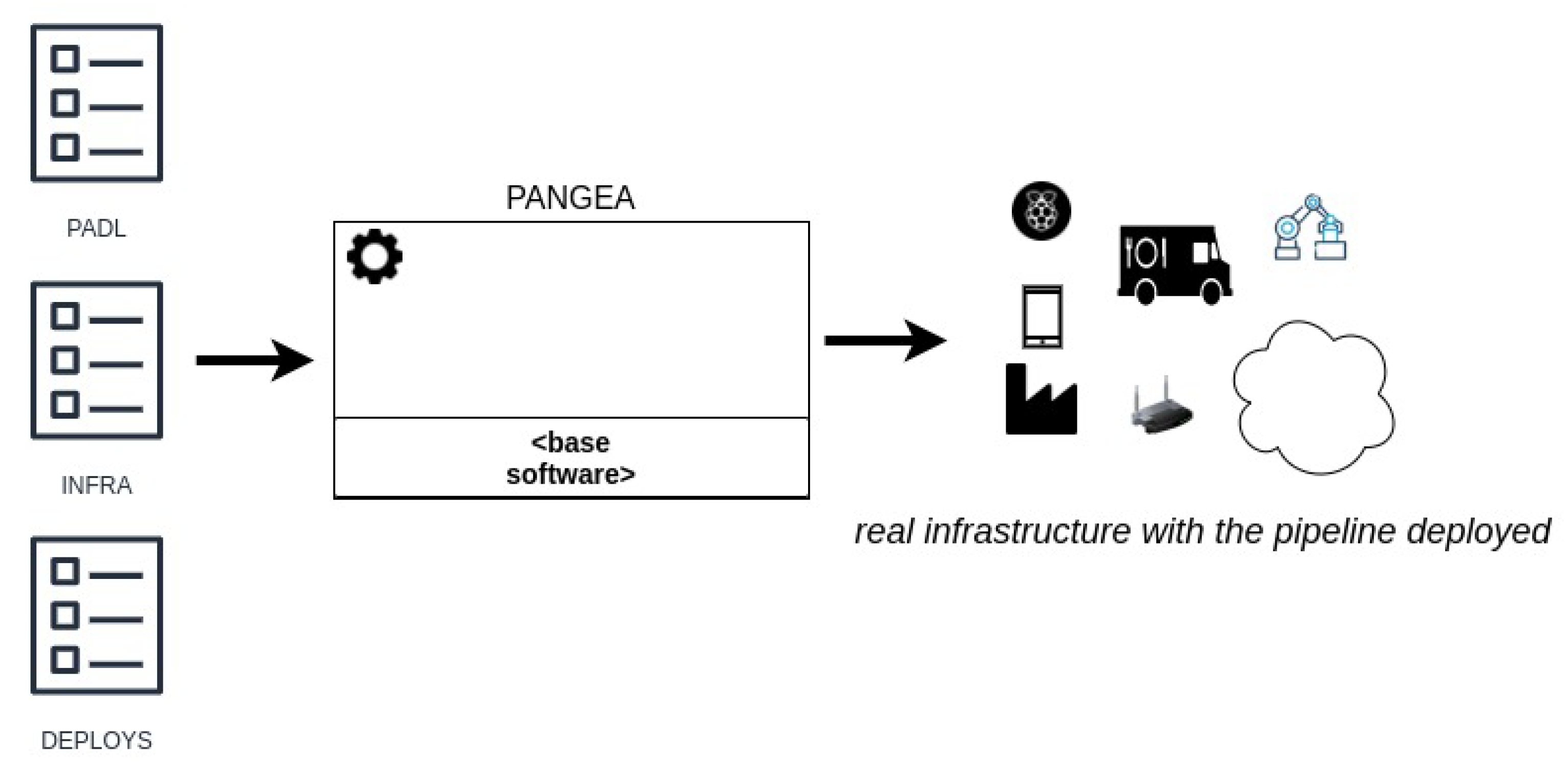
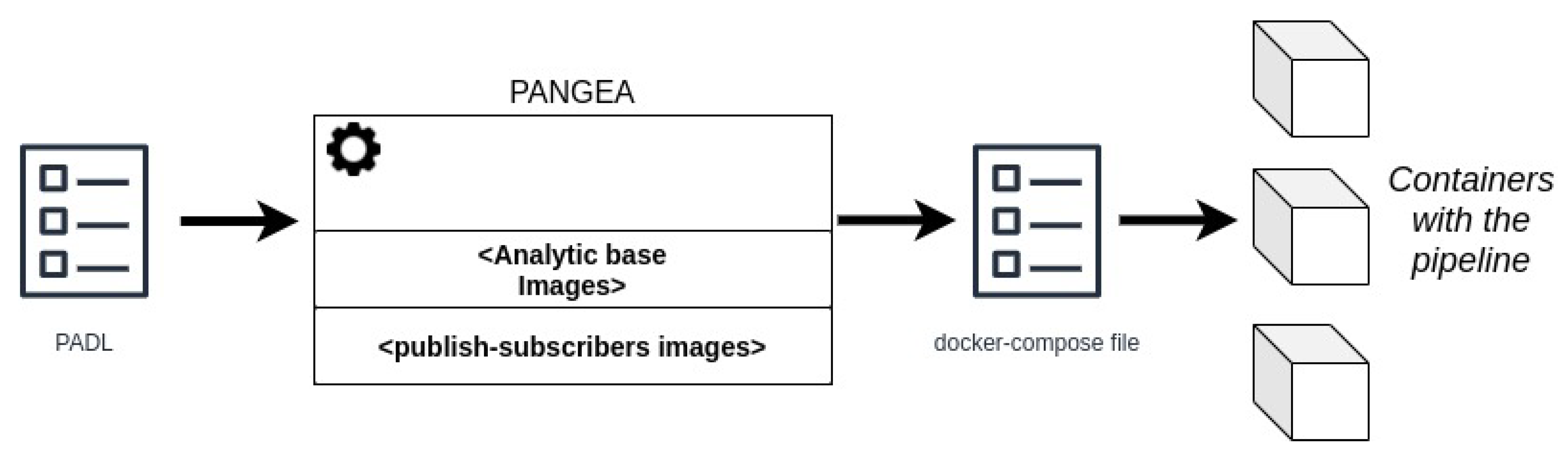
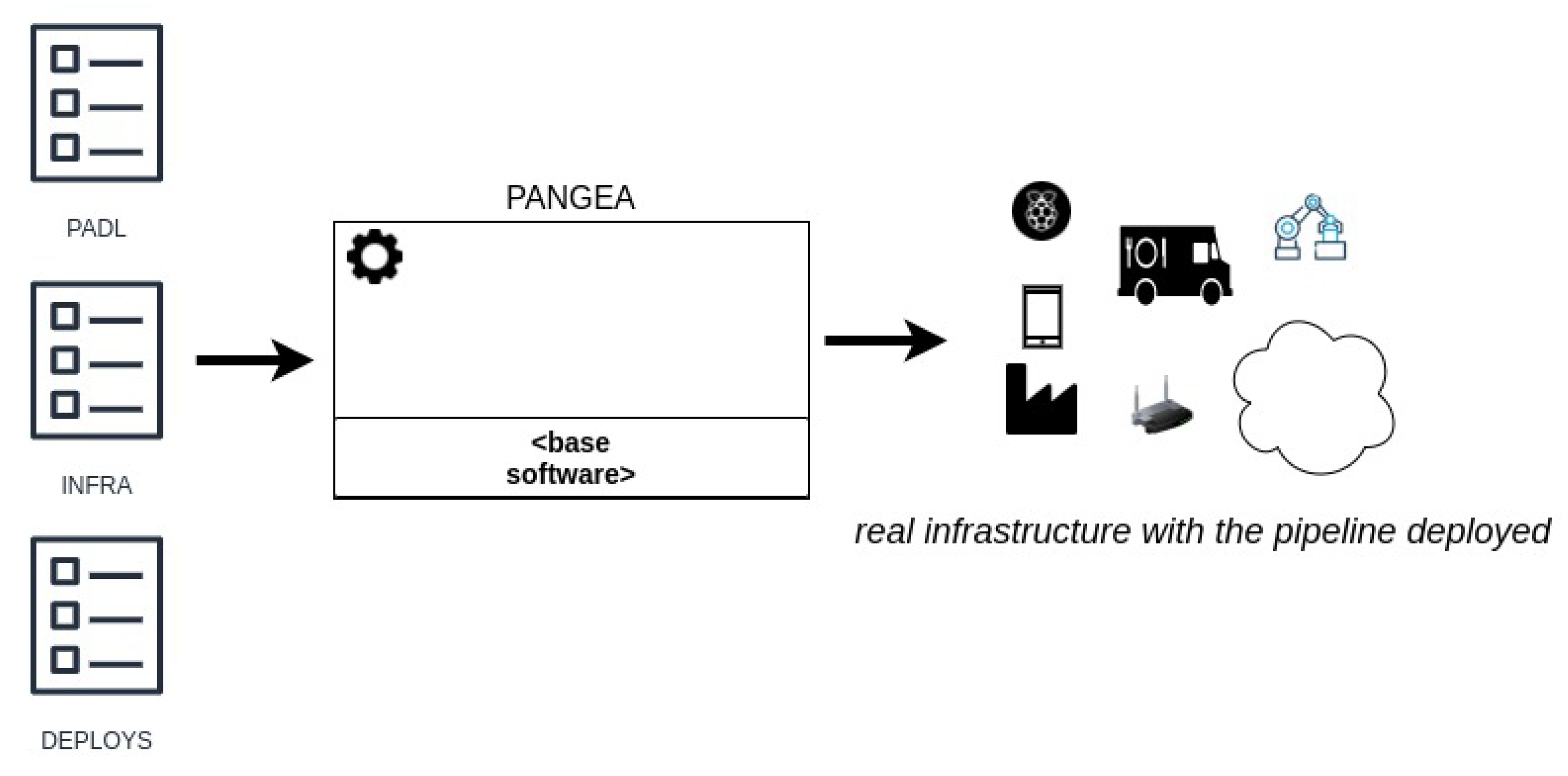
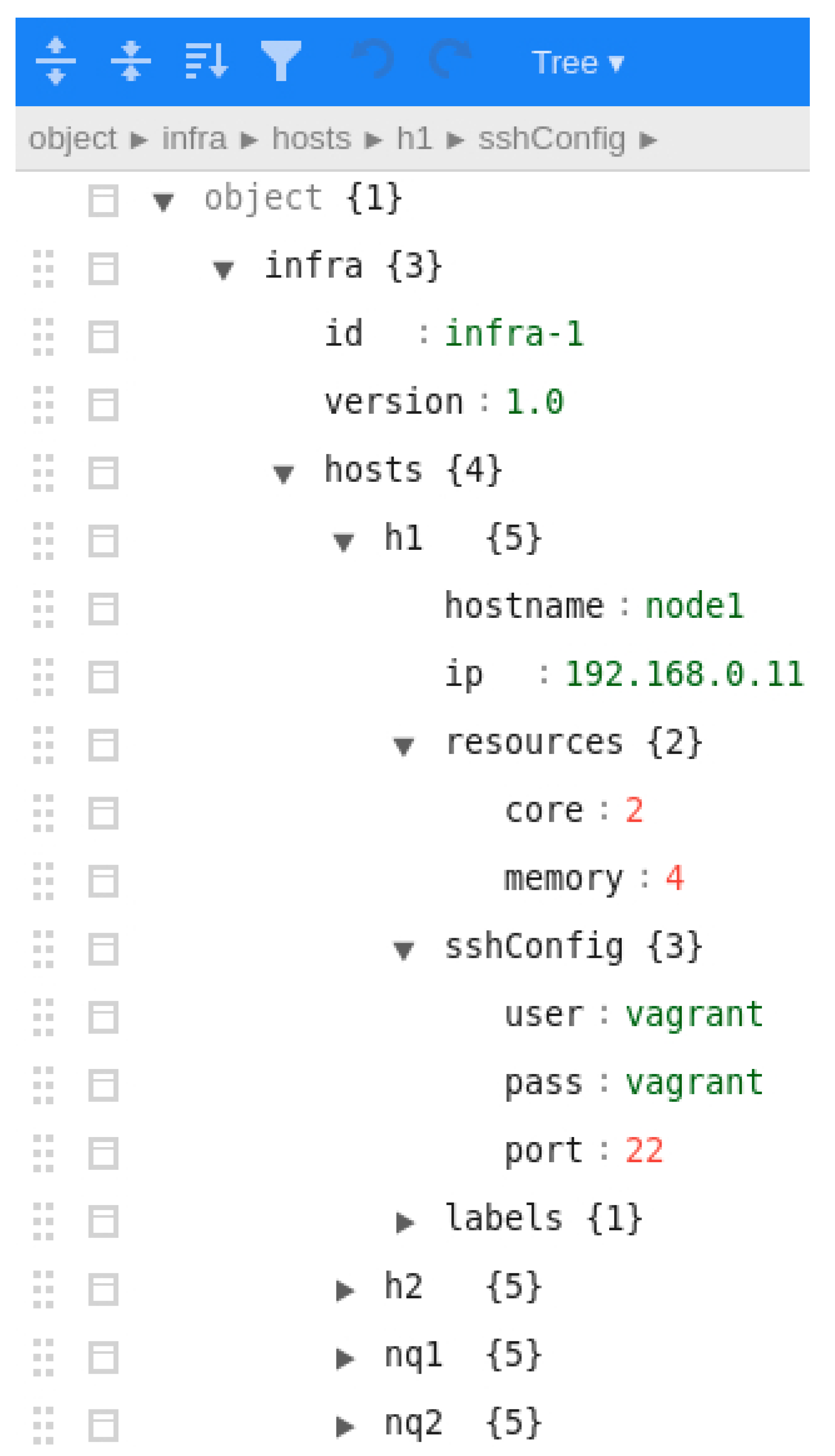
- Infrastructure document describes the infrastructure by listing the available nodes and their required properties such as universally unique identifiers (UUID), hostname, resources (CPU, number of cores, disk and memory) or root credentials for SSH access.
- Deploy map document: defines a mapping between the PADL and the infrastructure documents. Specifically, the hosts where the steps of the pipeline and the communication technologies must be deployed in. If the steps of the pipeline do not have any host assigned due to insufficient pre-existing infrastructure, a suitable infrastructure will be automatically generated for such steps.
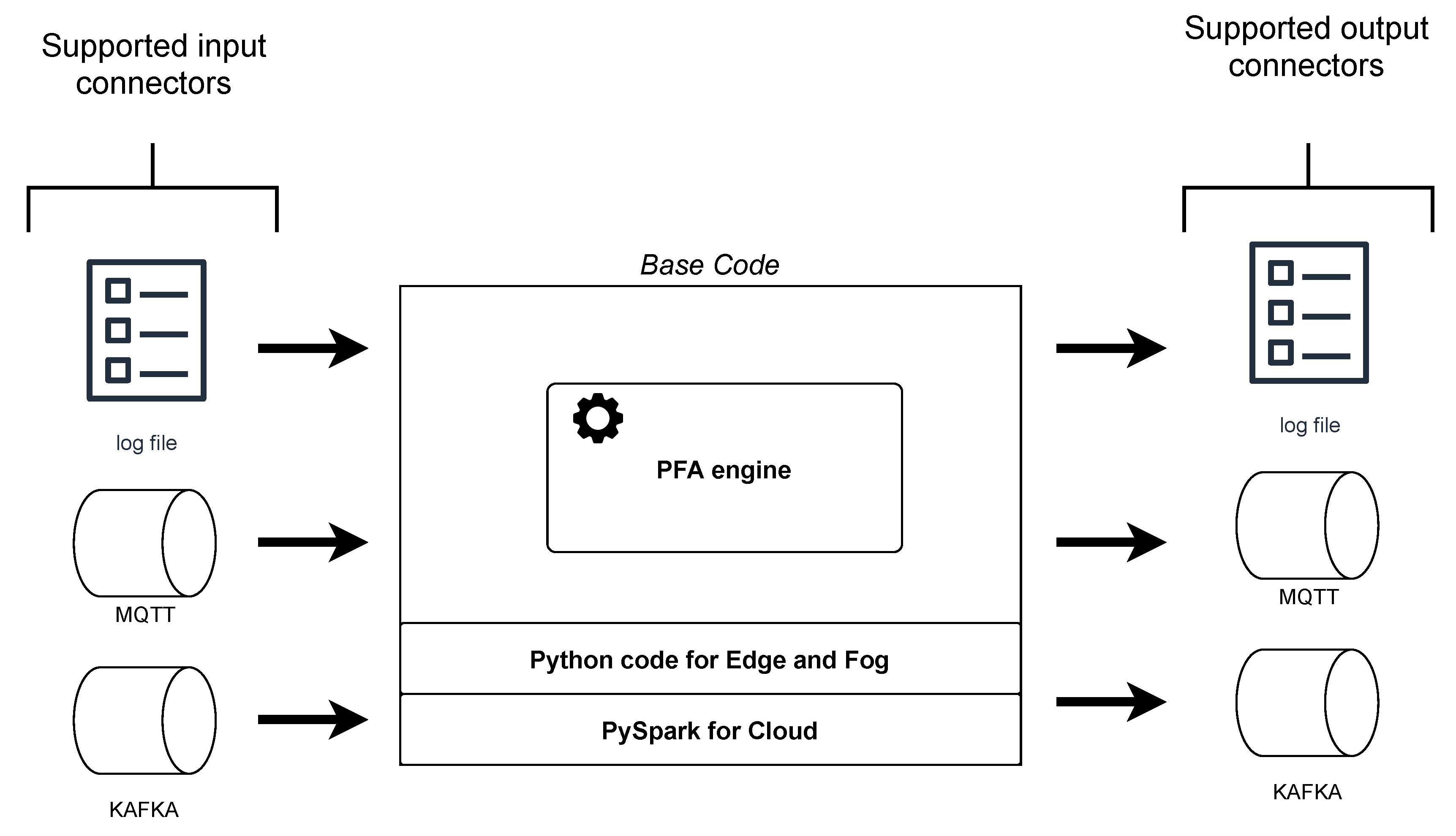
4.2. Compatible Models
4.3. Architecture
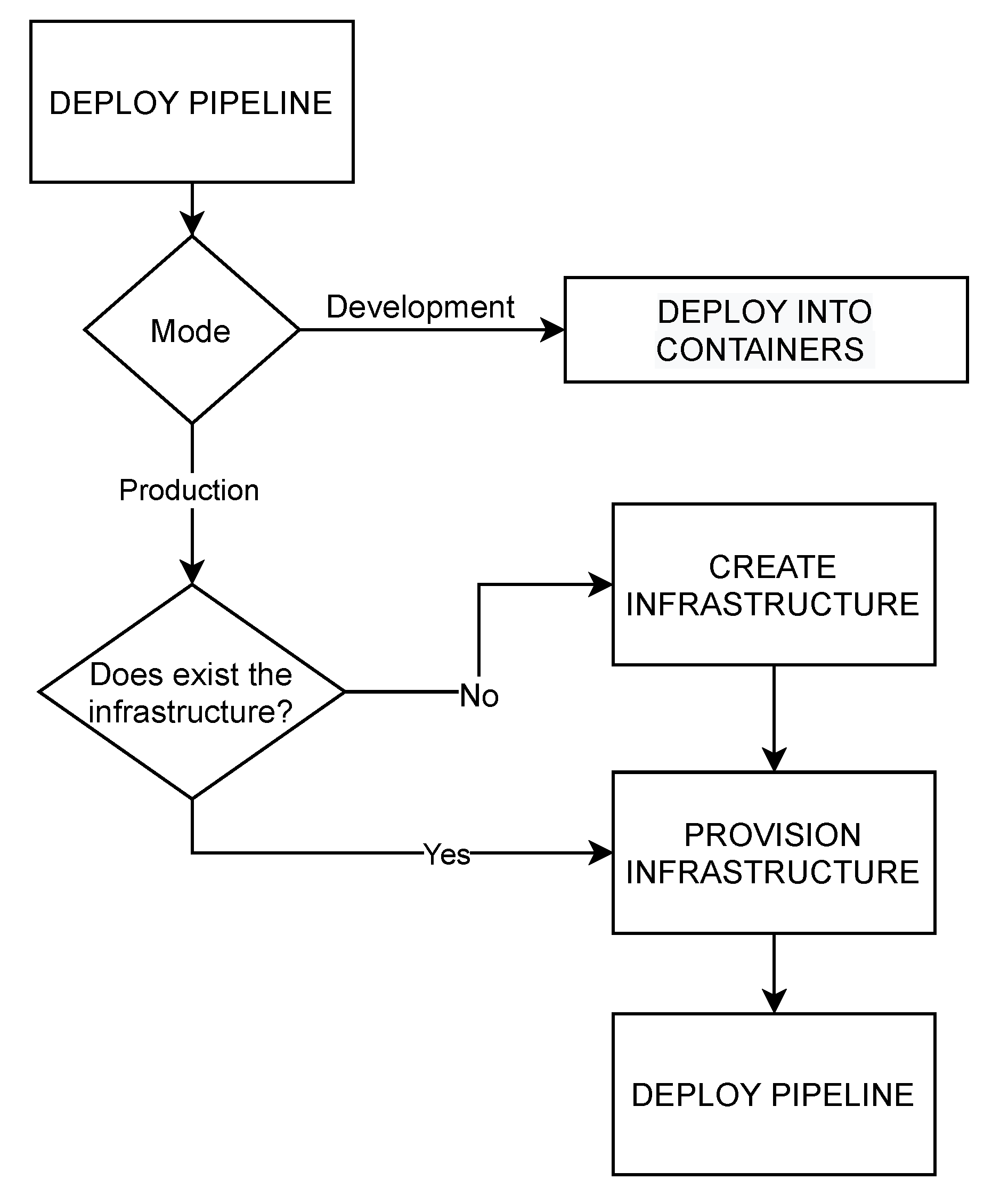
- 1.
- Whether the analytic pipeline requires being deployed in a development or production environment.
- 2.
- Whether it is necessary to create additional infrastructure and with which technologies or, in contrast, there is already sufficient infrastructure.
- 3.
- The configurations, dependencies and code required for executing each step of a given pipeline.
- RDBMS (Relational Database Management System) includes traditional databases for managing static data.
- NoSQL for scalable computations and support of distributed data.
- Time Series to enhance the management of temporal data.
- Search Engines for supporting complex data searches.
- Publish/subscribe technologies since they are widely used in real-time applications.
- File processing must be supported to deal with local or remote logs, comma-separated values (CSV), JavaScript Object Notation (JSON) or extensible markup language (XML).
4.4. Augmenting PADL with Expression Language

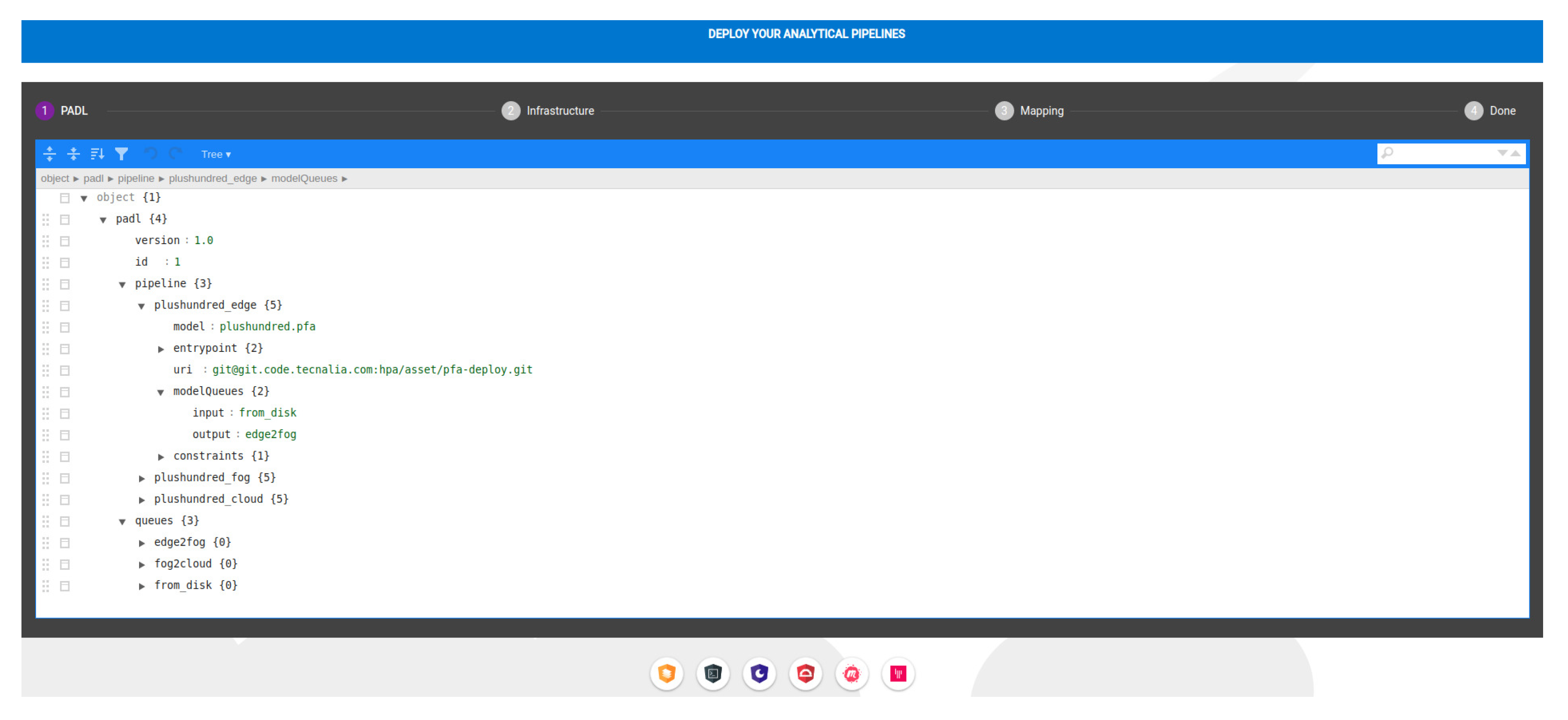
4.5. Web Client
4.6. Implementation
5. Validation
5.1. Objective and Design of the Experiment
- 1.
- Pangea can deploy analytic pipelines in heterogeneous environments in development and production modes.
- 2.
- If necessary, unavailable infrastructure must be generated.
- 3.
- The interaction with Pangea proposing a Web client which uses standard communication protocols such as HTTP (HyperText Transfer Protocol) can be facilitated.
- 1.
- Is Pangea able to assist in the deployment of a local pipeline for development?
- 2.
- Is Pangea able to deploy a pipeline in a production environment in an edge–fog–cloud infrastructure?
- 3.
- Is Pangea able to automatically create the required infrastructure?
- 4.
- Does the web client provide JSON editors to build the necessary files and can the web client submit such files to Pangea?
5.2. Execution Environment


5.3. Execution







- Parse of the input documents.
- Create the required infrastructure: in this step, the infrastructure marked as prescription in the deploy map document needs to be generated. For this purpose, a Terraform template is provided with variables that are generated on-the-fly by examining the input documents. Then, the terraform init and terraform apply processes are triggered to create the infrastructure using such a template populated with the necessary values. Finally, the correspondent data of the recently created infrastructure are integrated in the infra and deploy maps documents.
- Provision: this step configures the nodes and downloads and installs the necessary code. This process can be divided into a few sub-steps:
- (a)
- If there were hosts in the infra document not used in the deploy map document, they are discarded.
- (b)
- An Ansible inventory file is generated to manage the nodes to operate with.
- (c)
- An Ansible configuration file is generated
- (d)
- SSH access is configured in the nodes to be operated with Ansible.
- (e)
- Several Ansible playbooks are executed to install the required dependencies in each node. For instance, the installation of Git, Mosquitto, Kafka or Spark.
- (f)
- The file /etc/hosts of each node is configured with the IP and hostname of the rest of the nodes involved in the pipeline to facilitate communication among them.
- (g)
- The code to execute in each node is downloaded by using the previously installed Git client. Concretely, for this example, the image of the PFA engine code is downloaded in edge and fog nodes, and the PFA engine code integrated with PySpark is downloaded in the cloud node.
- Deploy: firstly, the expressions defined in the parameters of the entrypoint are evaluated to extract the values and then, the code is invoked in each node by another Ansible playbook with these parameters and the command is also defined in the entrypoint.
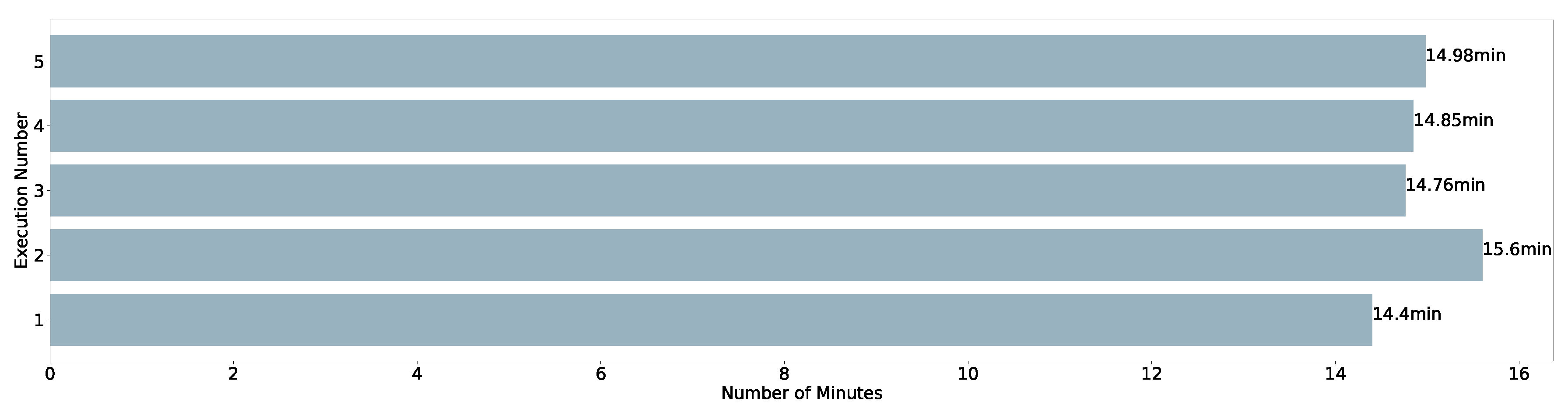
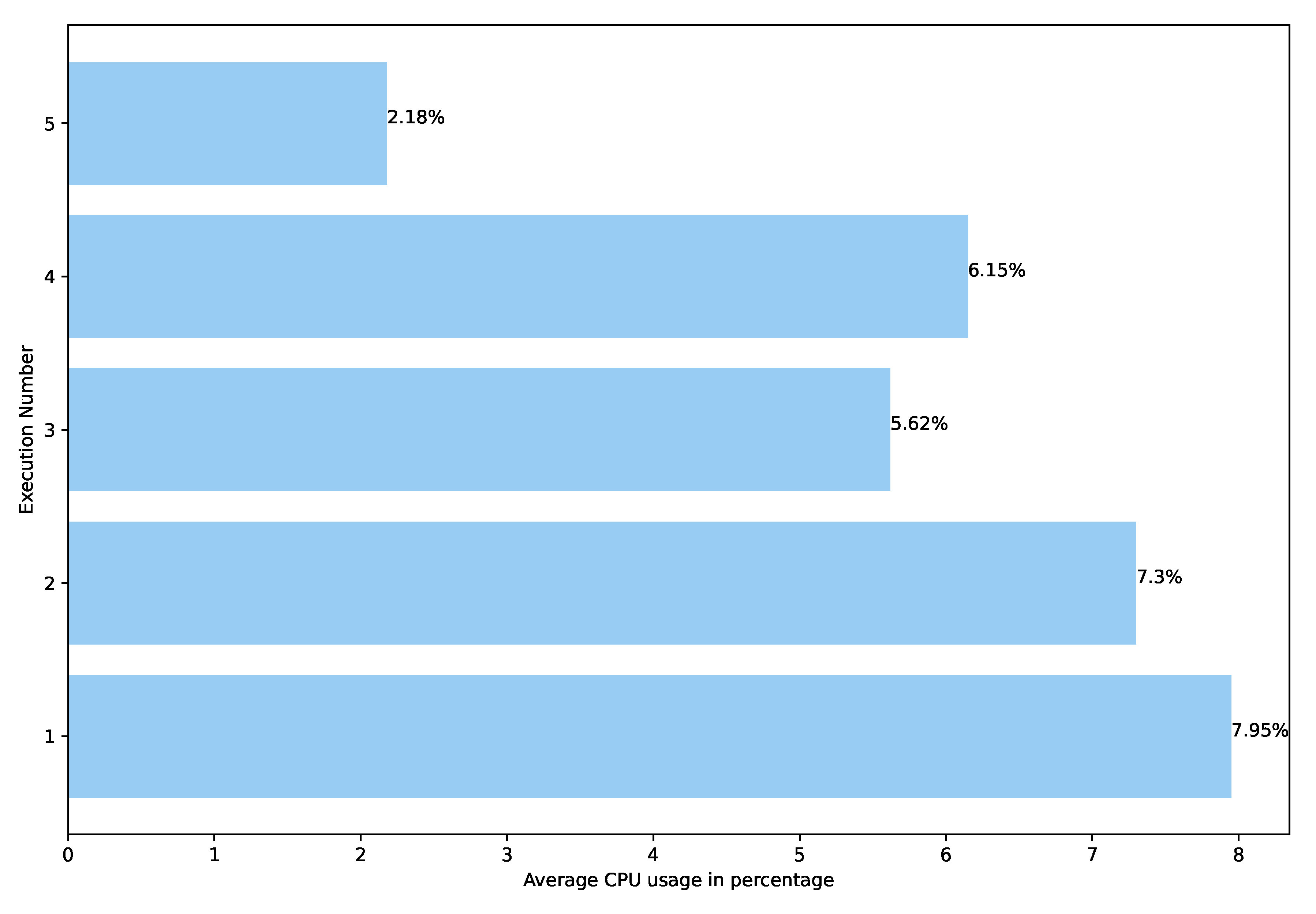
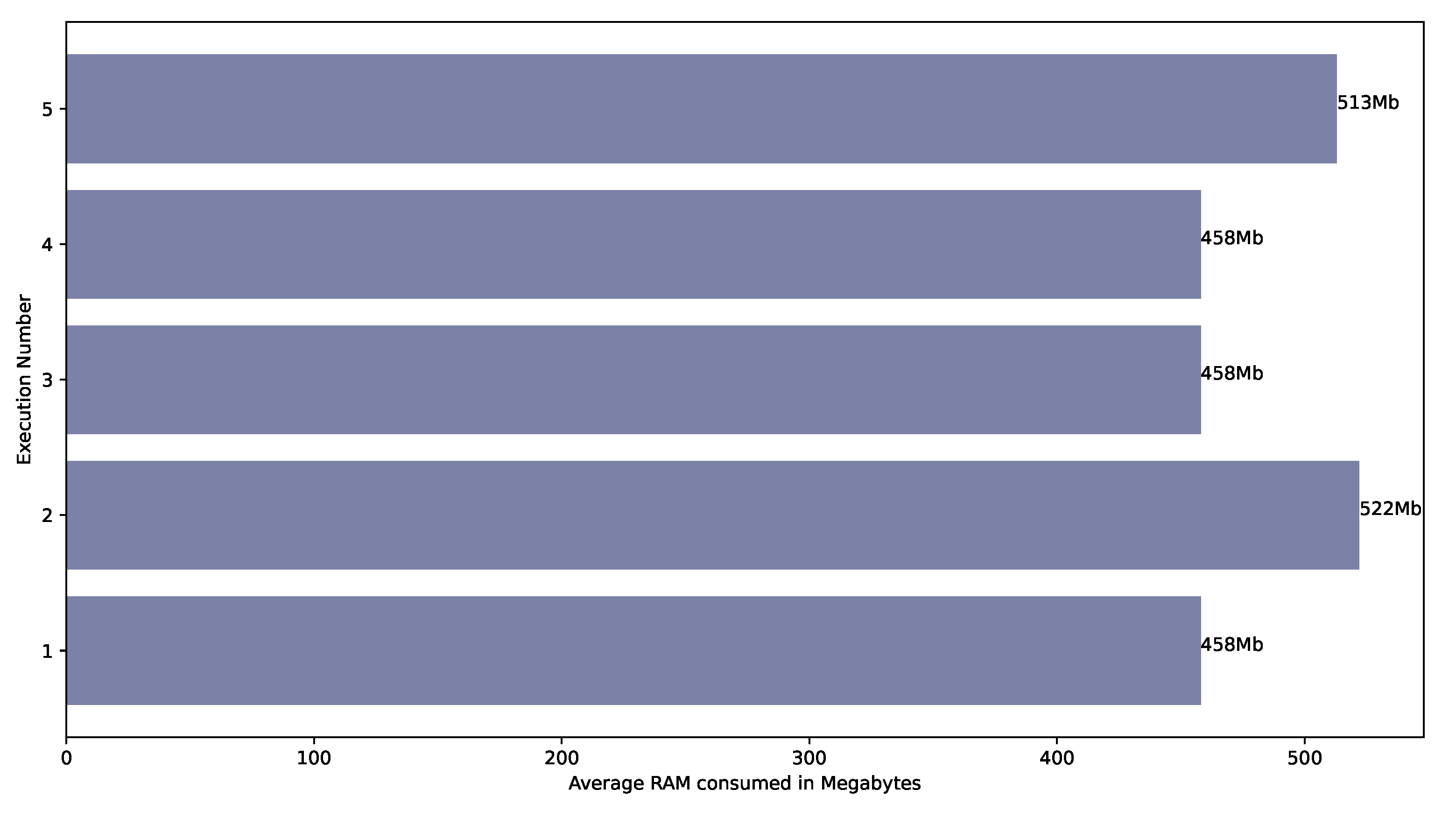
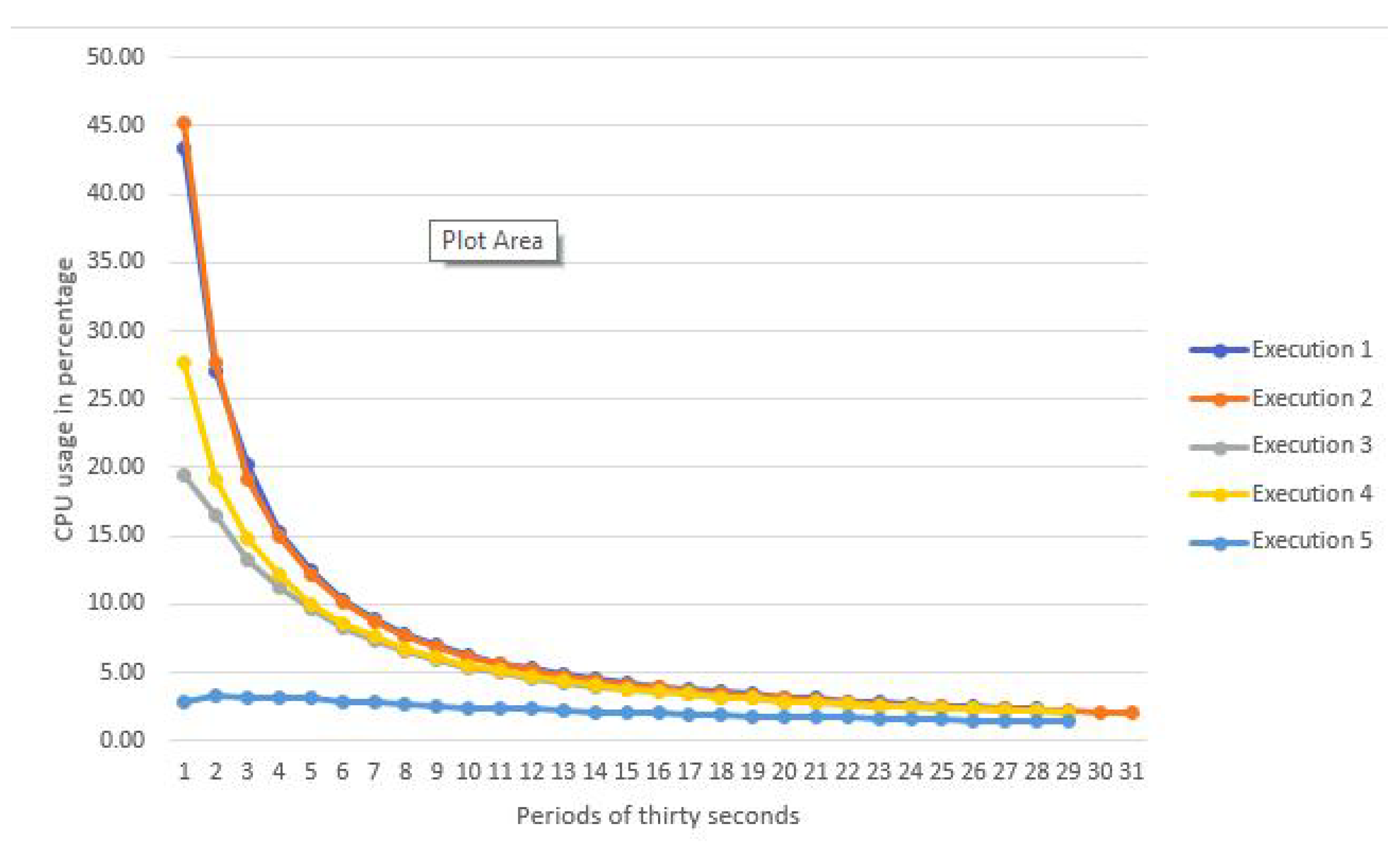
5.4. Performance
5.5. Summary
- 1.
- Automatically deploying analytic pipelines for both contexts development and production in edge, fog and cloud infrastructures: the pipelines created by the data scientist were deployed in a heterogeneous infrastructure composed of edge, fog and cloud layers.
- 2.
- Automatically generating previously unavailable infrastructure: the cloud infrastructure was not available and a virtual machine in Amazon Web Service was created to satisfy this requirement.
- 3.
- Providing a usable client: the process of submitting the required documents to Pangea was conducted using an Angular client created for such an objective. As such, data scientists do not require using a command line interface to create HTTP requests or an external tool such as Postman.
6. Conclusions
7. Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Adadi, A. A survey on data-efficient algorithms in big data era. J. Big Data 2021, 8, 1–54. [Google Scholar] [CrossRef]
- Jones, J.; Ionita, A.; Mihai, I.C. AI and IoT Mapping and the Transition to an Interconnected Cyber Defence and Intelligence Capabilities. Int. Conf. Cybersecur. Cybercrime 2022, 9, 5–22. [Google Scholar] [CrossRef]
- Romero, O.; Wrembel, R.; Song, I.Y. An Alternative View on Data Processing Pipelines from the DOLAP 2019 Perspective. J. Inf. Syst. 2020, 92, 101489. [Google Scholar] [CrossRef]
- Alla, S.; Adari, S.K. What Is MLOps? In Beginning MLOps with MLFlow: Deploy Models in AWS SageMaker, Google Cloud, and Microsoft Azure; Apress: Berkeley, CA, USA, 2021; pp. 79–124. [Google Scholar] [CrossRef]
- Leite, L.; Rocha, C.; Kon, F.; Milojicic, D.; Meirelles, P. A Survey of DevOps Concepts and Challenges. ACM Comput. Surv. 2019, 52. [Google Scholar] [CrossRef]
- Challenges with ML in Production. 2022. Available online: https://docs.cloudera.com/machine-learning/1.1/product/topics/ml-challenges-in-prod.html (accessed on 31 May 2022).
- Díaz-de Arcaya, J.; Miñón, R.; Torre-Bastida, A.I.; Del Ser, J.; Almeida, A. PADL: A Modeling and Deployment Language for Advanced Analytical Services. Sensors 2020, 20, 6712. [Google Scholar] [CrossRef]
- Wagner, H. Deep Mining: A Rock Engineering Challenge. Rock Mech. Rock Eng. 2019, 52, 1417–1446. [Google Scholar] [CrossRef]
- Li, C.C. Principles and methods of rock support for rockburst control. J. Rock Mech. Geotech. Eng. 2021, 13, 46–59. [Google Scholar] [CrossRef]
- Rajapakse, R. Rock Bolts, Dowels, and Cable Bolts. In Geotechnical Engineering Calculations and Rules of Thumb; Rajapakse, R., Ed.; Elsevier/Butterworth-Heinemann: Amsterdam, The Netherlands, 2008; pp. 303–320. [Google Scholar] [CrossRef]
- Nöger, M.; Hartlieb, P.; Moser, P.; Griesser, T.; Ladinig, T.; Dendl, D. The potential of a mine-wide digital rock mass condition monitoring system. In Proceedings of the 5th International Future Mining Conference, Perth, Australia and Online, 6–8 December 2021. [Google Scholar]
- Singh, A.; Singh, U.K.; Kumar, D. IoT in mining for sensing, monitoring and prediction of underground mines roof support. In Proceedings of the 2018 4th International Conference on Recent Advances in Information Technology (RAIT), Dhanbad, India, 15–17 March 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Song, G.; Li, W.; Wang, B.; Ho, S.C.M. A Review of Rock Bolt Monitoring Using Smart Sensors. Sensors 2017, 17, 776. [Google Scholar] [CrossRef]
- illuMINEation-Projcet. 2022. Available online: https://www.illumineation-h2020.eu/ (accessed on 31 May 2022).
- Pivarski, J.; Bennett, C.; Grossman, R.L. Deploying analytics with the portable format for analytics (PFA). In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, San Francisco, CA, USA, 13–17 August 2016; pp. 579–588. [Google Scholar]
- Rahman, A.; Mahdavi-Hezaveh, R.; Williams, L. A systematic mapping study of infrastructure as code research. Inf. Softw. Technol. 2019, 108, 65–77. [Google Scholar] [CrossRef]
- Chef. 2022. Available online: https://www.chef.io (accessed on 31 May 2022).
- Loope, J. Managing Infrastructure with Puppet: Configuration Management at Scale; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2011. [Google Scholar]
- Zadka, M. Salt Stack. In DevOps in Python: Infrastructure as Python; Apress: Berkeley, CA, USA, 2019; pp. 121–137. [Google Scholar] [CrossRef]
- Zadka, M. Ansible. In DevOps in Python: Infrastructure as Python; Apress: Berkeley, CA, USA, 2019; pp. 139–145. [Google Scholar] [CrossRef]
- Chef vs. Puppet vs. Ansible vs. Saltstack: WhichWorks Best for You? 2022. Available online: https://www.edureka.co/blog/chef-vs-puppet-vs-ansible-vs-saltstack (accessed on 31 May 2022).
- Terraform. 2022. Available online: https://www.terraform.io (accessed on 31 May 2022).
- AWS CloudFormation. 2022. Available online: https://aws.amazon.com/es/cloudformation (accessed on 31 May 2022).
- Openstack Heat. 2022. Available online: https://docs.openstack.org/heat (accessed on 31 May 2022).
- Cloudera. 2022. Available online: https://www.cloudera.com (accessed on 31 May 2022).
- 1010data. 2022. Available online: https://www.1010data.com (accessed on 31 May 2022).
- Azure HD Insight. 2022. Available online: https://azure.microsoft.com/es-es/services/hdinsight (accessed on 31 May 2022).
- Verma, A.; Pedrosa, L.; Korupolu, M.; Oppenheimer, D.; Tune, E.; Wilkes, J. Large-scale cluster management at Google with Borg. In Proceedings of the Tenth European Conference on Computer Systems, Bordeaux, France, 21–24 April 2015; pp. 1–17. [Google Scholar]
- Foundation, C.N.C. Official Kubernetes Website. 2022. Available online: https://kubernetes.io (accessed on 31 May 2022).
- Hykes, S. Docker Swarm Engine. 2022. Available online: https://docs.docker.com/engine/swarm (accessed on 31 May 2022).
- KubeEdge. 2022. Available online: https://kubeedge.io (accessed on 31 May 2022).
- Apache Airflow. 2022. Available online: https://airflow.apache.org (accessed on 31 May 2022).
- Guazzelli, A.; Zeller, M.; Lin, W.-C.; Williams, G. PMML: An open standard for sharing models. R J. 2009, 1, 60–65. [Google Scholar] [CrossRef]
- ONNX. 2021. Available online: https://onnx.ai/ (accessed on 31 May 2022).
- Zaharia, M.; Chen, A.; Davidson, A.; Ghodsi, A.; Hong, S.A.; Konwinski, A.; Murching, S.; Nykodym, T.; Ogilvie, P.; Parkhe, M.; et al. Accelerating the Machine Learning Lifecycle with MLflow. IEEE Data Eng. Bull. 2018, 41, 39–45. [Google Scholar]
- Liu, P.; Bravo-Rocca, G.; Guitart, J.; Dholakia, A.; Ellison, D.; Hodak, M. Scanflow: An End-to-End Agent-Based Autonomic ML Workflow Manager for Clusters. In Proceedings of the 22nd International Middleware Conference: Demos and Posters, Middleware ‘21, Virtual Event, 6–10 December 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1–2. [Google Scholar] [CrossRef]
- Crankshaw, D.; Wang, X.; Zhou, G.; Franklin, M.J.; Gonzalez, J.E.; Stoica, I. Clipper: A {Low-Latency} Online Prediction Serving System. In Proceedings of the 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17), Boston, MA, USA, 27–29 March 2017; pp. 613–627. [Google Scholar]
- ML.Net. 2022. Available online: https://dotnet.microsoft.com/learn/ml-dotnet/ (accessed on 31 May 2022).
- Lee, Y.; Scolari, A.; Chun, B.G.; Weimer, M.; Interlandi, M. From the Edge to the Cloud: Model Serving in ML. NET. IEEE Data Eng. Bull. 2018, 41, 46–53. [Google Scholar]
- Zhao, J.; Tiplea, T.; Mortier, R.; Crowcroft, J.; Wang, L. Data analytics service composition and deployment on edge devices. In Proceedings of the 2018 Workshop on Big Data Analytics and Machine Learning for Data Communication Networks, Budapest, Hungary, 20 August 2018; pp. 27–32. [Google Scholar]
- PyCaret. 2022. Available online: https://pycaret.org (accessed on 31 May 2022).
- Seldon. 2022. Available online: https://www.seldon.io (accessed on 31 May 2022).
- Talagala, N.; Sundararaman, S.; Sridhar, V.; Arteaga, D.; Luo, Q.; Subramanian, S.; Ghanta, S.; Khermosh, L.; Roselli, D. ECO: Harmonizing Edge and Cloud with ML/DL Orchestration. Available online: https://www.usenix.org/system/files/conference/hotedge18/hotedge18-papers-talagala.pdf (accessed on 31 May 2022).
- Bhattacharjee, A.; Barve, Y.; Khare, S.; Bao, S.; Kang, Z.; Gokhale, A.; Damiano, T. Stratum: A bigdata-as-a-service for lifecycle management of iot analytics applications. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 1607–1612. [Google Scholar]
- Pytorch, TorchServe. 2022. Available online: https://pytorch.org/serve/ (accessed on 3 March 2022).
- Baylor, D.; Breck, E.; Cheng, H.T.; Fiedel, N.; Foo, C.Y.; Haque, Z.; Haykal, S.; Ispir, M.; Jain, V.; Koc, L.; et al. Tfx: A tensorflow-based production-scale machine learning platform. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1387–1395. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. {TensorFlow}: A System for {Large-Scale} Machine Learning. In Proceedings of the 12th USENIX symposium on operating systems design and implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Kubeflow. 2022. Available online: https://www.kubeflow.org (accessed on 31 May 2022).
- Overview of Docker Compose. 2022. Available online: https://docs.docker.com/compose/ (accessed on 31 May 2022).
- Angular Json Editor package. 2022. Available online: https://www.npmjs.com/package/ang-jsoneditor (accessed on 31 May 2022).
- Angular Material design Stepper component. 2022. Available online: https://material.angular.io/components/stepper/overview (accessed on 31 May 2022).
- Titus. 2022. Available online: https://pypi.org/project/titus2 (accessed on 31 May 2022).
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J.; et al. Apache spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Chef | Puppet | Ansible | Salt |
|---|---|---|---|---|
| Availability | √ | √ | √ | √ |
| Ease of setup | Not very easy | Not very easy | Easy | Not very easy |
| Management | Not very easy | Not very easy | Easy | Easy |
| Scalability | Highly scalable | Highly scalable | Highly scalable | Highly scalable |
| Conf. Language | DSL (Ruby) | DSL (Puppet DSL) | YAML (Python) | YAML (Python) |
| Pricing (up to 100 nodes) | USD 13,700 | USD 11,200–19,900 | USD 10,000 | USD 15,000 |
| Technology | Generate Infrastructure | Provision Machines | Deployment in Distinct Machines | Edge, Fog, Cloud Support |
|---|---|---|---|---|
| MLFlow | - | - | - | √ |
| Scanflow | - | - | - | √ |
| Clipper | - | - | - | √ |
| ML.NET | - | - | - | √ |
| ZOO | - | - | - | √ |
| PyCaret | - | - | - | - |
| Seldom | - | - | - | - |
| ECO | - | - | √ | √ |
| STRATUM | √ | √ | √ | √ |
| TFX | - | - | √ | √ |
| TorchServe | - | - | √ | √ |
| Kubeflow | - | - | √ | - |
| Pangea | √ | √ | √ | √ |
| Name | IP | Node | CPUs | RAM (Mb) |
|---|---|---|---|---|
| node1 | 192.168.0.11 | EDGE | 1 | 512 |
| node2 | 192.168.0.12 | FOG | 2 | 4096 |
| nq1 | 192.168.0.21 | MQTT | 2 | 2048 |
| nq2 | 192.168.0.22 | Kafka | 2 | 4096 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miñón, R.; Diaz-de-Arcaya, J.; Torre-Bastida, A.I.; Hartlieb, P. Pangea: An MLOps Tool for Automatically Generating Infrastructure and Deploying Analytic Pipelines in Edge, Fog and Cloud Layers. Sensors 2022, 22, 4425. https://doi.org/10.3390/s22124425
Miñón R, Diaz-de-Arcaya J, Torre-Bastida AI, Hartlieb P. Pangea: An MLOps Tool for Automatically Generating Infrastructure and Deploying Analytic Pipelines in Edge, Fog and Cloud Layers. Sensors. 2022; 22(12):4425. https://doi.org/10.3390/s22124425
Chicago/Turabian StyleMiñón, Raúl, Josu Diaz-de-Arcaya, Ana I. Torre-Bastida, and Philipp Hartlieb. 2022. "Pangea: An MLOps Tool for Automatically Generating Infrastructure and Deploying Analytic Pipelines in Edge, Fog and Cloud Layers" Sensors 22, no. 12: 4425. https://doi.org/10.3390/s22124425
APA StyleMiñón, R., Diaz-de-Arcaya, J., Torre-Bastida, A. I., & Hartlieb, P. (2022). Pangea: An MLOps Tool for Automatically Generating Infrastructure and Deploying Analytic Pipelines in Edge, Fog and Cloud Layers. Sensors, 22(12), 4425. https://doi.org/10.3390/s22124425