1. Introduction
Since the birth of computers in the last century, the use of passwords has become a widespread way to verify a user’s identity [
1]. This system is simple to program and easy to use, which means the password authentication system could exist for a long time [
2]. To meet safety concerns, a good password must be long and irregular. However, in practice, people have tens or hundreds of accounts to manage, so [
3] saving passwords in a notebook or software might also cause a leakage risk [
4,
5]. Later, people used human-memorable passwords, which can be attacked [
6,
7]. We usually measure the strength of a password using the concept of guessing time. If a password is set using ten small letters, the attacker needs to try at most
guesses.
Businesses, especially small and medium enterprises, suffer from cyber-breaches [
8], and not fixing them in time can lead to data breaches [
9]. If the victim uses plain text to save passwords, attackers can use the leaked username–password pair to stuff the credentials of users onto other service providers [
10], which seriously damages the users’ information security. To protect user passwords, a website usually saves the calculation result of one-way hash functions such as SHA256 in the database rather than the plain text, which significantly increases the cost of attacks [
11,
12]. For higher protection, the websites can add a random string into plain passwords and calculate the hash value of the processed string, called the “salted hash” [
13]. It has been mathematically proven that, for a given hash function such as SHA256, calculating the original text back from a given hash value is almost impossible [
14]. However, calculating the hash value of a given text is relatively easy, so the attacker’s only means of obtaining the password from the hash value is to guess each password and verify its hash value. Attackers can save all the hash values of each password they have ever tried, and they would crack the target hash value when it meets the exact hash text [
15]. Rainbow tables can accelerate this process using the time–space trade-off method [
16]. Recovering passwords from hash values is usually called an offline attack.
It is hard to hit a hash value calculated by a long random string for the salted hash [
17]. To accelerate the attack speed, some researchers focus on improving the hash calculation speed to make attackers try faster [
18], including designing a special application-specific integrated circuit (ASIC) to calculate hash functions and deploy the program on distributed computers [
19,
20,
21,
22]. Accelerating the guessing speed is crucial to making more guesses, but our research in this article focuses on generating high-quality passwords. As long as people keep using human-memorable passwords, most of them will have patterns and laws [
23], in which case the guessing time for the attacker could be much shorter than the worst-case scenario:
, where
s is the size of all possible characters and
l is the maximum length of the password [
24]. The password-generation model based on machine learning can mine password data to generate good passwords in large quantities [
25]. For this reason, it has become a viable option for efficient password cracking.
There are different ways to build a password-generation model. A directed method is the “brute force attack”, which entails trying all possible combinations one by one [
26]. Another method is the “dictionary attack” in which a list of all possible passwords is tried one by one [
27,
28]. These were quite useful for early systems that had small password length limits. With the development of information systems, password-generation methods based on password dictionaries and heuristic rules [
29] were proposed and became the popular methods for guessing a password. Later, a password-generation model based on the Markov process appeared [
16]. Then came probabilistic context-free grammar (PCFG) [
30], which can automatically learn from training data. With the development of deep learning, password-generation models based on an artificial neural network (ANN) have also been proposed, such as long short-term memory (LSTM) [
31] and generative adversarial network (GAN) [
32].
During an offline password attack, high-probability passwords such as 123456 are limited and easy to cover by a trained password-generation model. Completely random passwords with an extremely low probability, such as 2jca3*4, do not have semantic information; therefore, we should not use machine learning models to generate them. However, low-probability passwords such as amen-1999-01 still contain obvious semantic information and have large numbers [
33]. In this work, the focus is on improving machine learning models to improve the generation of low-probability passwords. On the one hand, more low-probability passwords will provide attackers with better password dictionaries in offline attacks. On the other hand, the strength of the passwords can be evaluated better by low-probability models to protect user information.
Our contributions are as follows:
We propose a degenerate distribution algorithm suitable for machine-learning-based password-generation models to generate low-probability passwords effectively.
We apply the algorithm to the PCFG model, which significantly improves the low-probability password hit numbers.
We explore the improvement in low-probability password generation of the model when applying the degenerate algorithms using different parameters to different parts of PCFG.
The structure of this paper is as follows. In
Section 2, we summarize different kinds of guessing methods. In
Section 3, we introduce the low-probability generation– probabilistic context-free grammar (LPG–PCFG) model based on the degeneration distribution. In
Section 4, we show our experiment result and analyze the reason for the difference in each parameter. In the last section, we present our conclusion and prospects for the future research.
2. Related Work
Password-attacking algorithms can be divided into brute force and dictionary cracking. In the brute force cracking method, attackers try to exhaust all strings that satisfy a particular requirement through an enumeration algorithm [
34]. With the help of a graphics processing units (GPUs) and distributed computing [
35], this method may be efficient in a small password space. These two attacks were first proposed to attack the UNIX security system [
36]. However, when the maximum length of the password and the size of the character dictionary increase, the number of operations increases exponentially. Currently, it is usually difficult to traverse all strings with limited computing resources [
37]. In the dictionary-cracking method [
38], attackers first generate a dictionary containing a large number of potential passwords and then try to crack the password. To increase the crack rate, some passwords in the dictionary are transformed by setting rules. Hashcat [
39] sets some common transformation rules to simulate human password creation, for example by turning “love” into “l0ve”. The program John the Ripper [
40] modifies, cuts, and expands words and adds more rules, so it could be more flexible and efficient in cracking.
These two methods are not effective, especially in a huge password space, because they have to perform a huge number of attempts, and some generated passwords are almost meaningless [
41]. Instead of attempting a traversal search, generation methods based on machine learning directly learn the probability distribution of passwords, so they obtain better results.
2.1. PCFG
The PCFG [
30] model splits a password into several variables according to the type of character (letter, digit, or special), so it can model the characters of different parts separately. Houshmand adds keyboard rules in PCFG to consider the relationship of adjacent characters on the keyboard [
42]. This rule makes the model crack some extra passwords that follow keyboard rules. Vears performs deep semantic mining on the letter variable [
43]. For passwords, it performs segmentation and parts-of-speech tagging operations. The model replaces a letter with a similar word on the basis of semantic analysis. Li proposes a Personal-PCFG that treats the user name, email prefix, name, birthday, mobile phone number, and ID card as new variables [
44] that have the same status and positively affect targeted attacks. In addition, other common content such as Chinese Pinyin, date, and common character combinations have also been added to the PCFG model [
45], which inspired Deng to construct a conditional random field generation model [
25]. Han realized the syntax knowledge transfer from short to long passwords by using a transPCFG model.
On the whole, compared with other models based on statistical learning, the PCFG model has finer modeling granularity [
46]. It subdivides the high-probability password structure to increase the number of passwords generated and improve the cracking ratio. Experiments show that it can crack more passwords because of the finer structural divisions.
2.2. Other Password-Generation Models
Other models are based on different assumptions, but they also achieve good cracking. The Markov model thinks that passwords just have local relevance so that each character just correlates with its first several characters [
16]. The Markov model treats all characters equally regardless of type. Tansey proposes a multilayer Markov model that expands the number of layers from one to
n. More layers give the model a stronger representational ability to generate better passwords [
47]. Based on the Markov model, Durmuth introduced OMEN, which generates passwords in descending order of probability [
48]. OMEN makes repeating a password impossible, so it greatly improves cracking efficiency. Guo proposes a dynamic Markov model, which reduces the repetition rate of password generation [
49]. Experimental results show that it definitely has advantages in a targeted attack. The Markov model and its variants usually have a good comprehensive performance [
50].
A neural network with deep layers usually has a larger capacity and better feature extraction capability, so the password-guessing models based on deep learning have received more attention [
51]. Sutskever first generated long text using a recurrent neural network (RNN), which indicated that it was suitable for capturing the relationship between characters [
52]. Since a password is essentially a sequence of strings, Melicher used an RNN to generate passwords [
31]. The RNN outputs a character in each time step and receives it as the input of the next time step. Xu improved the network architecture and replaced the RNN with LSTM, to mine long-range dependency [
53]. Teng proposes PG-RNN, which increases the number of neurons and has a competitive effect on different datasets [
54].
The GAN [
55] is a powerful generation model that has a strong learning ability in computer vision [
56,
57] and natural language processing [
58]. Hitaj introduces PassGAN to generate passwords [
32]. In the PassGAN model, every character is encoded by a one-hot vector and the password is organized into a sparse matrix. The model implicitly learns the probability distribution of the password by minimizing the distance between a fake and real distribution. Nam uses relative GAN to improve the objective function, and it greatly improves password generation through multisource training [
59]. Nam improves the generator by using an RNN to obtain a better iterative representation [
60]. Guo analyzes the generation effect of the GAN and proposes a PG-GAN model that can reduce the password repetition rate [
61].
First, compared to the RNN and GAN models, PCFG has an apparent speed advantage. During training, many weight parameters have to be trained, and some problems such as “non-convergence mode collapse” may appear [
62]. In training, PCFG just needs to count frequency, but in the generation process, it needs fewer calculations than a neural network, which has to perform a large number of multiplication and activation operations. Then, considering password generation quality, the assumption of the Markov model is simple and the learning ability of the neural network is restricted to model capacity [
63]. Passwords generated by PCFG usually comply with most password patterns, and mining semantic information to letter variables could guarantee a reasonable password. Eventually, the neural network model generates duplicate passwords, especially in GAN.
In summary, the PCFG model has fine-grained modeling accuracy and has an advantage in comprehensive ability, including the time cost and quality of generated passwords. Therefore, we modified the PCFG model to generate low-probability passwords.
3. Method
3.1. Random Sampling
After completing the training of the password-generation model
G using the training dataset, a probability value is assigned to each password
x on the support set
, as shown in
Figure 1. Since the password distribution approximately conforms to the Zipf law [
64,
65], the frequency of a password is inversely proportional to its frequency ranking in the password set. There will be many low-probability passwords in the password distribution
, but it will be tough to use enumeration and random sampling directly. Next, we analyze these two methods.
For the generation model based on enumeration, the password is usually generated in approximate descending order of probability; that is, the passwords with high probability are first generated, and then, the passwords in a lower probability interval are generated. Therefore, in the early stage of inferencing of the model, many passwords that are not in the low-probability interval will be generated. Regarding the design of the search algorithm, the enumeration method inevitably traverses and accesses high-probability passwords when searching for low-probability password intervals, which cannot be the model’s sole focus because that would be a waste of computing resources. Finally, the range of low-probability password intervals is extensive compared to those of high-probability, and searching for low-probability passwords would result in unacceptable computational overhead.
The password-generation model can be regarded as random sampling directly from the probability distribution . However, since the chance of occurrence is related to its probability value, the model usually prefers high-probability passwords and has a weaker preference for generating low-probability passwords. Considering the inhomogeneous distribution of password probability values in , there is a magnitude difference between the values of high-probability and low-probability passwords, so directly using random-sampling-based methods to generate low-probability passwords will have lower efficiency.
Compared to the random generation method, the password-generation model based on random sampling reduces the attention range from the string space to the support set so that the learned password features can be used fully, leading to a more extensive, more significant low-probability password-generation potential. Compared to the enumeration method, random sampling does not establish a mandatory password output priority, and in any random sampling, a password with any probability may be generated. Although the frequency of passwords follows a statistical law in a random sample, this method retains many possibilities for creating low-probability passwords. We chose to optimize the password-generation model based on random sampling to adapt it to low-probability tasks.
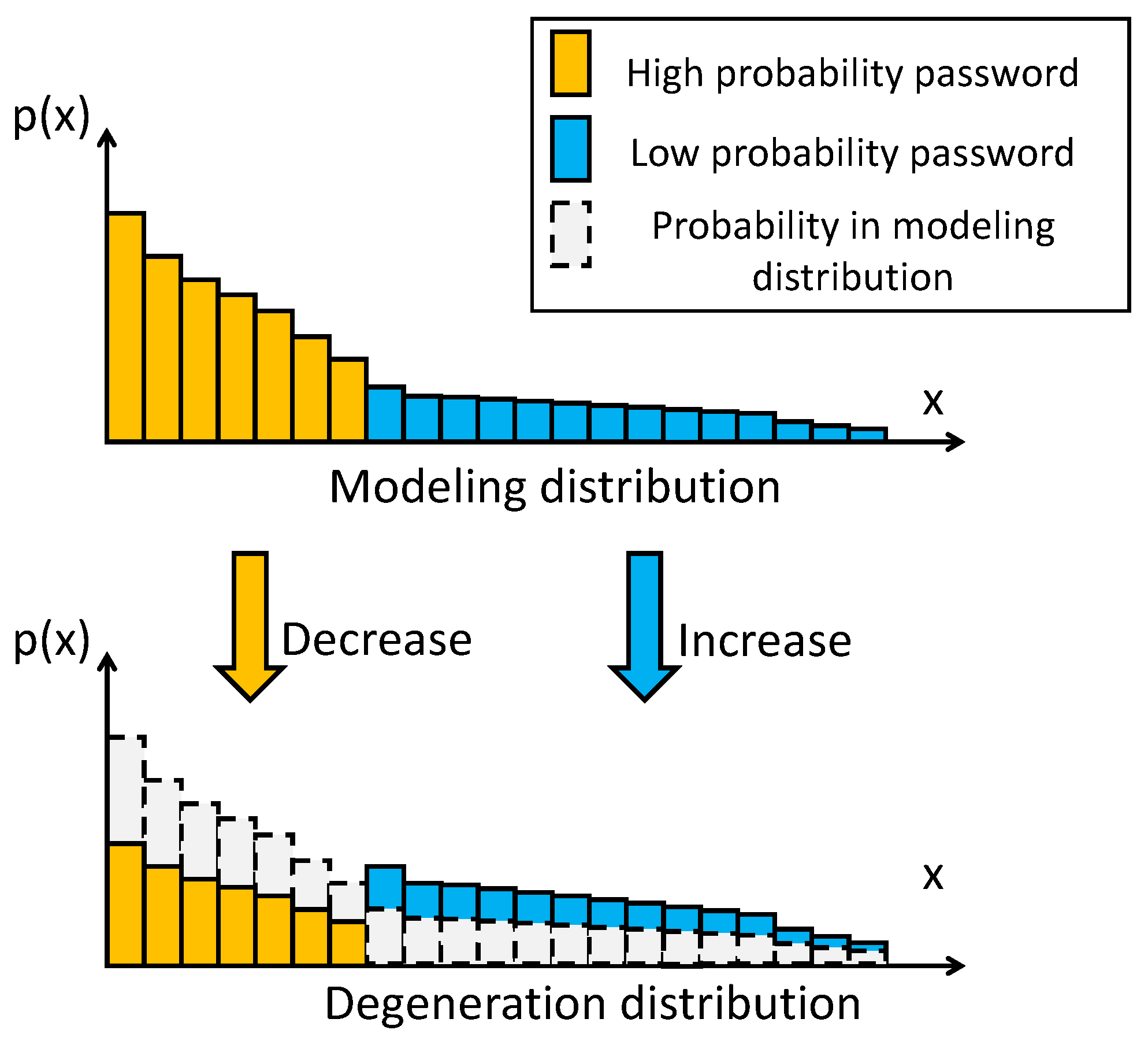
3.2. Degeneration Distribution
The trained password-generation model models the password, and its distribution is recorded as the distribution
. In
, the probability value of the low-probability password
relative to the high-probability password
has many orders of magnitude difference. The degeneration distribution
is a password distribution obtained from the evolution of the modeling distribution
. The difference between the probability values of
and
is significantly reduced, as shown in
Figure 2. Random sampling from the degenerate distribution
can improve the generation of low-probability passwords.
The degeneration distribution is an intermediate state between the modeling and uniform distributions , where retains all the learned password features. At the same time, cannot reflect any password features; it assigns the same probability value to all passwords in the support set. In its initial evolution from the modeling distribution to , the closer the degeneration distribution comes to the uniform distribution, the better the distribution will be for generating low-probability passwords. However, the generated passwords will lack the learned features when the degeneration distribution is very close to the uniform distribution. It is challenging to trade-off high-quality and low-probability passwords in a limited number of generation times. In summary, there is an optimal degeneration distribution that can achieve a balance between the modeling and uniform distributions so that many low-probability passwords can be generated efficiently.
To obtain the degeneration distribution, a high-probability password in the modeling distribution
is necessary; then, it is possible to modify its probability value. The random sampling method has a natural preference for high-probability passwords, which means they can be extracted by random sampling in
, after which the degeneration distribution can be obtained by directly reducing the probability value. To make the degeneration distribution always take the uniform distribution as the endpoint in the evolution, we adopted the following mechanism: whenever the password
was obtained by sampling the generation model, its probability was modified to
, and the
possibility of other passwords in the support set was changed to
, where
represents the number of password elements in the support set. This was recorded as Rule 1, as shown in
Table 1. In addition, considering that the granularity of PCFG modeling is small, we designed three different probability modification rules, denoted as Rules 2–5, to find the optimal degeneration distribution. The specific methods are shown in
Table 1.
Next, we explain that the five password probability adjustment rules in
Table 1 can change the degeneration distribution approach in the direction of a uniform distribution. We used the Kullback–Leibler (KL) divergence to measure the distance between the degenerate
and uniform distributions
:
where
represents the probability of password
in the degenerate distribution. We performed a first-order Taylor expansion in the neighborhood of
, and this approximate expression was obtained:
The distribution after the small adjustment of
is denoted as
, and the corresponding password probability is
. We denote the probability of the currently generated password
as
and all other passwords
as
with
. To compare the changes in KL divergence caused by the above rule adjustment, we had to verify the positive and negative first-order term A of the approximate expression of the KL divergence. In Rule 1,
and
, so
A becomes
According to the inequality,
When
,
. In Rule 2,
and
, so then,
A becomes
Obviously, if
, then
. In Rule 3,
and
, so then,
A becomes
According to the inequality, we have
If
, then
. Finally, in Rule 5,
and
, so then,
A becomes
Similarly, if
is satisfied, then
. It can be shown that when the probability of model
G generating a password is above the average value and the evolution of the degenerate distribution is performed according to
Table 1, the degenerate distribution will continue to move closer to a uniform distribution.
3.3. LPG–PCFG
We applied the degeneration distribution acquisition method described above to the PCFG model and designed the corresponding LPG–PCFG model, for which training was divided into two stages: modeling and degeneration. In the modeling stage, LPG–PCFG learned to obtain the modeling distribution
through the training dataset; in the degeneration stage, the model mainly learned the degeneration distribution
. In the inference phase, we used the random sampling algorithm to sample
for password generation, as shown in
Figure 3.
3.3.1. Modeling Stage
The LPG–PCFG model distinguishes the characters in the password into three types: letters (case-insensitive)
l, numbers
d, and characters
s. The letter part contains 26 letters, the number part 10 numbers, and the character part symbols such as !, @, …, ?. The structure of any password can be parsed from left to right according to its character type. For example, the corresponding structure of the password 123abc123!! is
. We denote
as letter, numeric, and special character variables. The LPG–PCFG model assumes that different variables are independent of each other, so the probability of a password is the product of the structural probability and each partial probability. For example, the probability of 123abc!! is
We parsed the password structure for each password in the training dataset and decomposed it into several parts of letters, numbers, and special characters during the modeling stage. For numeric variables, we counted the occurrence frequencies of those of different lengths, such as
,
,
. For special character and letter variables, it was necessary to conduct similar frequency statistics. All password structures were considered uniformly, and the counts are the different frequency of occurrence of the structure. By normalizing the results of the structure statistics
and
and the statistical results of different length variables, we obtained the probability distribution
of the password structure and the probability distributions of different variable types as
, as shown in
Figure 4.
The letter part usually contains much complex semantic information, so directly treating it as the whole string will not achieve fine-grained modeling. The LPG–PCFG model uses an n-gram language model for further semantic mining to model the letter parts. Each letter in the section has only a probabilistic connection to its n preceding letters, but not to the other letters. We denote as n-gram segments, where represents a particular letter. A letter variable containing m letters can be decomposed into m n-gram segments, so the probability calculation method of the letter variable is the probability multiplication of multiple n-gram segments. For example, the probability of the letter string abc is .
3.3.2. Generation Stage
Since the password needs to be generated in the LPG–PCFG model in both the degeneration and generation stages, we first describe the generation method of the LPG–PCFG model.
When generating a password, the password structure probability distribution
must first be randomly sampled to obtain a specific structure, for example, the selected structure
. Then, the variables of different parts are filled in independently from left to right. The digital
and the special character variables
can be directly obtained by random sampling in the probability distribution
and
. For the the letter variables
, it is necessary to sample continuously n times according to the n-gram model to obtain
n letters, that is, continuous sampling in the conditional probability distributions such as
. The password-generation process is shown in
Figure 5.
3.3.3. Degeneration Stage
In the degeneration stage, whenever a password is generated, its probability value needs to be reduced. When applying the probability adjustment idea to the LPG–PCFG model, we considered the following four aspects:
(1) The probability expression of a password is composed of four probability factors: structural, numerical, special character, and letter n-gram. If the probability is reduced for all factor parts during adjustment, the password probability value having the same character part as the password will also be significantly reduced, which may cause some low-probability passwords to disappear directly. For example, the selected high-probability password “abcd” is very easy to obtain by sampling, while the password “abcd!12” has a low probability. If and are reduced at the same time, the probability of the password ” may be reduced to such an extent that it is a challenge to be sampled later. Therefore, the LPG–PCFG model selects only one factor for probabilistic modification.
(2) When modifying the probability of the factor, the conditional probability distribution of the letter part, which includes up to 26 elements, is relatively simple. The distributions may include many elements, especially when n is relatively large, even into the thousands or tens of thousands. In addition, the password structure distribution also includes more elements. The high-frequency adjustment of these probability distributions with many features requires a sizeable computational resource overhead, and this limitation also made us choose only one factor for probability modification.
(3) When we adjust the probability of a single factor, we only reduce it to a certain extent, not to 0. As shown in the previous example, if the probability of is directly reduced to 0, the likelihood of the password “abcd!12*” also becomes 0 correspondingly, due to the multiplicative relationship of conditional probabilities. If is not modified afterward, the likelihood of “abcd!12*” always remains 0, so it is impossible to sample.
(4) For the modeling distribution of the LPG–PCFG model, the size of its support set is much smaller than that of the string space . For the password that has a probability assigned as 0 by the LPG–PCFG model, its feature is fragile. The passwords in the support set and the string space may have shared strings, but to ensure that the probability adjustment does not affect the non-support set part in the string space, the LPG–PCFG model only restricts adjustment of the probability distribution to the support set. The other passwords in the area always have a probability value of 0.
To sum up, the degeneration distribution used by the LPG–PCFG model is as follows: When the password is generated, a distribution is randomly selected from the distribution of the password structure, numeric variable, special character variable, and n-gram conditional probability distribution in the letter variable, where C is a random variable and the distribution values in C are , while the corresponding probability is . Let the element that increases the probability be and the element that decreases the probability be , where . The LPG–PCFG model correspondingly designs the modification method of according to the above five rules. (1) Subtracting the constant from gives , while increasing becomes ; (2) subtracting the constant gives , while increasing gives ; (3) press by the ratio of to while increasing gives ; (4) reduced to becomes , while increasing becomes ; (5) reduce to , while increasing to .
4. Experiment and Discussion
4.1. Experiment Setup
To verify the effectiveness of the LPG–PCFG model, we conducted model implementation, training, and related comparative experiments on the rockyou [
66] public dataset.
The implementation environment was the Ubuntu 16.04.6 LTS operating system; the programming language was python 3.6; the central processing unit used for program running was an Intel(R) Xeon(R) Silver 4116, with the main frequency being 2.10 GHz and 12 cores and 128 GB of memory.
The algorithm of the LPG–PCFG model in the training stage is shown in Algorithm 1. When the initial training stage was completed, the degenerate stage needed to be performed. The algorithm used in the related experiments in the degeneration stage of the LPG–PCFG model is shown in Algorithm 2. It should be noted that the speed affecting the model included the degeneration times, rules, range, and rate. The degeneration rules comprised the above five rules, and the degeneration range included password structures and different types of variables. The degeneration rule and range significantly affected model performance, and we explore them here in-depth. Finally, for the degeneration LPG–PCFG model, the random sampling algorithm used in the generation stage is shown in Algorithm 3.
| Algorithm 1: LPG–PCFG model training algorithm. |
| 1 Set the initial password structure statistics as |
| 2 Set the numbers statistics as |
| 3 Set the special characters statistics as |
| 4 Set the letters n-gram statistics as |
| 5 for password sample x in training set: |
| 6 Pause the structures of x and obtain |
| 7 for v in ps: |
| 8 if v is number: |
| 9 Update |
| 10 end if |
| 11 if v is special characters: |
| 12 Update |
| 13 end if |
| 14 if v is letter: |
| 15 Update n-gram table |
| 16 Update |
| 17 end if |
| 18 end for |
| 19 Update |
| 20 end for |
| Algorithm 2: LPG–PCFG model degeneration algorithm. |
| 1 Set degeneration rule as , degeneration times as |
| 2 for :: |
| 3 Generate a password x through random sampling |
| 4 Pause the structures of x and obtain |
| 5 Randomly select a part from to degenerate the probability |
| 6 if Selected and the changed part is a number: |
| 7 Change according to |
| 8 end if |
| 9 if The selected and the changed part is a letter: |
| 10 Randomly select an n-gram part to change |
| 11 Change according to |
| 12 end if |
| 13 if The selected and the changed part is a special character: |
| 14 Change according to |
| 15 end if |
| 16 if Selected and the changed part is structure: |
| 17 Change according to |
| 18 end if |
| 19 end for |
| Algorithm 3: LPG–PCFG model generation algorithm. |
| 1 Set generation numbers as |
| 2 for :: |
| 3 Set x as an empty string |
| 4 Randomly select a password structure from |
| 5 for v in : |
| 6 if v is a number: |
| 7 Randomly select a number string form |
| 8 Concat number string into x |
| 9 end if |
| 10 if v is a letter: |
| 11 Continuously sample random letters according to the n-gram table |
| 12 Concat letters into x |
| 13 end if |
| 14 if v is a special character: |
| 15 Randomly select a special character string form |
| 16 Concat special characters string into x |
| 17 end if |
| 18 end for |
| 19 x is a generated password |
| 20 end for |
4.2. Effect of Parameter
First, in the LPG–PCFG model, the training set of the rockyou public dataset is used to complete model training and obtain the modeling distribution . Since the degeneration rule, range, rate, and times affect the distribution , we used the control variable method to examine, in turn, the influence of the above factors in the degeneration stage. To reasonably compare the performance of various degeneration distributions, a certain number of passwords in the experiment were first generated. When examining the hits of low-probability passwords, we counted the number of password hits in a test set in the range of .
4.2.1. Effect of Degeneration Rate
For the five specific degeneration rules, we uniformly limited the probability adjustment range to the structure parts: letters, numbers, and special characters. The number of degeneration times was selected as
; the number of generated passwords was
; the adjustment rate was a gradient in an order of magnitude setup. The degeneration rates in Rules 1 and 2 were 0.99, 0.999, 0.9999, 0.99999, 0.999999, 0.9999999, 0.99999999; the degeneration rates in Rules 3 and 4 were
; the degeneration rate of Rule 5 was 1.01, 1.001, 1.0001, 1.00001, 1.000001, 1.0000001, 1.00000001. The number of low-probability passwords hits in the test set is shown in
Table 2,
Table 3 and
Table 4.
The experimental results show that the degeneration rate has a very significant effect on the model performance of LPG–PCFG. For example, in Rule 2, the degeneration rate of 0.99 and 0.9999999 produced an order of magnitude difference in the number of hits. For different degeneration rules, under the condition of degenerations, the relationship between the rate parameter and the number of low-probability password hits was also different. In Rules 1–3, with an increasing degeneration rate, the number of hits increased gradually and tended to be stable; in Rules 4 and 5, the number of hits increased first and then decreased, which achieved the best performance at and 1.000001, respectively. Overall, when the degeneration rate was larger, the number of hits was generally lower, and when the degeneration rate was lower, LPG–PCFG tended to have a better performance. However, a too-low degeneration rate may not have generated a high hit count.
4.2.2. Effect of Degeneration Range
Next, we discuss the effect of the degeneration range on model performance. In the LPG–PCFG model, the four parts—password structure, letters, numbers, and special characters (respectively, denoted as
p,
l,
n,
s)—are mutually independent in password probability calculations. These four parts also have different ranges of expression. Intuitively, the password structure has the most comprehensive expression range; for the letters and numbers, it is relatively weak; special characters usually have the lowest, so we set up multiple degeneration ranges. To perform a more detailed analysis of the degeneration effect, we also considered the influence of the degeneration rate and fixed the number of degeneration at
. The number of password generations was still set to
. The experimental results under Degeneration Rules 4 and 5 are shown in
Table 5 and
Table 6, respectively.
The experimental results showed that defining different degeneration ranges significantly affected model performance. When the range included the four parts, , the number of low-probability password hits varied with the degeneration rate and reached the maximum number of hits at a specific rate. When the degeneration range did not include the password structure (, , or l), the number of hits remained almost unchanged and relatively stable. When the degeneration range was p or , the changing trends were consistent, and both exhibited a significant increase in hits.
From the analysis of the above results, it could be seen that modifying the distribution of the password structure obtained a better degeneration distribution compared with letters, numbers, and special characters. In this regard, we believe that the structure distributions of high-probability and low-probability passwords are quite different. When the structural part of the passwords has degenerated, more patterns corresponding to low-probability passwords appear, so the random sampling can generate more low-probability passwords.
4.2.3. Effect of Degeneration Times
Now, we discuss the effect of the number of degenerations.
Section 4.2.2 showed that password structure is the optimal choice for the adjustment range, so in this section, we only considered adjusting the degenerate password structure. Since the adjustment rate significantly influences the number of hits, it was still set to the gradient configuration of
Section 4.2.1 and
Section 4.2.2. The number of degenerations was set to
,
,
,
, and
, respectively. The number of generated passwords remained set at
. The experimental results according to Degeneration Rules 4 and 5 are shown in
Table 7 and
Table 8.
It can be seen from the results that the impact of the number of degenerations on low-probability password hits was complex. Overall, for any number of degenerations, the number of hits still varied with the degeneration rate, and the highest number of hits was obtained at a specific degeneration rate. Second, for any degeneration rate, as the number of degenerations increased, the number of hits increased overall. However, the above two trends do not strictly conform to all experimental data. They may also violate phenomena under certain conditions, such as when the degeneration rate in Rule 5 is 1.00000001 and the degeneration number is .
For the above experimental phenomena, we believe that the features of low-probability passwords are relatively insignificant enough, so the LPG–PCFG model often needs slow- and high-frequency adjustments when obtaining the degenerate distribution. Otherwise, the password features are easily lost. Higher degeneration times and lower degeneration rates enable fine-tuned distribution adjustments, while lower degeneration times may make the adjustment insufficient for a good degeneration distribution.
4.2.4. Effect of Degeneration Rule
Based on the above experiments, we discuss how the degeneration rules affected the hits of low-probability passwords. We comprehensively considered three factors: degeneration rate, range, and times. The selection of the degeneration rate is shown in
Section 4.2.1, the choice of degeneration range in
Section 4.2.2, and the selection of degeneration times in
Section 4.2.3. Under the fixed condition of
-times password generation, the optimal model under the five degeneration rules was screened. The results are shown in
Table 9.
The experimental results showed that different degenerate rules will generate different numbers of low-probability password hits when generated times. Rules 1 and 3 can hit about 1600 passwords, while Rules 2, 4, and 5 can hit about 1600–2200. When the optimal performance of Rules 1 and 2 was obtained, the degeneration rate was 0.999999, and the degeneration times were ; the degeneration rate corresponding to the optimal models of Rules 3 and 4 was , and the degeneration times were both . In addition, the degeneration ranges corresponding to the above five rules were all p, which is only the modified password structure.
4.3. Model Performance Comparison
Finally, we compared the performance of the LPG–PCFG model with the PCFG model. According to the conclusion of
Section 4.2.4, the LPG–PCFG model with the best performance was selected according to Degeneration Rule 2; the range was
p; the times were
; the rate was 0.999999. For a fine comparison of the performance of the modeling and degeneration distributions, the number of generated passwords was set to
and
, respectively, and the number of hits to low-probability passwords is shown in
Figure 6 and
Figure 7.
The results showed that below generations, LPG–PCFG can hit 2238 low-probability passwords, while PCFG hit 1488, a relative increase of 50.4%; under generating times, LPG–PCFG can hit 21,208 passwords, while PCFG hit 14,932, a relative increase of 42.0%. It can be seen from the curve that LPG–PCFG can always hit more low-probability passwords than PCFG regardless of the number generated. The difference in the number of hits between the two will increase with the number of generated passwords.
To sum up, on the basis of PCFG, LPG–PCFG finally obtained a satisfactory degeneration distribution by finely controlling the degeneration rate, range, times, and rules. The degenerate distribution limits high-probability passwords and significantly increases the probability value of low-probability passwords. At this time, random sampling in the degenerate distribution found a larger number of low-probability passwords. The results fully demonstrated the effectiveness of the LPG–PCFG model.
However, this algorithm could not effectively improve the low-probability password hit capability of the LPG–PCFG model in all cases. Next, we discuss the different cases of model failure. The degradation rate represents the range of each degradation operation. The results showed that, in most cases, the degradation rate was too large or too small, limiting the model’s low-probability password generation ability. We believe there were two reasons when the degradation rate was too large. First, the probability distribution of the model was excessively degraded, resulting in a password with a lower probability that also had a similar probability to the password in the target interval, thus diluting the occurrence probability of the password in the low probability interval. Second, excessive changes caused by a single degradation may have damaged the modeling of password semantic features, resulting in model failure. In the research on the degradation range, we found that it was the most effective for password structure, but the worst for numbers and special characters. We believe that this phenomenon occurred mainly because the password structure part contained more semantic information; the combination of special symbols and specific numbers had less semantic information, so the effect of degenerate directional numbers and special characters was not good. In the degradation times, the failure situation was similar to the reason for the degradation rate. Insufficient times prevented an improvement in the password probability of the target interval. At the same time, too many degradation times led to the probability of excessive degradation and password dilution outside the target interval, which possibly impaired the modeling of semantic features. In the research on degenerate rules, Rules 1 and 3 did not work well, and the difference between these rules and others was that these two rules would even increase the probability of missing passwords. In comparison, the three different rules made passwords with relatively high probability boost relatively higher probability. We believe that the average increase in low-probability passwords may have caused password probability outside the target range to increase too quickly, thus diluting the probability of the occurrence of passwords in the target range.
5. Conclusions
The trained password-generation model completed the modeling of the password probability distribution. At this time, whether based on the random sampling method or enumeration method, high-probability passwords were straightforward to generate, while many low-probability passwords were not easily generated, resulting in insufficient coverage of low-probability-interval passwords. We analyzed the three aspects of password distribution, sampling method, and model design and proposed a degenerate distribution suitable for dealing with low-probability password generation. Based on the PCFG model, but with finer granularity, we presented the low-probability password-generation model LPG–PCFG based on a degenerate distribution. By finely tuning multiple factors such as degeneration rate, range, times, and rules, we obtained the optimal LPG–PCFG.
The LPG–PCFG model has the following advantages:
Compared with neural-network-based password generation, the LPG–PCFG model had high efficiency and low resource consumption in both the training and generation stages.
Compared with a state-of-the-art PCFG model based on statistical machine learning, LPG–PCFG had a significantly improved low-probability password generation. After generations, the number of hits increased by , and after generations, LPG–PCFG had a relative improvement of .
The degradation algorithm proposed in this paper is interpretable. We mathematically proved that in continuous degradation, the model’s evaluation of the password distribution gradually approached a uniform distribution, so the chances of finding a probabilistic password will gradually increase.
This paper proposed a degeneration algorithm to generate low-probability passwords in specific intervals that proved to be effective in a PCFG model. In password generation, neural networks show excellent performance; however, numerous learnable parameters usually lead to a certain degree of overfitting, which means that neural network model generalization is poor. In the following work, we will focus on applying this algorithm to solving the problems of overfitting and insufficient generalization in models of neural network password generation.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}